1. Introduction
Nowadays, cyber security and digital forensics are the foundations for ensuring security for all digital flows of information. Both main disciplines can be divided into smaller, more specific fields. The discipline of digital forensics encompasses many different areas, including computer forensics, network forensics, mobile forensics, IoT forensics, and malware forensics [
1]. The emerging sub-discipline of digital forensics also covers financial technologies, which include different money activities such as payments, fund transfers, and other financial transactions. As they are intended for a wide range of users, they include those with good and bad intentions. The latter are leveraging financial transactions for fraud, extortion, money laundering, and other financial activities in the criminal underground. Those incidents may use and abuse the traditional financial infrastructure, online and mobile payment systems, or independently distributed crypto currency systems [
1].
With the daily increase of different digital frauds, especially those connected to financial fraud, there is a need for more effective tools and approaches to prevent them. Furthermore, there is also a need for fraud investigators. Recently, many traditional digital forensic investigators have had to pay more attention to financial investigations. To fill the gap and facilitate work for investigators, this paper presents STALITA, an innovative platform for the analysis of bank transactions. STALITA enables the import of large-scale heterogeneous data into a complex network represented by a Neo4j graph-based database [
2]. Due to data sensitivity, it enables independent transaction inspections. Graph data and their topological properties are analysed using various graph algorithms supported by Neo4j and third-party libraries, while custom-built graph-based visual analytics allow for more in-depth investigations and the discovery of new knowledge.
Furthermore, the Law Enforcement Agency (LEA) struggles to find useful information in large amounts of heterogeneous data that can be crucial for investigations. In doing so, investigators face the following challenges:
Most of the investigations in the LEA are related to large amounts of electronic data that must be analysed;
Most of these data are in an unstructured or semi-structured form and various formats that require the use of special domain-specific tools for data gathering, cleaning, and parsing;
The data can include crucial information for the investigation, but the ratio between useful information in these data and all available data is very low. Therefore, LEAs need efficient tools for knowledge discovery in data;
Almost each investigation requires a specific domain-specific approach, including various data analysis techniques and tools.
Thus, LEAs need efficient, user-friendly analytical platforms, including basic and advanced techniques, for the discovery of useful information in a large amount of heterogeneous data related to investigations.
A new platform (STALITA) for bank transaction analysis is presented in this paper, which supports heterogeneous data sources, most of the advanced techniques for graph analysis due to the use of Neo4j technology, various types of machine learning and graph-based algorithms that can be incorporated for financial fraud investigation, and, finally, various visual analytics tools. The platform supports collaborative and uniform workflow on diverse data sources through web-based applications, user-friendly extensions (template queries) for domain-specific analyses, and a high level of customisability of visual analytics tools.
The rest of the paper is organised as follows: The related work is explained in the next section.
Section 3 provides the methodology used in the proposed paper. The results achieved with the proposed platform are presented in
Section 4.
Section 5 concludes the paper.
2. Related Work
The aim of digital forensic analysis is to determine answers to investigation and inquiry questions: who, how, what, why, when, and where [
3]. To achieve this, digital forensics is the practice of collecting, analysing, and reporting on digital data in a way that is legally admissible. Therefore, several process models were proposed for forensic investigation [
4]. Academics in the forensic field held consortiums and defined a general standard digital investigation process model. This model is composed of six stages: planning, incident response, collecting data, data analysis, presentation of findings, and instance closure [
4]. The National Institute of Standards and Technology described the original forensic process model. This model includes four phases: collection, examination, analysis, and reporting [
5]. All those steps are possible to achieve in a reasonable time if the investigated data are in an accepted quantity and quality. Due to the growing amount of data that needs to be investigated, the authors of [
6] presented a realistic implementation of the reduction of collection and processing times, as well as reducing the time needed to undertake analysis and providing investigators with evidence or actionable intelligence in a timely manner [
6].
