
A Modeling Approach for Measuring the Performance of a Human-AI Collaborative Process



Abstract
:1. Introduction
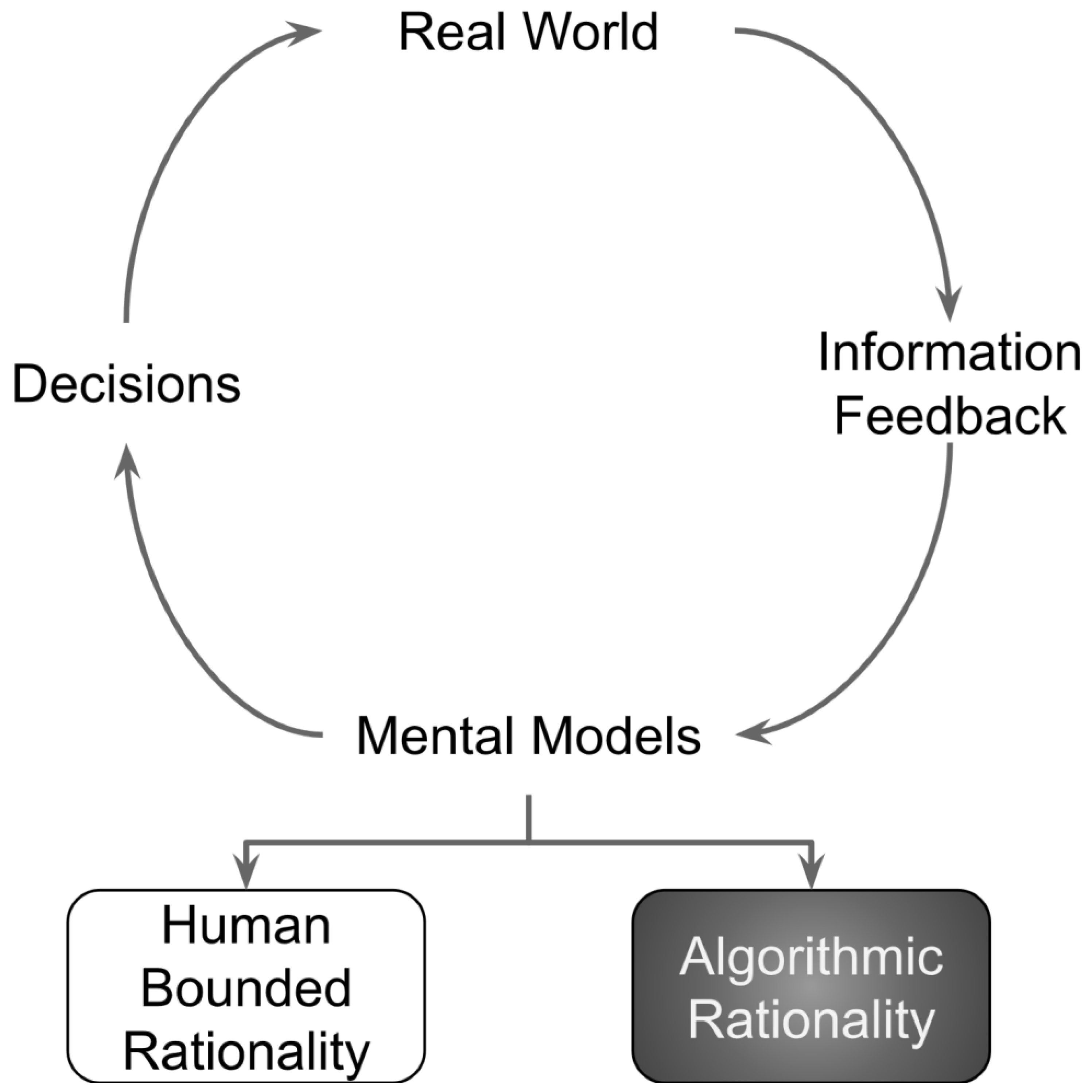
- We complement the conceptual literature on human–ML teaming that, by necessity (as it caters to various types of organizations), provides general guidelines on effectively structuring collaborations. Our modeling framework allows quantification of the blending of algorithmic ML rationality and bounded human rationality. We test our approach using an imaginary case of a company trying to improve its supply chain planning process.
- We complement existing work on explanatory AI in terms of framing “why” questions. Concretely, two metrics generally evaluate ML’s explanations: interpretability and completeness [33]. Our model provides the organizational problem-solving context (shedding light on the landscape of choices human and ML agents navigate) that must inform the selection of relevant “why” questions.
2. Related Work
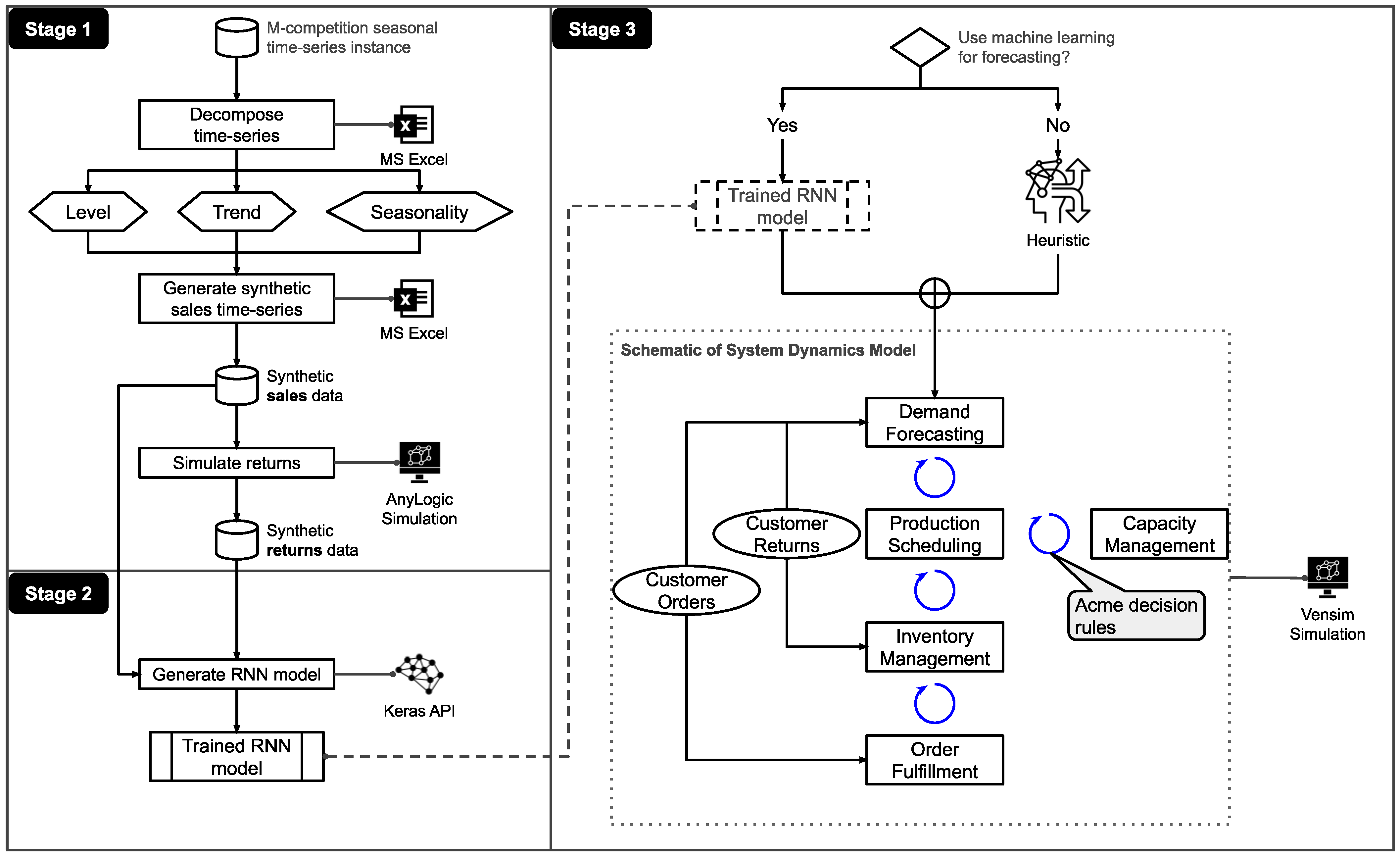
3. Design of a Quantitative Model
4. Experiment
4.1. Problem Context
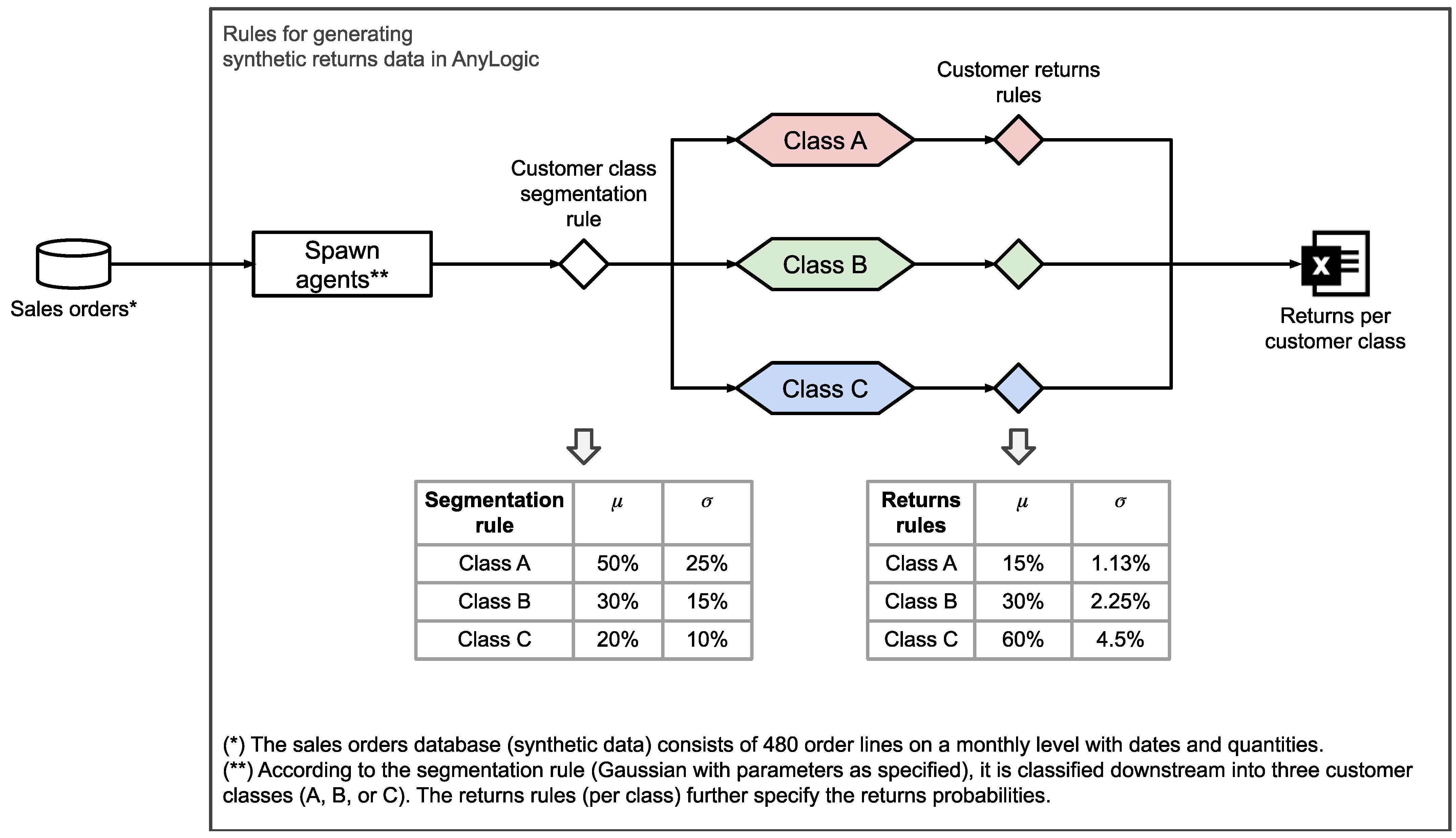
4.2. Data
4.3. Main Components
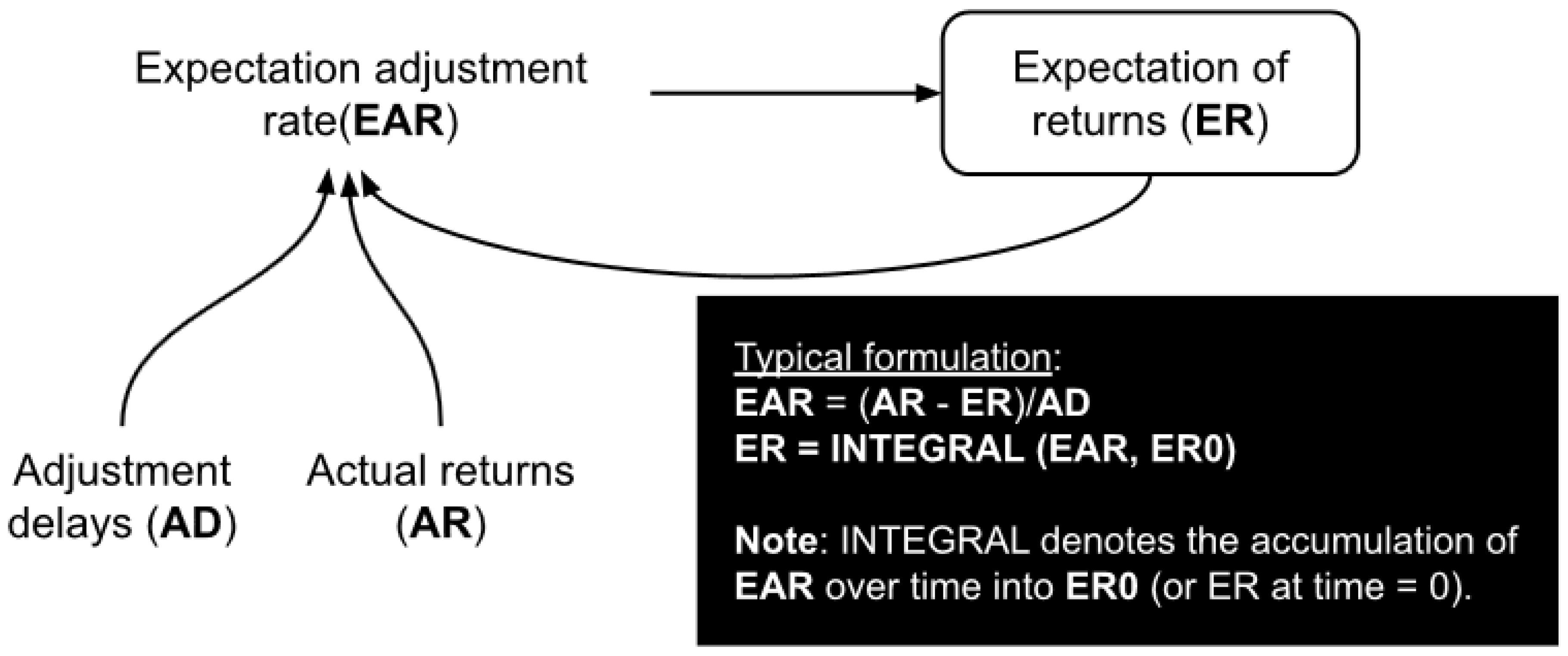
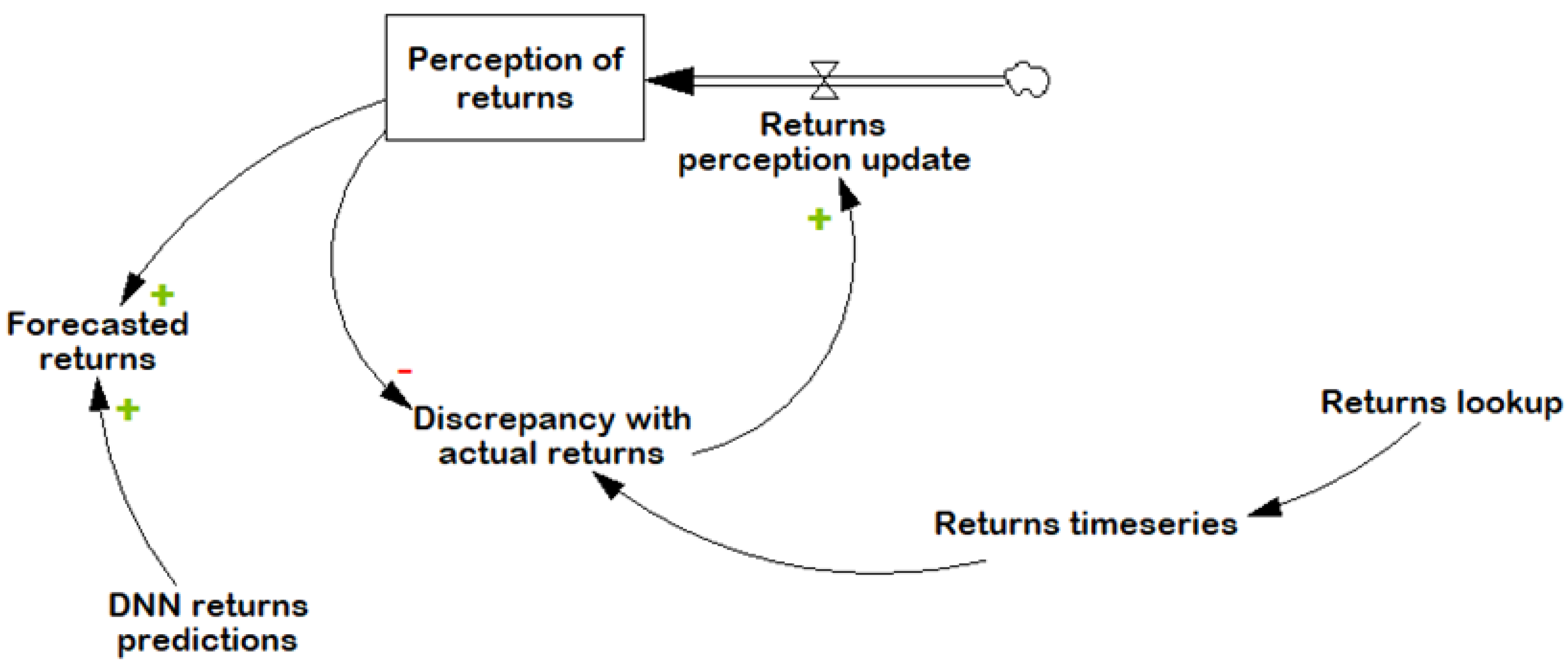
