
B-Spline Curve Fitting of Hungry Predation Optimization on Ship Line Design

Abstract
:1. Introduction
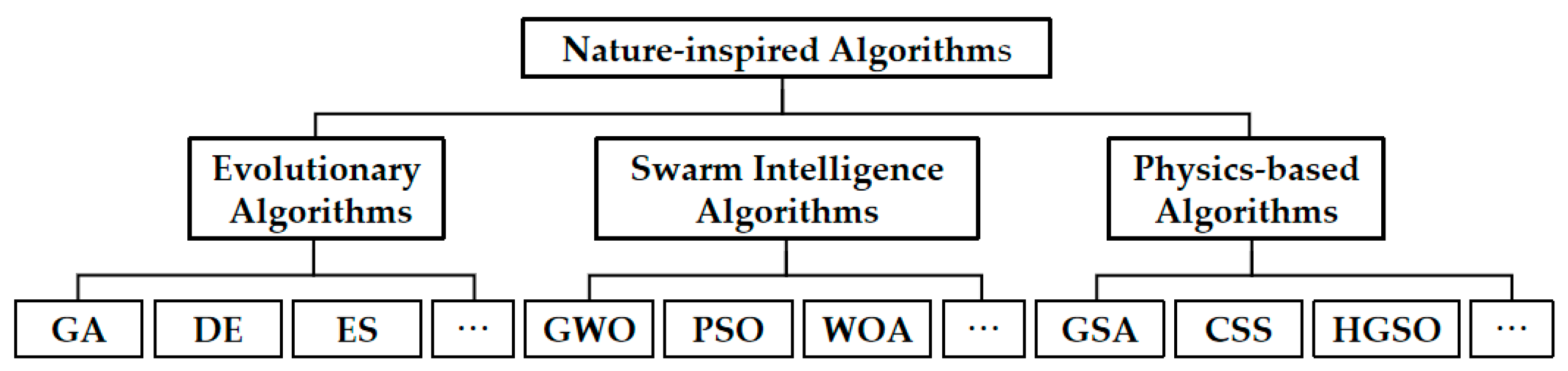
2. Related Works
2.1. B-Spline Theory Knowledge
2.2. Research Status
3. A B-Spline Curve Fitting of Hungry Predation Optimization Algorithm with Knot Guidance
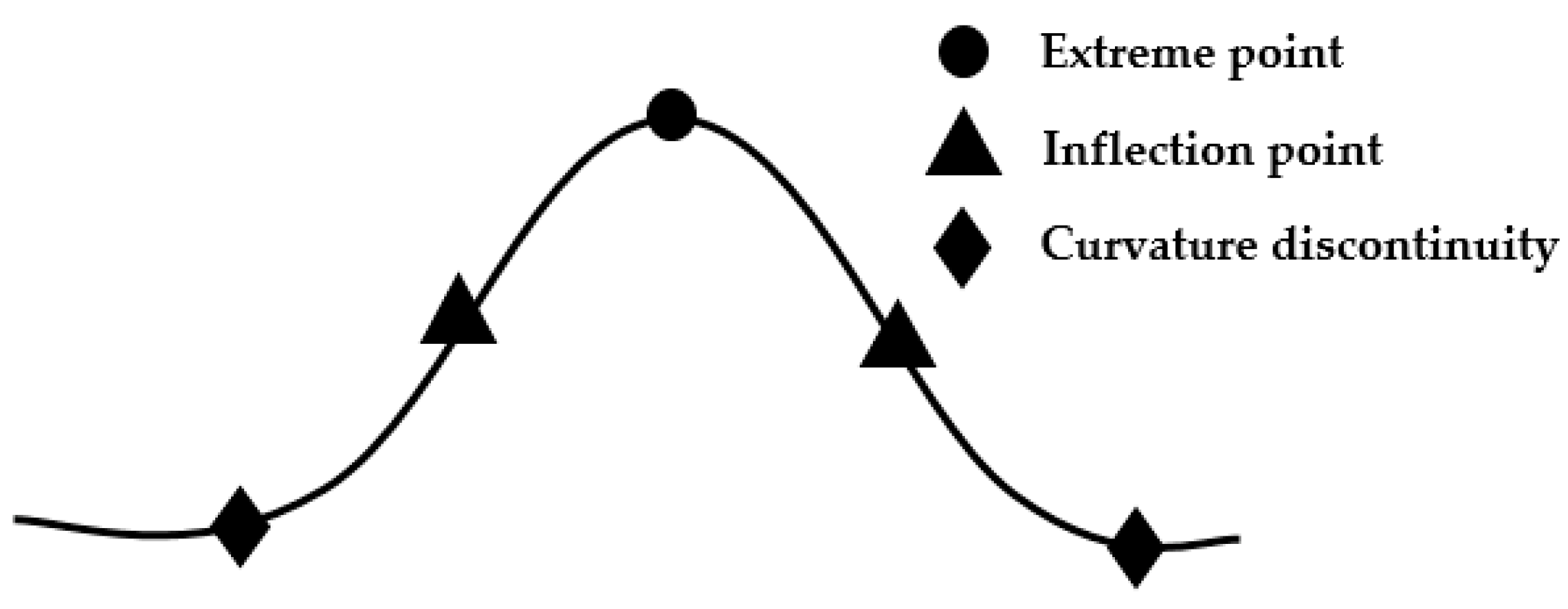
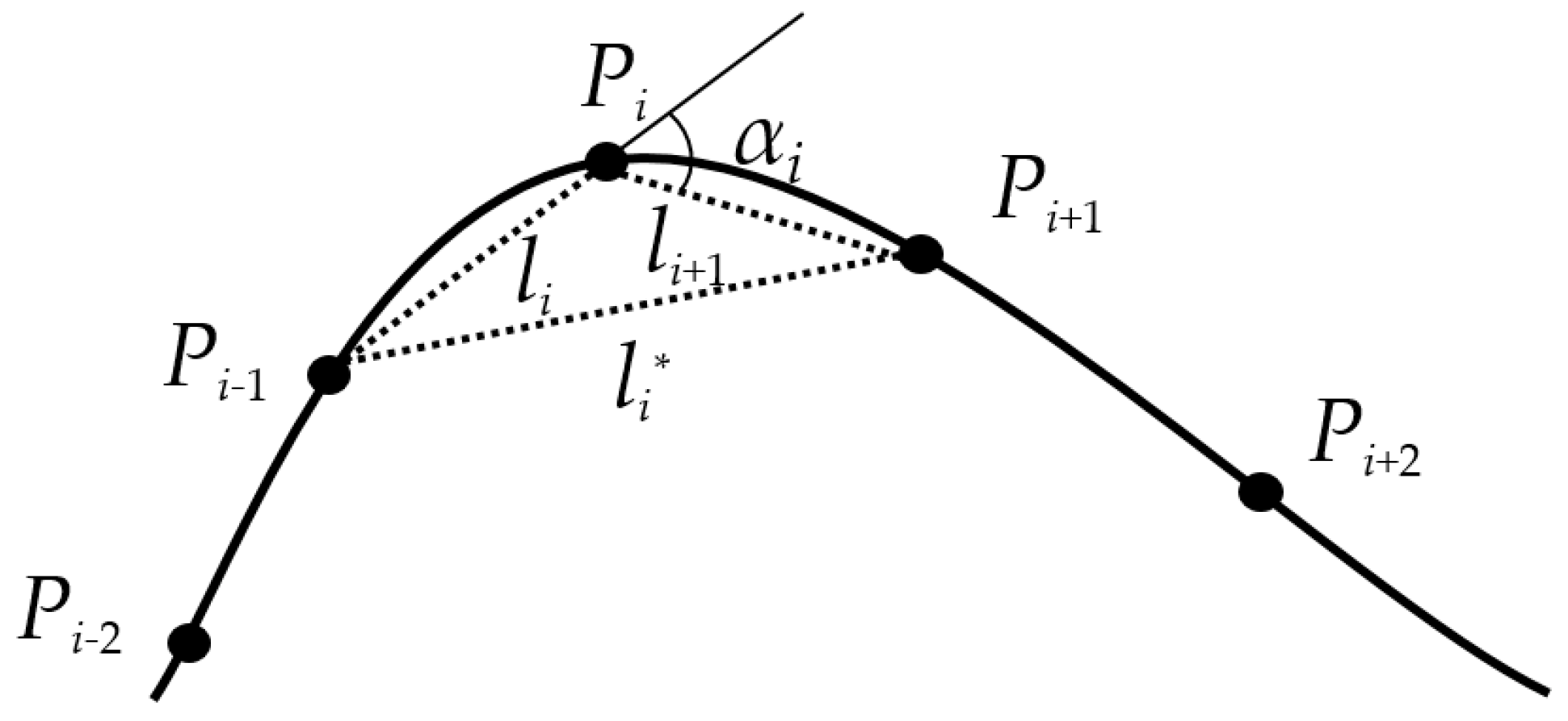
3.1. Knot Guidance Technology
3.2. Hungry Predation Optimization Algorithm
3.3. Fitness Function Selection
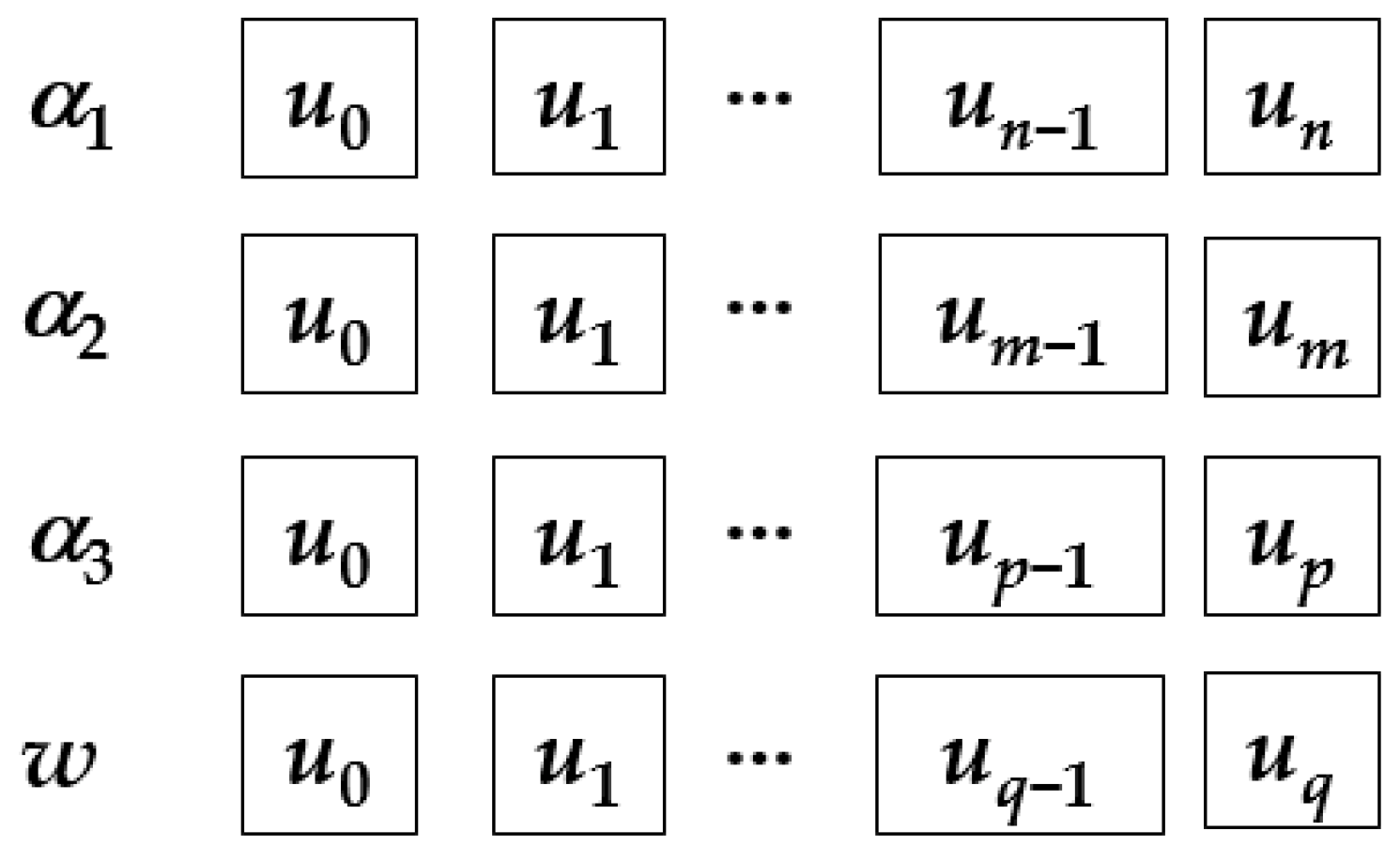
3.4. Dimension Calculation Rule
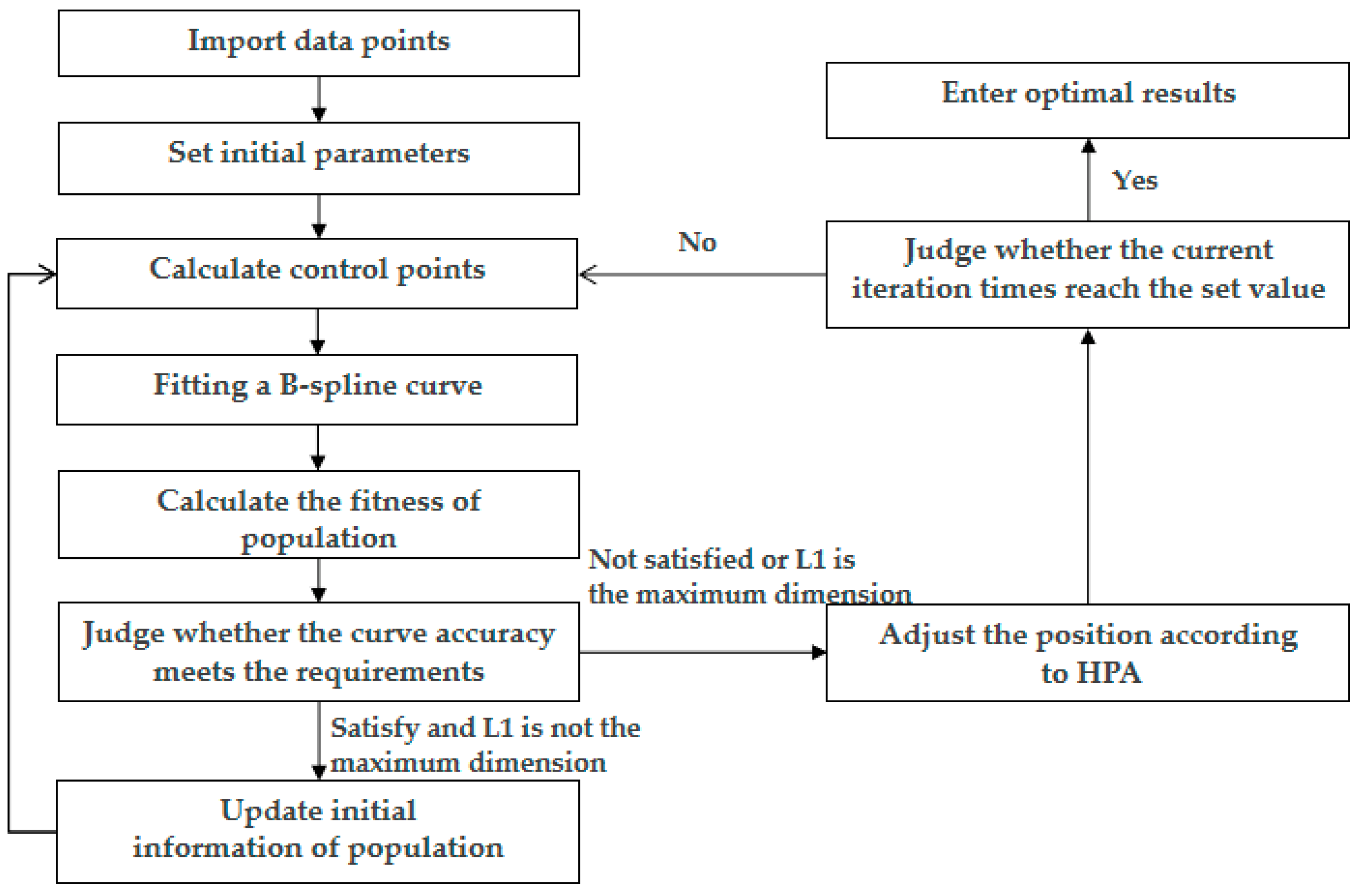
3.5. Algorithm Flow
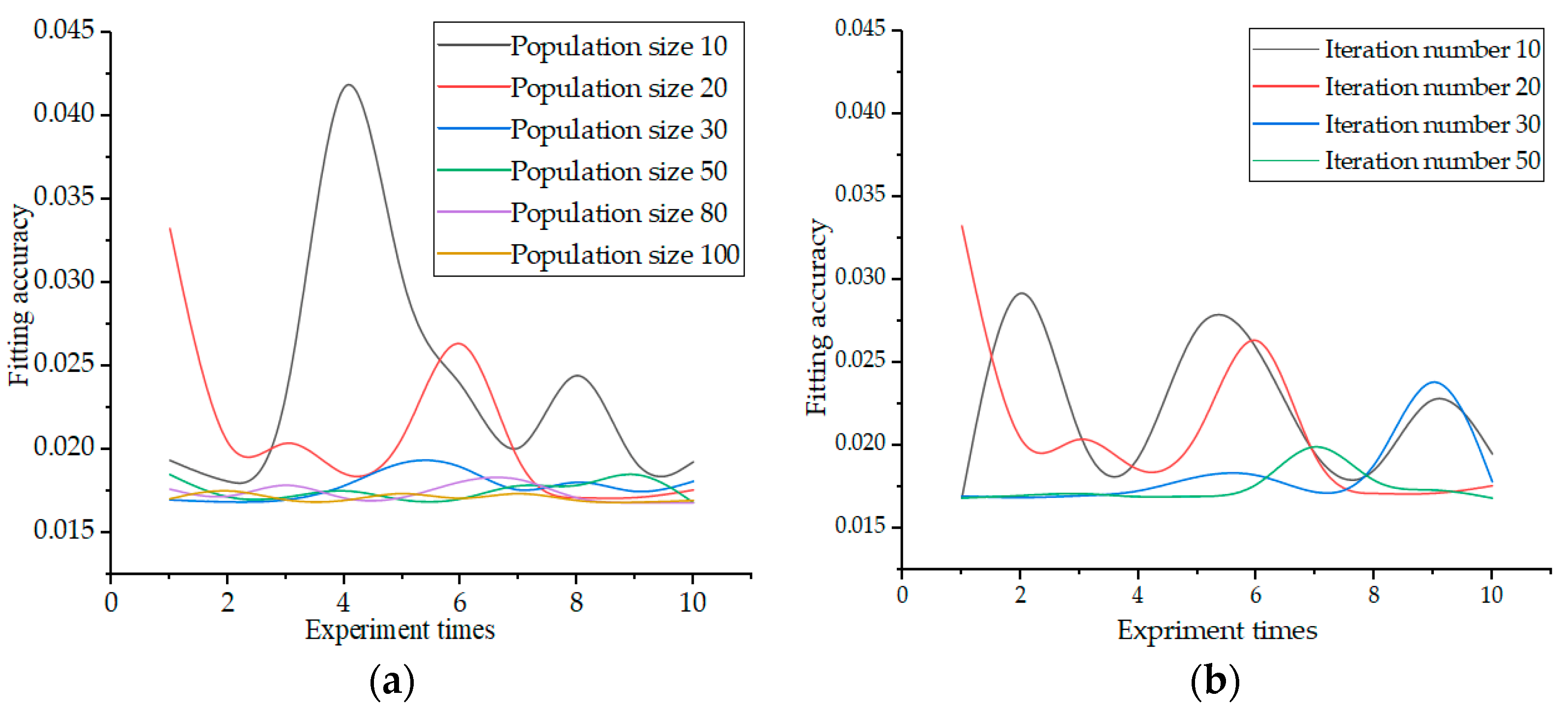
4. Key Parameter Settings
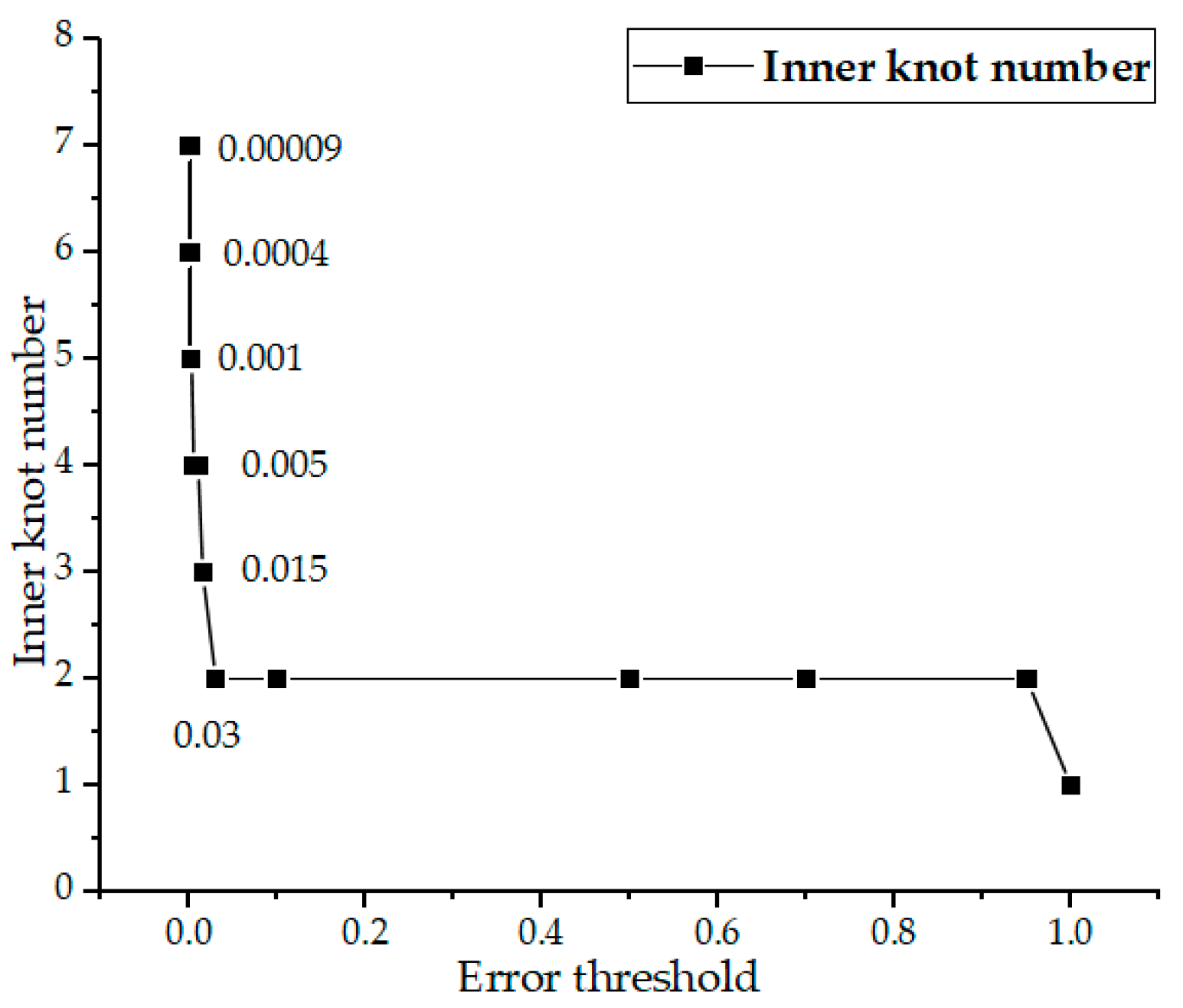
5. HPA Algorithm Test
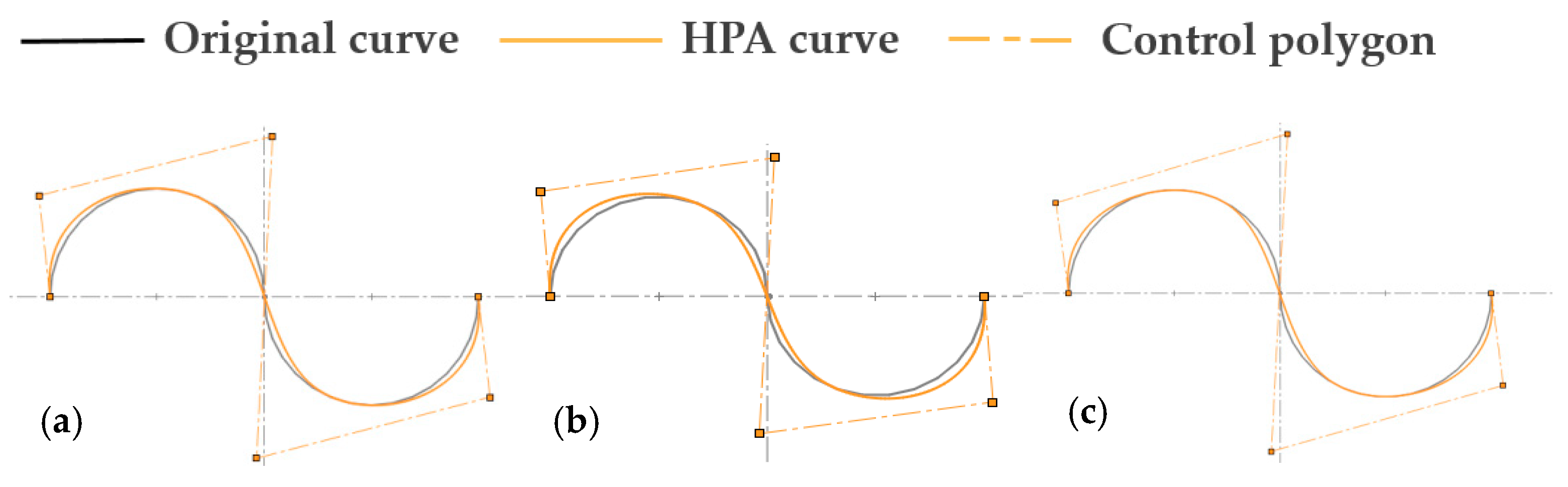
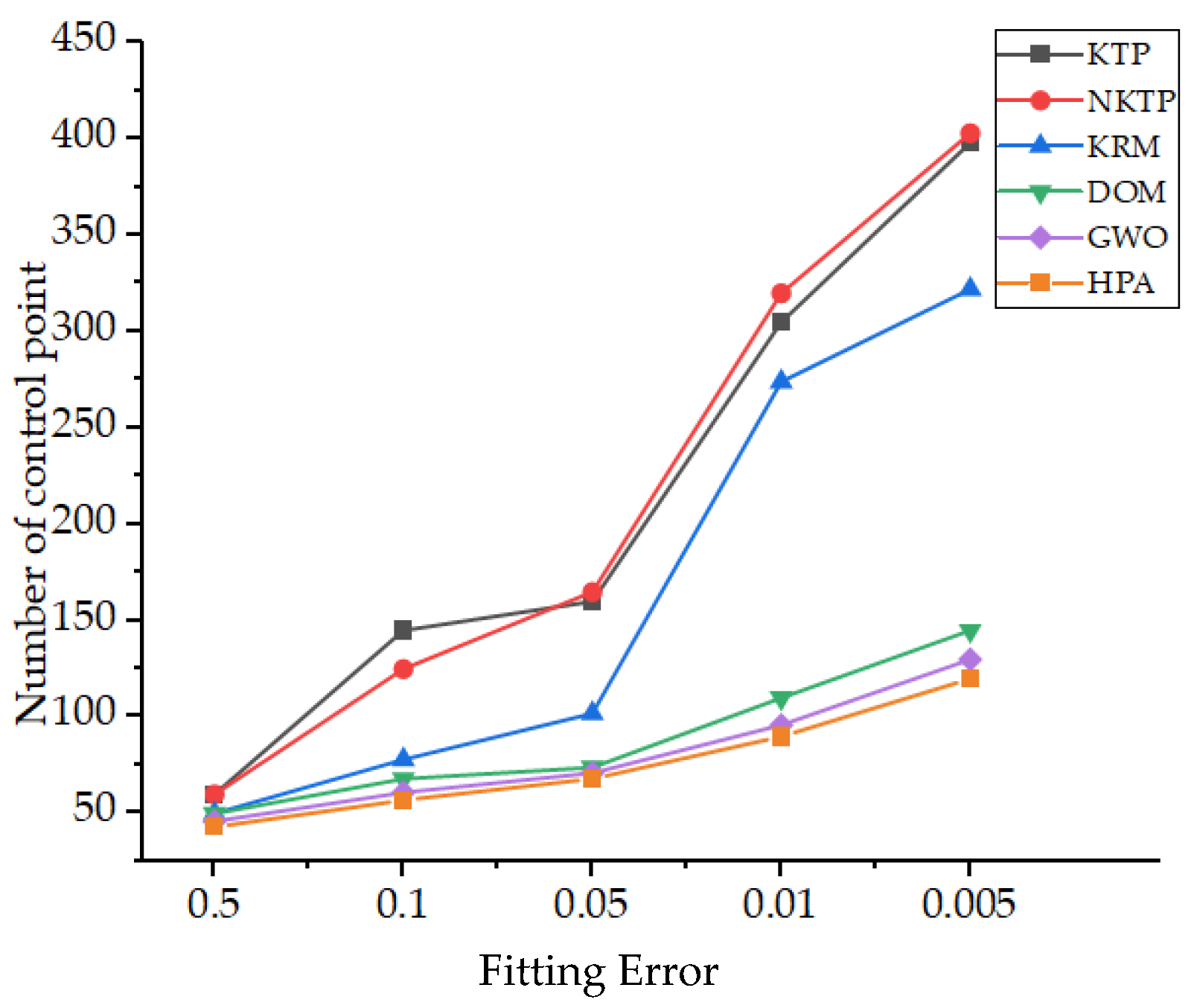
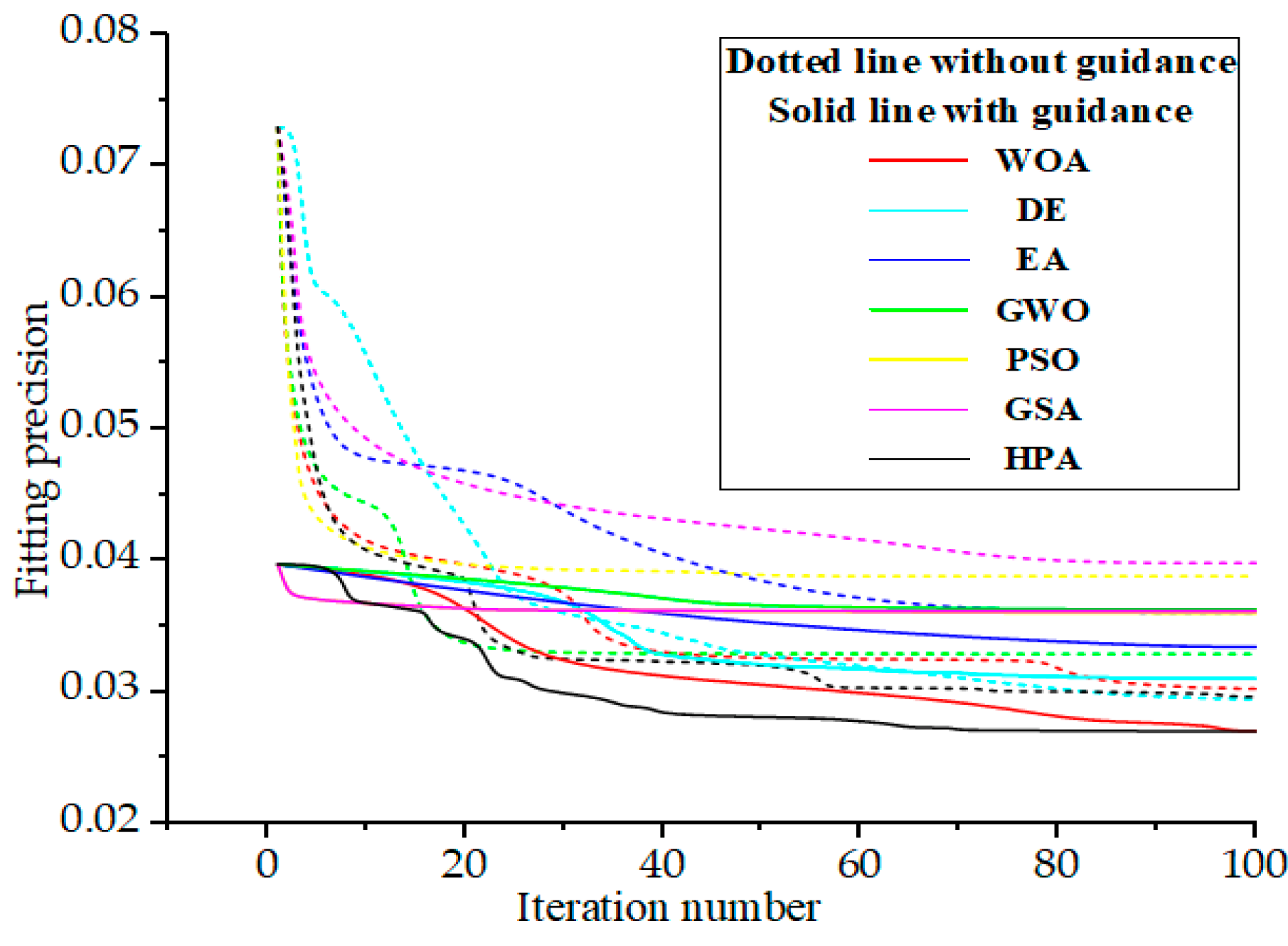
5.1. Comparison with Existing Research
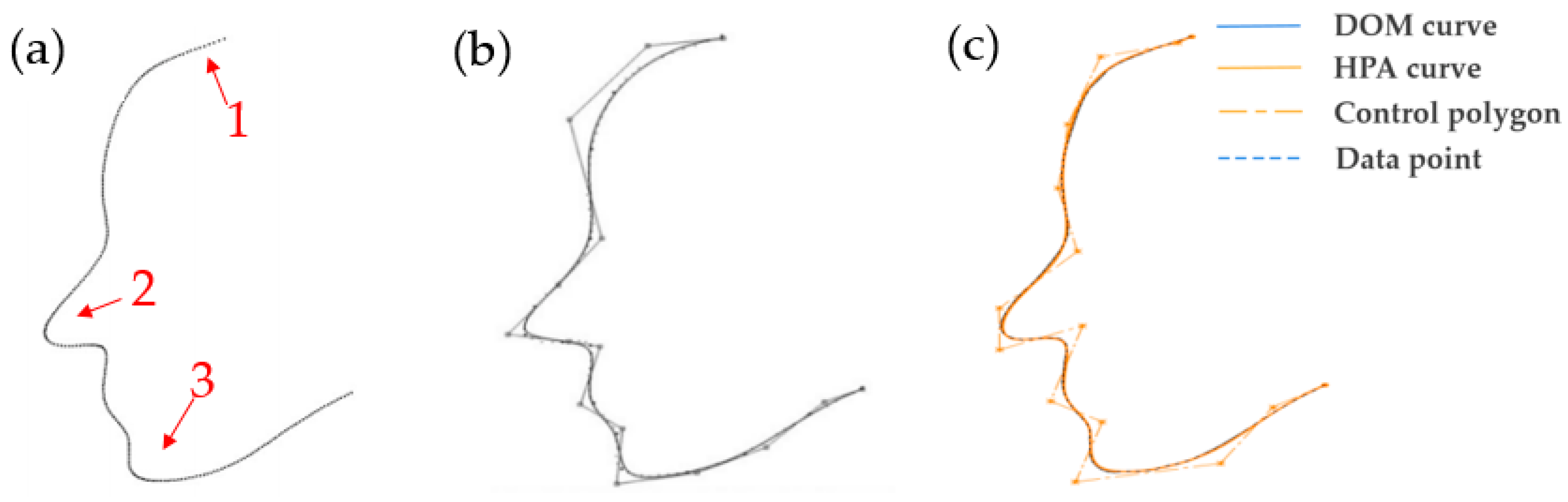
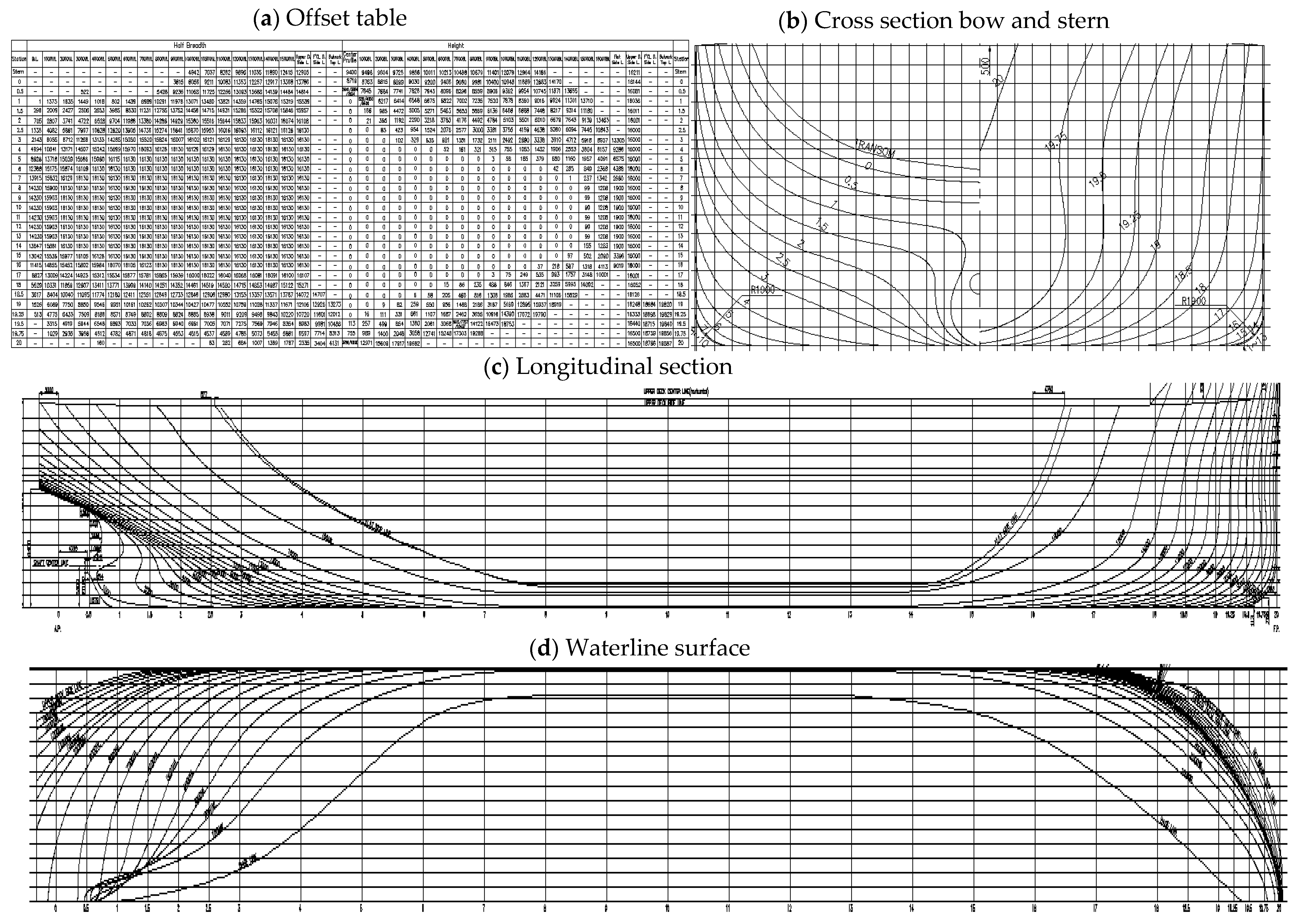
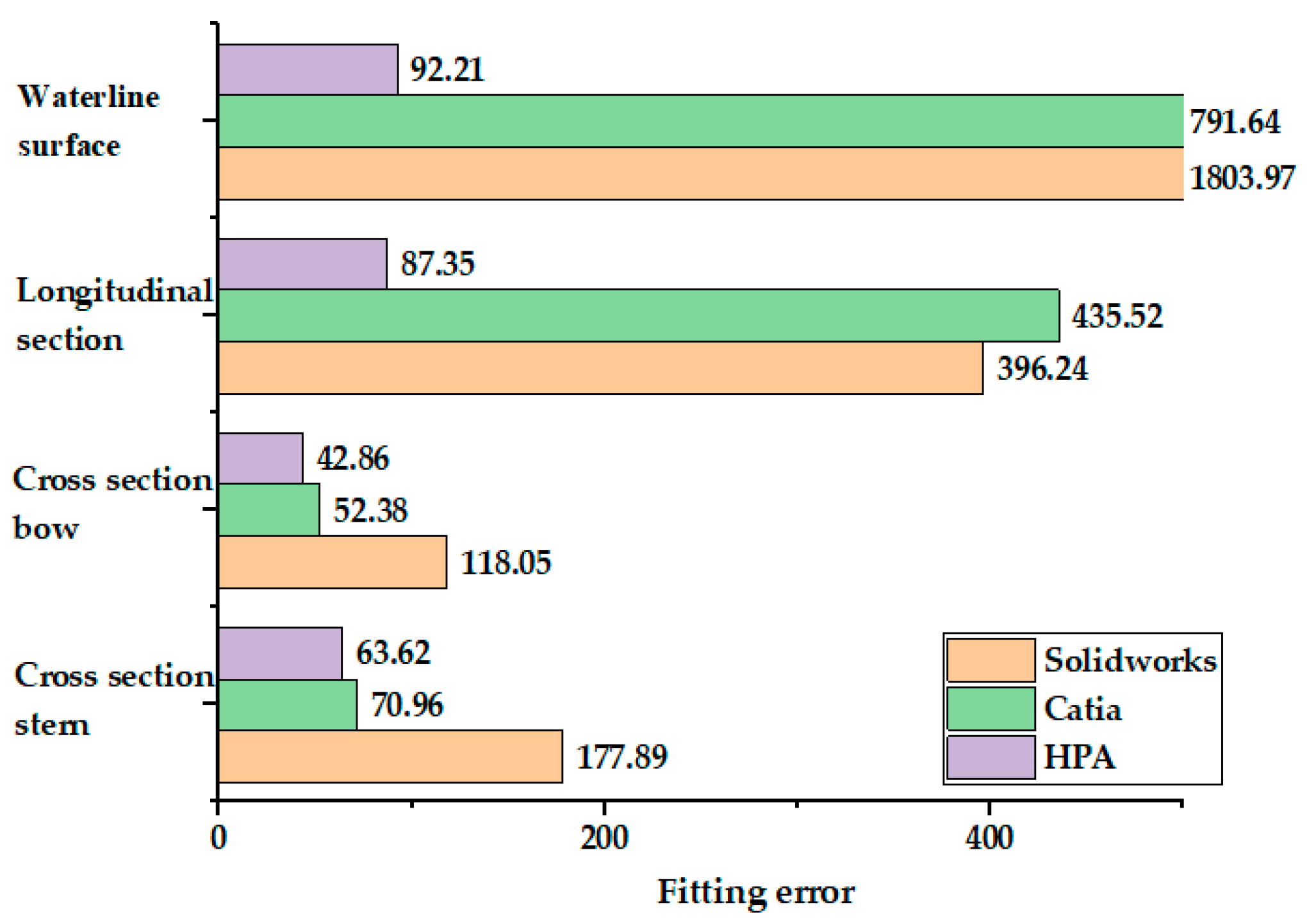
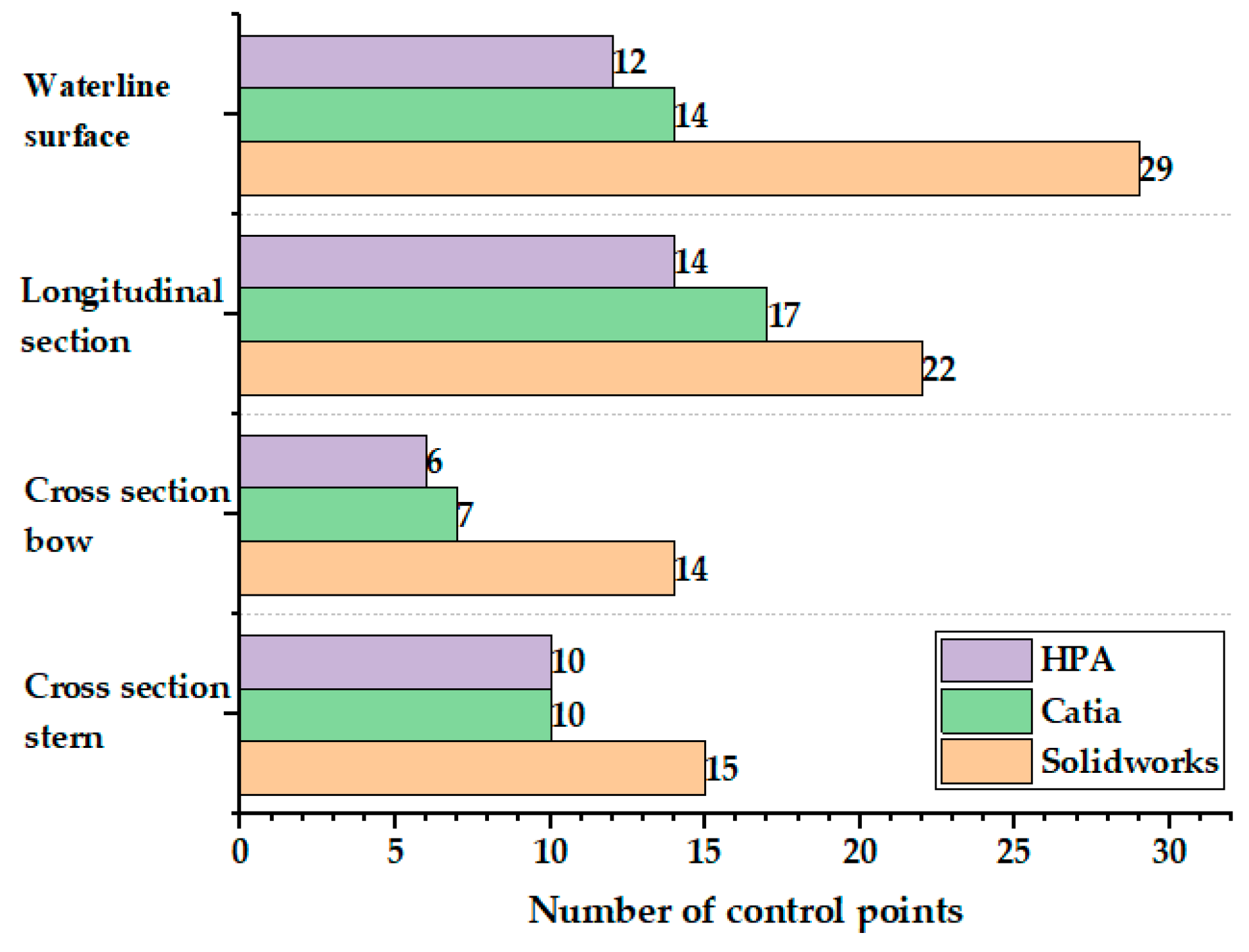
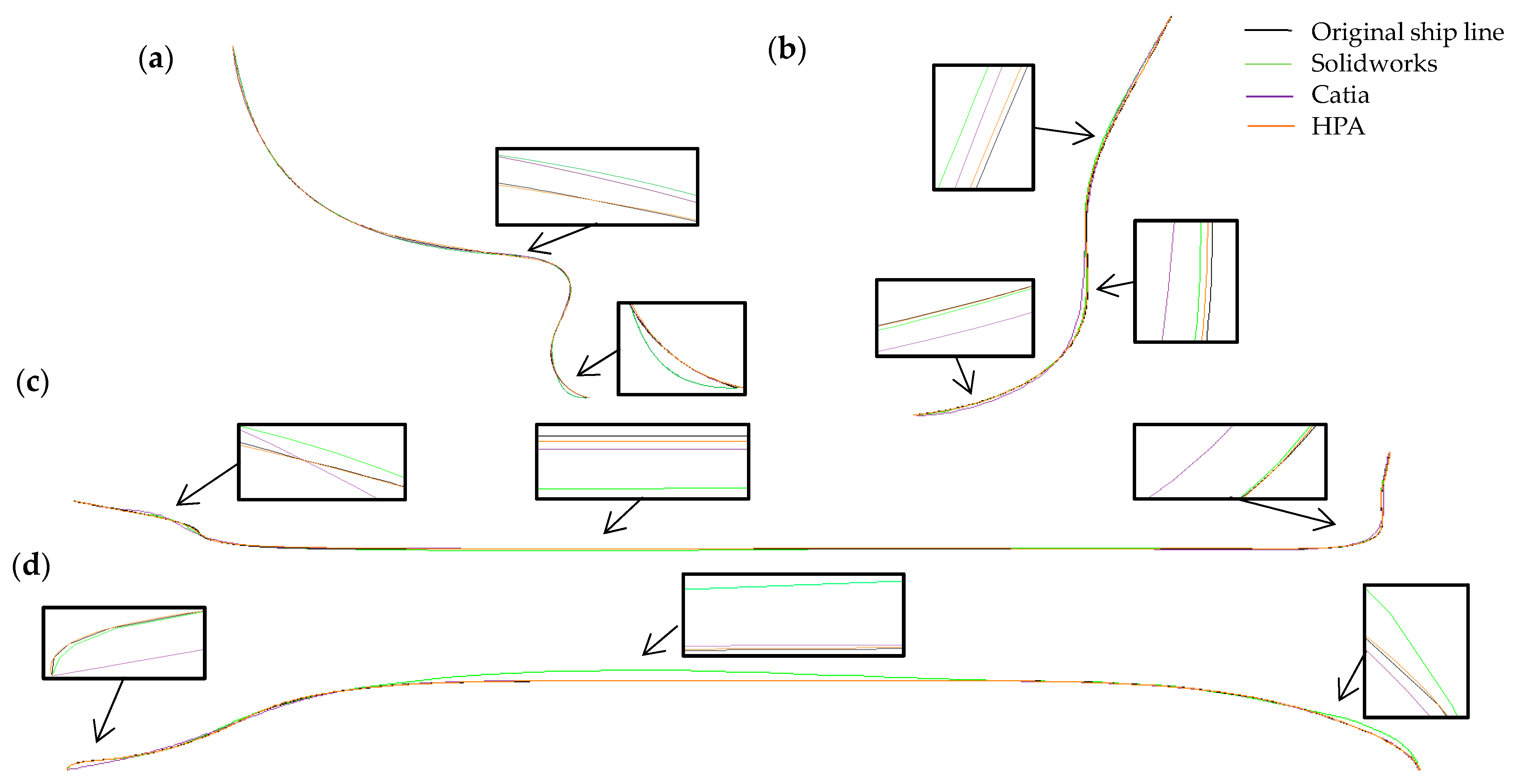
5.2. Fitting of Ship Line
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duan, J.; Wang, B.; Cui, K.; Dai, Z. Path Planning Based on NURBS for Hyper-Redundant Manipulator Used in Narrow Space. Appl. Sci. 2022, 12, 1314. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, S.; Qiu, L.; Liu, X.; Wang, Z.; Wang, Y. Double B-Spline Curve-Fitting and Synchronization-Integrated Feedrate Scheduling Method for Five-Axis Linear-Segment Toolpath. Appl. Sci. 2020, 10, 3158. [Google Scholar] [CrossRef]
- Liu, Y.; Wan, Z.; Yang, C.; Wang, X. NURBS-Enhanced Meshfree Method with an Integration Subtraction Technique for Complex Topology. Appl. Sci. 2020, 10, 2587. [Google Scholar] [CrossRef]
