
BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling

 ,
,  , , ,
, , ,  and
and 
Abstract
:1. Introduction
- We proposed to solve the nested named-entity-recognition problem using the transfer-learning approach, i.e., by fine-tuning pretrained, BERT-based language models.
- The proposed transfer-learning approach (fine-tuning a pretrained BERT language model) could outperform many of the existing heavily engineered, complex-architecture-based approaches for the nested named-entity-recognition problem.
- The nested datasets were jointly labeled so that conventional named-entity-recognition models could also be used, which treated the nested named entity problem as the flat named-entity-recognition task.
- The experiment was carried with two other well-known machine-learning models (conditional random field and the Bi-LSTM-CRF) for the performance comparison. In addition, the performance of the best-performing proposed model was compared with the existing research work.
- This research work compared the performance of different variants of the pretrained BERT models for the nested named-entity-recognition problem based on domain, size of models (base or large), and cased and uncased versions.
- The results were analyzed and discussed in detail while clarifying the factors that were important in the variants of the pretrained BERT models for different categories, which further led to providing good results for the nested named-entity-recognition problem.
2. Related Works
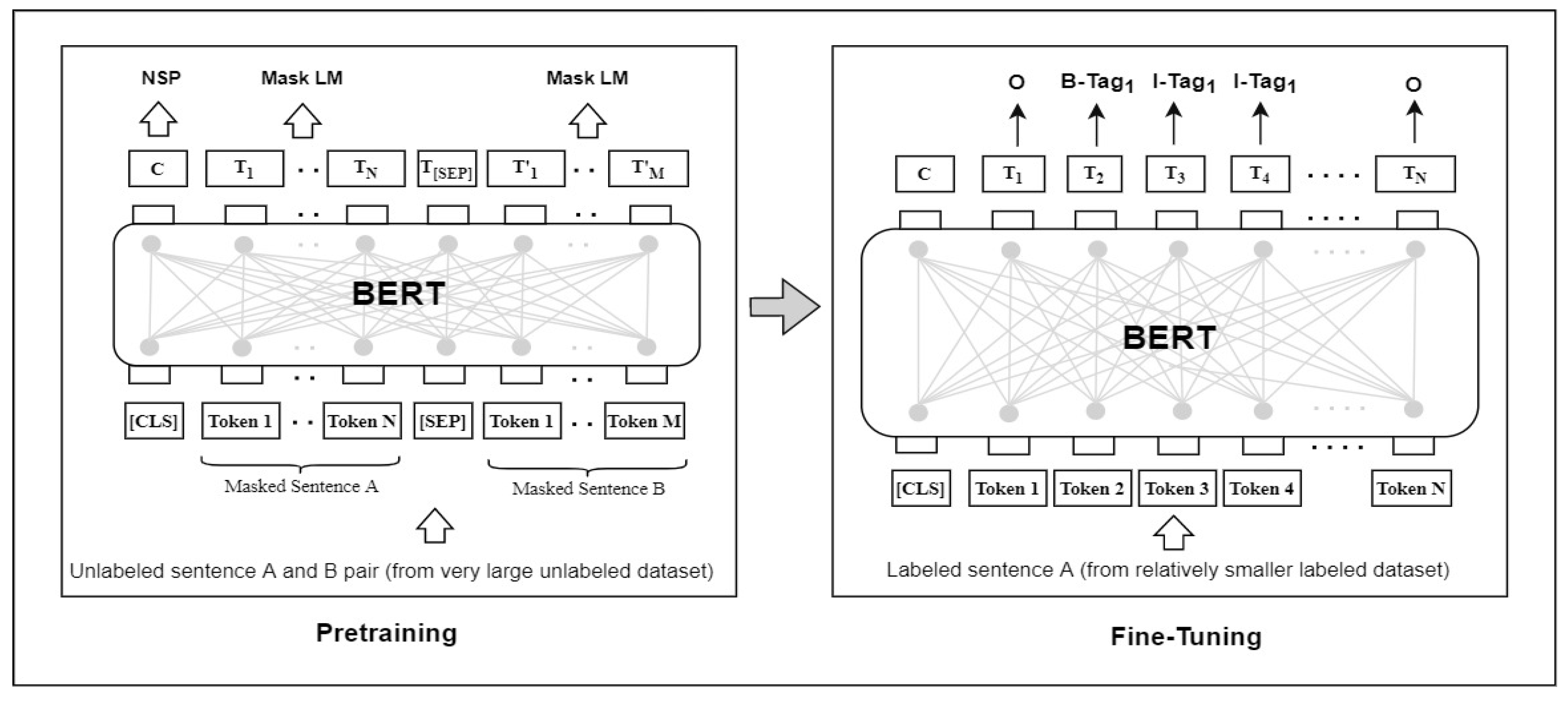
3. Transfer-Learning Approach
3.1. Pretrained BERT Models Used in the Transfer-Learning-Based Approach
3.1.1. Google AI’s Pretrained BERT Models
3.1.2. SciBERT Pretrained BERT Models
3.1.3. BioBERT Pretrained BERT Models
4. Existing Machine-Learning Models
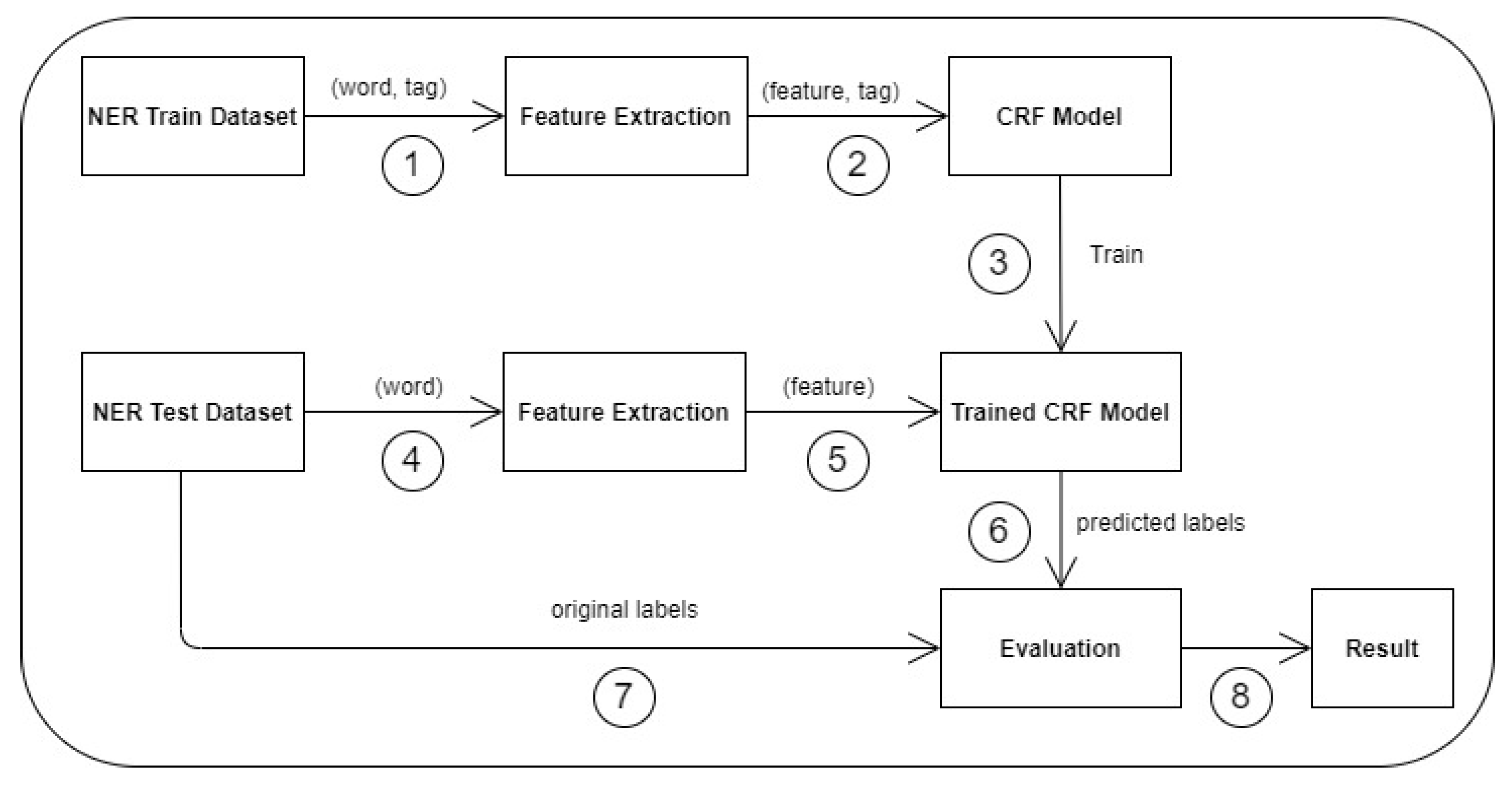
4.1. Conditional Random Field Model
Feature Extraction for the CRF Model
4.2. Bidirectional LSTM-CRF Model
5. Datasets
5.1. GermEval 2014 Dataset
5.2. GENIA Dataset
5.3. JNLPBA Dataset
6. Evaluation Tool and Metrics
7. Results and Discussion
7.1. Discussion of Results for BERT-Based Models
7.2. Discussion of Results for the CRF Model
7.3. Discussion of Results for the Bi-LSTM-CRF Model
7.4. Comparison of the Results with Other Existing Approaches
- On comparing the CRF, Bi-LSTM-CRF, and BERT-based language models, it was found that almost all the BERT-based models performed better than both the other models. The performance of the Bi-LSTM-CRF models was better than that of the CRF model, but not the fine-tuning-based, pretrained BERT-based models.
- There was a huge impact of the language on the BERT-based model, which was clear from the results for the GermEval 2014 (German) nested NER dataset. Even the Bi-LSTM-CRF model performed poorly if the English GLOVE word vectors were used for the word embedding (due to which the German FastText word vectors were used only for the GermEval 2014 dataset).
