


AT-CRF: A Chinese Reading Comprehension Algorithm Based on Attention Mechanism and Conditional Random Fields


Abstract
:1. Introduction
- We use a Chinese pre-trained language model in combination with multiple attention mechanisms to acquire input representations and fully learn the connection between the local and global contexts;
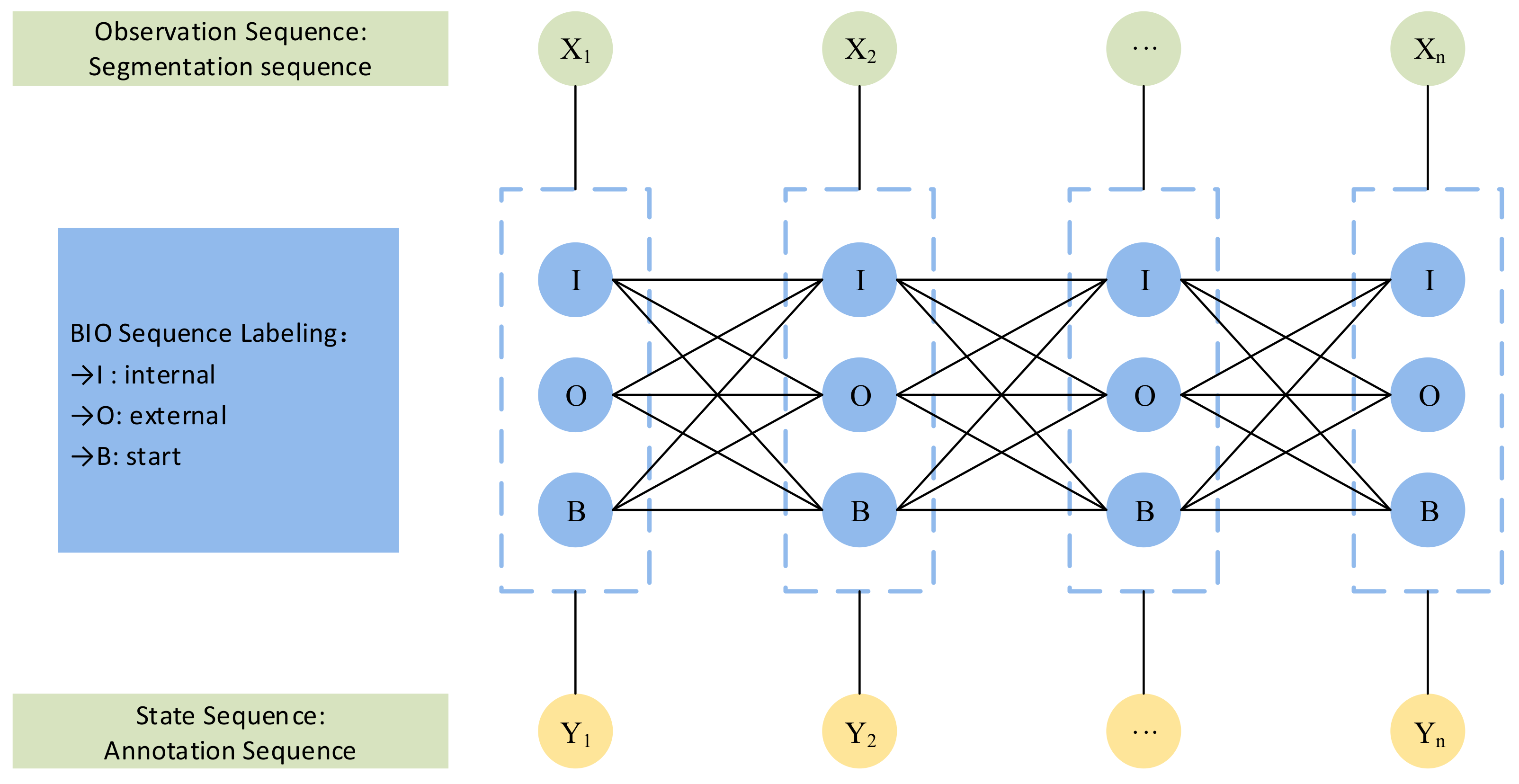
- We use the CRF to convert the output prediction into the sequence labeling question to predict the starting and ending position of the answer, and output the correct answer sequence when the question is answerable, while identifying the unanswerable questions and responding appropriately;
- We validate the performance of the model by comparing the AT-CRF Reader with state-of-the-art MRC models on CMRC2018 and DuReader-checklist datasets.
