
Novel Semantic-Based Probabilistic Context Aware Approach for Situations Enrichment and Adaptation



Abstract
:1. Introduction
- Enhance semantic description of user’s context profile and improve classification of situations rule based on four probability-based-context items (user’s location and time, user’s role, user’s preferences and user’s experiences).
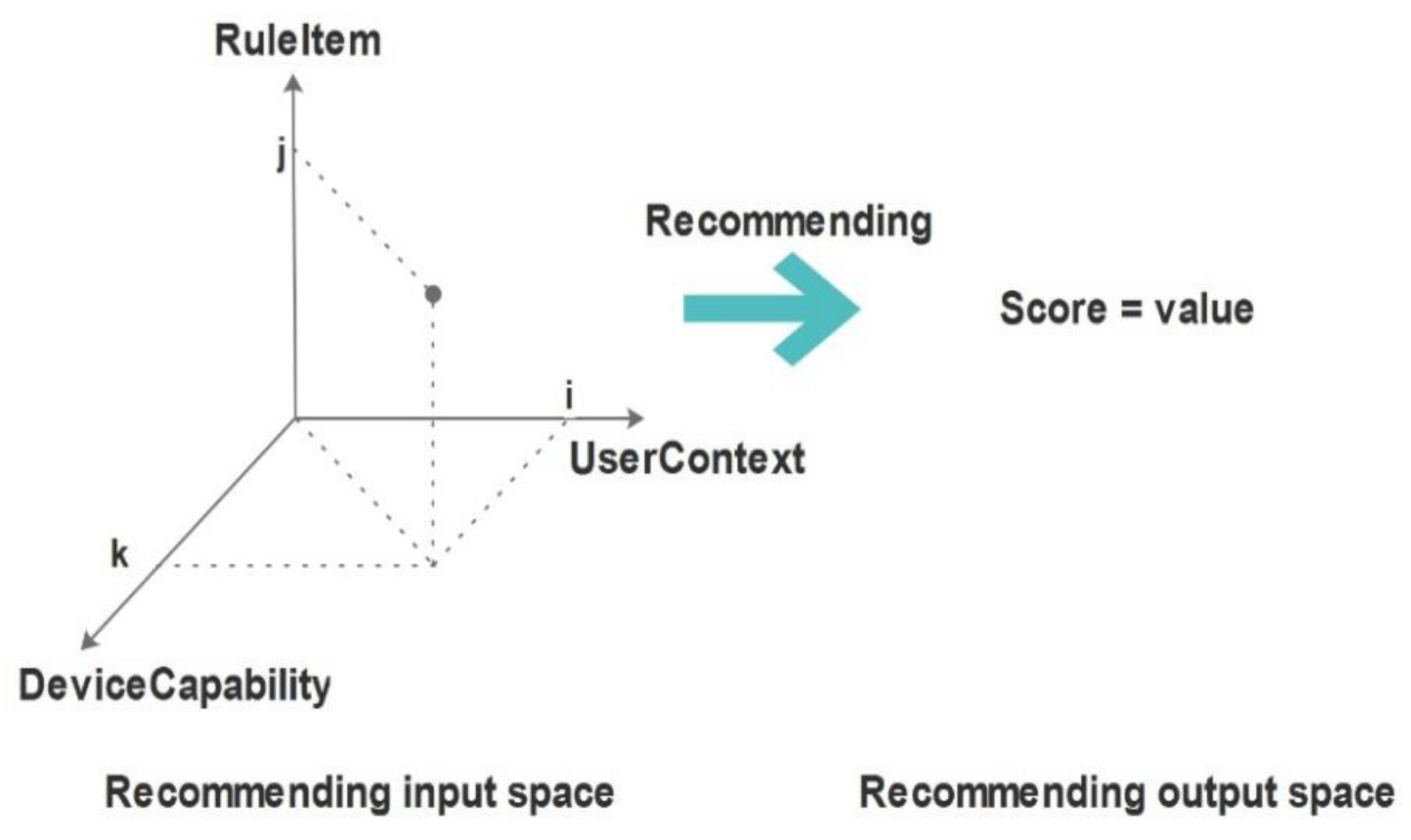
- Apply multidimensional (user’s context, device capability and rule content) recommendation space for smart environments.
- Combine semantic classification techniques and Bayesian-classifier to improve recommendation of situation rules and a high accuracy rate by Bayesian-classifier. The weighted linear combination is applied to calculate the similarity of rule items. The higher scores between the selected items are used to identify the relevant user’s situations.
- Compare performance between the proposed approach and four other recommendation approaches among the most common algorithms learning-recommendation for various performance metrics.
2. Related Works
2.1. Content-Based Filtering
2.2. Collaborative-Filtering (CF)
2.3. Hybrid Filtering
2.4. Context-Aware Recommendation System
2.5. Comparison of Recommendation Works
3. Situation-Based Contextual Model: Definitions and Formalizations
3.1. Modeling Multidimensional Recommendation Space
3.2. The User Context Profile Formalization
3.3. The Rule Preference Formalization
3.4. The Device Context
3.5. The Situation Rules Formalization
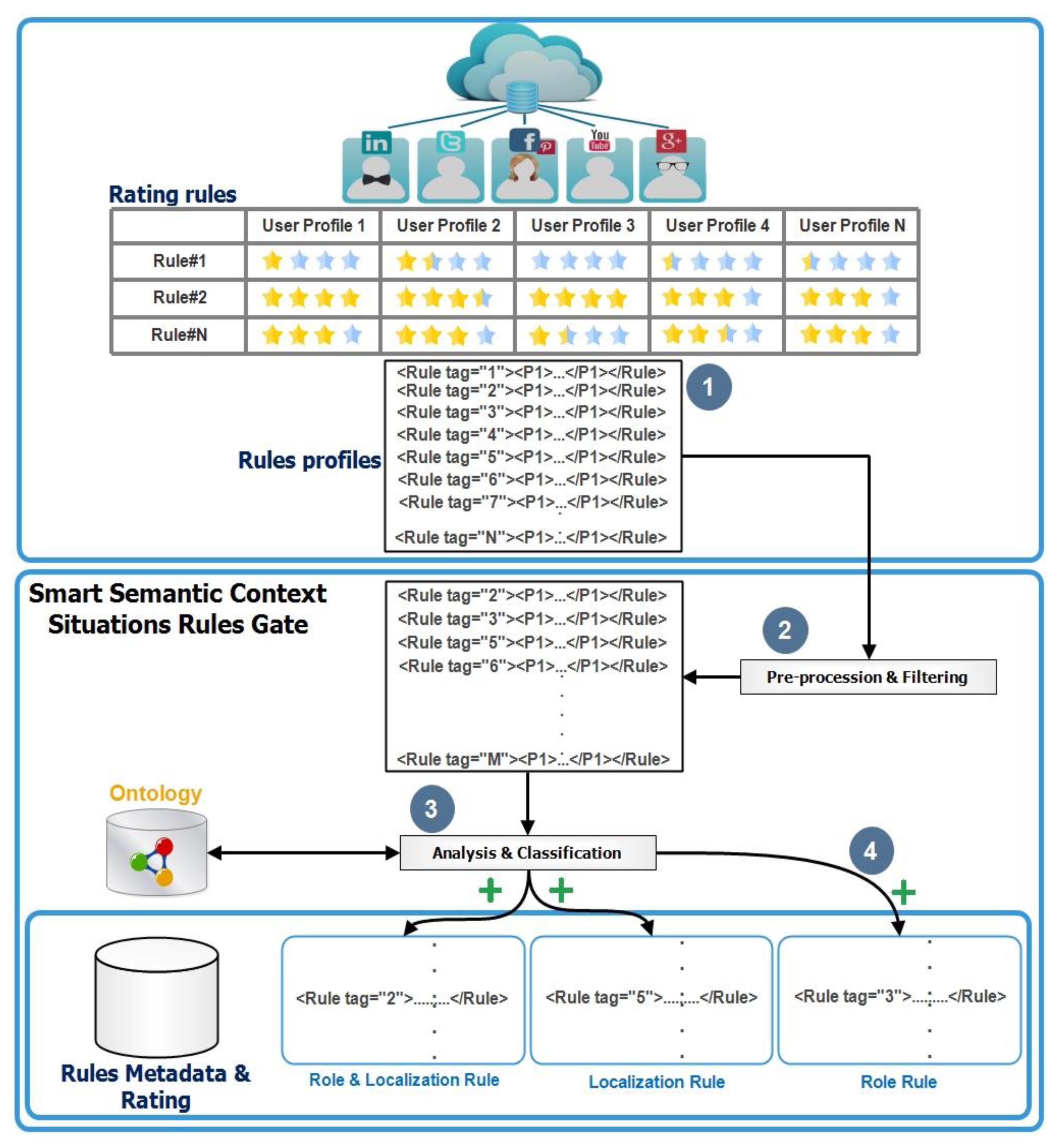
3.6. Classification of Situation Rules
- Role-based rules: This kind of rules depends on the user’s role. As an example of role-based rules, Rule#1(Work) rule checks time axis is equal to the planed time and user’s job is an employer. This rule is described as follows:
- Localization-based rules: This kind of rules depends on the user’s location. As an example of localization-based rule, Rule#2 () situation rule consists of two projections: and . checks the user’s location is outside home and checks time is between 8 pm and 5 am. It is, exceptionally, unchecked in Sunday. It is described as follows:
- Rules-based on localization and role: These kinds of rules depend on both location and role of a user. For example, Rule#3 (Meeting) situation rule checks the user’s location is inside the meeting room and time axis is equal to the meeting time and his role axis is employer.
