
A Star-Identification Algorithm Based on Global Multi-Triangle Voting

Abstract
:1. Introduction
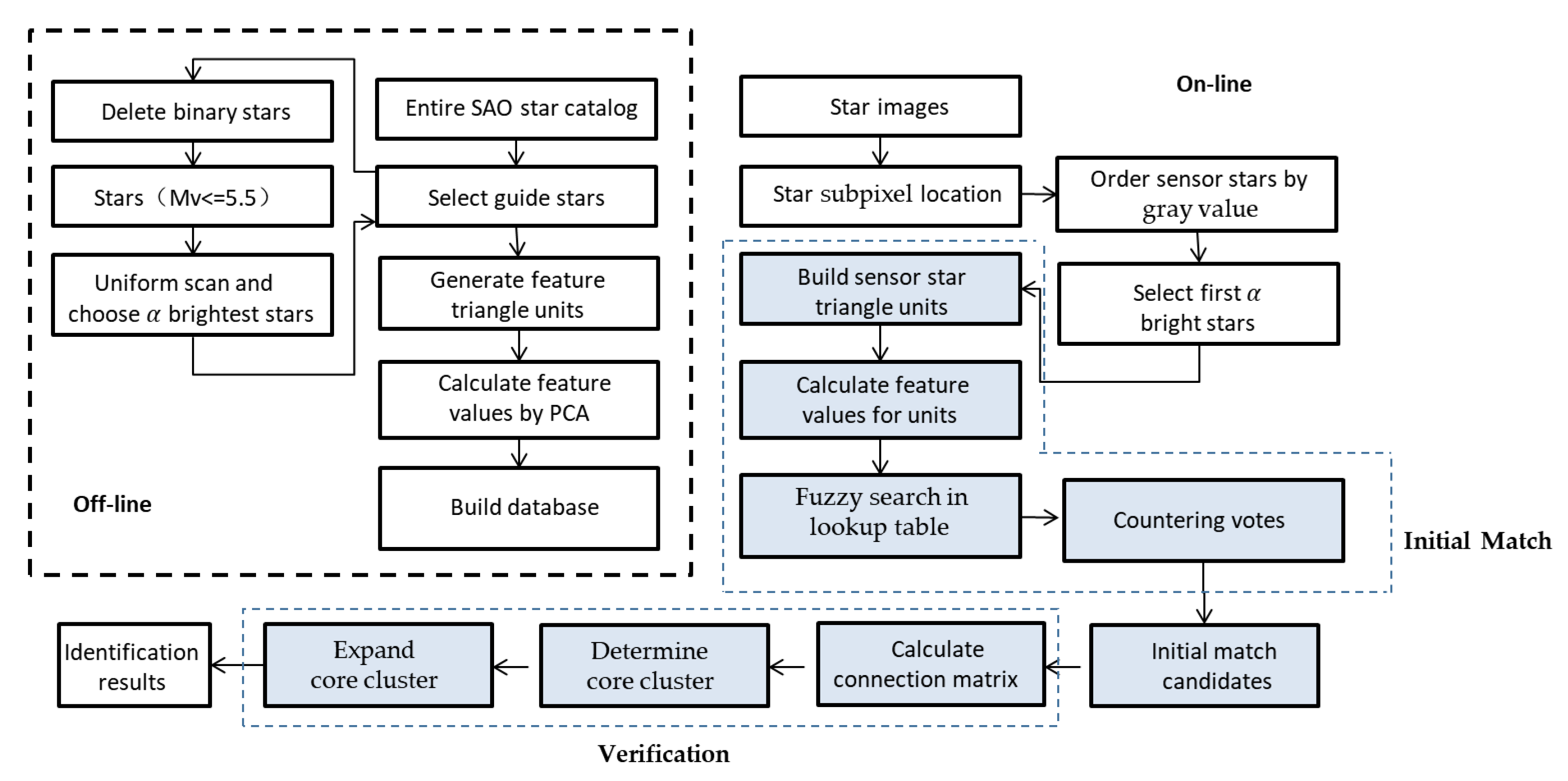
2. Algorithm Description
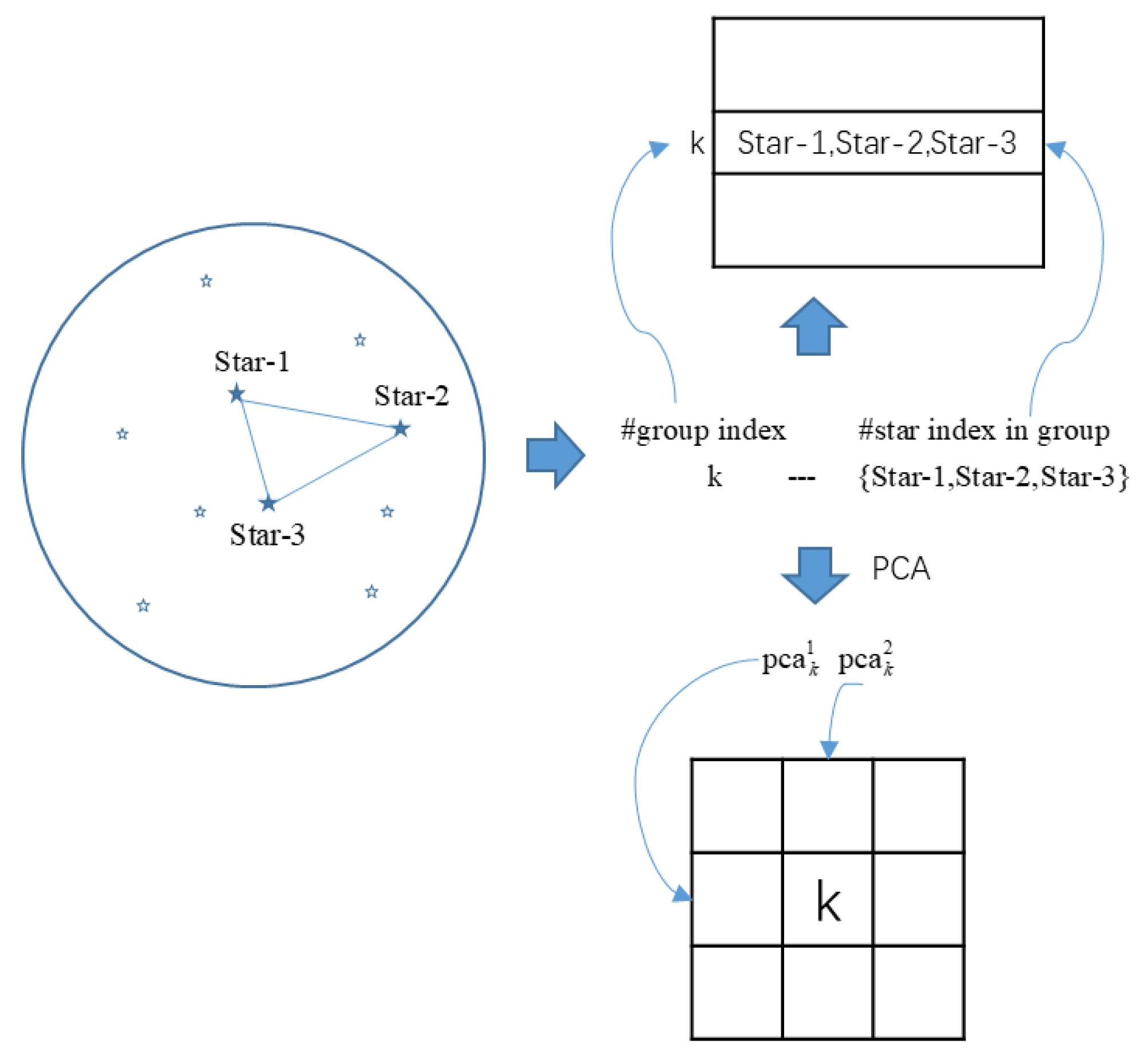
2.1. Triangle Unit and Feature Extraction
2.2. Onboard Database Generation
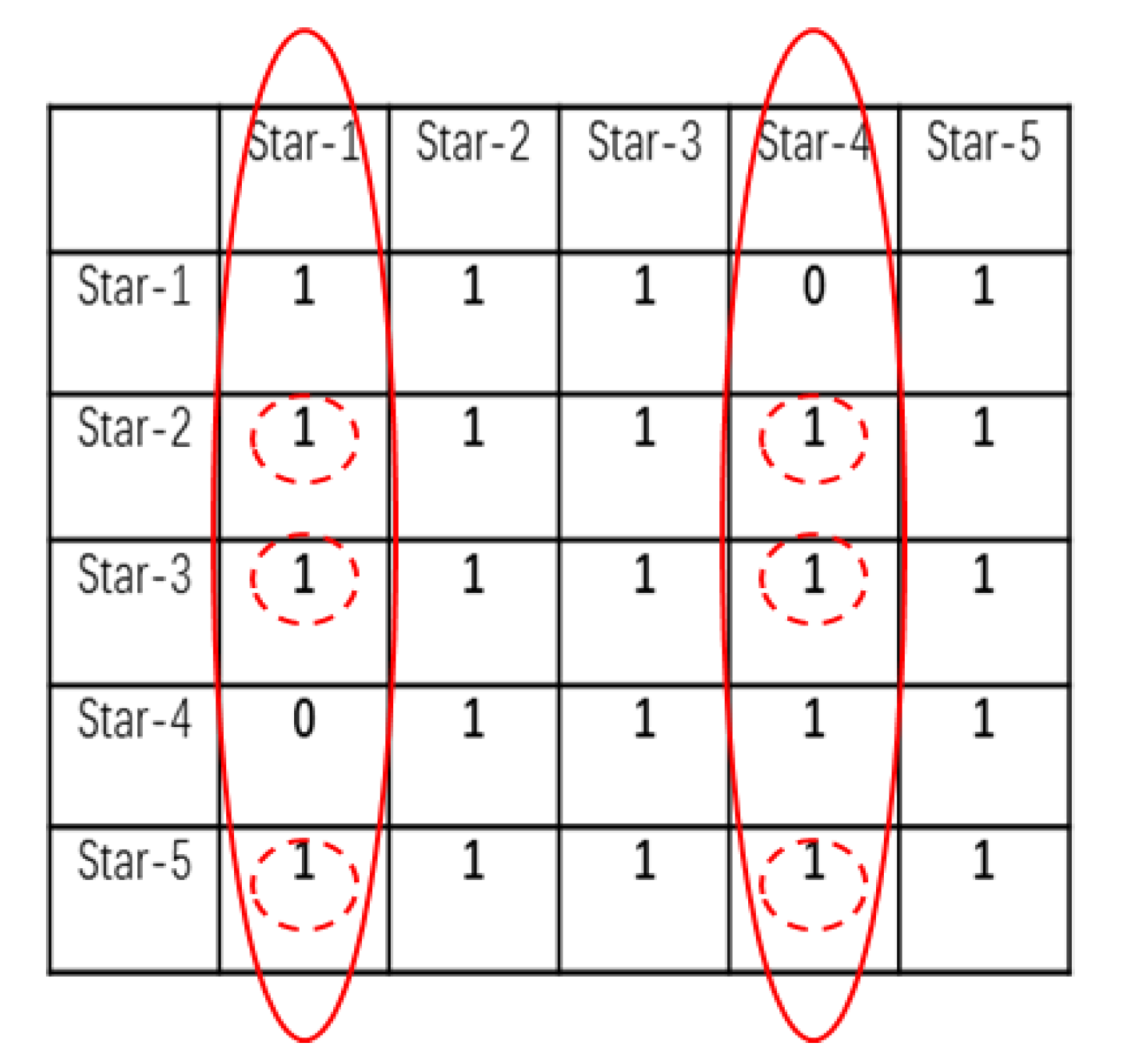
2.3. Global Multi-Triangle Voting Algorithm
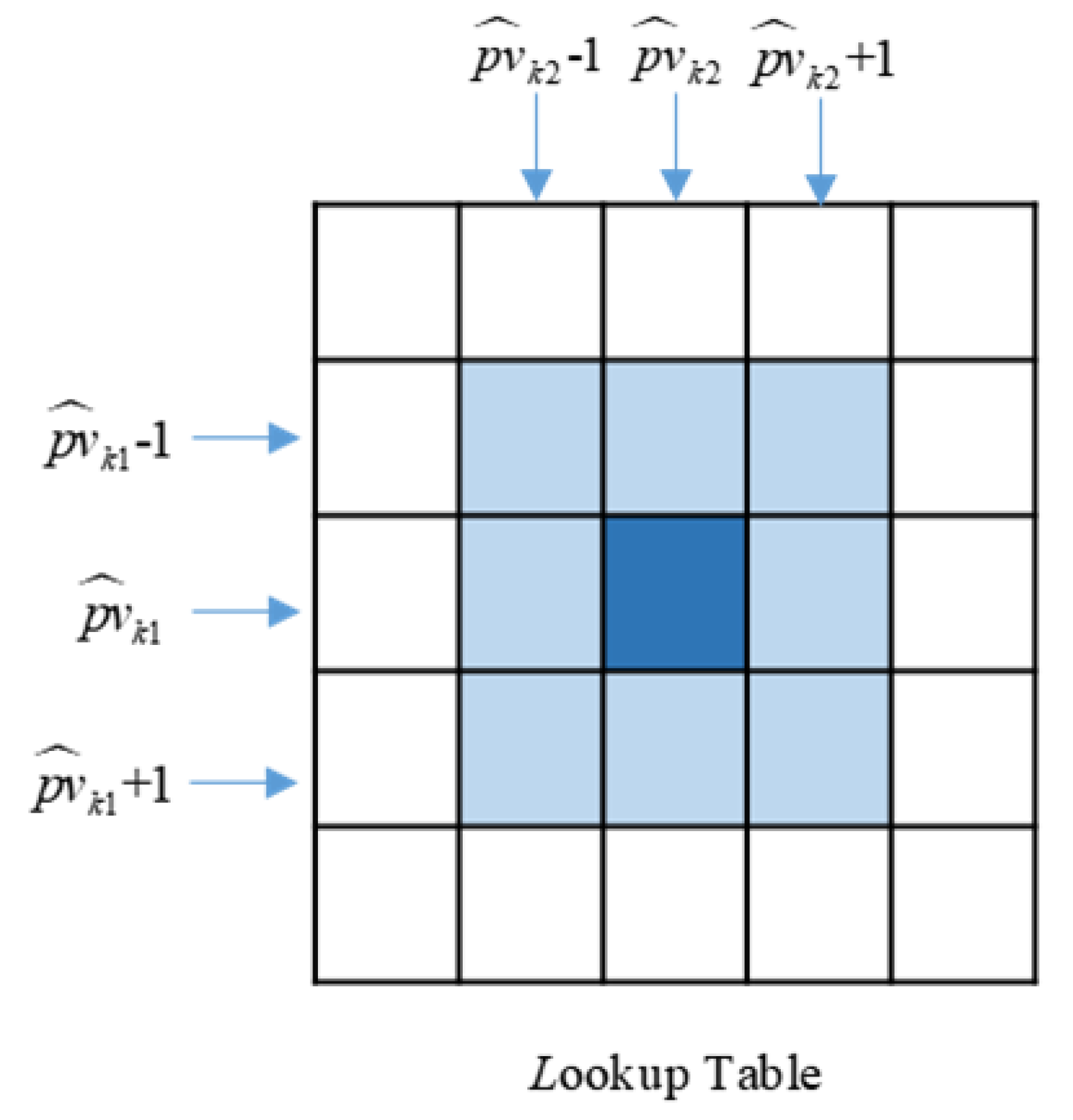
2.3.1. Initial Match
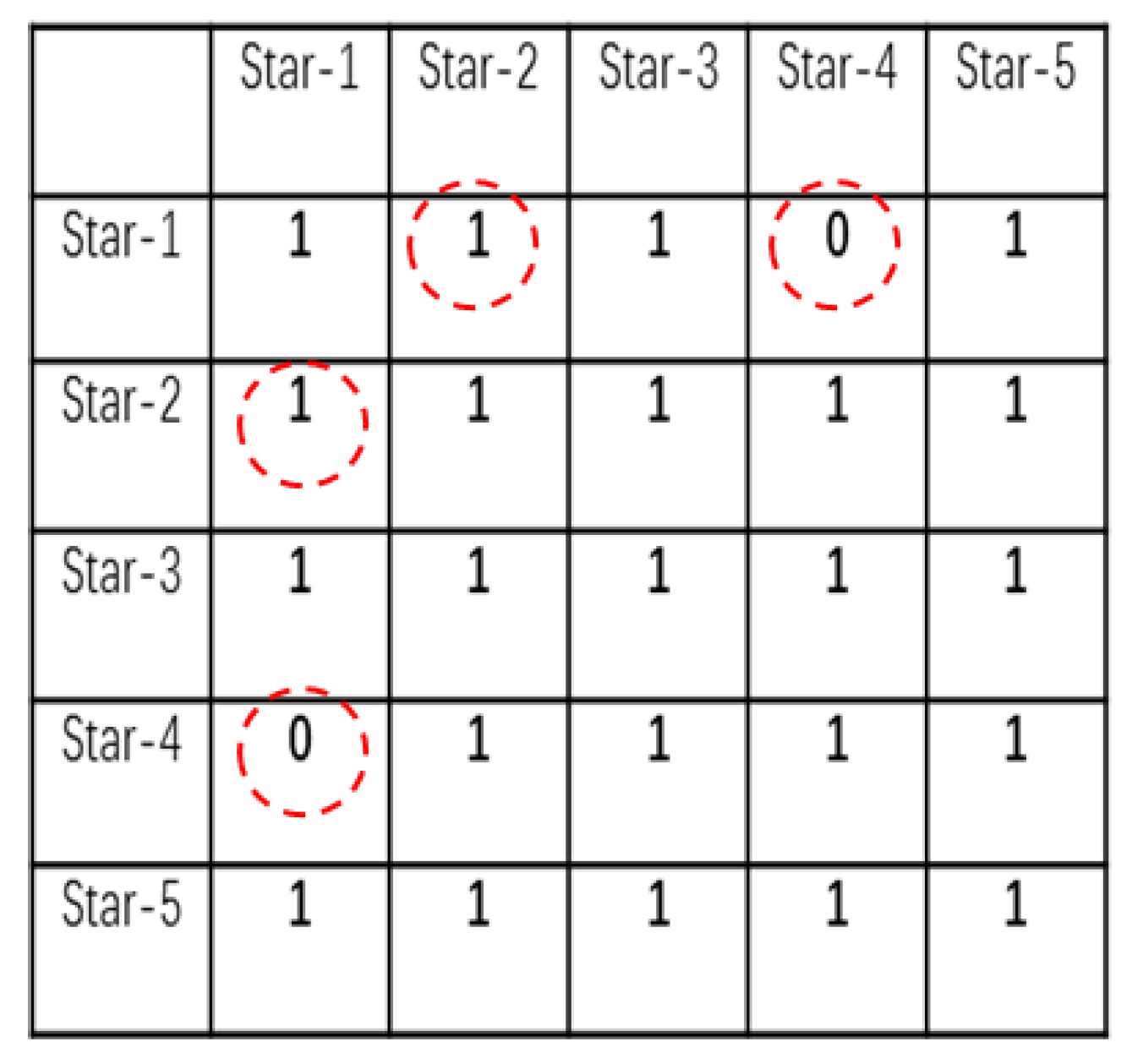
2.3.2. Verification
3. Simulations and Results
3.1. Parameter Selection
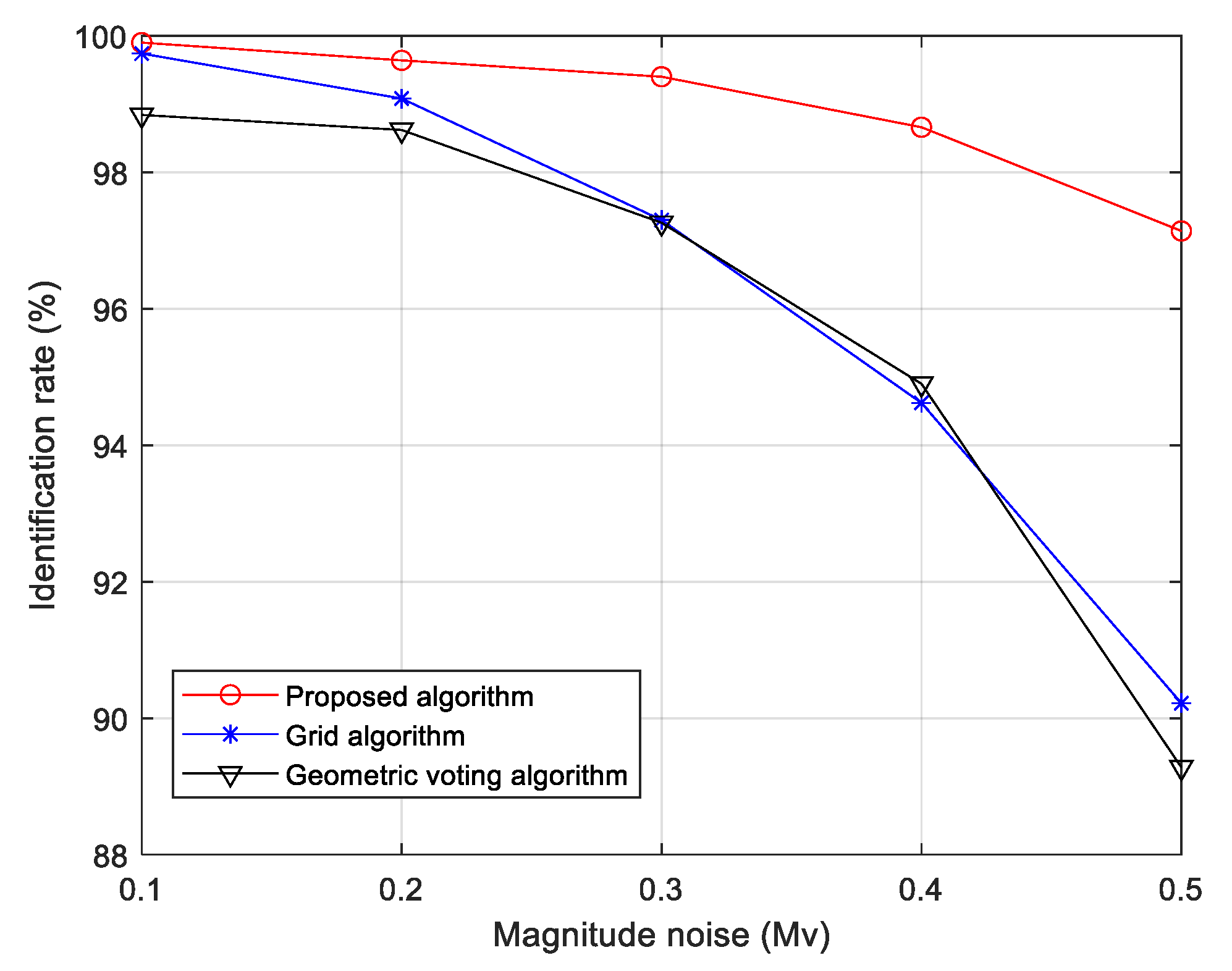
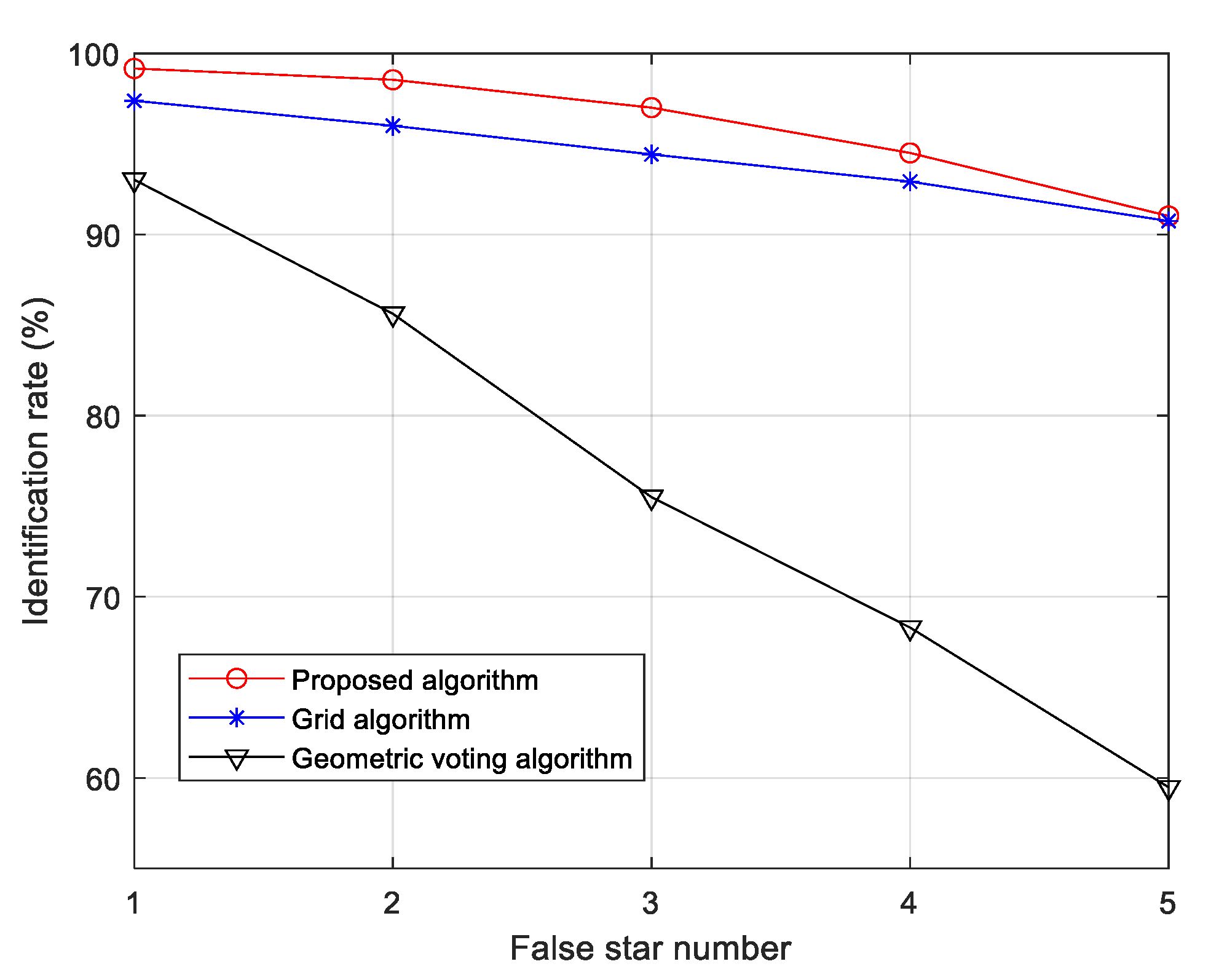
3.2. Comparison and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liebe, C.C. Accuracy performance of star trackers-a tutorial. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 587–599. [Google Scholar] [CrossRef]
