



Bridge Node Detection between Communities Based on GNN

Abstract
:1. Introduction
- A deep learning-based framework named BND is proposed to detect bridge nodes, through which we can avoid expensive community detection algorithms;
- On this basis, we applied graph learning technology and constructed a GNN model, BND-GCN, for bridge node detection on complex networks;
- We test our model on sex real social networks and compare it with other baseline methods. Experiments show that BND-GCN performs well on bridge node detection tasks, and is generally better than the baselines.
2. Related Works
2.1. Bridge Nodes Detection Methods
2.1.1. Community-Unaware Approach
2.1.2. Community-Aware Approach
2.2. Graphical Representation Learning
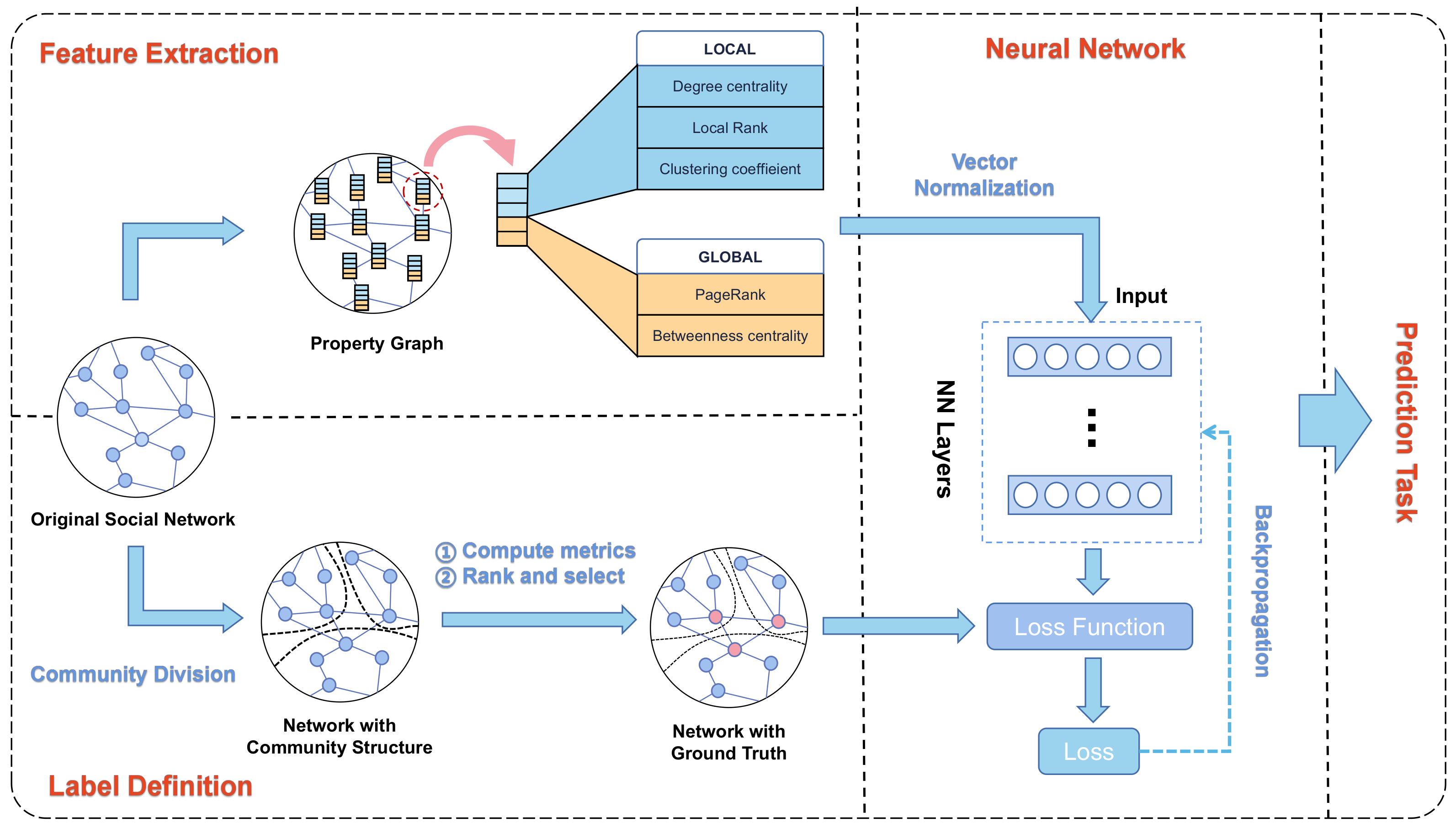
3. Main Framework
3.1. Label Definition
3.2. Feature Extraction
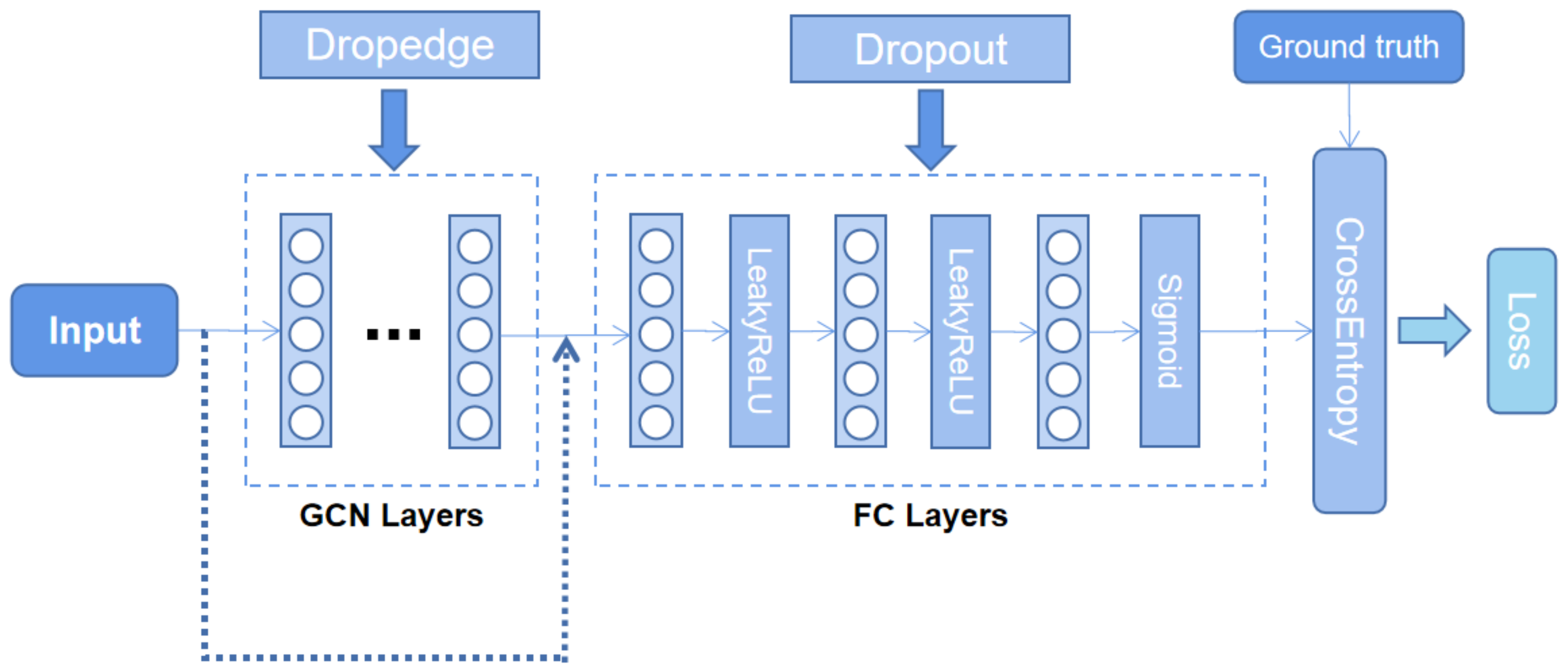
3.3. Graph Neural Network
4. Experiment
4.1. Dataset Construction
4.2. Parameter Settings
4.3. Baseline Methods
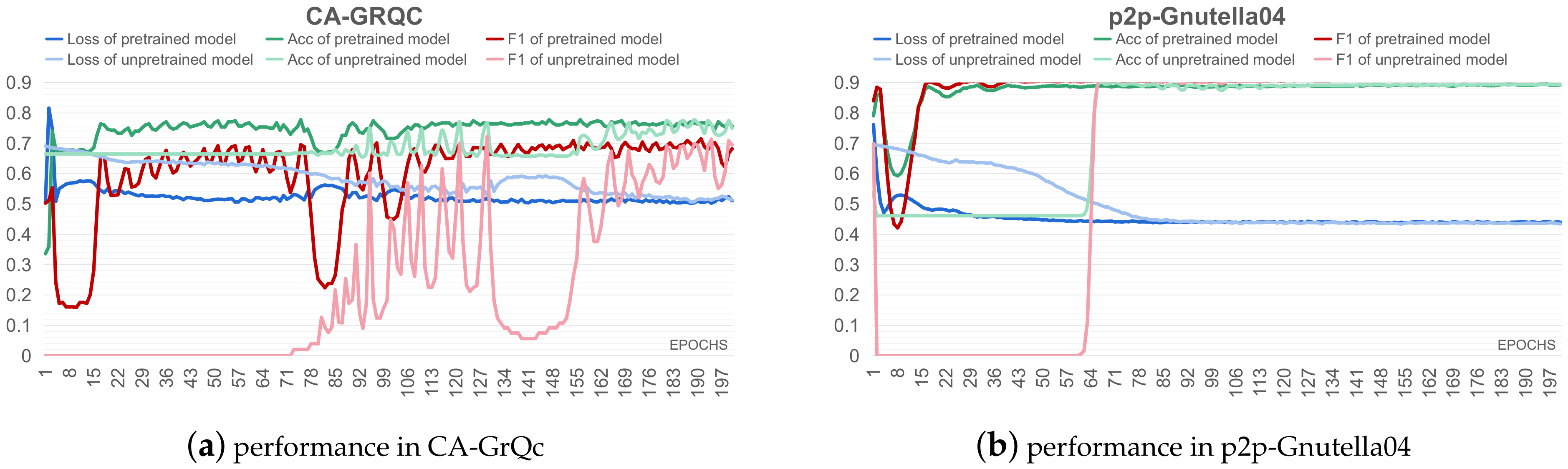
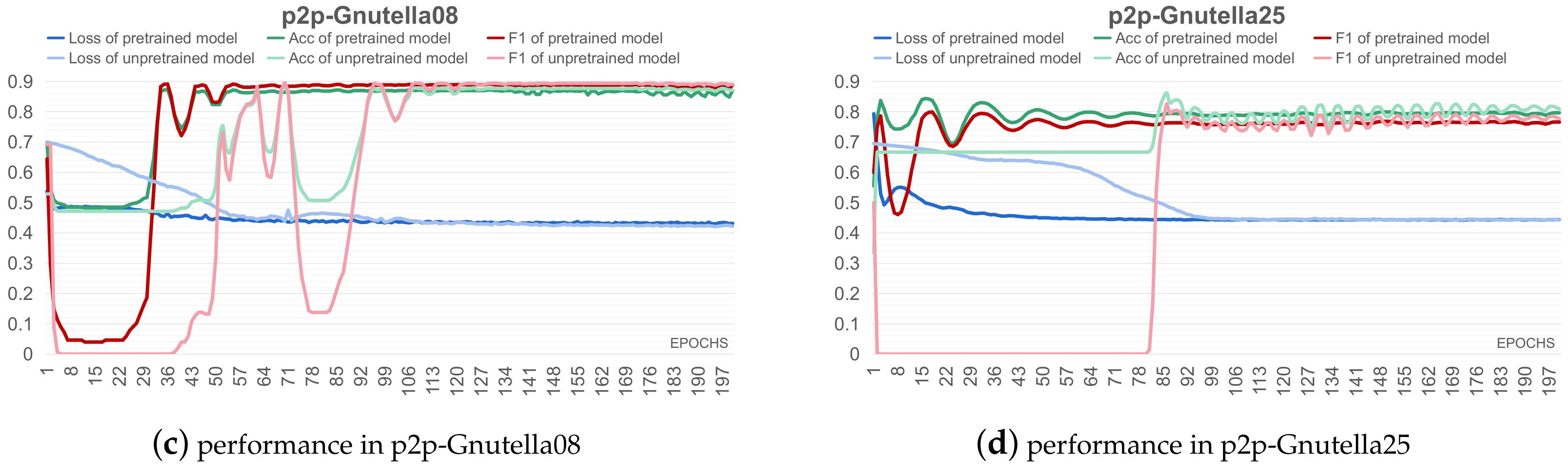
5. Experimental Results and Analyses
5.1. Bridge Node Prediction Experiment
5.2. Hyperparameter Analysis
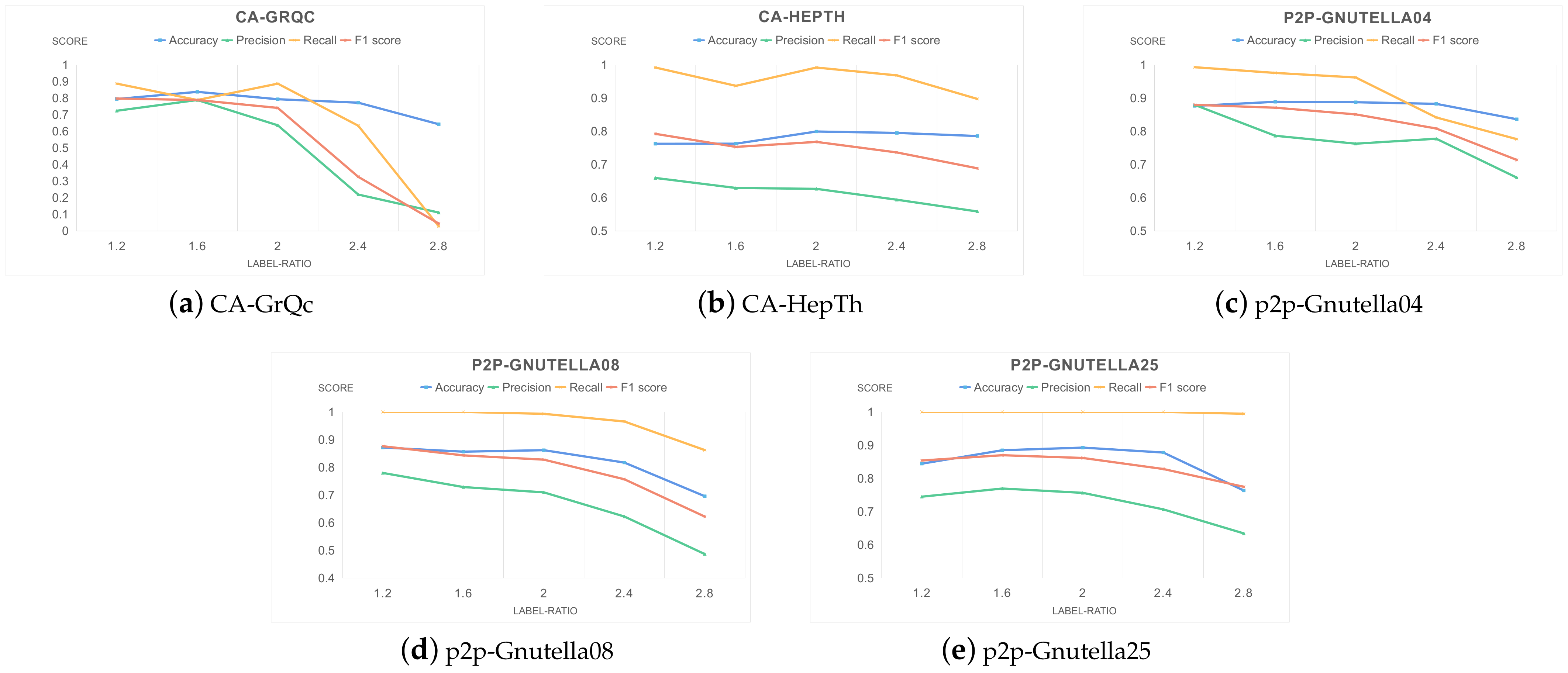
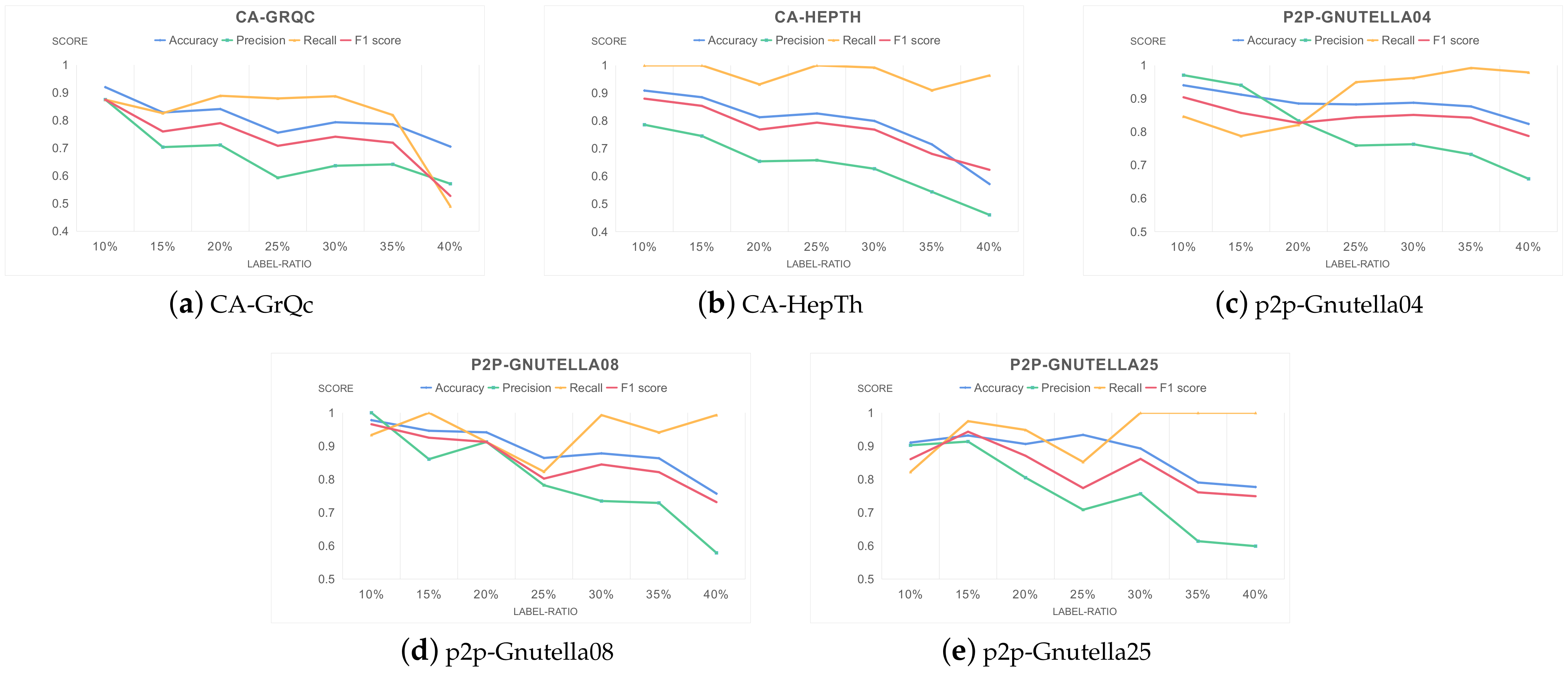
5.2.1. Label-Ratio
5.2.2. Bridge-Percentage