4. Proposed Approach
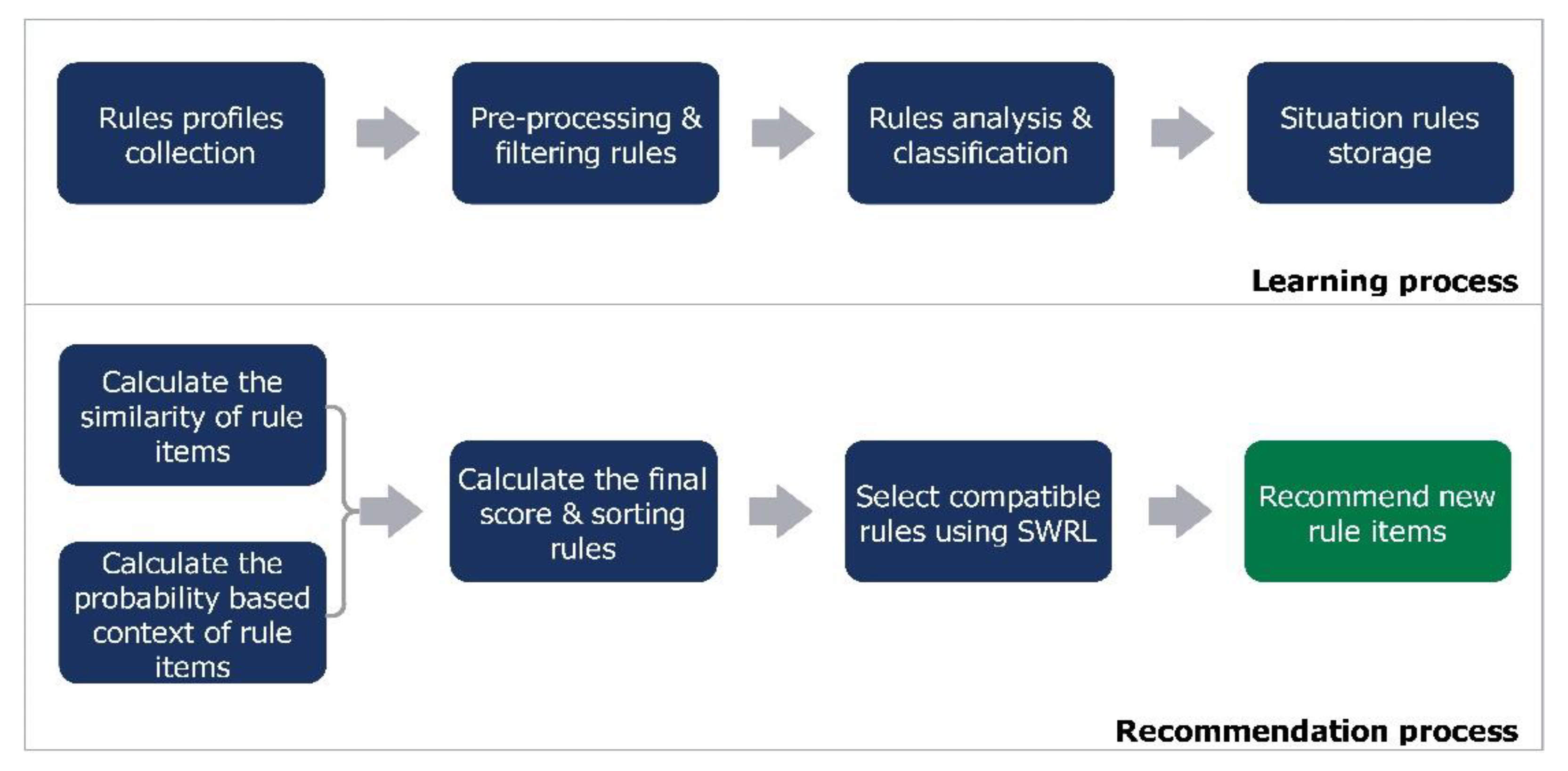
4.1. Situation Rules Learning Process
- : the popularity of situation i.
- : the rating of user j for situation i.
- : the number of users rated the situation i.
