
Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents



Abstract
:1. Introduction
- (1)
- To employ six traditional ML methods: naïve Bayes (NB), logistic regression (LR), k-nearest neighbour (k-NN), AdaBoost, support vector machine (SVM), and random forest (RF) on a real-life dataset containing primary and secondary RTA features. The main reasons for using these specific ML classifiers are their unique characteristics and their popularity in the literature;
- (2)
- To include dimensionality reduction techniques, principal component analysis (PCA) and linear discriminant analysis (LDA) were utilised to identify the relationship between the RTA variables to improve the performance of the proposed models. The study further implemented various missing data methods such as the mean, median, k-NN, and multiple imputations by chained equations (MICE) to handle missing values in the RTA dataset;
- (3)
- To further use well-established evaluation metrics such as accuracy, root-mean-square error (RMSE), precision, recall, and the area under the receiver operating characteristic (ROC) curve (also referred to as the AUC—the area under the ROC) to evaluate the performance of the classification models.
2. Literature Review
2.1. Classification
2.2. Related Studies
3. Methodology
3.1. Machine Learning Classifiers
3.1.1. Naïve Bayes
3.1.2. Logistic Regression
3.1.3. k-Nearest Neighbour
3.1.4. AdaBoost
3.1.5. Random Forest
3.1.6. Support Vector Machine
3.2. Missing Data Strategies
3.2.1. Mean and Median
3.2.2. k-Nearest Neighbour
3.2.3. Multiple Imputations by Chained Equations (MICE)
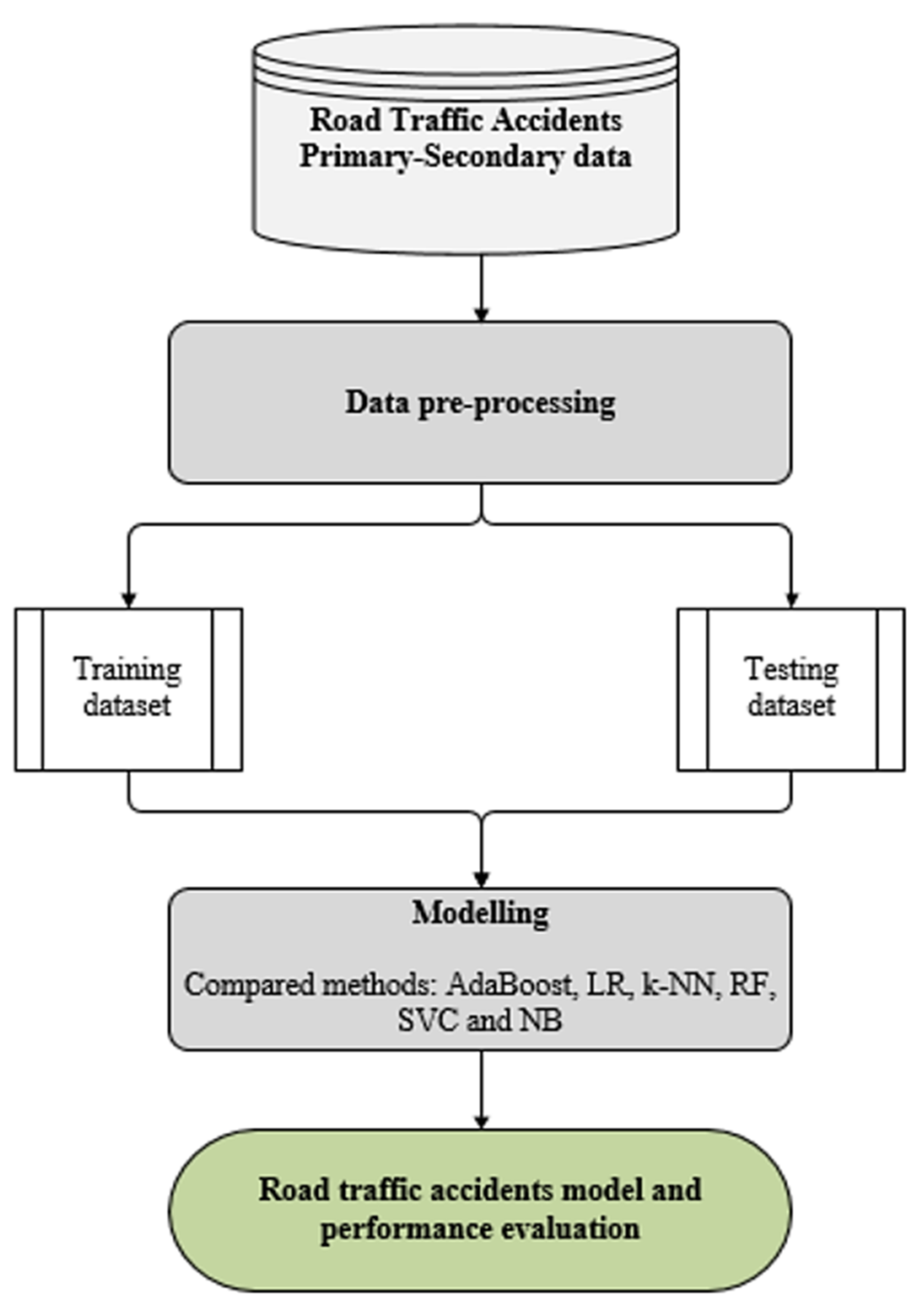
3.3. Experimental Setup
RTA Experimental Process
3.4. Dataset and Statistical Analysis
RTA Dataset
3.5. Model Evaluation
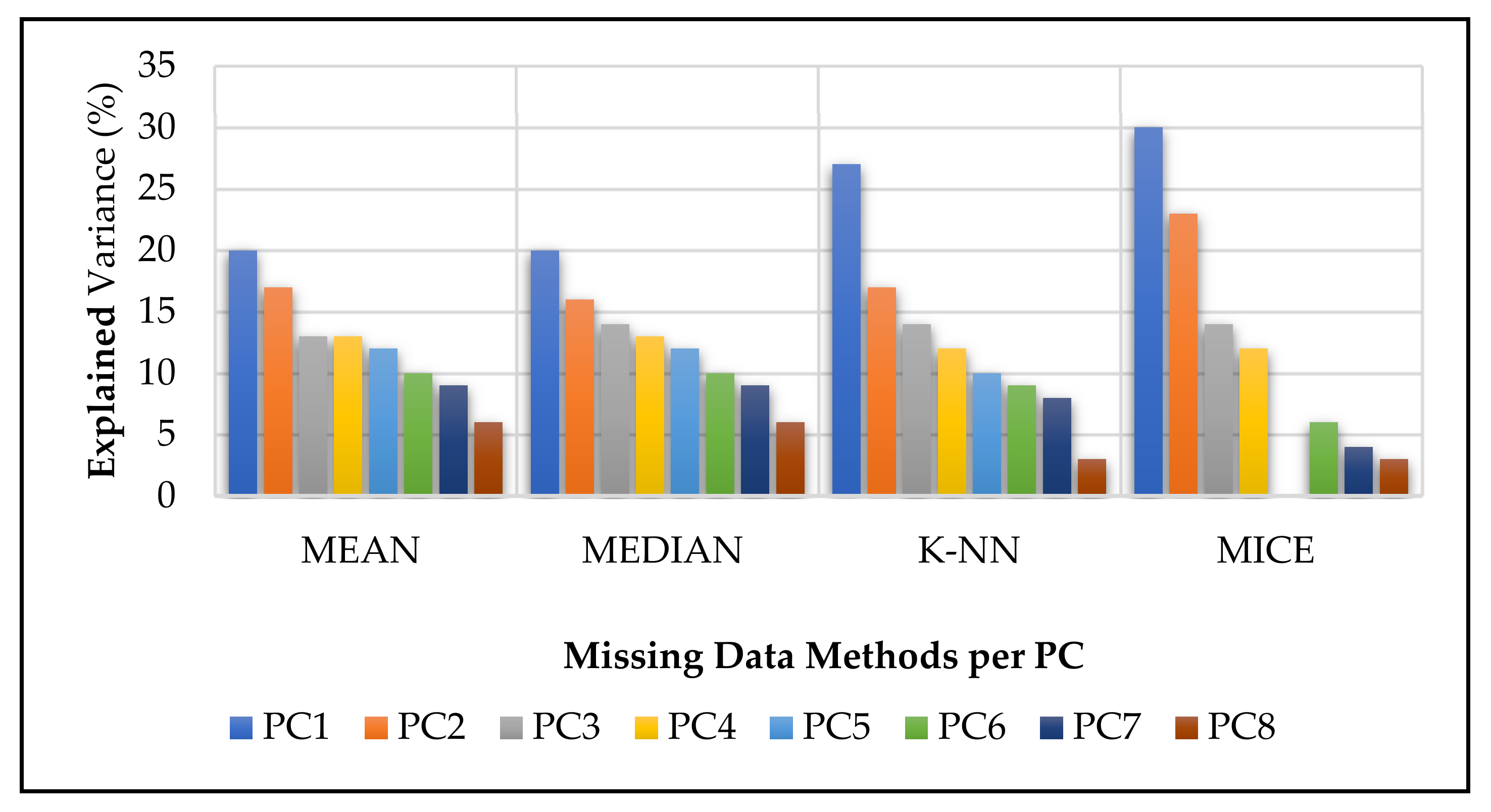
4. Dimensionality Reduction
- (1)
- Mean missing data method: PC1—20%, PC2—17%, and PC3—13%, which explained 50% of the overall dataset;
- (2)
- Median method: PC1—20%, PC2—16%, and PC3—14%, which explained 50%;
- (3)
- k-NN method: PC1—27%, PC2—17%, and PC3—14%, which explained 58%;
- (4)
- MICE method: PC1—30%, PC2—23%, and PC3—14%, which explained 67% (of the overall dataset).