- The transfer-learning-based approach without any modifications or any external resources performed well on the GENIA, GermEval 2014, and JNLPBA datasets compared to many of the existing approaches. In Table 6, Table 7 and Table 8, comparisons were made with existing research work. There were a number of other research works in this area that achieved better results than the presented transfer-learning approach. Note that we are still far from the state-of-the-art results for the above three datasets. Our approach did not possess any kind of complexity in architecture or implementation. The same was not true for the other existing research works. In this study, we wanted to compare the performances of the pretrained, BERT-based transfer-learning approach without using any external resources such as embeddings, unsupervised training on the new dataset, etc. The study was conducted for a performance comparison between the pretrained BERT models based on domain, model size (base or large), and cased and uncased versions.
- Domain-based pretrained models could perform significantly better than the other BERT models pretrained on different domains. For example, the BioBERT-based models performed better on the GENIA dataset, Google’s multilingual BERT-based model performed better on the GermEval 2014 dataset, and the SciBERT-based model performed better on the JNLPBA dataset (followed by the BioBERT).
- The model size of the pretrained BERT model can also put some impact on the results (in most cases). However, the result difference may not be very significant between the base and large models in all the cases.
- In most cases (for the GENIA and GermEval 2014 datasets), the performance of the cased version of the model was better than that of the uncased version of the model. However, the uncased versions of the BERT language model performed better on the JNLPBA dataset.
- Some of the common postprocessing methods from the existing research works have been carried to improve the prediction of best-performing models. However, the performance declined, rather than improving. So, postprocessing is not recommended for the named-entity-recognition problem.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Wang, G.; Cao, J.; Cai, Y. A Multi-Agent Communication Based Model for Nested Named Entity Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2123–2136. [Google Scholar] [CrossRef]
- Alzubi, J.A.; Jain, R.; Singh, A.; Parwekar, P.; Gupta, M. COBERT: COVID-19 Question Answering System Using BERT. Arab. J. Sci. Eng. 2021, 1–11. [Google Scholar] [CrossRef]
- Chauhan, S.; Saxena, S.; Daniel, P. Fully unsupervised word translation from cross-lingual word embeddings especially for healthcare professionals. Int. J. Syst. Assur. Eng. Manag. 2021, 1–10. [Google Scholar] [CrossRef]
- Kumar, N.; Kumar, M.; Singh, M. Automated ontology generation from a plain text using statistical and NLP techniques. Int. J. Syst. Assur. Eng. Manag. 2016, 7, 282–293. [Google Scholar] [CrossRef]
- Kumar, R.B.; Suresh, P.; Raja, P.; Sivaperumal, S. Artificial intelligence powered diagnosis model for anaesthesia drug injection. Int. J. Syst. Assur. Eng. Manag. 2021, 1–9. [Google Scholar] [CrossRef]
- Parthasarathy, J.; Kalivaradhan, R.B. An effective content boosted collaborative filtering for movie recommendation systems using density based clustering with artificial flora optimization algorithm. Int. J. Syst. Assur. Eng. Manag. 2021, 1–10. [Google Scholar] [CrossRef]
- Dai, X. Recognizing Complex Entity Mentions: A Review and Future Directions. In Proceedings of the ACL 2018, Student Research Workshop, Melbourne, Australia, 15–20 July 2018; pp. 37–44. Available online: https://aclanthology.org/P18-3006.pdf (accessed on 15 March 2021).
- Alex, B.; Haddow, B.; Grover, C. Recognising Nested Named Entities in Biomedical Text. In Proceedings of the Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 29 June 2007; pp. 65–72. Available online: https://aclanthology.org/W07-1009.pdf (accessed on 15 March 2021).
- Chen, Y.; Zheng, Q.; Chen, P. A Boundary Assembling Method for Chinese Entity-Mention Recognition. IEEE Intell. Syst. 2015, 30, 50–58. [Google Scholar] [CrossRef]
- Plank, B.; Jensen, K.N.; Van Der Goot, R. DaN+: Danish Nested Named Entities and Lexical Normalization. In Proceedings of the 28th International Conference on Computational Linguistics, Bacelona, Spain, 8–13 December 2020; pp. 6649–6662. [Google Scholar]
- Mulyar, A.; Uzuner, O.; McInnes, B. MT-clinical BERT: Scaling clinical information extraction with multitask learning. J. Am. Med. Inform. Assoc. 2021, 28, 2108–2115. [Google Scholar] [CrossRef] [PubMed]
- Bang, Y.; Ishii, E.; Cahyawijaya, S.; Ji, Z.; Fung, P. Model Generalization on COVID-19 Fake News Detection. arXiv 2021, arXiv:2101.03841. [Google Scholar]
- Zheng, C.; Cai, Y.; Xu, J.; Leung, H.-F.; Xu, G. A Boundary-aware Neural Model for Nested Named Entity Recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 357–366. Available online: https://aclanthology.org/D19-1034.pdf (accessed on 11 March 2021).
- Straková, J.; Straka, M.; Hajic, J. Neural Architectures for Nested NER through Linearization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 5326–5331. Available online: http://aclanthology.lst.uni-saarland.de/P19-1527.pdf (accessed on 13 March 2021).
- Wang, J.; Shou, L.; Chen, K.; Chen, G. Pyramid: A Layered Model for Nested Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5918–5928. Available online: https://aclanthology.org/2020.acl-main.525.pdf (accessed on 11 March 2021).
