
Ambulatory Monitoring of Subglottal Pressure Estimated from Neck-Surface Vibration in Individuals with and without Voice Disorders
 , , , ,
, , , ,
Abstract
:Featured Application
Abstract
1. Introduction
1.1. Traditional Methods of Subglottal Pressure Estimation
1.2. Subglottal Pressure Estimation from Anterior Neck-Surface Vibration
1.3. Clinical Motivation for Ambulatory Monitoring of Subglottal Pressure
1.4. Study Goals
2. Materials and Methods
2.1. Study Participants
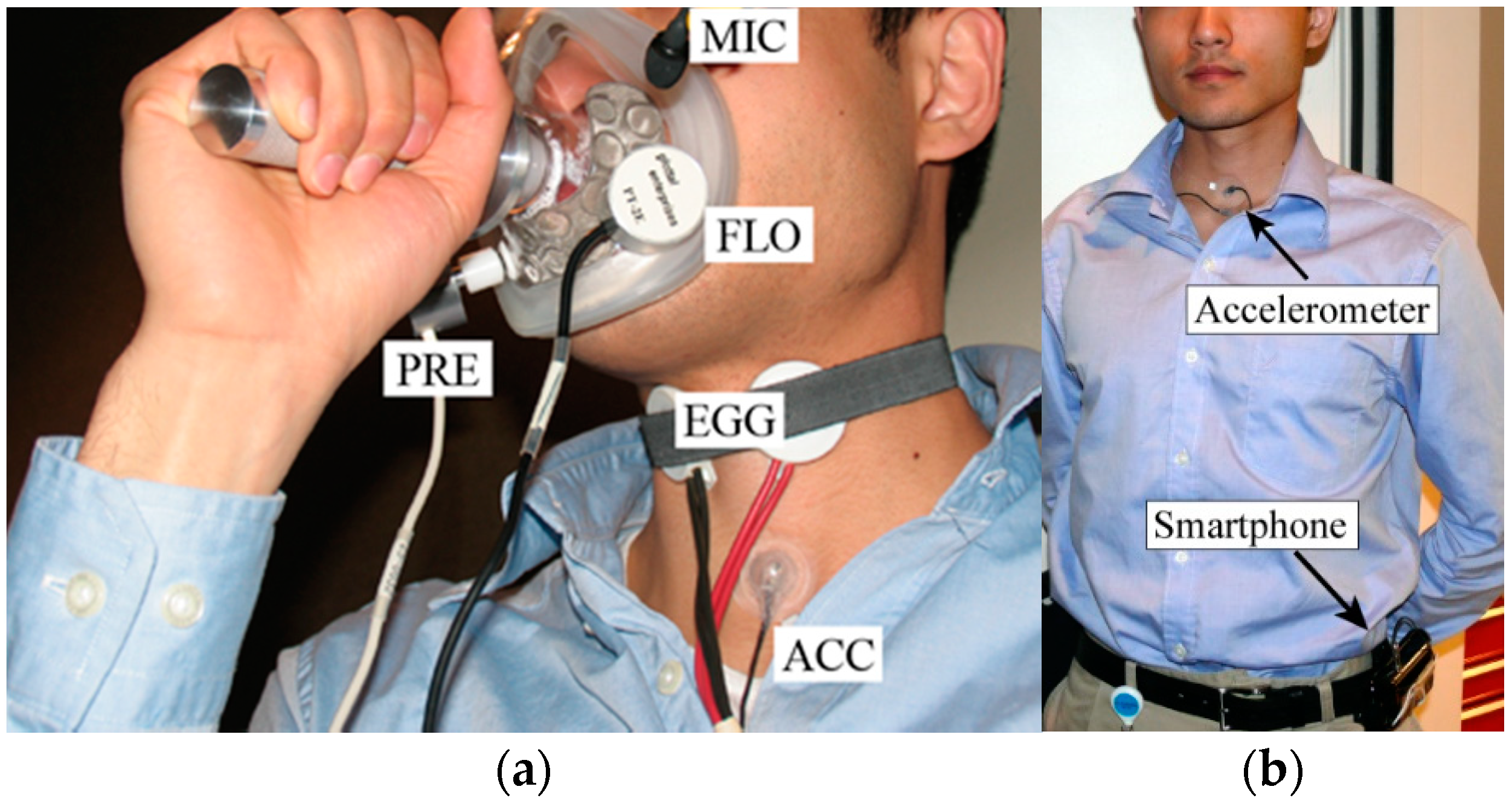
2.2. Laboratory and Ambulatory Data Collection
2.3. Laboratory Data Analysis
2.3.1. Signal Pre-Processing
2.3.2. Ps Estimation Method 1: Empirical Relationship with SPL and fo
2.3.3. Ps Estimation Method 2: Linear Regression Model Using ACC Signal Magnitude Only
2.3.4. Ps Estimation Method 3: Multiple Linear Regression Model
2.3.5. Ps Estimation Method 4: Nonlinear Neural Network Model
2.4. Statistical Comparison of Ps Estimation Methods
2.5. Ambulatory Data Analysis
3. Results
3.1. Laboratory Results: Accuracy of Subglottal Pressure Estimation Using Four Methods
3.2. Laboratory Results: Inclusion Frequency of Vocal Function Measures into Ps Estimation Method 3
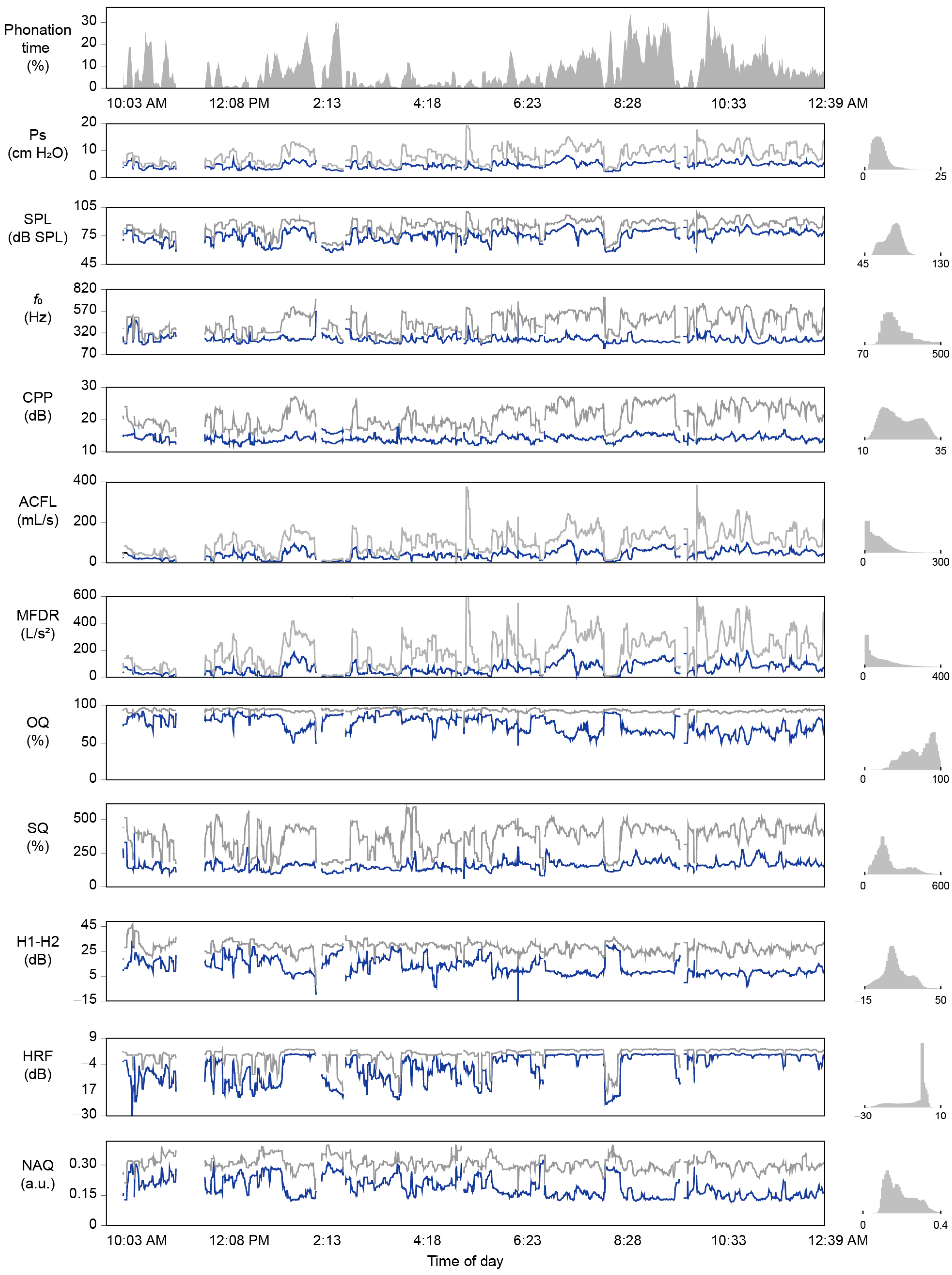
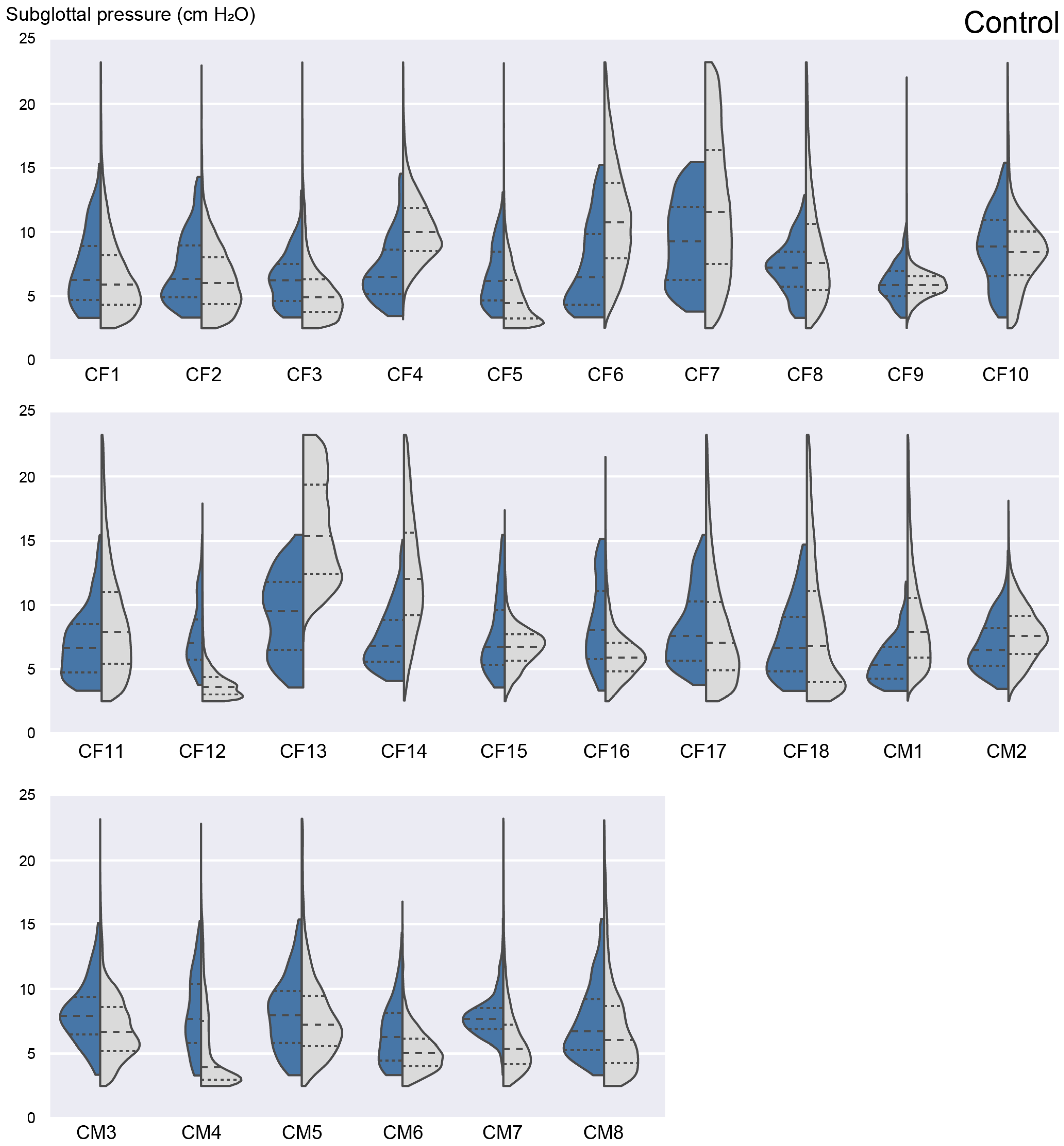
3.3. Ambulatory Results: Feasability of Subglottal Pressure Estimation during Daily Life
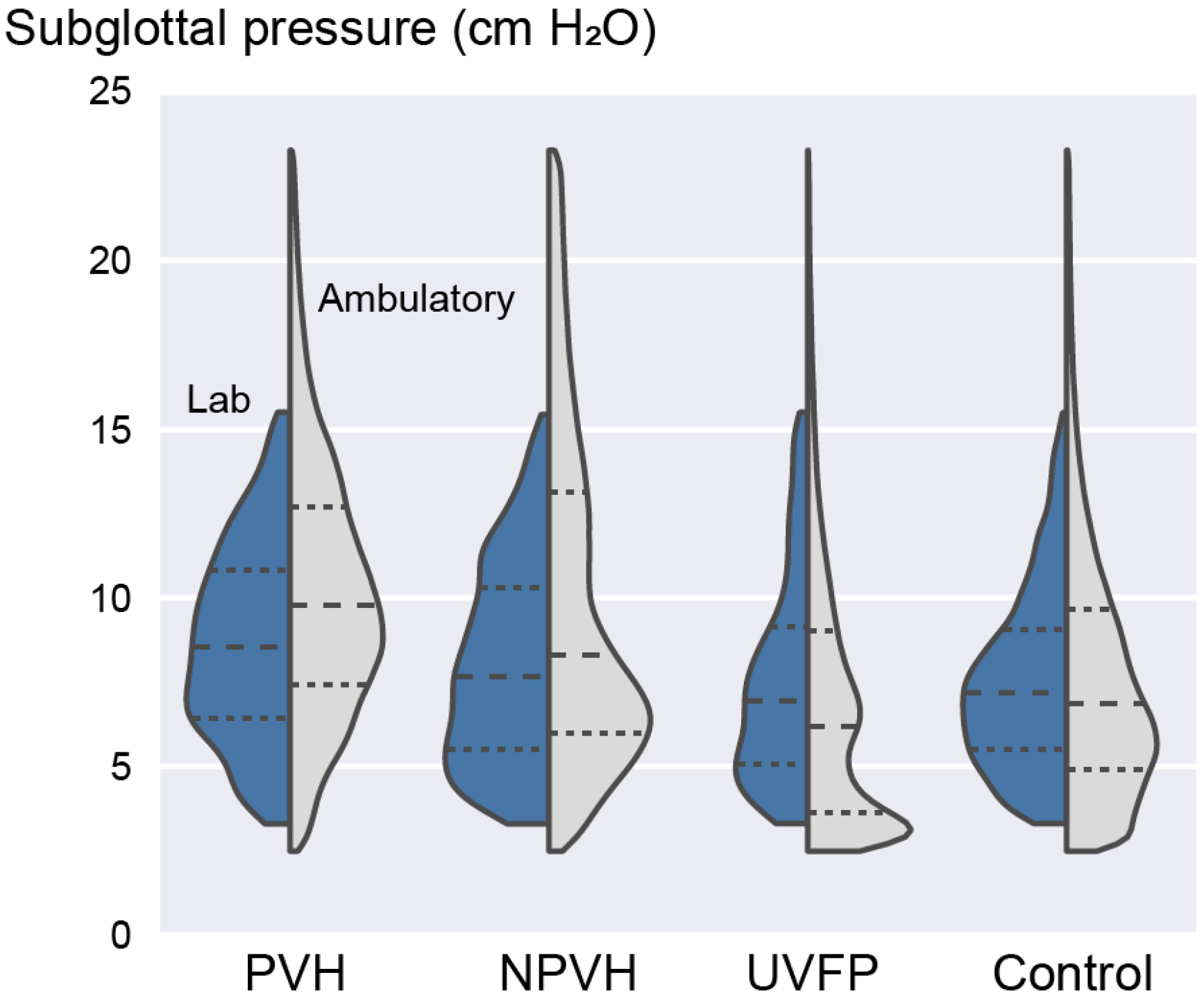
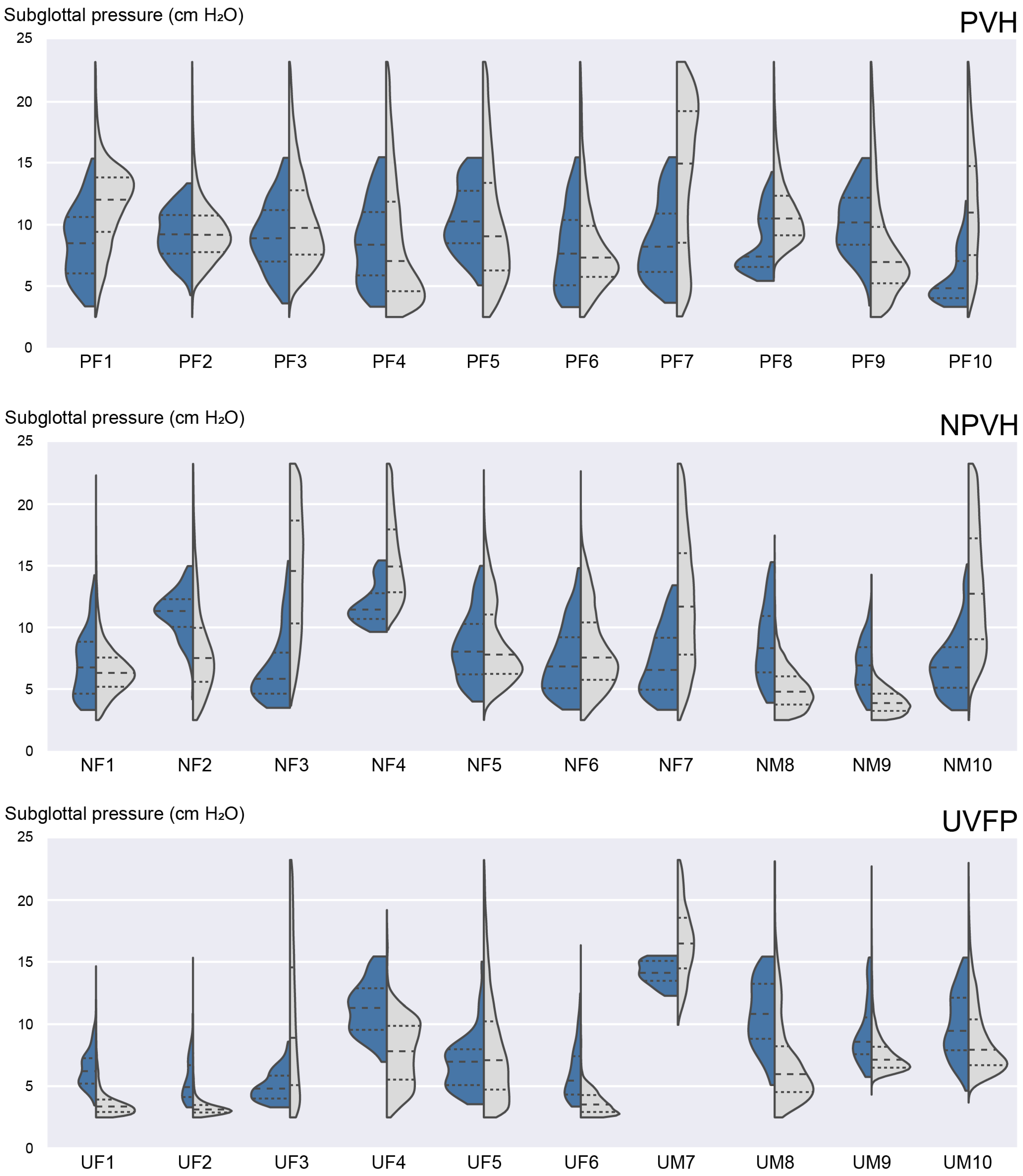
3.4. Laboratory versus Ambulatory Distribution of Subglottal Pressure
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID * | Method 1 | Method 2 | Method 3 | Method 4 | Overall Severity |
|---|---|---|---|---|---|
| PF1 | 2.45 | 2.03 | 1.65 | 2.61 | 3 |
| PF2 | 2.73 | 1.48 | 1.32 | 1.89 | 14 |
| PF3 | 2.42 | 1.59 | 1.02 | 2.60 | 21 |
| PF4 | 5.81 | 2.11 | 1.56 | 4.12 | 11 |
| PF5 | 1.82 | 1.78 | 1.03 | 1.75 | 50 |
| PF6 | 11.51 | 1.98 | 1.84 | 3.78 | 0 |
| PF7 | 3.35 | 1.63 | 1.42 | 2.81 | 18 |
| PF8 | 2.69 | 2.44 | 2.18 | 2.61 | 37 |
| PF9 | 6.43 | 4.85 | 2.96 | 7.58 | 51 |
| PF10 | 1.74 | 1.11 | 1.09 | 2.00 | 19 |
| NF1 | 4.78 | 1.92 | 1.45 | 4.77 | 23 |
| NF2 | 3.58 | 2.54 | 2.31 | 3.94 | 62 |
| NF3 | 1.37 | 1.06 | 1.05 | 2.29 | 9 |
| NF4 | 7.67 | 3.96 | 3.96 | 8.52 | 93 |
| NF5 | 3.82 | 1.61 | 0.97 | 1.97 | 7 |
| NF6 | 3.05 | 2.61 | 2.23 | 2.51 | 26 |
| NF7 | 3.12 | 0.84 | 0.74 | 1.77 | 4 |
| NM8 | 3.61 | 2.56 | 2.30 | 4.21 | 7 |
| NM9 | 2.90 | 2.03 | 1.19 | 1.71 | 4 |
| NM10 | 3.66 | 1.69 | 1.49 | 3.37 | 18 |
| UF1 | 5.20 | 1.36 | 1.31 | 3.89 | 57 |
| UF2 | 5.87 | 1.23 | 1.10 | 4.34 | 77 |
| UF3 | 2.02 | 1.98 | 1.75 | 2.44 | 56 |
| UF4 | 9.82 | 2.43 | 2.08 | 8.49 | 73 |
| UF5 | 3.17 | 2.57 | 2.42 | 2.34 | 48 |
| UF6 | 2.29 | 1.86 | 0.96 | 1.61 | 95 |
| UM7 | 6.49 | 2.11 | 1.70 | 9.84 | 19 |
| UM8 | 3.24 | 3.15 | 2.88 | 6.02 | 77 |
| UM9 | 6.28 | 1.04 | 0.98 | 5.36 | 10 |
| UM10 | 3.06 | 2.90 | 2.36 | 4.25 | 33 |
| ID * | Method 1 | Method 2 | Method 3 | Method 4 |
|---|---|---|---|---|
| CF1 | 2.61 | 1.29 | 0.73 | 2.41 |
| CF2 | 1.69 | 1.04 | 0.78 | 2.55 |
| CF3 | 2.43 | 1.34 | 0.76 | 4.30 |
| CF4 | 2.78 | 1.47 | 1.31 | 3.22 |
| CF5 | 1.44 | 1.09 | 0.57 | 2.90 |
| CF6 | 1.39 | 0.98 | 0.87 | 1.96 |
| CF7 | 4.16 | 2.47 | 2.12 | 3.81 |
| CF8 | 2.18 | 1.47 | 1.28 | 2.54 |
| CF9 | 4.68 | 1.17 | 1.04 | 3.81 |
| CF10 | 2.03 | 1.48 | 1.23 | 2.57 |
| CF11 | 4.59 | 1.68 | 1.39 | 3.26 |
| CF12 | 4.68 | 1.56 | 1.29 | 2.75 |
| CF13 | 2.34 | 1.90 | 1.23 | 2.38 |
| CF14 | 2.35 | 0.82 | 0.73 | 2.52 |
| CF15 | 1.88 | 1.05 | 0.81 | 2.22 |
| CF16 | 4.08 | 2.36 | 1.74 | 5.44 |
| CF17 | 5.29 | 1.92 | 1.29 | 1.94 |
| CF18 | 1.79 | 1.28 | 0.84 | 2.24 |
| CM1 | 4.54 | 0.85 | 0.69 | 2.06 |
| CM2 | 1.21 | 1.29 | 0.85 | 1.88 |
| CM3 | 2.26 | 2.33 | 1.58 | 3.51 |
| CM4 | 6.58 | 2.31 | 1.06 | 3.19 |
| CM5 | 2.31 | 1.82 | 1.33 | 2.93 |
| CM6 | 3.64 | 0.97 | 0.87 | 2.83 |
| CM7 | 2.49 | 1.63 | 1.50 | 2.55 |
| CM8 | 1.58 | 1.61 | 1.41 | 3.41 |
Appendix B


References
- Roy, N.; Merrill, R.M.; Gray, S.D.; Smith, E.M. Voice disorders in the general population: Prevalence, risk factors, and occupational impact. Laryngoscope 2005, 115, 1988–1995. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharyya, N. The prevalence of voice problems among adults in the United States. Laryngoscope 2014, 124, 2359–2362. [Google Scholar] [CrossRef]
- NIDCD. 2017–2021 NIDCD Strategic Plan; National Institute on Deafness and Other Communication Disorders (NIDCD), U.S. Department of Health and Human Services: Bethesda, MD, USA, 2017. [Google Scholar]
- Cohen, S.M.; Kim, J.; Roy, N.; Asche, C.; Courey, M. Direct health care costs of laryngeal diseases and disorders. Laryngoscope 2012, 122, 1582–1588. [Google Scholar] [CrossRef] [PubMed]
- Cohen, S.M.; Kim, J.; Roy, N.; Asche, C.; Courey, M. The impact of laryngeal disorders on work-related dysfunction. Laryngoscope 2012, 122, 1589–1594. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Maffei, M.; Masson, M.L.V.; Mehta, D.D.; Burns, J.A.; Hillman, R.E. Self-ratings of vocal status in daily life: Reliability and validity for patients with vocal hyperfunction and a normative group. Am. J. Speech Lang. Pathol. 2017, 26, 1167–1177. [Google Scholar] [CrossRef] [Green Version]
