
Visual Sorting Method Based on Multi-Modal Information Fusion



Abstract
:1. Introduction
- A new object detection network based on multi-modal information fusion (OD-MF) is proposed to detect parcels in stacked scenes, which not only achieves high detection accuracy, but also meets the real-time requirements for robots performing sorting tasks.
- A novel multi-modal segmentation network based on Swin Transformer (MS-ST) is proposed, which obtains the pickable region and the occlusion degree of the parcels. As is known, it is the first network to complete these two tasks at the same time. Then, the optimal sorting position and pose of parcels can be calculated.
- A novel strategy for the optimal sorting order of parcels is proposed, which can effectively ensure the stability of robot system during the sorting process.
2. Visual Sorting Method for Stacked Parcels in Complex Scenes
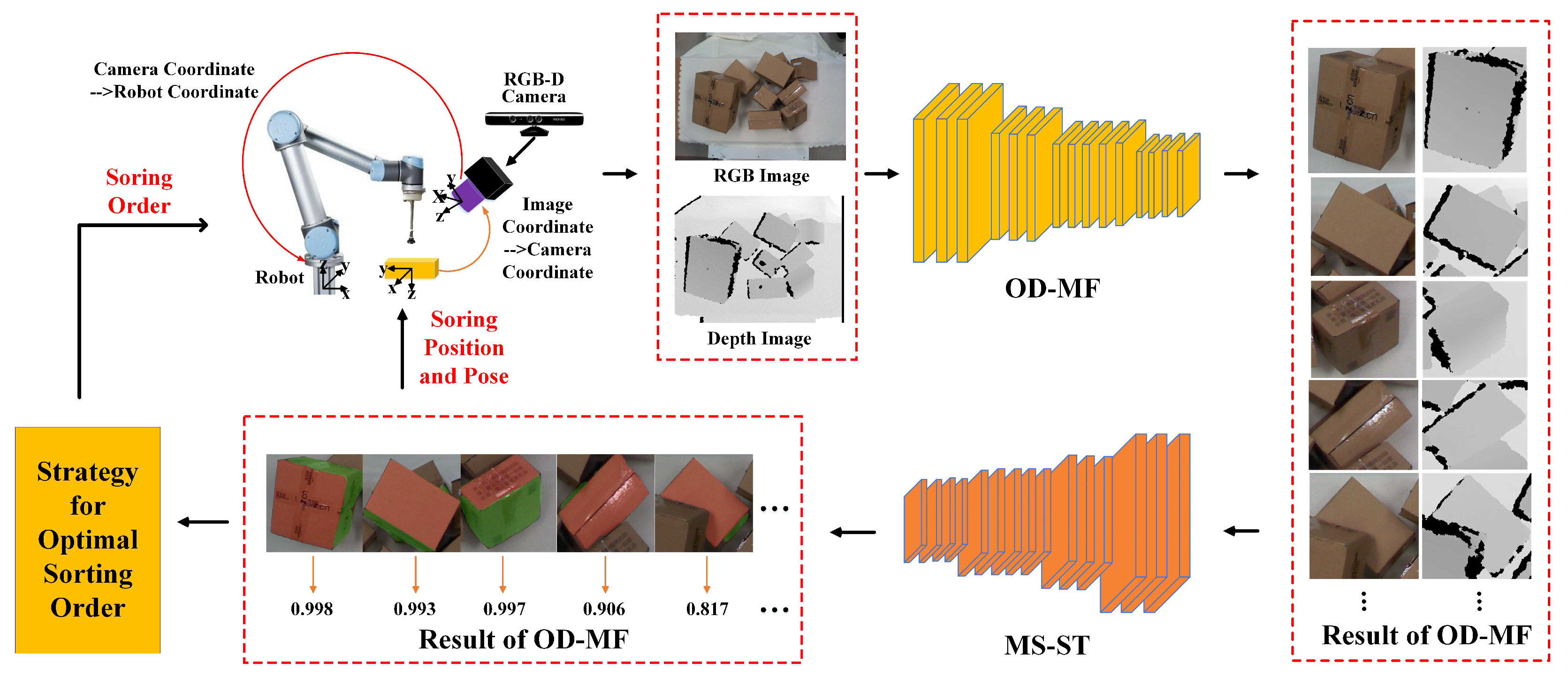
2.1. Overall Framework
