
FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection


Abstract
:1. Introduction
- To effectively detect fake news with text and image, we propose a novel model for fine-grained fusion of textual features and visual features.
- The proposed model utilizes attention mechanism to enhance the visual features as well as the textual features, and fuse the enhanced visual features and the enhanced textual features, which not only considers the correlations between different visual features but also captures the dependencies between textual features and visual features.
- We conduct extensive experiments on the real-word dataset. The results demonstrate the effectiveness of the proposed model.
2. Related Work
2.1. Unimodal Fake News Detection
2.2. Multimodal Fake News Detection
2.3. Scaled-Dot Product Attention
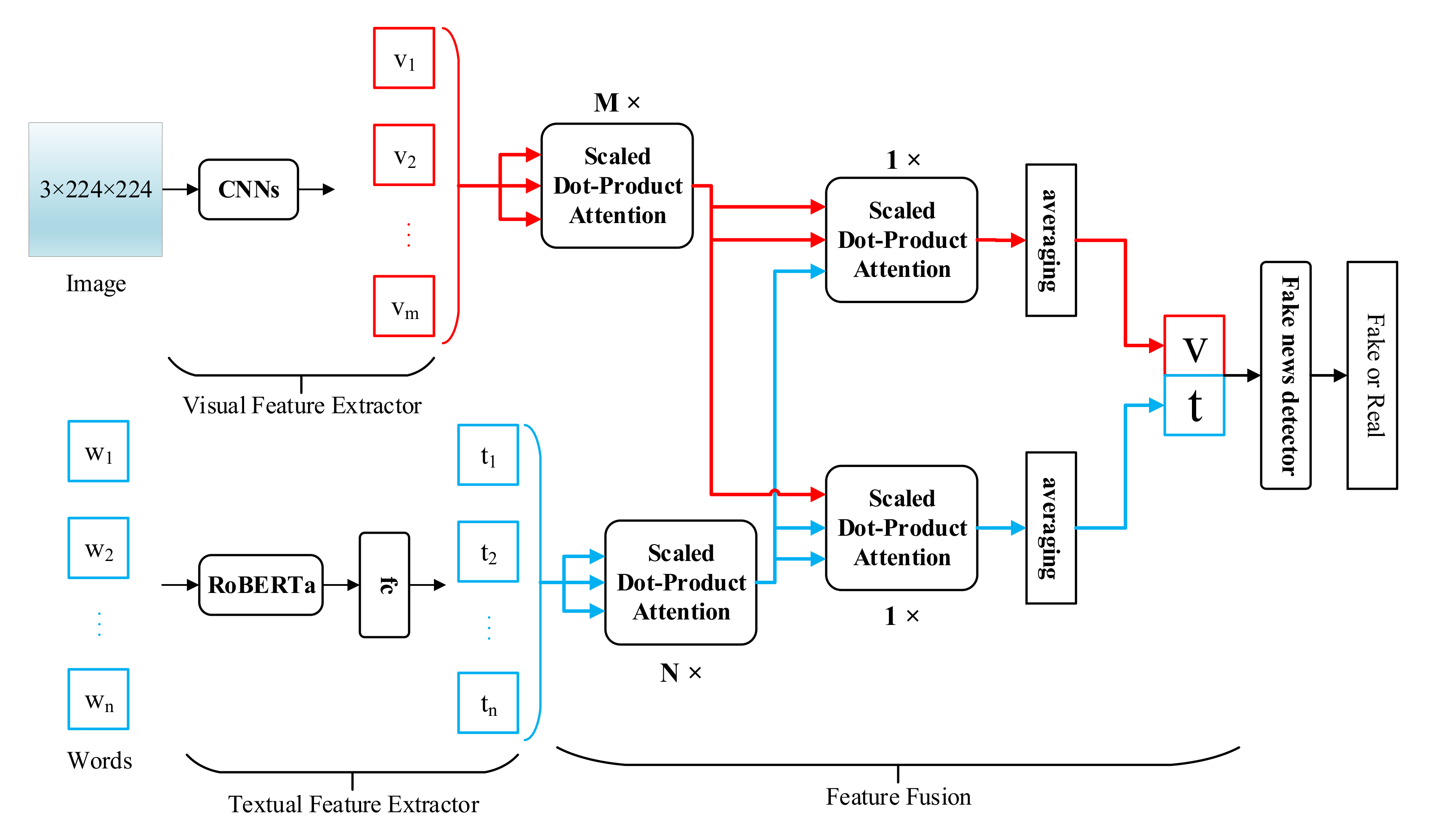
3. Model
3.1. Model Overview
3.2. Visual Feature Extraction
3.3. Textual Feature Extraction
3.4. Feature Fusion
3.5. Fake News Detector and Model Learning
4. Experiments
4.1. Dataset
4.2. Settings
4.3. Baselines
- Textual: All scaled dot-product attention blocks and the visual feature extractor are removed from the proposed model FMFN. The textual features obtained by the textual feature extractor are transformed to a vector by the averaging, and the vector is fed into a binary classifier to train a model. For a fair comparison, the parameters of the RoBERTa in the textual feature extractor are frozen.
