
DPMF: Decentralized Probabilistic Matrix Factorization for Privacy-Preserving Recommendation




Abstract
:1. Introduction
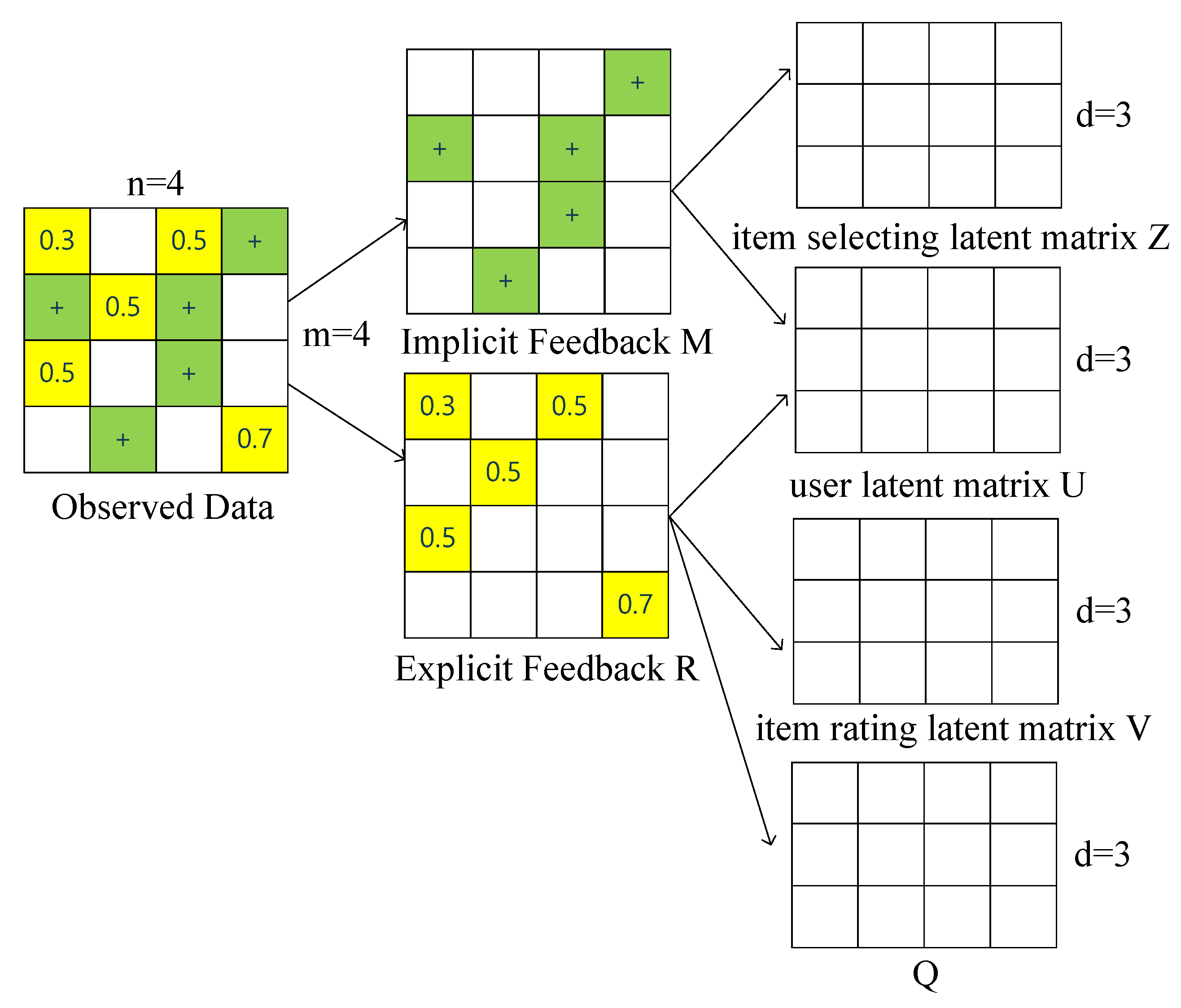
- We devise a novel probabilistic matrix factorization method for recommender systems. It uses both explicit and implicit feedback simultaneously to model user preferences and item characteristics, which is practical and interpretable in rating prediction and item recommendation.