- Silani, E.; Lovera, M. Star identification algorithms: Novel approach & comparison study. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 1275–1288. [Google Scholar]
- Sun, L.; Jiang, J.; Zhang, G.; Wei, X. A discrete HMM-Based feature sequence model approach for star identification. IEEE Sens. 2016, 16, 931–940. [Google Scholar] [CrossRef]
- Mehta, D.S.; Chen, S.; Liang, R.; Low, K.S. A rotation-invariant additive vector sequence based star pattern recognition. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 689–705. [Google Scholar] [CrossRef]
- Samaan, M.A.; Mortari, D.; Junkins, J.L. Recursive mode star identification algorithms. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1246–1254. [Google Scholar] [CrossRef]
- Rijlaarsdam, D.; Yous, H.; Byrne, J.; Oddenino, D.; Furano, G.; Moloney, D. A Survey of Lost-in-Space Star Identification Algorithms Since 2009. Sensors 2020, 20, 2579. [Google Scholar] [CrossRef]
- Padgett, C.; Kreutz-Delgado, K. A grid algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 202–213. [Google Scholar] [CrossRef]
- Na, M.; Zheng, D.; Jia, P. Modified grid algorithm for noisy all-sky autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 516–522. [Google Scholar] [CrossRef]
- Clouse, D.S.; Padgett, C.W. Small field-of-view star identification using Bayesian decision theory. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 773–783. [Google Scholar] [CrossRef]
- Aghaei, M.; Moghaddam, H.A. Grid star identification improvement using optimization approaches. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2080–2090. [Google Scholar] [CrossRef]
- Zhang, G.; Wei, X.; Jiang, J. Full-sky autonomous star identification based on radial and cyclic features of star pattern. Image Vis. Comput. 2008, 26, 891–897. [Google Scholar] [CrossRef]