5.3. Pre-Training Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taghavian, F.; Salehi, M.; Teimouri, M. A local immunization strategy for networks with overlapping community structure. Phys. A Stat. Mech. Appl. 2017, 467, 148–156. [Google Scholar] [CrossRef]
- Kumar, M.; Singh, A.; Cherifi, H. An efficient immunization strategy using overlapping nodes and its neighborhoods. In Proceedings of the Companion Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1269–1275. [Google Scholar]
- Hwang, W.C.; Zhang, A.; Ramanathan, M. Identification of information flow-modulating drug targets: A novel bridging paradigm for drug discovery. Clin. Pharmacol. Ther. 2008, 84, 563–572. [Google Scholar] [CrossRef] [PubMed]
- Meghanathan, N. Neighborhood-based bridge node centrality tuple for complex network analysis. Appl. Netw. Sci. 2021, 6, 47. [Google Scholar] [CrossRef]
- Liu, W.; Pellegrini, M.; Wu, A. Identification of bridging centrality in complex networks. IEEE Access 2019, 7, 93123–93130. [Google Scholar] [CrossRef]
- Jiang, L.; Jing, Y.; Hu, S.; Ge, B.; Xiao, W. Identifying node importance in a complex network based on node bridging feature. Appl. Sci. 2018, 8, 1914. [Google Scholar] [CrossRef] [Green Version]