- Shibuya, T.; Hovy, E. Nested Named Entity Recognition via Second-best Sequence Learning and Decoding. Trans. Assoc. Comput. Linguistics 2020, 8, 605–620. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Tong, H.; Zhu, Z. HIT: Nested Named Entity Recognition via Head-Tail Pair and Token Interaction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6027–6036. Available online: https://aclanthology.org/2020.emnlp-main.486.pdf (accessed on 12 March 2021).
- Chen, Y.; Wu, L.; Deng, L.; Qing, Y.; Huang, R.; Zheng, Q.; Chen, P. A Boundary Regression Model for Nested Named Entity Recognition. arXiv 2020, arXiv:2011.14330. [Google Scholar]
- Dadas, S.; Protasiewicz, J. A Bidirectional Iterative Algorithm for Nested Named Entity Recognition. IEEE Access 2020, 8, 135091–135102. [Google Scholar] [CrossRef]
- Tan, C.; Qiu, W.; Chen, M.; Wang, R.; Huang, F. Boundary Enhanced Neural Span Classification for Nested Named Entity Recognition. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9016–9023. [Google Scholar] [CrossRef]
- Finkel, J.R.; Manning, C.D. Nested Named Entity Recognition. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 141–150. Available online: https://aclanthology.org/D09-1015.pdf (accessed on 7 March 2021).
- Fu, Y.; Tan, C.; Chen, M.; Huang, S.; Huang, F. Nested Named Entity Recognition with Partially-Observed TreeCRFs. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Lu, W.; Roth, D. Joint Mention Extraction and Classification with Mention Hypergraphs. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 857–867. Available online: https://aclanthology.org/D15-1102.pdf (accessed on 14 March 2021).
- Wang, B.; Lu, W. Neural Segmental Hypergraphs for Overlapping Mention Recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Muis, A.O.; Lu, W. Labeling Gaps Between Words: Recognizing Overlapping Mentions with Mention Separators. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2018. [Google Scholar]
- Luo, Y.; Zhao, H. Bipartite Flat-Graph Network for Nested Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6408–6418. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA; 2019; Volume 1, pp. 4171–4186. Available online: https://aclanthology.org/N19-1423.pdf (accessed on 19 March 2021).
- Howard, J.; Ruder, S. Fine-tuned Language Models for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Kang, M.; Lee, K.; Lee, Y. Filtered BERT: Similarity Filter-Based Augmentation with Bidirectional Transfer Learning for Protected Health Information Prediction in Clinical Documents. Appl. Sci. 2021, 11, 3668. [Google Scholar] [CrossRef]
- Nainan, C. Scikit-Learn Wrapper to Finetune BERT. Available online: https://github.com/charles9n/bert-sklearn (accessed on 5 January 2021).
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Rush, A.; Wolf, T.; Debut, L.; Sanh, V.; Chaunmond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, October 2020; pp. 38–45. [Google Scholar]
- Team, T.H. Multi-Lingual Models. Available online: https://huggingface.co/transformers/multilingual.html (accessed on 25 August 2021).
- Beltagy, I.; Cohan, A.; Lo, K. SciBERT: Pretrained Contextualized Embeddings for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Wallach, H.M. Conditional Random Fields: An Introduction. 2004. Available online: http://www.inference.org.uk/hmw26/papers/crf_intro.pdf (accessed on 7 March 2021).
- Zhu, X. CS838-1 Advanced NLP: Conditional Random Fields. 2007. Available online: http://pages.cs.wisc.edu/~jerryzhu/cs838/CRF.pdf (accessed on 7 March 2021).
- Korobov, M. Sklearn-Crfsuite Docs. Available online: https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html (accessed on 11 August 2021).
- Tsuruoka, Y.; Tateishi, Y.; Kim, J.-D.; Ohta, T.; McNaught, J.; Ananiadou, S.; Tsujii, J. Developing a Robust Part-of-Speech Tagger for Biomedical Text. In Proceedings of the Advances in Informatics 10th Panhellenic Conference on Informatics, PCI 2005, Volos, Greece, 11–13 November 2005; Bozanis, P., Houstis, E.N., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 382–392. [Google Scholar]
- Tsuruoka, Y.; Tsujii, J. Bidirectional Inference with the Easiest-First Strategy for Tagging Sequence Data. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Vancouver, BC, Canada, 2005; pp. 467–474. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. Available online: https://nlp.stanford.edu/projects/glove/ (accessed on 5 January 2021).
- Inc, F. Word Vectors for 157 Languages. Available online: https://fasttext.cc/docs/en/crawl-vectors.html (accessed on 7 August 2021).
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Genthial, G. Intro to Tf.Estimator and Tf.Data. Available online: https://guillaumegenthial.github.io/introduction-tensorflow-estimator.html (accessed on 6 August 2021).
- Benikova, D.; Biemann, C.; Reznicek, M. NoSta-D Named Entity Annotation for German: Guidelines and Dataset. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 2524–2531. Available online: http://www.lrec-conf.org/proceedings/lrec2014/pdf/276_Paper.pdf (accessed on 4 March 2021).
- Benikova, D.; Biemann, C.; Kisselew, M.; Pado, S. GermEval 2014 Named Entity Recognition Shared Task: Companion Paper. 2014. Available online: https://www.inf.uni-hamburg.de/en/inst/ab/lt/publications/2014-benikovaetal-germeval2014.pdf (accessed on 10 March 2021).