- Hanschmann, H.; Lohmann, A.; Berger, R. Comparison of subjective assessment of voice disorders and objective voice measurement. Folia Phoniatr. Logop. 2011, 63, 83–87. [Google Scholar] [CrossRef]
- Carroll, T.; Nix, J.; Hunter, E.; Emerich, K.; Titze, I.; Abaza, M. Objective measurement of vocal fatigue in classical singers: A vocal dosimetry pilot study. Otolaryngol.—Head Neck Surg. 2006, 135, 595–602. [Google Scholar] [CrossRef] [Green Version]
- Rosenthal, A.L.; Lowell, S.Y.; Colton, R.H. Aerodynamic and acoustic features of vocal effort. J. Voice 2014, 28, 144–153. [Google Scholar] [CrossRef] [Green Version]
- Ramig, L.O.; Dromey, C. Aerodynamic mechanisms underlying treatment-related changes in vocal intensity in patients with Parkinson disease. J. Speech Hear. Res. 1996, 39, 798–807. [Google Scholar] [CrossRef]
- McKenna, V.S.; Stepp, C.E. The relationship between acoustical and perceptual measures of vocal effort. J. Acoust. Soc. Am. 2018, 144, 1643–1658. [Google Scholar] [CrossRef]
- Colton, R.H.; Casper, J.K.; Leonard, R.J. Understanding Voice Problems: A Physiological Perspective for Diagnosis and Treatment; Lippincott Williams & Wilkins: Baltimore, MD, USA, 2006; p. 498. [Google Scholar]
- Björklund, S.; Sundberg, J. Relationship between subglottal pressure and sound pressure level in untrained voices. J. Voice 2016, 30, 15–20. [Google Scholar] [CrossRef] [PubMed]
- Titze, I. Quantifying vocal efficiency and economy—How can computation augment clinical assessment? Proc. Meet. Acoust. 2013, 19, 060244. [Google Scholar]
- Titze, I.R. Vocal efficiency. J. Voice 1992, 6, 135–138. [Google Scholar] [CrossRef]
- Titze, I.R.; Maxfield, L.; Palaparthi, A. An oral pressure conversion ratio as a predictor of vocal efficiency. J. Voice 2016, 30, 398–406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Titze, I.R. Comments on the myoelastic-aerodynamic theory of phonation. J. Speech Hear. Res. 1980, 23, 495–510. [Google Scholar] [CrossRef]
- Titze, I.R. On the relation between subglottal pressure and fundamental frequency in phonation. J. Acoust. Soc. Am. 1989, 85, 901–906. [Google Scholar] [CrossRef]
- Sundberg, J.; Titze, I.; Scherer, R. Phonatory control in male singing: A study of the effects of subglottal pressure, fundamental frequency, and mode of phonation on the voice source. J. Voice 1993, 7, 15–29. [Google Scholar] [CrossRef]
- Åkerlund, L.; Gramming, P. Average loudness level, mean fundamental frequency, and subglottal pressure: Comparison between female singers and nonsingers. J. Voice 1994, 8, 263–270. [Google Scholar] [CrossRef]
- Speyer, R. Effects of voice therapy: A systematic review. J. Voice 2008, 22, 565–580. [Google Scholar] [CrossRef]
- Hartl, D.M.; Hans, S.; Vaissière, J.; Riquet, M.; Brasnu, D.F. Objective voice quality analysis before and after onset of unilateral vocal fold paralysis. J. Voice 2001, 15, 351–361. [Google Scholar] [CrossRef]
- Holmberg, E.B.; Doyle, P.; Perkell, J.S.; Hammarberg, B.; Hillman, R.E. Aerodynamic and acoustic voice measurements of patients with vocal nodules: Variation in baseline and changes across voice therapy. J. Voice 2003, 17, 269–282. [Google Scholar] [CrossRef]
- Zeitels, S.M.; Hillman, R.E.; Franco, R.A.; Bunting, G.W. Voice and treatment outcome from phonosurgical management of early glottic cancer. Ann. Otol. Rhinol. Laryngol. 2002, 111 (Suppl. 190), 1–20. [Google Scholar] [CrossRef] [PubMed]
- Zeitels, S.M.; Hochman, I.; Hillman, R.E. Adduction arytenopexy: A new procedure for paralytic dysphonia and the implications for implant medialization. Ann. Otol. Rhinol. Laryngol. 1998, 107 (Suppl. 173), 1–24. [Google Scholar]
- Zeitels, S.M.; Lopez-Guerra, G.; Burns, J.A.; Lutch, M.; Friedman, A.M.; Hillman, R.E. Microlaryngoscopic and office-based injection of bevacizumab (Avastin) to enhance 532-nm pulsed KTP laser treatment of glottal papillomatosis. Ann. Otol. Rhinol. Laryngol. 2009, 118 (Suppl. 201), 1–13. [Google Scholar] [CrossRef]
- Jiang, J.; Stern, J. Receiver operating characteristic analysis of aerodynamic parameters obtained by airflow interruption: A preliminary report. Ann. Otol. Rhinol. Laryngol. 2004, 113, 961–966. [Google Scholar] [CrossRef]
- Hillman, R.E.; Holmberg, E.B.; Perkell, J.S.; Walsh, M.; Vaughan, C. Objective assessment of vocal hyperfunction: An experimental framework and initial results. J. Speech Hear. Res. 1989, 32, 373–392. [Google Scholar] [CrossRef]
- Toles, L.E.; Seidman, A.Y.; Hillman, R.E.; Mehta, D.D. Clinical utility of the ratio of sound pressure level to subglottal pressure in patients surgically treated for phonotraumatic vocal fold lesions. J. Speech. Lang. Hear. Res. 2022; in press. [Google Scholar]
- Plant, R.L.; Hillel, A.D. Direct measurement of subglottic pressure and laryngeal resistance in normal subjects and in spasmodic dysphonia. J. Voice 1998, 12, 300–314. [Google Scholar] [CrossRef]
- Sundberg, J.; Scherer, R.; Hess, M.; Müller, F.; Granqvist, S. Subglottal pressure oscillations accompanying phonation. J. Voice 2013, 27, 411–421. [Google Scholar] [CrossRef]