The investigation of fraud in the financial domain is restricted to those who have access to relevant data. Customer financial records are protected by law and internal policies; therefore, they are not available for most of the researchers in the area of fraud detection [
7]. Due to these restrictions, cyber forensic tools are more common in other areas, such as computer forensics, network forensics, mobile forensics, and database forensics [
8]. However, they still do not support processing data from multimodal data sources in a uniform way. In computer forensics, EnCase is a commercial platform for deep analysis for recovering deleted files, sorting, and reviewing files, file signature analysis, internet history review, hash value and registry analysis, timeline, and gallery review [
9]. Network traffic analysis, multithreading, modularity of the input and output interfaces, port-independent protocol identification, and large-scale PCAP data analysis are the main features of Xplico. XRY is a mobile forensics tool to investigate smart phones, mobile phones, tablets, and GPS navigation systems. It is used in the areas of intelligence operations, criminal investigations, law enforcement, and military agencies [
10]. The SQLite forensics browser is a database forensics tool for creating, managing, and analysing evidence during the creation of the case. The tool has the capabilities of creating databases, scanning, and previewing database files, database indexing, adding custodian entries, searching, and exporting file formats [
11]. More advanced techniques need to be used due to the restrictions mentioned in the financial domain and the inability to support heterogeneous data.
Anomaly detection in the financial domain has been studied extensively for this purpose, and most of the studies rely on statistical, artificial, and machine learning techniques [
12]. To overcome the challenges associated with supervised techniques, semi-supervised and unsupervised algorithms are becoming more common [
12]. Frequently used models for financial fraud are decision trees, support vector machines, logistic regressions, k-means, and k-nearest neighbour clustering [
13,
14,
15]. Nowadays, deep learning detection techniques have emerged and gained importance in the last few years, demonstrating significantly better performance than other techniques in addressing financial fraud problems [
12]. These include neural network architectures of various types, such as convolutional neural networks, long short-term memory networks, autoencoders, and generative adversarial networks [
16]. Pourhabibi et al. presented a literature review of different graph-based anomaly detection techniques that have been studied in the published literature in the context of financial fraud [
17]. The authors of [
17] divided graph-based approaches into five different groups, such as community-based, probabilistic-based, structural-based, compression-based, and decomposition-based [
17]. Jeong et al. [
18] provided an overview of the research on data mining-based fraud detection. They showed that data mining techniques are providing great aid in financial accounting fraud detection and are applied most extensively to provide primary solutions to the problems. The authors have also classified research under a few criteria, such as data set, data mining algorithm, and viewpoint of research. The authors of [
19] presented a theoretical framework to predict when and how investigators might use data visualisation techniques to detect fraudulent transactions [
19]. The author Astrakhantseva in [
20] proposed a supplement for classical financial analysis with a special section that analyses transactions for compliance with market conditions, identifies schematic and fictitious transactions, and determines the degree of their impact on the occurrence of property insufficiency and signs of bankruptcy [
20].
3. Materials and Methods
The platform presented for bank transaction analysis is composed of three main components: data import, backend Application Programming Interface (API), and custom frontend visual analytics. In the continuation, each of these main parts will be dissected and described in detail, while
Figure 1 shows the overall infrastructure of the proposed STALITA platform.
3.1. Data Importation
The data import is possible in three different ways: directly by using the Neo4j Cypher query language; via Extensible Markup Language (XML); and via the Representational State Transfer (REST) supported in Neo4J. Although the Neo4j Cypher query language allows for the import of diverse data via appropriate queries, it is the least useful because most data is provided in a standard format, and the following approaches are more efficient on larger datasets. A more frequently used approach is via a user interface, which is incorporated into the visual part of the platform using XML files. The ISO 20022 Standard and bank statement CAMT.053 format are used for the XML [
27]. XML importation is much more suitable, as you can import data transactions received from the banks directly. The backend API is in charge of validating the XML files and then importing data directly into the Neo4j database. The third option is to use the REST protocol, which is a very similar approach as with XML files. The complete datasets are sent to the backend API.
