1. Introduction
Text classification refers to classifying text content according to certain rules or models [
1]. As a basic task of natural language processing (NLP), it is widely used in applications such as emotion recognition, spam classification, news text classification, etc. At present, long text, especially document-level text data, shows an explosive growth trend. Long text classification has become a hot topic in text classification due to its rich information and long text length.
The traditional text classification algorithms mainly use
n-gram [
2], TF-IDF [
3] to extract text features and then input the text features into the machine learning models for training. For example, Shahi et al. made use of hybrid features (FastText+TF-IDF) to represent Nepali COVID-19-related tweets for the sentiment classification [
4]. The evaluation results on the NepCOV19Tweets demonstrated that their method achieved excellent performance. However, these methods rely heavily on manual feature engineering and ignore the contextual relationship and location information between words, which severely limits the model performance. With the rapid development of deep learning, neural network models such as convolutional neural network (CNN) [
5], recurrent neural network (RNN) [
6], and long short-term memory (LSTM) [
7] are widely applied in the field of text classification. The rise of pretrained language models represented by bidirectional encoder representation from transformers (BERT) [
8] indicates that the transformer [
9] architecture can be fully applied to the field of text classification, enabling text context information to participate in the expression of word vectors in a more comprehensive and reasonable way. However, due to the limitation of the input data length, the pretrained language models perform poorly in the field of long text classification. Therefore, how to effectively reduce the text length while minimizing the loss of semantic information is the key to improving the performance of pretrained language models in the field of long text classification.
Long text data preprocessing methods can be classified into four categories: truncation method [
10], pooling method [
11], compression method [
12,
13] and transformer model improvement [
14]. However, these methods generally have problems such as information loss, resource waste and insufficient precision. In long texts, there are often many redundant sentence segments that are not very relevant to the topic, which is usually considered as data noise. On the one hand, this noise information interferes with model learning; on the other hand, these redundant sentence segments occupy input positions that do not belong to them. Due to the length limitation, the BERT model must abandon other more important sentence segments, which results in poor performance of the BERT model in long text classification scenarios. Therefore, it is an important method to use label embedding to filter sentence segments irrelevant to the topic in long text, and how to better learn to obtain the label embedding is also a key step.
Label embedding represents the vector representation of label words obtained by model learning. At present, the mainstream label word learning methods include label-word joint embedding methods [
15], multi-task label-embedding methods [
16], interactive mechanism-based methods [
17], and some improvements have also been made on the basis of these methods.
However, there are two main problems with these methods. The first problem is that these methods do not learn the textual information of domain-specific data, because they are all methods derived from the idea of word embedding. Word embedding refers to embedding a high-dimensional sparse word space into a low-dimensional dense word vector space. The training corpus of word embedding is mainly from general domain data, such as Wikipedia, Gigaword Dataset, etc. [
18]. In the process of obtaining word vectors based on word embeddings, these methods are not further trained for specific domain data, so they cannot learn the unique text information in specific domain data. The second problem is that these methods do not alleviate the problem of “polysemy”. For example, the word “apple” might represent both a fruit and a brand name. If the word “apple” is directly embedded without a prompt template, the obtained word vector is not accurate enough. However, if a prompt template is added in front of the word that needs to be represented, for example, a prompt template of “the brand of this electronic product is” is added in front of “apple”, then the word mapping of “apple” we obtain is obviously related to electronic products. By introducing a prompt template, the problem of “polysemy” will be subtly alleviated.
For problem one, Howard and Ruder proposed a general paradigm ULMFiT [
19]. The ULMFiT paradigm mainly divided model training into three stages. The first stage trained the language model on a large number of general corpora, the second stage continued to train the language model on the specific domain data, and the third stage carried out specific tasks on the specific domain data. After the first stage, we can obtain a pretrained model, which made the convergence of the second stage much faster. In the second stage, domain-specific data were used as the pretraining object, so the model can quickly adapt to the characteristics of the target data, so as to fully learn the context information of the specific domain data. For problem two, Schick and Schütze proposed a semi-supervised model: pattern-exploiting training (PET) [
20]. By introducing a prompt template, PET reformulated the model input into cloze-style phrases, which can help the language model understand the given task. At the same time, PET added a prompt template before the user input, which was equivalent to limiting the semantic range corresponding to the user input in a prompt manner. This method enabled word embeddings to accurately represent the user input, thus effectively alleviating the problem of polysemy.