4.3.1. Modeling Judgmental Forecast
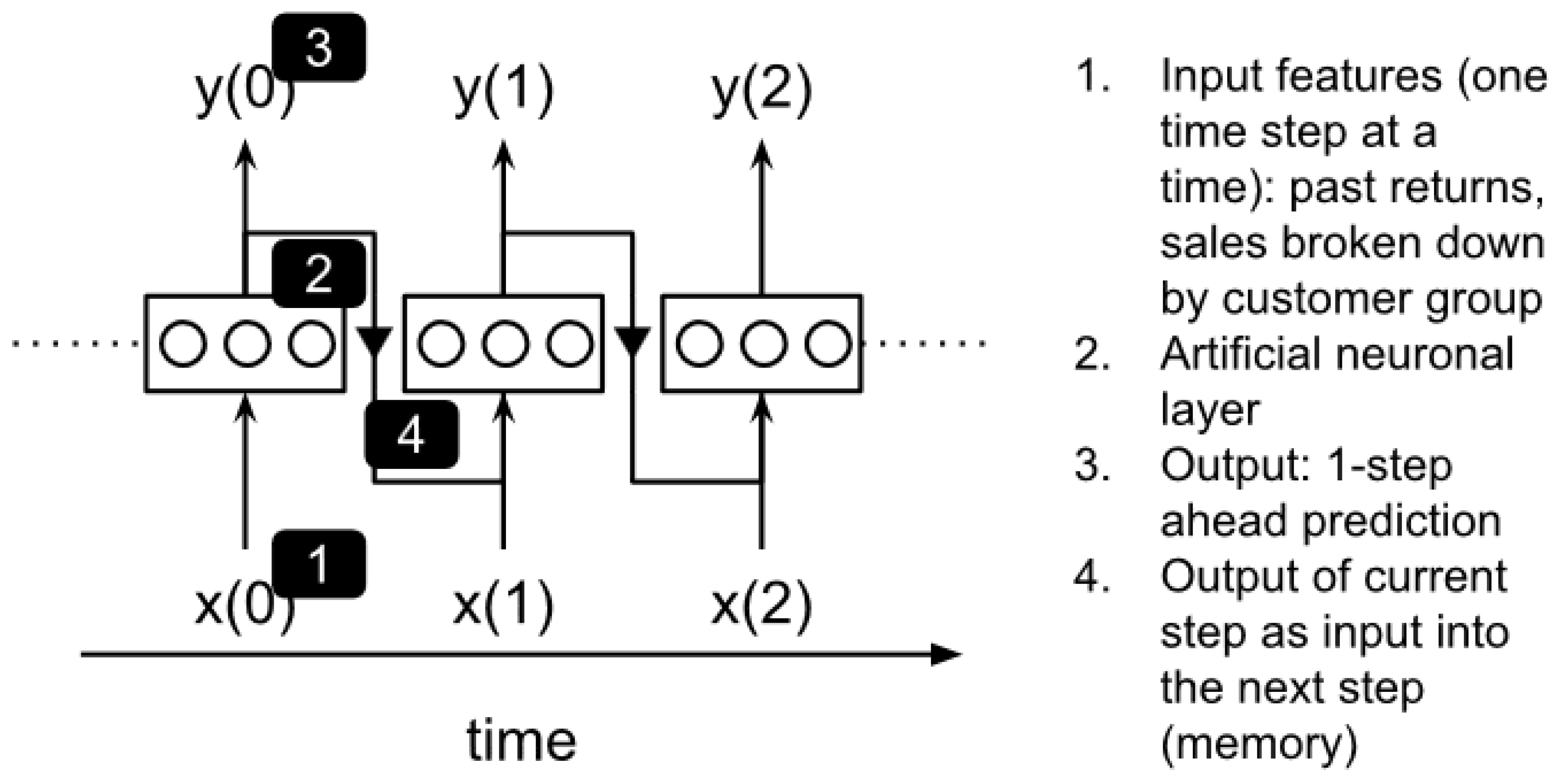
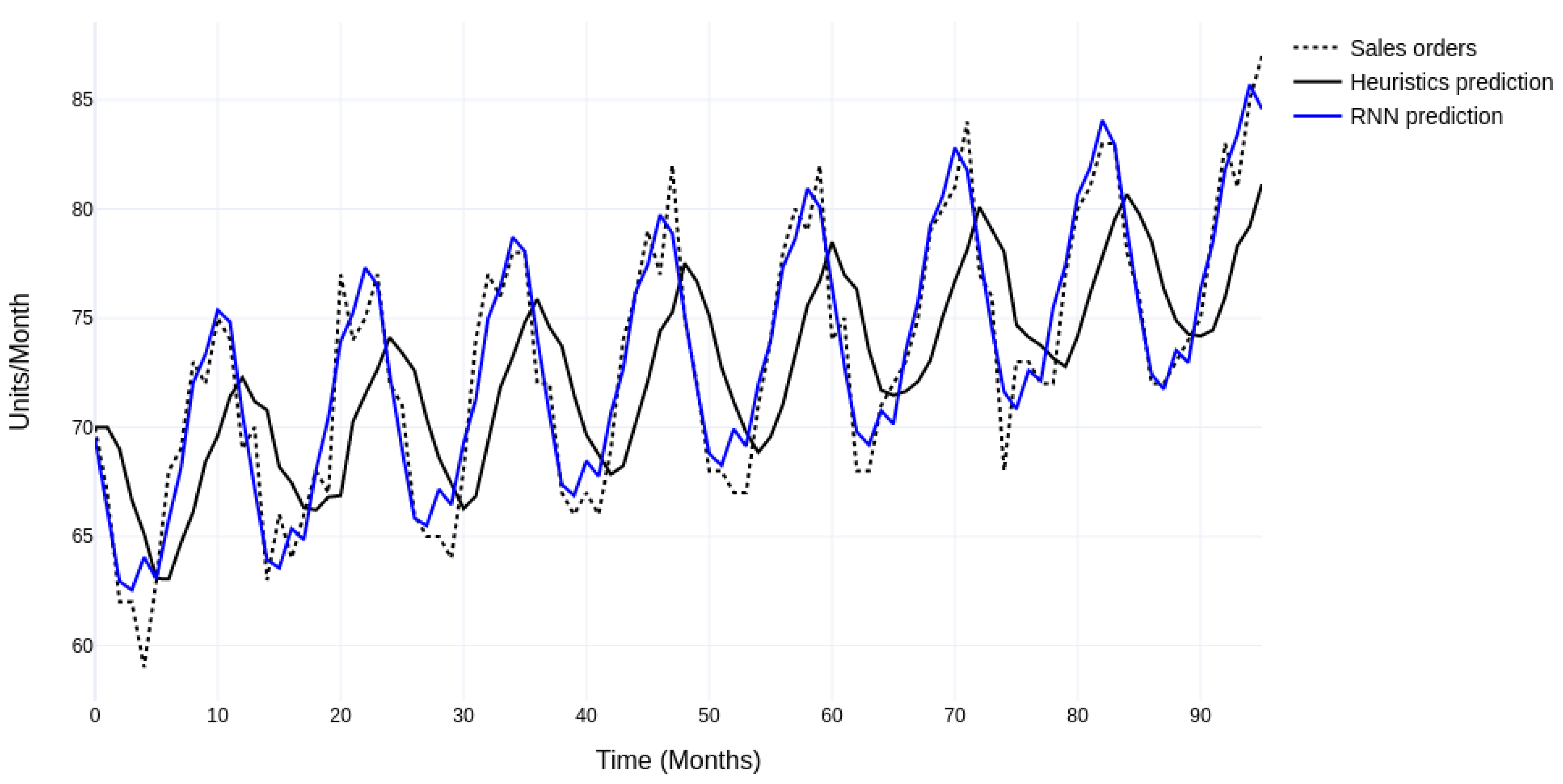
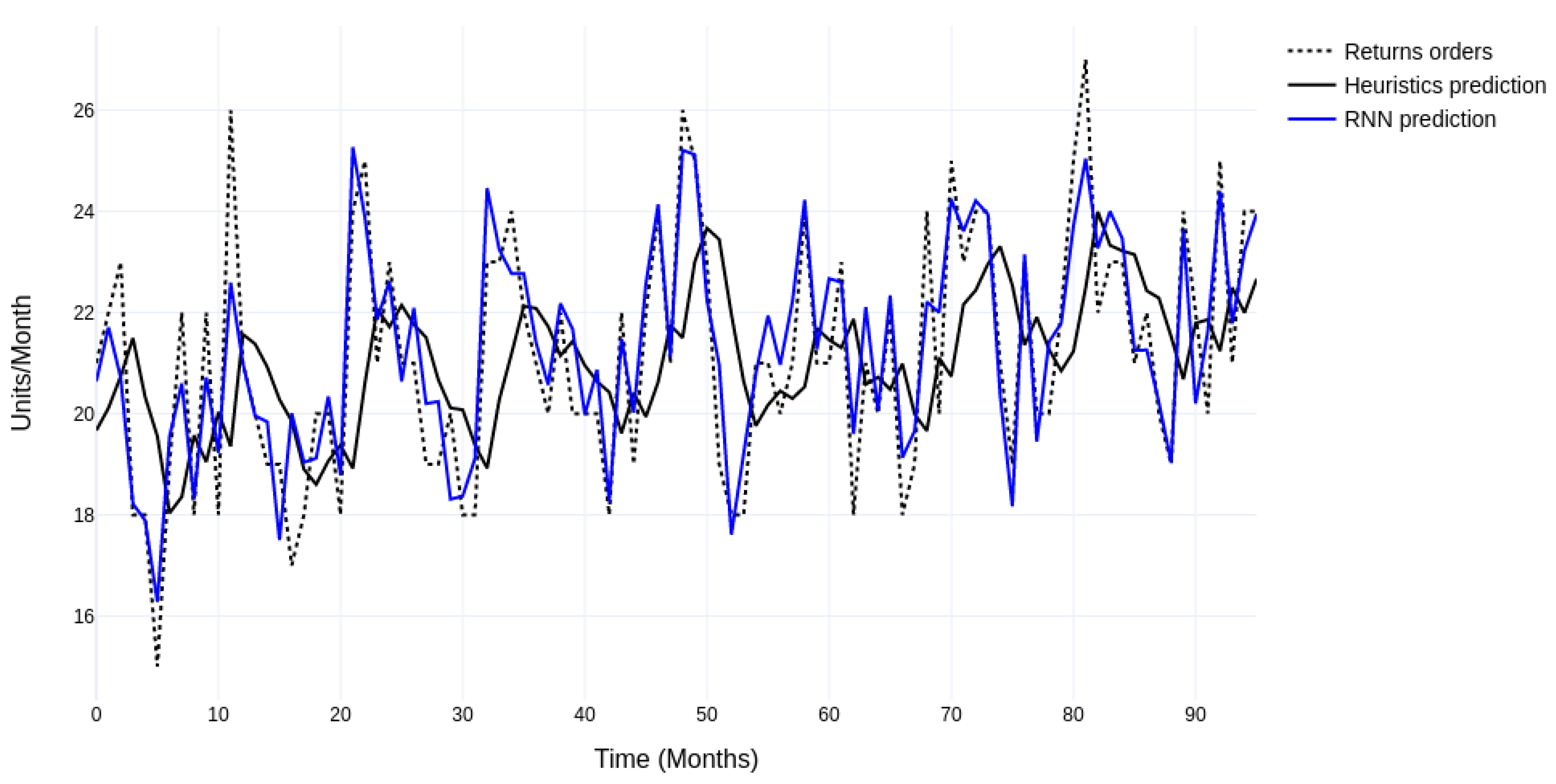
4.3.2. Modeling ML Forecast
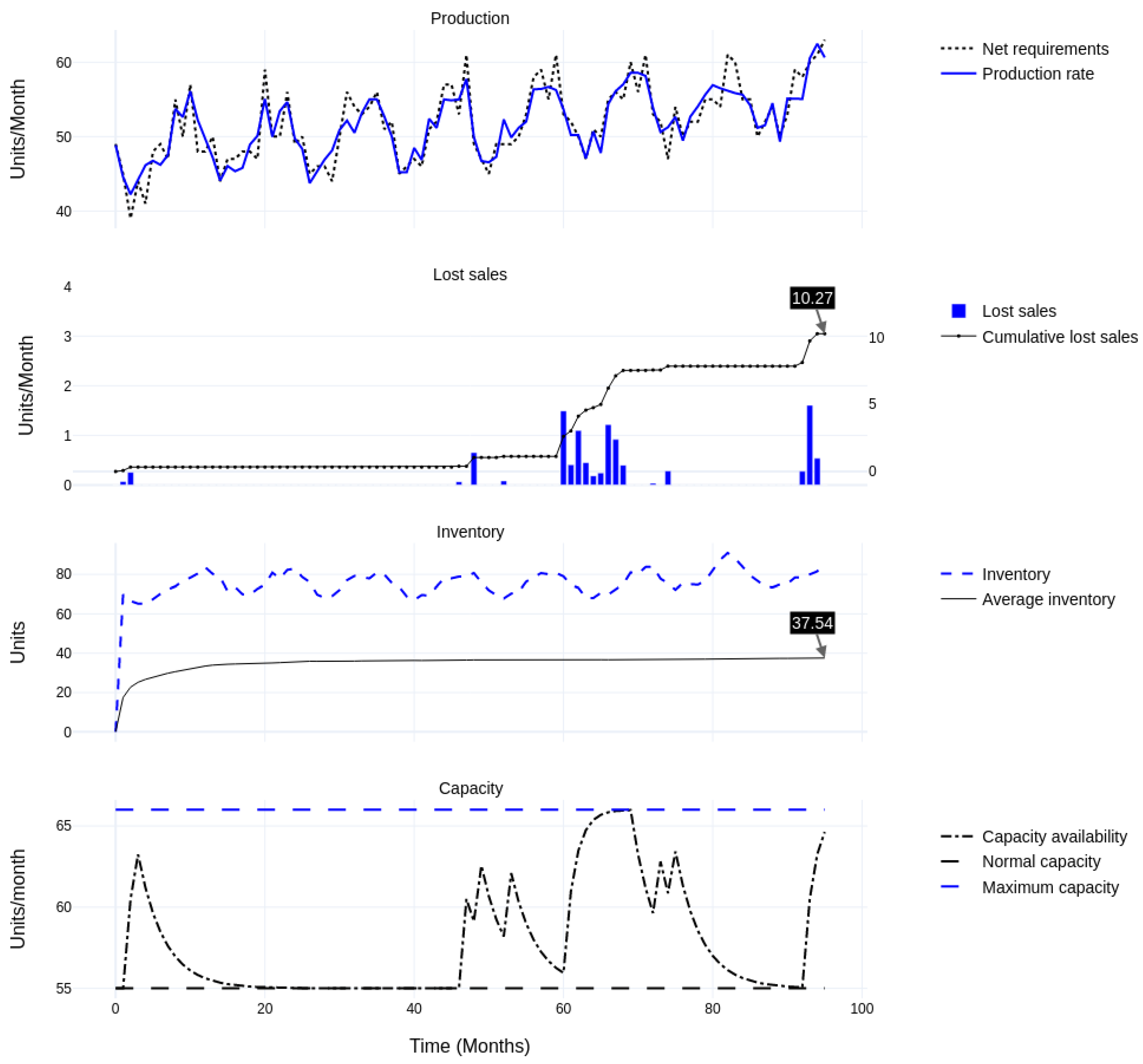
4.4. Execution and Results
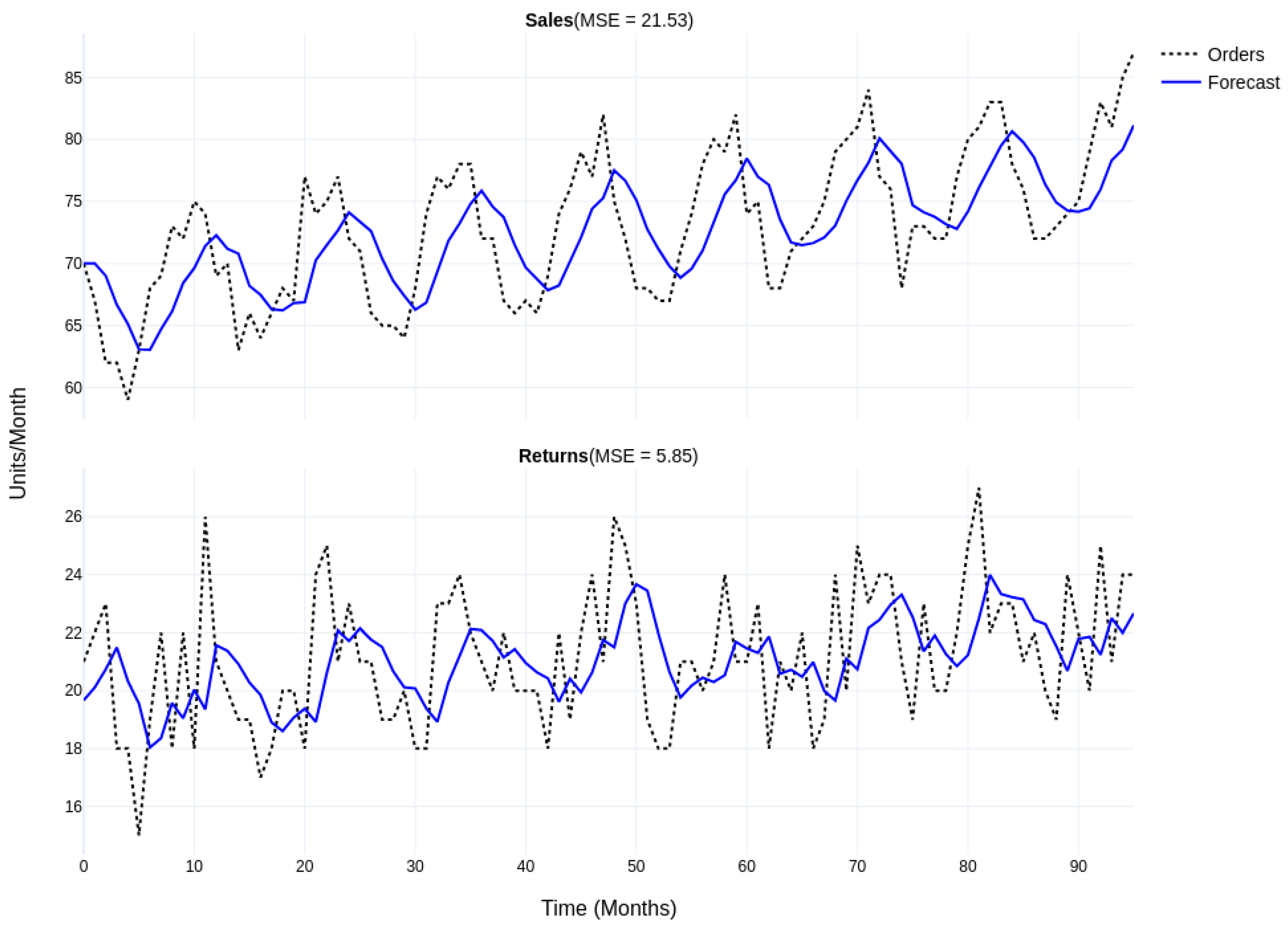
4.4.1. Comparing Stand-Alone Forecasting Performance
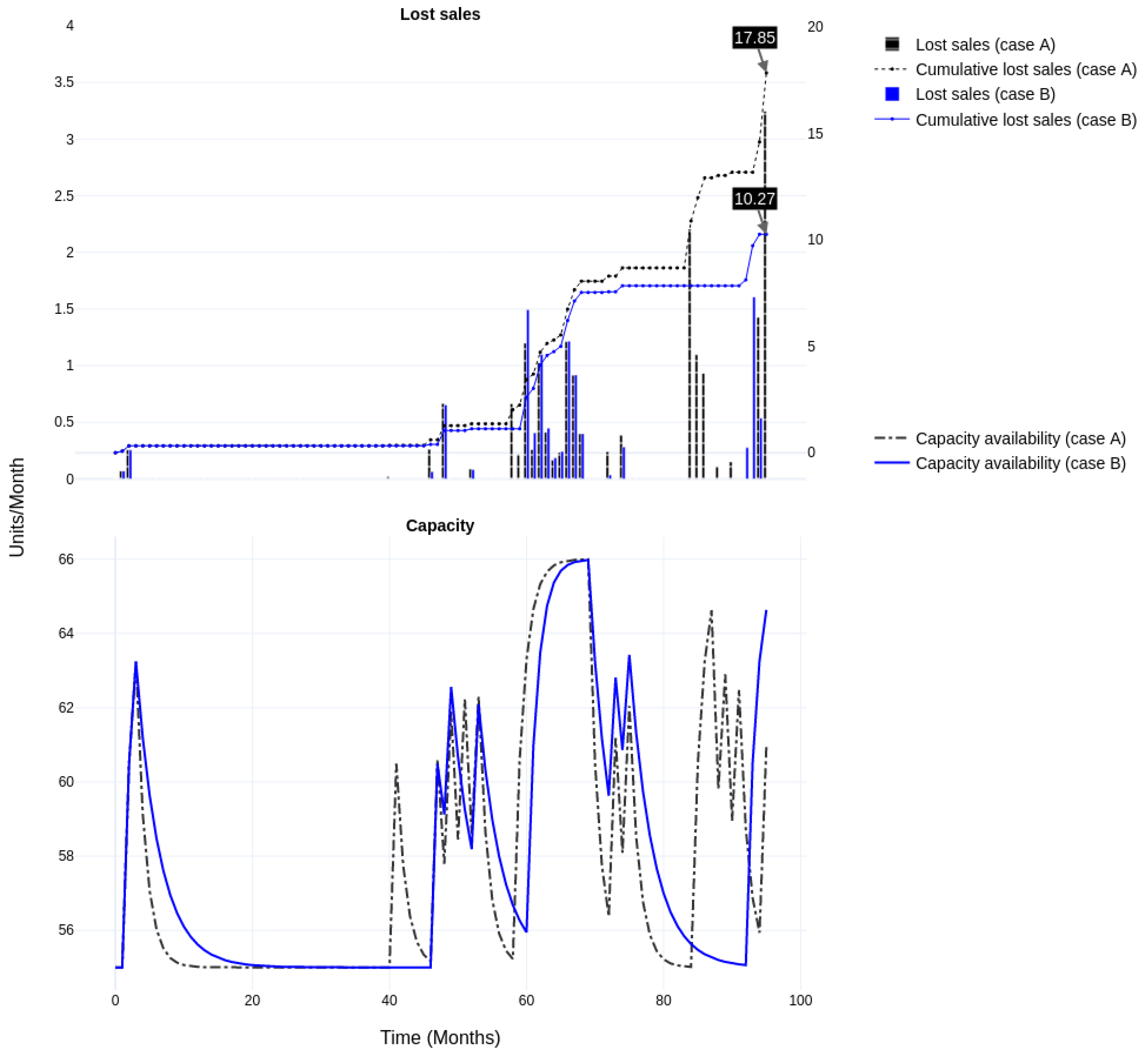
4.4.2. Comparing Overall System Performance
Base Case
Heuristic Adjustment
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Credits
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
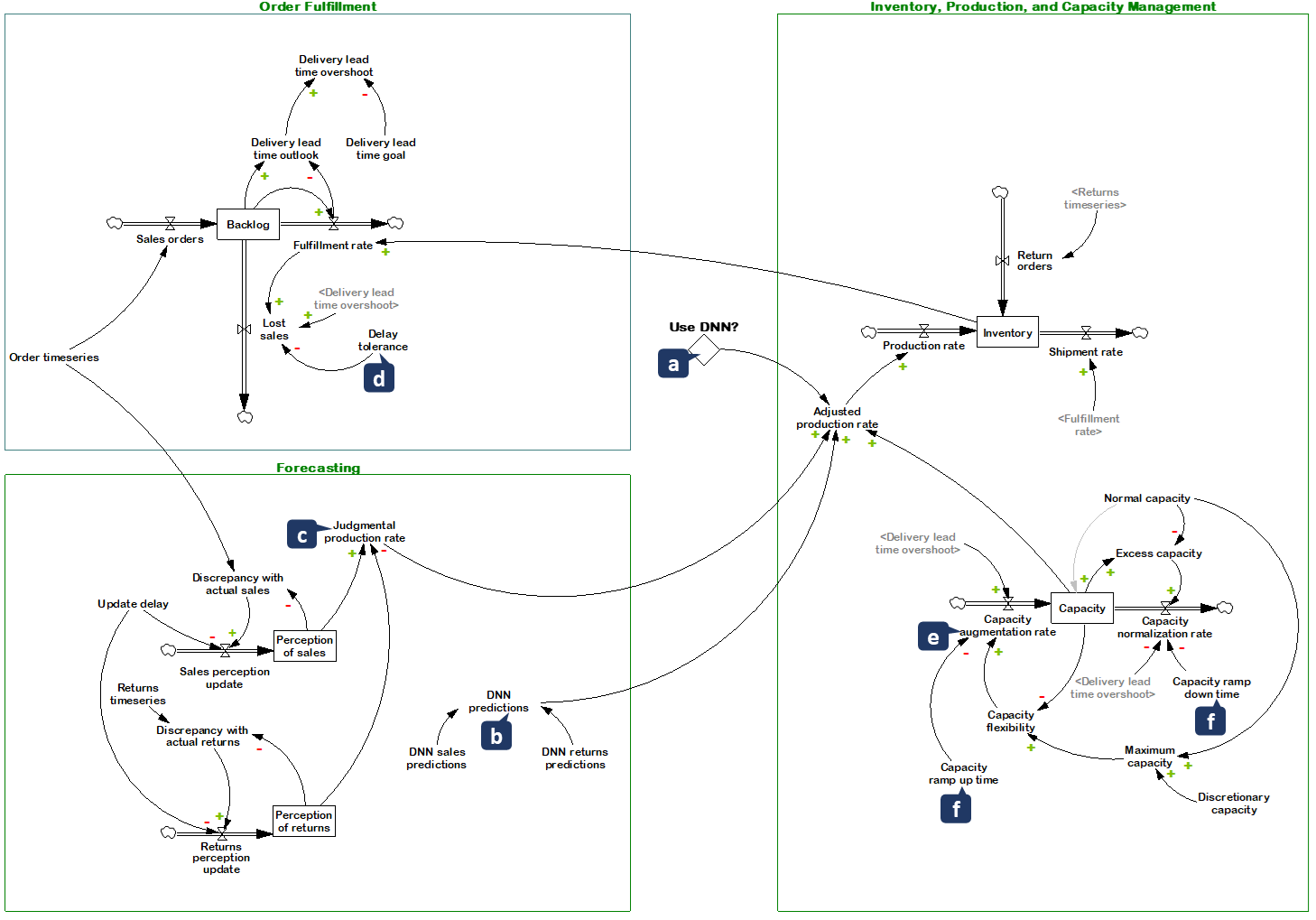
| Variable | Equation or Value | Units |
|---|---|---|
| Adjusted production rate | IF THEN ELSE (“Use DNN?” = 1, MIN (Capacity, DNN predictions), MIN (Capacity, Judgmental production rate)) | Pcs/Month |
| Backlog | INTEG (Sales orders − Fulfillment rate − Lost sales, 0) | Pcs |
| Capacity | INTEG (Capacity augmentation rate − Capacity normalization rate, Normal capacity) | Pcs/Month |
| Capacity augmentation rate | IF THEN ELSE (Delivery lead time overshoot > 0, Capacity flexibility/Capacity ramp-up time, 0) | Pcs/(Month × Month) |
| Capacity flexibility | Maximum capacity − Capacity | Pcs/Month |
