
Commonsense Knowledge-Aware Prompt Tuning for Few-Shot NOTA Relation Classification


Abstract
:1. Introduction
2. Related Work
2.1. Few-Shot Relation Classification
2.2. Open-World Detection
2.3. Prompt-Tuning
3. Materials and Methods
3.1. Problem Definition
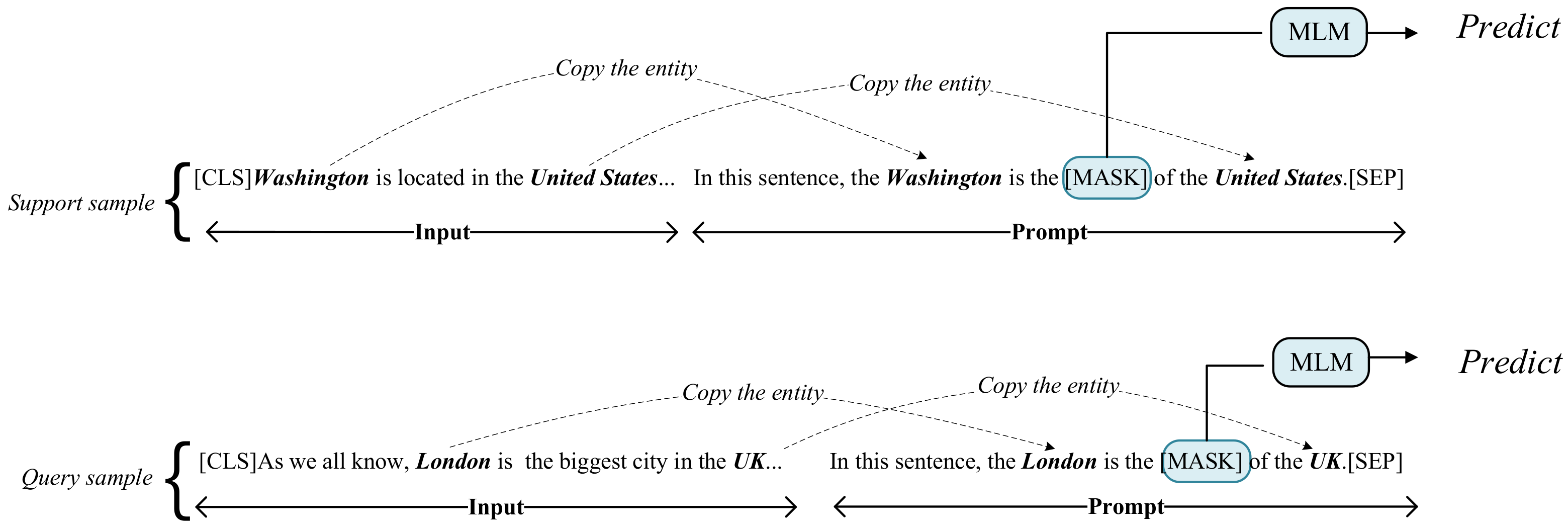
3.2. Prompt Tuning Construction
3.3. Commonsense Knowledge Enhanced Prompt-Tuning
3.4. A Learned Scoring Strategy
4. Results
4.1. Dataset
4.2. Experimental Setup
4.3. Experimental Details