- Wei, X.; Wen, D.; Song, Z.; Xi, J.; Zhang, W.; Liu, G.; Li, Z. A star identification algorithm based on radial and dynamic cyclic features of star pattern. Adv. Space Res. 2019, 63, 2245–2259. [Google Scholar] [CrossRef]
- Liu, H.; Wei, X.; Jian, L.; Wang, G. A star identification algorithm based on recommended radial pattern. IEEE Sens. 2022, 22, 8030–8040. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, G.; Jiang, J. Star identification algorithm based on log-polar transform. J. Aerosp. Comput. Inf. Commun. 2009, 6, 483–490. [Google Scholar] [CrossRef]
- Jiang, J.; Ji, F.; Yan, J.; Sun, L.; Wei, X. Redundant-coded radial and neighbor star pattern identification algorithm. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 2811–2822. [Google Scholar] [CrossRef]
- Kim, S.; Cho, M. New star identification algorithm using labelling technique. Acta Astronaut. 2019, 162, 367–372. [Google Scholar] [CrossRef]
- Du, J.; Wei, X.; Jian, L.; Wang, G.; Zang, C. Star identification based on radial triangle mapping Matrix. IEEE Sens. 2022, 22, 8795–8807. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, J.; Zhang, G. Star identification based on spider-web image and hierarchical CNN. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 3055–3062. [Google Scholar]
- Xu, L.; Jiang, J.; Liu, L. A representation learning-based star identification algorithm. IEEE Access 2019, 7, 91193–92202. [Google Scholar] [CrossRef]
- Yang, S.; Liu, L.; Zhou, J.; Zhao, Y.; Hua, G.; Sun, H.; Zheng, N. Robust and efficient star identification algorithm based on 1D convolutional neural network. IEEE Trans. Aerosp. Electron. Syst. 2022. [Google Scholar] [CrossRef]