4.2. Recommendation Process of Situation Rules
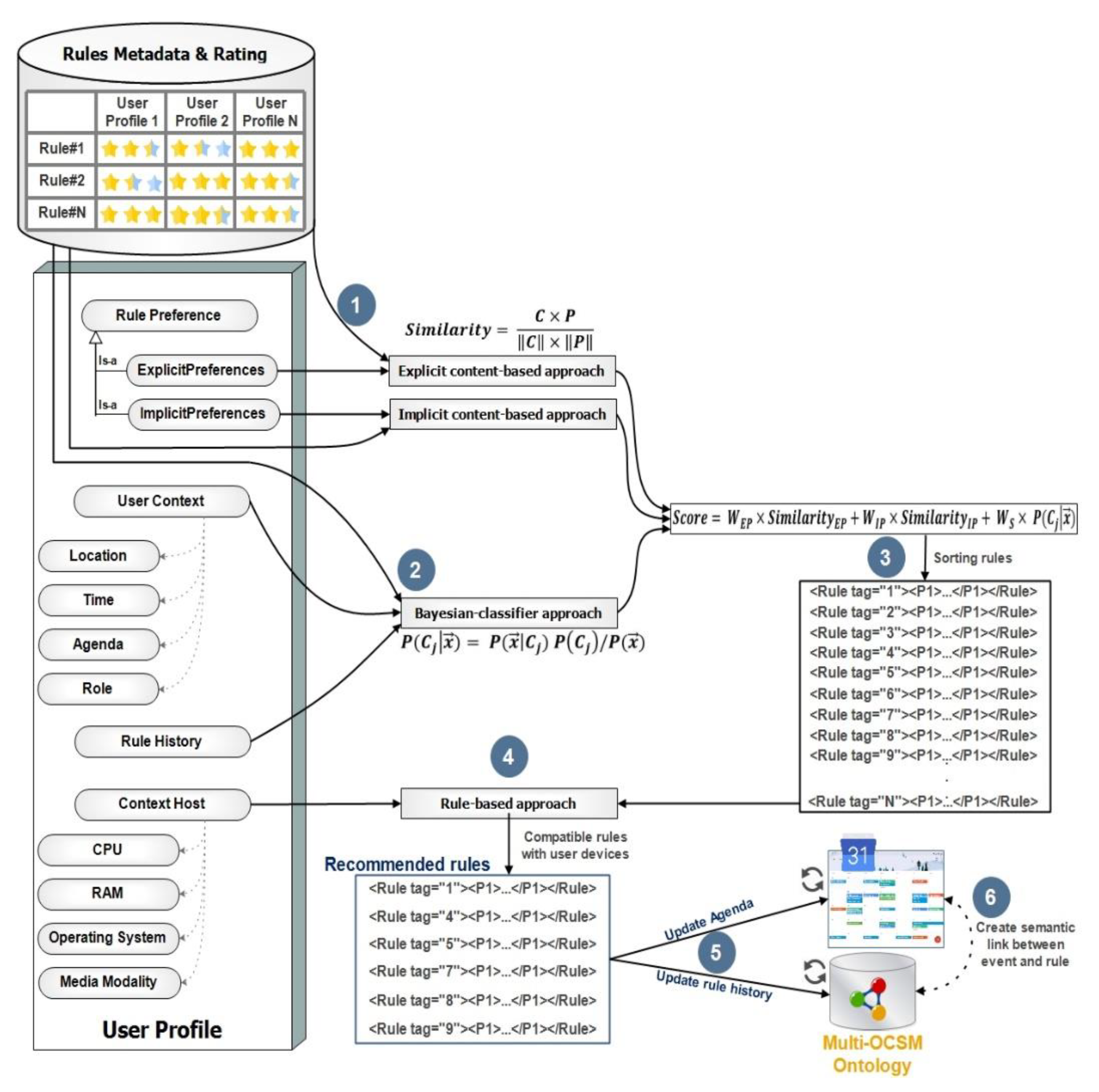
4.2.1. Rule’s Content-Based Approach
- −
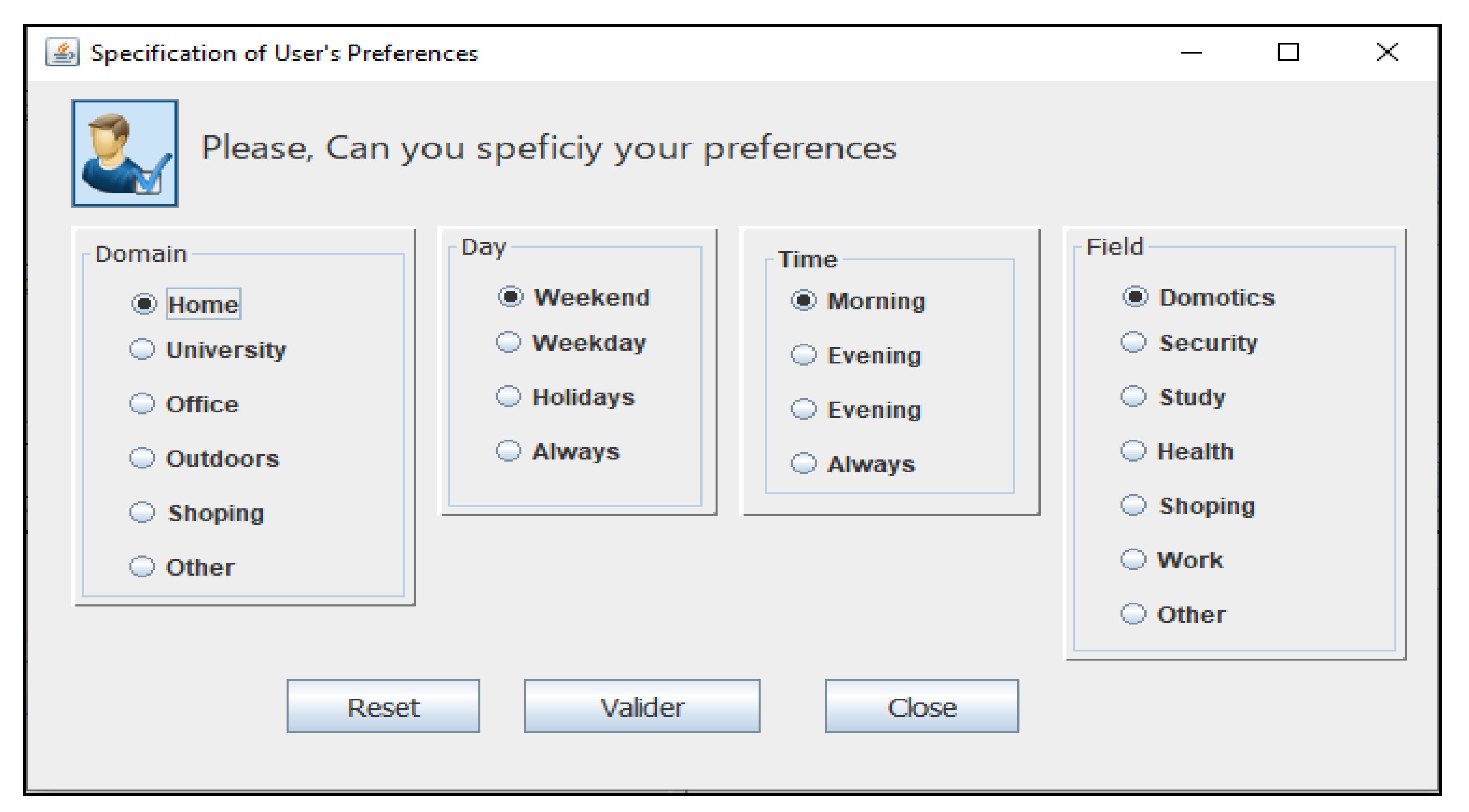
- Domain: The application’s domain in the configuration preferences, as a string of the possible values (Home, Car, Office, University, Shop, Security, Hospital).
- −
- Day: The days in the configuration preferences, as a string of the possible values (Weekday, Weekend).
- −
- Time: The time in the configuration preferences, as a string of the possible values (Morning, Afternoon, Evening, Night).
- −
- Field: The field of user’s domain in the configuration preferences, as a string of the values (Security, Demotics, Study, Health, Work, Shopping).
| Algorithm 1: Extract Terms from Explicit Preferences (EP). |
| Input: Explicit preference vector ; |
| Output: Term vector ; |
| Begin |
|
| End. |
| Algorithm 2: Extract Terms from Rules Repository (RR) |
| Input: Rules repository vector ; |
| Output: Implicit preference vector ; |
| Begin |
|
| End. |
| Algorithm 3: Generating the Vector C. |
| Inputs: Rule item’s metadata (item to recommend); |
| The vector ; |
| Output: The vector ; |
| Begin |
|
| End |
4.2.2. Bayesian-Classifier Approach
- −
- Location: The user’s location has the possible values (Home, University, Office and Outdoors).
- −
- Day: The days have the possible values (Weekday and Weekend).
- −
- Time: The time has the possible values (Morning, Afternoon, Evening and Night.) and,
- −
- Role: The user’s role has the possible values (Citizen, Student, Worker and Driver).
- represents the ith tag of .
- represents the total number of users that has used the situation rules in .
- represents the total number of rules in situation rules repository.
- represents number of tag appears in .
- represents the sum of all tags appear in .
- represents the total number of tags appearing in .
- is assigned to explicit similarity .
- is assigned to implicit similarity .
- is assigned to situation probability similarity .
- .
