
Fresher Experience Plays a More Important Role in Prioritized Experience Replay

Abstract
:1. Introduction
- Evaluation of Freshness. A freshness discounted factor is introduced evaluate the freshness of each experience during the calculation of the priority of each experience. The constraint of increases sampling probability of the fresher experience. We refer to this method as freshness prioritized experience replay (FPER) in the rest of this paper.
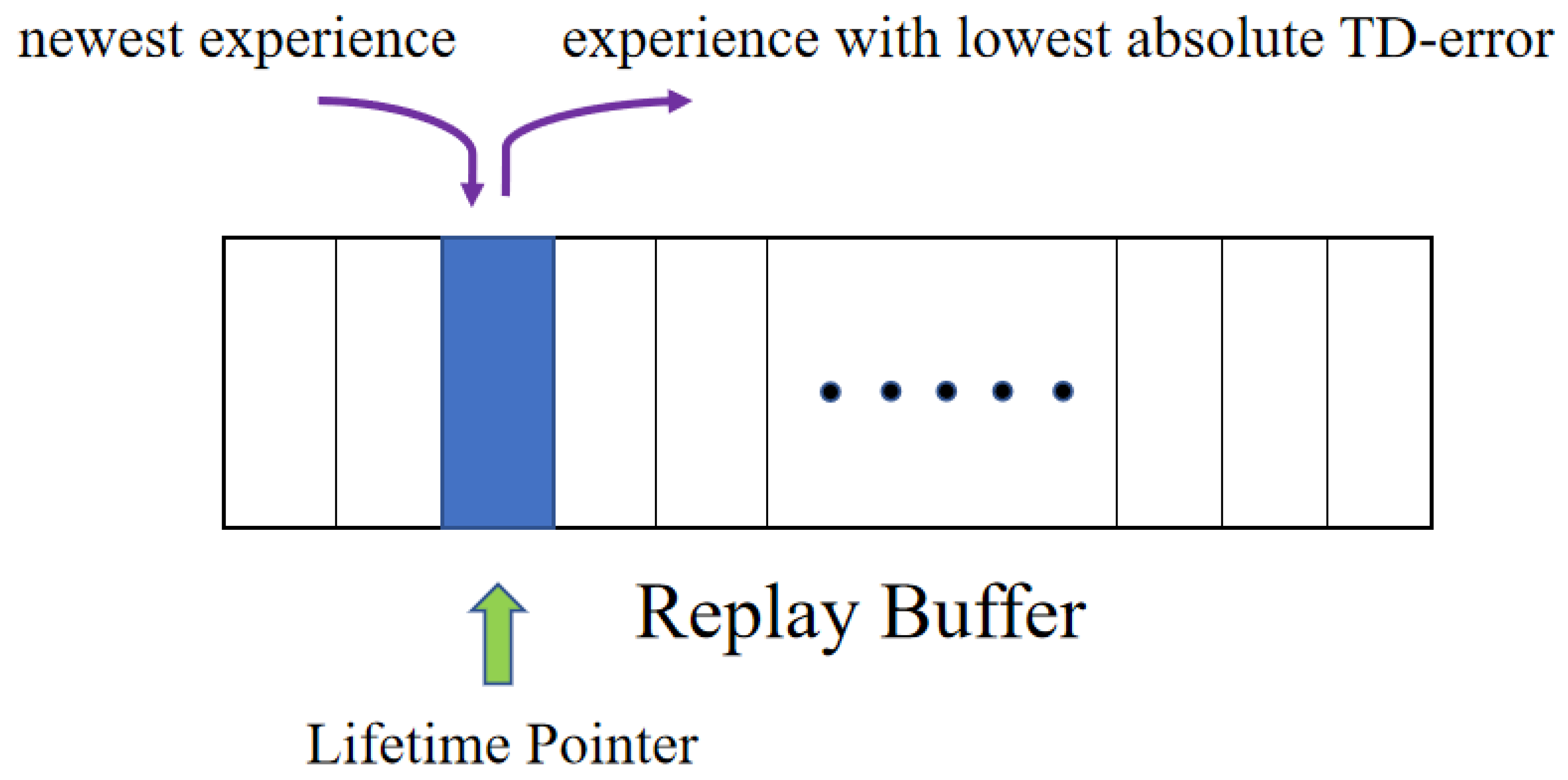
- Lifetime Pointer. In order to make the learning process more stable and to accelerate the convergence process, a lifetime pointer scheme is proposed. The pointer always points to the position of the experience with the lowest absolute TD-error. When the latest experience enters the buffer, it overwrites on the position pointed by the lifetime pointer. It prolongs the lifetime of valuable experiences, reduces the lifetime of worthless experiences, and further breaks the data correlation.