Inspired by this, we propose the LTTA-LE algorithm. First, two prefix templates are constructed to prompt user input, which effectively limits the semantic range corresponding to user input. Then, an adaptive filtering threshold equation is designed, which dynamically determines the filtering amount of each long text. Next, the similarity between the label embedding and each segment in the long text is calculated, effectively filtering out invalid information in the long text. Finally, a three-stage model training architecture is introduced, which significantly improves the classification performance and generalization ability of the model. The main contributions of this paper are as follows.
- 1.
Unique prefix template design, which can alleviate the problem of polysemy. This paper constructs a pretraining prefix template and a label word mapping prefix template. By constructing the pretraining prefix template, the joint training of label words and long texts is realized. During the pretraining process, the long text and the label words are fully interacted to avoid the gap between them. With the help of the label word mapping prefix template, the label word embedding can more accurately describe the real semantics expressed by the user input, which effectively alleviates the problem of polysemy.
- 2.
More efficient long text noise filtering scheme. Considering that there are a large number of redundant sentence segments irrelevant to the topic in long texts, we can filter invalid information in long texts by calculating the similarity between the label embedding and each sentence segment in long texts. On the one hand, it can meet the limitation of the BERT model on the length of the input corpus. On the other hand, it can effectively filter the noise and improve the classification performance of the model.
- 3.
Adaptive filtering threshold equation. By designing an adaptive filtering threshold equation, the filtering quantity of each long text is dynamically determined, which avoids the problem of incomplete information filtering caused by too long text or serious information loss caused by too short text after filtering.
- 4.
A general and efficient three-stage model training scheme. This paper introduces a three-stage model training scheme, which mainly includes: in-domain pretraining, finetuning, and prediction. Among them, the in-domain pretraining stage can help the model learn the characteristics of specific domain data in advance and improve the model’s ability to represent sentences. The finetuning stage enables the model to be quickly applied to downstream tasks and improves the generalization ability of the model. In the prediction stage, the pseudo-label method is used to predict the test set, and the test set is filtered based on the obtained pseudo-label, which can avoid the interference of the model by the noise data in the test set. Through this three-stage model training scheme, the classification performance and generalization ability of the model can be significantly improved.
In the experimental phase, we verify and compare the algorithm performance on three public datasets. In terms of overall algorithm performance, our proposed LTTA-LE algorithm surpasses other long text processing methods.
In addition, we also design an experimental scheme to conduct an in-depth analysis of the main modules of the algorithm. We compare the performance of the algorithm on the Arxiv Dataset under different max_len, where max_len refers to the maximum text length of the model input. It is found that for most max_len, our algorithm achieves the best performance due to its superior filtering effect on long text, which means that we can reduce max_len as much as possible to save memory on the premise of fixed precision requirements. Meanwhile, we compare the impact of four label-embedding schemes on the final performance of the algorithm. The LTTA-LE algorithm uses the prefix template to jointly train the long text and the label word, and it fully learns the interaction information between them. Therefore, the LTTA-LE algorithm achieves the best result.
3. Method
As an improved compression method for the long text classification algorithm, the basic idea of the LTTA-LE algorithm is to first learn the similarity measure of each sentence segment and the label word after cutting the long text and then filter out the sentence segments with low similarity and recombine the remaining sentence segments into a new short text. Finally, the obtained new short text and original labels are input into the model for training. Through these steps, the purpose of compressing long text into the BERT model is achieved while minimizing the semantic loss.
Figure 1 shows the whole framework. As can be seen from
Figure 1, our proposed LTTA-LE can be summarized into three parts. The details are as follows.
The first part is the text encoding layer, which includes two sub-modules: the vectorized representation of long text and the vectorized representation of label words. To fully learn the contextual semantic information of the label words, the pretrained corpus data are reconstructed by constructing the prefix template, and the label word vector is retrained and extracted based on the mask language model (MLM).
The second part is the long text filtering module. This module first calculates the cosine similarity between each sentence segment of the long text and the label word; then, it filters and retains the most similar top-k sentence segments and finally recombines the top-k sentence segments to form a new shorter text. With the help of this module, the purpose of compressing the long text is realized.
The third part is the model training strategy module, which inputs the compressed text data together with the text classification labels into the model for training and prediction. This module consists of three parts: in-domain pretraining, finetuning and prediction. By learning the semantic information of a specific dataset, the gap between upstream and downstream tasks is eliminated.
3.1. Label Embedding
Label word representation methods mainly include one-hot embedding representation, static word vector representation (such as word2vec [
26]), and word vector extraction based on the pretrained BERT model. In comparison, one-hot embedding and static word vectors find it difficult to capture contextual information, while the word vector extraction method based on pretraining model finds it difficult to capture the interaction information between long text and label words. In order to better obtain the vector representation of label words and alleviate the problem of polysemy, the method of constructing a prefix template is improved on the basis of the BERT model.