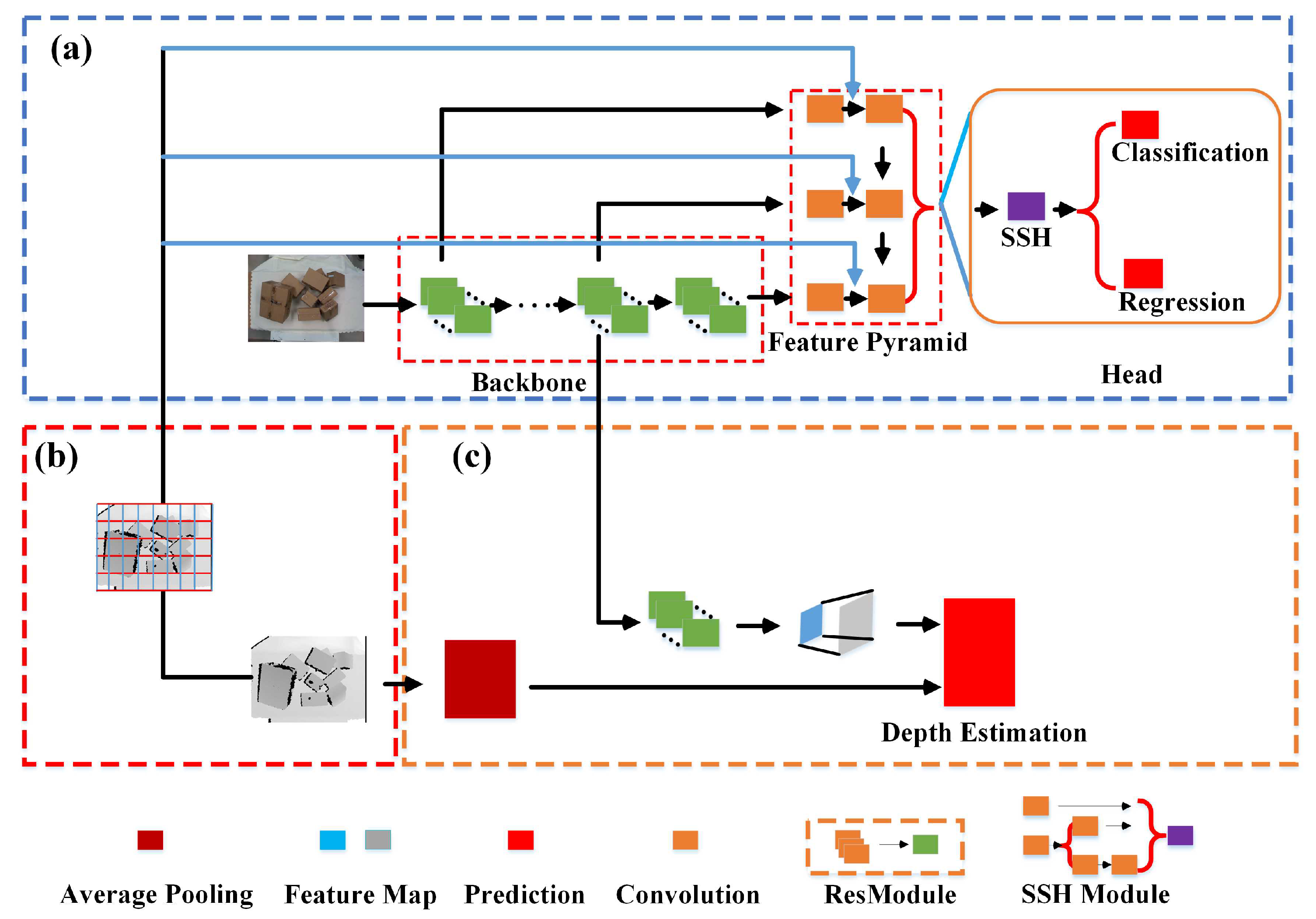
2.2. Object Detection Network Based on Multi-Modal Information Fusion
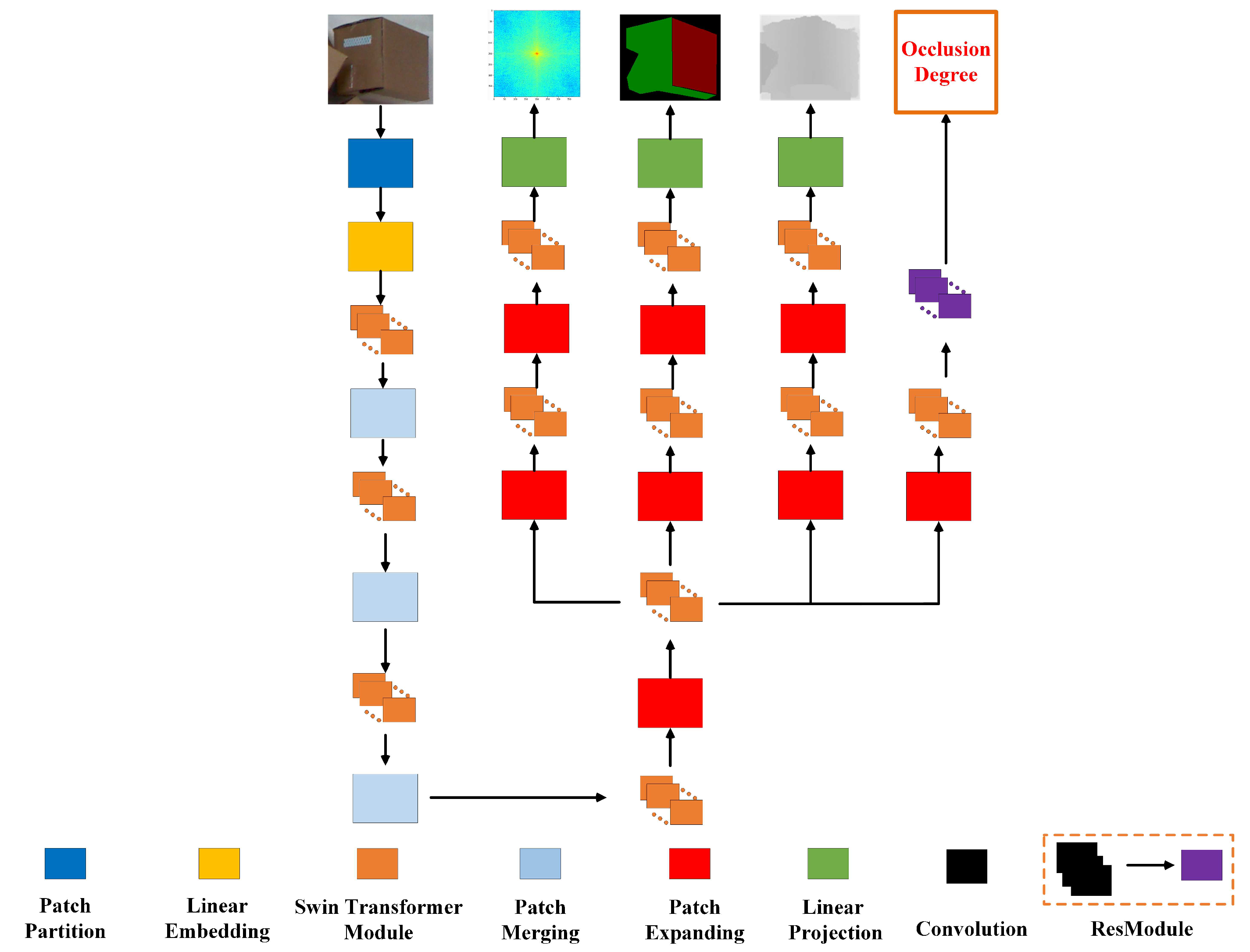
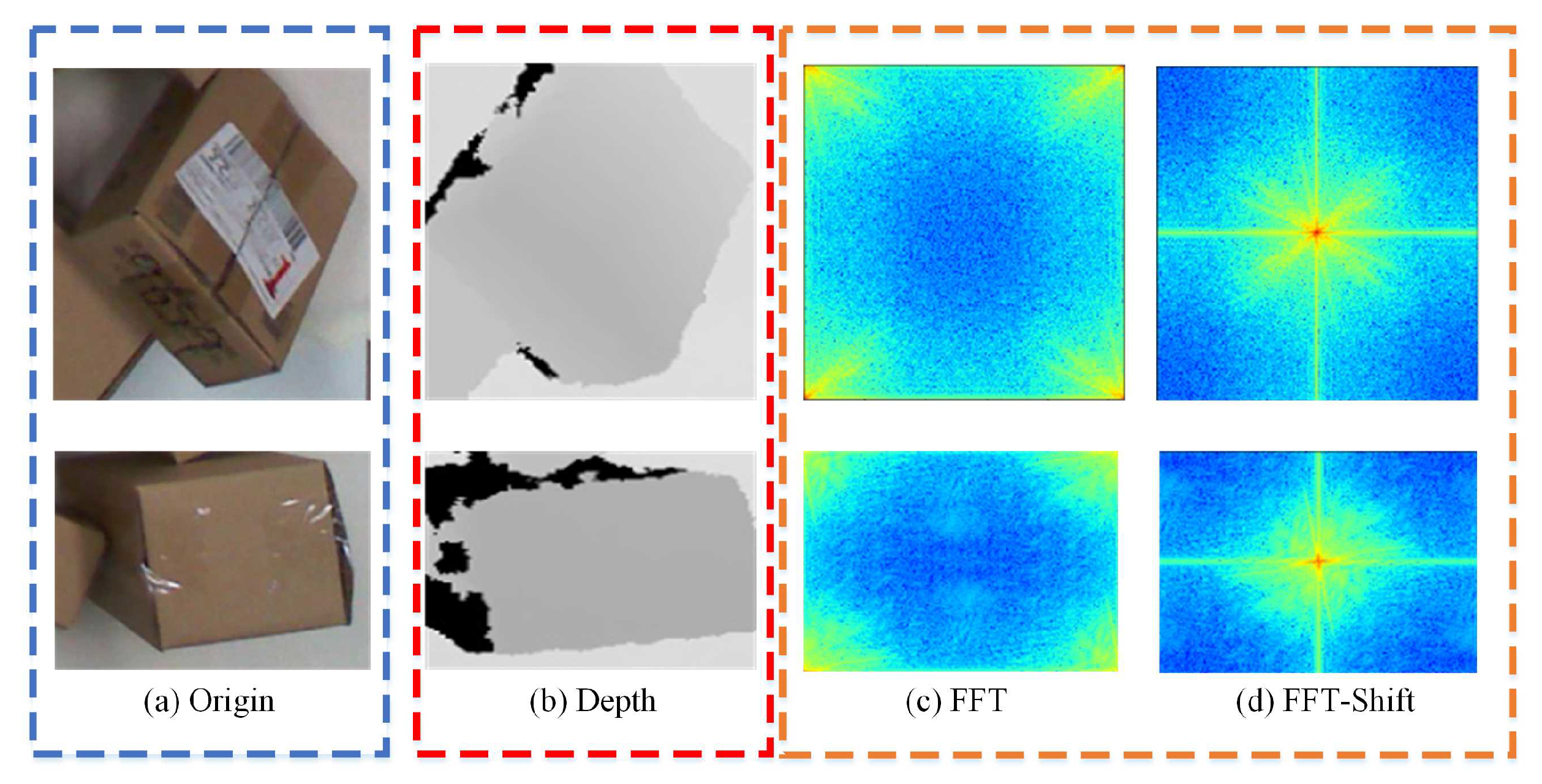
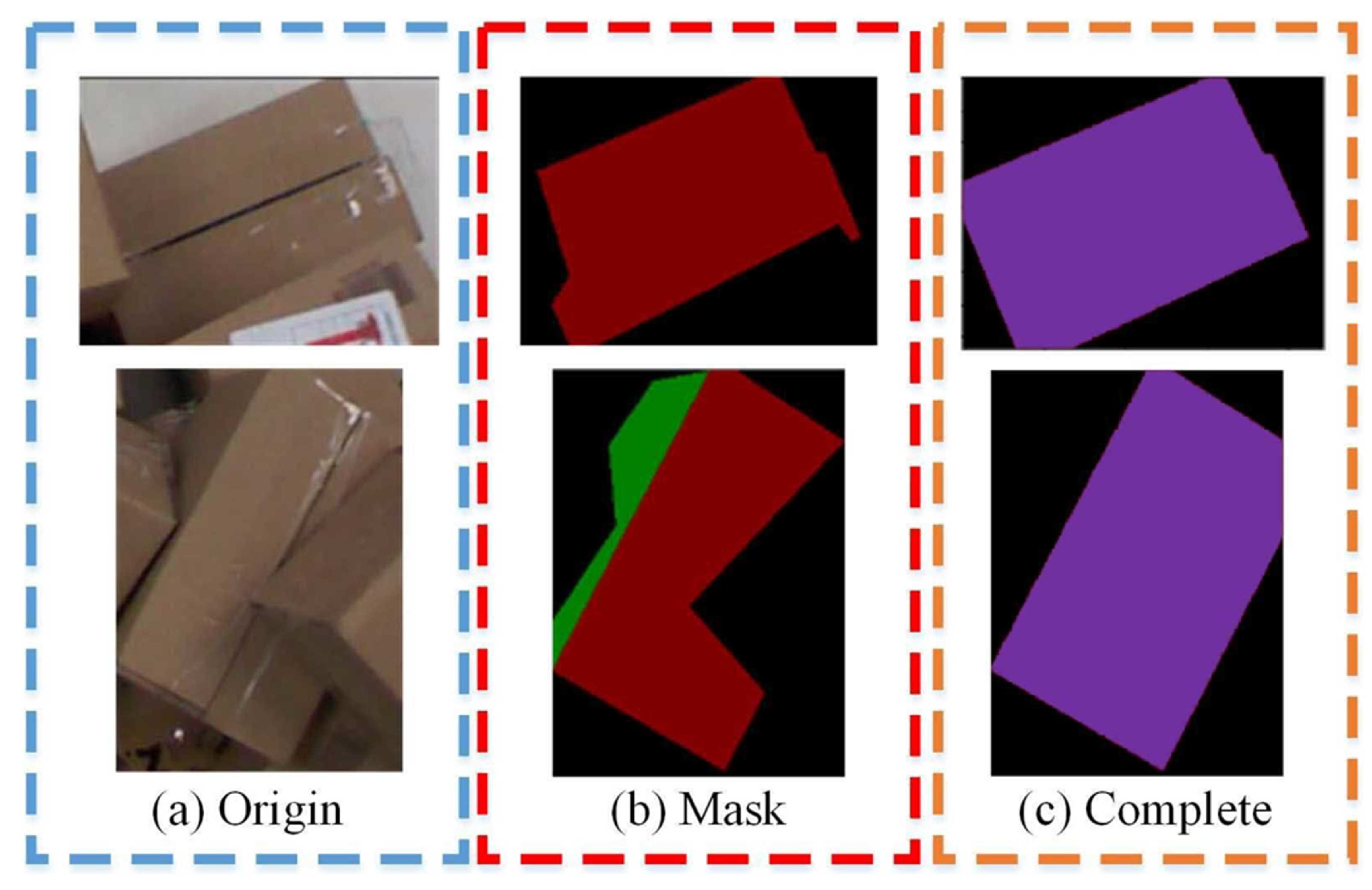
2.3. Multi-Modal Segmentation Network Based on Swin Transformer
2.4. Strategy for Optimal Sorting Order
3. Experiment and Analysis
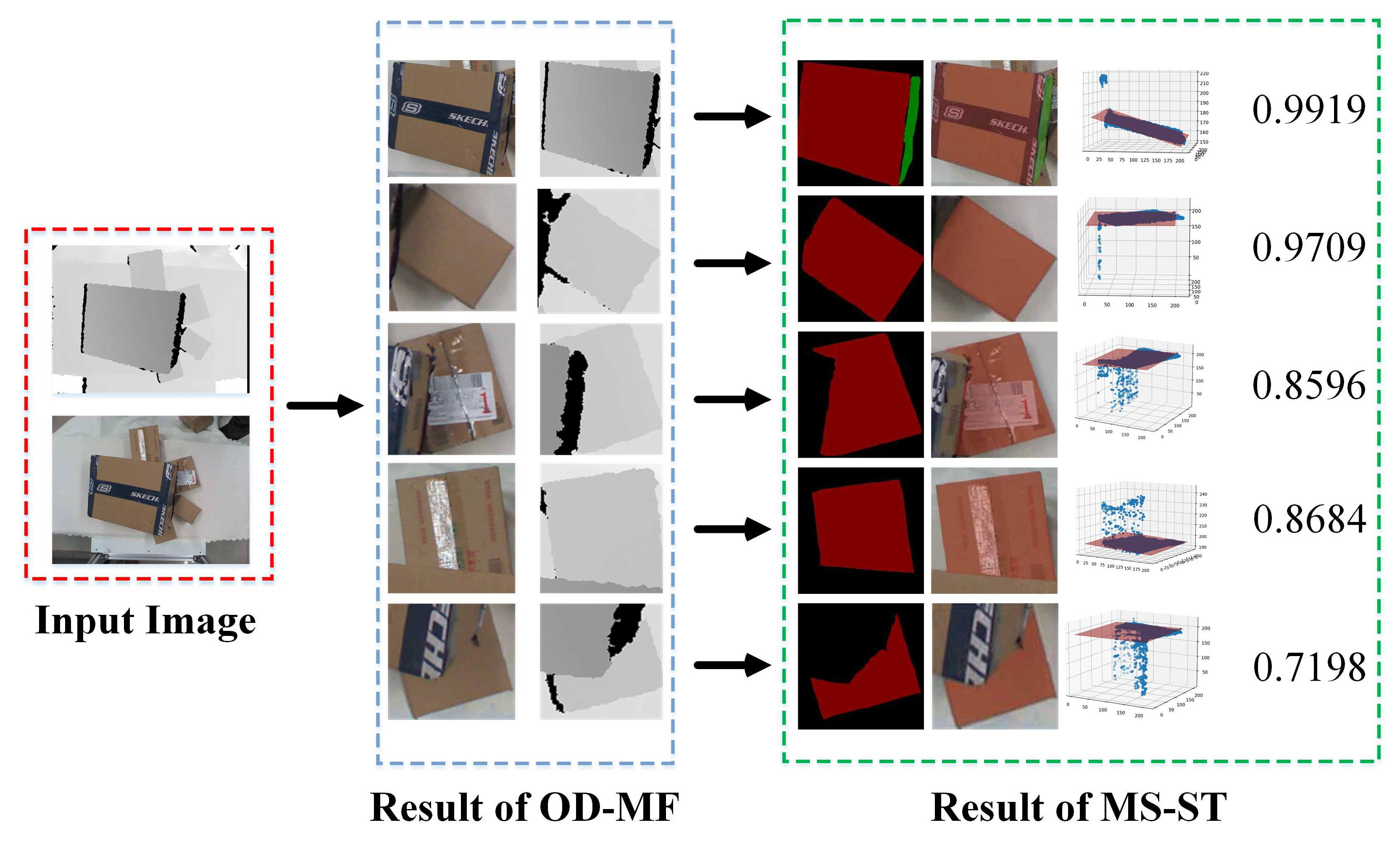
3.1. Experiment on OD-MF
3.2. Experiment on MS-ST
3.3. Experiment on Strategy for Optimal Sorting Order
3.4. Robot Sorting Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sansoni, G.; Bellandi, P.; Leoni, F.; Docchio, F. Optoranger: A 3D pattern matching method for bin picking applications. Opt. Lasers Eng. 2014, 54, 222–231. [Google Scholar] [CrossRef]
- Wu, C.H.; Jiang, S.Y.; Song, K.T. CAD-based pose estimation for random bin-picking of multiple objects using a RGB-D camera. In Proceedings of the 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea, 13–16 October 2015. [Google Scholar]