- We propose a novel decomposing strategy to decompose the shared information among users into two parts, and only share the non-private part. In this way, the model not only gains a guarantee of convergence by exchanging the public information, but also maintains user privacy as the private information is kept locally by users.
- We propose a secure and efficient method to train our model. By finding neighbors from the trust statement, users exchange public model information with others. The public and personal model gradients are updated through stochastic gradient descent. Extensive experiments on two real-world datasets show that our method outperforms the existing state-of-the-art CF methods with lower RMSE loss in rating prediction task and higher precision in item recommendation task.
2. Background
2.1. Probabilistic Matrix Factorization
2.2. Probabilistic Model for Implicit Feedback
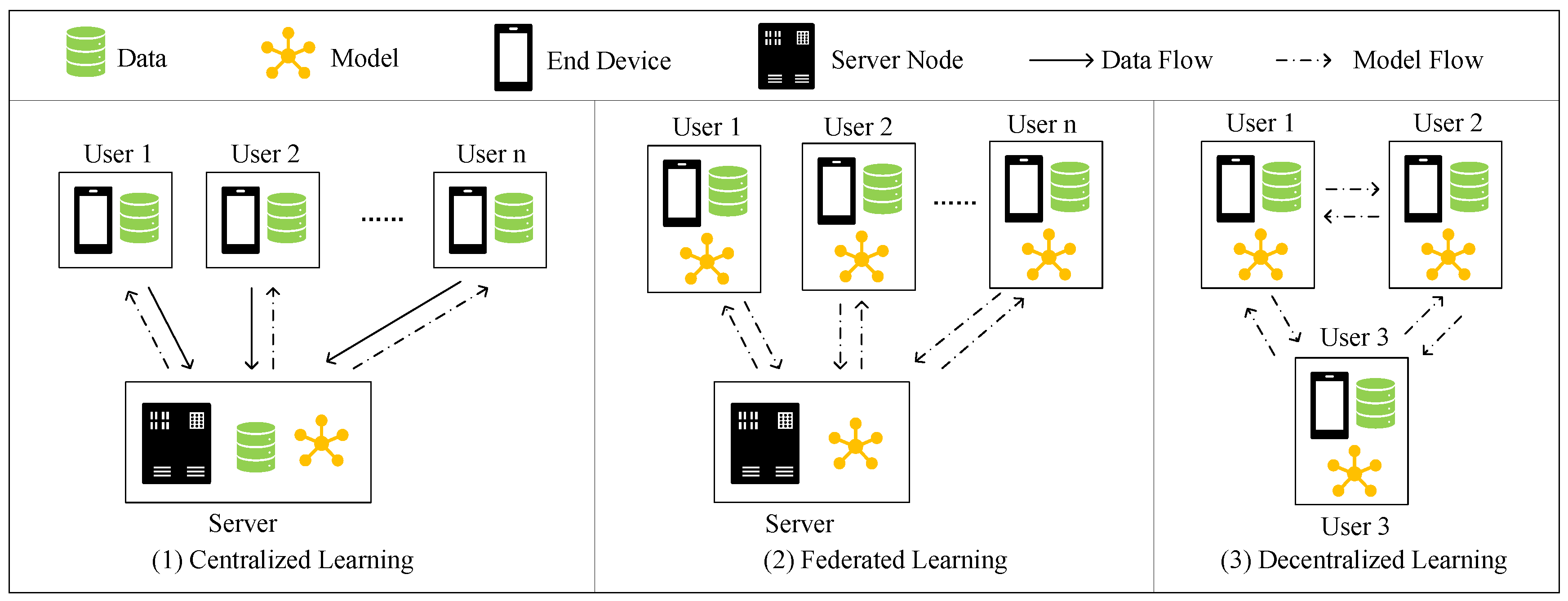
2.3. Decentralized Learning
3. The Proposed Model
3.1. Overview
3.2. Matrix Co-Factorization
| Algorithm 1: Stochastic gradient descent learning for probabilistic matrix co-factorization. |
 |
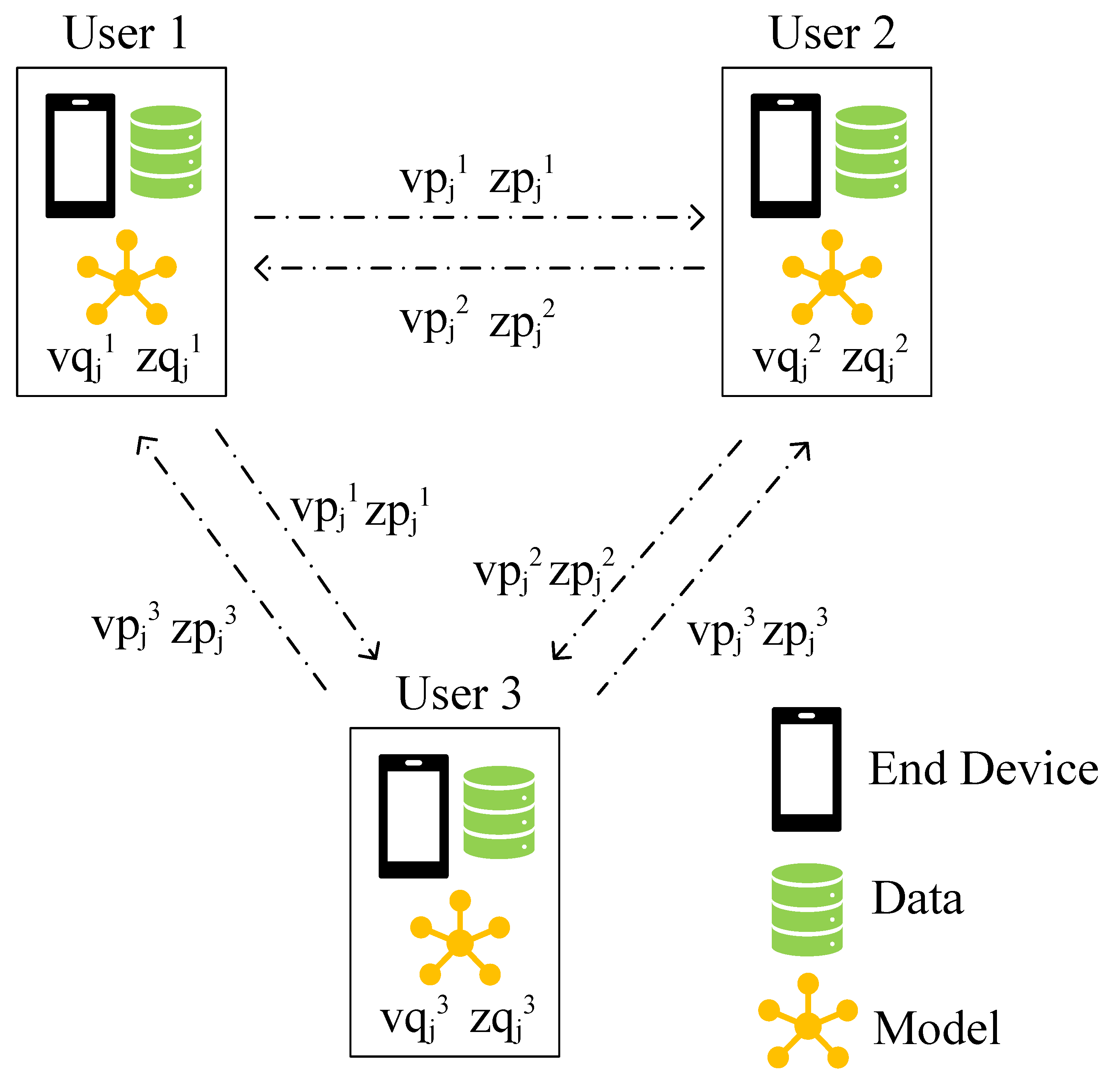
3.3. Decentralized PMF
| Algorithm 2: Decentralized PMF Algorithm. |
 |
4. Evaluation
