
An Artificial Intelligence-Based Algorithm for the Assessment of Substitution Voicing

 ,
, 
Abstract
:1. Introduction
1.1. Issue
1.2. A State of the Art Review in Machine Learning Applications for Vocal Pathology Detection and Analysis
1.3. Proposed Research
2. Materials and Methods
2.1. Groups
2.2. Speech Recordings
2.3. Auditory-Perceptual Evaluation
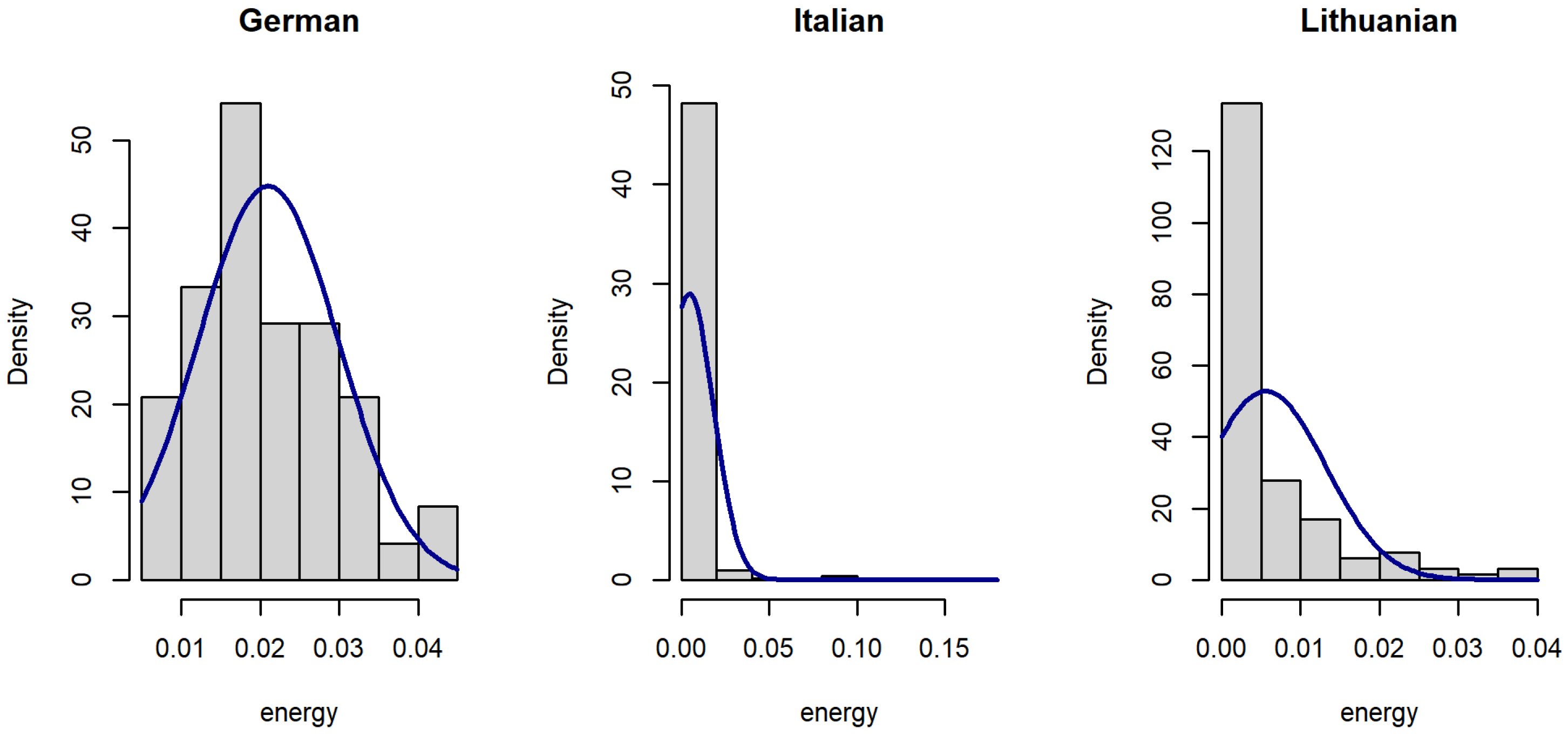
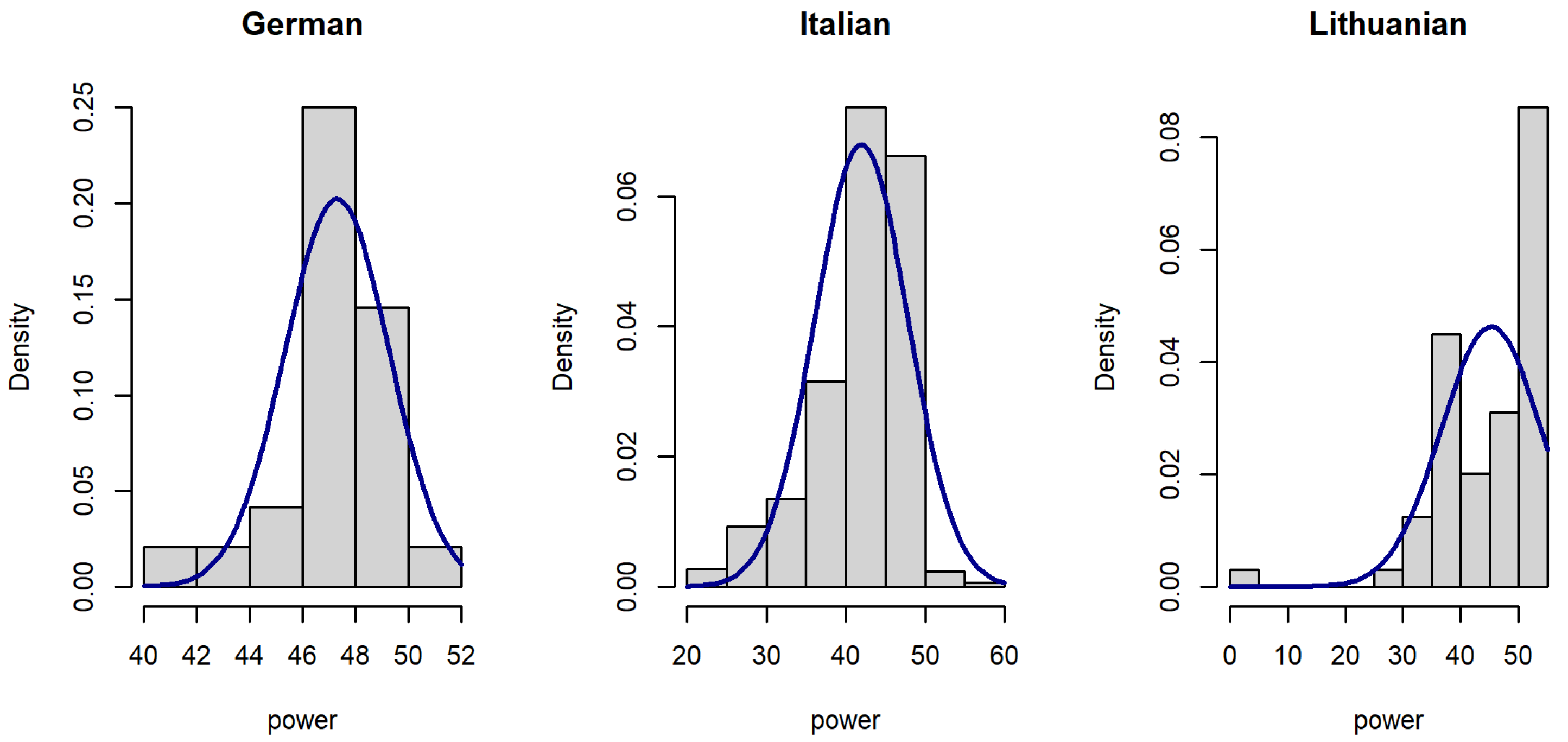
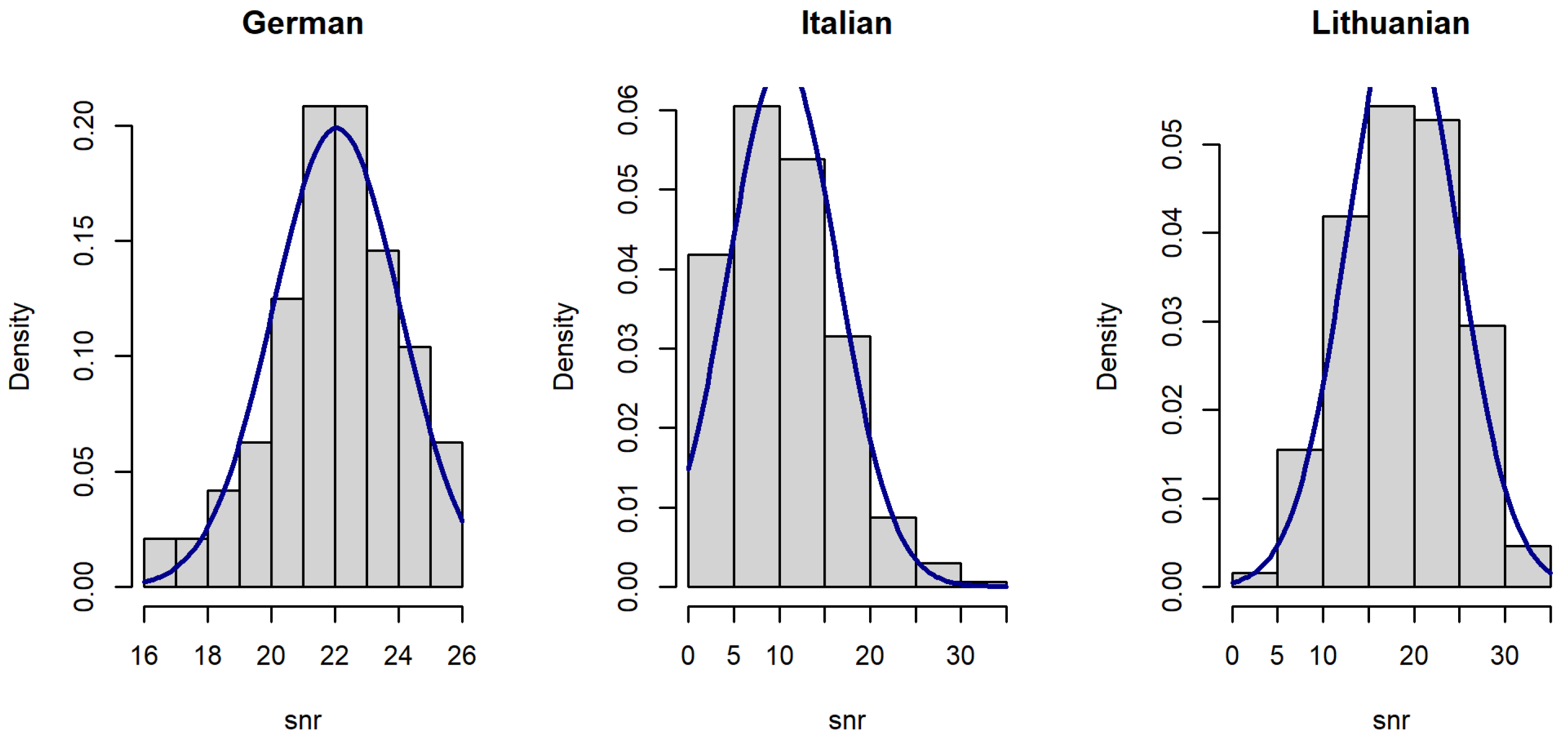
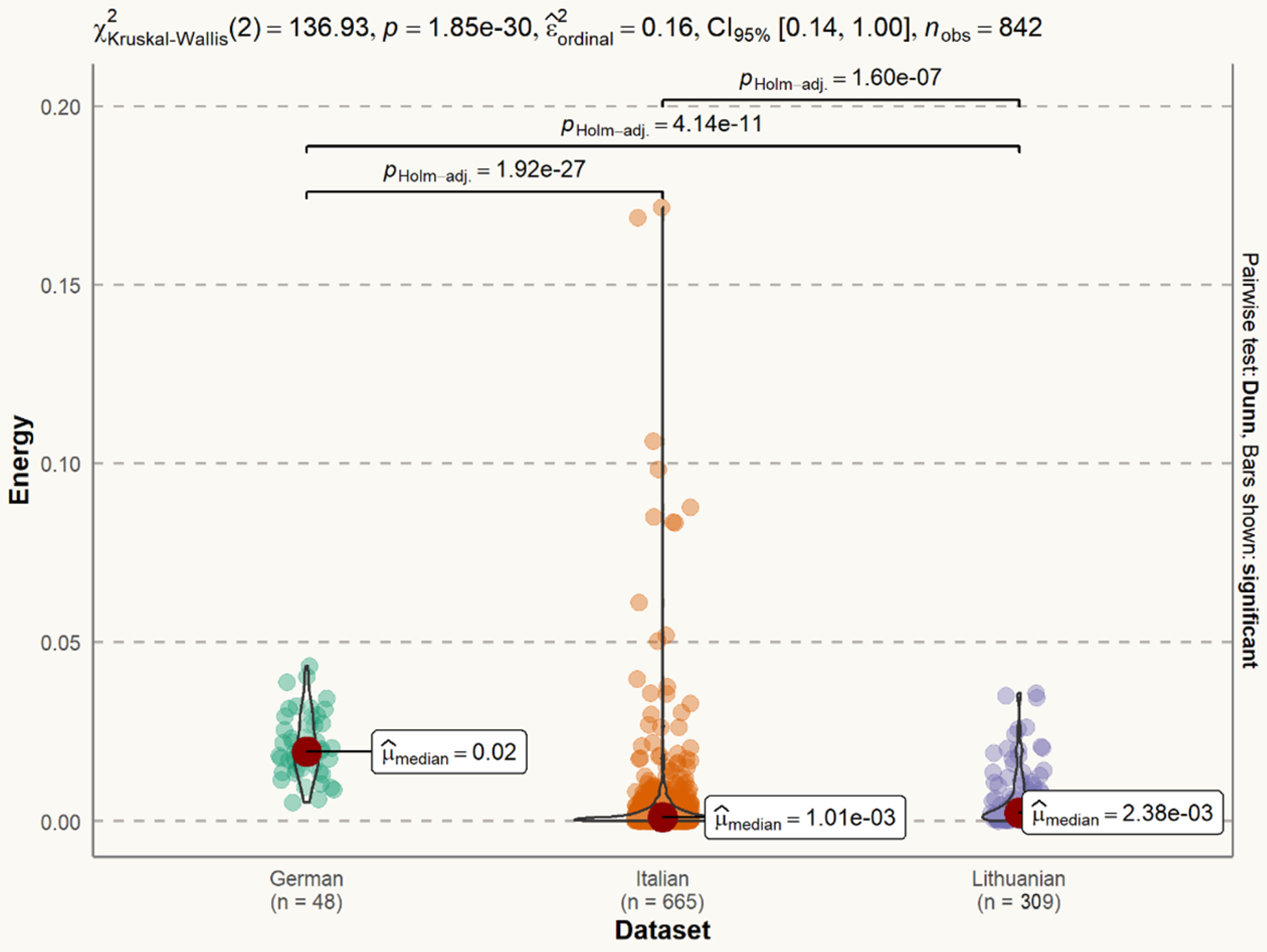
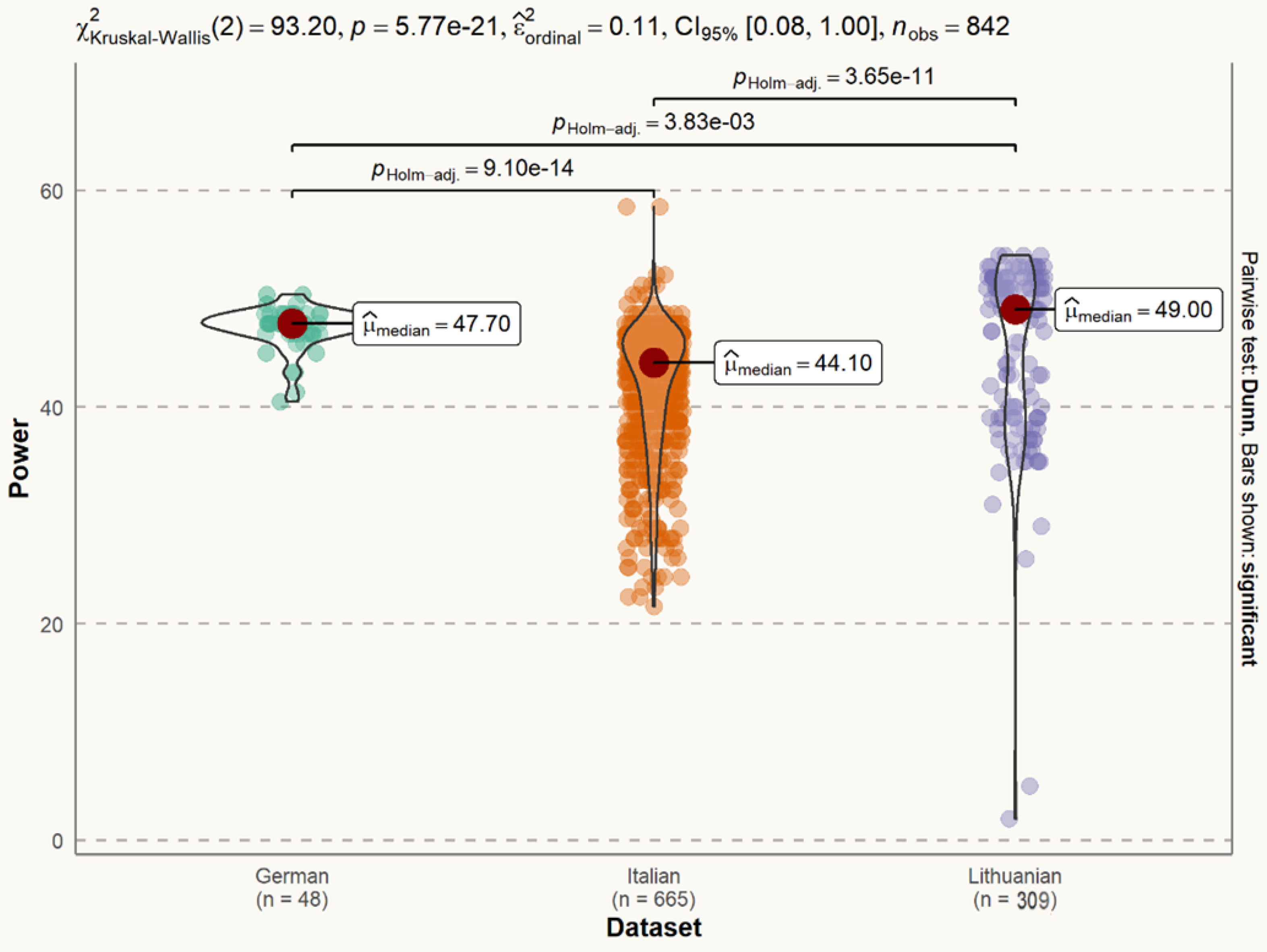
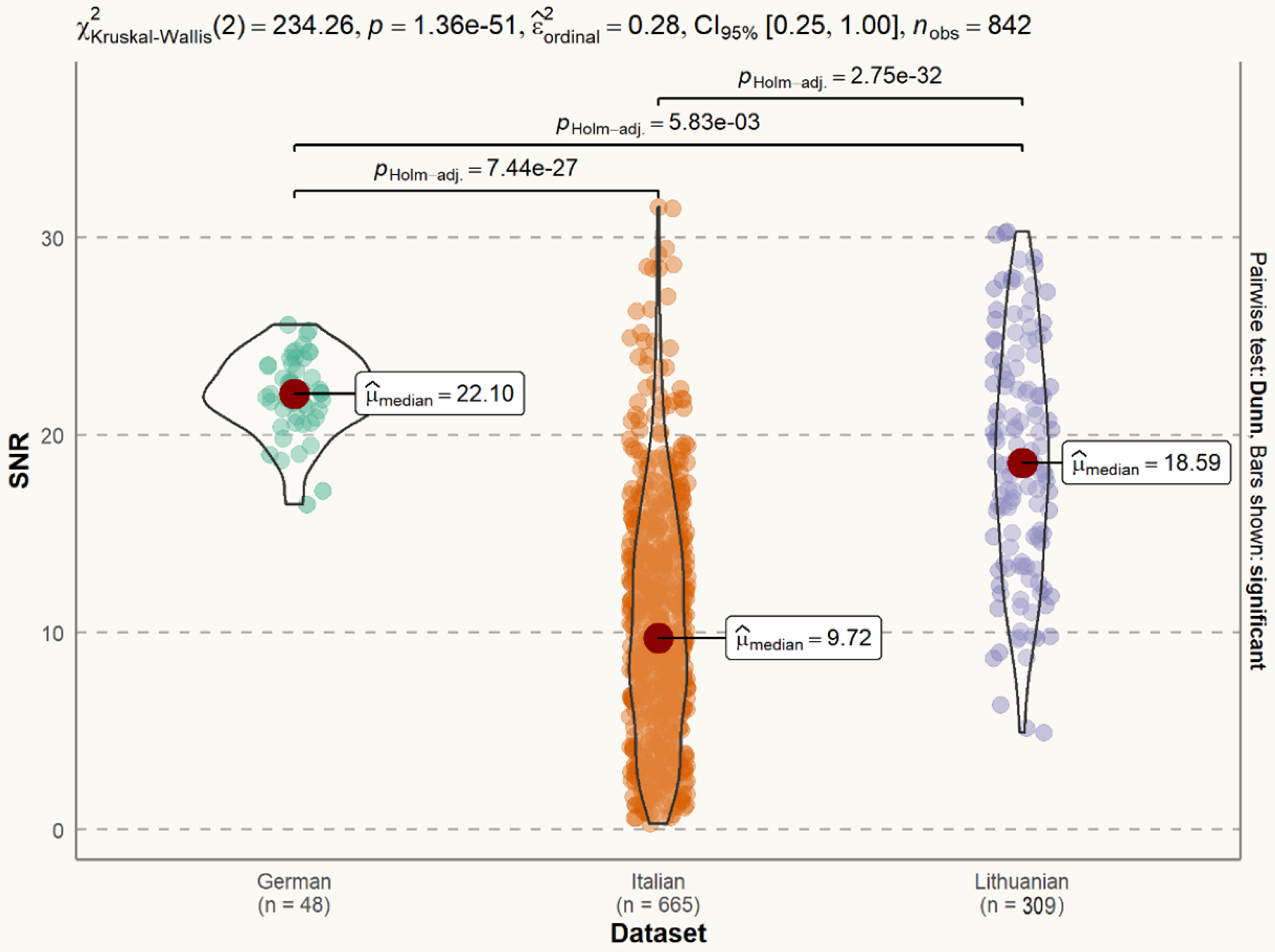
2.4. Exploratory Analysis of the Datasets
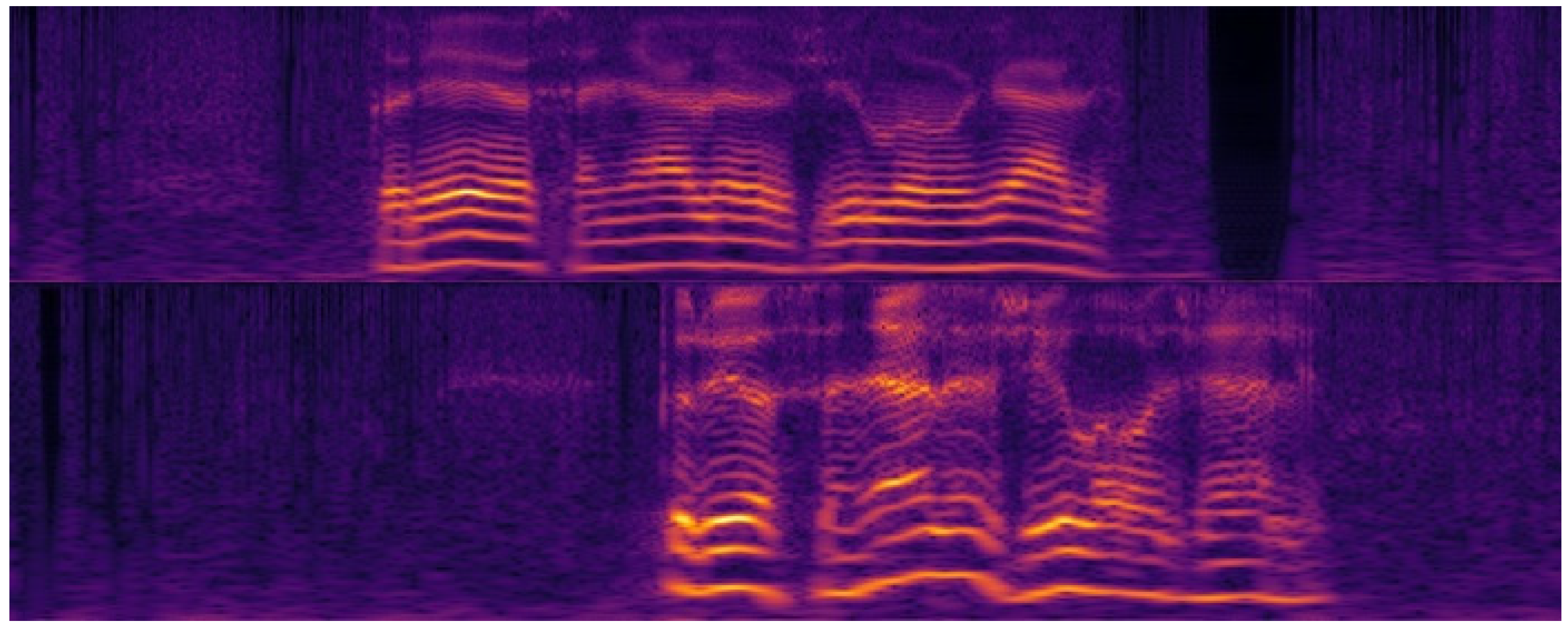
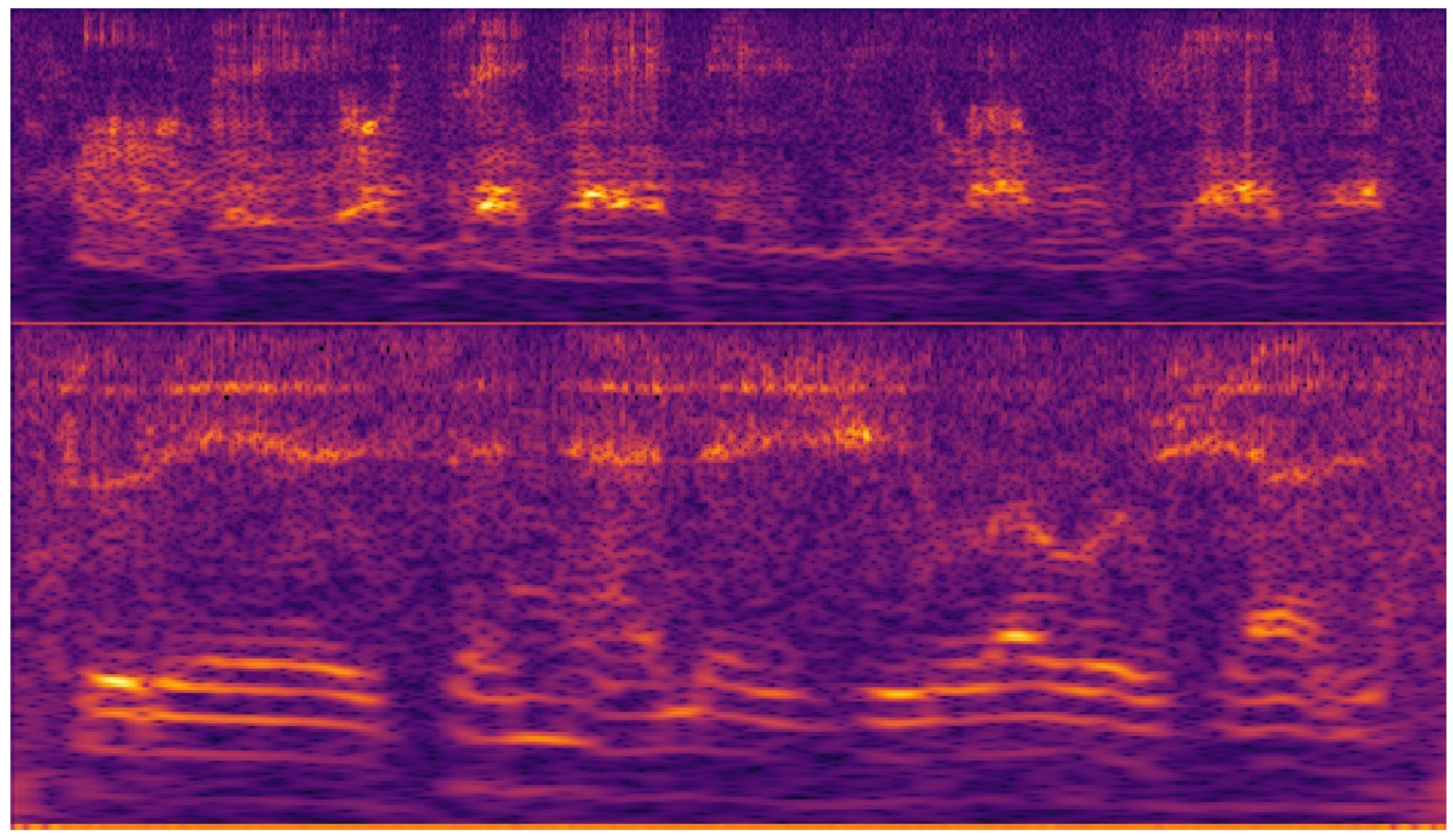
2.5. Cochleagrams of the Speech Signal
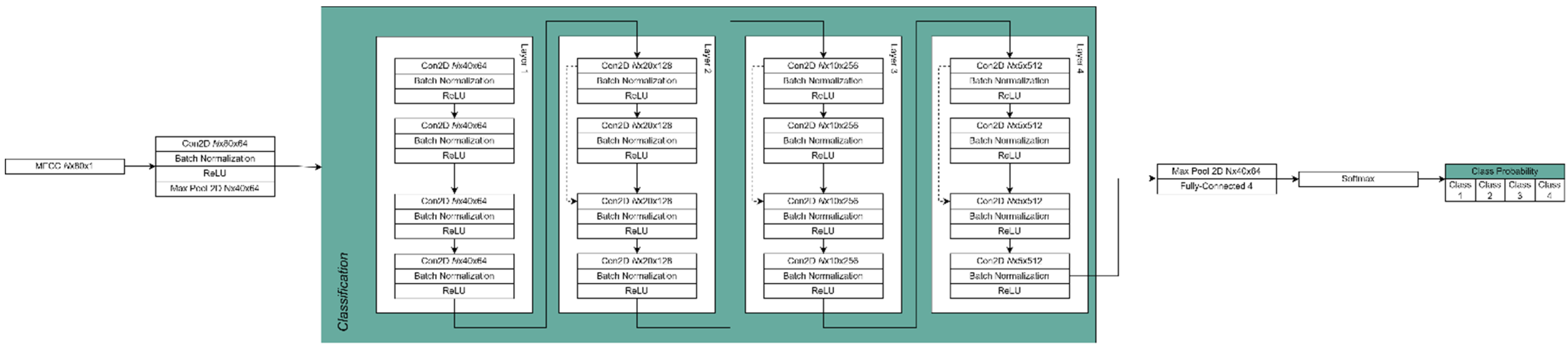
2.6. Network Model
2.7. Fast Response Network
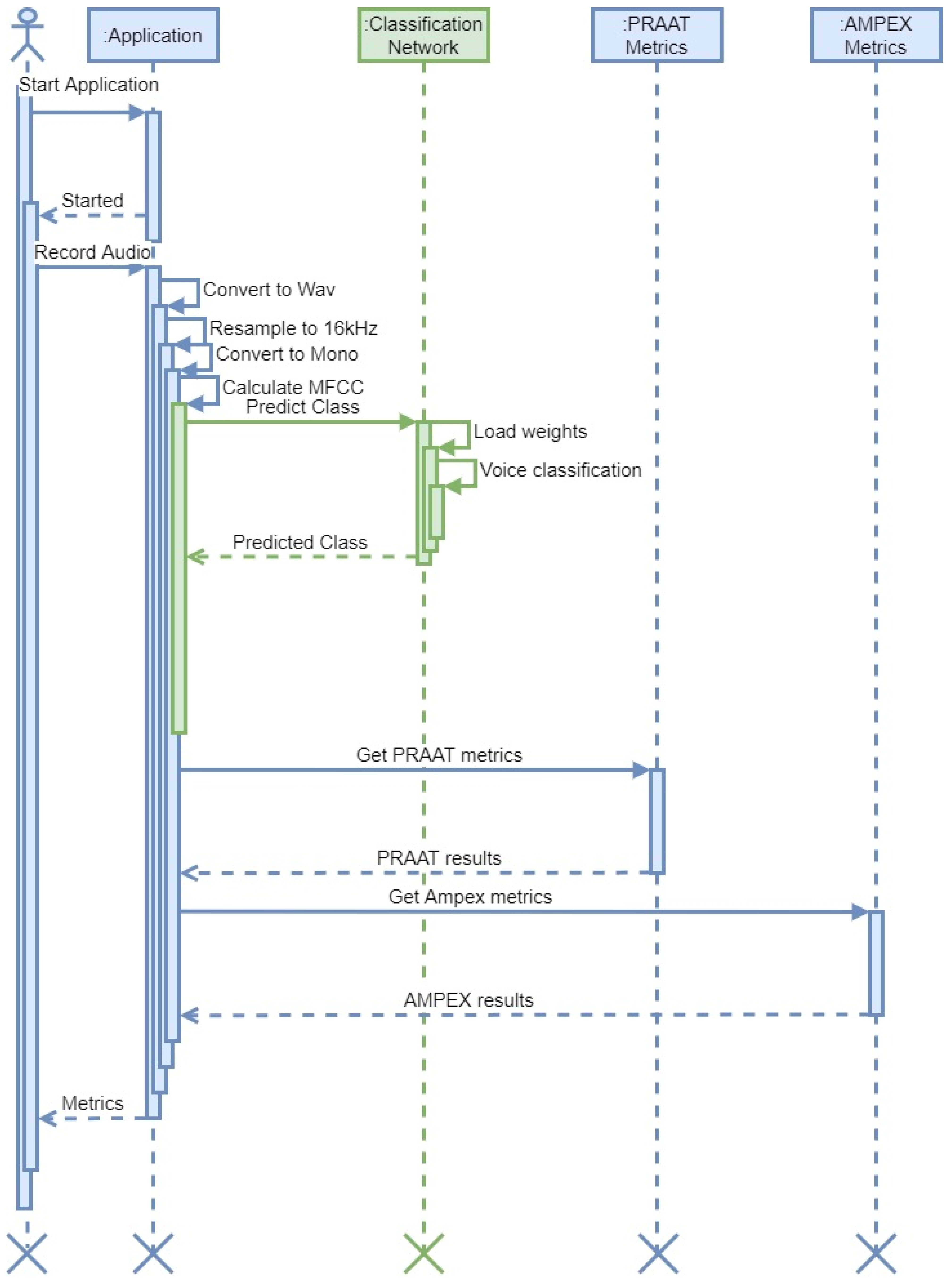
2.8. Network Implementation
3. Results
3.1. Auditory-Perceptual Speech Evaluation Outcomes
3.2. Developing a Combined Model for SV and Speech Assessment in Patients after Laryngeal Oncosurgery
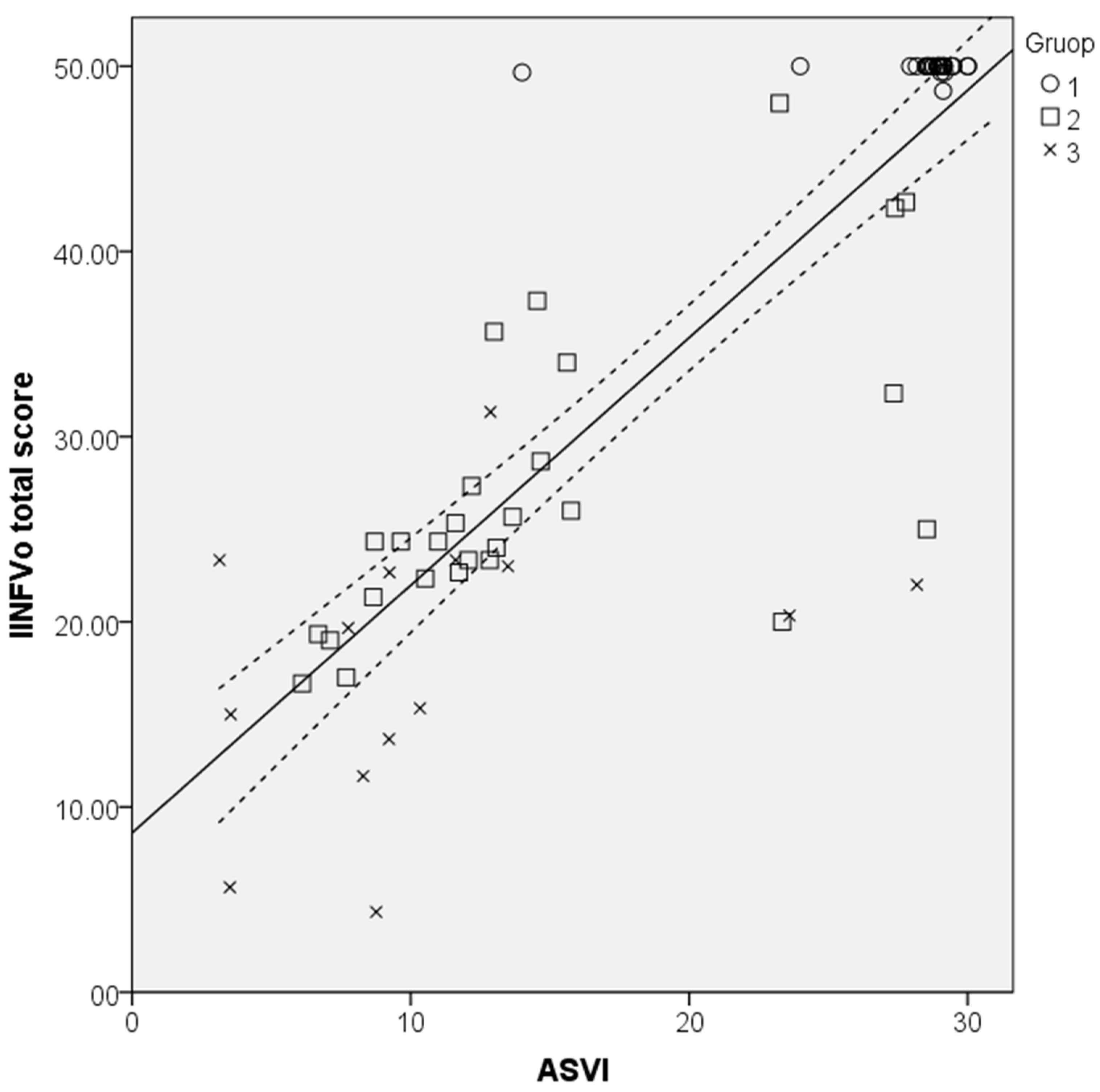
3.3. Testing of the ASVI Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Groome, P.A.; O’Sullivan, B.; Irish, J.C.; Rothwell, D.M.; Schulze, K.; Warde, P.R.; Schneider, K.M.; MacKenzie, R.G.; Hodson, D.I.; Hammond, J.A.; et al. Management and Outcome Differences in Supraglottic Cancer Between Ontario, Canada, and the Surveillance, Epidemiology, and End Results Areas of the United States. J. Clin. Oncol. 2003, 21, 496–505. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer statistics, 2022. CA A Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef] [PubMed]
- Thomas, A.; Manchella, S.; Koo, K.; Tiong, A.; Nastri, A.; Wiesenfeld, D. The impact of delayed diagnosis on the outcomes of oral cancer patients: A retrospective cohort study. Int. J. Oral Maxillofac. Surg. 2021, 50, 585–590. [Google Scholar] [CrossRef] [PubMed]