- Song, K.T.; Wu, C.H.; Jiang, S.Y. CAD-based Pose Estimation Design for Random Bin Picking using a RGB-D Camera. J. Intell. Robot. Syst. 2017, 87, 455–470. [Google Scholar] [CrossRef]
- Viereck, U.; Pas, A.T.; Saenko, K.; Platt, R. Learning a visuomotor controller for real world robotic grasping using simulated depth images. In Proceedings of the Conference on Robot Learning (CoRL), Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Du, X.; Cai, Y.; Lu, T.; Wang, S.; Yan, Z. A robotic grasping method based on deep learning. Robot 2017, 39, 820–837. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Zhang, H.; Lan, X.; Zhou, X.; Tian, Z.; Zhang, Y. Visual Manipulation Relationship Network for Autonomous Robotics. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018. [Google Scholar]
- Sundermeyer, M.; Marton, Z.; Durner, M.; Triebel, R. Augmented autoencoders: Implicit 3d orientation learning for 6d object detection. Int. J. Comput. Vis. 2020, 128, 714–729. [Google Scholar] [CrossRef]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-less: An rgb-d dataset for 6d pose estimation of texture-less objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV) IEEE, Santa Rosa, CA, USA, 24–31 March 2017; pp. 880–888. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2pose: Pixelwise coordinate regression of objects for 6d pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7668–7677. [Google Scholar]
- Wei, J.; Liu, H.; Yan, G.; Sun, F. Robotic grasping recognition using multi-modal deep extreme learning machine. Multidimens. Syst. Signal Process. 2017, 28, 817–833. [Google Scholar] [CrossRef]
- Andy, Z.; Shuran, S.; Kuan-Ting, Y.; Elliott, D.; Alberto, R. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Long, J.; Evan, S.; Trevor, D. