1. Introduction
Parkinson’s Disease (PD) is the second most prevalent late-onset neurodegenerative disease [
1], in which progressive symptoms of tremor, stiffness, slowed movement and imbalance affect functional independence and quality of life for millions of people around the world. The average time to diagnosis with 90% accuracy is 2.9 years [
2], usually after the onset of motor deficits, though the condition has a much longer prodromal phase lasting up to decades. In some cases, this delay in final diagnosis leads to sub-optimal therapies for those who suffer from it. Moreover, when new neuroprotective therapies are ready [
3], such prolonged delays in treatment lead to irreversible striatopallidal injury damage that could have been prevented.
In the last decade, a number of studies have proposed using recordings of sustained phonation as a tool to automatically detect PD using models obtained by means of signal processing and machine learning techniques [
4]. The use of voice as a biomarker is motivated by evidence of the impact of PD on voice and speech [
5], even in early stages [
6,
7,
8]. As a voice signal, the advantages of sustained phonations is that they provide information about tremor and rigidity in the respiratory and glottal structures and the subjects are not required to read or memorize a sentence. Furthermore, as the detection models based on phonatory features do not rely on articulatory-specific information, these can be sometimes considered multilingual or are easily adapted to be employed in populations with different mother tongues. However, sustained phonation signals are less complex than those from connected speech, which require the precise coordination of multiple articulators while also conveying phonatory information. This makes connected speech more suitable in the analysis of kinetic aspects.
Although the interest in the development of diagnostic tools employing Persons with Parkinson’s Disease (PwPD)’ phonation is increasing [
4], there is not a clear consensus about the validity of the methodologies proposed in the literature, as different data sets and validation procedures vary between studies. Certain experiments have suggested that machine learning and signal processing can automatically distinguish between PwPD and controls with significant confidence. However, some of these papers contain methodological issues that are known and understood in the machine learning community. For example, employing separate corpora for each class [
9,
10] may train classifiers to detect PD via meta-characteristics such as environmental noise, the sampling frequency, or the recording technology of each corpus.
Another common problem identified in the literature is that some studies employ data sets in which the average age difference of speakers with and without PD exceeds 5 years [
10,
11,
12,
13,
14,
15]. Generally, these studies report high recall in their trials of automatic PD detection. They have not considered that since age influences speech; their classifiers may be detecting characteristics related to age difference between groups in lieu of PD patterns. This could lead to overoptimistic results as the influence of age in speech has been shown to help differentiate between classes [
16]. However, details of the examined class demographics and speaker statistics (e.g., age, sex, and stage of the disease, at the very least), are not always regularly reported, potentially impacting conclusions.
Some articles [
17] claim that using sustained vowels leads to better results than other speaking tasks in detecting differences between speakers with and without PD. Using sustained vowels, word utterances, and short sentence readings, this study measures amplitude/frequency perturbation qualities, such as jitter, shimmer, Harmonic to Noise Ratio (HNR), Noise to Harmonics Ratio (NHR) and other pitch statistics. However, one may consider it unorthodox to use these coefficients on non-sustained vowels because quantifying the quality of the phonation is their principal use [
18]. Connected speech includes prosody and articulation, which both cause major modulations in amplitude and frequency. As such, using amplitude and frequency perturbation measures such as jitter and shimmer on voiceless consonants, for instance, might lead to incorrect conclusions. There is no inherent meaning of these features when measured in voiceless consonants.
When considering sustained vowels, some corpora are distributed with the onset and offset of the phonation, while others have trimmed each recording to contain only the middle, most stable, segment. This is usually more adequate when employing acoustic analysis or features proposed to be used in the stable part of the phonation, such as complexity or frequency and amplitude perturbation features [
18]. Therefore, some studies take corpora distributed with the full recording and shorten them to as short as one second [
14,
19,
20]. Nevertheless, the onset and offset contain articulatory information and might add extra differentiation between classes, especially when employing certain features such as Mel-Frequency Cepstral Coefficients (MFCC) to characterize them. However, to our knowledge, there are no studies analyzing the influence of these segments on accuracy.
Moreover, many studies employ large feature vectors obtained with feature extraction libraries to characterize the phonation recordings without reasoning or selecting the most appropriate features for PD detection. In this respect, a recent letter [
21] to the editors of a publication reveals that the use of high-dimensional feature vectors with small data sets (100 times smaller than the feature vector dimension, in that case) leads to overoptimistic classification accuracy and non-reproducible results. The reasoning behind this idea is that the larger the feature vector, the more chances to find one type of feature that might randomly correlate with the classes to be classified without any scientific grounding.