- Li, X.; He, L. Shape Optimization Design for a Centrifuge Structure with Multi Topological Configurations Based on the B-Spline FCM and GCMMA. Appl. Sci. 2020, 10, 620. [Google Scholar] [CrossRef]
- Ni, Y.; Liu, F.; Wu, Y.; Wang, X. Continuous-Time Fast Motion of Explosion Fragments Estimated by Bundle Adjustment and Spline Representation Using HFR Cameras. Appl. Sci. 2021, 11, 2676. [Google Scholar] [CrossRef]
- Son, M.J.; Kim, T.W. Implementation of an executable business process management model for the ship hull production design process. J. Mar. Sci. Technol. 2014, 19, 170–184. [Google Scholar] [CrossRef]
- Yi, L. Application of Web technology and non-uniform B-splines in hull line design system. Ship Sci. Technol. 2020, 42, 4–6. [Google Scholar]
- Ma, J.; Xie, K.; Tong, X. Research and application of hull shape design software based on non-uniform B-splines. Comput. Eng. Appl. 2004, 23, 223–225. [Google Scholar]
- Wang, P. Discussion on the smoothing method of hull line shape. China Water Transp. 2016, 16, 3–5+15. [Google Scholar]
- Ma, W.; Kruth, J.P. Parameterization of randomly measured points for least squares fitting of b-spline curves and surfaces. Comput. Aided Des. 1995, 27, 663–675. [Google Scholar] [CrossRef]
- Lin, H.; Chen, W.; Wang, G. Curve reconstruction based on an interval B-spline curve. Vis. Comput. 2005, 21, 418–427. [Google Scholar] [CrossRef]
- Yang, Z.; Deng, J.; Chen, F. Fitting unorganized point clouds with active implicit B-spline curves. Vis. Comput. 2005, 21, 831–839. [Google Scholar] [CrossRef]