2. Related Works
2.1. Machine Reading Comprehension Research
2.2. Conditional Random Field
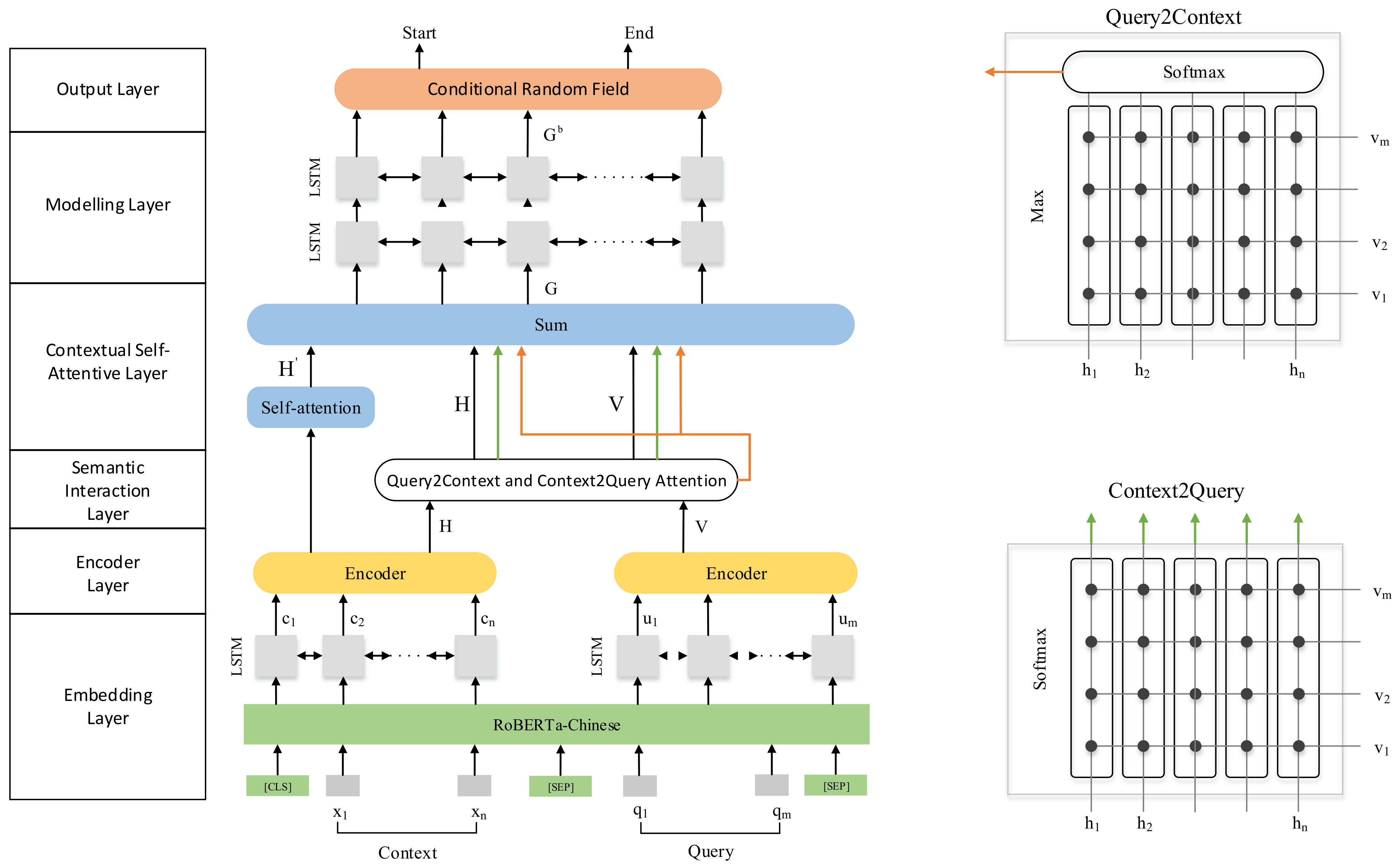
3. Model Architecture
3.1. Embedding Layer
- The model adopts the Whole Word Mask (WWM) mechanism, which improves the learning ability by constantly changing the masking position during training.