- Noel, C.W.; Li, Q.; Sutradhar, R.; Eskander, A. Total Laryngectomy Volume During the COVID-19 Pandemic. JAMA Otolaryngol. Neck Surg. 2021, 147, 909. [Google Scholar] [CrossRef] [PubMed]
- Pfister, D.G.; Spencer, S.; Adelstein, D.; Adkins, D.; Anzai, Y.; Brizel, D.M.; Bruce, J.Y.; Busse, P.M.; Caudell, J.J.; Cmelak, A.J.; et al. Head and Neck Cancers, Version 2.2020, NCCN Clinical Practice Guidelines in Oncology. J. Natl. Compr. Cancer Netw. 2020, 18, 873–898. [Google Scholar] [CrossRef]
- Moerman, M.; Martens, J.-P.; Dejonckere, P. Multidimensional assessment of strongly irregular voices such as in substitution voicing and spasmodic dysphonia: A compilation of own research. Logop. Phoniatr. Vocology 2014, 40, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Mattys, S.L.; Davis, M.H.; Bradlow, A.R.; Scott, S.K. Speech recognition in adverse conditions: A review. Lang. Cogn. Process. 2012, 27, 953–978. [Google Scholar] [CrossRef]
- Dejonckere, P.H.; Bradley, P.; Clemente, P.; Cornut, G.; Crevier-Buchman, L.; Friedrich, G.; Van De Heyning, P.; Remacle, M.; Woisard, V. A basic protocol for functional assessment of voice pathology, especially for investigating the efficacy of (phonosurgical) treatments and evaluating new assessment techniques. Eur. Arch. Oto-Rhino-Laryngol. 2001, 258, 77–82. [Google Scholar] [CrossRef]
- Moerman, M.B.J.; Martens, J.P.; Van Der Borgt, M.J.; Peleman, M.; Gillis, M.; Dejonckere, P.H. Perceptual evaluation of substitution voices: Development and evaluation of the (I)INFVo rating scale. European Arch. Oto-Rhino-Laryngol. Head Neck 2005, 263, 183–187. [Google Scholar] [CrossRef]
- Semple, C.; Parahoo, K.; Norman, A.; McCaughan, E.; Humphris, G.; Mills, M. Psychosocial interventions for patients with head and neck cancer. Cochrane Database Syst. Rev. 2013, CD009441. [Google Scholar] [CrossRef] [Green Version]