| Capacity normalization rate | IF THEN ELSE (Delivery lead time overshoot > 0, 0, Excess capacity/Capacity ramp-down time) | Pcs/(Month × Month) |
| Capacity ramp-down time | 2 (base case); 4 (heuristic adjustment) | Month |
| Capacity ramp-up time | 2 | Month |
| Delay tolerance | 2 | Month |
| Delivery lead time goal | 1 | Month |
| Delivery lead time outlook | IF THEN ELSE (Backlog = 0, 1, Backlog/Fulfillment rate) | Month |
| Delivery lead time overshoot | MAX(0, Delivery lead time outlook − Delivery lead time goal) | Month |
| Discrepancy with actual returns | Returns time series (Time/One month) − Perception of returns | Pcs/Month |
| Discrepancy with actual sales | Order time series (Time/One month) − Perception of sales | Pcs/Month |
| Discretionary capacity | 0.2 | Dmnl |
| DNN predictions | DNN sales predictions (Time/One month) − DNN returns predictions (Time/One month) | Pcs/Month |
| DNN returns predictions | The result of RNN returns forecast is programmatically fed. | Pcs/Month |
| DNN sales predictions | The result of RNN sales forecast is programmatically fed. | Pcs/Month |
| Excess capacity | MAX(0, Capacity − Normal capacity) | Pcs/Month |
| FINAL TIME | 96 | Month |
| Fulfillment rate | MIN(Backlog, Inventory)/One month | Pcs/Month |