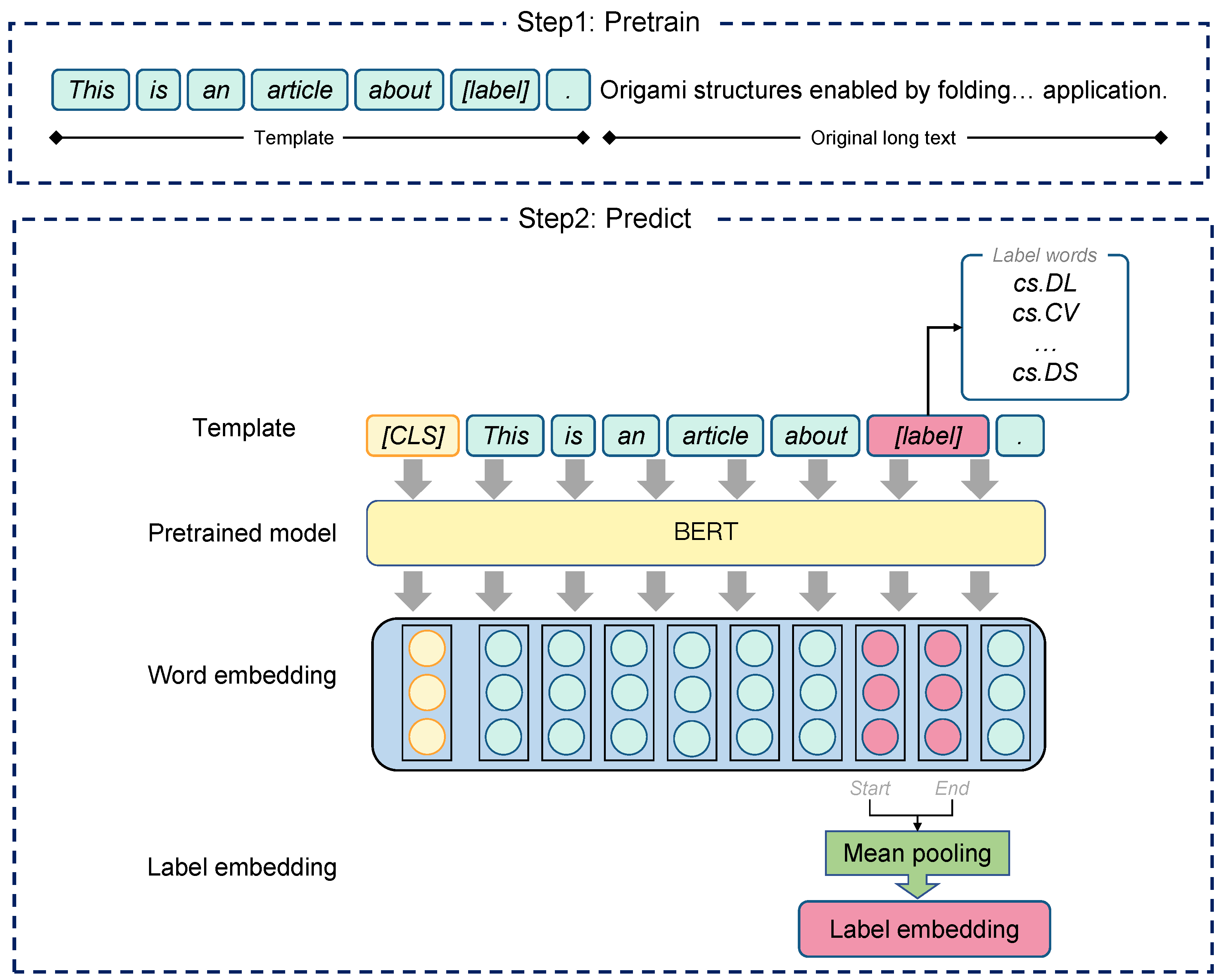
Figure 2 shows the whole framework of label embedding.
As can be seen from
Figure 2, this framework consists of two steps.
Step 1: Label word pretraining based on prefix template constructing
Firstly, we construct training sample pairs which shows as:
where
is the long text, and
is the corresponding label.
Secondly, for each sample pair , define the pretraining prefix template as:
Thirdly, fill the training sample pair data into the prefix template to obtain the new text data , which contains the original long text and label words.