4.2.3. Rule-Based Adaptation Process
| Algorithm 4: Check Device’s Requirements with Situation Rule |
| User_Profile (?u) ∧ User_Domain (?u, ?d) ∧ hasCPUReq_device (?d, ?CPUSpeed_device) ∧ hasRAMReq_device (?d, ?RAMSize_device) ∧ hasNetworkReq_device (?d, ?network_device) ∧ Situation_Rule (?r, “Home_Intrusion_Alarm”) ∧ hasCPUReq_rule (?rule, ?CPUSpeed_rule) ∧hasRAMReq_rule (?d, ?RAMSize_rule) ∧ hasNetworkReq_rule (?d, ?network_rule) ∧ greaterThan(?CPUSpeed_device, ?CPUSpeed_rule) ∧ greaterThan (?RAMSize_device, ?RAMSize_rule) ∧ greaterThan (?network_device, ?network_rule) → agenda(?u, ?r) |
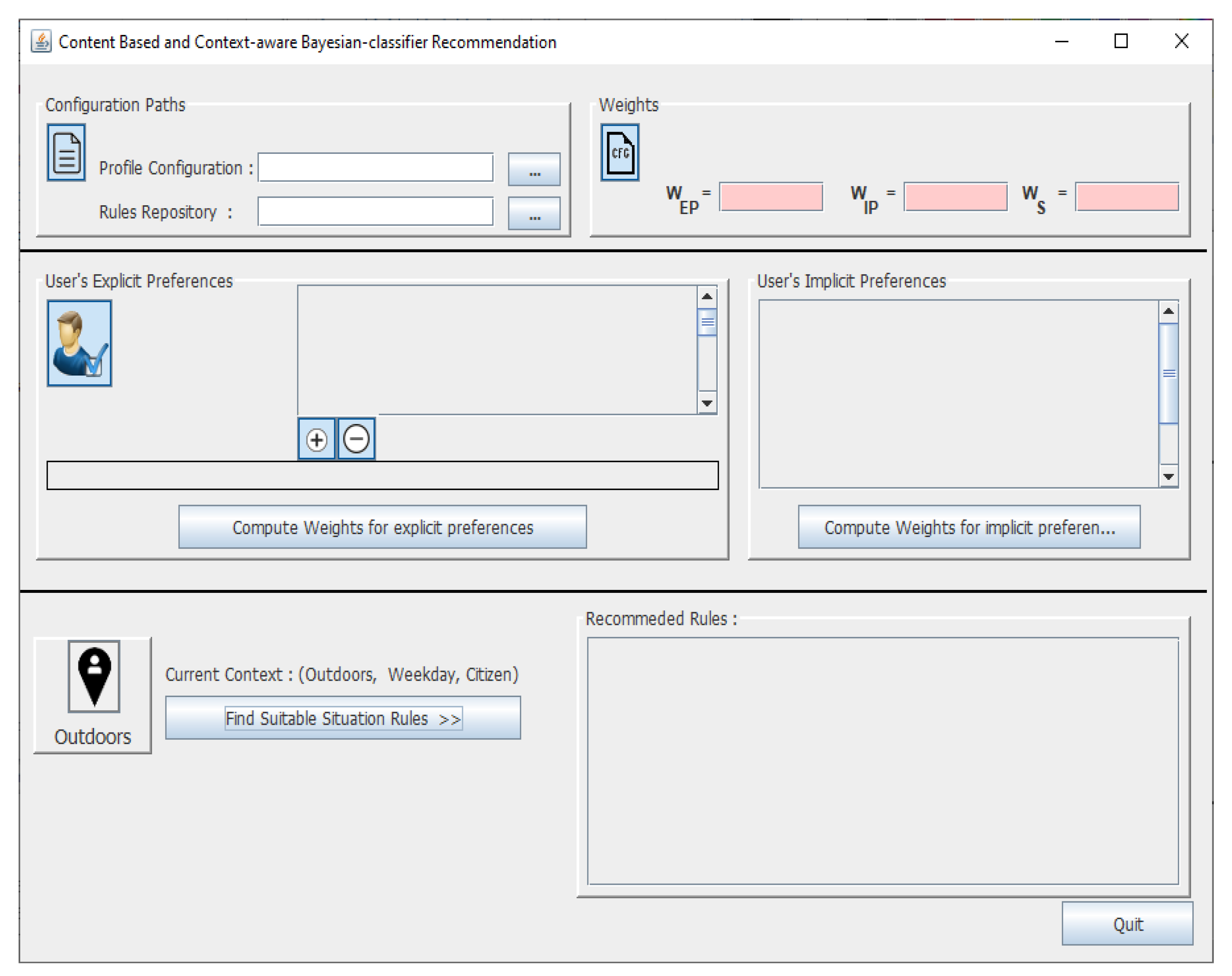
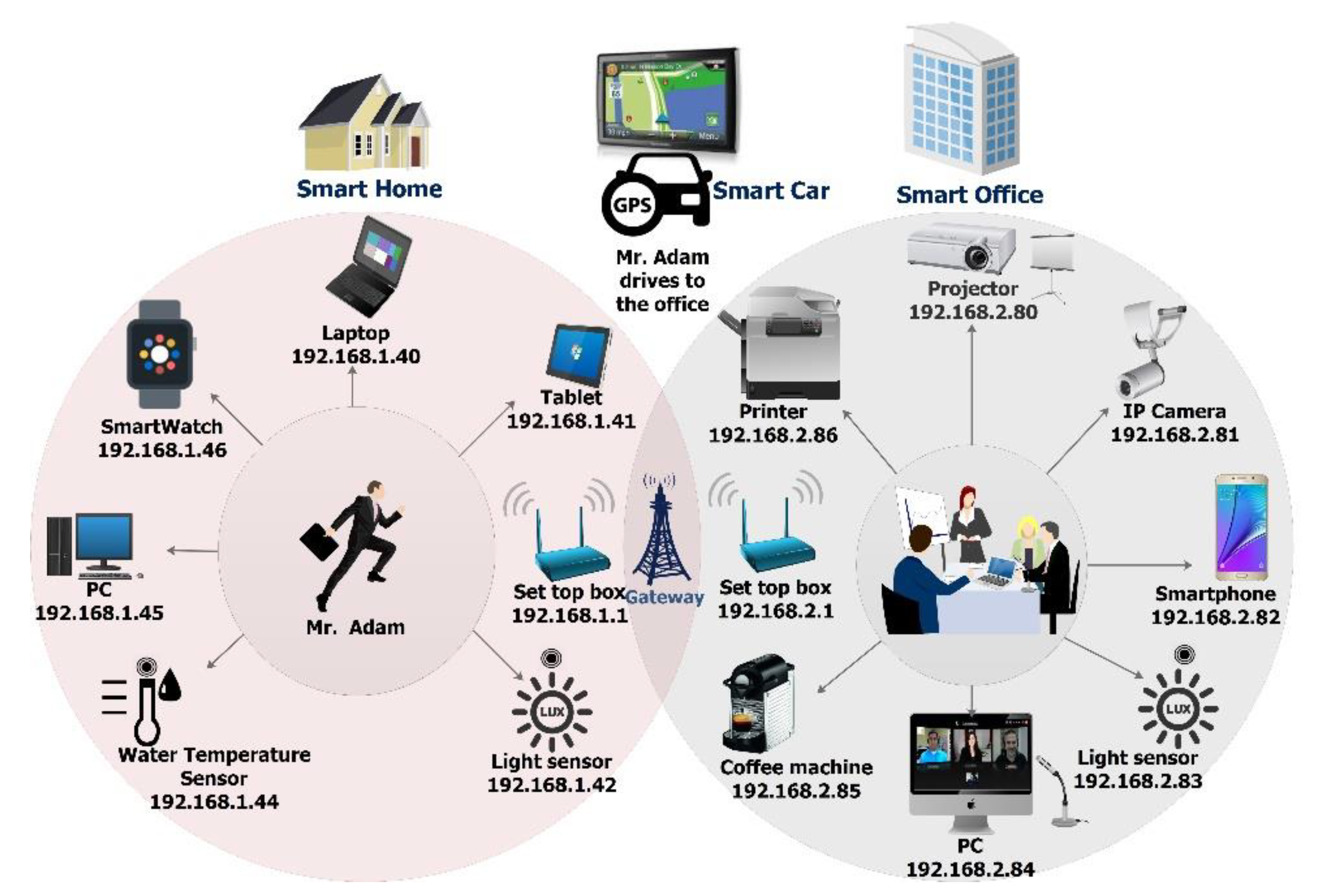
5. The Prototype
5.1. Prototype Implementation
- Create and save a novel profile with its preferences in the profile configuration file.