4.4. Models
4.5. FewRel 2.0 Result
4.6. Few-Shot TACRED Results
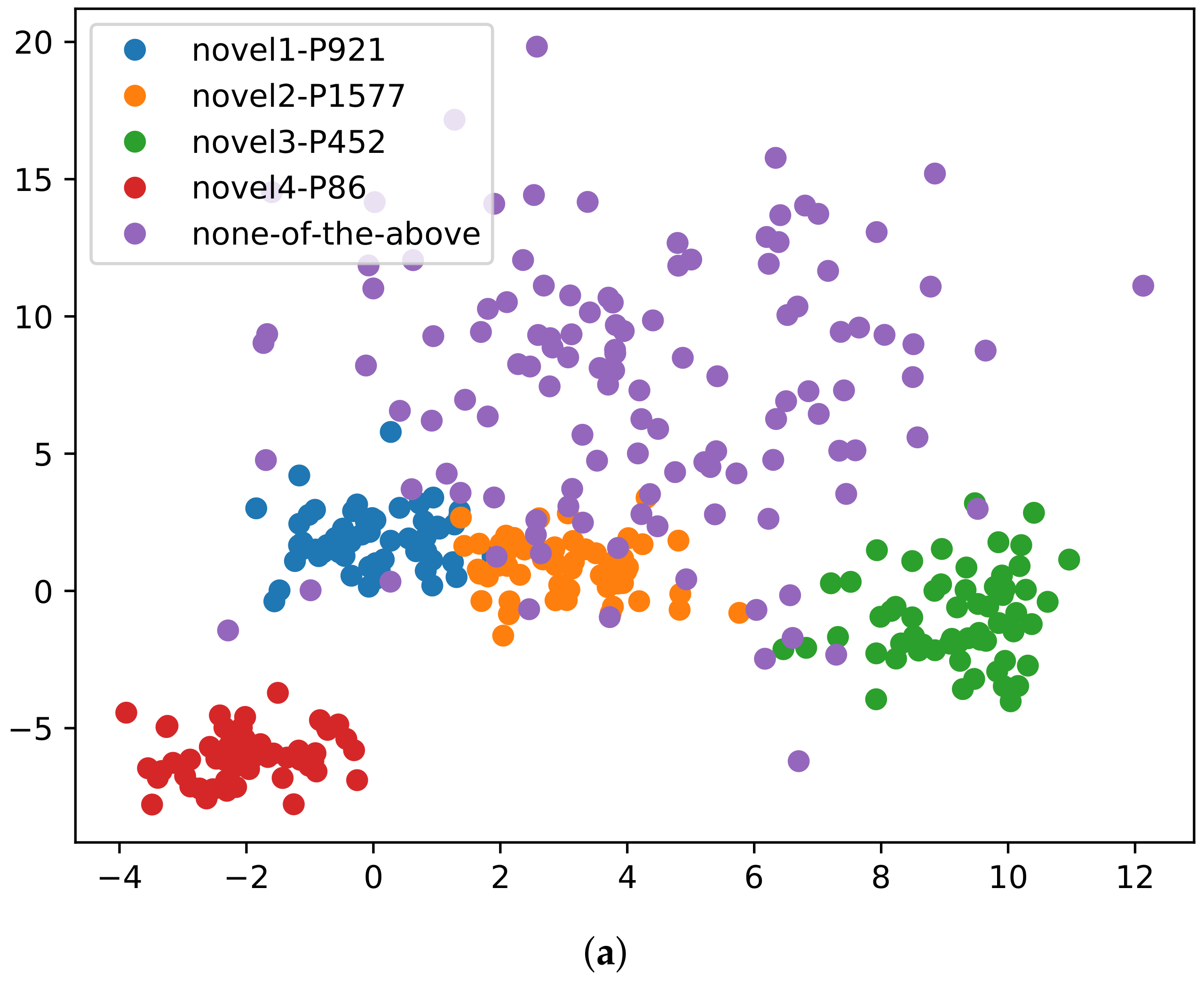
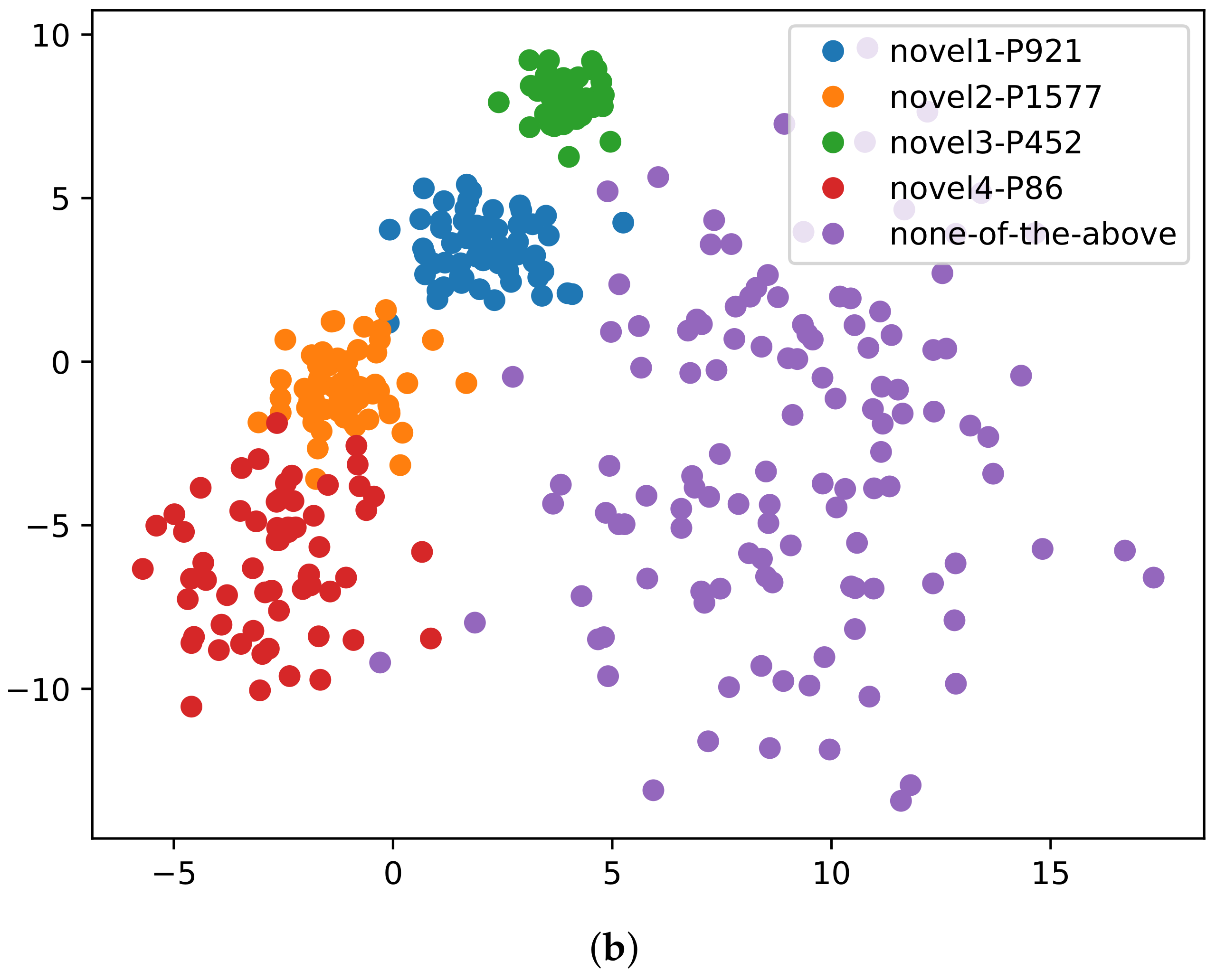
4.7. Ablation Experiments
4.8. Effect of Templates
4.9. NOTA Rates Impact
4.10. Effect of NOTA Loss
4.11. Effect of the Number of Expanding Label Words
4.12. Run-Time of the Model Prediction
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| NOTA | None-of-the-above |
| PLMs | Pre-trained language models |
| CKPT | Commonsense knowledge-aware prompt tuning |
References
- Gao, T.; Han, X.; Zhu, H.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 6250–6255. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding; NAACL: Baltimore, MD, USA, 2019. [Google Scholar]
- Sabo, O.M.S.; Elazar, Y.; Goldberg, Y.; Dagan, I. Revisiting Few-shot Relation Classification: Evaluation Data and Classification Schemes. Trans. Assoc. Comput. Linguist. 2021, 9, 691–706. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 16 January 2022).