Finally, the new text data
are input into the BERT model for in-domain pretraining to fully learn the interaction information between long text and label words. Through in-domain pretraining, we obtain a pretrained model
H, and the steps of in-domain pretraining will be described in detail in
Section 3.3.1.
Step 2: Label word representation
In order to obtain the vector representation of each label word, the forward propagation method is used to predict the label word vector based on the BERT model trained in the previous step.
Firstly, construct a new label word mapping prefix template as below:
In this step, by constructing a label word mapping prefix template, richer context information is introduced into the label word, and the semantic range corresponding to the label word is limited, so that the problem of polysemy can be alleviated.
Secondly, as shown in
Figure 2, the prefix template containing the label word is input into the pretrained model
H. Then, we can obtain the embedding of each word in the prefix template.
Finally, due to the unpredictability of the text category during word segmentation, a label word may occupy multiple characters, so we simultaneously record the start and end positions of the label word: and . For all vectors in the range of and , mean pooling is conducted to obtain the embedding of each label word.
In addition, in order to make the reader understand this process more clearly, we summarize the process of label embedding in Algorithm 1.
| Algorithm 1 Label-embedding algorithm. |
- Input:
The traning sample pairs ; The pretraining prefix template and the label word mapping prefix template . - Output:
Label word vector . - 1:
Fill the sample pair consisting of and into the to obtain new text data . - 2:
Input into the BERT model for in-domain pretraining, and obtain the pretrained model H. - 3:
Fill into to obtain label prompt data, and record the start position and end position of the label word. - 4:
Input the label prompt data in step 3 into H to obtain the corresponding embedding vector. - 5:
For all vectors in the range of and in step 4, perform mean pooling to obtain the label embedding .
|
3.2. Long Text Filtering Based on Similarity Calculation
Since there are a large number of expressions unrelated to label words in long texts, we propose a long text filtering scheme based on text and label similarity calculation to filter more valuable texts in long texts, so as to shorten the text length and improve the long text classification performance. The encoding of the label word has been introduced in the previous section, and the label word vector is defined as .
3.2.1. Similarity Calculation between Sentence Vector and Label Word Vector
In the encoding stage of the long text, considering that the length of the long text far exceeds the length limit of the model, our method adopts the form of sentence vectors for representation, as shown in
Figure 1. Firstly, sentence
is obtained by truncating the long text according to the text truncation dictionary Text_SD (Text_SD = [‘,’, ‘:’, ‘;’, ‘.’, ‘?’, ‘!’, ‘\t’, ‘\n’]). Secondly, in order to ensure the model performance and objectivity of the sentence vector, this scheme uses the pipeline function [
27] in the Hunging Face open source transformer package to characterize the sentence segment
to obtain the sentence vector
. Finally, based on the obtained sentence vector
and label word vector
, the similarity between the two is calculated to filter sentences with more relevant label information. A cosine similarity equation is adopted for similarity calculation, which is expressed as:
where
represents the
k-th dimension value in the
vector,
represents the
k-th dimension value in the
vector,
d represents the BERT model output vector dimension, and
d = 768 is set in this paper.
3.2.2. Sentence Vector Filtering and Text Reorganization
According to the value of cosine similarity, sort all sentence vectors from large to small, and select the top-
k most similar sentence vectors. Then, the corresponding index is obtained according to the selected sentence vectors. Next, keep the corresponding sentence segments based on these indexes, and finally recombine these sentence segments into a new short text. When choosing the value of
k, we comprehensively consider the number of sentences in the long text, the number of words and the maximum text length in the input model for modeling. We specify the maximum text length of the input model as max_len, the number of tokens in the long text as len(tokens), and the number of sentences as len(sentences). By calculating the ratio of the maximum text length to the number of tokens in the long text, the
k value of each long text data is obtained. The adaptive filtering threshold equation is:
According to the equation, the value of
k corresponding to each long text data is calculated, the sorted sentence vectors are extracted, and the top-
k sentence segments with the highest correlation with the label words are selected. Finally, the sentence segments are reorganized according to the original order of the sentences, so as to shorten the length of the long text while preserving the original contextual semantics of the original long text. In general, Algorithm 2 shows the detailed steps of the LTTA-LE algorithm.
| Algorithm 2 LTTA-LE algorithm. |
- Input:
The traning sample pairs ; Text segmentation dictionary Text_SD = [‘,’, ‘:’, ‘;’, ‘.’, ‘?’, ‘!’, ‘\t’, ‘\n’]. - Output:
New shorter text. - 1:
According to Text_SD, truncate to obtain the truncated set . - 2:
Use the pipeline function [ 27] to encode to obtain the sentence vector . - 3:
Utilize label-embedding algorithm to embed the label to obtain label word vector . - 4:
Based on Equation ( 1), calculate the similarity between and . - 5:
Calculate the threshold k according to Equation ( 2). - 6:
According to the similarity value, keep the indexes corresponding to the top-k. - 7:
According to the index of retained in step 6, filter out the corresponding (i.e., in Figure 2), and splice it into a new short text.
|
3.3. Model Training
The training process of our model can be divided into three stages: in-domain pretraining, finetuning and prediction.