| INITIAL TIME | 1 | Month |
| Inventory | INTEG (Production rate + Return orders − Shipment rate, 0) | Pcs |
| Judgmental production rate | Perception of sales − Perception of returns | Pcs/Month |
| Lost sales | (Delivery lead time overshoot × Fulfillment rate)/Delay tolerance | Pcs/Month |
| Maximum capacity | Normal capacity × (1 + Discretionary capacity) | Pcs/Month |
| Net requirements | Sales orders − Return orders | Pcs/Month |
| Normal capacity | 55 | Pcs/Month |
| One month | 1 | Month |
| Order time series | Test dataset for actual customer orders. | Pcs/Month |
| Perception of returns | INTEG (Returns perception update, 19.67) (Note: 19.67 is the initial value; equals the average of last 6 months of returns) | Pcs/Month |
| Perception of sales | INTEG (Sales perception update, 70) (Note: 70 is the initial value; equals the average of last 6 months of sales) | Pcs/Month |
| Production rate | Adjusted production rate | Pcs/Month |
| Return orders | Returns time series (Time/One month) | Pcs/Month |
| Returns perception update | Discrepancy with actual returns/Update delay | Pcs/(Month × Month) |
| Returns time series | Test dataset for actual customer returns. | Pcs/Month |
| Sales orders | Order time series (Time/One month) | Pcs/Month |
| Sales perception update | Discrepancy with actual sales/Update delay | Pcs/(Month × Month) |
| Shipment rate | Fulfillment rate | Pcs/Month |
| Update delay | 3 | Month |
| “Use DNN?” | Programmatically set to switch between heuristic forecasting and RNN. | Dmnl |
References
- Brynjolfsson, E.; Mitchell, T. What can Machine Learning Do? Workforce Implications. Science 2017, 358, 1530–1534. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Makridakis, S. The forthcoming Artificial Intelligence (AI) revolution: Its impact on society and firms. Futures 2017, 90, 46–60. [Google Scholar] [CrossRef]
- Mitchell, M. Why AI Is Harder Than We Think. arXiv 2021, arXiv:2104.12871. [Google Scholar]
- Chollet, F. On the Measure of Intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Marcus, G. The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence. arXiv 2020, arXiv:2002.06177. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Blackman, R.; Ammanath, B. When—and Why—You Should Explain How Your AI Works. Harvard Business Review, 31 August 2022. Available online: https://hbr.org/2022/08/when-and-why-you-should-explain-how-your-ai-works(accessed on 28 October 2022).