The validation strategies found in studies employing phonatory aspects to detect PD are also diverse. The most common is cross-validation, in which the employed corpus is divided into multiple folds that are used to sequentially train and test several models, yielding a weighted average accuracy from the individual models. It is uncommon to find studies which employ different corpora in model training and testing (cross-corpora validation) [
22]. In some cases, the authors do not use cross-validation, and divide the corpus into training and testing subsets randomly [
14,
22,
23,
24,
25,
26]. This increases the uncertainty of the results when using small corpora (usually no more than 3 h of recordings), as the testing partition is not large enough to be considered representative.
Moreover, some studies where there are more than one recording per participant ensure that recordings from a speaker used to train a model are not considered to test or validate the same model (subject-wise split) [
19,
25,
27], whereas other studies randomly select the recordings employed in the training and testing processes or intentionally use recordings from the same speakers in training and testing subsets (record-wise split) [
11,
14]. The latter studies do not consider that when both training and testing processes contain speaker identity information encoded in sustained vowels, their classifiers may be detecting characteristics of specific speakers in addition to PD patterns. This could produce overoptimistic results, as coefficients like MFCCs and Perceptual Linear Prediction (PLP), employed as the input of the classifier, have notably succeeded in speaker recognition tasks [
28,
29] and could lead to classifier bias. Motivated by this discrepancy, several studies [
13,
16,
30] have reported a marked difference in accuracy between randomly populating folds in cross-validation with (1) single recordings at a time (record-wise); and (2) all recordings from a single participant (subject-wise), with record-wise experiments leading to artificially higher accuracy. This observation also arises in other speech-based medical evaluation models, such as one which estimates depression level from audio recordings [
31].
Lastly, each study tends to employ their own corpus, due to the scarcity of publicly available data sets to compare results across different methodologies. As a result of the differences in data collection, populations, and methodologies, the literature provides a variety of results that sometimes lead to contradictory or controversial conclusions regarding which acoustic features better characterize the presence of PD. This methodological variability and the inclusion of methodological issues makes it hard to distinguish between valuable and minor/misleading contributions. For instance, it is not possible to know if the high detection accuracy reported in some studies is caused by the acoustic patterns of PD in the voice of the participants or because the average age difference between PwPD and controls was higher than ten years. To our knowledge, no article has analyzed and compared in detail the influence of the different methodological issues in the results of the automatic detection of PD employing different corpora in a single work.
With these premises, the purposes of this study are:
To analyze the influence of certain factors, such as age difference between classes, speaker identity in training/testing folds, or feature vector length that might bias results;
To study how different validation and classification methodologies influence the PD detection results;
To study the differences between corpora that might lead to differences in results and conclusions.
A graphical summary of the purposes of this work is included in
Figure 1.
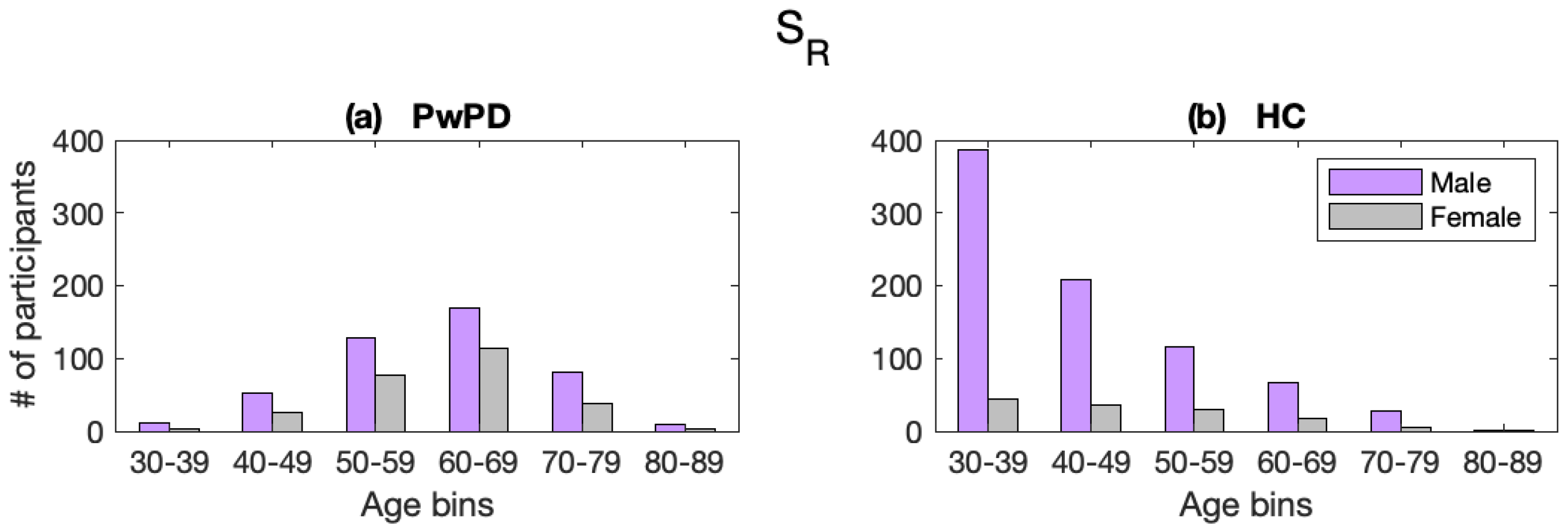