- Jose, E.; Carlos, H.; Maria, D.; Juan, G.; Raul, E.; Horacio, R. Parallel Hierarchical Genetic Algorithm for Scattered Data Fitting through B-Splines. Appl. Sci. 2019, 9, 2336. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Wang, Y.; Liu, Z.; Lu, B. Non-Uniform Rational B-Splines Curve Fitting Based on the Least Control Points. J. Xi’an Jiaotong Univ. 2008, 42, 73–77. [Google Scholar]
- Zhao, D.; Guo, H. A Trajectory Planning Method for Polishing Optical Elements Based on a Non-Uniform Rational B-Spline Curve. Appl. Sci. 2018, 8, 1355. [Google Scholar] [CrossRef]
- Hu, M.; Feng, J.; Zheng, J. An additional branch free algebraic B-spline curve fitting method. Vis. Comput. 2010, 26, 801–811. [Google Scholar] [CrossRef]
- Yoshimoto, F.; Harada, T.; Yoshimoto, Y. Data fitting with a spline using a real-coded genetic algorithm. Comput. Aided Des. 2003, 35, 751–760. [Google Scholar] [CrossRef]
- Sarfraz, M. Representing shapes by fitting data using an evolutionary approach. Comput. Aided Des. A 2013, 1, 179–185. [Google Scholar] [CrossRef]
- Özkan, İ.; İsmail, K. Gray Wolf Optimizer for Knot Placement in B-Spline Curve Fitting. Gaziosmanpasa J. Sci. Res. 2017, 6, 97–109. [Google Scholar]
- He, B.; Feng, R.; Yv, S. B-Spline Curve and Surface Fitting Using Differential Evolution Algorithm. J. Graph. 2016, 37, 178–183. [Google Scholar] [CrossRef]
- Kübra, U.; Erkan, Ü. B-spline curve fitting with invasive weed optimization. Appl. Math. Model. 2017, 52, 320–340. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A.; Avila, A.; Otero, C.; Arias, R.; Manchado, C. Elitist clonal selection algorithm for optimal choice of free knots in B-spline data fitting. Appl. Soft Comput. 2015, 26, 90–106. [Google Scholar] [CrossRef]
- Piegl, L.; Tiller, W. Tiller, the NURBS Book; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Shi, F. CAGD&NURBS; Higher Education Press: Beijing, China, 2013; pp. 57–59. [Google Scholar]