- Crosetti, E.; Fantini, M.; Arrigoni, G.; Salonia, L.; Lombardo, A.; Atzori, A.; Panetta, V.; Schindler, A.; Bertolin, A.; Rizzotto, G.; et al. Telephonic voice intelligibility after laryngeal cancer treatment: Is therapeutic approach significant? Eur. Arch. Otorhinolaryngol. 2016, 274, 337–346. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.S.; Muhammad, G.; Alamri, A. Smart healthcare monitoring: A voice pathology detection paradigm for smart cities. Multimedia Syst. 2017, 25, 565–575. [Google Scholar] [CrossRef]
- Cummins, N.; Baird, A.; Schuller, B.W. Speech analysis for health: Current state-of-the-art and the increasing impact of deep learning. Methods 2018, 151, 41–54. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-Y. Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System Using the Saarbruecken Voice Database. Appl. Sci. 2021, 11, 7149. [Google Scholar] [CrossRef]
- Chinchu, M.S.; Kirubagari, B. An evaluation of deep learning approaches for detection of voice disorders. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1085, 01201. [Google Scholar] [CrossRef]
- Maskeliūnas, R.; Kulikajevas, A.; Damaševičius, R.; Pribuišis, K.; Ulozaitė-Stanienė, N.; Uloza, V. Lightweight Deep Learning Model for Assessment of Substitution Voicing and Speech after Laryngeal Carcinoma Surgery. Cancers 2022, 14, 2366. [Google Scholar] [CrossRef]
- Barsties, B.; De Bodt, M. Assessment of voice quality: Current state-of-the-art. Auris Nasus Larynx 2015, 42, 183–188. [Google Scholar] [CrossRef]
- Awan, S.N.; Roy, N.; Dromey, C. Estimating dysphonia severity in continuous speech: Application of a multi-parameter spectral/cepstral model. Clin. Linguistics Phon. 2009, 23, 825–841. [Google Scholar] [CrossRef]
- Maryn, Y.; De Bodt, M.; Roy, N. The Acoustic Voice Quality Index: Toward improved treatment outcomes assessment in voice disorders. J. Commun. Disord. 2010, 43, 161–174. [Google Scholar] [CrossRef]
- Latoszek, B.B.V.; Mathmann, P.; Neumann, K. The cepstral spectral index of dysphonia, the acoustic voice quality index and the acoustic breathiness index as novel multiparametric indices for acoustic assessment of voice quality. Curr. Opin. Otolaryngol. Head Neck Surg. 2021, 29, 451–457. [Google Scholar] [CrossRef]