- Zhang, G.J.; Wei, X.G.; Jiang, J. Star map identification based on a modified triangle algorithm. Aeronaut. Astronaut. Sin. 2006, 27, 1150–1154. [Google Scholar]
- Fang, J.; Quan, W.; Meng, X. All-sky autonomous star map identification algorithm based on Delaunay triangulation cutting algorithm. J B Univ Aeronaut Astronaut 2005, 31, 311–315. [Google Scholar]
- Sun, L.; Zhou, Y. MVDT-SI: A Multi-View Double-Triangle Algorithm for Star Identification. Sensors 2020, 20, 3027. [Google Scholar] [CrossRef] [PubMed]
- Mortari, D.; Samaan, M.A.; Bruccoleri, C.; Junkins, J.L. The pyramid star identification technique. Navigation 2004, 51, 171–183. [Google Scholar] [CrossRef]
- Kolomenkin, M.; Pollak, S.; Shimshoni, I.; Lindenbaum, M. Geometric voting algorithm for star trackers. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 441–456. [Google Scholar] [CrossRef]
- Quine, B.M.; Durrant-Whyte, H.F. A fast autonomous star-acquisition algorithm for spacecraft. Control. Eng. Pract. 1996, 4, 1735–1740. [Google Scholar] [CrossRef]
- Wang, Z.; Quan, W. An all-sky autonomous star map identification algorithm. IEEE Trans. Aerosp. Electron. Syst. 2004, 19, 10–14. [Google Scholar] [CrossRef]
- Wang, G.; Jian, L.; Wei, X. Star identification based on hash map. IEEE Sens. 2017, 18, 1591–1599. [Google Scholar] [CrossRef]
- Zhao, Y.; Wei, X.; Jian, L.; Wang, G. Star identification algorithm based on K–L transformation and star walk formation. IEEE Sens. 2016, 16, 5202–5210. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field of View | 25° × 25° |
|---|---|
| Resolution | 1024 × 1024 |
| Pixel size | 15 μm |
| Focal Length | 34.64 mm |
| Minimum Sensitivity | 5.5 Mv |
| Algorithm | Our Method | Grid | Geometric Voting |
|---|---|---|---|
| Run time | 18.36 ms | 72.71 ms | 96.86 ms |
| Memory size | 1.5 MB | 0.5 MB | 0.6 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Zhu, J.; Zhu, K.; Li, X. A Star-Identification Algorithm Based on Global Multi-Triangle Voting. Appl. Sci. 2022, 12, 9993. https://doi.org/10.3390/app12199993
Yuan X, Zhu J, Zhu K, Li X. A Star-Identification Algorithm Based on Global Multi-Triangle Voting. Applied Sciences. 2022; 12(19):9993. https://doi.org/10.3390/app12199993
Chicago/Turabian StyleYuan, Xiaobin, Jingping Zhu, Kaijian Zhu, and Xiaobin Li. 2022. "A Star-Identification Algorithm Based on Global Multi-Triangle Voting" Applied Sciences 12, no. 19: 9993. https://doi.org/10.3390/app12199993
APA StyleYuan, X., Zhu, J., Zhu, K., & Li, X. (2022). A Star-Identification Algorithm Based on Global Multi-Triangle Voting. Applied Sciences, 12(19), 9993. https://doi.org/10.3390/app12199993