- Kim, J.-D.; Ohta, T.; Tateisi, Y.; Tsujii, J. GENIA corpus—a semantically annotated corpus for bio-textmining. Bioinformatics 2003, 19, i180–i182. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Project, G. BioNLP/JNLPBA Shared Task. 2004. Available online: http://www.geniaproject.org/shared-tasks/bionlp-jnlpba-shared-task-2004 (accessed on 11 March 2021).
- Nguyen, T.-S.; Nguyen, L.-M. Nested Named Entity Recognition Using Multilayer Recurrent Neural Networks BT-Computational Linguistics. In Proceedings of the NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; Hasida, K., Pa, W.P., Eds.; Springer: Singapore, 2018; pp. 233–246. [Google Scholar]
- Tjong Kim Sang, E.F.; Buchholz, S. Introduction to the CoNLL-2000 Shared Task: Chunking. In Proceedings of the Fourth Conference on Computational Natural Language Learning and the Second Learning Language in Logic Workshop, Lisbon, Portugal, 13–14 September 2000; pp. 127–132. Available online: https://www.clips.uantwerpen.be/conll2000/pdf/12732tjo.pdf (accessed on 8 March 2021).
- Katiyar, A.; Cardie, C. Nested Named Entity Recognition Revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA; 2018; Volume 1 (Long Papers), pp. 861–871. Available online: https://aclanthology.org/N18-1079.pdf (accessed on 16 March 2021).
- Wang, B.; Lu, W.; Wang, Y.; Jin, H. A Neural Transition-based Model for Nested Mention Recognition. arXiv 2018, arXiv:1810.01808. [Google Scholar]
- Shao, Y.; Hardmeier, C.; Nivre, J. Multilingual Named Entity Recognition using Hybrid Neural Networks. In Proceedings of the Sixth Swedish Language Technology Conference (SLTC); 2016. Available online: https://uu.diva-portal.org/smash/get/diva2:1055627/FULLTEXT01.pdf (accessed on 13 March 2021).
- Pikuliak, M.; Simko, M.; Bielikova, M. Towards Combining Multitask and Multilingual Learning. In Proceedings of the SOFSEM 2019: Theory and Practice of Computer Science, Nový Smokovec, Slovakia, 27–30 January 2019; Catania, B., Královič, R., Nawrocki, J., Pighizzini, G., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 435–446. [Google Scholar]
- Marcińczuk, M.; Radom, J. A Single-run Recognition of Nested Named Entities with Transformers. Procedia Comput. Sci. 2021, 192, 291–297. [Google Scholar] [CrossRef]
- Labusch, K.; Neudecker, C.; Zellhöfer, D. BERT for Named Entity Recognition in Contemporary and Historic German. In Proceedings of the KONVENS, Erlangen, Germany, 9–11 October 2019; pp. 8–11. [Google Scholar]
- Sohrab, M.G.; Miwa, M. Deep exhaustive model for nested named entity recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2843–2849. [Google Scholar]
- Gridach, M. Character-level neural network for biomedical named entity recognition. J. Biomed. Inform. 2017, 70, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Kocaman, V.; Talby, D. Biomedical Named Entity Recognition at Scale. Intell. Comput. Theor. Appl. 2021, 635–646. [Google Scholar] [CrossRef]
- Yuan, Z.; Liu, Y.; Tan, C.; Huang, S.; Huang, F. Improving Biomedical Pretrained Language Models with Knowledge. In Proceedings of the 20th Workshop on Biomedical Language Processing, Online, 11 June 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Sentence | Barauszahlungen | Sind | Grundsätzlich | Nicht | Möglich | . |
|---|---|---|---|---|---|---|
| Label | O + O | O + O | O + O | O + O | O + O | O + O |