- Sampath, P.; Sridhar, N.S.; Shanmuganathan, V.; Lee, Y. TREASURE: Text Mining Algorithm Based on Affinity Analysis and Set Intersection to Find the Action of Tuberculosis Drugs against Other Pathogens. Appl. Sci. 2021, 11, 6834. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, G.; Ma, Y. Syntax-Informed Self-Attention Network for Span-Based Joint Entity and Relation Extraction. Appl. Sci. 2021, 11, 1480. [Google Scholar] [CrossRef]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4803–4809. [Google Scholar]
- Dou, Z.Y.; Yu, K.; Anastasopoulos, A. Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 1192–1197. [Google Scholar]
- Satorras, V.G.; Estrach, J.B. Few-Shot Learning with Graph Neural Networks. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A Simple Neural Attentive Meta-Learner. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bengio, Y.; Bengio, S.; Cloutier, J. Learning a synaptic learning rule. In Proceedings of the IJCNN-91-Seattle International Joint Conference on Neural Networks, Seattle, WA, USA, 8–12 July 1991; Volume II, p. 969. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Geng, X.; Chen, X.; Zhu, K.Q.; Shen, L.; Zhao, Y. MICK: A Meta-Learning Framework for Few-shot Relation Classification with Small Training Data. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020. [Google Scholar]
- Wang, Y.; Bao, J.; Liu, G.; Wu, Y.; He, X.; Zhou, B.; Zhao, T. Learning to Decouple Relations: Few-Shot Relation Classification with Entity-Guided Attention and Confusion-Aware Training. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 5799–5809. [Google Scholar]
- Dong, B.; Yao, Y.; Xie, R.; Gao, T.; Han, X.; Liu, Z.; Lin, F.; Lin, L. Meta-Information Guided Meta-Learning for Few-Shot Relation Classification. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2019; pp. 1594–1605. [Google Scholar]
- Qu, M.; Gao, T.; Xhonneux, L.P.; Tang, J. Few-shot Relation Extraction via Bayesian Meta-learning on Relation Graphs. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; Volume 119, pp. 7867–7876. [Google Scholar]
- Seo, C.W.; Seo, Y. Seg2pix: Few Shot Training Line Art Colorization with Segmented Image Data. Appl. Sci. 2021, 11, 1464. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar] [CrossRef] [Green Version]
- Ren, H.; Cai, Y.; Chen, X.; Wang, G.; Li, Q. A Two-phase Prototypical Network Model for Incremental Few-shot Relation Classification. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 1618–1629. [Google Scholar] [CrossRef]
- Fan, M.; Bai, Y.; Sun, M.; Li, P. Large Margin Prototypical Network for Few-shot Relation Classification with Fine-grained Features. In Proceedings of the 2019 ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; Zhu, W., Tao, D., Cheng, X., Cui, P., Rundensteiner, E.A., Carmel, D., He, Q., Yu, J.X., Eds.; ACM: New York, NY, USA, 2019; pp. 2353–2356. [Google Scholar]
- Ding, N.; Wang, X.; Fu, Y.; Xu, G.; Wang, R.; Xie, P.; Shen, Y.; Huang, F.; Zheng, H.T.; Zhang, R. Prototypical Representation Learning for Relation Extraction. In Proceedings of the 2021 International Conference on Learning Representations, Vienna, Austria, 30 April–3 May 2021. [Google Scholar]
- Wu, L.; Zhang, H.P.; Yang, Y.; Liu, X.; Gao, K. Dynamic Prototype Selection by Fusing Attention Mechanism for Few-Shot Relation Classification. In ACIIDS (1); Nguyen, N.T., Jearanaitanakij, K., Selamat, A., Trawinski, B., Chittayasothorn, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 431–441. [Google Scholar]
- Tan, M.; Yu, Y.; Wang, H.; Wang, D.; Potdar, S.; Chang, S.; Yu, M. Out-of-Domain Detection for Low-Resource Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Linguistics: Hong Kong, China, 2019; pp. 3566–3572. [Google Scholar]
- Teigen, A.L.; Saad, A.; Stahl, A.; Mester, R. Few-Shot Open World Learner. IFAC-PapersOnLine 2021, 54, 444–449. [Google Scholar] [CrossRef]
- Willes, J.; Harrison, J.; Harakeh, A.; Finn, C.; Pavone, M.; Waslander, S.L. Bayesian Embeddings for Few-Shot Open World Recognition. CoRR 2021. Available online: http://xxx.lanl.gov/abs/2107.13682 (accessed on 16 January 2022).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. CoRR 2021. Available online: http://xxx.lanl.gov/abs/2107.13586 (accessed on 16 January 2022).
- Schick, T.; Schütze, H. Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Online, 10 September 2020. [Google Scholar]
- Han, X.; Zhao, W.; Ding, N.; Liu, Z.; Sun, M. PTR: Prompt Tuning with Rules for Text Classification. arXiv 2021, arXiv:2105.11259. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the NAACL-HLT 2019: Demonstrations, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Ding, N.; Chen, Y.; Han, X.; Xu, G.; Xie, P.; Zheng, H.; Liu, Z.; Li, J.; Kim, H. Prompt-Learning for Fine-Grained Entity Typing. CoRR 2021. Available online: http://xxx.lanl.gov/abs/2108.10604 (accessed on 16 January 2022).