- Kim, I. A development of data structure and mesh generation algorithm for whole ship analysis modeling system. Adv. Eng. Softw. 2006, 37, 85–96. [Google Scholar] [CrossRef]
- Lee, H.-D.; Son, M.-J.; Oh, M.-J.; Lee, H.-W.; Ki, T.-W. Development of a simple model for batch and boundary information updation for a similar ship’s block model. Sci. China Inf. Sci. 2012, 55, 1019–1031. [Google Scholar] [CrossRef]
- Lee, D.; Lee, K.-H. An approach to case-based system for conceptual ship design assistant. Expert Syst. Appl. 1999, 16, 97–104. [Google Scholar] [CrossRef]
- Yv, Y. Research on Reconstruction and Deployment Technology of Ship Curved Surface Segmented Outer Plate; Jiangsu University of Science and Technology: Jiangsu, China, 2016. [Google Scholar]
- Várady, T.; Martin, R.R.; Cox, J. Reverse engineering of geometric models—An introduction. Comput. Aided Des. 1997, 29, 255–268. [Google Scholar] [CrossRef]
- Piegl, L.; Tiller, W. Least–Square B–Spline Curve Approximation with Arbitrary End Derivatives. Eng. Comput. 2000, 16, 109–116. [Google Scholar] [CrossRef]
- Lyche, T.; Morken, K. Knot removal for parametric B-Spline curves and surface. Comput. Aided Geom. Des. 1987, 4, 217–230. [Google Scholar] [CrossRef]
- Lyche, T.; Morken, K. A date reduction strategy for splines. IMA J. Numer. Anal. 1988, 8, 185–208. [Google Scholar] [CrossRef]
- Razdan, A. Knot Placement for B-Spline Curve Approximation; ASU: Phoenix, AZ, USA, 1999. [Google Scholar]
- Park, H.; Lee, J.-H. B-spline curve fitting based on adaptive curve refinement using dominant points. Comput. Aided Des. 2007, 39, 439–451. [Google Scholar] [CrossRef]