- Zolas, N.; Kroff, Z.; Brynjolfsson, E.; McElheran, K.; Beede, D.N.; Buffington, C.; Goldschlag, N.; Foster, L.; Dinlersoz, E. Advanced Technologies Adoption and Use by U.S. Firms: Evidence from the Annual Business Survey; National Bureau of Economic Research: Cambridge, MA, USA, 2020. [Google Scholar] [CrossRef]
- Karp, R.; Peterson, A. Find the Right Pace for Your AI Rollout. Harvard Business Review, 25 August 2022. Available online: https://hbr.org/2022/08/find-the-right-pace-for-your-ai-rollout(accessed on 28 October 2022).
- Agrawal, A.; Gans, J.S.; Goldfarb, A. What to Expect from Artificial Intelligence. MIT Sloan Management Review, 7 February 2017. Available online: https://sloanreview-mit-edu.plymouth.idm.oclc.org/article/what-to-expect-from-artificial-intelligence/(accessed on 14 September 2021).
- Raisch, S.; Krakowski, S. Artificial Intelligence and Management: The Automation–Augmentation Paradox. Acad. Manag. Rev. 2021, 46, 192–210. [Google Scholar] [CrossRef]
- Shestakofsky, B. Working Algorithms: Software Automation and the Future of Work. Work. Occup. 2017, 44, 376–423. [Google Scholar] [CrossRef]
- Brynjolfsson, E.; McAfee, A. Will Humans Go the Way of Horses. Foreign Aff. 2015, 94, 8. [Google Scholar]
- Autor, D. Polanyi’s Paradox and the Shape of Employment Growth; NBER Working Papers 20485; National Bureau of Economic Research: Cambridge, MA, USA, 2014. [Google Scholar] [CrossRef]
- Melville, N.; Kraemer, K.; Gurbaxani, V. Review: Information Technology and Organizational Performance: An Integrative Model of IT Business Value. MIS Q. 2004, 28, 283–322. [Google Scholar] [CrossRef] [Green Version]
- Sturm, T.; Gerlach, J.P.; Pumplun, L.; Mesbah, N.; Peters, F.; Tauchert, C.; Nan, N.; Buxmann, P. Coordinating Human and Machine Learning for Effective Organizational Learning. MIS Q. 2021, 45, 1581–1602. [Google Scholar] [CrossRef]
- Malone, T.W. How Human-Computer ‘Superminds’ Are Redefining the Future of Work. MIT Sloan Management Review, 21 May 2018. Available online: https://sloanreview-mit-edu.plymouth.idm.oclc.org/article/how-human-computer-superminds-are-redefining-the-future-of-work/(accessed on 22 September 2021).
- Elena Revilla, M.J.S.; Simón, C. Designing AI Systems with Human-Machine Teams. MIT Sloan Management Review, 18 March 2020. Available online: https://sloanreview.mit.edu/article/designing-ai-systems-with-human-machine-teams/(accessed on 8 September 2021).
- Puranam, P. Human-AI collaborative decision-making as an organization design problem. J. Org. Design 2021, 10, 75–80. [Google Scholar] [CrossRef]
- Shrestha, Y.R.; Ben-Menahem, S.M.; von Krogh, G. Organizational Decision-Making Structures in the Age of Artificial Intelligence. Calif. Manag. Rev. 2019, 61, 66–83. [Google Scholar] [CrossRef]
- Brynjolfsson, E. The Turing Trap: The Promise & Peril of Human-Like Artificial Intelligence. Daedalus 2022, 151, 272–287. [Google Scholar] [CrossRef]
- Rahmandad, H.; Repenning, N.; Sterman, J. Effects of feedback delay on learning. Syst. Dyn. Rev. 2009, 25, 309–338. [Google Scholar] [CrossRef]
- Hogarth, R.M.; Lejarraga, T.; Soyer, E. The Two Settings of Kind and Wicked Learning Environments. Curr. Dir. Psychol. Sci. 2015, 24, 379–385. [Google Scholar] [CrossRef]
- Ethiraj, S.K.; Levinthal, D. Bounded Rationality and the Search for Organizational Architecture: An Evolutionary Perspective on the Design of Organizations and Their Evolvability. Adm. Sci. Q. 2004, 49, 404–437. [Google Scholar] [CrossRef]
- Knudsen, T.; Srikanth, K. Coordinated Exploration: Organizing Search by Multiple Specialists to Overcome Mutual Confusion and Joint Myopia. Adm. Sci. Q. 2013, 59, 409–441. [Google Scholar] [CrossRef]
- Simon, H.A.; Newell, A. Human problem solving: The state of the theory in 1970. Am. Psychol. 1971, 26, 145–159. [Google Scholar] [CrossRef]
- Glazer, R.; Steckel, J.H.; Winer, R.S. Locally Rational Decision Making: The Distracting Effect of Information on Managerial Performance. Manag. Sci. 1992, 38, 212–226. [Google Scholar] [CrossRef]
- Nonaka, I. The Knowledge-Creating Company. Harvard Business Review, 1 July 2007. Available online: https://hbr.org/2007/07/the-knowledge-creating-company(accessed on 6 September 2021).
- Narayanan, M.; Chen, E.; He, J.; Kim, B.; Gershman, S.; Doshi-Velez, F. How do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation. arXiv 2018, arXiv:1802.00682. [Google Scholar]
- Elgendy, N. Enhancing Collaborative Rationality between Humans and Machines through Data-Driven Decision Evaluation. In Proceedings of the 21st International Conference on Perspectives in Business Informatics Research (BIR), Rostock, Germany, 20–23 September 2022; p. 12. [Google Scholar]
- Sterman, J. System Dynamics: Systems Thinking and Modeling for a Complex World. Massachusetts Institute of Technology. Engineering Systems Division, Working Paper, May 2002. Available online: https://dspace.mit.edu/handle/1721.1/102741 (accessed on 2 June 2022).
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar] [CrossRef] [Green Version]
- Kasparov, G. Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins, 1st ed.; PublicAffairs: New York, NY, USA, 2017. [Google Scholar]
- Hassabis, D. Artificial Intelligence: Chess match of the century. Nature 2017, 544, 7651. [Google Scholar] [CrossRef]
- Simon, H.A. Administrative Behavior, 4th ed.; Free Press: New York, NY, USA, 1997. [Google Scholar]
- Lee, K.-F. AI Superpowers: China, Silicon Valley, and the New World Order, 1st ed.; Mariner Books: Boston, MA, USA, 2018. [Google Scholar]
- Reeves, M.; Ueda, D. Designing the Machines That Will Design Strategy. Harvard Business Review, 18 April 2016. Available online: https://hbr.org/2016/04/welcoming-the-chief-strategy-robot(accessed on 20 September 2021).