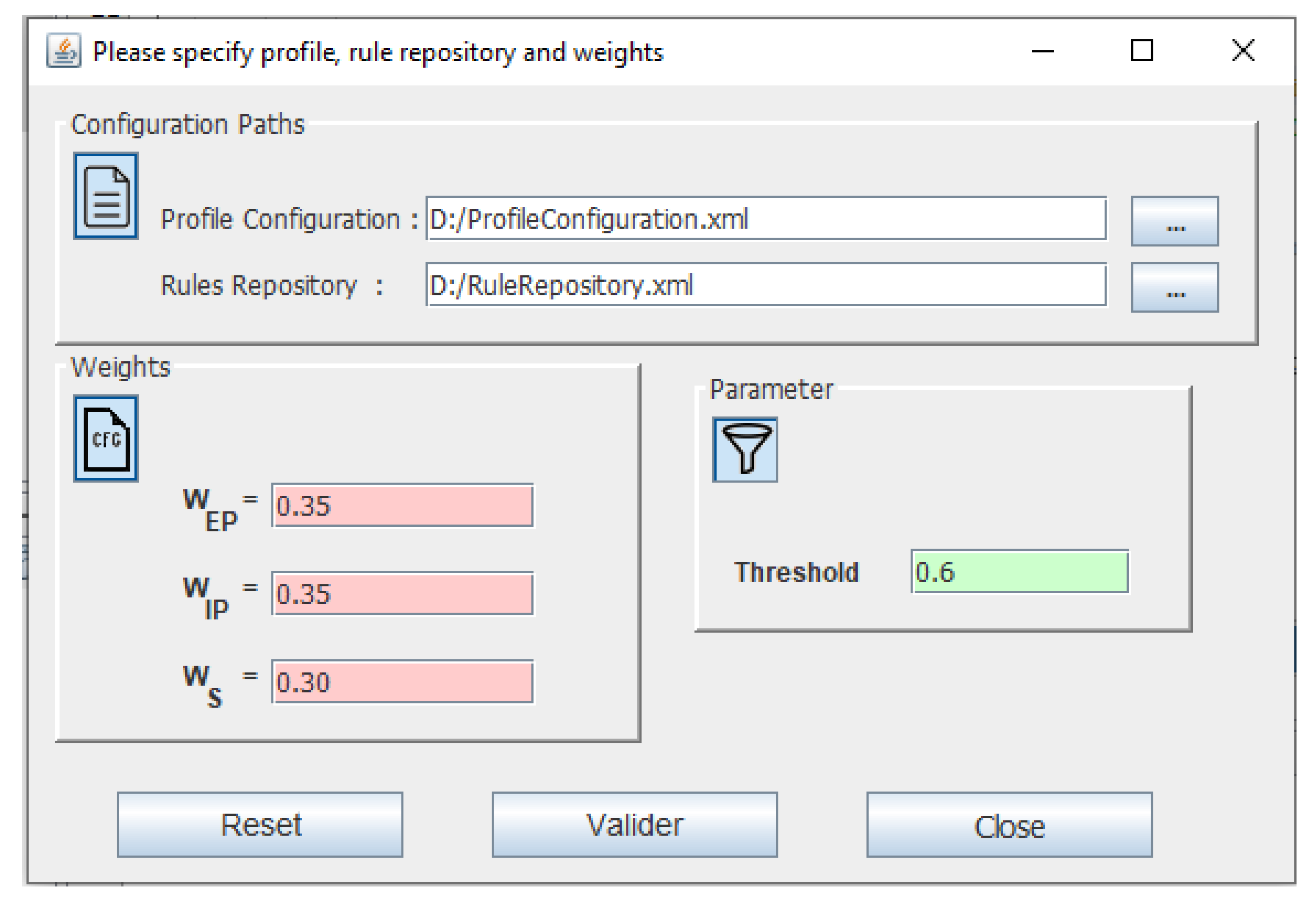
- Manage any user’s preferences, which has several customizable options according to user preferences. For example, the user can select between locations, roles to either worker or others. The weight for the recommendation processes can be also customized by the user, selecting a value among [0, 1] in the GUI.
- Recommend relevant rules according to profile configuration.
- Adapt actions services based on the device’s characteristics information.
5.2. Possible Scenarios
5.3. Evaluation and Comparison
5.3.1. Dataset
5.3.2. Performance Measures
- Precision () is the ratio of relevant recommended rule items to the user and the total among the recommended ones.
- Recall () is the ratio of relevant recommended items among the total number of all items.
- F1-score () is used to evaluate a weighted average of precision and recall.
- TP is the total number of relevant rules items (True Positive).
- FP is the total number of non-relevant rules items (False Positive).
- TN is the total number of relevant rules items that are not selected by the proposed approach (True Negative).
- FN is the total number of non-relevant rules items that are not selected by the proposed approach (False Negative).
5.3.3. Tests and Configuration Setup
- Test # 1: Rules items recommendation based on explicit preference context
- Test # 2: Rules items recommendation based on hybrid preference-based approach
- Test # 3: Rules items recommendation based on implicit preference context
- Test # 4: Rules items recommendation based on situation context Bayesian-based approach
- Test # 5: Rules items recommendation based on the proposed approach
5.4. Results and Discussion
5.4.1. Evaluation and Comparison Regarding Accuracy
- 1.
- Explicit Preferences (EP).
- 2.
- Implicit Preferences (IP).
- 3.
- Both Explicit and Implicit preferences (EIP).
- 4.
- Contextual-based Bayesian (Cx-Bayesian).
- 5.
- All criteria are considered (EIP and Cx-Bayesian).