- Jnr, B.A. Implications of telehealth and digital care solutions during COVID-19 pandemic: A qualitative literature review. Informatics Heal. Soc. Care 2020, 46, 68–83. [Google Scholar] [CrossRef]
- Hu, H.-C.; Chang, S.-Y.; Wang, C.-H.; Li, K.-J.; Cho, H.-Y.; Chen, Y.-T.; Lu, C.-J.; Tsai, T.-P.; Lee, O.K.-S. Deep Learning Application for Vocal Fold Disease Prediction Through Voice Recognition: A Preliminary Development Study (Preprint). J. Med. Internet Res. 2020, 23, e25247. [Google Scholar] [CrossRef] [PubMed]
- Raj, J.R.; Jabez, J.; Srinivasulu, S.S.; Gowri, S.; Vimali, J.S. Voice Pathology Detection Based on Deep Neural Network Approach. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1020, 012001. [Google Scholar] [CrossRef]
- Hegde, S.; Shetty, S.; Rai, S.; Dodderi, T. A Survey on Machine Learning Approaches for Automatic Detection of Voice Disorders. J. Voice 2019, 33, 947.e11–947.e33. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Wu, K. Pathological Voice Analysis; Springer: Singapore, 2020. [Google Scholar]
- Chen, L.; Wang, C.; Chen, J.; Xiang, Z.; Hu, X. Voice Disorder Identification by using Hilbert-Huang Transform (HHT) and K Nearest Neighbor (KNN). J. Voice 2020, 35, 932.e1–932.e11. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, C.; Zhu, X.; Tao, Z.; Zhao, H. Class-imbalanced voice pathology classification: Combining hybrid sampling with optimal two-factor random forests. Appl. Acoust. 2022, 190, 108618. [Google Scholar] [CrossRef]
- Al-Dhief, F.T.; Latiff, N.M.A.; Baki, M.M.; Malik, N.N.N.A.; Sabri, N.; Albadr, M.A.A. Voice Pathology Detection Using Support Vector Machine Based on Different Number of Voice Signals. In Proceedings of the 2021 26th IEEE Asia-Pacific Conference on Communications (APCC), Kuala Lumpur, Malaysia, 11–13 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Likhitha, T.; Elizabeth, T.C.; Mary Posonia, A. Discovery and Categorization of Voice Pathology Using Feature Selection Techniques. In Sixth International Conference on Intelligent Computing and Applications. Advances in Intelligent Systems and Computing; Springer: Singapore, 2021; Volume 1369. [Google Scholar] [CrossRef]