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Nguyen, A.; Kanoulas, D.; Caldwell, D.G.; Tsagarakis, N.G. Object-based affordances detection with convolutional neural networks and dense conditional random fields. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Lafferty, J.; Andrew, M.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–01 July 2001. [Google Scholar]
- Do, T.; Anh, N.; Ian, R. Affordancenet: An end-to-end deep learning approach for object affordance detection. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Kaiming, H.; Georgia, G.; Piotr, D. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Han, X.; Liu, X.-P. Robotic sorting method in complex scene based on deep neural network. J. Beijing Univ. Posts Telecommun. 2019, 42, 22–28. [Google Scholar]
- Han, S.; Liu, X.-P.; Han, X.; Wang, G.; Wu, S. Visual sorting of express parcels based on multi-task deep learning. Sensors 2020, 20, 6785. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 March 2021. [Google Scholar]
- Alexey, D.; Lucas, B.; Alexander, K.; Dirk, W. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the ICLR, Vienna, Austria, 3–7 April 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 March 2021. [Google Scholar]
- Panda, S.; Hafez, A.; Jawahar, C. Learning support order for manipulation in clutter. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Rosman, B.; Ramamoorthy, S. Learning spatial relationships between objects. Int. J. Robot. Res. 2011, 30, 1328–1342. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 21 October 2017. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Horaud, R.; Fadi, D. Hand-eye calibration. Int. J. Robot. Res. 1995, 14, 195–210. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| batch size | 16 |
| base learning rate | 0.01 |
| learning rate decay | 9000, 14,000 |
| rate of learning rate change | 0.1 |
| maximum iterations | 16,000 |
| Momentum | 0.9 |
| weight decay | 0.0005 |
| Model | Precision (%) | Recall (%) | FPS |