- Huang, M.-H.; Rust, R.; Maksimovic, V. The Feeling Economy: Managing in the Next Generation of Artificial Intelligence (AI). Calif. Manag. Rev. 2019, 61, 43–65. [Google Scholar] [CrossRef]
- Simon, H.A. The Sciences of the Artificial, 3rd ed.; The MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Klein, G.A. Sources of Power: 20th Anniversary Edition, 1st ed.; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Galbraith, J.R. Organization Design: An Information Processing View. INFORMS J. Appl. Anal. 1974, 4, 28–36. [Google Scholar] [CrossRef] [Green Version]
- Nelson, R.R.; Winter, S.G. Neoclassical vs. Evolutionary Theories of Economic Growth: Critique and Prospectus. Econ. J. 1974, 84, 886–905. [Google Scholar] [CrossRef]
- Gigerenzer, G.; Goldstein, D.G. Reasoning the fast and frugal way: Models of bounded rationality. Psychol. Rev. 1996, 103, 650–669. [Google Scholar] [CrossRef] [Green Version]
- Panchalavarapu, P.R.; De Kok, A.G.; Stephen, C.; Graves, C.S. (Eds.) 2004. Handbooks in Operations Research and Management Science: Supply Chain Management: Design, Coordination and Operation. Interfaces 2005, 35, 339–341. [Google Scholar]
- Devaraj, S.; Kohli, R. Performance Impacts of Information Technology: Is Actual Usage the Missing Link? Manag. Sci. 2003, 49, 273–289. [Google Scholar] [CrossRef] [Green Version]
- Wernerfelt, B. A resource-based view of the firm. Strateg. Manag. J. 1984, 5, 171–180. [Google Scholar] [CrossRef]
- Brynjolfsson, E.; Milgrom, P. 1. Complementarity in Organizations. In The Handbook of Organizational Economics; Princeton University Press: Princeton, NJ, USA, 2012; pp. 11–55. [Google Scholar] [CrossRef]
- Mithas, S.; Ramasubbu, N.; Sambamurthy, V. How Information Management Capability Influences Firm Performance. MIS Q. 2011, 35, 237–256. [Google Scholar] [CrossRef] [Green Version]
- Brynjolfsson, E.; Hitt, L. Computing Productivity: Firm-Level Evidence. Rev. Econ. Stat. 2003, 85, 793–808. [Google Scholar] [CrossRef] [Green Version]
- Haynes, C.; Palomino, M.A.; Stuart, L.; Viira, D.; Hannon, F.; Crossingham, G.; Tantam, K. Automatic Classification of National Health Service Feedback. Mathematics 2022, 10, 983. [Google Scholar] [CrossRef]
- Melville, N.; Gurbaxani, V.; Kraemer, K. The productivity impact of information technology across competitive regimes: The role of industry concentration and dynamism. Decis. Support Syst. 2007, 43, 229–242. [Google Scholar] [CrossRef]
- Will, J.; Bertrand, M.; Fransoo, J.C. Operations management research methodologies using quantitative modeling. Int. J. Oper. Prod. Manag. 2002, 22, 241–264. [Google Scholar] [CrossRef]
- Ackoff, R.L. The Future of Operational Research is Past. J. Oper. Res. Soc. 1979, 30, 93–104. [Google Scholar] [CrossRef]
- Frank, M.R.; Autor, D.; Bessen, J.E.; Brynjolfsson, E.; Cebrian, M.; Deming, D.J.; Feldman, M.; Groh, M.; Lobo, J.; Moro, E.; et al. Toward understanding the impact of artificial intelligence on labor. Proc. Natl. Acad. Sci. USA 2019, 116, 6531–6539. [Google Scholar] [CrossRef] [Green Version]
- Morecroft, J.D.W. Rationality in the Analysis of Behavioral Simulation Models. Manag. Sci. 1985, 31, 900–916. [Google Scholar] [CrossRef]
- Sterman, J.D. Business Dynamics; International Edition; McGraw-Hill Education: Boston, MA, USA, 2000. [Google Scholar]
- Powers, W.T. Feedback: Beyond Behaviorism. Science 1973, 179, 351–356. [Google Scholar] [CrossRef] [Green Version]
- Pruyt, E. Small System Dynamics Models for Big Issues: Triple Jump towards Real-World Complexity; TU Delft Library: Delft, The Netherlands, 2013. [Google Scholar]
- Houghton, J.; Siegel, M. Advanced data analytics for system dynamics models using PySD. In Proceedings of the 33rd International Conference of the System Dynamics Society, Cambridge, MA, USA, 19–23 July 2015. [Google Scholar]
- Anderson, C. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Wired, 23 June 2008. Available online: https://www.wired.com/2008/06/pb-theory/ (accessed on 26 August 2022).
- Pearl, J. Radical Empiricism and Machine Learning Research. J. Causal Inference 2021, 9, 78–82. [Google Scholar] [CrossRef]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef] [Green Version]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜. In Proceedings of the 2021 ACM Conference on Fairness. Accountability, and Transparency, Virtual Event Canada, 3–10 March 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Pearl, J. Theoretical Impediments to Machine Learning with Seven Sparks from the Causal Revolution. arXiv 2018, arXiv:1801.04016. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed]
- Souza, G.C. Closed-Loop Supply Chains: A Critical Review, and Future Research*. Decis. Sci. 2013, 44, 7–38. [Google Scholar] [CrossRef]