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3816–3830. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan, R.L., IV; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4222–4235. [Google Scholar] [CrossRef]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021. [Google Scholar]
- Hambardzumyan, K.; Khachatrian, H.; May, J. WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4921–4933. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhong, V.; Chen, D.; Angeli, G.; Manning, C.D. Position-aware Attention and Supervised Data Improve Slot Filling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 35–45. [Google Scholar]
- Amato, F.; Moscato, F.; Moscato, V.; Pascale, F.; Picariello, A. An agent-based approach for recommending cultural tours. Pattern Recognit. Lett. 2020, 131, 341–347. [Google Scholar] [CrossRef]
- Colace, F.; De Santo, M.; Lombardi, M.; Mercorio, F.; Mezzanzanica, M.; Pascale, F. Towards Labour Market Intelligence through Topic Modelling. In Proceedings of the Hawaii International Conference on System Sciences, Maui, HI, USA, 8–11 January 2019. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test |
|---|---|---|---|
| FewRel 2.0 | 70,000 | 2500 | 3000 |
| Few-Shot TACRED | 8163 | 633 | 804 |
| Dataset | Model | 1-Shot(15%) | 1-Shot (50%) | 5-Shot(15%) | 5-Shot (50%) |
|---|---|---|---|---|---|
| FewRel 2.0 test | Sentence-Pair | 77.67% | 80.31% | 84.19% | 86.06% |
| Threshold | 63.41% | 76.48%. | 65.43 % | 78.95% | |
| NAV | 77.17% | 81.47% | 82.97% | 87.08% | |
| MNAV | 79.06% | 81.69% | 85.52% | 87.74% | |
| CKPT | 80.37% | 83.02% | 86.26% | 88.12% | |
| FewRel 2.0 val | Sentence-Pair | 70.32% | 75.48% | 74.27% | 78.43% |
| Threshold | 63.28% | 76.32% | 66.89% | 80.30% | |
| NAV | - | 78.54% | - | 80.44% | |
| MNAV | - | 78.23% | - | 81.25% | |
| CKPT | 73.28% | 81.25% | 77.92% | 83.62% |
| Model | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| Sentence-Pair | 10.19 ± 0.81% | - |
| Threshold | 6.87 ± 0.48% | 13.57 ± 0.46% |
| NAV | 8.38 ± 0.80% | 18.38 ± 2.01% |
| MNAV | 12.39 ± 1.01% | 30.04 ± 1.92% |
| CKPT | 15.14 ± 1.12% | 32.26 ± 2.13% |
| Model | 5-Way 1-Shot (50%) | 5-Way 5-Shot (50%) |
|---|---|---|
| PT | 79.64 ± 0.10% | 82.25 ± 0.13% |
| PT + NOTA-Loss | 80.35 ± 0.15% | 82.76 ± 0.14% |
| CKPT | 81.25 ± 0.12% | 83.62 ± 0.13% |
| Template | 5-Way | |
|---|---|---|
| 1-Shot (50%) | 5-Shot (50%) | |
| x.the is the [MASK] the . | 80.34 ± 0.11% | 82.16 ± 0.18% |
| x.In this sentence, the is the [MASK] the . | 80.95 ± 0.12% | 82.87 ± 0.14% |
| x.In this sentence, the is the [MASK] the . | 81.25 ± 0.12% | 83.62 ± 0.13% |
| Model | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| NAV | 0.52 s | 2.62 s |
| MNAV | 0.68 s | 3.12 s |
| CKPT | 0.47 s | 2.28 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, B.; Jin, L.; Zhang, Y.; Wang, H.; Li, X.; Guo, Z. Commonsense Knowledge-Aware Prompt Tuning for Few-Shot NOTA Relation Classification. Appl. Sci. 2022, 12, 2185. https://doi.org/10.3390/app12042185
Lv B, Jin L, Zhang Y, Wang H, Li X, Guo Z. Commonsense Knowledge-Aware Prompt Tuning for Few-Shot NOTA Relation Classification. Applied Sciences. 2022; 12(4):2185. https://doi.org/10.3390/app12042185
Chicago/Turabian StyleLv, Bo, Li Jin, Yanan Zhang, Hao Wang, Xiaoyu Li, and Zhi Guo. 2022. "Commonsense Knowledge-Aware Prompt Tuning for Few-Shot NOTA Relation Classification" Applied Sciences 12, no. 4: 2185. https://doi.org/10.3390/app12042185
APA StyleLv, B., Jin, L., Zhang, Y., Wang, H., Li, X., & Guo, Z. (2022). Commonsense Knowledge-Aware Prompt Tuning for Few-Shot NOTA Relation Classification. Applied Sciences, 12(4), 2185. https://doi.org/10.3390/app12042185