To achieve these objectives, we performed PD detection employing sustained vowels as acoustic material obtained from three different corpora, of which two are publicly available. We calculated the most commonly used features in these types of studies found in literature [
4], also employing publicly available feature extraction and machine learning code for reproducibility. We repeated the experiments several times, changing the methodology in order to evaluate how the identified methodological issues can influence the results. We started from a baseline experiment and compared its results with each methodological variation; i.e., including the same speaker in training and testing, using different average age differences between speakers with and without PD, or using different parts of the acoustic signal, among other experiments.
The goal of this study is not to identify or point out which studies have methodological issues. Instead, we aim to provide a comprehensive analysis of how the outlined issues may be affecting results in order to avoid repeating them in future work. Some seminal studies can be of capital importance because these paved the path for the automatic detection of PD through speech and yet have methodological issues that need to be addressed for iterative scientific advancement.
This document is organized as follows:
Section 2 describes the three corpora used in this study.
Section 3 provides an overview of our experimental processes. This includes how we calculate our coefficients and employ dimensionality reduction (
Section 3.2), construct our classification architecture (
Section 3.3), and vary our methodological strategy between several different scenarios (
Section 3.4).
Section 4 contains tables and graphics which demonstrate the impact of each methodological difference on classification accuracy. Finally,
Section 5 includes the conclusions of the study.
4. Results & Discussion
In this Section, we include and discuss the results obtained for each of the proposed scenarios, i.e., baseline, influence of speaker’s identity, influence of age difference, influence of feature randomness, influence of onset/offset, and cross-corpora experiments. The cross-validation results were obtained by pooling all the scores from the testing folds and calculating a single global accuracy. Most of these results are reported in terms of classification accuracy (%) for the sake of simplicity, given that we report results per vowel, corpus, and feature extraction library in multiple scenarios.
4.1. Baseline Results
Table 12 includes the classification accuracy results of the baseline of the study. In this scenario, all the analyzed data sets are class-balanced and the PwPD and HC classes are age- and gender-matched. In these, and in most of the trials of this study, the ItalianPVS corpus provided the best results overall, with accuracy near
when using RFC classifiers. This corresponds to more perceptible dysphonia in PwPD, according to
Figure 5. In each experiment, RFCs tend to have much higher accuracy than SVMs. In RFC trials on the Neurovoz corpus, the vowels /iː/ and /uː/ tend to perform the best. In that corpus, the vowel /aː/ frequently provides worse results, and it never provides the highest accuracy when compared to the rest of the trials. One possible reason could be that the production of the open-back vowel /aː/ requires a more relaxed position of tongue than other tighter, extreme vowels such as the back-close /uː/ and the front-close /iː/ [
63]. However, another possible reason when analyzing results of the vowel /uː/ could be that this vowel contains fewer recordings, as indicated in
Table 1. As discussed in
Section 3.4.4, a smaller number of observations might lead to higher (overoptimistic) accuracy when employing very large feature vectors. In ItalianPVS trials, the RFC experiments also tend to provide the highest detection accuracy, but the differences between RFC classifiers are lower, especially when using the AVCA-based feature extraction algorithms.