3.3.1. In-Domain Pretraining
In order to improve the model’s ability to learn in-domain knowledge, we need to pretrain the model based on the experimental dataset. Therefore, the first step of the in-domain pretraining stage is to construct an in-domain pretraining dataset.
As shown in
Figure 1, at the end of part 2, we obtain the filtered new shorter text. Based on the new shorter text, we build the in-domain pretraining dataset
, where
represents the
i-th filtered text.
The in-domain pretraining stage includes two subtasks, namely next sentence prediction (NSP) and MLM. In the NSP task, two sentences
and
are randomly selected from the dataset
P to construct the positive and negative splicing sample pairs according to (
3). We define that if
and
are adjacent sentences, the spliced sample is a positive sample with label “1”; otherwise, the sample is negative with label “0”. By constructing sentence-level positive and negative samples, the model can learn sentence-level contextual information in the experimental dataset.
where [CLS] is the sentence vector representation slot used to output the sentence vector representation. [SEP] is the representation notation used to separate two sentences in NSP tasks.
In the MLM task, for each sentence in the dataset P, we first randomly mask 15% of the words; then, the masked words are used as labels. Finally, the unmasked context information is used to predict the masked words. By re-predicting the masked words, the model can learn word-level contextual information in the experimental dataset.
In general, with the help of NSP and MLM, we have completed in-domain pretraining, and the model can fully learn the sentence-level and word-level context information from the experimental dataset.
3.3.2. Finetuning
The input of the finetuning stage consists of the pretrained model and the finetuning dataset. Specifically, we obtain the pretrained model H of the experimental dataset after in-domain pretraining. Combining the dataset P and the original category label data, we can construct the finetuning dataset .
There are three steps in the model finetuning:
- 1.
Input finetuning dataset into BERT model loaded with the pretrained model H.
- 2.
Calculate the cross-entropy loss between the output [CLS] of the model hidden layer and the real category label.
- 3.
Update model parameters according to step 2.
In addition, the specific calculation equation of cross-entropy loss is:
where
and
refer to the probability distributions of the true category label and predicted category label of the
i-th text, respectively, and
is the value of cross-entropy.
After finetuning, we obtain the finetuned model N.
3.3.3. Prediction
The LTTA-LE algorithm needs to filter long text according to label data. However, due to the lack of label data in the test set, the label data cannot be used to filter the noise information in the prediction stage. Therefore, we need to take advantage of the pseudo-label method [
28] to make predictions on the test set and then complete the filtering of the test set based on the obtained pseudo-labels. The specific implementation steps are as follows.
- 1.
In order to make the length of the test set meet the input requirements of the BERT model, we first shorten the test set by the head + tail truncation method, i.e., keep the fixed-length words in the head and tail of the test set as the input of the BERT model. Then, we use the model N trained in the finetuning stage to make predictions on the test set to obtain the predicted pseudo-labels.
- 2.
Based on our proposed LTTA-LE algorithm, the test set is filtered according to the predicted pseudo-labels, and new shorter texts are obtained after filtering.
- 3.
Use the model N trained in the finetuning stage to predict the new shorter text and obtain the final predicted category label of the test set.
Through the above steps, the problem of missing labels in the test set can be solved and the performance of the model can be significantly improved. Furthermore, the model training process including the above three stages is summarized in Algorithm 3.
| Algorithm 3 Model training algorithm. |
- Input:
New shorter text ; Label dataset . - Output:
The predict label. - 1:
Input P into the BERT model for in-domain pretraining, and obtain the pretrained model H. - 2:
According to P and Y, build the finetuning dataset . - 3:
Input D into model H for finetuning, and obtain the finetuned model N. - 4:
Use N to make predictions on the test set and obtain pseudo-labels. - 5:
Based on the LTTA-LE algorithm and the predicted pseudo-labels in step 4, the long texts in the test set are filtered to obtain new shorter texts. - 6:
Use N to predict the new shorter text in step 5 to obtain the final predict label of the test set.
|




{kind=link}
{kind=link}