3.2. Backend API
The second main part of the proposed investigation platform is the backend API. Each of the main components, such as the Neo4j databases and the PostgreSQL database for metadata, are encapsulated in Docker containers. Docker not only enables faster deployment and testing, but also enables additional data isolation and security [
28]. The latter is also significant for data from financial fraud investigations. Each investigation case is encapsulated in its own container (i.e., access is enabled only for authorised case investigators); therefore, other users have no access (e.g., unauthorised case investigators or possible intruders). Moreover, the encapsulation in containers is not the only security measure since STALITA also uses Azure Active Directory (AAD) and Lightweight Directory Access Protocol (LDAP) for user management and authentication purposes. Only the Neo4j processing part is utilised in the presented investigation platform, while the frontend visual analytics are custom made and will be described in the continuation. Neo4j`s main advantage is a large set of general graph-based algorithms implemented in open-source extension libraries such as the Awesome Procedures on Cypher (APOC) and Graph Data Science (GDS) [
29,
30]. APOC includes over 450 standard procedures, providing functionality for utilities, conversions, graph updates, and more [
29]. The metadata stored in PostgreSQL includes users and their permissions, log history, each case’s metadata (e.g., case investigators, history of cypher queries, and investigator’s notes), and custom entity icons are treated as the platform’s metadata. The entire backend API is developed and implemented in the Java Spring framework using IntelliJ IDEA.
3.3. Frontend Application
Finally, the third main part is the web-based frontend application, which controls the backend and enables a user-friendly visual analytical task. The application runs inside a web browser, which enables high portability and execution on various platforms (from desktop environments to smart phones). The user interface is implemented in Angular, which brings a modern, portable, and responsive graphical user interface. The application supports:
Management of users;
Management of investigation cases;
Data import for individual investigation cases;
Communication between users about the specific investigation case;
Advanced analytical tasks.
The most important part of the analytical tasks is the visualisation of graph data. The users can perform Cypher queries on specific investigation cases and visualise the results. This can be done in two ways: direct and indirect modes. In the direct mode, the user enters the Cypher query manually, which requires good knowledge of the Cypher query language. In this mode, the application increases productivity by automatically verifying the entered Cypher query and marking any potential errors. Finally, the entered query can be stored for potential reuse by other users.
For beginners, the Cypher query language is tedious to write. Therefore, the application brings a novel approach to user-friendly queries: indirect mode, which works in a way similar to user-defined extensions. This concept works as follows: An advanced user prepares a template in the Cypher query, which is an ordinary Cypher query with parametrised fields, e.g., the name of a potential suspect and date of the bank transaction. A description of each parametrised field and allowed data format are defined at the same time. Finally, the template query is saved in the backend for other users. Less advanced users can execute the template Cypher queries without any knowledge of the Cypher query language. The only task for the user is to fill in the required fields with the parameters and execute the query.
The tabular mode of visualising query results is the default, allowing for direct inspection of the Cypher query results. In the case of graph data, nodes and edges are converted into tabular form. For higher productivity, the application supports data export into the CSV format and the filtration of data.
Given that the Cypher query language works on graph-based data representation, the application supports the graphical visualisation of entities, which are represented with nodes, and connections between entities, which are represented by edges between nodes. The visualisation is performed directly inside the web browser by using 2-D hardware acceleration, which allows for interactive visualisation of large graphs with thousands of entities.
To visualise the graphs, the nodes are placed on the canvas using the force graph layout [
31]. In this way, neighbouring nodes are grouped based on their connectivity. Additionally, the user can move individual nodes interactively, which moves nearby nodes proportionally to the neighbourhood. This method provides a clear visualisation of data by grouping nodes into distinct clusters. Moreover, for data with a hierarchical structure, the application can align the nodes automatically into the tree layout.