- The model uses the full-sentences and the doc-sentences as input to dynamically increase the batch size to replace the Next Sentence Prediction objective (NSP) in Bert.
- The model is trained using a larger batch size with more training data and longer training time.
- The model uses a larger Byte to construct the vocabulary table.
3.2. Encoder Layer
3.3. Semantic Interaction Layer
3.4. Contextual Self-Attention Layer
3.5. Modeling Layer
3.6. Output Layer
4. Experimental Results and Discussion
4.1. Experimental Dataset
4.2. Evaluation Indicators
4.3. Experimental Parameter Settings
4.4. Experimental Results and Analysis
4.4.1. Comparison Experiment
4.4.2. Ablation Experiment
4.4.3. Other Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, S.; Zhang, X.; Zhang, S.; Wang, H.; Zhang, W. Neural machine reading comprehension: Methods and trends. Appl. Sci. 2019, 9, 3698. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Li, Y.; Lin, M. Review of Conversational Machine Reading Comprehension. J. Front. Comput. Sci. Technol. 2021, 15, 1607. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Chi, P.; Chung, P.; Wu, T.; Hsieh, C.; Chen, Y.; Li, S.; Lee, H. Audio albert: A lite Bert for self-supervised learning of audio representation. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Virtual, 19–22 January 2021; pp. 344–350. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chen, D.; Ma, J.; Ma, Z.; Zhou, J. Review of Pre-training Techniques for Natural Language Processing. Front. Comput. Sci. Technol. 2021, 15, 31. [Google Scholar]
- Yin, F.; Wang, Y.; Liu, J. Modeling multi-prototype Chinese word representation learning for word similarity. Complex Intell. Syst. 2021, 7, 2977–2990. [Google Scholar] [CrossRef]
- Liao, W.; Huang, M.; Ma, P.; Wang, Y. Extracting Knowledge Entities from Sci-Tech Intelligence Resources Based on BiLSTM and Conditional Random Field. IEICE Trans. Inf. Syst. 2021, 104, 1214–1221. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, T.; Che, W.; Xiao, L.; Chen, Z.; Ma, W.; Wang, S.; Hu, G. A Span-Extraction Dataset for Chinese Machine Reading Comprehension. In Proceedings of the EMNLP/IJCNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- He, W.; Liu, K.; Liu, J.; Lyu, Y.; Zhao, S.; Xiao, X.; Liu, Y.; Wang, Y.; Wu, H.; She, Q.; et al. DuReader: A Chinese Machine Reading Comprehension Dataset from Real-World Applications. In Proceedings of the QA@ ACL, Melbourne, Australia, 19 July 2018. [Google Scholar]
- Riloff, E.; Thelen, M. A rule-based question answering system for reading comprehension tests. In Proceedings of the ANLP-NAACL 2000 Workshop: Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding Systems, Seattle, WA, USA, 4 May 2000. [Google Scholar]
- Hirschman, L.; Light, M.; Breck, E.; Burger, J.D. Deep read: A reading comprehension system. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 325–332. [Google Scholar]
- Chen, D.; Bolton, J.; Manning, C.D. A thorough examination of the cnn/daily mail reading comprehension task. arXiv 2016, arXiv:1606.02858. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know what you don’t know: Unanswerable questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; Hu, G. Attention-over-attention neural networks for reading comprehension. arXiv 2016, arXiv:1607.04423. [Google Scholar]
- Wang, S.; Jiang, J. Machine comprehension using match-lstm and answer pointer. arXiv 2016, arXiv:1608.07905. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated self-matching networks for reading comprehension and question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 189–198. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Cui, Y.; Liu, T.; Chen, Z.; Wang, S.; Hu, G. Consensus attention-based neural networks for Chinese reading comprehension. arXiv 2016, arXiv:1607.02250. [Google Scholar]