- van den Berg, J. Direct and indirect determination of the mean subglottic pressure: Sound level, mean subglottic pressure, mean air flow, “subglottic power” and “efficiency” of a male voice for the vowel (a). Folia Phoniatr. 1956, 8, 1–24. [Google Scholar] [CrossRef]
- Cranen, B.; Boves, L. Pressure measurements during speech production using semiconductor miniature pressure transducers: Impact on models for speech production. J. Acoust. Soc. Am. 1985, 77, 1543–1551. [Google Scholar] [CrossRef]
- Tanaka, S.; Gould, W.J. Relationships between vocal intensity and noninvasively obtained aerodynamic parameters in normal subjects. J. Acoust. Soc. Am. 1983, 73, 1316–1321. [Google Scholar] [CrossRef] [PubMed]
- Hixon, T.J. Some new techniques for measuring the biomechanical events of speech production: One laboratory’s experiences. Am. Speech Hear. Assoc. Rep. 1972, 7, 68–103. [Google Scholar]
- Schutte, H.K. The Efficiency of Voice Production; State University Hospital: Gröningen, The Netherlands, 1980. [Google Scholar]
- Rothenberg, M. A new inverse filtering technique for deriving glottal air flow waveform during voicing. J. Acoust. Soc. Am. 1973, 53, 1632–1645. [Google Scholar] [CrossRef] [PubMed]
- Löfqvist, A.; Carlborg, B.; Kitzing, P. Initial validation of an indirect measure of subglottal pressure during vowels. J. Acoust. Soc. Am. 1982, 72, 633–635. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Leder, C.; Bichler, A. Estimating subglottal pressure using incomplete airflow interruption. Laryngoscope 2006, 116, 89–92. [Google Scholar] [CrossRef]
- Jiang, J.; O’Mara, T.; Conley, D.; Hanson, D. Phonation threshold pressure measurements during phonation by airflow interruption. Laryngoscope 1999, 109, 425–432. [Google Scholar] [CrossRef]
- Patel, R.R.; Awan, S.N.; Barkmeier-Kraemer, J.; Courey, M.; Deliyski, D.; Eadie, T.; Paul, D.; Svec, J.G.; Hillman, R. Recommended protocols for instrumental assessment of voice: American Speech-Language-Hearing Association Expert Panel to develop a protocol for instrumental assessment of vocal function. Am. J. Speech Lang. Pathol. 2018, 27, 887–905. [Google Scholar] [CrossRef]
- Fryd, A.S.; Van Stan, J.H.; Hillman, R.E.; Mehta, D.D. Estimating subglottal pressure from neck-surface acceleration during normal voice production. J. Speech Lang. Hear. Res. 2016, 59, 1335–1345. [Google Scholar] [CrossRef] [Green Version]
- McKenna, V.S.; Llico, A.F.; Mehta, D.D.; Perkell, J.S.; Stepp, C.E. Magnitude of neck-surface vibration as an estimate of subglottal pressure during modulations of vocal effort and intensity in healthy speakers. J. Speech Lang. Hear. Res. 2017, 60, 3404–3416. [Google Scholar] [CrossRef]
- Lin, J.Z.; Espinoza, V.M.; Marks, K.L.; Zañartu, M.; Mehta, D.D. Improved subglottal pressure estimation from neck-surface vibration in healthy speakers producing non-modal phonation. IEEE J. Sel. Top. Signal Process. 2020, 14, 449–460. [Google Scholar] [CrossRef]
- Espinoza, V.M.; Mehta, D.D.; Van Stan, J.H.; Hillman, R.E.; Zañartu, M. Glottal aerodynamics estimated from neck-surface vibration in women with phonotraumatic and nonphonotraumatic vocal hyperfunction. J. Speech Lang. Hear. Res. 2020, 63, 2861–2869. [Google Scholar] [CrossRef] [PubMed]
- Ibarra, E.J.; Parra, J.A.; Alzamendi, G.A.; Cortés, J.P.; Espinoza, V.M.; Mehta, D.D.; Hillman, R.E.; Zañartu, M. Estimation of subglottal pressure, vocal fold collision pressure, and intrinsic laryngeal muscle activation from neck-surface vibration using a neural network framework and a voice production model. Front. Physiol. 2021, 12, 732244. [Google Scholar] [CrossRef] [PubMed]
- Zañartu, M.; Ho, J.C.; Kraman, S.S.; Pasterkamp, H.; Huber, J.E.; Wodicka, G.R. Air-borne and tissue-borne sensitivities of bioacoustic sensors used on the skin surface. IEEE Trans. Biomed. Eng. 2009, 56, 443–451. [Google Scholar] [CrossRef]
- Cheyne, H.A.; Hanson, H.M.; Genereux, R.P.; Stevens, K.N.; Hillman, R.E. Development and testing of a portable vocal accumulator. J. Speech Lang. Hear. Res. 2003, 46, 1457–1467. [Google Scholar] [CrossRef]
- Porter, H.C. Extraction of Pitch from the Trachea; Research Note; Air Force Cambridge Research Laboratories, Office of Aerospace Research, United States Air Force: L.G. Hanscom Field, MA, USA, 1963; AFCRL-63-24. [Google Scholar]
- Zañartu, M.; Ho, J.C.; Mehta, D.D.; Hillman, R.E.; Wodicka, G.R. Subglottal impedance-based inverse filtering of voiced sounds using neck surface acceleration. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1929–1939. [Google Scholar] [CrossRef]
- Popolo, P.S.; Švec, J.G.; Titze, I.R. Adaptation of a Pocket PC for use as a wearable voice dosimeter. J. Speech Lang. Hear. Res. 2005, 48, 780–791. [Google Scholar] [CrossRef]
- Lindstrom, F.; Waye, K.P.; Södersten, M.; McAllister, A.; Ternström, S. Observations of the relationship between noise exposure and preschool teacher voice usage in day-care center environments. J. Voice 2011, 25, 166–172. [Google Scholar] [CrossRef]