- Sharifi, M.; Asadi-Pooya, A.A.; Mousavi-Roknabadi, R.S. Burnout among Healthcare Providers of COVID-19; a Systematic Review of Epidemiology and Recommendations. Arch. Acad. Emerg. Med. 2020, 9, e7. [Google Scholar] [CrossRef]
- Uloza, V.; Padervinskis, E.; Vegiene, A.; Pribuisiene, R.; Saferis, V.; Vaiciukynas, E.; Gelzinis, A.; Verikas, A. Exploring the feasibility of smart phone microphone for measurement of acoustic voice parameters and voice pathology screening. Eur. Arch. Otorhinolaryngol. 2015, 272, 3391–3399. [Google Scholar] [CrossRef]
- Amami, R.; Smiti, A. An incremental method combining density clustering and support vector machines for voice pathology detection. Comput. Electr. Eng. 2017, 57, 257–265. [Google Scholar] [CrossRef]
- Lee, J.Y. A two-stage approach using Gaussian mixture models and higher-order statistics for a classification of normal and pathological voices. EURASIP J. Adv. Signal. Process. 2012, 2012, 252. [Google Scholar] [CrossRef]
- Wu, H.; Soraghan, J.; Lowit, A.; Di Caterina, G. Convolutional Neural Networks for Pathological Voice Detection. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2018, 2018, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Areiza-Laverde, H.J.; Castro-Ospina, A.E.; Peluffo-Ordóñez, D.H. Voice Pathology Detection Using Artificial Neural Networks and Support Vector Machines Powered by a Multicriteria Optimization Algorithm. In Applied Computer Sciences in Engineering; Figueroa-García, J., López-Santana, E., Rodriguez-Molano, J., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 915, pp. 148–159. [Google Scholar] [CrossRef]