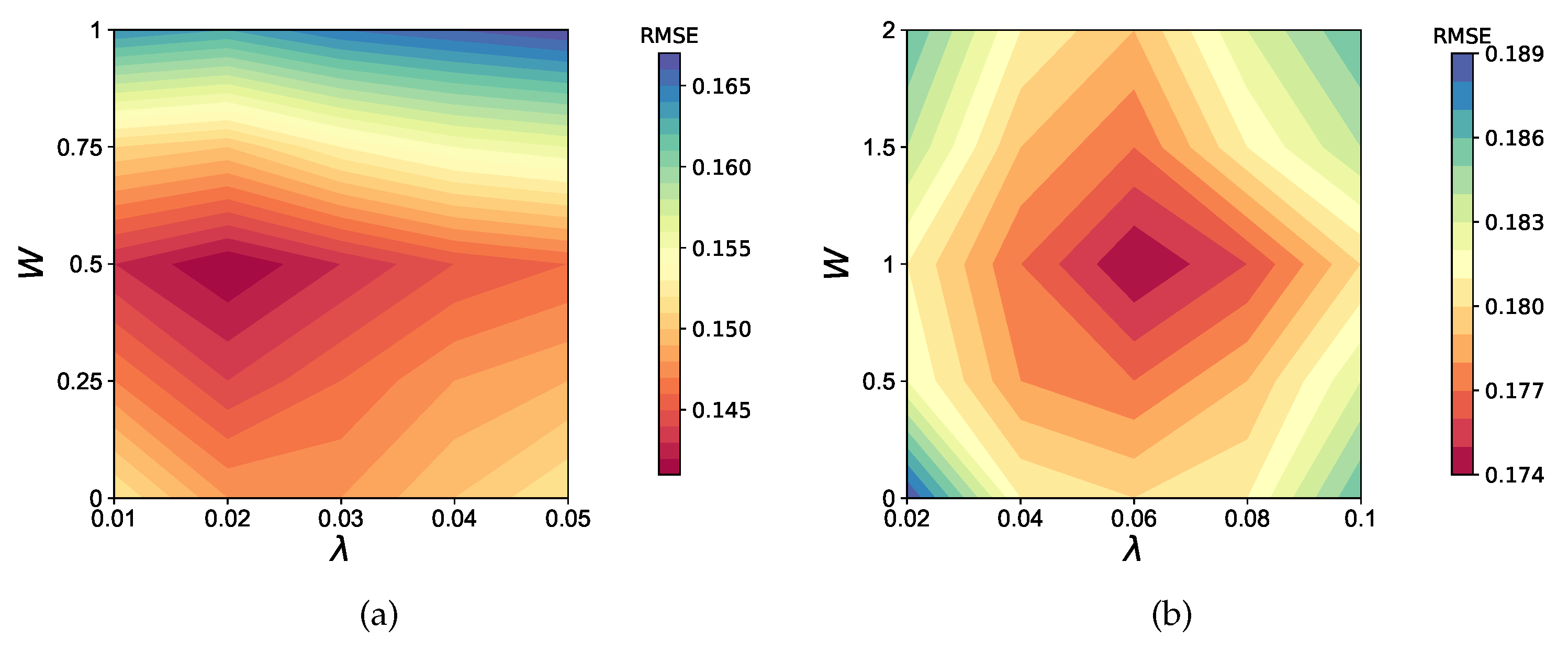
4.1. Setting
4.1.1. Datasets
4.1.2. Implicit Data
4.1.3. Neighbor Adjacent Matrix
4.1.4. Metric
4.1.5. Baseline Methods
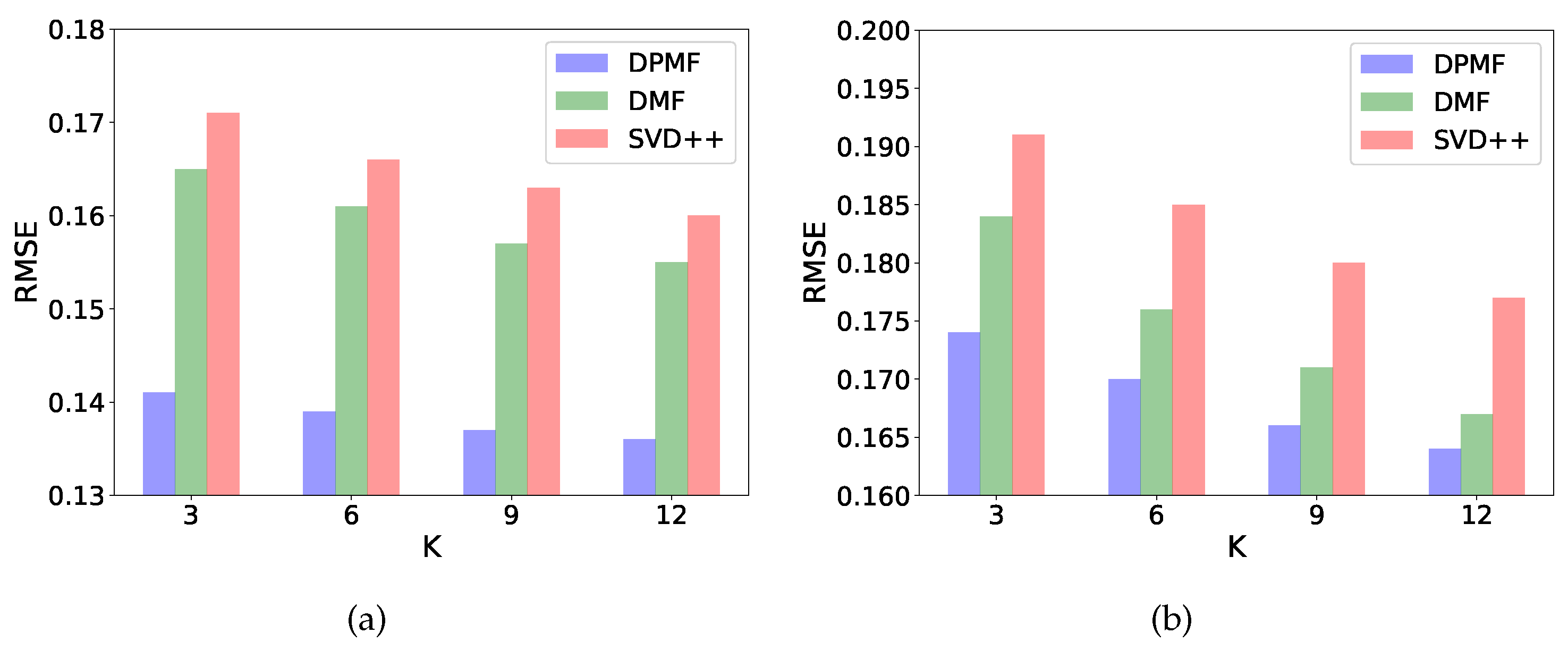
- DMF [18] is a decentralized model based on MF. It is mainly designed for point-of-interest recommendation, therefore we simplify the setting and make it practical for handling the same rating prediction problem as DPMF.