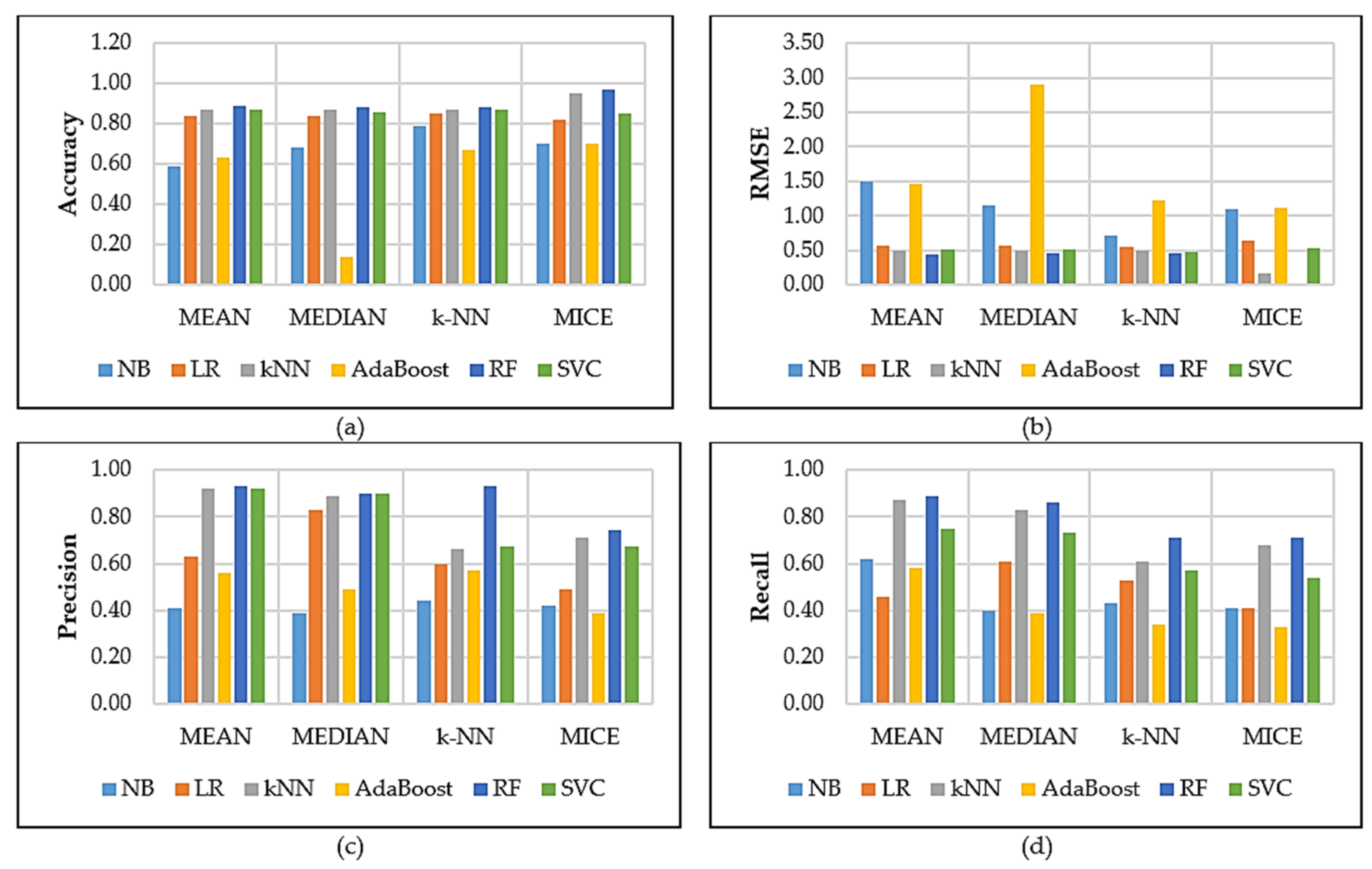
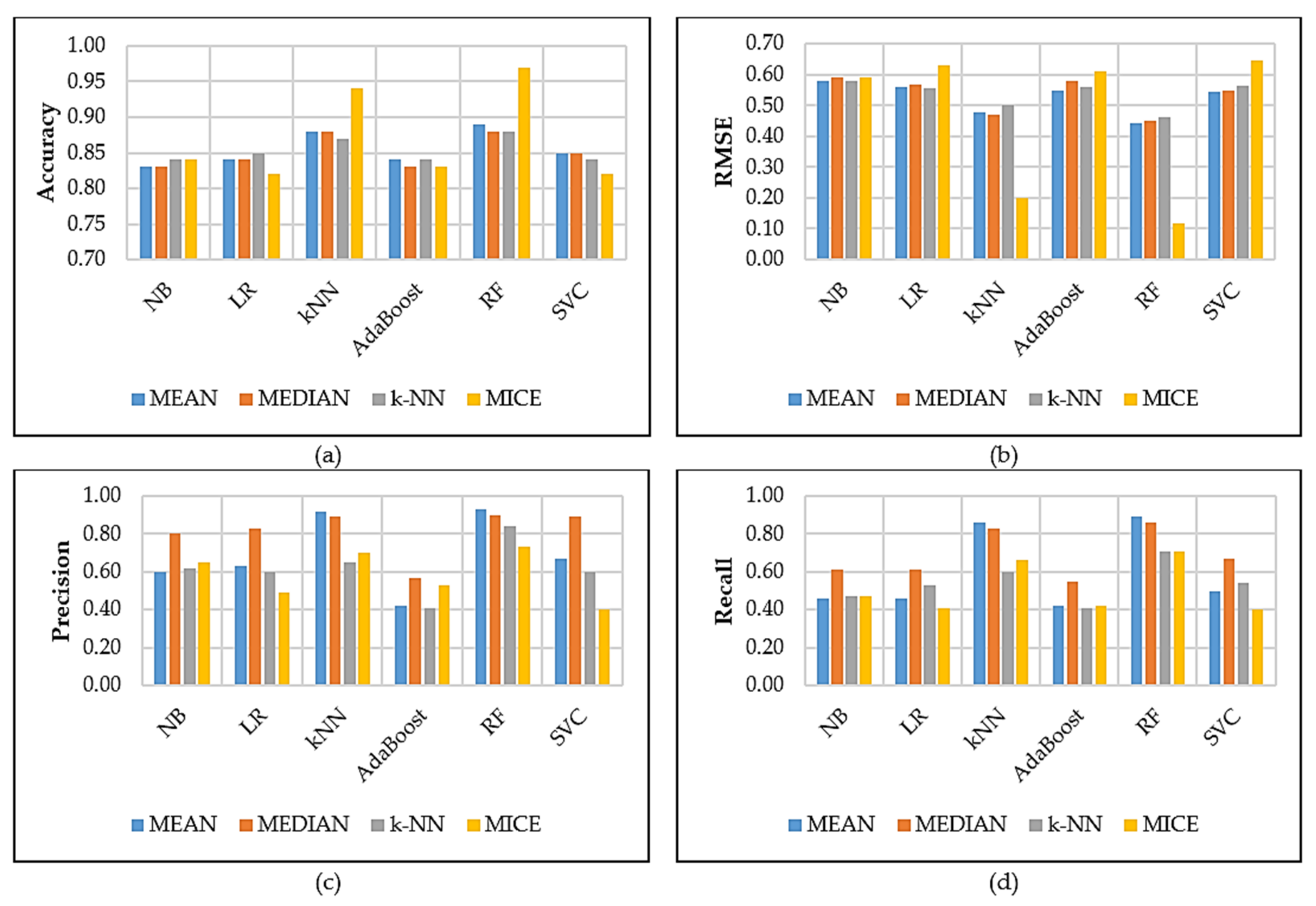
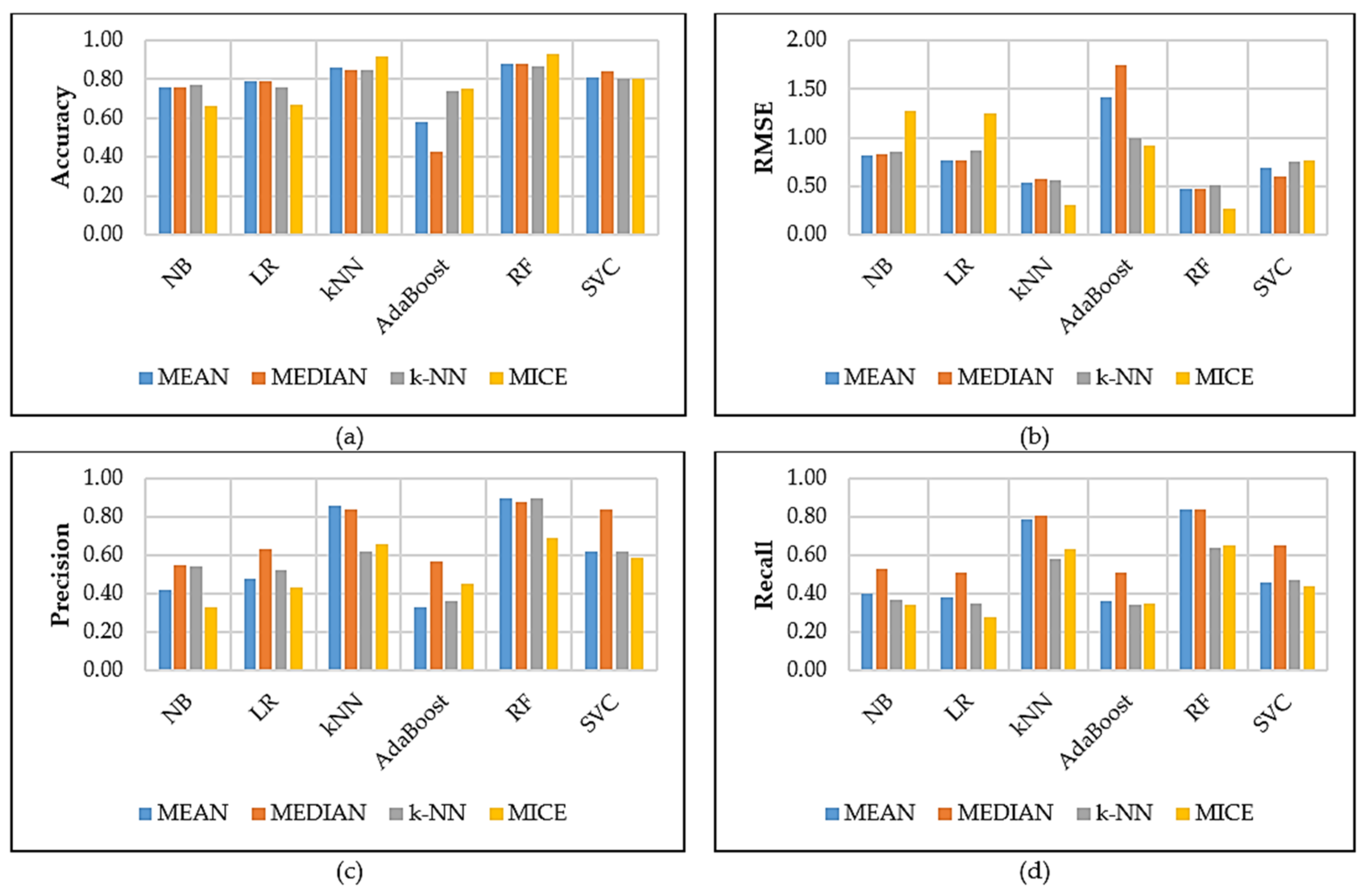
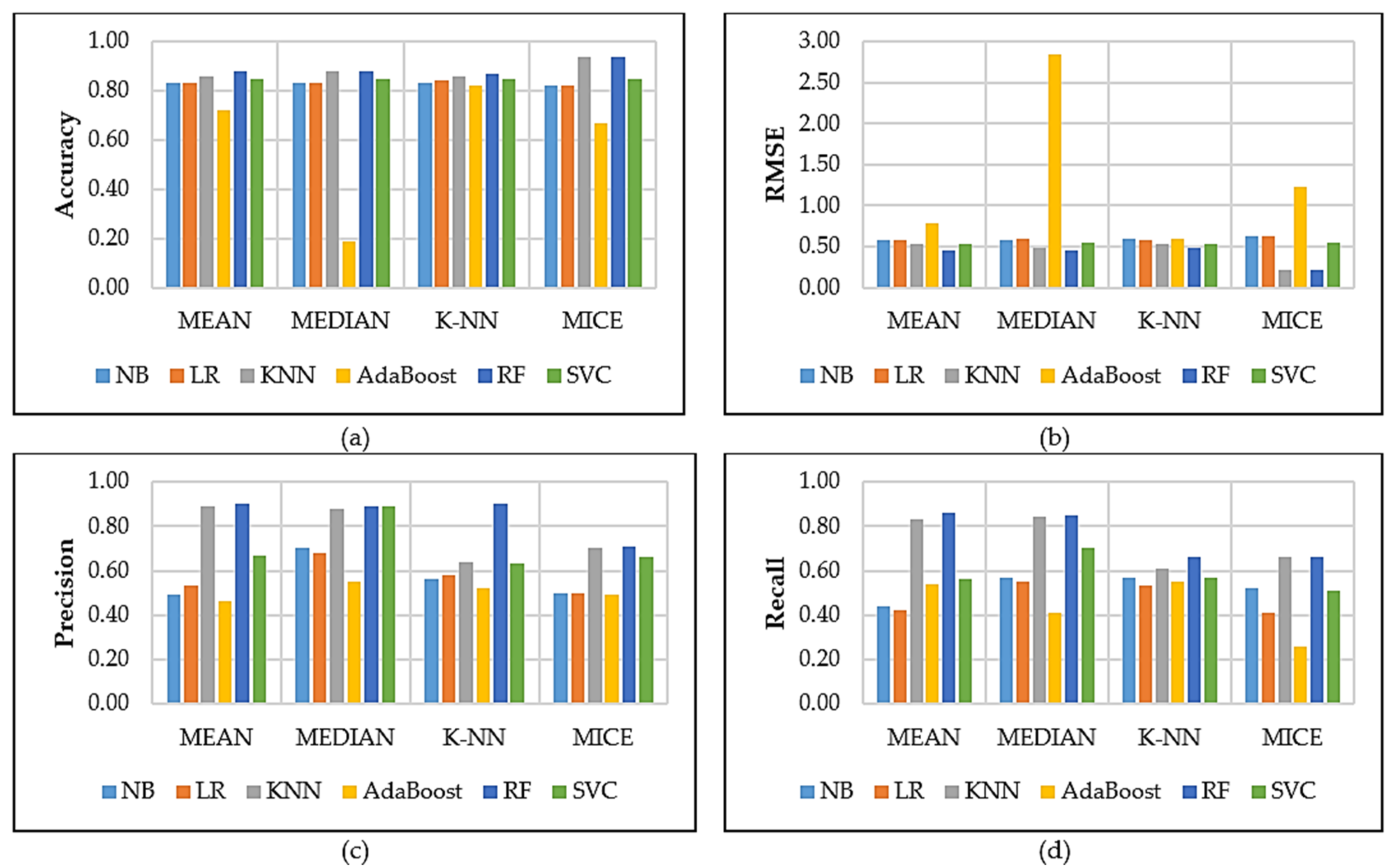
5. Results and Discussion
5.1. Comparison Results
5.2. ROC Curve (AUC)
6. Conclusions
- (1)
- Statistical analysis included two-dimensionality reduction methods, with LDA obtaining promising results compared with PCA. In terms of missing data methods, MICE achieved good results;
- (2)
- A wide range of ML methods was applied due to their popularity and characteristics. It was observed from the empirical analysis that RF performed best when compared with the rest;
- (3)
- Furthermore, the AUC evaluation method was introduced to validate the classification results once the evaluation performance was assessed using accuracy, precision, and recall.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Economic Forum. The Number of Cars Worldwide Is Set to Double by 2040. 2016. Available online: https://www.weforum.org/agenda/2016/04/the-number-of-cars-worldwide-is-set-to-double-by-2040 (accessed on 8 February 2021).