- Chen, L.; Chen, J. Deep Neural Network for Automatic Classification of Pathological Voice Signals. J. Voice 2022, 36, 288.e15–288.e24. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.-H.; Tsao, Y.; Hsiao, M.-J.; Chen, J.-Y.; Lai, Y.-H.; Lin, F.-C.; Wang, C.-T. Detection of Pathological Voice Using Cepstrum Vectors: A Deep Learning Approach. J. Voice 2018, 33, 634–641. [Google Scholar] [CrossRef] [PubMed]
- Zakariah, M.; Ajmi Alothaibi, Y.; Guo, Y.; Tran-Trung, K.; Elahi, M.M. An Analytical Study of Speech Pathology Detection Based on MFCC and Deep Neural Networks. Comput. Math. Methods Med. 2022, 2022, 1–15. [Google Scholar] [CrossRef]
- Miliaresi, I.; Poutos, K.; Pikrakis, A. Combining acoustic features and medical data in deep learning networks for voice pathology classification. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–22 January 2021; pp. 1190–1194. [Google Scholar] [CrossRef]
- Syed, S.A.; Rashid, M.; Hussain, S.; Zahid, H. Comparative Analysis of CNN and RNN for Voice Pathology Detection. BioMed Res. Int. 2021, 2021, 1–8. [Google Scholar] [CrossRef]
- Kim, H.; Jeon, J.; Han, Y.J.; Joo, Y.; Lee, J.; Lee, S.; Im, S. Convolutional Neural Network Classifies Pathological Voice Change in Laryngeal Cancer with High Accuracy. J. Clin. Med. 2020, 9, 3415. [Google Scholar] [CrossRef] [PubMed]
- Ankışhan, H.; Inam, S. Voice pathology detection by using the deep network architecture. Appl. Soft Comput. 2021, 106, 107310. [Google Scholar] [CrossRef]
- Mittal, V.; Sharma, R.K. Deep Learning Approach for Voice Pathology Detection and Classification. Int. J. Heal. Inf. Syst. Informatics 2021, 16, 1–30. [Google Scholar] [CrossRef]
- Chaiani, M.; Selouani, S.A.; Boudraa, M.; Yakoub, M.S. Voice disorder classification using speech enhancement and deep learning models. Biocybern. Biomed. Eng. 2022, 42, 463–480. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Y.; Zhou, C.; Zhang, X.; Tao, Z. Class-Imbalanced Voice Pathology Detection and Classification Using Fuzzy Cluster Oversampling Method. Appl. Sci. 2021, 11, 3450. [Google Scholar] [CrossRef]