- Makridakis, S.; Hibon, M. The M3-Competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Borshchev, A. Multi-method modelling: AnyLogic. Discret. Event Simul. Syst. Dyn. Manag. Decis. Mak. 2014, 9781118349, 248–279. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python, 2nd ed.; Manning: Shelter Island, New York, USA; Hong Kong, China, 2021. [Google Scholar]
- Grus, J. Data Science from Scratch: First Principles with Python, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Sterman, J.D. Misperceptions of feedback in dynamic decision making. Organ. Behav. Hum. Decis. Process. 1989, 43, 301–335. [Google Scholar] [CrossRef] [Green Version]
- Kahneman, D.; Slovic, S.P.; Slovic, P.; Tversky, A.; Press, C.U. Judgment under Uncertainty: Heuristics and Biases; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly Media: Beijing, China; Sebastopol, CA, USA, 2019. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and Statistical Modeling with Python. In Proceedings of the 9th Python in Science Conference (SciPy), Austin, TX, USA, 28 June–3 July 2010; pp. 92–96. [Google Scholar] [CrossRef] [Green Version]
- Tabrizi, B.; Lam, E.; Girard, K.; Irvin, V. Digital Transformation Is Not About Technology. Harvard Business Review, 13 March 2019. Available online: https://hbr.org/2019/03/digital-transformation-is-not-about-technology(accessed on 7 September 2021).
- LaValle, S.; Lesser, E.; Shockley, R.; Hopkins, M.S.; Kruschwitz, N. Big Data, Analytics and the Path from Insights to Value. MIT Sloan Management Review. Available online: https://sloanreview.mit.edu/article/big-data-analytics-and-the-path-from-insights-to-value/ (accessed on 11 October 2021).
- Weill, P.; Woerner, S.L. Is Your Company Ready for a Digital Future? MIT SMR, 4 December 2017. Available online: https://sloanreview.mit.edu/article/is-your-company-ready-for-a-digital-future/(accessed on 7 November 2022).
- Westerman, G.; Bonnet, D.; McAfee, A. Leading Digital: Turning Technology into Business Transformation; Harvard Business Press: Bosto, MA, USA, 2014. [Google Scholar]
- Case, N. How To Become A Centaur. J. Des. Sci. 2018. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning, 2nd ed.; An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Hopp, W.J.; Spearman, M.L. Factory Physics; Reissue Edition; Waveland Pr Inc.: Long Grove, IL, USA, 2011. [Google Scholar]
- Galbraith, J.R. Organizational Design Challenges Resulting from Big Data. 10 April 2014. Available online: https://papers.ssrn.com/abstract=2458899 (accessed on 7 November 2022).
- Clark, S.; Hyndman, R.J.; Pagendam, D.; Ryan, L.M. Modern Strategies for Time Series Regression. Int. Stat. Rev. 2020, 88, S179–S204. [Google Scholar] [CrossRef]
















| Parameter | Description | Value | |
|---|---|---|---|
| Sales | Returns | ||
| Historical periods | Actual historical sales or returns horizon to use for forecasting. | 36 months | 1 month |
| Forecast periods | Forecast horizon. | 1 month | 1 month |
| RNN layer | There are three built-in layers in Keras: SimpleRNN, GRU, and LSTM (the latter two support longer time-series sequences; we describe the rationale in the text). | LSTM | GRU |
| Optimizer | Gradient method used. | Adam | Adam |
| Layers | Depth of the neural network. | 1 | 1 |
| Number of units | Artificial neurons per layer. | 225 | 150 |
| Dropout | Regularization parameter (described in the text). | 10% | 10% |
| Epochs | Training iterations. | 150 | 150 |
| Case B vs. Case A | ||||||
|---|---|---|---|---|---|---|
| Metric (in Units) | Heuristics (H) | RNN (R) | R vs. H | Heuristics | RNN | |
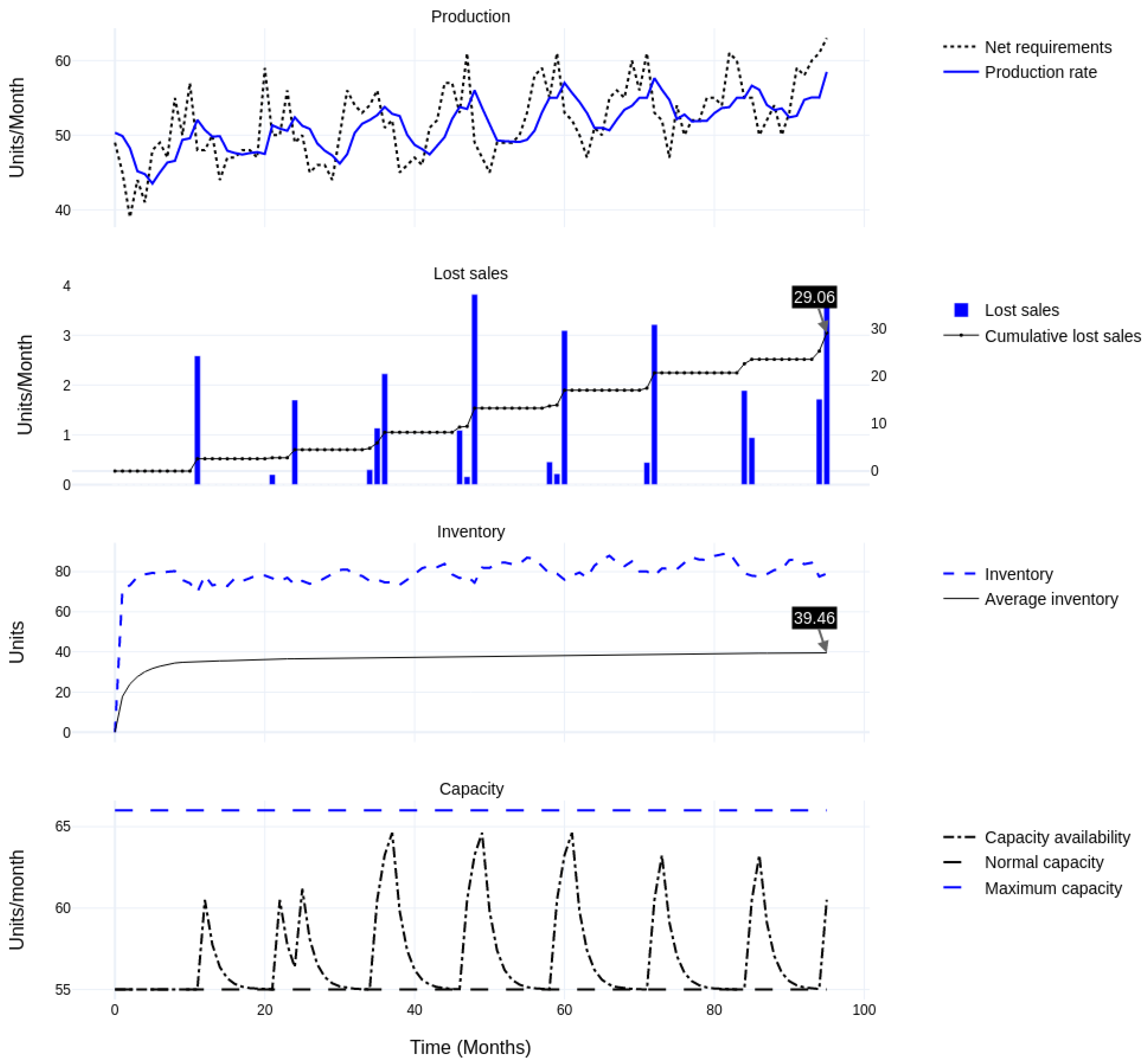
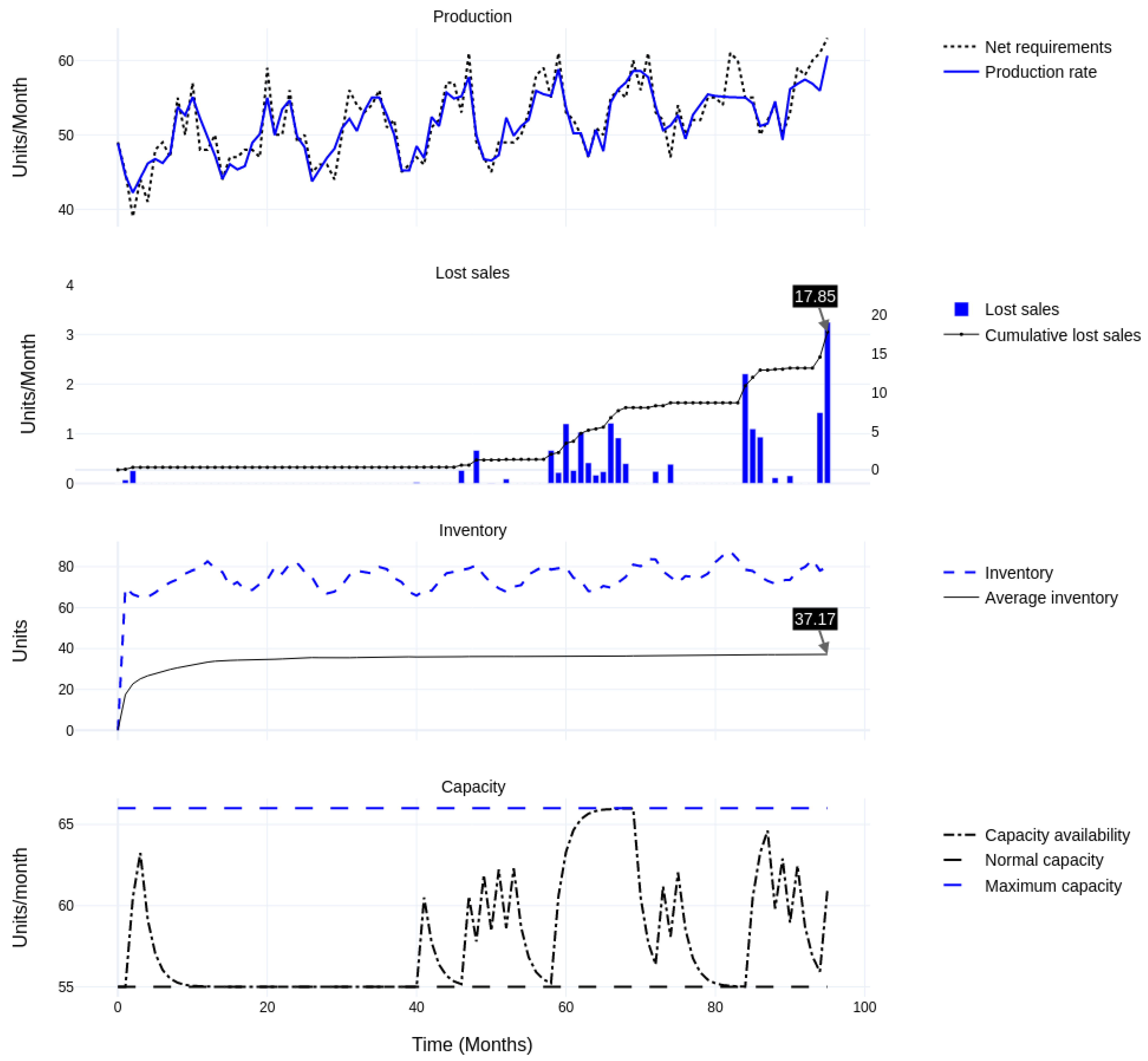
| (A) Base case: 20% discretionary capacity, quick ramp-up and ramp-down (1) | Lost Sales | 29.06 | 17.85 | −39% | N/A | N/A |
| Inventory | 39.46 | 37.17 | −6% | N/A | N/A | |
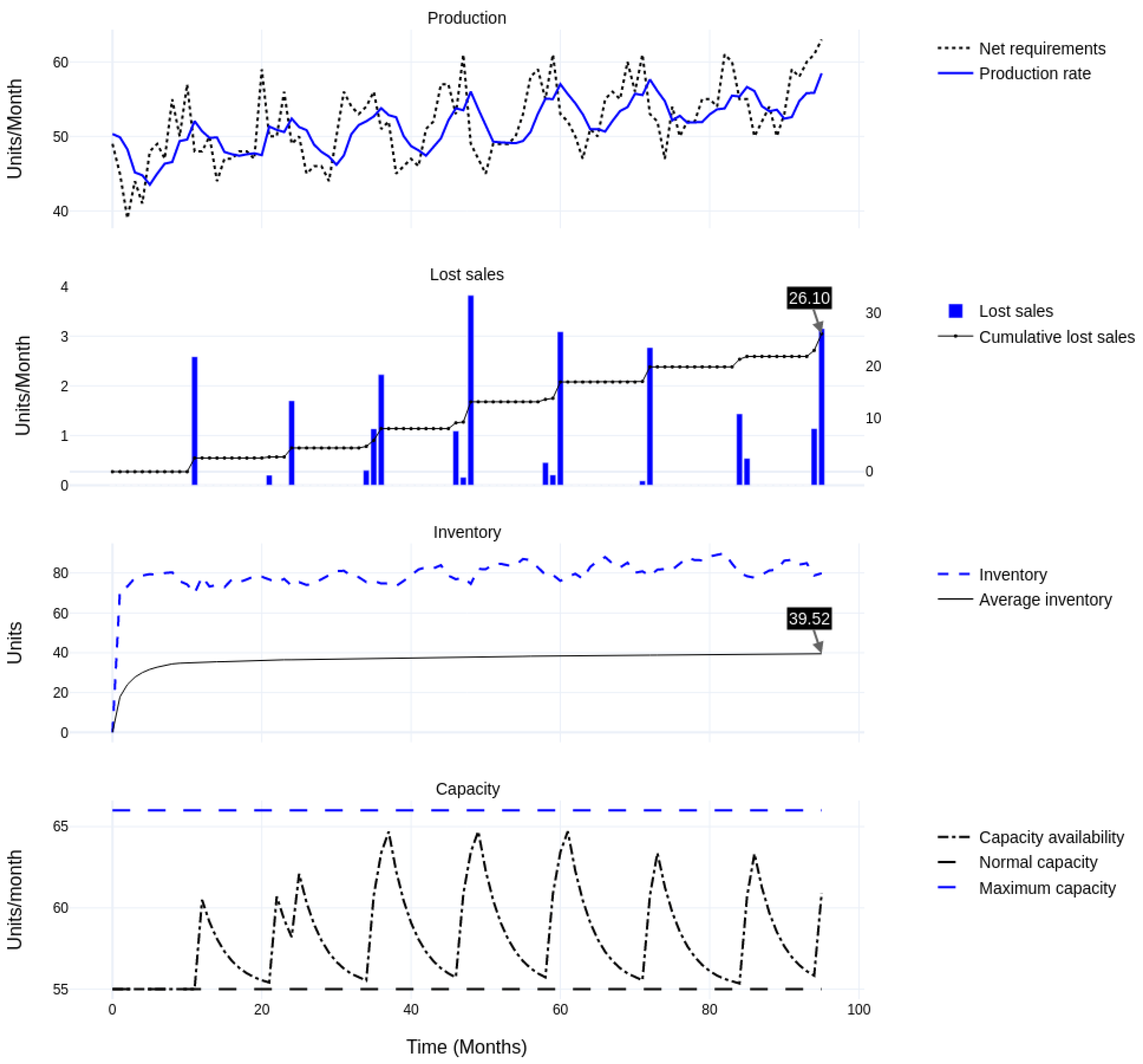
| (B) After heuristic adjustment: 20% discretionary capacity; quick ramp-up and slow ramp-down (2) | Lost Sales | 26.10 | 10.27 | −61% | −10.2% | −42.5% |
| Inventory | 39.52 | 37.54 | −5% | 0.2% | 1.0% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sankaran, G.; Palomino, M.A.; Knahl, M.; Siestrup, G. A Modeling Approach for Measuring the Performance of a Human-AI Collaborative Process. Appl. Sci. 2022, 12, 11642. https://doi.org/10.3390/app122211642
Sankaran G, Palomino MA, Knahl M, Siestrup G. A Modeling Approach for Measuring the Performance of a Human-AI Collaborative Process. Applied Sciences. 2022; 12(22):11642. https://doi.org/10.3390/app122211642
Chicago/Turabian StyleSankaran, Ganesh, Marco A. Palomino, Martin Knahl, and Guido Siestrup. 2022. "A Modeling Approach for Measuring the Performance of a Human-AI Collaborative Process" Applied Sciences 12, no. 22: 11642. https://doi.org/10.3390/app122211642
APA StyleSankaran, G., Palomino, M. A., Knahl, M., & Siestrup, G. (2022). A Modeling Approach for Measuring the Performance of a Human-AI Collaborative Process. Applied Sciences, 12(22), 11642. https://doi.org/10.3390/app122211642