| Features | {‘word.lower()’: ‘barauszahlungen’, ‘word.len()’: 15, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘ngen’, ‘word[−3:]’: ‘gen’, ‘word[−2:]’: ‘en’, ‘word[:2]’: ‘Ba’, ‘word[:3]’: ‘Bar’, ‘word[:4]’: ‘Bara’, ‘word.type’: ‘Alpha’, ‘word.case()’: ‘Title’, ‘word.pattern()’: ‘ULLLLLLLLLLLLLL’, ‘stem’: ‘barauszahl’, ‘BOS’: True, ‘+1:word.lower()’: ‘sind’, ‘+1:word.len()’: 4, ‘+1:word.hasHyphen()’: False, ‘+1:word.type’: ‘Alpha’, ‘+1:word.case()’: ‘Lower’, ‘+1:word.pattern()’: ‘LLLL’, ‘+2:word.lower()’: ‘grundsätzlich’, ‘+2:word.len()’: 13, ‘+2:word.hasHyphen()’: False, ‘+2:word.type’: ‘Alpha’, ‘+2:word.case()’: ‘Lower’, ‘+2:word.pattern()’: ‘LLLLLLLLLLLLL’} | {‘word.lower()’: ‘sind’, ‘word.len()’: 4, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘sind’, ‘word[−3:]’: ‘ind’, ‘word[−2:]’: ‘nd’, ‘word[:2]’: ‘si’, ‘word[:3]’: ‘sin’, ‘word[:4]’: ‘sind’, ‘word.type’: ‘Alpha’, ‘word.case()’: ‘Lower’, ‘word.pattern()’: ‘LLLL’, ‘stem’: ‘sind’, ‘−1:word.lower()’: ‘barauszahlungen’, ‘−1:word.len()’: 15, ‘−1:word.hasHyphen()’: False, ‘−1:word.type’: ‘Alpha’, ‘−1:word.case()’: ‘Title’, ‘−1:word.pattern()’: ‘ULLLLLLLLLLLLLL’, ‘+1:word.lower()’: ‘grundsätzlich’, ‘+1:word.len()’: 13, ‘+1:word.hasHyphen()’: False, ‘+1:word.type’: ‘Alpha’, ‘+1:word.case()’: ‘Lower’, ‘+1:word.pattern()’: ‘LLLLLLLLLLLLL’, ‘+2:word.lower()’: ‘nicht’, ‘+2:word.len()’: 5, ‘+2:word.hasHyphen()’: False, ‘+2:word.type’: ‘Alpha’, ‘+2:word.case()’: ‘Lower’, ‘+2:word.pattern()’: ‘LLLLL’} | {‘word.lower()’: ‘grundsätzlich’, ‘word.len()’: 13, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘lich’, ‘word[−3:]’: ‘ich’, ‘word[−2:]’: ‘ch’, ‘word[:2]’: ‘gr’, ‘word[:3]’: ‘gru’, ‘word[:4]’: ‘grun’, ‘word.type’: ‘Alpha’, ‘word.case()’: ‘Lower’, ‘word.pattern()’: ‘LLLLLLLLLLLLL’, ‘stem’: ‘grundsatz’, ‘−1:word.lower()’: ‘sind’, ‘−1:word.len()’: 4, ‘−1:word.hasHyphen()’: False, ‘−1:word.type’: ‘Alpha’, ‘−1:word.case()’: ‘Lower’, ‘−1:word.pattern()’: ‘LLLL’, ‘−2:word.lower()’: ‘barauszahlungen’, ‘−2:word.len()’: 15, ‘−2:word.hasHyphen()’: False, ‘−2:word.type’: ‘Alpha’, ‘−2:word.case()’: ‘Title’, ‘−2:word.pattern()’: ‘ULLLLLLLLLLLLLL’, ‘+1:word.lower()’: ‘nicht’, ‘+1:word.len()’: 5, ‘+1:word.hasHyphen()’: False, ‘+1:word.type’: ‘Alpha’, ‘+1:word.case()’: ‘Lower’, ‘+1:word.pattern()’: ‘LLLLL’, ‘+2:word.lower()’: ‘möglich’, ‘+2:word.len()’: 7, ‘+2:word.hasHyphen()’: False, ‘+2:word.type’: ‘Alpha’, ‘+2:word.case()’: ‘Lower’, ‘+2:word.pattern()’: ‘LLLLLLL’} | {‘word.lower()’: ‘nicht’, ‘word.len()’: 5, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘icht’, ‘word[−3:]’: ‘cht’, ‘word[−2:]’: ‘ht’, ‘word[:2]’: ‘ni’, ‘word[:3]’: ‘nic’, ‘word[:4]’: ‘nich’, ‘word.type’: ‘Alpha’, ‘word.case()’: ‘Lower’, ‘word.pattern()’: ‘LLLLL’, ‘stem’: ‘nicht’, ‘−1:word.lower()’: ‘grundsätzlich’, ‘−1:word.len()’: 13, ‘−1:word.hasHyphen()’: False, ‘−1:word.type’: ‘Alpha’, ‘−1:word.case()’: ‘Lower’, ‘−1:word.pattern()’: ‘LLLLLLLLLLLLL’, ‘−2:word.lower()’: ‘sind’, ‘−2:word.len()’: 4, ‘−2:word.hasHyphen()’: False, ‘−2:word.type’: ‘Alpha’, ‘−2:word.case()’: ‘Lower’, ‘−2:word.pattern()’: ‘LLLL’, ‘+1:word.lower()’: ‘möglich’, ‘+1:word.len()’: 7, ‘+1:word.hasHyphen()’: False, ‘+1:word.type’: ‘Alpha’, ‘+1:word.case()’: ‘Lower’, ‘+1:word.pattern()’: ‘LLLLLLL’, ‘+2:word.lower()’: ‘.’, ‘+2:word.len()’: 1, ‘+2:word.hasHyphen()’: False, ‘+2:word.type’: ‘None’, ‘+2:word.case()’: ‘None’, ‘+2:word.pattern()’: ‘.’} | {‘word.lower()’: ‘möglich’, ‘word.len()’: 7, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘lich’, ‘word[−3:]’: ‘ich’, ‘word[−2:]’: ‘ch’, ‘word[:2]’: ‘mö’, ‘word[:3]’: ‘mög’, ‘word[:4]’: ‘mögl’, ‘word.type’: ‘Alpha’, ‘word.case()’: ‘Lower’, ‘word.pattern()’: ‘LLLLLLL’, ‘stem’: ‘moglich’, ‘−1:word.lower()’: ‘nicht’, ‘−1:word.len()’: 5, ‘−1:word.hasHyphen()’: False, ‘−1:word.type’: ‘Alpha’, ‘−1:word.case()’: ‘Lower’, ‘−1:word.pattern()’: ‘LLLLL’, ‘−2:word.lower()’: ‘grundsätzlich’, ‘−2:word.len()’: 13, ‘−2:word.hasHyphen()’: False, ‘−2:word.type’: ‘Alpha’, ‘−2:word.case()’: ‘Lower’, ‘−2:word.pattern()’: ‘LLLLLLLLLLLLL’, ‘+1:word.lower()’: ‘.’, ‘+1:word.len()’: 1, ‘+1:word.hasHyphen()’: False, ‘+1:word.type’: ‘None’, ‘+1:word.case()’: ‘None’, ‘+1:word.pattern()’: ‘.’