- Visual: Similar to textual, the visual feature extractor, and a binary classifier are jointly trained for fake news detection. For a fair comparison, the parameters of the first 16 convolutional layers in the visual feature extractor are fixed.
- VQA [38]: The objective of visual question answering is to answer questions concerning certain images. The multi-class classifier in the VQA model is replaced with a binary classifier, and one-layer LSTM is used for a fair comparison.
- NeuralTalk [39]: The model aims to produce captions for given images. The joint representation is obtained by averaging the outputs of RNN at each time step.
- att-RNN [4]: A novel RNN with an attention mechanism is utilized to fuse multimodal features for effective rumor detection. For a fair comparison, we do not consider the social context, and only fuse textual features and visual features.
- EANN [5]: The model is based on adversarial networks, which can learn event-invariant features containing multimodal information.
- MVAE [6]: By jointly training the VAE and a classifier, the model is able to learn a shared representation of multimodal information.
- CARMN [7]: An attention mechanism is used to fuse word embeddings and one image embedding to obtain fused features. From the fuse features, key features are extracted as a joint representation.
4.4. Comparison with Baselines
5. Ablation Analysis
5.1. Component Analysis
- FMFN(CONCAT): The last two scaled dot-product attention blocks are removed from the proposed model FMFN. By the averaging, the and are transformed to two vectors, respectively. The concatenation of the two vector is fed into the fake news detector. Therefore, it cannot capture the dependencies between textual features and visual features.
- FMFN(TEXT): We do not use the refined visual features and only use the refined textual features . The refined textual features are transformed to a vector by the averaging, and the vector is fed into the fake news detector.
- FMFN (M = 0): The number of scaled dot-product attention blocks is set to 0, which means that we do not consider the correlations between different visual features.
5.2. Visualization of the Joint Representation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Czeglédi, C.; Valentinyi, K.V.; Borsos, E.; Járási, É.; Szira, Z.; Varga, E. News Consuming Habits of Young Social Media Users in the Era of Fake News. WSEAS Trans. Comput. 2019, 18, 264–273. [Google Scholar]
- Helmstetter, S.; Paulheim, H. Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision. Future Internet 2021, 13, 114. [Google Scholar] [CrossRef]
- Zakharchenko, A.; Peráček, T.; Fedushko, S.; Syerov, Y.; Trach, O. When Fact-Checking and ‘BBC Standards’ Are Helpless: ‘Fake Newsworthy Event’ Manipulation and the Reaction of the ‘High-Quality Media’ on It. Sustainability 2021, 13, 573. [Google Scholar] [CrossRef]
- Jin, Z.; Cao, J.; Guo, H.; Zhang, Y.; Luo, J. Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 795–816. [Google Scholar]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar]
- Khattar, D.; Goud, J.S.; Gupta, M.; Varma, V. MVAE: Multimodal Variational Autoencoder for Fake News Detection. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2915–2921. [Google Scholar]
- Song, C.; Ning, N.; Zhang, Y.; Wu, B. A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Inf. Process. Manag. 2021, 58, 102437. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Islam, N.; Shaikh, A.; Qaiser, A.; Asiri, Y.; Almakdi, S.; Sulaiman, A.; Moazzam, V.; Babar, S.A. Ternion: An Autonomous Model for Fake News Detection. Appl. Sci. 2021, 11, 9292. [Google Scholar] [CrossRef]