- SVD++ [25] is an improved version for MF version that takes users’ historical interactions into consideration.
- WRMF [12] is a typical centralized matrix factorization method for implicit feedback.
- PMF is the probabilistic model that we introduced in Section 2.2.
4.2. Complexity Analysis
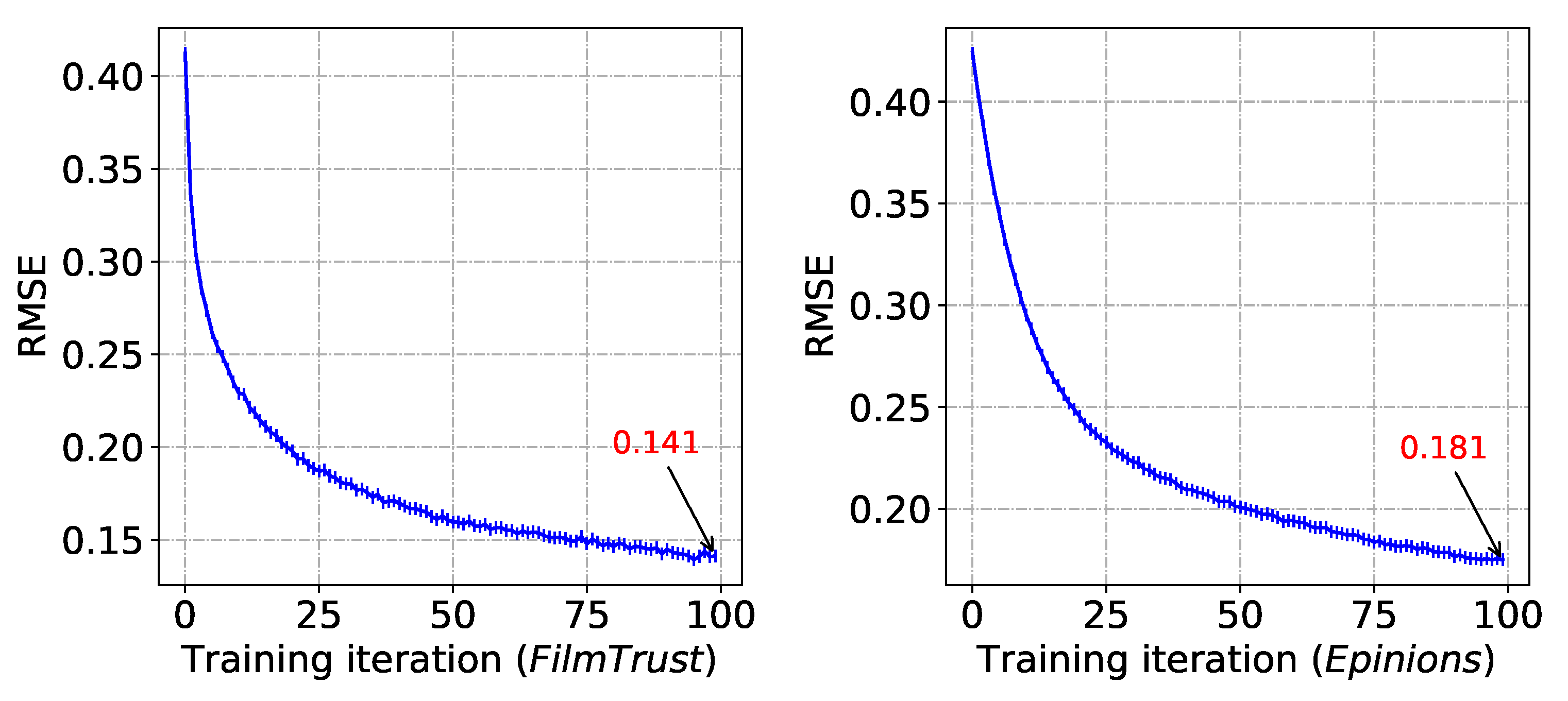
4.3. Rating Prediction
4.4. Item Recommendation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alhijawi, B.; Awajan, A.; Fraihat, S. Survey on the Objectives of Recommender System: Measures, Solutions, Evaluation Methodology, and New Perspectives. ACM Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Cui, Z.; Xu, X.; Fei, X.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized recommendation system based on collaborative filtering for IoT scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Duriakova, E.; Huáng, W.; Tragos, E.; Lawlor, A.; Smyth, B.; Geraci, J.; Hurley, N. An algorithmic framework for decentralised matrix factorisation. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2020; pp. 307–323. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, J.; Wu, D.; Chen, B.; Yu, S. Poisoning attack in federated learning using generative adversarial nets. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security Furthermore, Privacy in Computing Furthermore, Communications/13th IEEE International Conference on Big Data Science Furthermore, Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 374–380. [Google Scholar]
- Hegedus, I.; Danner, G.; Jelasity, M. Decentralized learning works: An empirical comparison of gossip learning and federated learning. J. Parallel Distrib. Comput. 2021, 148, 109–124. [Google Scholar] [CrossRef]
- Song, M.; Wang, Z.; Zhang, Z.; Song, Y.; Wang, Q.; Ren, J.; Qi, H. Analyzing user-level privacy attack against federated learning. IEEE J. Sel. Areas Commun. 2020, 38, 2430–2444. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Wittkopp, T.; Acker, A. Decentralized federated learning preserves model and data privacy. In Proceedings of the International Conference on Service-Oriented Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 176–187. [Google Scholar]
- Saito, Y.; Yaginuma, S.; Nishino, Y.; Sakata, H.; Nakata, K. Unbiased recommender learning from missing-not-at-random implicit feedback. In Proceedings of the 13th International Conference on Web Search and Data Mining; Machinery: New York, NY, USA, 2020; pp. 501–509. [Google Scholar]