- World Health Organisation. Global Status Report on Road Safety. 2015. Available online: https://www.who.int/violence_injury_prevention/road_safety_status/2015/en/ (accessed on 25 January 2021).
- World Health Organisation. Global Status Report on Road Safety. 2018. Available online: https://www.who.int/violence_injury_prevention/road_safety_status/2018/en/ (accessed on 25 January 2021).
- National Institute of Statistics and Economic Studies (INSEE). Road Accidents. 2020. Available online: https://www.insee.fr/en/metadonnees/definition/c1116 (accessed on 25 January 2021).
- Wesson, H.K.; Boikhutso, N.; Hyder, A.A.; Bertram, M.; Hofman, K.J. Informing road traffic intervention choices in South Africa: The role of economic evaluations. Global Health Action. 2016, 9, 30728. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Liu, B.; Fu, T.; Liu, S.; Stipancic, J. Modelling when and where a secondary accident occurs. Accid. Anal. Prev. 2019, 130, 160–166. [Google Scholar] [CrossRef]
- World Health Organisation. Global Status Report on Road Safety. 2019. Available online: https://www.who.int/violence_injury_prevention/road_safety_status/2019/en/ (accessed on 8 January 2021).
- Makaba, T.; Gatsheni, B. A decade bibliometric review of road traffic accidents and incidents: A computational perspective. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; IEEE: New York, NY, USA, 2019; pp. 510–516. [Google Scholar]
- Sánchez González, S.; Bedoya-Maya, F.; Calatayud, A. Understanding the Effect of Traffic Congestion on Accidents Using Big Data. Sustainability 2021, 13, 7500. [Google Scholar] [CrossRef]
- Zhang, H.; Khattak, A. What is the role of multiple secondary incidents in traffic operations? J. Transp. Eng. 2010, 136, 986–997. [Google Scholar] [CrossRef] [Green Version]
- Zhan, C.; Shen, L.; Hadi, M.A.; Gan, A. Understanding the Characteristics of Secondary Crashes on Freeways; No. 08-1835; Transportation Research Board: Washington, DC, USA, 2008. [Google Scholar]
- Ramageri, B.M. Data mining techniques and applications. Indian J. Comput. Sci. Eng. 2010, 1, 301–305. [Google Scholar]
- Li, L.; Shrestha, S.; Hu, G. Analysis of road traffic fatal accidents using data mining techniques. In Proceedings of the 2017 IEEE 15th International Conference on Software Engineering Research, Management and Applications (SERA), London, UK, 7–9 June 2017; IEEE: New York, NY, USA, 2017; pp. 363–370. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Expert AI. What Is Machine Learning? A Definition. 2020. Available online: https://www.expert.ai/blog/machine-learning-definition/ (accessed on 20 March 2021).
- Costanza, R.; Daly, L.; Fioramonti, L.; Giovannini, E.; Kubiszewski, I.; Mortensen, L.F.; Pickett, K.E.; Ragnarsdottir, K.V.; De Vogli, R.; Wilkinson, R. Modelling and measuring sustainable wellbeing in connection with the UN Sustainable Development Goals. Ecol. Econ. 2016, 130, 350–355. [Google Scholar] [CrossRef]
- Sachs, J.D.; Kroll, C.; Lafortune, G.; Fuller, G.; Woelm, F. Sustainable Development Report: The Decade of Action for the Sustainable Development Goals. 2021. Available online: https://s3.amazonaws.com/sustainabledevelopment.report/2021/2021-sustainable-development-report.pdf (accessed on 21 March 2021).
- Asiri, S. Machine Learning Classification, towards Data Science. 2018. Available online: https://towardsdatascience.com/machine-learning-classifiers-a5cc4e1b0623 (accessed on 20 December 2020).
- Waseem, M. How to Implement Classification in Machine Learning, Data Science with Python. 2021. Available online: https://www.edureka.co/blog/classification-in-machine-learning/#classification (accessed on 5 April 2021).