- Mehta, D.D.; Zañartu, M.; Feng, S.W.; Cheyne II, H.A.; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [Green Version]
- Coleman, R.F. Comparison of microphone and neck-mounted accelerometer monitoring of the performing voice. J. Voice 1988, 2, 200–205. [Google Scholar] [CrossRef]
- Gunter, H.E.; Howe, R.D.; Zeitels, S.M.; Kobler, J.B.; Hillman, R.E. Measurement of vocal fold collision forces during phonation: Methods and preliminary data. J. Speech Lang. Hear. Res. 2005, 48, 567–576. [Google Scholar] [CrossRef]
- Mehta, D.; Van Stan, J.; Hillman, R. Relationships between vocal function measures derived from an acoustic microphone and a subglottal neck-surface accelerometer. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 659–668. [Google Scholar] [CrossRef] [PubMed]
- Švec, J.G.; Titze, I.R.; Popolo, P.S. Estimation of sound pressure levels of voiced speech from skin vibration of the neck. J. Acoust. Soc. Am. 2005, 117, 1386–1394. [Google Scholar] [CrossRef]
- Titze, I.R.; Švec, J.G.; Popolo, P.S. Vocal dose measures: Quantifying accumulated vibration exposure in vocal fold tissues. J. Speech Lang. Hear. Res. 2003, 46, 919–932. [Google Scholar] [CrossRef]
- Titze, I.R.; Hunter, E.J. Comparison of vocal vibration-dose measures for potential-damage risk criteria. J. Speech Lang. Hear. Res. 2015, 58, 1425–1439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Titze, I.R.; Sundberg, J. Vocal intensity in speakers and singers. J. Acoust. Soc. Am. 1992, 91, 2936–2946. [Google Scholar] [CrossRef] [PubMed]
- Titze, I.R. Phonation threshold pressure: A missing link in glottal aerodynamics. J. Acoust. Soc. Am. 1992, 91, 2926–2935. [Google Scholar] [CrossRef] [PubMed]
- Holmberg, E.B.; Hillman, R.E.; Perkell, J.S. Glottal airflow and transglottal air pressure measurements for male and female speakers in soft, normal, and loud voice. J. Acoust. Soc. Am. 1988, 84, 511–529. [Google Scholar] [CrossRef]
- Marks, K.L.; Lin, J.Z.; Fox, A.B.; Toles, L.E.; Mehta, D.D. Impact of nonmodal phonation on estimates of subglottal pressure from neck-surface acceleration in healthy speakers. J. Speech Lang. Hear. Res. 2019, 62, 3339–3358. [Google Scholar] [CrossRef]
- Marks, K.L.; Lin, J.Z.; Burns, J.A.; Hron, T.A.; Hillman, R.E.; Mehta, D.D. Estimation of subglottal pressure from neck surface vibration in patients with voice disorders. J. Speech Lang. Hear. Res. 2020, 63, 2202–2218. [Google Scholar] [CrossRef]
- Castellana, A.; Carullo, A.; Corbellini, S.; Astolfi, A. Discriminating pathological voice from healthy voice using cepstral peak prominence smoothed distribution in sustained vowel. IEEE Trans. Instrum. Meas. 2018, 67, 646–654. [Google Scholar] [CrossRef]
- Hillenbrand, J.; Cleveland, R.A.; Erickson, R.L. Acoustic correlates of breathy vocal quality. J. Speech Hear. Res. 1994, 37, 769–778. [Google Scholar] [CrossRef] [PubMed]
- Hillenbrand, J.; Houde, R.A. Acoustic correlates of breathy vocal quality: Dysphonic voices and continuous speech. J. Speech Hear. Res. 1996, 39, 311–321. [Google Scholar] [CrossRef] [PubMed]
- Heman-Ackah, Y.D.; Heuer, R.J.; Michael, D.D.; Ostrowski, R.; Horman, M.; Baroody, M.M.; Hillenbrand, J.; Sataloff, R.T. Cepstral peak prominence: A more reliable measure of dysphonia. Ann. Otol. Rhinol. Laryngol. 2003, 112, 324–333. [Google Scholar] [CrossRef]
- Awan, S.N.; Roy, N.; Jetté, M.E.; Meltzner, G.S.; Hillman, R.E. Quantifying dysphonia severity using a spectral/cepstral-based acoustic index: Comparisons with auditory-perceptual judgements from the CAPE-V. Clin. Linguist. Phon. 2010, 24, 742–758. [Google Scholar] [CrossRef]
- Espinoza, V.M.; Zañartu, M.; Van Stan, J.H.; Mehta, D.D.; Hillman, R.E. Glottal aerodynamic measures in women with phonotraumatic and nonphonotraumatic vocal hyperfunction. J. Speech Lang. Hear. Res. 2017, 60, 2159–2169. [Google Scholar] [CrossRef] [PubMed]
- Zeitels, S.M.; Hillman, R.E.; Desloge, R.B.; Bunting, G.A. Cricothyroid subluxation: A new innovation for enhancing the voice with laryngoplastic phonosurgery. Ann. Otol. Rhinol. Laryngol. 1999, 108, 1126–1131. [Google Scholar] [CrossRef]
- Gillespie, A.I.; Gartner-Schmidt, J.; Rubinstein, E.N.; Abbott, K.V. Aerodynamic profiles of women with muscle tension dysphonia/aphonia. J. Speech Lang. Hear. Res. 2013, 56, 481–488. [Google Scholar] [CrossRef]
- Dastolfo, C.; Gartner-Schmidt, J.; Yu, L.; Carnes, O.; Gillespie, A.I. Aerodynamic outcomes of four common voice disorders: Moving toward disorder-specific assessment. J. Voice 2016, 30, 301–307. [Google Scholar] [CrossRef]
- Ghassemi, M.; Van Stan, J.H.; Mehta, D.D.; Zañartu, M.; Cheyne, H.A., II; Hillman, R.E.; Guttag, J.V. Learning to detect vocal hyperfunction from ambulatory neck-surface acceleration features: Initial results for vocal fold nodules. IEEE Trans. Biomed. Eng. 2014, 61, 1668–1675. [Google Scholar] [CrossRef] [Green Version]
- Hillman, R.E.; Mehta, D.D. Ambulatory monitoring of daily voice use. Perspect. Voice Voice Disord. 2011, 21, 56–61. [Google Scholar] [CrossRef] [Green Version]