- Salathé, M.; Jones, J.H. Dynamics and control of diseases in networks with community structure. PLoS Comput. Biol. 2010, 6, e1000736. [Google Scholar] [CrossRef] [Green Version]
- Morone, F.; Makse, H.A. Influence maximization in complex networks through optimal percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef] [Green Version]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Nepusz, T.; Petróczi, A.; Négyessy, L.; Bazsó, F. Fuzzy communities and the concept of bridgeness in complex networks. Phys. Rev. E 2008, 77, 016107. [Google Scholar] [CrossRef] [Green Version]
- Gupta, N.; Singh, A.; Cherifi, H. Centrality measures for networks with community structure. Phys. A Stat. Mech. Appl. 2016, 452, 46–59. [Google Scholar] [CrossRef]
- Salavati, C.; Abdollahpouri, A.; Manbari, Z. Ranking nodes in complex networks based on local structure and improving closeness centrality. Neurocomputing 2019, 336, 36–45. [Google Scholar] [CrossRef]
- Ghalmane, Z.; Hassouni, M.E.; Cherifi, H. Immunization of networks with non-overlapping community structure. Soc. Netw. Anal. Min. 2019, 9, 45. [Google Scholar] [CrossRef] [Green Version]
- Ghalmane, Z.; El Hassouni, M.; Cherifi, C.; Cherifi, H. Centrality in modular networks. EPJ Data Sci. 2019, 8, 15. [Google Scholar] [CrossRef]