2. Related Work
3. Methodology
3.1. Dueling DQN and DDPG
3.2. PER
3.3. Evaluation of Freshness
3.4. Lifetime Pointer
4. Algorithm
| Algorithm 1 Dueling DQN with FPER |
|
| Algorithm 2 DDPG with FPER |
|
5. Experiment
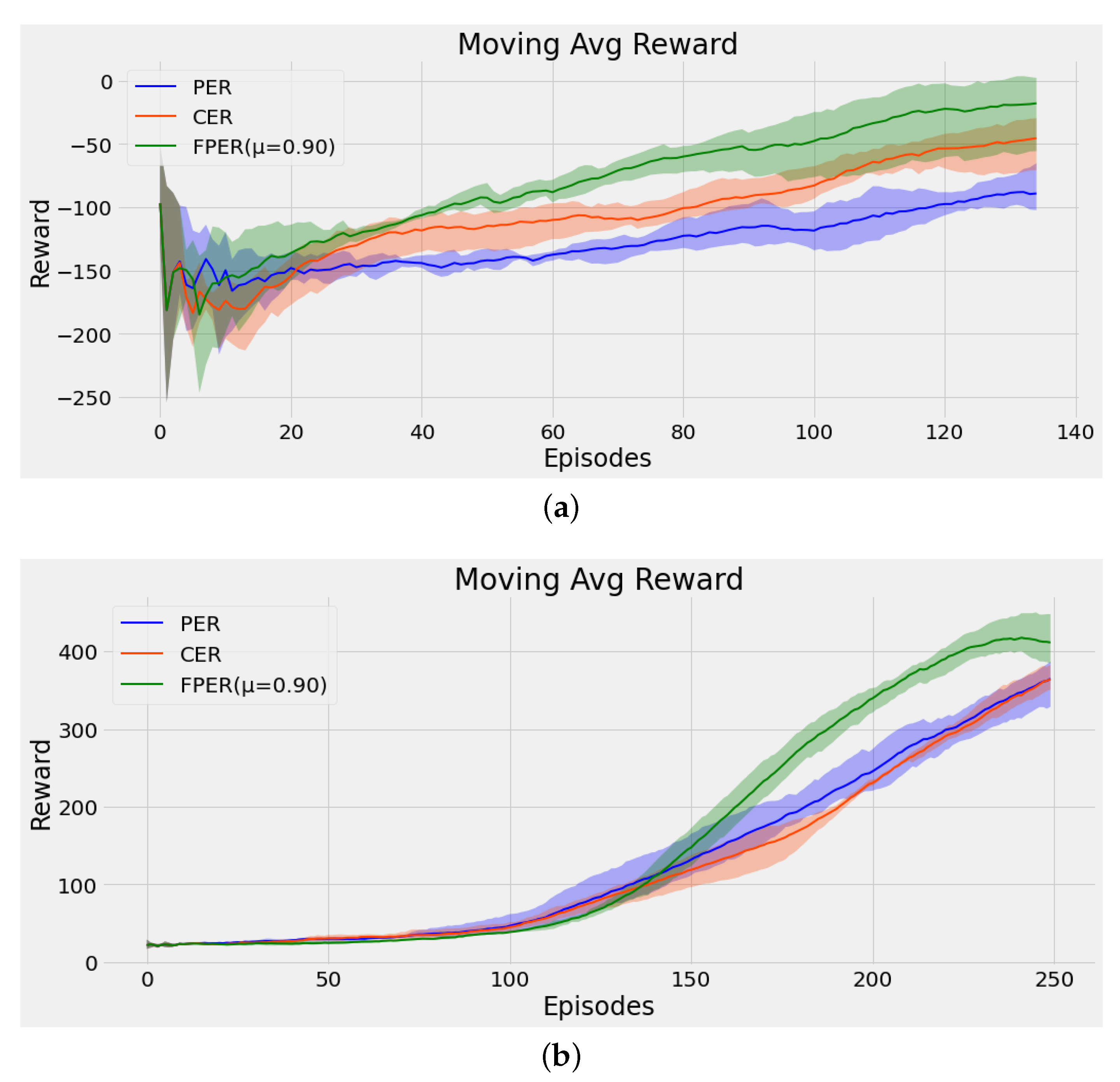
5.1. Discrete Control
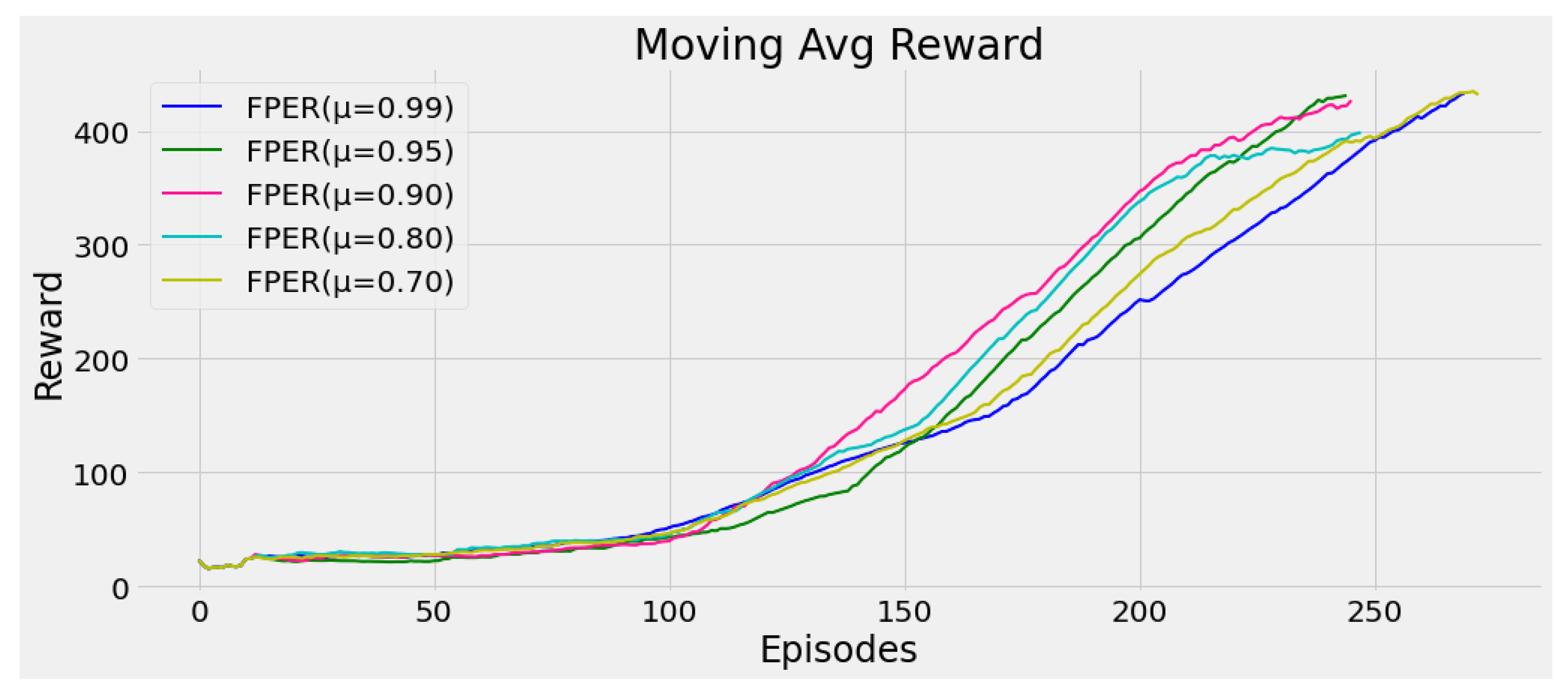
5.2. Importance of Freshness
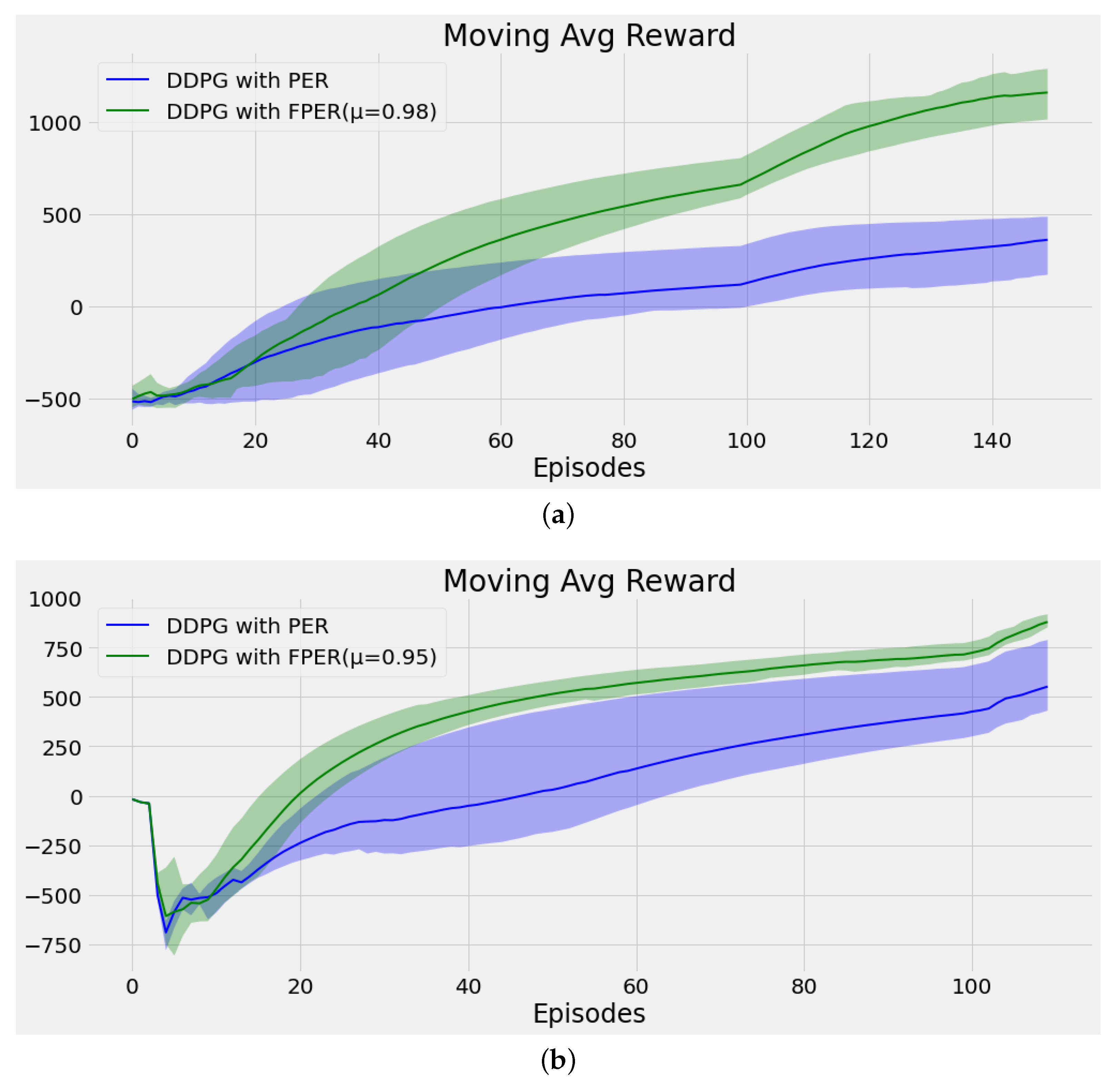
5.3. Continuous Control
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.; Guez, A.; Sifre, L.; Driessche, G.V.D.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Deisenroth, M.P. A Survey on Policy Search for Robotics. Found. Trends Robot. 2011, 2, 1–142. [Google Scholar] [CrossRef] [Green Version]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Hu, Y.J.; Lin, S.J. Deep Reinforcement Learning for Optimizing Finance Portfolio Management. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 14–20. [Google Scholar] [CrossRef]
- Charpentier, A.; Elie, R.; Remlinger, C. Reinforcement learning in economics and finance. Comput. Econ. 2021, 1–38. [Google Scholar] [CrossRef]