- Sarangam, A. Classification in Machine Learning: A Comprehensive Guide, Jigsaw. 2021. Available online: https://www.jigsawacademy.com/blogs/ai-ml/classification-in-machine-learning (accessed on 8 August 2021).
- Priyanka, A.; Sathiyakumari, K. A comparative study of classification algorithm using accident data. Int. J. Comput. Sci. Eng. Technol. 2014, 5, 1018–1023. [Google Scholar]
- AlMamlook, R.E.; Kwayu, K.M.; Alkasisbeh, M.R.; Frefer, A.A. Comparison of machine learning algorithms for predicting traffic accident severity. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; IEEE: New York, NY, USA, 2019; pp. 272–276. [Google Scholar]
- Labib, M.F.; Rifat, A.S.; Hossain, M.M.; Das, A.K.; Nawrine, F. Road accident analysis and prediction of accident severity by using machine learning in Bangladesh. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Miri, Malaysia, 28–30 June 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Lee, J.; Yoon, T.; Kwon, S.; Lee, J. Model evaluation for forecasting traffic accident severity in rainy seasons using machine learning algorithms: Seoul City study. Appl. Sci. 2020, 10, 129. [Google Scholar] [CrossRef] [Green Version]
- Ijaz, M.; Zahid, M.; Jamal, A. A comparative study of machine learning classifiers for injury severity prediction of crashes involving three-wheeled motorised rickshaw. Accid. Anal. Prev. 2021, 154, 106094. [Google Scholar] [CrossRef] [PubMed]
- Sangare, M.; Gupta, S.; Bouzefrane, S.; Banerjee, S.; Muhlethaler, P. Exploring the forecasting approach for road accidents: Analytical measures with hybrid machine learning. Expert Syst. Appl. 2021, 167, 113855. [Google Scholar] [CrossRef]
- Zong, F.; Xu, H.; Zhang, H. Prediction for traffic accident severity: Comparing the Bayesian network and regression models. Math. Probl. Eng. 2013, 2013, 475194. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Haghani, A. Real-time prediction of secondary incident occurrences using vehicle probe data. Transportation Research Part C Emerg. Technol. 2016, 70, 69–85. [Google Scholar] [CrossRef]
- Bahiru, T.K.; Singh, D.K.; Tessfaw, E.A. Comparative study on data mining classification algorithms for predicting road traffic accident severity. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; IEEE: New York, NY, USA, 2018; pp. 1655–1660. [Google Scholar]
- Kumeda, B.; Zhang, F.; Zhou, F.; Hussain, S.; Almasri, A.; Assefa, M. Classification of road traffic accident data using machine learning algorithms. In Proceedings of the 2019 IEEE 11th International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 12–15 June 2019; IEEE: New York, NY, USA, 2019; pp. 682–687. [Google Scholar]
- Jha, A.N.; Chatterjee, N.; Tiwari, G. A performance analysis of prediction techniques for impacting vehicles in hit-and-run road accidents. Accid. Anal. Prev. 2021, 157, 106164. [Google Scholar] [CrossRef] [PubMed]
- Valenti, G.; Lelli, M.; Cucina, D. A comparative study of models for the incident duration prediction. Eur. Transp. Res. Rev. 2010, 2, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Vlahogianni, E.I.; Karlaftis, M.G.; Orfanou, F.P. Modelling the effects of weather and traffic on the risk of secondary incidents. J. Intell. Transp. Syst. 2012, 16, 109–117. [Google Scholar] [CrossRef]
- Dogru, N.; Subasi, A. Traffic accident detection using random forest classifier. In Proceedings of the 2018 15th learning and technology conference (L&T), Jeddah, Saudi Arabia, 26–28 February 2018; IEEE: New York, NY, USA, 2018; pp. 40–45. [Google Scholar]
- Makaba, T.; Doorsamy, W.; Paul, B.S. Exploratory framework for analysing road traffic accident data with validation on Gauteng province data. Cogent Eng. 2020, 7, 1834659. [Google Scholar] [CrossRef]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.C.; Manzoni, P. Modeling and characterisation of traffic flows in urban environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef] [Green Version]
- Makaba, T.; Doorsamy, W.; Paul, B.S. Bayesian Network-Based Framework for Cost-Implication Assessment of Road Traffic Collisions. Int. J. Intell. Transp. Syst. Res. 2021, 19, 240–253. [Google Scholar] [CrossRef]
- Mir, Z.H.; Filali, F. An adaptive Kalman filter based traffic prediction algorithm for urban road network. In Proceedings of the 2016 12th International Conference on Innovations in Information Technology, Al-Ain, United Arab Emirates, 28–30 November 2016; IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Budiawan, W.; Saptadi, S.; Tjioe, C.; Phommachak, T. Traffic accident severity prediction using Naive Bayes algorithm—A case study of Semarang Toll Road. IOP Conf. Ser. Mater. Sci. Eng. 2019, 598, 012089. [Google Scholar] [CrossRef]