- Xu, J.; Ke, Y.; Qu, W. B-spline curve approximation technology based on automatic identification of feature points. Chin. J. Mech. Eng. 2009, 45, 212–217. [Google Scholar] [CrossRef]
- Park, H.; Kim, K.; Lee, S.C. A method for approximate NURBS curve compatibility based on multiple curve refitting. Comput. Aided Des. 1995, 32, 237–252. [Google Scholar] [CrossRef]
- Hamann, B.; Chen, J. Data point selection for piecewise linear curve approximation. Comput. Aided Geom. Des. 1994, 11, 289–301. [Google Scholar] [CrossRef]
- Liu, G.; Wong, Y.; Zhang, Y.; Loh, H. Adaptive fairing of digitized data with discrete curvature. Comput. Aided Des. 2002, 34, 309–320. [Google Scholar] [CrossRef]
- Li, W.; Xu, S.; Zhao, G.; Goh, L. Adaptive knot placement in b-spline curve approximation. Comput. Aided Des. 2005, 37, 791–797. [Google Scholar] [CrossRef]
- Zhou, M.; Sun, S. Genetic Algorithm: Theory and Applications; National Defence Industry Press: Beijing, China, 1999. (In Chinese) [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Seyedali, M.; Seyed, M.; Andrew, L. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X. Review of Research on Grey Wolf Optimization Algorithm. Comput. Sci. 2019, 46, 30–38. [Google Scholar]
- Seyedali, M.; Andrew, L. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Fatma, A.; Essam, H.; Mai, S.; Walid, A.; Seyedali, M. Henry gas solubility optimization: A novel physics-based algorithm. Future Gener. Comput. Syst. 2019, 101, 646–667. [Google Scholar] [CrossRef]
- De Boor, C.; Rice, J.R. Least Squares Cubic Spline Approximation II—Variable Knots; Computer Science Technical Report; International Mathematical Statistical Libraries: Houston, TX, USA, 1968. [Google Scholar]