- Hambly, B.; Xu, R.; Yang, H. Recent advances in reinforcement learning in finance. arXiv 2021, arXiv:2112.04553. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. (CSUR) 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Zhang, D.; Han, X.; Deng, C. Review on the research and practice of deep learning and reinforcement learning in smart grids. CSEE J. Power Energy Syst. 2018, 4, 362–370. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-line building energy optimization using deep reinforcement learning. IEEE Trans. Smart Grid 2018, 10, 3698–3708. [Google Scholar] [CrossRef] [Green Version]
- Wei, F.; Wan, Z.; He, H. Cyber-attack recovery strategy for smart grid based on deep reinforcement learning. IEEE Trans. Smart Grid 2019, 11, 2476–2486. [Google Scholar] [CrossRef]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Citeseer: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Lin, L.J. Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hasselt, V.H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI’16 Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, V.H.; Lanctot, M.; Freitas, D.N. Dueling Network Architectures for Deep Reinforcement Learning. Int. Conf. Mach. Learn. 2016, 32, 1995–2003. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International conference on machine learning. PMLR, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.V.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A distributional perspective on reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 449–458. [Google Scholar]
- Dabney, W.; Rowland, M.; Bellemare, M.; Munos, R. Distributional reinforcement learning with quantile regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Zhang, S.; Sutton, R.S. A Deeper Look at Experience Replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Liu, R.; Zou, J. The Effects of Memory Replay in Reinforcement Learning. In Proceedings of the 56th Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 2–5 October 2018. [Google Scholar]
- Hou, Y.; Liu, L.; Wei, Q.; Xu, X.; Chen, C. A novel DDPG method with prioritized experience replay. In Proceedings of the IEEE International Conference on Systems, Banff, AB, Canada, 5–8 October 2017. [Google Scholar]
- Shen, K.H.; Tsai, P.Y. Memory Reduction through Experience Classification f or Deep Reinforcement Learning with Prioritized Experience Replay. In Proceedings of the 2019 IEEE International Workshop on Signal Processing Systems (SiPS), Nanjing, China, 20–23 October 2019. [Google Scholar]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Wu, F.; Zhao, J. An Overview of the Action Space for Deep Reinforcement Learning. In Proceedings of the 2021 4th International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 22–24 December 2021; pp. 1–10. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | LunarLander-v2 | CartPole-v1 | ||