The coefficients obtained using the AVCA toolbox provide similar results to those calculated using the DARTH-VAT toolbox when using RFC classifiers. However, AVCA-related trials tend to provide higher accuracy than those from DARTH-VAT when employing SVM classification schemes. For instance, in the ItalianPVS experiments, SVM accuracy ranges from 77.8–93.9% using AVCA versus 49.5–53.5% using DARTH-VAT. The differences in the other corpora are much subtler but still present nonetheless. These differences may be attributed to the PLP and Modulation Spectrum (MS) features from AVCA, which are not present in DARTH-VAT.
In most experiments using the mPower corpus, vowel /aː/ classification accuracy is lower than in the other corpora by as much as 16.4% (absolute). In order to ensure that the mPower subset is representative, we obtained six parallel subsets by randomly selecting speakers from the reference subset (
) and obtaining the same age and gender statistics indicated in
Table 6.
Table 12 includes the mean and variance of accuracy from repeating the grid search with each of the six subsets. These results are supported by the GRBAS results of this corpus as well: there is a notably smaller difference of perceived dysphonia between those with and without PD. Although the perceptual evaluation reveals a less distinguishable dysphonia, other factors could be influencing these results, such as the differences in microphones, background noise, and acoustic conditions in the mPower corpus collection method, as suggested in previous studies [
64,
65].
Using dimensionality reduction techniques increased the SVM classifier accuracy in most experiments. On the other hand, feature selection using SelectKBest on RFC classifiers led to ambivalent results, while PCA lowered the accuracy in every experiment. In fact, given that the decision trees included in RFC classifiers are based on an algorithm that finds the features that better differentiate between classes, as in many feature selection algorithms, using dimensionality reduction techniques might be unuseful or redundant when employing these types of ensemble algorithms.
4.2. Influence of Speaker Identity on Classification Accuracy
Table 13 includes the results from trials where we used record-wise fold creation rather than subject-wise, which was used in the baseline.
Figure 7 includes the comparison between the maximum accuracy obtained when using subject-wise versus record-wise folds for the two feature extraction libraries employed in this study. As described in
Section 3.4.2, recordings from the same speaker belong to both the training and testing data sets.
Compared to the baseline results shown in
Table 12 (in which the same speakers’ recordings belong to only one of the training/testing folds), the accuracy obtained in this new scenario is higher in most cases. Given the potential impact of record-wise fold creation discussed in
Section 3.4.2, the classifier could have been biased to detect unique individual information, represented mainly by MFCC and PLP coefficients, rather than actual biomarkers or PD patterns. Detection accuracy in AVCA-related trials was generally higher than that from DARTH-VAT-related trials in the record-wise fold experiments. The reason could be that the coefficients obtained via the AVCA library contain more speaker information as there are two perceptual coefficient families: MFCC and PLP, whereas the DARTH-VAT only calculates MFCCs.
Trials using the Neurovoz corpus increased the most in accuracy: only 2 out of 30 RF trials and 7 out of 30 SVC trials saw a decrease in accuracy from the baseline, though most differences are by no more than 3 absolute percentage points. The fact that both RFC and SVM classifiers perform better suggests that speaker information has an impact on classification and leads to overoptimistic results in experiments in which there are recordings from the same speakers in training and testing. In some instances, dimensionality reduction trials saw little to no increase in accuracy with respect to the baseline scenario. This suggests that the loss of information might include some pertaining to speaker-specific features.
On the other hand, results using ItalianPVS do not vary as significantly between these two scenarios. First of all, we can simply note that the classification accuracy reaches nearly
without the addition of speaker-specific information in the training data. Furthermore, we analyzed which features are most important for classifying each corpus (described later on
Section 4.8). Briefly, classifiers trained with Neurovoz and mPower both depend heavily on perceptual coefficients such as MFCCs and PLPs, while models trained with ItalianPVS rely more on features related to voice quality, which contain less speaker-specific information. This could be explained by the more evident dysphonia of PwPD in ItalianPVS than those in mPower and Neurovoz (see
Section 2.4).
4.3. Influence of Age Difference between Classes on Classification Accuracy
In this scenario, we used different age distributions between PwPD and HC speakers in order to evaluate how age differences might influence detection accuracy. For these experiments, we only considered mPower, as it is the corpus with the most participants as well as a wider age range. To this end, we trained and tested new PD detection models as in the subject-wise baseline experiments.