- Llico, A.F.; Zañartu, M.; González, A.J.; Wodicka, G.R.; Mehta, D.D.; Van Stan, J.H.; Hillman, R.E. Real-time estimation of aerodynamic features for ambulatory voice biofeedback. J. Acoust. Soc. Am. 2015, 138, EL14–EL19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, D.D.; Van Stan, J.H.; Zañartu, M.; Ghassemi, M.; Guttag, J.V.; Espinoza, V.M.; Cortés, J.P.; Cheyne, H.A., II; Hillman, R.E. Using ambulatory voice monitoring to investigate common voice disorders: Research update. Front. Bioeng. Biotechnol. 2015, 3, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, D.D.; Woodbury Listfield, R.; Cheyne, H.A., II; Heaton, J.T.; Feng, S.W.; Zañartu, M.; Hillman, R.E. Duration of ambulatory monitoring needed to accurately estimate voice use. In Proceedings of the INTERSPEECH 2012, Portland, OR, USA, 9–13 September 2012; pp. 1335–1338. [Google Scholar]
- Van Stan, J.H.; Mehta, D.D.; Hillman, R.E. The effect of voice ambulatory biofeedback on the daily performance and retention of a modified vocal motor behavior in participants with normal voices. J. Speech Lang. Hear. Res. 2015, 58, 713–721. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Mehta, D.D.; Zeitels, S.M.; Burns, J.A.; Barbu, A.M.; Hillman, R.E. Average ambulatory measures of sound pressure level, fundamental frequency, and vocal dose do not differ between adult females with phonotraumatic lesions and matched control subjects. Ann. Otol. Rhinol. Laryngol. 2015, 124, 864–874. [Google Scholar] [CrossRef] [Green Version]
- Bottalico, P.; Ipsaro Passione, I.; Astolfi, A.; Carullo, A.; Hunter, E.J. Accuracy of the quantities measured by four vocal dosimeters and its uncertainty. J. Acoust. Soc. Am. 2018, 143, 1591–1602. [Google Scholar] [CrossRef]
- Nusseck, M.; Richter, B.; Spahn, C.; Echternach, M. Analysing the vocal behaviour of teachers during classroom teaching using a portable voice accumulator. Logop. Phoniatr. Vocol. 2018, 43, 1–10. [Google Scholar] [CrossRef]
- Holmberg, E.B.; Hillman, R.E.; Perkell, J.S. Glottal airflow and transglottal air pressure measurements for male and female speakers in low, normal, and high pitch. J. Voice 1989, 3, 294–305. [Google Scholar] [CrossRef]
- Hillman, R.E.; Holmberg, E.B.; Perkell, J.S.; Walsh, M.; Vaughan, C. Phonatory function associated with hyperfunctionally related vocal fold lesions. J. Voice 1990, 4, 52–63. [Google Scholar] [CrossRef]
- Holmberg, E.B.; Hillman, R.E.; Perkell, J.S.; Gress, C. Relationships between intra-speaker variation in aerodynamic measures of voice production and variation in SPL across repeated recordings. J. Speech Hear. Res. 1994, 37, 484–495. [Google Scholar] [CrossRef]
- Hillman, R.E.; Montgomery, W.W.; Zeitels, S.M. Appropriate use of objective measures of vocal function in the multidisciplinary management of voice disorders. Curr. Opin. Otolaryngol. Head Neck Surg. 1997, 5, 172–175. [Google Scholar] [CrossRef]
- Galletti, B.; Sireci, F.; Mollica, R.; Iacona, E.; Freni, F.; Martines, F.; Scherdel, E.P.; Bruno, R.; Longo, P.; Galletti, F. Vocal Tract Discomfort Scale (VTDS) and Voice Symptom Scale (VoiSS) in the early identification of Italian teachers with voice disorders. Int. Arch. Otorhinolaryngol. 2020, 24, e323–e329. [Google Scholar] [CrossRef] [PubMed]
- Marks, K.L.; Verdi, A.; Toles, L.E.; Stipancic, K.L.; Ortiz, A.J.; Hillman, R.E.; Mehta, D.D. Psychometric analysis of an ecological vocal effort scale in individuals with and without vocal hyperfunction during activities of daily living. Am. J. Speech Lang. Pathol. 2021, 30, 2589–2604. [Google Scholar] [CrossRef]
- Baldner, E.F.; Doll, E.; van Mersbergen, M.R. A review of measures of vocal effort with a preliminary study on the establishment of a vocal effort measure. J. Voice 2015, 29, 530–541. [Google Scholar] [CrossRef] [PubMed]
- van Leer, E.; van Mersbergen, M. Using the Borg CR10 physical exertion scale to measure patient-perceived vocal effort pre and post treatment. J. Voice 2017, 31, 389.e19–389.e25. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.D.; Hillman, R.E. Current role of stroboscopy in laryngeal imaging. Curr. Opin. Otolaryngol. Head Neck Surg. 2012, 20, 429–436. [Google Scholar] [CrossRef] [Green Version]
- Hogikyan, N.D.; Sethuraman, G. Validation of an instrument to measure voice-related quality of life (V-RQOL). J. Voice 1999, 13, 557–569. [Google Scholar] [CrossRef]
- Kempster, G.B.; Gerratt, B.R.; Verdolini Abbott, K.; Barkmeier-Kraemer, J.; Hillman, R.E. Consensus auditory-perceptual evaluation of voice: Development of a standardized clinical protocol. Am. J. Speech Lang. Pathol. 2009, 18, 124–132. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.D.; Zañartu, M.; Van Stan, J.H.; Feng, S.W.; Cheyne II, H.A.; Hillman, R.E. Smartphone-Based Detection of Voice Disorders by Long-Term Monitoring of Neck Acceleration Features. In Proceedings of the IEEE International Conference on Body Sensor Networks, Cambridge, MA, USA, 6–9 May 2013; pp. 1–6. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer; Amsterdam, The Netherlands; Available online: http://www.praat.org (accessed on 1 July 2017).