} | {‘word.lower()’: ‘.’, ‘word.len()’: 1, ‘word.hasHyphen()’: False, ‘word[−4:]’: ‘.’, ‘word[−3:]’: ‘.’, ‘word[−2:]’: ‘.’, ‘word[:2]’: ‘.’, ‘word[:3]’: ‘.’, ‘word[:4]’: ‘.’, ‘word.type’: ‘None’, ‘word.case()’: ‘None’, ‘word.pattern()’: ‘.’, ‘stem’: ‘.’, ‘EOS’: True, ‘−1:word.lower()’: ‘möglich’, ‘−1:word.len()’: 7, ‘−1:word.hasHyphen()’: False, ‘−1:word.type’: ‘Alpha’, ‘−1:word.case()’: ‘Lower’, ‘−1:word.pattern()’: ‘LLLLLLL’, ‘−2:word.lower()’: ‘nicht’, ‘−2:word.len()’: 5, ‘−2:word.hasHyphen()’: False, ‘−2:word.type’: ‘Alpha’, ‘−2:word.case()’: ‘Lower’, ‘−2:word.pattern()’: ‘LLLLL’} |
| Sentence | Label L1 | Label L2 | Joint Label |
|---|---|---|---|
| Ab | O | O | O + O |
| 16 | O | O | O + O |
| Uhr | O | O | O + O |
| sind | O | O | O + O |
| dann | O | O | O + O |
| die | O | O | O + O |
| Verfolger | O | O | O + O |
| Aston | B-ORG | B-LOC | B-ORG + B-LOC |
| Villa | I-ORG | O | I-ORG + O |
| und | O | O | O + O |
| Tottenham | B-ORG | B-LOC | B-ORG + B-LOC |
| Hotspur | I-ORG | O | I-ORG + O |
| gefordert | O | O | O + O |
| . | O | O | O + O |
| Sentence | Label L1 | Label L2 | Label L3 | Label L4 | Joint Label |
|---|---|---|---|---|---|
| In | O | O | O | O | O + O + O + O |
| order | O | O | O | O | O + O + O + O |
| to | O | O | O | O | O + O + O + O |
| study | O | O | O | O | O + O + O + O |
| CD14 | B-protein | B-DNA | O | O | B-protein + B-DNA + O+O |
| gene | O | I-DNA | O | O | O + I-DNA + O+O |
| regulation | O | O | O | O | O + O + O + O |
| , | O | O | O | O | O + O + O + O |
| the | O | O | O | O | O + O + O + O |
| human | O | B-protein | B-DNA | O | O + B-protein + B-DNA + O |
| CD14 | B-protein | I-protein | I-DNA | O | B-protein + I-protein + I-DNA + O |
| gene | O | O | I-DNA | O | O + O + I-DNA + O |
| was | O | O | O | O | O + O + O + O |
| cloned | O | O | O | O | O + O + O + O |
| from | O | O | O | O | O + O + O + O |
| a | O | O | O | O | O + O + O + O |
| partial | O | O | O | O | O + O + O + O |
| EcoRI | B-protein | B-DNA | O | O | B-protein + B-DNA + O+O |
| digested | O | I-DNA | O | O | O + I-DNA + O+O |
| chromosome | O | I-DNA | O | O | O + I-DNA + O+O |
| 5 | O | I-DNA | O | O | O + I-DNA + O+O |
| library | O | I-DNA | O | O | O + I-DNA + O+O |
| O | O | O | O | O + O + O + O |
| Dataset | Training Dataset | Testing Dataset | No. of Entity Types (Except Others) | ||||
|---|---|---|---|---|---|---|---|
| No. of Abstracts | No. Sent | No. of Tokens | No. of Abstracts | No. Sent | No. of Tokens | ||
| GENIA | 1800 (approx.) | 16,692 | 503,857 | 200 (approx.) | 1854 | 57,024 | 5 |
| GermEval 2014 | - | 26,202 | 494,506 | - | 5100 | 96,499 | 12 |
| JNLPBA | 2000 | 20,546 | 494,551 | 404 | 4260 | 101,443 | 5 |
| S. No. | Model Details | Dataset Details | ||||
|---|---|---|---|---|---|---|
| Nested Dataset | Non-Nested Dataset | |||||
| Model Category | Model Name | F1 Score (GENIA Test Dataset) | F1 Score (GermEval 2014 Test Dataset) | F1 Score (JNLPBA Test Dataset) | ||
| A. | 1. | Google AI’s pretrained BERT models | bert-base-uncased | 72.91 0.09 | 79.08 0.24 | 80.13 ± 0.04 |
| 2. | bert-large-uncased | 73.11 0.11 | 80.76 0.24 | 79.98 0.14 | ||
| 3. | bert-base-cased | 73.19 0.08 | 79.76 0.25 | 79.51 0.24 | ||
| 4. | bert-large-cased | 73.38 ± 0.09 | 81.37 0.24 | 80.11 0.16 | ||