- Magelinski, T.; Bartulovic, M.; Carley, K.M. Measuring node contribution to community structure with modularity vitality. IEEE Trans. Netw. Sci. Eng. 2021, 8, 707–723. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph representation learning. Synth. Lect. Artifical Intell. Mach. Learn. 2020, 14, 1–159. [Google Scholar]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; Janardan, R.; Li, Q. Two-dimensional linear discriminant analysis. Adv. Neural Inf. Process. Syst. 2004, 17. [Google Scholar]
- Robinson, S.L.; Bennett, R.J. A typology of deviant workplace behaviors: A multidimensional scaling study. Acad. Manag. J. 1995, 38, 555–572. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Ahmed, A.; Shervashidze, N.; Narayanamurthy, S.; Josifovski, V.; Smola, A.J. Distributed large-scale natural graph factorization. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 37–48. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 891–900. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Qiu, J.; Tang, J.; Ma, H.; Dong, Y.; Wang, K.; Tang, J. Deepinf: Social influence prediction with deep learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2110–2119. [Google Scholar]
- Yu, E.Y.; Wang, Y.P.; Fu, Y.; Chen, D.B.; Xie, M. Identifying critical nodes in complex networks via graph convolutional networks. Knowl.-Based Syst. 2020, 198, 105893. [Google Scholar] [CrossRef]