- Lai, Y.; Tseng, Y.; Lin, P.; Hsiao, V.; Shao, C. D-Reader: A Reading Comprehension Model by Full-text Prediction. J. Chin. Inf. Process. 2018, 32, 135–142. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting pre-trained models for Chinese natural language processing. arXiv 2020, arXiv:2004.13922. [Google Scholar]
- Guo, S.; Guan, Y.; Tan, H.; Li, R.; Li, X. Frame-based neural network for machine reading comprehension. Knowl.-Based Syst. 2021, 219, 106889. [Google Scholar] [CrossRef]
- Sun, Z.; Li, X.; Sun, X.; Meng, Y.; Ao, X.; He, Q.; Wu, F.; Li, J. Chinesebert: Chinese pretraining enhanced by glyph and pinyin information. arXiv 2021, arXiv:2106.16038. [Google Scholar]
- Chopra, D.; Morwal, S.; Purohit, G. Hidden markov model based named entity recognition tool. Int. J. Found. Comput. Sci. Technol. (IJFCST) 2013, 3, 67–73. [Google Scholar]
- Xie, C.; Chen, D.; Shi, H.; Fan, M. Attention-Based Bidirectional Long Short Term Memory Networks Combine with Phrase Convolution Layer for Relation Extraction. In Proceedings of the 2021 5th SLAAI International Conference on Artificial Intelligence (SLAAI-ICAI), Kelaniya, Sri Lanka, 6–7 December 2021; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Test Set | |
|---|---|---|---|
| Question # | 10321 | 3351 | 4895 |
| Answers per Q | 1 | 3 | 3 |
| Max P tokens | 962 | 961 | 980 |
| Max Q tokens | 89 | 56 | 50 |
| Max A tokens | 100 | 85 | 92 |
| Avg P tokens | 452 | 469 | 472 |
| Avg Q tokens | 15 | 15 | 15 |
| Avg A tokens | 17 | 9 | 9 |
| Training Set | Test Set | |
|---|---|---|
| Question # | 3000 | 1130 |
| Answers per Q | 1 | 1 |
| Q with A | 1404 | 539 |
| Unanswerable Q | 1596 | 591 |
| Parameter | Setting Value |
|---|---|
| Epoch | 3 |
| Batch size | 32 |
| Learning-rate | 3 × 10−5 |
| Dropout | 0.01 |
| Max A tokens | 50 |
| Max-seq-length | 512 |
| Model | EM/% | F1/% |
|---|---|---|
| Bert-base(Chinese) | 61.07 | 84.86 |
| Ernie | 62.91 | 86.52 |
| RoBERTa-wwm-ext | 63.87 | 86.36 |
| ELECTRA | 64.43 | 86.73 |
| MacBERT-Chinese | 65.34 | 86.84 |
| ChineseBERT | 65.83 | 88.09 |
| AT-CRF Reader | 65.52 | 87.51 |
| Model | EM/% | F1/% |
|---|---|---|
| Bert-base(Chinese) | 70.57 | 84.71 |
| Ernie | 71.48 | 85.77 |
| RoBERTa-wwm-ext | 73.11 | 86.58 |
| ELECTRA | 73.82 | 86.83 |
| MacBERT-Chinese | 73.96 | 87.14 |
| ChineseBERT | 74.62 | 87.76 |
| AT-CRF Reader | 74.45 | 87.39 |
| Model | EM/% | F1/% |
|---|---|---|
| Bert-base(Chinese) | 70.57 | 84.71 |
| AT Reader | 73.32 | 87.11 |
| AT-CRF Reader | 74.45 | 87.39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, N.; Wang, H.; Cheng, Y. AT-CRF: A Chinese Reading Comprehension Algorithm Based on Attention Mechanism and Conditional Random Fields. Appl. Sci. 2022, 12, 10459. https://doi.org/10.3390/app122010459
Shi N, Wang H, Cheng Y. AT-CRF: A Chinese Reading Comprehension Algorithm Based on Attention Mechanism and Conditional Random Fields. Applied Sciences. 2022; 12(20):10459. https://doi.org/10.3390/app122010459
Chicago/Turabian StyleShi, Nawei, Huazhang Wang, and Yongqiang Cheng. 2022. "AT-CRF: A Chinese Reading Comprehension Algorithm Based on Attention Mechanism and Conditional Random Fields" Applied Sciences 12, no. 20: 10459. https://doi.org/10.3390/app122010459
APA StyleShi, N., Wang, H., & Cheng, Y. (2022). AT-CRF: A Chinese Reading Comprehension Algorithm Based on Attention Mechanism and Conditional Random Fields. Applied Sciences, 12(20), 10459. https://doi.org/10.3390/app122010459