- Li, H.; Diao, X.; Cao, J.; Zheng, Q. Collaborative filtering recommendation based on all-weighted matrix factorization and fast optimization. IEEE Access 2018, 6, 25248–25260. [Google Scholar] [CrossRef]
- Xu, S.; Zhuang, H.; Sun, F.; Wang, S.; Wu, T.; Dong, J. Recommendation algorithm of probabilistic matrix factorization based on directed trust. Comput. Electr. Eng. 2021, 93, 107206. [Google Scholar] [CrossRef]
- Cai, G.; Chen, N. Constrained probabilistic matrix factorization with neural network for recommendation system. In Proceedings of the International Conference on Intelligent Information Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 236–246. [Google Scholar]
- Chen, S.; Peng, Y. Matrix Factorization for Recommendation with Explicit and Implicit Feedback. Knowl.-Based Syst. 2018, 158, 109–117. [Google Scholar] [CrossRef]
- Huang, H.; Savkin, A.V.; Huang, C. Decentralized autonomous navigation of a UAV network for road traffic monitoring. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 2558–2564. [Google Scholar] [CrossRef]
- Alshamaa, D.; Mourad-Chehade, F.; Honeine, P. Decentralized kernel-based localization in wireless sensor networks using belief functions. IEEE Sens. J. 2019, 19, 4149–4159. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Z.; Zhao, P.; Zhou, J.; Li, X. Privacy preserving point-of-interest recommendation using decentralized matrix factorization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 4–6 February 2018; Volume 32. [Google Scholar]
- Wu, W.; Fu, S.; Luo, Y. Practical Privacy Protection Scheme In WiFi Fingerprint-based Localization. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 699–708. [Google Scholar]
- Li, Q.; Xiong, D.; Shang, M. Adjusted stochastic gradient descent for latent factor analysis. Inf. Sci. 2022, 588, 196–213. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Yorke-Smith, N. A novel Bayesian similarity measure for recommender systems. IJCAI 2013, 13, 2619–2625. [Google Scholar]
- Massa, P.; Souren, K.; Salvetti, M.; Tomasoni, D. Trustlet, open research on trust metrics. Scalable Comput. Pract. Exp. 2008, 9. Available online: https://personal.ntu.edu.sg/zhangj/paper/ijcai13-guibing.pdf (accessed on 25 August 2022).