- Zhao, G.; Jia, P.; Zhou, A.; Zhang, B. InfGCN: Identifying influential nodes in complex networks with graph convolutional networks. Neurocomputing 2020, 414, 18–26. [Google Scholar] [CrossRef]
- Chen, D.; Lü, L.; Shang, M.S.; Zhang, Y.C.; Zhou, T. Identifying influential nodes in complex networks. Phys. A Stat. Mech. Appl. 2012, 391, 1777–1787. [Google Scholar] [CrossRef] [Green Version]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards deep graph convolutional networks on node classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 2-es. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Feature | Description |
|---|---|---|
| Local | Degree | Measure the number of the neighbors of a node. |
| LocalRank | Aggregate the information contained in the fourth-order neighbors of each node. | |
| Clustering coefficient | Describe the degree of interconnection between the neighbors of a node. | |
| Global | PageRank | Measure the importance of a particular webpage relative to other webpages. |
| Betweenness | Measure the degree of interaction between the node and other nodes based on the shortest path. |
| Network | Nodes | Edges |
|---|---|---|
| CA-GrQc | 5242 | 14,496 |
| CA-HepTh | 9877 | 25,998 |
| p2p-Gnutella04 | 10,876 | 39,994 |
| p2p-Gnutella08 | 6301 | 20,777 |