- Kim, D.; Jung, S.; Yoon, S. Risk Prediction for Winter Road Accidents on Expressways. Appl. Sci. 2021, 11, 9534. [Google Scholar] [CrossRef]
- Li, P.; Abdel-Aty, M.; Yuan, J. Real-time crash risk prediction on arterials based on LSTM-CNN. Accid. Anal. Prev. 2020, 135, 105371. [Google Scholar] [CrossRef] [PubMed]
- Twala, B. Dancing with dirty road traffic accidents data: The case of Gauteng Province in South Africa. J. Transp. Saf. Secur. 2012, 4, 323–335. [Google Scholar] [CrossRef]
- Yu, H.; Ji, N.; Ren, Y.; Yang, C. A special event-based K-nearest neighbor model for short-term traffic state prediction. IEEE Access. 2019, 7, 81717–81729. [Google Scholar] [CrossRef]
- Zhang, X.; Waller, S.T.; Jiang, P. An ensemble machine learning-based modelling framework for analysis of traffic crash frequency. Comput. -Aided Civ. Infrastruct. Eng. 2020, 35, 258–276. [Google Scholar] [CrossRef]
- Chen, M.M.; Chen, M.C. Modelling road accident severity with Comparisons of Logistic Regression, Decision Tree and Random Forest. Information 2020, 11, 270. [Google Scholar] [CrossRef]
- Lin, Y.; Li, R. Real-time traffic accidents post-impact prediction: Based on crowdsourcing data. Accid. Anal. Prev. 2020, 145, 105696. [Google Scholar] [CrossRef] [PubMed]
- Parsa, A.B.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Real-time accident detection: Coping with imbalanced data. Accid. Anal. Prev. 2019, 129, 202–210. [Google Scholar] [CrossRef]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash injury severity analysis using a two-layer stacking framework. Accid. Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef] [PubMed]
- Makaba, T.; Dogo, E. A comparison of strategies for missing values in data on machine learning classification algorithms. In Proceedings of the 2019 International Multidisciplinary Information Technology and Engineering Conference (IMITEC), Vanderbijyl Park, South Africa, 21–22 November 2019; IEEE: New York, NY, USA, 2019; pp. 1–7. [Google Scholar]
- Liu, Y.; Brown, S.D. Comparison of five iterative imputation methods for multivariate classification. Chemom. Intell. Lab. Syst. 2013, 120, 106–115. [Google Scholar] [CrossRef]
- Chowdhury, K.R. KNN Imputer: A Robust Way to Impute Missing Values Using Scikit-Learn. 2020. Available online: https://www.analyticsvidhya.com/blog/2020/07/knnimputer-a-robust-way-to-impute-missing-values-using-scikit-learn/ (accessed on 22 December 2020).
- Mokoatle, M.; Marivate, V.; Bukohwo, M.E. Predicting road traffic accident severity using accident report data in South Africa. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai, United Arab Emirates, 18–20 June 2019; ACM: New York, NY, USA, 2019; pp. 11–17. [Google Scholar]
- Buuren, S.V.; Groothuis-Oudshoorn, K. Mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2010, 45, 1–68. [Google Scholar]
- Ramani, R.G.; Shanthi, S. Classifier prediction evaluation in modelling road traffic accident data. In Proceedings of the 2012 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2012; IEEE: New York, NY, USA, 2012; pp. 1–4. [Google Scholar]
- Gutierrez-Osorio, C.; Pedraza, C. Modern data sources and techniques for analysis and forecast of road accidents: A review. J. Traffic Transp. Eng. 2020, 7, 432–446. [Google Scholar] [CrossRef]
- Cigdem, A.; Ozden, C. Predicting the severity of motor vehicle accident injuries in Adana-turkey using machine learning methods and detailed meteorological data. Int. J. Intell. Syst. Appl. Eng. 2018, 6, 72–79. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Features | Data Type | Events |
|---|---|---|---|
| 1. | Primary Cause | Categorical | Major |
| 2. | Primary Sub Cause | Categorical | Minor |
| 3. | Secondary Cause | Categorical | Natural disaster |
| 4. | Wet Road | Categorical | None |
| 5. | No. of Travel Lanes | Numeric | Unknown |
| 6. | No. of Vehicles Involved | Numeric | - |
| 7. | Roadway Name | Categorical | - |
| 8. | Date Time | Date time | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bokaba, T.; Doorsamy, W.; Paul, B.S. Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents. Appl. Sci. 2022, 12, 828. https://doi.org/10.3390/app12020828
Bokaba T, Doorsamy W, Paul BS. Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents. Applied Sciences. 2022; 12(2):828. https://doi.org/10.3390/app12020828
Chicago/Turabian StyleBokaba, Tebogo, Wesley Doorsamy, and Babu Sena Paul. 2022. "Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents" Applied Sciences 12, no. 2: 828. https://doi.org/10.3390/app12020828
APA StyleBokaba, T., Doorsamy, W., & Paul, B. S. (2022). Comparative Study of Machine Learning Classifiers for Modelling Road Traffic Accidents. Applied Sciences, 12(2), 828. https://doi.org/10.3390/app12020828