- Alonso, M.A.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment Analysis for Fake News Detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.-F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3818–3824. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A convolutional approach for misinformation identification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3901–3907. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.-F. Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learning. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3049–3055. [Google Scholar]
- Jin, Z.; Cao, J.; Zhang, Y.; Zhou, J.; Tian, Q. Novel Visual and Statistical Image Features for Microblogs News Verification. IEEE Trans. Multimed. 2017, 19, 598–608. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media: A Data Mining Perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Qi, P.; Cao, J.; Yang, T.; Guo, J.; Li, J. Exploiting Multi-domain Visual Information for Fake News Detection. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 518–527. [Google Scholar]
- Wu, K.; Yang, S.; Zhu, K.Q. False rumors detection on Sina Weibo by propagation structures. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 651–662. [Google Scholar]
- Liu, Y.; Wu, Y.-F.B. Early Detection of Fake News on Social Media Through Propagation Path Classification with Recurrent and Convolutional Networks. In Proceedings of the 32th AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal. Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wallace, B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 5753–5763. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R.B. Masked Autoencoders Are Scalable Vision Learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z.; Wang, S.; Hu, G. Pre-Training with Whole Word Masking for Chinese BERT. arXiv 2019, arXiv:1906.08101. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. arXiv 2020, arXiv:2004.13922. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Viualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |
|---|---|---|
| fake news | 3345 | 862 |
| real news | 2807 | 835 |
| images | 6152 | 1697 |
| Method | Accuracy | Fake News | Real News | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | ||
| Textual | 0.725 | 0.763 | 0.661 | 0.708 | 0.677 | 0.774 | 0.722 |
| Visual | 0.657 | 0.682 | 0.617 | 0.648 | 0.622 | 0.68 | 0.65 |
| VQA | 0.736 | 0.797 | 0.634 | 0.706 | 0.695 | 0.838 | 0.76 |
| NeuralTalk | 0.726 | 0.794 | 0.613 | 0.692 | 0.684 | 0.84 | 0.754 |
| att-RNN | 0.772 | 0.854 | 0.656 | 0.742 | 0.72 | 0.889 | 0.795 |
| EANN | 0.782 | 0.827 | 0.697 | 0.756 | 0.752 | 0.863 | 0.804 |
| MVAE | 0.824 | 0.854 | 0.769 | 0.809 | 0.802 | 0.875 | 0.837 |
| CARMN | 0.853 | 0.891 | 0.814 | 0.851 | 0.818 | 0.894 | 0.854 |
| FMFN | 0.885 | 0.878 | 0.851 | 0.864 | 0.874 | 0.896 | 0.885 |
| Method | Accuracy | Fake News F1 | Real News F1 |
|---|---|---|---|
| FMFN (CONCAT) | 0.867 | 0.839 | 0.872 |
| FMFN (TEXT) | 0.874 | 0.845 | 0.876 |
| FMFN (M = 0) | 0.877 | 0.851 | 0.880 |
| FMFN | 0.885 | 0.864 | 0.885 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Mao, H.; Li, H. FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection. Appl. Sci. 2022, 12, 1093. https://doi.org/10.3390/app12031093
Wang J, Mao H, Li H. FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection. Applied Sciences. 2022; 12(3):1093. https://doi.org/10.3390/app12031093
Chicago/Turabian StyleWang, Jingzi, Hongyan Mao, and Hongwei Li. 2022. "FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection" Applied Sciences 12, no. 3: 1093. https://doi.org/10.3390/app12031093
APA StyleWang, J., Mao, H., & Li, H. (2022). FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection. Applied Sciences, 12(3), 1093. https://doi.org/10.3390/app12031093