| p2p-Gnutella25 | 22,687 | 54,705 |
| Model | Score | CA-GrQc | CA-HepTh | p2p-Gnutella04 | p2p-Gnutella08 | p2p-Gnutella25 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | Accuracy Precision | 0.6667 | 0.5000 | 0.6860 | 0.7857 | 0.7731 | 0.9043 | 0.5971 | 1.0000 | 0.8007 | 0.8591 |
| Recall F1 score | 0.0141 | 0.0274 | 0.0866 | 0.1560 | 0.3574 | 0.5123 | 0.0276 | 0.0537 | 0.5903 | 0.6998 | |
| SVM | Accuracy Precision | 0.6230 | 0.3333 | 0.6887 | 0.6667 | 0.8293 | 0.8777 | 0.6728 | 0.8000 | 0.8832 | 0.8013 |
| Recall F1 score | 0.0141 | 0.0270 | 0.1417 | 0.2338 | 0.5670 | 0.6889 | 0.0276 | 0.0533 | 0.8641 | 0.8315 | |
| MLP | Accuracy Precision | 0.7789 | 0.7647 | 0.5955 | 0.4661 | 0.7292 | 0.5925 | 0.7604 | 0.8361 | 0.7676 | 0.6105 |
| Recall F1 score | 0.5493 | 0.6393 | 0.9213 | 0.6190 | 0.8694 | 0.7047 | 0.3517 | 0.4951 | 0.9777 | 0.7516 | |
| Inf-GCN | Accuracy Precision | 0.7418 | 0.5889 | 0.8285 | 0.6802 | 0.8832 | 0.7723 | 0.7742 | 0.7238 | 0.8683 | 0.7199 |
| Recall F1 score | 0.7465 | 0.5684 | 0.9213 | 0.7826 | 0.9210 | 0.8401 | 0.5241 | 0.6080 | 0.9907 | 0.8339 | |
| BND-GraphSAGE | Accuracy Precision | 0.7559 | 0.6044 | 0.8047 | 0.6448 | 0.8305 | 0.7527 | 0.7604 | 0.5945 | 0.7789 | 0.6189 |
| Recall F1 score | 0.7746 | 0.6790 | 0.9291 | 0.7613 | 0.7320 | 0.7422 | 0.8897 | 0.7127 | 0.8771 | 0.7257 | |