- Cortés, J.P.; Espinoza, V.M.; Ghassemi, M.; Mehta, D.D.; Van Stan, J.H.; Hillman, R.E.; Guttag, J.V.; Zañartu, M. Ambulatory assessment of phonotraumatic vocal hyperfunction using glottal airflow measures estimated from neck-surface acceleration. PLoS ONE 2018, 13, e0209017. [Google Scholar] [CrossRef] [Green Version]
- Galindo, G.E.; Peterson, S.D.; Erath, B.D.; Castro, C.; Hillman, R.E.; Zañartu, M. Modeling the pathophysiology of phonotraumatic vocal hyperfunction with a triangular glottal model of the vocal folds. J. Speech Lang. Hear. Res. 2017, 60, 2452–2471. [Google Scholar] [CrossRef] [Green Version]
- Van Stan, J.H.; Mehta, D.D.; Petit, R.J.; Sternad, D.; Muise, J.; Burns, J.A.; Hillman, R.E. Integration of motor learning principles into real-time ambulatory voice biofeedback and example implementation via a clinical case study with vocal fold nodules. Am. J. Speech Lang. Pathol. 2017, 26, 1–10. [Google Scholar] [CrossRef]
- Manriquez, R.; Espinoza, V.M.; Castro, C.; Cortes, J.P.; Zañartu, M. Parameter analysis and uncertainties of impedance-based inverse filtering from neck surface acceleration. In Proceedings of the 14th International Conference on Advances in Quantitative Laryngology, Voice and Speech Research (AQL 2021), Bogotá, Colombia, 9–10 June 2021. [Google Scholar]
- Cortés, J.P.; Alzamendi, G.A.; Weinstein, A.J.; Yuz, J.I.; Espinoza, V.M.; Mehta, D.D.; Hillman, R.E.; Zañartu, M. Kalman filter implementation of subglottal impedance-based inverse filtering to estimate glottal airflow during phonation. Appl. Sci. 2022, 12, 401. [Google Scholar] [CrossRef]
- Van Stan, J.H.; Mehta, D.D.; Ortiz, A.J.; Burns, J.A.; Toles, L.E.; Marks, K.L.; Vangel, M.; Hron, T.; Zeitels, S.; Hillman, R.E. Differences in weeklong ambulatory vocal behavior between female patients with phonotraumatic lesions and matched controls. J. Speech Lang. Hear. Res. 2020, 63, 372–384. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Mehta, D.D.; Ortiz, A.J.; Burns, J.A.; Marks, K.L.; Toles, L.E.; Stadelman-Cohen, T.; Krusemark, C.; Muise, J.; Hron, T.; et al. Changes in a Daily Phonotrauma Index after laryngeal surgery and voice therapy: Implications for the role of daily voice use in the etiology and pathophysiology of phonotraumatic vocal hyperfunction. J. Speech Lang. Hear. Res. 2020, 63, 3934–3944. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Ortiz, A.J.; Cortes, J.P.; Marks, K.L.; Toles, L.E.; Mehta, D.D.; Burns, J.A.; Hron, T.; Stadelman-Cohen, T.; Krusemark, C.; et al. Differences in daily voice use measures between female patients with nonphonotraumatic vocal hyperfunction and matched controls. J. Speech Lang. Hear. Res. 2021, 64, 1457–1470. [Google Scholar] [CrossRef]
- Van Stan, J.H.; Ortiz, A.J.; Marks, K.L.; Toles, L.E.; Mehta, D.D.; Burns, J.A.; Hron, T.; Stadelman-Cohen, T.; Krusemark, C.; Muise, J.; et al. Changes in the Daily Phonotrauma Index following the use of voice therapy as the sole treatment for phonotraumatic vocal hyperfunction in females. J. Speech Lang. Hear. Res. 2021, 64, 3446–3455. [Google Scholar] [CrossRef]
- Van Stan, J.H.; Ortiz, A.J.; Sternad, D.; Mehta, D.D.; Huo, C.; Hillman, R.E. Ambulatory voice biofeedback: Acquisition and retention of modified daily voice use in patients with phonotraumatic vocal hyperfunction. Am. J. Speech Lang. Pathol. 2022, 31, 409–418. [Google Scholar] [CrossRef]
- Mehta, D.D.; Kobler, J.B.; Zeitels, S.M.; Zañartu, M.; Erath, B.D.; Motie-Shirazi, M.; Peterson, S.D.; Petrillo, R.H.; Hillman, R.E. Toward development of a vocal fold contact pressure probe: Bench-top validation of a dual-sensor probe using excised human larynx models. Appl. Sci. 2019, 9, 4360. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.D.; Kobler, J.B.; Zeitels, S.M.; Zañartu, M.; Ibarra, E.J.; Alzamendi, G.A.; Manriquez, R.; Erath, B.D.; Peterson, S.D.; Petrillo, R.H.; et al. Direct measurement and modeling of intraglottal, subglottal, and vocal fold collision pressures during phonation in an individual with a hemilaryngectomy. Appl. Sci. 2021, 11, 7256. [Google Scholar] [CrossRef]
- Maffei, M. Self-Ratings of Vocal Fatigue in Daily Life for Individuals with Muscle Tension Dysphonia and Healthy Controls. Master’s Thesis, MGH Institute of Health Professions, Boston, MA, USA, 2016. [Google Scholar]
- Mehta, D.D.; Van Stan, J.H.; Masson, M.L.V.; Maffei, M.; Hillman, R.E. Relating ambulatory voice measures with self-ratings of vocal fatigue in individuals with phonotraumatic vocal hyperfunction. J. Acoust. Soc. Am. 2017, 141, 3838. [Google Scholar] [CrossRef]
- Nudelman, C.J.; Ortiz, A.J.; Fox, A.B.; Mehta, D.D.; Hillman, R.E.; Van Stan, J.H. Daily Phonotrauma Index: An objective indicator of large differences in self-reported vocal status in the daily life of females with phonotraumatic vocal hyperfunction. Am. J. Speech Lang. Pathol. 2022, 31, 1412–1423. [Google Scholar] [CrossRef]