The application also supports multiple charts for data in tabular form: histograms, radial chart/flow maps, line charts, scatter plots, and pivot tables. In general, the application supports standard chart visualisation, where the user can define the columns used in the visualisation. Additionally, the application brings the following novelties to individual charts: Because a line chart is intended to be used also for temporal data, the application includes value aggregation on a daily, monthly, and hourly basis. The scatter plot is designed for discrete variables; therefore, the application supports colouring of individual entries according to the Cypher query results. In the same manner, tool-tip texts are displayed above each entry.
3.4. Definition of Graphs’ Topological Properties
As was previously noted, the basic data structure of the presented platform is based on graphs. The definition of graphs, their most common topologies, and some topological properties used in graph analysis are presented in this subsection. Graphs
G are defined as
G = (
N, E), where
N = {
ni} is a node-set, and
E = {
ei,j} is an edge-set of
G [
32]. A given node, ni, corresponds to a subject (in the context of bank transaction analysis, this could be a bank account, a person, or a company), whereas an edge,
ei,j = (
ni,
nj), can define ownership (the person owns an account, the person owns a company), or a transaction (from one account to another). There are many different options for node and edge meanings as we are working with unstructured data. Graph topologies are typically defined by their topological properties, and we know four major types of graphs: small-world, scale-free, random, and regular [
33].
The topological properties that define graph types can also be applied to basic and assembled analyses of case investigations. Some of the properties are presented and described in the continuation:
Node’s degree k[ni] could, for example, be used to count a number of people's bank accounts or transactions, and similar countings are defined as (1):