5.4.2. Compared Classifiers Regarding Accuracy
5.4.3. Evaluation of Response Time
5.4.4. Discussion
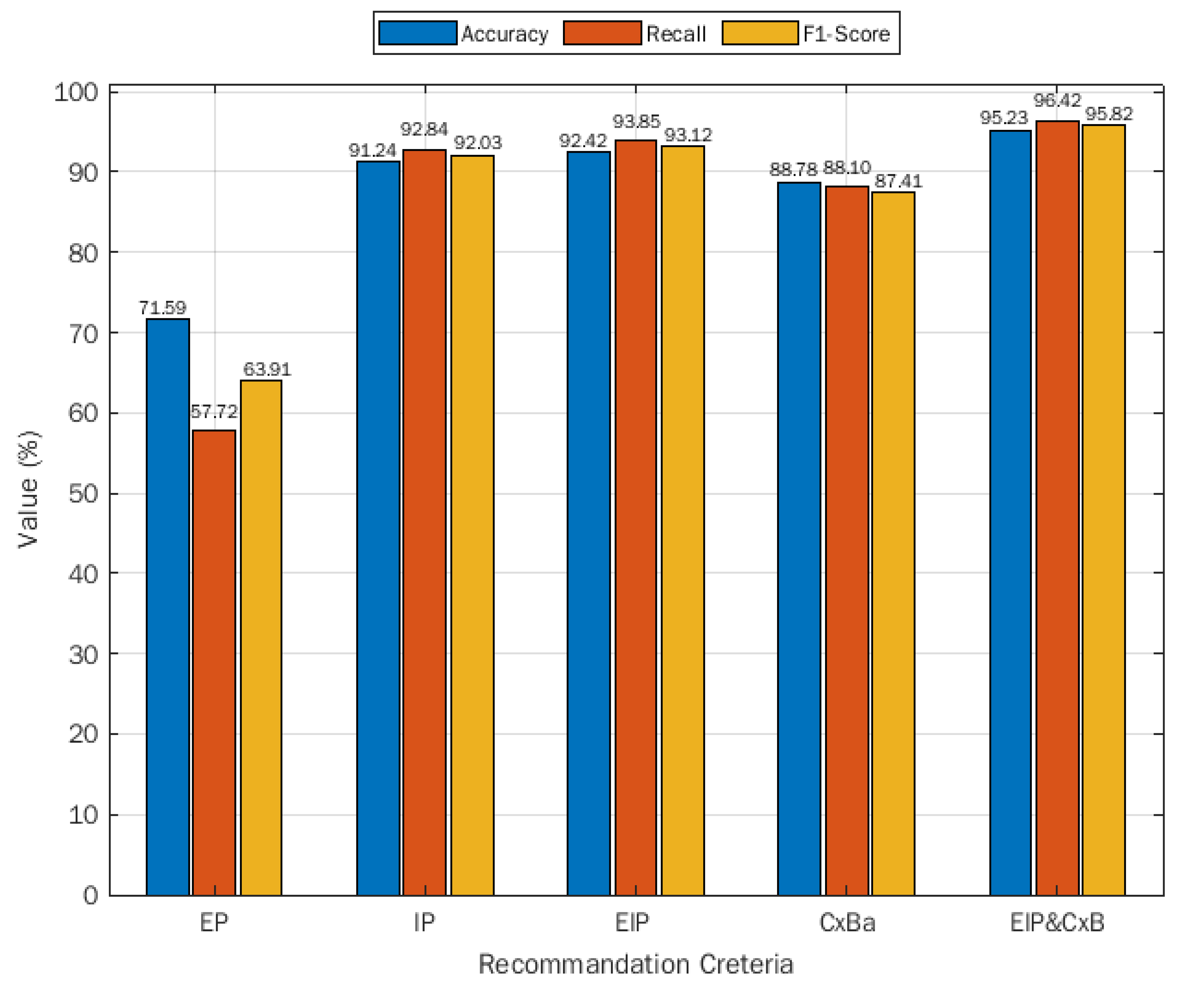
- Among the four recommendation criteria, the proposed approach-using user’s implicit and explicit preferences, user’s history, user’s current situation gives highest accuracy for rule item recommendation. However, explicit preference-based approach gives lowest accuracy.
- In addition, the proposed approach shows highest level of performance with 100% smart domains covered under the different user’s domains (security, demotic, health, study, work, tourism and shopping). The explicit preference-based approach shows lowest area covered under poor user-specified preferences.
- Among the four approaches, explicit preference-based approach presents the fastest algorithm for rule item recommendation with the highest prediction speed and lowest training time. However, the proposed approach presents best recommendation approach with the highest accuracy and recall rates and acceptable execution time.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, J.; Gubbi, J.; Marusic, S.; Palaniswami, M.S. An Information Framework for Creating a Smart City Through Internet of Things. IEEE Internet Things J. 2014, 1, 112–121. [Google Scholar] [CrossRef]
- Khan, M.; Silva, B.N.; Han, K. Internet of Things Based Energy Aware Smart Home Control System. IEEE Access 2016, 4, 7556–7566. [Google Scholar] [CrossRef]
- Lakehal, A.; Alti, A.; Laborie, S.; Philippe, R. Ontology-based Context-aware Recommendation Approach for Dynamic Situations Enrichment. In Proceedings of the 2018 13th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Zaragoza, Spain, 6–7 September 2018; pp. 81–86. [Google Scholar]
- Tekli, J.; Chbeir, R.; Traina, A.J.; Traina, C., Jr.; Yetongnon, K.; Ibanez, C.R.; Kallas, C. Full-fledged semantic indexing and querying model designed for seamless integration in legacy RDBMS. Data Knowl. Eng. 2018, 117, 133–173. [Google Scholar] [CrossRef] [Green Version]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Tkalčič, M.; Burnik, U.; Košir, A. Using affective parameters in a content-based recommender system for images. User Model. User-Adapted Interact. 2010, 20, 279–311. [Google Scholar] [CrossRef]
- Deldjoo, Y.; Elahi, M.; Cremonesi, P.; Garzotto, F.; Piazzolla, P.; Quadrana, M. Content-based video recommendation system based on stylistic visual features. J. Data Semant. 2016, 5, 99–113. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Liang, Y.; Xu, D.; Feng, X.; Guan, R. A content-based recommender system for computer science publications. Knowl.-Based Syst. 2018, 157, 1–9. [Google Scholar] [CrossRef]
- Chen, B.; He, H.; Guo, J. Constructing Maximum Entropy Language Models for Movie Review Subjectivity Analysis. J. Comput. Sci. Technol. 2008, 23, 231–239. [Google Scholar] [CrossRef]
- Jin, C.; Ma, T.; Hou, R.; Tang, M.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. Chi-square Statistics Feature Selection Based on Term Frequency and Distribution for Text Categorization. IETE J. Res. 2015, 61, 351–362. [Google Scholar] [CrossRef]
- Zhang, D. An Item-based Collaborative Filtering Recommendation Algorithm Using Slope One Scheme Smoothing. In Proceedings of the 2009 Second International Symposium on Electronic Commerce and Security, Nanchang, China, 22–24 May 2009; Volume 2, pp. 215–217. [Google Scholar]
- Hernando, A.; Bobadilla, J.; Ortega, F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowl.-Based Syst. 2016, 97, 188–202. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval; Association for Computing Machinery (ACM), Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 217–253. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’13, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Zhou, G.; Zhang, S.; Fan, Y.; Li, J.; Yao, W.; Liu, H. Recommendations based on user effective point-of-interest path. Int. J. Mach. Learn. Cybern. 2019, 10, 2887–2899. [Google Scholar] [CrossRef]
- Hong, L.; Zou, L.; Zeng, C.; Zhang, L.; Wang, J.; Tian, J. Context-Aware Recommendation Using Role-Based Trust Network. ACM Trans. Knowl. Discov. Data 2015, 10, 1–25. [Google Scholar] [CrossRef]
- Seo, Y.-D.; Kim, Y.-G.; Lee, E.; Baik, D.-K. Personalized recommender system based on friendship strength in social network services. Expert Syst. Appl. 2017, 69, 135–148. [Google Scholar] [CrossRef]
- Horrocks, I.; Patel-Schneider, F.; Boley, H.; Grosof, S.T.B.; Dean, M. SWRL: A Semantic Web Rule Language Combining OWL and RuleML. Available online: www.w3.org/Submission/SWRL (accessed on 17 July 2019).