- Ulker, E.; Arslan, A. Automatic knot adjustment using an artificial immune system for B-spline curve approximation. Inf. Sci. 2009, 179, 1483–1494. [Google Scholar] [CrossRef]
- Ulker, E. B-Spline curve approximation using Pareto envelope-based selection algorithm-PESA. Int. J. Comput. Commun. 2013, 2, 60–63. [Google Scholar] [CrossRef]
- Valenzuela, O.; Delgado-Marquez, B.; Pasadas, M. Evolutionary computation for optimal knots allocation in smoothing splines. Appl. Math. Model. 2013, 37, 5851–5863. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A. Firefly algorithm for explicit B-spline curve fitting to data points. Math. Probl. Eng. 2013, 2013, 528215. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, N.; Zhou, S. Adaptive B-spline knot selection using multiresolution basis set. IIE Trans. 2013, 45, 1263–1277. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
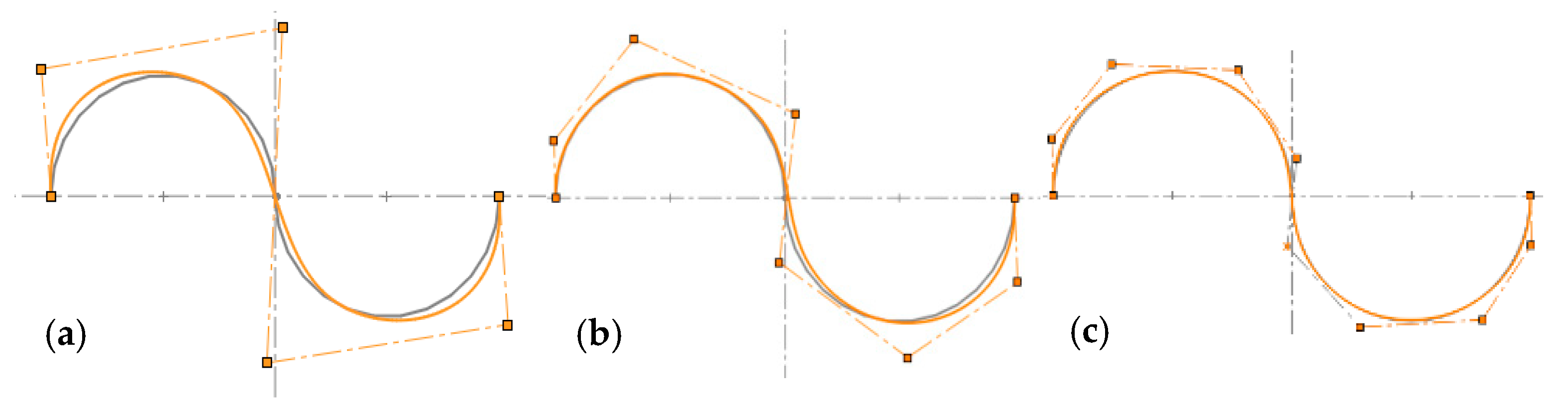{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Incremental Method Using KTP or NKTP | Knot Removal Method KRM | Incremental Method Using DOM | Adaptive Adjustment Using HPA | |
|---|---|---|---|---|
| Preprocessing | 1 Parameterization | 1 Parameterization 2 Interpolation of all points | 1 Parameterization 2 Selection of seed points | 1 Parameterization 2 Find feature points |
| Iteration process | 1 Knot placement 2 Least-squares minimization 3 Deviation check | 1 Selection of a candidate knot 2 Deviation check 3 Knot removal | 1 Knot placement 2 Least-squares minimization 3 Deviation check 4 Selection of a new dominant point | 1 Knot placement 2 Least-squares minimization 3 Comparative fitness 4 Knot adaptive adjustment |
| Ref. | [23,30] | [31] | [34] | Our method |
| Fuction | Description | Variable Range |
|---|---|---|
| 1 | Data point [48] | |