Figure 8 displays the cross-validation maximum accuracy per subset for trials employing the DARTH-VAT and AVCA toolboxes to extract features. These results were obtained employing the same RFC grid search used in the baseline. On the range of mean age difference between the PwPD and HC classes that we examined, there is a consistent positive correlation between these gaps and the accuracy achieved. We further explored the potential conflation of age and PD detection using subset
S (described in
Table 4). Subset
S has a mean age difference of 26.6 years, though the distribution is not Gaussian. After running the same RFC grid search on subset
S, we found that accuracy increases even more as the mean age difference increases. Consequently, the results suggest that a difference in the mean age between speakers with and without PD could be leading to overoptimistic results, as age-related effects on the voice of the speakers can bias the classifier.
4.4. Influence of Feature Randomness on Classification Accuracy
As described in
Section 3.4.4, we repeated the RFC experiments with the same architecture used in the baseline tests, except we replaced each coefficient with a random number between zero and one with a feature vector dimensionality as those calculated using DARTH-VAT. The results of these trials are listed in
Table 14 as well as depicted graphically in
Figure 9. Results suggest that, even when the random coefficients do not include any information related to the speakers, it is possible to obtain accuracies over 72% in ItalianPVS, and over 67% in Neurovoz with the proposed baseline experiments. This effect is less clear in mPower. The reason is that ItalianPVS contains many fewer audio recordings than mPower, and this number is much smaller than the feature vector dimensionality. The larger the difference between the number of files and feature vector dimension, the higher chances to find a feature that randomly correlates to the class labels.
4.5. Mitigation of Random Over-Fitting Using Development Data
A possible way to avoid selecting configurations that randomly over-fit training and testing data is to use development folds. As such, we performed cross-validation with development fold to choose the best model, and tested it using a testing fold. The results from these experiments are listed in
Table 15 and depicted graphically in
Figure 10. In this case, the experiments with random features are repeated six times with six different new sets of random coefficients, and average accuracy is reported. In each trial, the testing data performs worse than the development. This is to be expected because development accuracy is the greatest observed over the entire grid search, while testing accuracy could be considered as a more balanced measure of classifier performance in new data not seen in training or validation. However, when using this technique with small corpora like Neurovoz or ItalianPVS, including a development fold also leads to less training data (one fold less), which is not desirable. Notably, the trials using random coefficients with corpus sizes of Neurovoz and ItalianPVS perform the most differently between the development and testing folds. This can be explained by the absolute lack of meaning of random features other than coincidental trends that correlate with condition label vectors.
When comparing the results from the baseline (
Table 12) with those from the tests using development folds (
Table 15), the classification accuracy using the development fold nearly matches the baseline’s reported “best accuracy”. On the other hand, following up with the testing fold produces a much lower classification accuracy on average.
Table 16 contextualizes these differences: the mean difference between development and baseline accuracy (in corpora with five vowels) does not exceed 1.00% across all vowels. Taking the average magnitude of the difference garners a similar result, not exceeding 1.50%. However, there is not a single case where testing accuracy exceeds the baseline or development accuracy. In fact, these differences are significantly more pronounced than those between development and baseline accuracy, reaching as high of a decrease as 8.46%. These calculations, displayed in
Table 16, support the hypothesis that using a single fold for model validation and evaluation could lead to overoptimistic results, and that using separating folds for each stage is an important methodological consideration.
4.6. Influence of Onset and Offset of Vowels on Classification Results
To test whether or not the onset and offset of the vowel contains important classification information, we repeated the baseline experiments with unclipped and clipped versions of Neurovoz and ItalianPVS, respectively, and obtained the results included in
Figure 11. We found that in both corpora, removing the beginning and end of recordings mostly decreased accuracy in both AVCA-based and DARTH-based trials. In Neurovoz, accuracy was reduced much more using AVCA-based coefficients. Additionally, the total decrease in accuracy for clipped audios is larger for Neurovoz than ItalianPVS. The discrepancy between the Neurovoz DARTH-based and AVCA-based results may be explained by the hypothesis that the onset and offset contains relevant articulatory information. The AVCA toolkit calculates two separate perceptual coefficient families: MFCCs and PLPs; while the DARTH-VAT toolkit only calculates the former. Assuming that removing onset and offset also removes some relevant articulatory information, it makes sense that AVCA-based trials would see a larger decrease in accuracy than their DARTH-VAT counterparts. As for ItalianPVS, not much difference between the coefficient type results suggests that although articulatory information has a marked impact on the results, it may not have as much of an impact as other factors, such as dysphonia of participants’ voices as discussed in
Section 4.7.