|---|---|---|---|
| YOLOv5s (Baseline) | 91.75 | 92.33 | 16.13 |
| + MMI | 98.28 (+6.53) | 95.56 (+3.23) | 13.89 |
| + Self-Attention | 93.23 (+1.48) | 96.05 (+3.72) | 15.15 |
| + MMI and Self-Attention | 98.57 (+6.82) | 96.62 (+4.29) | 13.51 |
| Model | Recall (%) | FPS |
|---|---|---|
| YOLOv5s + Self-Attention | 96.62 | 13.51 |
| + normalization | 96.85 (+0.23) | 13.33 |
| + normalization and MAG | 97.24 (+0.62) | 13.15 |
| Model | PA of Pickable Region (%) | PA of Unpickable Region (%) | MIOU (%) |
|---|---|---|---|
| MS-ST (Baseline) | 87.24 | 90.57 | 89.11 |
| +FFT | 90.36 (+3.12) | 91.15 (+0.58) | 90.57 (+1.46) |
| +Depth | 94.15 (+6.91) | 96.71 (+6.14) | 95.41 (+6.30) |
| +FFT and Depth | 95.03 (+7.79) | 96.94 (+6.37) | 95.97 (+6.86) |
| Model | MAE of Position | MAE of Pose |
|---|---|---|
| RSDNN | 14.97 ± 0.61 | 0.59 ± 0.07 |
| VSMT | 13.76 ± 0.42 | 0.42 ± 0.05 |
| MS-ST | 12.68 ± 0.36 | 0.23 ± 0.02 |
| Model | MAP | Sorting Success Rate |