| 2 | [−2, 2] | |
| 3 | [0, 4π] | |
| 4 | [0, 1] | |
| 5 | [−2, 2] | |
| 6 | [−2, 2] |
| Fuction | Degree of Curve | Population Size | Number of Iteration | Number of Point | Number of Knot | Number of Control Point | MSE (GWO) | MSE (HPA) |
|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 50 | 100 | 49 | 16 | 20 | 0.024 | 3.21 × 10−3 |
| 2 | 3 | 50 | 100 | 90 | 53 | 57 | 0.010 | 6.32 × 10−7 |
| 3 | 3 | 50 | 100 | 200 | 77 | 81 | 0.008 | 2.31 × 10−6 |
| 4 | 3 | 50 | 100 | 201 | 40 | 44 | 1.395 | 3.18 × 10−3 |
| 5 | 3 | 50 | 100 | 201 | 46 | 50 | 0.032 | 2.43 × 10−4 |
| 6 | 3 | 50 | 100 | 201 | 37 | 41 | 0.026 | 7.58 × 10−4 |
| Authors, Year and Reference | Method | Iteration Number | Knot Number | BIC |
|---|---|---|---|---|
| Yoshimoto et al. [17] | Genetic algorithms (GA) | 200 | 5 | 1188 |
| Sarfraz and Raza [18] | GA and Detection Algorithms | 120 | × | × |
| Özkan İNİK et al. [19] | Gray Wolf Optimization (GWO) | 100 | 40 | 704 |
| Kübra Uyar et al. [21] | Invasive Weed Optimization (IWO) | 15 | 6 | 430 |
| Gálvez et al. [22] | Artifificial Immune Systems (AIS) | 100 | 5 | 1121 |
| Ulker and Arslan [49] | Artifificial Immune Systems | 500 | × | × |
| Ulker [50] | Pareto Envelope-Based Selection Algorithm (PESA) | 500 | × | × |
| Valenzula et al. [51] | Multi-Objective Genetic Algorithms (MOGA) | 120 | × | × |
| Gálvez and Iglesias [52] | Fireflfly Algorithm (FFA) | 500 | × | × |
| Yuan et al. [53] | Adaptive Multiresolution Basis Set with Lasso Selection Method | Variable | × | × |
| Inner Knot Number | Method | Q1 | RMSE | BIC |
|---|---|---|---|---|
| κ = 3 | HPA | 500.889 | 1.578 | 1313.12 |
| AIS | 593.977 | 1.719 | 1336.79 | |
| κ = 4 | HPA | 329.117 | 1.279 | 1239.32 |
| AIS | 381.871 | 1.378 | 1258.60 | |