4.7. Cross-Corpora Experiments
Since ItalianPVS has a lower sampling rate in its audios (16 kHz), we downsampled the Neurovoz audios to match this frequency.
Figure 12 shows the results of these experiments when the models trained with ItalianPVS and Neurovoz are tested with the other corpus. The model obtained with Neurovoz and evaluated with ItalianPVS led to higher accuracy, reaching up to 83.8% for the vowels iː and uː. These results are not observed when the model is trained with ItalianPVS and evaluated with Neurovoz, where the accuracy never goes beyond 55.9%. One possible factor influencing these results is that Neurovoz contains a larger amount of recordings per vowel than ItalianPVS (176 vs. 99), leading to a more robust model. The other reason, aligned with the results obtained in the baseline trials, is that the voices of PwPD of ItalianPVS are more clearly affected by the disease.In other words, the dysphonia of these PwPD is more evident and probably easier to detect with the models trained with Neurovoz.
4.8. Feature Analysis
In order to better understand the differences in the results between corpora, we analyzed the feature importance per vowel, corpora, and coefficient type using the hyperparameters of the best-performing classifiers from the baseline experiments. The feature importance values are calculated as the mean of accumulation of the impurity decrease at each decision tree trained in the random forest of the employed classification library [
57]. The higher the average decrease in impurity caused by a feature during the training process, the higher the importance. The rankings in
Table 17 depict the order of coefficients from most to least important in classification considering only the models trained in the baseline trials corresponding to the highest accuracy for each corpus. These were calculated using a system of votes: for each repeated experiment in each corpus, the coefficient importances were averaged between each fold. The top 12 most-voted features of all 3 corpora and both coefficient calculation toolboxes appear in
Table 17. Although this analysis does not point out a specific confounding factor, it provides support for some other conclusions obtained in this study.
For DARTH-VAT-based trials, the most significant features in the Neurovoz and mPower are the means and variances of MFCC coefficients and their derivatives. On the other hand, the most important features when using ItalianPVS are related to complexity, noise, and shimmer. In most of our experiments, ItalianPVS classifiers perform with the highest accuracy. An explanation of this may be that, as mentioned in
Section 2.4, the dysphonia of PwPD in ItalianPVS is perceptually more evident than those in mPower and Neurovoz (hence the importance of features which characterize voice quality).
For AVCA-based trials, nearly all of the top-ranked coefficients of Neurovoz are also spectral-cepstral, with some MS features. As such, AVCA-based classification accuracy improved more from speaker-wise to record-wise fold separation experiments compared to their DARTH-based counterparts. Again, ItalianPVS has different top features than the other two corpora. Nearly all of its top 12 coefficients are related to the complexity of the signal. This finding also explains why the accuracy of ItalianPVS classifiers only minimally changed between the baseline and record-wise trials. The mPower feature ranking is interesting because the top seven features are all related to the MS. In the mPower classifiers, AVCA coefficients performed slightly better than DARTH-VAT coefficients, which implies that in larger corpora, modulation spectrum characteristics may contain important information as to whether or not the speaker has PD.
Figure 13 includes the boxplots of the most important features for each data set in the vowel /aː/. It can be observed that the distributions of the most important features tend to overlap less between classes for ItalianPVS, in comparison to the other two corpora.
5. Conclusions
In this study, we have analyzed the influence of potential methodological issues that may lead to overoptimistic results in the automatic classification of PwPD and HC employing sustained vowels from three different corpora. We analyzed the effects of record-wise vs. subject-wise experiments, mean age difference between the two classes, cross-validation design, and feature vector length on classification accuracy. Additionally, we analyzed other factors such as vowel onset and offset removal, different feature extraction libraries, classification techniques, and performed cross-corpora trials in order to find answers to why the same techniques provide different results in different corpora. The purpose of this study is not to report a precise analysis of optimizing our classifiers to achieve the highest possible accuracy. Rather, the goal of this research is to empirically demonstrate whether each aforementioned methodological factor skews classifier accuracy.