- Wahengbam, K.; Singh, M.P.; Nongmeikapam, K.; Singh, A.D. A Group Decision Optimization Analogy-Based Deep Learning Architecture for Multiclass Pathology Classification in a Voice Signal. IEEE Sens. J. 2021, 21, 8100–8116. [Google Scholar] [CrossRef]
- Muhammad, G.; Alhussein, M. Convergence of Artificial Intelligence and Internet of Things in Smart Healthcare: A Case Study of Voice Pathology Detection. IEEE Access 2021, 9, 89198–89209. [Google Scholar] [CrossRef]
- Omeroglu, A.N.; Mohammed, H.M.; Oral, E.A. Multi-modal voice pathology detection architecture based on deep and handcrafted feature fusion. Eng. Sci. Technol. Int. J. 2022, 36, 101148. [Google Scholar] [CrossRef]
- Abdulmajeed, N.Q.; Al-Khateeb, B.; Mohammed, M.A. A review on voice pathology: Taxonomy, diagnosis, medical procedures and detection techniques, open challenges, limitations, and recommendations for future directions. J. Intell. Syst. 2022, 31, 855–875. [Google Scholar] [CrossRef]
- Remacle, M.; Eckel, H.E.; Antonelli, A.; Brasnu, D.; Chevalier, D.; Friedrich, G.; Olofsson, J.; Rudert, H.H.; Thumfart, W.; De Vincentiis, M.; et al. Endoscopic cordectomy. A proposal for a classification by the Working Committee, European Laryngological Society. Eur. Arch. Otorhinolaryngol. 2000, 257, 227–231. [Google Scholar] [CrossRef]
- Succo, G.; Peretti, G.; Piazza, C.; Remacle, M.; Eckel, H.E.; Chevalier, D.; Simo, R.; Hantzakos, A.G.; Rizzotto, G.; Lucioni, M.; et al. Open partial horizontal laryngectomies: A proposal for classification by the working committee on nomenclature of the European Laryngological Society. Eur. Arch. Otorhinolaryngol. 2014, 271, 2489–2496. [Google Scholar] [CrossRef]
- Boersma, P.; Weenink, D. PRAAT, a system for doing phonetics by computer. Glot Int. 2001, 5, 341–345. [Google Scholar]
- Barry, B. Saarbruecken Voice Database; Institute of Phonetics, Saarland University: Saarbrücken, Germany, 2022; Available online: http://stimmdb.coli.uni-saarland.de/ (accessed on 9 September 2022).