The average degree ka[ni] of nodes linked to ni can, for example, describe the average number of transactions for the persons linked to
ni. It is defined as (2):
The number of triplets of transactions t[ni] that include node ni is, for example, used for the search of circles of transactions in the investigation of money laundering cases. Mathematically, it is defined as (3):
The local clustering coefficient u[ni] the proximity of a cluster of transactions, a bank account, or, eventually, people to the center. The coefficient could be written as (4):
Local betweenness centrality b[ni] shows the size of clusters of, for example, bank accounts, persons, or transactions that a given
ni (bank account, person, or transaction) is linked with. Its mathematical definition is (5):
The size of nodes and edge sets in graphs also defines the time complexity for different types of graphs and different topological properties. In [
28], it has been shown that the number of edges does not influence the time complexity, as they are checking all possible connections in the graph (full graph). In the case of bank transactions` investigations, we will rarely search in full graphs, and, by considering that, we can assume that the number of nodes and edges has an influence on time complexity in our graph database structure.
5. Conclusions
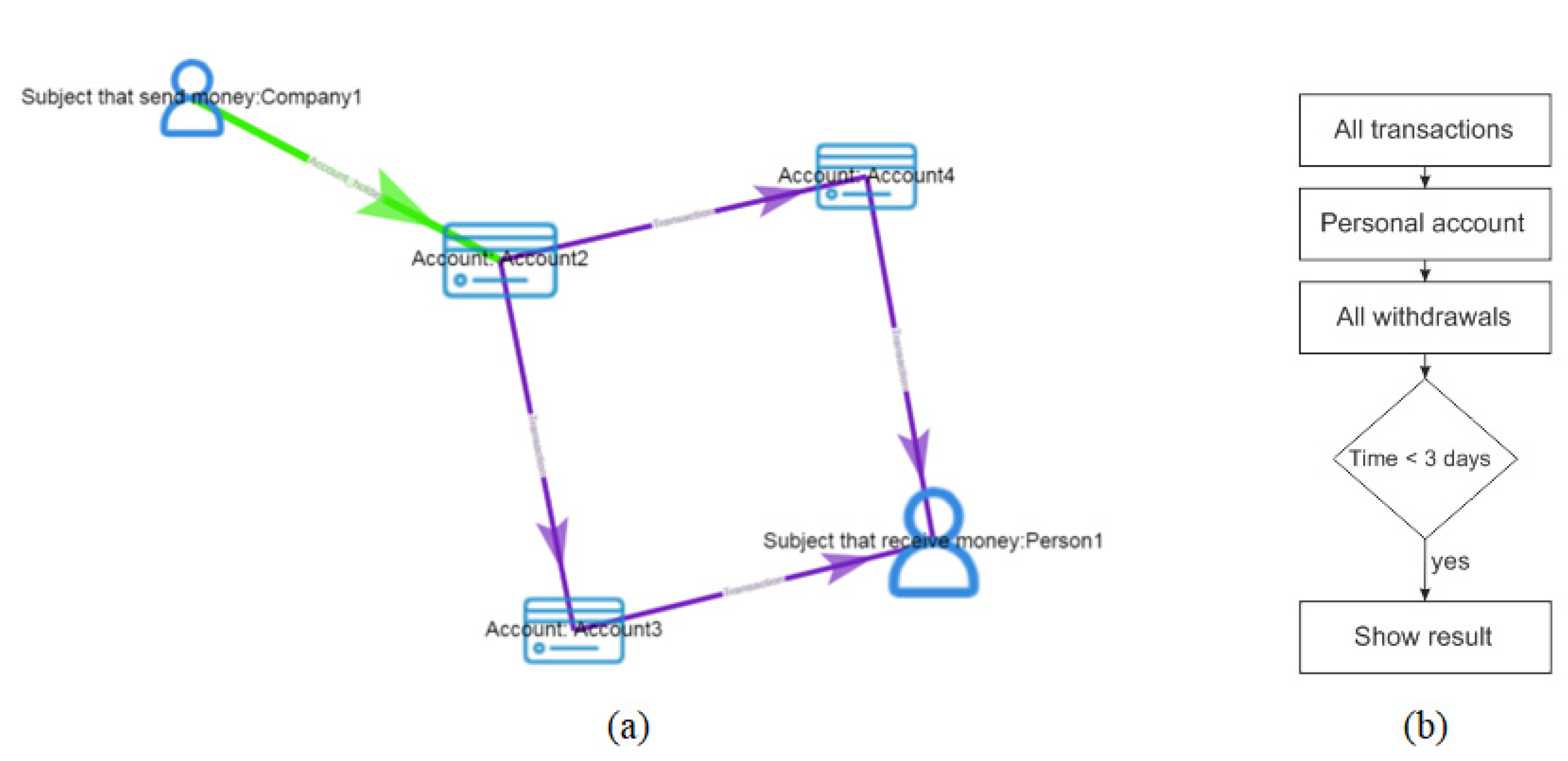
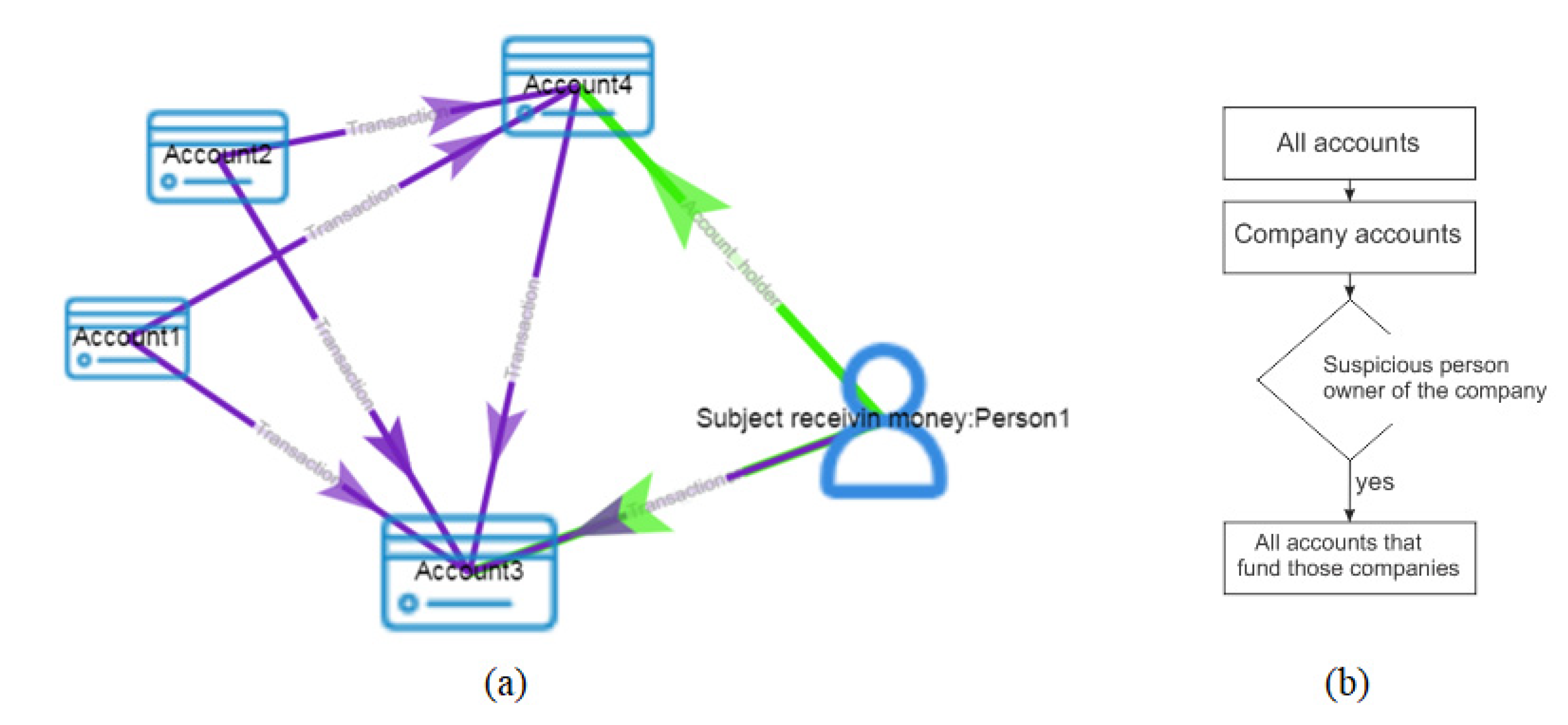
Bank transactions are excellent examples of STALITA graph data analyses. Tabular data and relational databases are good for joining and aggregating but not for discovering relationships. For example, in the tables, the transactions between actors are not as visible as in the graphs. Cypher queries in STALITA are excellent tools for the discovery of suspicious patterns in the data. For example, simple queries provide answers such as: which person, in different steps, sent money to certain accounts that was withdrawn at a certain time.