|---|---|---|---|---|
| Time Steps | ||||
| Algorithm | ||||
| FPER | ||||
| CER | ||||
| PER | ||||
| Environment | HalfCheetah-v1 | Ant-v1 | ||
|---|---|---|---|---|
| Time Steps | ||||
| Algorithm | ||||
| FPER | ||||
| PER | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Ning, D.; Zhang, C.; Liu, S. Fresher Experience Plays a More Important Role in Prioritized Experience Replay. Appl. Sci. 2022, 12, 12489. https://doi.org/10.3390/app122312489
Ma J, Ning D, Zhang C, Liu S. Fresher Experience Plays a More Important Role in Prioritized Experience Replay. Applied Sciences. 2022; 12(23):12489. https://doi.org/10.3390/app122312489
Chicago/Turabian StyleMa, Jue, Dejun Ning, Chengyi Zhang, and Shipeng Liu. 2022. "Fresher Experience Plays a More Important Role in Prioritized Experience Replay" Applied Sciences 12, no. 23: 12489. https://doi.org/10.3390/app122312489
APA StyleMa, J., Ning, D., Zhang, C., & Liu, S. (2022). Fresher Experience Plays a More Important Role in Prioritized Experience Replay. Applied Sciences, 12(23), 12489. https://doi.org/10.3390/app122312489