| 5. | bert-base-multilingual-uncased | 72.49 0.24 | 84.72 0.17 | 79.42 0.11 | ||
| 6. | bert-base-multilingual-cased | 72.44 0.24 | 85.29 ± 0.23 | 79.65 0.12 | ||
| B. | 1. | SciBERT pretrained BERT models | scibert-scivocab-uncased | 74.07 ± 0.18 | 76.35 0.14 | 80.68 ± 0.22 |
| 2. | scibert-scivocab-cased | 73.56 0.13 | 77.38 0.13 | 80.60 0.07 | ||
| 3. | scibert-basevocab-uncased | 73.34 0.05 | 78.66 0.11 | 80.33 0.18 | ||
| 4. | scibert-basevocab-cased | 73.57 0.21 | 79.05 ± 0.23 | 79.82 0.18 | ||
| C. | 1. | BioBERT pretrained BERT models | biobert-base-cased | 74.38 ± 0.14 | 75.67 0.26 | 80.43 0.14 |
| 2. | biobert-v1.1-pubmed-base-cased | 74.29 0.07 | 75.76 0.32 | 80.42 0.14 | ||
| 3. | biobert-v1.0-pubmed-base-cased | 73.63 0.07 | 76.32 0.36 | 80.25 0.15 | ||
| 4. | biobert-v1.0-pubmed-pmc-base-cased | 73.79 0.21 | 76.62 0.11 | 80.48 ± 0.04 | ||
| 5. | biobert-v1.0-pmc-base-cased | 73.84 0.18 | 77.02 ± 0.25 | 80.44 0.24 | ||
| D. | CRF model | 65.15 0.21 | 68.93 0.23 | 74.23 0.38 | ||
| E. | Bi-LSTM-CRF | 70.19 0.56 | 76.14 0.31 | 77.56 0.36 | ||
| Source | Used Approach | F1-Score |
|---|---|---|
| [21] | Parser-based | 70.33 |
| [23] | Mention-hypergraph-based | 68.70 |
| [25] | Multigraph-based | 70.80 |
| [51] | Neural-network-based (LSTM, hypergraph features) | 73.80 |
| [52] | Neural-network-based (LSTM-CRF, seq2seq, contextual embeddings) | 73.90 |
| [13] | Neural-network-based (boundary aware Bi-LSTM) | 73.90 |
| This Paper | Transfer-learning-based (best BERT model) | 74.38 |
| [16] | Neural-network-based (Bi-LSTM-CRF, contextual embeddings) | 77.36 |
| [14] | Neural-network-based (seq2seq, contextual embeddings) | 78.31 |
| Source | Used Approach | F1-Score |
|---|---|---|
| [13] | Neural-network-based (boundary aware Bi-LSTM) | 71.7 |
| [53] | Neural-network-based (feed forward, Bi-LSTM, Win-bi-LSTM) | 76.12 |
| [54] | Neural-network-based (Bi-LSTM-CRF) | 75.3 |
| [17] | Neural-network-based (head–tail pair, token interaction tagger) | 72.6 |
| This Paper | Transfer-learning-based (best BERT model) | 85.29 |
| [55] | Neural-network-based (PolDeepNer2) | 87.69 |
| [56] | Transfer-learning-based (unsupervised pretraining, pretrained BERT) | 88.6 |
| Source | Used Approach | F1-Score |
|---|---|---|
| [57] | Neural-network-based (Bi-LSTM, embeddings) | 78.4 |
| [17] | Neural-network-based (head–tail pair, token interaction tagger) | 74.9 |
| [58] | Neural-network-based (Bi-LSTM, embeddings) | 75.87 |
| This Paper | Transfer-learning-based (best BERT model) | 80.48 |
| [59] | Neural-network-based (BLSTM-CNN-Char and Spark NLP) | 81.29 |
| [60] | Transformer-based | 82.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agrawal, A.; Tripathi, S.; Vardhan, M.; Sihag, V.; Choudhary, G.; Dragoni, N. BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling. Appl. Sci. 2022, 12, 976. https://doi.org/10.3390/app12030976
Agrawal A, Tripathi S, Vardhan M, Sihag V, Choudhary G, Dragoni N. BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling. Applied Sciences. 2022; 12(3):976. https://doi.org/10.3390/app12030976
Chicago/Turabian StyleAgrawal, Ankit, Sarsij Tripathi, Manu Vardhan, Vikas Sihag, Gaurav Choudhary, and Nicola Dragoni. 2022. "BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling" Applied Sciences 12, no. 3: 976. https://doi.org/10.3390/app12030976
APA StyleAgrawal, A., Tripathi, S., Vardhan, M., Sihag, V., Choudhary, G., & Dragoni, N. (2022). BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling. Applied Sciences, 12(3), 976. https://doi.org/10.3390/app12030976