An investigator can visualise results in STALITA with tables, charts, and graphs. On the one hand, a graph makes it easier to find suspicious connections. On the other hand, time charts show distributions with increasing numbers of transactions or amounts. The result can also be analysed with pivot tables and exported in tabular format. STALITA also enables the combination of bank transaction data with other data, such as phone calls. For example, investigators can supplement the database containing transactions between accounts and account holders with the telephone numbers held by these account holders and their calls to each other, allowing investigators to search for patterns and links between bank and telephone traffic.
The advantages of the platform are validated by the example investigation case presented in the results. The initial findings of the OPML have been proven by applying the tools implemented in STALITA. In four short steps of the presented investigation, the whole, usually complicated process has been completed, and the money laundering fraud has been confirmed. One of the STALITA tools presented, the Cypher query, confirmed the OPML suspicions immediately and, even more, revealed new similar accounts used for the money laundering in the same investigation case. To confirm the findings, other tools supported by the presented platform have been used, such as pivot tables, time, and scatter charts. The sums of income and the withdrawals on the suspicious accounts have been proven by applying the mentioned tools. Finally, the suspects were prosecuted criminally.
The presented investigation case is only one of many possible uses of the presented platform. The platform will be further developed in the future for specific uses with various types of data. The possible improvements to the platform are automatic data enrichment, either online or from some other sources, and support for the input of newer data formats.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}