| κ = 5 | HPA | 169.758 | 0.919 | 1116.86 |
| AIS | 182.761 | 0.953 | 1121.09 | |
| κ = 6 | HPA | 142.331 | 0.842 | 1092.05 |
| AIS | 181.051 | 0.949 | 1129.81 | |
| κ = 7 | HPA | 122.786 | 0.782 | 1072.96 |
| AIS | 178.013 | 0.941 | 1137.01 | |
| κ = 8 | HPA | 102.723 | 0.715 | 1047.71 |
| AIS | 176.391 | 0.936 | 1145.78 | |
| κ = 9 | HPA | 94.045 | 0.684 | 1040.57 |
| AIS | 174.515 | 0.931 | 1154.24 | |
| κ = 10 | HPA | 92.984 | 0.680 | 1043.60 |
| AIS | 172.218 | 0.919 | 1159.61 |
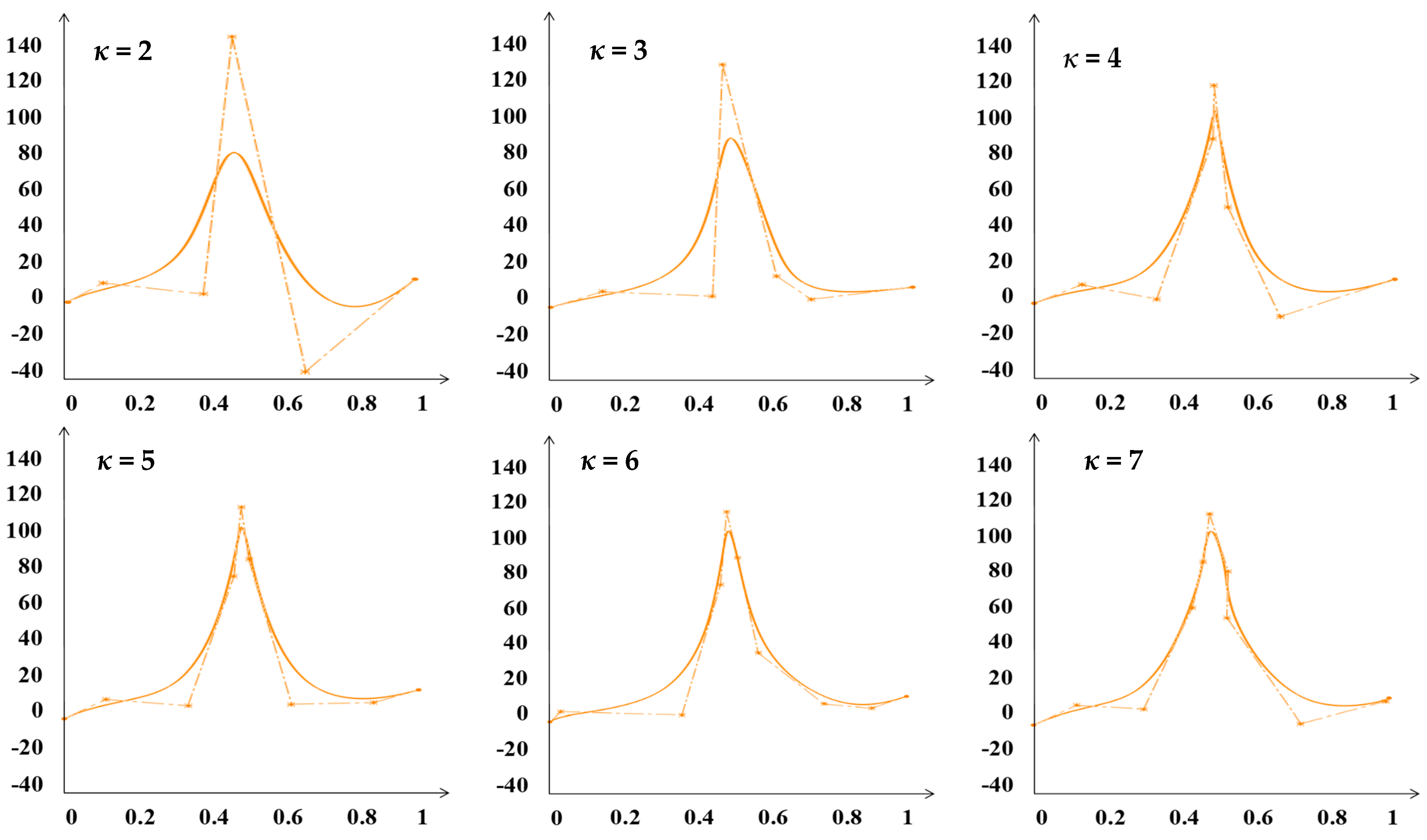
| Inner Knot Number | MSE | BIC | Knot Distribution |
|---|---|---|---|
| κ = 2 | 2.737 | 446.37 | 0.311, 0.372 |
| κ = 3 | 1.015 | 268.32 | 0.282, 0.528, 0.604 |
| κ = 4 | 0.756 | 230.31 | 0.192, 0.505, 0.505, 0.505 |
| κ = 5 | 0.735 | 245.76 | 0.152, 0.472, 0.472, 0.472, 0.717 |
| κ = 6 | 0.707 | 259.12 | 0.151, 0.476, 0.476, 0.476, 0.697, 0.819 |
| κ = 7 | 0.643 | 261.50 | 0.230, 0.309, 0.470, 0.470, 0.530, 0.673, 0.785 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Liu, M.; Ge, S. B-Spline Curve Fitting of Hungry Predation Optimization on Ship Line Design. Appl. Sci. 2022, 12, 9465. https://doi.org/10.3390/app12199465
Sun C, Liu M, Ge S. B-Spline Curve Fitting of Hungry Predation Optimization on Ship Line Design. Applied Sciences. 2022; 12(19):9465. https://doi.org/10.3390/app12199465
Chicago/Turabian StyleSun, Changle, Mingzhi Liu, and Shihao Ge. 2022. "B-Spline Curve Fitting of Hungry Predation Optimization on Ship Line Design" Applied Sciences 12, no. 19: 9465. https://doi.org/10.3390/app12199465
APA StyleSun, C., Liu, M., & Ge, S. (2022). B-Spline Curve Fitting of Hungry Predation Optimization on Ship Line Design. Applied Sciences, 12(19), 9465. https://doi.org/10.3390/app12199465