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar]
- Castells, P.; Moffat, A. Offline recommender system evaluation: Challenges and new directions. AI Mag. 2022, 43, 225–238. [Google Scholar] [CrossRef]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| user set | |
| item set | |
| R | explicit feedback matrix |
| predicted rating matrix | |
| M | implicit feedback matrix |
| W | implicit feedback weighting matrix |
| U | user latent factor matrix |
| V | item rating latent factor matrix |
| Z | item selecting latent factor matrix |
| Q | user offset latent factor matrix |
| m | size of the user set |
| n | size of the item set |
| logistic function | |
| I | identity matrix |
| indicator that equals 1 when user i rates item j | |
| and 0 otherwise | |
| loss function | |
| d closest neighbors of user i | |
| λU, λV, λZ, λQ, λ | regularization parameters |
| learning rate | |
| T | numbers of training iterations |
| d | number of neighbors for a user |
| K | dimension of the latent factors |
| Dataset | #Rating | #User | #Item | #Trust |
|---|---|---|---|---|
| FilmTrust | 35,497 | 1508 | 2071 | 1853 |
| Epinions | 30,000 | 1336 | 6584 | 7465 |
| Methods | SVD++ | DMF | WRMF | PMF | DPMF |
|---|---|---|---|---|---|
| Computation | |||||
| Communication | - | - | - |
| FilmTrust | Epinions | |||
|---|---|---|---|---|
| Metrics | ||||
| Dimension | ||||
| PMF | 0.0332 | 0.0711 | 0.0715 | 0.1529 |
| WRMF | 0.0352 | 0.0751 | 0.0717 | 0.1497 |
| DPMF | 0.0342 | 0.0722 | 0.0716 | 0.1524 |
| Dimension | ||||
| PMF | 0.0380 | 0.0771 | 0.0761 | 0.1571 |
| WRMF | 0.0379 | 0.0763 | 0.0760 | 0.1563 |
| DPMF | 0.0396 | 0.0796 | 0.0781 | 0.1599 |
| Dimension | ||||
| PMF | 0.0410 | 0.0831 | 0.0781 | 0.1611 |
| WRMF | 0.0404 | 0.0823 | 0.0789 | 0.1603 |
| DPMF | 0.0435 | 0.0889 | 0.0821 | 0.1653 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Luo, Y.; Fu, S.; Xu, M.; Chen, Y. DPMF: Decentralized Probabilistic Matrix Factorization for Privacy-Preserving Recommendation. Appl. Sci. 2022, 12, 11118. https://doi.org/10.3390/app122111118
Yang X, Luo Y, Fu S, Xu M, Chen Y. DPMF: Decentralized Probabilistic Matrix Factorization for Privacy-Preserving Recommendation. Applied Sciences. 2022; 12(21):11118. https://doi.org/10.3390/app122111118
Chicago/Turabian StyleYang, Xu, Yuchuan Luo, Shaojing Fu, Ming Xu, and Yingwen Chen. 2022. "DPMF: Decentralized Probabilistic Matrix Factorization for Privacy-Preserving Recommendation" Applied Sciences 12, no. 21: 11118. https://doi.org/10.3390/app122111118
APA StyleYang, X., Luo, Y., Fu, S., Xu, M., & Chen, Y. (2022). DPMF: Decentralized Probabilistic Matrix Factorization for Privacy-Preserving Recommendation. Applied Sciences, 12(21), 11118. https://doi.org/10.3390/app122111118