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Soboroff, I.; Nicholas, C. Combining content and collaboration in text filtering. Proc. IJCAI 1999, 99, 86–91. [Google Scholar]
- Yu, Z.; Zhou, X.; Zhang, D.; Chin, C.-Y.; Wang, X.; Men, J. Supporting context-aware media recommendations for smartphones. IEEE Pervasive Comput. 2006, 5, 68–75. [Google Scholar]
- Nilashi, M.; Ibrahim, O.; Ithnin, A.P.D.N.; Sarmin, N.H. A multi-criteria collaborative filtering recommender system for the tourism domain using Expectation Maximization (EM) and PCA–ANFIS. Electron. Commer. Res. Appl. 2015, 14, 542–562. [Google Scholar] [CrossRef]
- Suria, S.; Palanivel, K. An enhanced web service recommendation system with ranking QoS information. Int. J. Emerg. Trends Technol. Comput. Sci. (IJETTCS) 2015, 4, 116–121. [Google Scholar]
- Zhong, Y.; Fan, Y.; Huang, K.; Tan, W.; Zhang, J. Time-Aware Service Recommendation for Mashup Creation in an Evolving Service Ecosystem. In Proceedings of the 2014 IEEE International Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 25–32. [Google Scholar]
- Wen, W.; Miao, H. Context-Based Service Recommendation System Using Probability Model in Mobile Devices. In Proceedings of the 2016 4th International Conference on Enterprise Systems (ES), Melbourne, VIC, Australia, 2–3 November 2016; pp. 178–182. [Google Scholar]
- Karchoud, R.; Roose, P.; Dalmau, M.; Illarramendi, A.; Ilarri, S. All for One and One for All: Dynamic Injection of Situations in a Generic Context-Aware Application. Procedia Comput. Sci. 2017, 113, 17–24. [Google Scholar] [CrossRef]
- Lakehal, A.; Alti, A.; Roose, P. Context-Aware Multi-layered Ontology for Composite Situation Model in Pervasive Computing. Ingénierie Systèmes Inf. 2020, 25, 543–558. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filtering Approaches | Accuracy | Online Learning | Dataset | Scalability | Adaptation | Flexibility | ||
|---|---|---|---|---|---|---|---|---|
| Content-based | [6] | 63.00% | ✗ | images | ✗ | ✗ | ✗ | |
| [7] | 70.50% | ✗ | Movies | ✗ | ✗ | ✗ | ||
| [8] | 72.30% | ✗ | Sc. papers | ✗ | ✗ | ✗ | ||
| Collaborative-based | [11] | 80.70% | ✗ | Movies | ✓ | Partial | ✗ | |
| [12] | 84.60% | ✗ | Netflix | ✓ | Partial | ✗ | ||
| [13] | 84.60% 97.30% | ✗ | Gowalla Book | ✓ | Partial | ✗ | ||
| Hybrid-based | [21] | 83.50% | ✗ | Movies | ✓ | Partial | ✗ | |
| [22] | 80.00% | ✗ | Movies | ✓ | ✓ | Partial | ||
| Context-aware | Trust-aware | [18] | 87.84% | ✗ | Services | ✓ | ✓ | Partial |
| Location-aware | [24] | 64.50% | ✗ | Services | ✓ | ✗ | Partial | |
| Time-aware | [25] | 43.40% | ✗ | Services | ✓ | ✗ | Partial | |
| Spatiotemporal-aware | [15] | 51.00% | ✗ | Foursquare | ✓ | ✗ | Partial | |
| Role-based | [17] | 63.50% | ✗ | Epinions | ✓ | ✗ | Partial | |
| Environment-aware | [28] | - | ✗ | Tourism | ✓ | ✓ | ✓ | |
| Mobile-aware | [26] | - | ✗ | Tourism | ✓ | ✓ | Partial | |
| Field | Rule Item | SIMEP | SIMIP | SIMs | Score |
|---|---|---|---|---|---|
| Study | Study_Home_Evening | 0.8165 | 0.8135 | 0.7291 | 0.7892 |
| Study_Home_Weekend | 0.8165 | 0.8135 | 0.6188 | 0.7561 | |
| Domotics | Adjuste_Water_Temperature | 0.8165 | 0.8135 | 0.8184 | 0.8160 |
| Morning_Preparation | 0.8165 | 0.8135 | 0.8184 | 0.8160 | |
| Morining_Turn_Light_Kitchen | 0.8165 | 0.8135 | 0.8184 | 0.8160 | |
| Enter_Bathroom_Light_On | 0.8165 | 0.8135 | 0.8184 | 0.8160 | |
| Wake_Up_All_Wakes_Up | 0.8165 | 0.8135 | 0.8184 | 0.8160 | |
| Leave_Bathroom_Light_Off | 0.8165 | 0.8135 | 0.8465 | 0.8244 | |
| Showing_Light_Color_Blue | 0.8165 | 0.8135 | 0.8465 | 0.8244 | |
| Security | House_Fire_Alarm | 0.8165 | 0.8135 | 0.7326 | 0.7902 |