|---|---|---|
| RSDNN | 73.4 | 79.5 |
| VSMT | 76.2 | 89.7 |
| VS-MF | 89.2 | 92.0 |
| VS-MF | 87.1 | 90.3 |
| VS-MF | 91.8 | 93.7 |
| VS-MF | 93.3 | 94.3 |
| VS-MF | 91.7 | 93.7 |
| VS-MF | 90.0 | 92.3 |
| VS-MF | 88.1 | 91.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Liu, X.; Wang, G. Visual Sorting Method Based on Multi-Modal Information Fusion. Appl. Sci. 2022, 12, 2946. https://doi.org/10.3390/app12062946
Han S, Liu X, Wang G. Visual Sorting Method Based on Multi-Modal Information Fusion. Applied Sciences. 2022; 12(6):2946. https://doi.org/10.3390/app12062946
Chicago/Turabian StyleHan, Song, Xiaoping Liu, and Gang Wang. 2022. "Visual Sorting Method Based on Multi-Modal Information Fusion" Applied Sciences 12, no. 6: 2946. https://doi.org/10.3390/app12062946
APA StyleHan, S., Liu, X., & Wang, G. (2022). Visual Sorting Method Based on Multi-Modal Information Fusion. Applied Sciences, 12(6), 2946. https://doi.org/10.3390/app12062946