- Lien, Y.-A.S.; Michener, C.M.; Eadie, T.L.; Stepp, C.E. Individual monitoring of vocal effort with relative fundamental frequency--Relationships with aerodynamics and listener perception. J. Speech Lang. Hear. Res. 2015, 58, 566–575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fontanet, J.G.; Yuz, J.I.; Zañartu, M. Parametric identification of a linear time invariant model for a subglottal system. IFAC-PapersOnLine 2021, 54, 577–582. [Google Scholar] [CrossRef]
- McHenry, M.A.; Kuna, S.T.; Minton, J.T.; Vanoye, C.R. Comparison of direct and indirect calculations of laryngeal airway resistance in connected speech. J. Voice 1996, 10, 236–244. [Google Scholar] [CrossRef]
- Perrine, B.L.; Scherer, R.C.; Whitfield, J.A. Signal interpretation considerations when estimating subglottal pressure from oral air pressure. J. Speech Lang. Hear. Res. 2019, 62, 1326–1337. [Google Scholar] [CrossRef]
- Hertegård, S.; Gauffin, J.; Lindestad, P.-A. A comparison of subglottal and intraoral pressure measurements during phonation. J. Voice 1995, 9, 149–155. [Google Scholar] [CrossRef]






| Group | No. Female (Male) | Mean (SD) Age (Years) | Age Range (Years) |
|---|---|---|---|
| PVH | 10 (0) | 29 (18) | 18–62 |
| NPVH | 7 (3) | 35 (11) | 19–64 |
| UVFP | 6 (4) | 45 (15) | 22–60 |
| Controls | 18 (8) | 31 (13) | 19–50 |
| Measure | Units | Description |
|---|---|---|
| RMS | cm/s2 | Root-mean-square signal magnitude |
| fo | Hz | Fundamental frequency |
| CPP | dB | Cepstral peak prominence |
| ACFL | mL/s | Peak-to-peak amplitude of the glottal airflow waveform |
| MFDR | L/s2 | Maximum flow declination rate: Negative peak of the first derivative of the glottal airflow waveform |
| OQ | % | Open quotient: Ratio of the open time of the glottal airflow waveform to the corresponding cycle period (tO/tC) |
| SQ | % | Speed quotient: Ratio of the opening time of the glottal airflow waveform to the closing time (100 × top/tcp) |
| H1–H2 | dB | Difference between the log-magnitude of the first two harmonics of the glottal airflow waveform |
| HRF | dB | Harmonic richness factor: Ratio of the sum of the first eight harmonic log-magnitudes to the first harmonic magnitude of the glottal airflow waveform |
| NAQ | a.u. | Normalized amplitude quotient: Ratio of ACFL to MFDR (ACFL/MFDR) divided by the glottal period (tO + tC) of the glottal airflow waveform |
| Feature | Units | VAD Criteria | Description |
|---|---|---|---|
| Sound pressure level @ 15 cm | dB SPL | 45–130 | Acceleration amplitude mapped to acoustic sound pressure level [57] |
| Fundamental frequency | Hz | 70–1000 | Reciprocal of first non-zero peak location in the normalized autocorrelation function [53] |
| Autocorrelation peak amplitude | a.u. | 0.60–1 | Amplitude of first non-zero peak in the normalized autocorrelation function [77,98] |
| Subharmonic peak | a.u. | 0.25–1 | Amplitude of a secondary peak, if it exists, located between the zero-lag and the autocorrelation peak in the normalized autocorrelation function [77,98] |
| Low-to-high spectral power ratio | dB | 22–50 | Difference between spectral power below and above 2000 Hz [77] |
| Group | Method 1 | Method 2 | Method 3 | Method 4 | Overall Severity |
|---|---|---|---|---|---|
| PVH | 4.10 (3.06) | 2.10 (1.04) | 1.61 (0.60) | 3.18 (1.73) | 22.4 (18.0) |
| NPVH | 3.76 (1.62) | 2.08 (0.90) | 2.08 (0.60) | 3.51 (2.07) | 25.3 (29.5) |
| UVFP | 4.74 (2.44) | 2.06 (0.71) | 1.75 (0.67) | 4.86 (2.66) | 54.5 (27.4) |
| Control | 2.96 (1.42) | 1.51 (0.48) | 1.13 (0.37) | 2.89 (0.82) | N/A |
| Effect | ||||
|---|---|---|---|---|
| Participant Group | 3 | 0.188 | 8.32 | <0.0001 |
| Ps Estimation Method | 3 | 0.750 | 33.25 | <0.0001 |
| Participant Group × Ps Estimation Method | 9 | 0.062 | 0.91 | 0.516 |
| Group | RMS | CPP | fo | ACFL | MFDR | OQ | NAQ | HRF | H1–H2 |
|---|---|---|---|---|---|---|---|---|---|
| PVH (n = 10) | 9 (90%) | 6 (60%) | 9 (90%) | 4 (40%) | 7 (70%) | 5 (50%) | 5 (50%) | 2 (20%) | 4 (40%) |
| NPVH (n = 10) | 8 (80%) | 7 (70%) | 6 (60%) | 5 (50%) | 5 (50%) | 5 (50%) | 3 (30%) | 4 (40%) | 3 (30%) |
| UVFP (n = 10) | 10 (100%) | 2 (20%) | 6 (60%) | 4 (40%) | 7 (70%) | 2 (20%) | 4 (40%) | 4 (40%) | 4 (40%) |
| Control (n = 26) | 25 (96%) | 16 (62%) | 18 (69%) | 11 (42%) | 13 (50%) | 10 (38%) | 10 (38%) | 13 (50%) | 14 (54%) |
| Average (%) | 92% | 53% | 70% | 43% | 60% | 40% | 40% | 38% | 41% |
| Ambulatory Statistic | PVH | NPVH | UVFP | Control |
| Monitoring duration (hh:mm:ss) | 11:27:43 (04:28:38) | 10:24:52 (02:18:50) | 10:21:54 (03:36:12) | 10:51:05 (02:49:34) |
| Phonation time | ||||
| Cumulative (mm:ss) | 48:45 (32:39) | 52:56 (33:22) | 28:39 (23:22) | 44:43 (28:14) |
| Normalized (%) | 7.1 (4.7) | 8.5 (5.3) | 4.6 (3.8) | 6.9 (4.3) |
| Ps (cm H2O) | ||||
| Mean | 11.7 (2.8) | 13.9 (8.1) | 8.2 (3.3) | 8.2 (3.6) |
| Mode | 9.2 (4.3) | 8.1 (4.0) | 5.8 (4.4) | 6.1 (2.7) |
| Standard deviation | 5.3 (1.9) | 6.4 (5.5) | 2.7 (2.0) | 3.9 (2.7) |
| Skewness | 1.957 (0.908) | 1.613 (0.540) | 2.474 (0.813) | 2.309 (1.017) |
| Minimum * | 5.8 (1.5) | 6.3 (2.5) | 5.6 (3.1) | 4.3 (1.3) |
| Maximum * | 21.5 (5.7) | 25.7 (18.0) | 13.3 (6.2) | 15.5 (9.1) |
| SPL (dB SPL @ 15 cm) | ||||
| Mean | 87.0 (8.0) | 82.7 (11.5) | 85.8 (8.4) | 86.0 (8.6) |