- Dimauro, G.; Girardi, F. Italian Parkinson’s Voice and Speech. Available online: https://ieee-dataport.org/open-access/italian-parkinsons-voice-and-speech (accessed on 16 August 2022).
- Sharan, R.V.; Moir, T.J. Cochleagram image feature for improved robustness in sound recognition. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing, South Brisbane, Australia, 21–24 July 2015; pp. 441–444. [Google Scholar] [CrossRef]
- Arias-Vergara, T.; Klumpp, P.; Vasquez-Correa, J.C.; Nöth, E.; Orozco-Arroyave, J.R.; Schuster, M. Multi-channel spectrograms for speech processing applications using deep learning methods. Pattern Anal. Appl. 2020, 24, 423–431. [Google Scholar] [CrossRef]
- Das, S.; Pal, S.; Mitra, M. Supervised model for Cochleagram feature based fundamental heart sound identification. Biomed. Signal Process. Control 2019, 52, 32–40. [Google Scholar] [CrossRef]
- Ingale, P.P.; Nalbalwar, S.L. Deep neural network based speech enhancement using mono channel mask. Int. J. Speech Technol. 2019, 22, 841–850. [Google Scholar] [CrossRef]
- Jiang, J.; Li, Y. Review of active noise control techniques with emphasis on sound quality enhancement. Appl. Acoust. 2018, 136, 139–148. [Google Scholar] [CrossRef]
- Avila, A.R.; Gamper, H.; Reddy, C.; Cutler, R.; Tashev, I.; Gehrke, J. Non-intrusive Speech Quality Assessment Using Neural Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 631–635. [Google Scholar] [CrossRef]
- Gamper, H.; Reddy, C.K.A.; Cutler, R.; Tashev, I.J.; Gehrke, J. Intrusive and Non-Intrusive Perceptual Speech Quality Assessment Using a Convolutional Neural Network. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 85–89. [Google Scholar] [CrossRef]
- Latoszek, B.B.V.; Maryn, Y.; Gerrits, E.; De Bodt, M. A Meta-Analysis: Acoustic Measurement of Roughness and Breathiness. J. Speech Lang. Hear. Res. 2018, 61, 298–323. [Google Scholar] [CrossRef] [PubMed]
- Zoughi, T.; Homayounpour, M.M.; Deypir, M. Adaptive windows multiple deep residual networks for speech recognition. Expert Syst. Appl. 2019, 139, 112840. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nair, V.; Hinton, E.G. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Nakashika, T.; Takaki, S.; Yamagishi, J. Complex-Valued Restricted Boltzmann Machine for Speaker-Dependent Speech Parameterization from Complex Spectra. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 244–254. [Google Scholar] [CrossRef]
- Van Immerseel, L.M.; Martens, J. Pitch and voiced/unvoiced determination with an auditory model. J. Acoust. Soc. Am. 1992, 91, 3511–3526. [Google Scholar] [CrossRef]
- Entezami, P.; Bs, B.T.; Mansour, J.; Asarkar, A.; Nathan, C.; Pang, J. Targets for improving disparate head and neck cancer outcomes in the low-income population. Laryngoscope 2021, 6, 1481–1488. [Google Scholar] [CrossRef]
- Vanagas, G.; Engelbrecht, R.; Damaševičius, R.; Suomi, R.; Solanas, A. eHealth Solutions for the Integrated Healthcare. J. Health Eng. 2018, 2018, 3846892. [Google Scholar] [CrossRef]
- Payten, C.L.; Nguyen, D.D.; Novakovic, D.; O’Neill, J.; Chacon, A.M.; Weir, K.A.; Madill, C.J. Telehealth voice assessment by speech language pathologists during a global pandemic using principles of a primary contact model: An observational cohort study protocol. BMJ Open 2022, 12, e052518. [Google Scholar] [CrossRef]
- Abia-Trujillo, D.; Tatari, M.M.; Venegas-Borsellino, C.P.; Hoffman, R.J.; Fox, H.T.; Fernandez-Bussy, I.; Guru, P.K. Misplaced tracheoesophageal voice prosthesis: A case of foreign body aspiration. Am. J. Emerg. Med. 2020, 41, 266.e1–266.e2. [Google Scholar] [CrossRef]
- Al-Dhief, F.T.; Latiff, N.M.A.; Malik, N.N.N.A.; Salim, N.S.; Baki, M.M.; Albadr, M.A.A.; Mohammed, M.A. A Survey of Voice Pathology Surveillance Systems Based on Internet of Things and Machine Learning Algorithms. IEEE Access 2020, 8, 64514–64533. [Google Scholar] [CrossRef]
- van Sluis, K.E.; van der Molen, L.; van Son, R.J.J.H.; Hilgers, F.J.M.; Bhairosing, P.A.; Brekel, M.W.M.V.D. Objective and subjective voice outcomes after total laryngectomy: A systematic review. Eur. Arch. Otorhinolaryngol. 2018, 275, 11–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Teaching | Testing | Total |
|---|---|---|---|
| Control (class 0) | 250 | 29 | 279 |
| Cordectomy and partial laryngectomy (class 1) | 41 | 29 | 70 |
| Total laryngectomy (class 2) | 18 | 12 | 30 |
| Feature | Description |
|---|---|
| F0 | Fundamental frequency |
| PVF | Percentage of voiced frames |
| PVS | Percentage of voiced speech frames |
| AVE | Mean voicing evidence of voiced frames (proportion) |
| PVFU | Percentage of voiced frames with unreliable F0 |
| MD | Average F0 modulation |
| MDc | MD only in frames with a “reliable” F0 estimate. Vocal frequency estimate F0 is considered reliable if it deviates less than 25% from the average over all voiced frames. |
| Jitter | F0-jitter in all voiced frame pairs (=2 consecutive frames) |
| Group | Teaching Group IINFVo Total Score (SD) | Testing Group IINFVo Total Score (SD) | p |
|---|---|---|---|
| Control (class 0) | 48.01 (2.88) | 49.02 (2.62) | 0.0724 |
| Cordectomy and partial laryngectomy (class 1) | 22.52 (9.98) | 26.62 (8.09) | 0.0721 |
| Total laryngectomy (class 2) | 16.92 (10.71) | 17.95 (7.44) | 0.7746 |
| Group | n | ASVI (SD) | p |
|---|---|---|---|
| Control (class 0) | 29 | 28.28 (2.93) | 0.001 |
| Cordectomy and partial laryngectomy (class 1) | 29 | 15.39 (7.31) | 0.001 |
| Total laryngectomy (class 2) | 12 | 8.48 (3.53) | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uloza, V.; Maskeliunas, R.; Pribuisis, K.; Vaitkus, S.; Kulikajevas, A.; Damasevicius, R. An Artificial Intelligence-Based Algorithm for the Assessment of Substitution Voicing. Appl. Sci. 2022, 12, 9748. https://doi.org/10.3390/app12199748
Uloza V, Maskeliunas R, Pribuisis K, Vaitkus S, Kulikajevas A, Damasevicius R. An Artificial Intelligence-Based Algorithm for the Assessment of Substitution Voicing. Applied Sciences. 2022; 12(19):9748. https://doi.org/10.3390/app12199748
Chicago/Turabian StyleUloza, Virgilijus, Rytis Maskeliunas, Kipras Pribuisis, Saulius Vaitkus, Audrius Kulikajevas, and Robertas Damasevicius. 2022. "An Artificial Intelligence-Based Algorithm for the Assessment of Substitution Voicing" Applied Sciences 12, no. 19: 9748. https://doi.org/10.3390/app12199748
APA StyleUloza, V., Maskeliunas, R., Pribuisis, K., Vaitkus, S., Kulikajevas, A., & Damasevicius, R. (2022). An Artificial Intelligence-Based Algorithm for the Assessment of Substitution Voicing. Applied Sciences, 12(19), 9748. https://doi.org/10.3390/app12199748