| Home_Intrusion_Alarm | 0.8165 | 0.8135 | 0.6548 | 0.7669 | |
| Home_Room_Unlocking | 0.8165 | 0.8135 | 0.6231 | 0.7574 | |
| Security_Control_Door | 0.8165 | 0.8135 | 0.7326 | 0.7902 | |
| Night_Garage_Close | 0.8165 | 0.8135 | 0.5551 | 0.7370 |
| Field | Rule Item | SIMEP | SIMIP | SIMs | Score |
|---|---|---|---|---|---|
| Driving | Path_Route | 0.4165 | 0.2235 | 0.5996 | 0.4038 |
| Car_Map_Weekday | 0.4165 | 0.2235 | 0.3528 | 0.3298 | |
| Shopping | Shop_Al_Othaim_Market | 0.4165 | 0.2235 | 0.4898 | 0.3709 |
| Shop_Al_Basem_Shop | 0.4165 | 0.2235 | 0.4831 | 0.3689 | |
| Shoping_Order_Google_Calendar | 0.4165 | 0.2235 | 0.4048 | 0.3454 | |
| Shop_Open_Send_Email | 0.4165 | 0.2235 | 0.3072 | 0.3161 |
| Field | Rule Item | SIMEP | SIMIP | SIMs | Score |
|---|---|---|---|---|---|
| Work | Plugged_Device_Battery_Low | 0.8660 | 0.4780 | 0.2955 | 0.5590 |
| Meeting_Office | 0.8660 | 0.4780 | 0.2899 | 0.5573 | |
| Office_High_Glucose_Inject_Insulin | 0.8660 | 0.4780 | 0.2610 | 0.5487 | |
| Work_Leave_Light_Off | 0.8660 | 0.4780 | 0.2610 | 0.5487 | |
| Save_Documents_After_Working_Time | 0.8660 | 0.4780 | 0.2351 | 0.5409 | |
| Mute_Phone_Enter_Work | 0.8660 | 0.4780 | 0.1117 | 0.5039 | |
| Security | Turn_Camera_On_Leave_Office | 0.8660 | 0.4780 | 0.1619 | 0.5189 |
| Office_Surveillance | 0.8660 | 0.4780 | 0.1241 | 0.5076 |
| Configurations | Smart Domain | Fields | Day | Time |
|---|---|---|---|---|
| Configuration#1 | Home | Study: 0.33 Domotics: 0.33 Security: 0.33 | Weekday: 0.33 Weekend: 0.67 | Weekday: 0.33 Weekend: 0.67 |
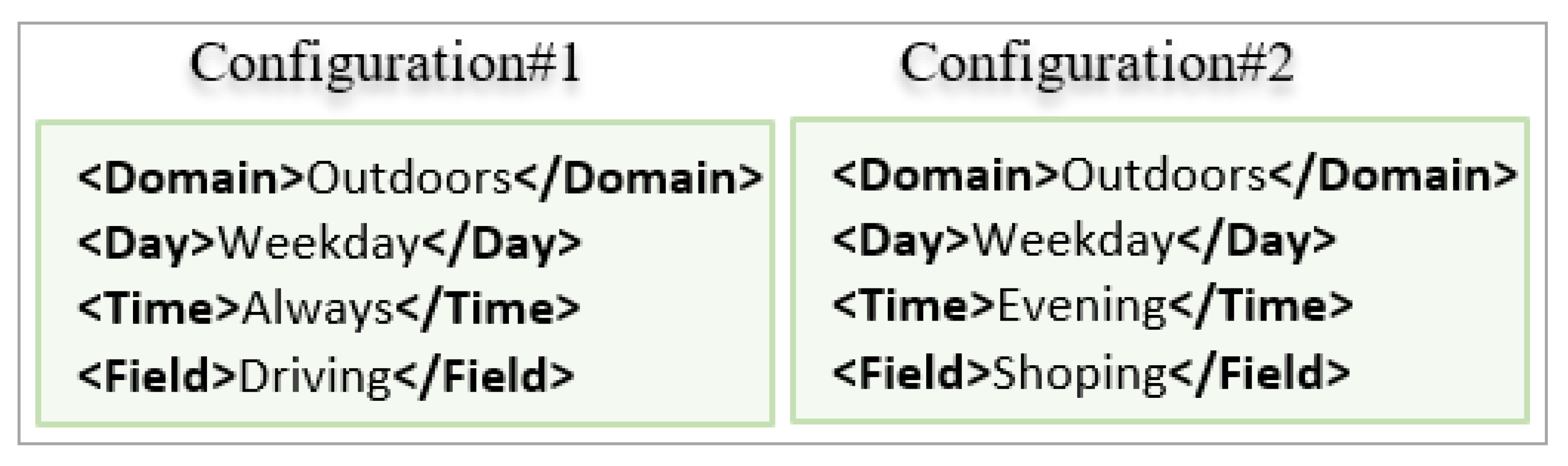
| Configuration#2 | Outdoors | Driving: 0.5 Shoping: 0.5 | Weekday: 1 | Weekday: 1 |
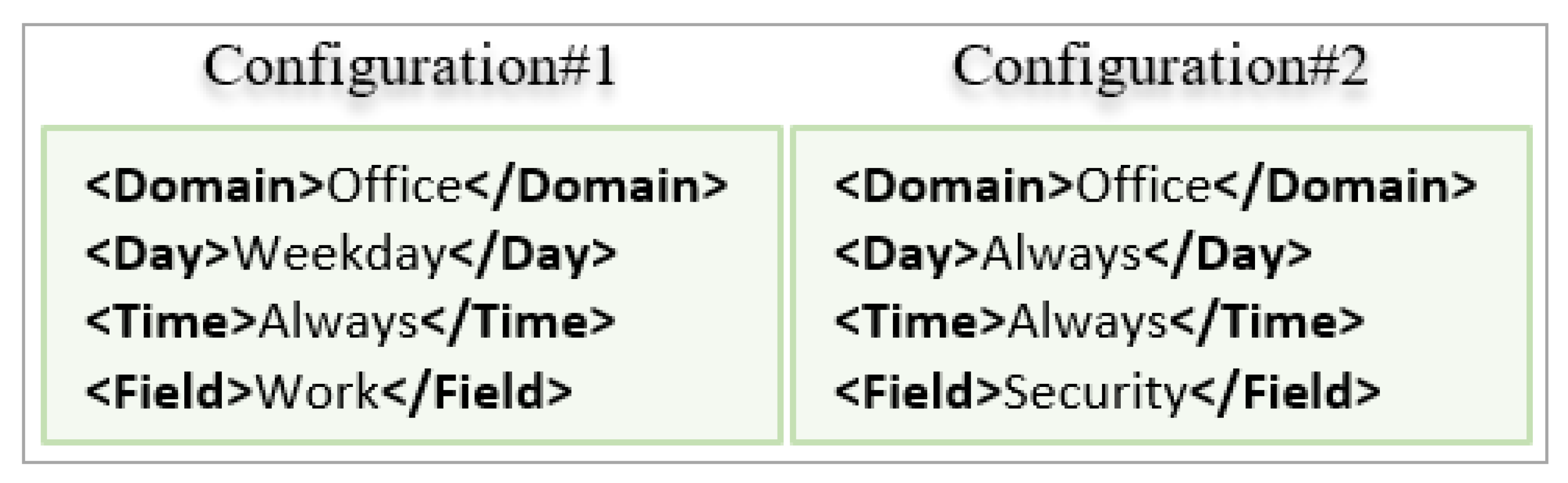
| Configuration#3 | Office | Work: 0.5 Security: 0.5 | Weekday: 1 | Weekday: 1 |
| Parameter | Size |
|---|---|
| Number of situations rules items | 100 |
| Number of daily activities | 80 |
| Number of health and security rules | 20 |
| Number of profiles configurations | 3 |
| Number of available devices | 10–1000 |
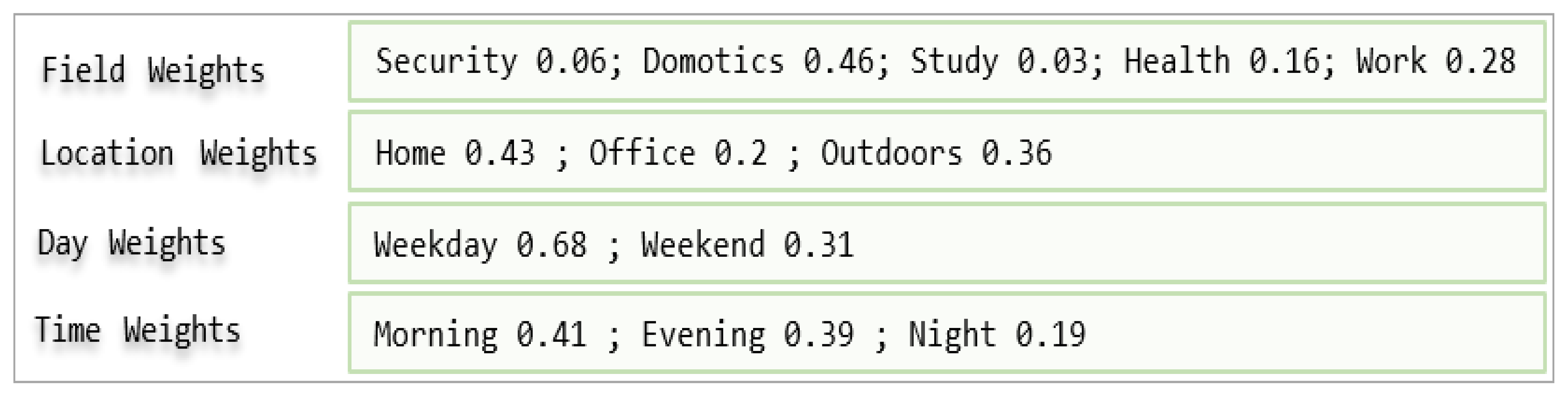
| Weights Explicit Preference (WEP) | 0.35 |
| Weights Implicit Preference (WIP) | 0.35 |
| Weights Naive Bayes (WS) | 0.30 |
| Classifier | Accuracy | Recall |
|---|---|---|
| KNN | 92.06% | 93.25% |
| DT | 80.95% | 86.39% |
| SVM | 87.30% | 86.39% |
| Proposed approach | 95.23% | 95.82% |
| Criteria | Number of Mobile Devices | ||
|---|---|---|---|
| 10 | 50 | 100 | |
| Explicit Preferences | 29.40 | 33.02 | 46.05 |
| Implicit Preferences (item content) | 25.20 | 36.74 | 61.18 |
| Explicit and Implicit Preferences | 42.32 | 51.37 | 84.19 |
| Contextual Bayesian (context situation) | 148.56 | 153.08 | 193.27 |
| Preferences and Contextual Bayesian | 177.04 | 182.24 | 245.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lakehal, A.; Alti, A.; Roose, P. Novel Semantic-Based Probabilistic Context Aware Approach for Situations Enrichment and Adaptation. Appl. Sci. 2022, 12, 732. https://doi.org/10.3390/app12020732
Lakehal A, Alti A, Roose P. Novel Semantic-Based Probabilistic Context Aware Approach for Situations Enrichment and Adaptation. Applied Sciences. 2022; 12(2):732. https://doi.org/10.3390/app12020732
Chicago/Turabian StyleLakehal, Abderrahim, Adel Alti, and Philippe Roose. 2022. "Novel Semantic-Based Probabilistic Context Aware Approach for Situations Enrichment and Adaptation" Applied Sciences 12, no. 2: 732. https://doi.org/10.3390/app12020732
APA StyleLakehal, A., Alti, A., & Roose, P. (2022). Novel Semantic-Based Probabilistic Context Aware Approach for Situations Enrichment and Adaptation. Applied Sciences, 12(2), 732. https://doi.org/10.3390/app12020732