| Standard deviation | 7.7 (2.3) | 7.2 (2.4) | 7.0 (3.0) | 7.2 (2.6) |
| Skewness | −0.448 (0.417) | −0.459 (0.279) | −0.073 (0.476) | −0.187 (0.357) |
| Minimum * | 73.5 (4.2) | 73.1 (7.2) | 70.6 (11.5) | 64.8 (8.1) |
| Maximum * | 97.2 (4.8) | 98.0 (9.4) | 94.0 (12.8) | 93.7 (9.7) |
| CPP (dB) | ||||
| Mean | 22.0 (1.3) | 18.8 (2.0) | 21.7 (1.7) | 18.7 (1.9) |
| Standard deviation | 4.2 (0.4) | 3.1 (0.7) | 3.9 (0.8) | 3.1 (0.7) |
| Skewness | −0.233 (0.219) | −0.212 (0.209) | −0.037 (0.180) | −0.115 (0.281) |
| Minimum * | 14.9 (0.6) | 14.7 (0.7) | 13.5 (0.8) | 14.6 (0.8) |
| Maximum * | 28.6 (1.1) | 28.3 (1.5) | 23.7 (2.9) | 28.4 (1.7) |
| H1−H2 (dB) | ||||
| Mean | 4.5 (2.1) | 8.3 (3.3) | 5.7 (4.0) | 8.3 (3.3) |
| Standard deviation | 7.6 (1.1) | 5.8 (1.1) | 6.8 (2.0) | 5.9 (1.0) |
| Skewness | 0.673 (0.433) | 0.669 (0.452) | 0.202 (0.394) | 0.552 (0.366) |
| Minimum * | −3.8 (1.6) | −5.8 (3.3) | −0.6 (3.7) | −3.7 (3.0) |
| Maximum * | 15.6 (2.7) | 18.5 (2.7) | 18.4 (2.9) | 18.1 (3.6) |
| Ambulatory Statistic | PVH | NPVH | UVFP | Control |
| ACFL (mL/s) | ||||
| Mean | 337.7 (213.3) | 482.6 (409.4) | 131.4 (131.0) | 195.6 (173.0) |
| Standard deviation | 267.5 (178.3) | 390.8 (325.6) | 109.3 (105.6) | 158.7 (142.2) |
| Skewness | 2.493 (1.653) | 2.282 (0.652) | 2.805 (1.570) | 2.680 (0.935) |
| Minimum | 48.4 (33.0) | 81.1 (88.0) | 23.5 (26.5) | 35.2 (34.5) |
| Maximum * | 831.9 (555.9) | 1260.7 (1089.7) | 323.6 (321.5) | 481.2 (430.7) |
| MFDR (L/s2) | ||||
| Mean | 529.2 (344.1) | 737.9 (624.5) | 166.5 (175.2) | 296.6 (287.1) |
| Standard deviation | 481.9 (324.9) | 659.7 (557.1) | 169.7 (175.2) | 277.5 (254.7) |
| Skewness | 2.765 (1.779) | 2.478 (0.853) | 3.292 (1.161) | 3.021 (0.899) |
| Minimum * | 49.8 (34.6) | 91.2 (97.0) | 21.8 (24.8) | 35.5 (39.0) |
| Maximum * | 1424.1 (978.9) | 2057.5 (1797.4) | 468.4 (487.9) | 792.7 (738.6) |
| OQ (%) | ||||
| Mean | 58.3 (6.9) | 57.2 (7.3) | 71.4 (10.1) | 62.4 (9.5) |
| Standard deviation | 19.2 (2.5) | 19.3 (1.4) | 15.3 (3.8) | 19.3 (3.2) |
| Skewness | 0.554 (0.591) | 0.503 (0.337) | −0.301 (0.806) | 0.109 (0.576) |
| Minimum * | 33.0 (4.2) | 31.8 (7.0) | 46.3 (12.7) | 33.7 (8.1) |
| Maximum * | 92.6 (4.2) | 92.1 (2.5) | 94.7 (2.7) | 93.7 (2.4) |
| SQ (%) | ||||
| Mean | 148.0 (10.9) | 143.6 (11.2) | 137.6 (15.9) | 147.7 (14.9) |
| Standard deviation | 69.9 (19.5) | 63.2 (21.6) | 61.1 (22.8) | 73.4 (18.8) |
| Skewness | 2.145 (0.520) | 2.079 (0.629) | 1.573 (0.457) | 1.857 (0.516) |
| Minimum * | 64.1 (23.1) | 63.6 (23.7) | 60.2 (14.4) | 55.1 (14.5) |
| Maximum * | 290.9 (66.1) | 267.5 (65.4) | 251.1 (69.8) | 290.4 (65.2) |
| H1–H2 (dB) | ||||
| Mean | 4.2 (4.5) | 2.9 (3.4) | 8.9 (6.9) | 6.1 (3.9) |
| Standard deviation | 10.8 (2.3) | 13.3 (5.8) | 9.3 (2.6) | 10.2 (2.4) |
| Skewness | 0.069 (0.825) | 0.676 (0.417) | 0.078 (0.765) | 0.280 (0.595) |
| Minimum * | −12.3 (4.2) | −17.7 (13.9) | −4.2 (8.0) | −8.8 (4.3) |
| Maximum * | 20.4 (4.4) | 27.4 (13.6) | 24.3 (4.7) | 22.0 (5.2) |
| HRF (dB) | ||||
| Mean | −2.5 (1.3) | −3.5 (2.9) | −7.6 (3.6) | −3.9 (2.4) |
| Standard deviation | 6.7 (1.6) | 8.9 (4.2) | 6.8 (1.9) | 7.6 (1.9) |
| Skewness | −3.556 (0.979) | −2.803 (1.085) | −1.390 (1.556) | −2.709 (1.164) |
| Minimum * | −15.7 (5.2) | −23.7 (16.4) | −20.2 (4.4) | −18.2 (5.7) |
| Maximum * | 2.2 (0.6) | 2.3 (1.2) | −0.2 (2.6) | 2.1 (0.9) |
| NAQ | ||||
| Mean | 0.169 (0.013) | 0.173 (0.031) | 0.212 (0.025) | 0.177 (0.024) |
| Standard deviation | 0.056 (0.007) | 0.059 (0.009) | 0.057 (0.008) | 0.063 (0.009) |
| Skewness | 1.917 (0.546) | 1.593 (0.451) | 1.201 (0.629) | 1.387 (0.517) |
| Minimum * | 0.106 (0.012) | 0.106 (0.023) | 0.136 (0.023) | 0.102 (0.019) |
| Maximum * | 0.285 (0.023) | 0.291 (0.043) | 0.316 (0.020) | 0.302 (0.028) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cortés, J.P.; Lin, J.Z.; Marks, K.L.; Espinoza, V.M.; Ibarra, E.J.; Zañartu, M.; Hillman, R.E.; Mehta, D.D. Ambulatory Monitoring of Subglottal Pressure Estimated from Neck-Surface Vibration in Individuals with and without Voice Disorders. Appl. Sci. 2022, 12, 10692. https://doi.org/10.3390/app122110692
Cortés JP, Lin JZ, Marks KL, Espinoza VM, Ibarra EJ, Zañartu M, Hillman RE, Mehta DD. Ambulatory Monitoring of Subglottal Pressure Estimated from Neck-Surface Vibration in Individuals with and without Voice Disorders. Applied Sciences. 2022; 12(21):10692. https://doi.org/10.3390/app122110692
Chicago/Turabian StyleCortés, Juan P., Jon Z. Lin, Katherine L. Marks, Víctor M. Espinoza, Emiro J. Ibarra, Matías Zañartu, Robert E. Hillman, and Daryush D. Mehta. 2022. "Ambulatory Monitoring of Subglottal Pressure Estimated from Neck-Surface Vibration in Individuals with and without Voice Disorders" Applied Sciences 12, no. 21: 10692. https://doi.org/10.3390/app122110692
APA StyleCortés, J. P., Lin, J. Z., Marks, K. L., Espinoza, V. M., Ibarra, E. J., Zañartu, M., Hillman, R. E., & Mehta, D. D. (2022). Ambulatory Monitoring of Subglottal Pressure Estimated from Neck-Surface Vibration in Individuals with and without Voice Disorders. Applied Sciences, 12(21), 10692. https://doi.org/10.3390/app122110692