| BND-GAT | Accuracy Precision | 0.7277 | 0.6585 | 0.7784 | 0.6443 | 0.8706 | 0.7947 | 0.8041 | 0.8409 | 0.9050 | 0.7883 |
| Recall F1 score | 0.3803 | 0.4821 | 0.7559 | 0.6957 | 0.8247 | 0.8094 | 0.5103 | 0.6352 | 0.9777 | 0.8728 | |
| BND-GCN | Accuracy Precision | 0.7934 | 0.6364 | 0.7995 | 0.6269 | 0.8877 | 0.7629 | 0.8779 | 0.7347 | 0.8925 | 0.7563 |
| Recall F1 score | 0.8873 | 0.7412 | 0.9921 | 0.7683 | 0.9622 | 0.8511 | 0.9931 | 0.8446 | 1.0000 | 0.8613 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Jia, P.; Zhou, A.; Liu, Y.; He, Z. Bridge Node Detection between Communities Based on GNN. Appl. Sci. 2022, 12, 10337. https://doi.org/10.3390/app122010337
Luo H, Jia P, Zhou A, Liu Y, He Z. Bridge Node Detection between Communities Based on GNN. Applied Sciences. 2022; 12(20):10337. https://doi.org/10.3390/app122010337
Chicago/Turabian StyleLuo, Hairu, Peng Jia, Anmin Zhou, Yuying Liu, and Ziheng He. 2022. "Bridge Node Detection between Communities Based on GNN" Applied Sciences 12, no. 20: 10337. https://doi.org/10.3390/app122010337
APA StyleLuo, H., Jia, P., Zhou, A., Liu, Y., & He, Z. (2022). Bridge Node Detection between Communities Based on GNN. Applied Sciences, 12(20), 10337. https://doi.org/10.3390/app122010337