In our baseline experiments, test speakers were restricted to only a single fold (subject-wise trials) and the age distributions were nearly identical. Between the three corpora, models trained with mPower participants perform the worst. One possible explanation may be that as shown in
Figure 5, the two classes from this corpus sound more qualitatively similar on the GRBAS scale than the others. However, models trained with ItalianPVS participants predict PD more accurately than models using Neurovoz despite the similar GRBAS differences between their classes. For this reason, we claim that GRBAS ratings are inconclusive benchmarks of a classifier performance in this study.
We examined the effect of speaker identity by splitting recordings from a single participant into separate folds (record-wise trials). This way, we guaranteed that theoretical speaker-specific information belonged to both training and testing data. The graphs in
Figure 7 illustrate our hypothesis that record-wise fold separation leads to higher accuracy than subject-wise fold separation. As such, we argue that studies employing record-wise methodologies might be reporting overoptimistic results. Further supporting this claim, record-wise RFCs using AVCA-derived coefficients, which contain two perceptual coefficient families (MFCCs and PLPs), perform better than those using DARTH-VAT-derived coefficients which contain only MFCCs.
To explore the impact of mean age difference between two classes, we used one mPower subset from the baseline and replaced participants in order to shift the age distributions. As the separation between participants with PD and HC’s mean age increased, classification accuracy consistently increased (
Figure 8). All experiments considered, we argue that studies with large mean age differences between the two classes could be reporting overoptimistic results.
We investigated the extent to which feature vector length influences classification accuracy. The smaller the number of observations compared to the feature vector length, the greater the chance that coefficients will randomly correlate with class labels. The results of these trials (
Table 14) suggest that smaller corpora like Neurovoz and ItalianPVS will inherently perform better than larger ones like mPower when using large feature vector size (several times the number of observations). A way to eliminate the influence of the feature vector length in the results is to employ development folds at the expense of reducing the amount of training data.
In some corpora, sustained phonation recordings have had their onset and offset removed. Our results (
Figure 11) suggest that models trained with samples containing onset and offset are usually more accurate than those without. Based on this observation, we claim that employing onset and offset from sustained vowel phonations in combination with certain features (such as MFCC) could provide higher accuracy.
We observed the generalization properties of our models using Neurovoz and ItalianPVS. Our results suggest that larger corpora provide better detection models. In any case, the differences in results across corpora may be caused by the different speech and voice phenotypes present in each corpus, as there might be different speech subgroups (prosodic, phonatory-prosodic, and articulatory-prosodic) associated with PD [
66].
As is the nature of an academic review, this study cannot encompass every single aspect of methodological design which could possibly impact the results. For example, the following limitations exist:
Our analysis is limited to two classification techniques (RFC and SVM) which commonly appear in other works. We do not evaluate the performance of other classifiers found in literature, such as DNN [
14,
19,
25,
26,
27,
36,
37,
58], Gaussian Mixture Model (GMM) [
39,
67,
68], logistic regression [
13,
22,
37], and ensemble classifiers other than RFC [
12,
13,
36,
59];
We do not have access to UPDRS/H & Y assessments of mPower and ItalianPVS participants, preventing comparison of severity variance between each corpus;
The mPower corpus only contains sustained vowel recordings. This impacts the reliability and reproducibility of the GRBAS assessment described in
Section 2.4;
Other unexplored factors that could also impact classification accuracy include sex, recording environment, microphone specifications, recording length, type of phonation, smoking/surgical history, time between medication and recording, coexisting neurological disorders, and stage of medical treatment.
The conclusions exposed in this paper do not necessarily imply that studies employing age-unmatched classes, very large feature vectors, or record-wise trials are not exploiting PD-related acoustic features or patterns useful to automatically detect or assess PD. However, including these methodological issues in experiments does not allow us to analyze if the results obtained are a direct consequence of the influence of PD in the voice of the participants or if other factors such as age or identity are contributing to the overall accuracy of the models.
A final takeaway from this study should be that although we have isolated several methodological practices which lead to overoptimistic classification accuracy, there are other possible factors which may influence the results in several different ways that have not been considered here.
In the future, this work and similar studies will open the door for discussion about new comprehensive baselines for experimental conduct in automatic PD detection from phonation, as well as other general applications of speech processing.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












