
A Comparative Study of a Fully-Connected Artificial Neural Network and a Convolutional Neural Network in Predicting Bridge Maintenance Costs

Abstract
:1. Introduction
2. Bridge Maintenance Cost Database
3. Neural Network-Based Bridge Maintenance Cost Prediction Framework
3.1. Selecting Input Indicators Based on Random Forest
- (1)
- Calculate the Gini index of the node m in a certain category K. The formula for calculating the Gini is:where K is the number of categories in the sample set and is the estimated probability that the sample of node m belongs to the k-th category; when the sample belongs to one of categories, K = 2.
- (2)
- The decision trees in the random forest used in this study only had two branches. Therefore, the Gini index of node m could be calculated as:where is the estimated probability that the sample belongs to any category at node m.
- (3)
- Calculate the VIM value of node m. The importance of indicator Xj at node m; that is, the variable quantity in the Gini index before and after the branch at node m is:where and represent the Gini indexes of two new nodes split by node .
- (4)
- Calculate the VIM value of indicator in the random forest. If the indicator appears times i-th in the tree, the importance of the indicator in the i-th tree is:
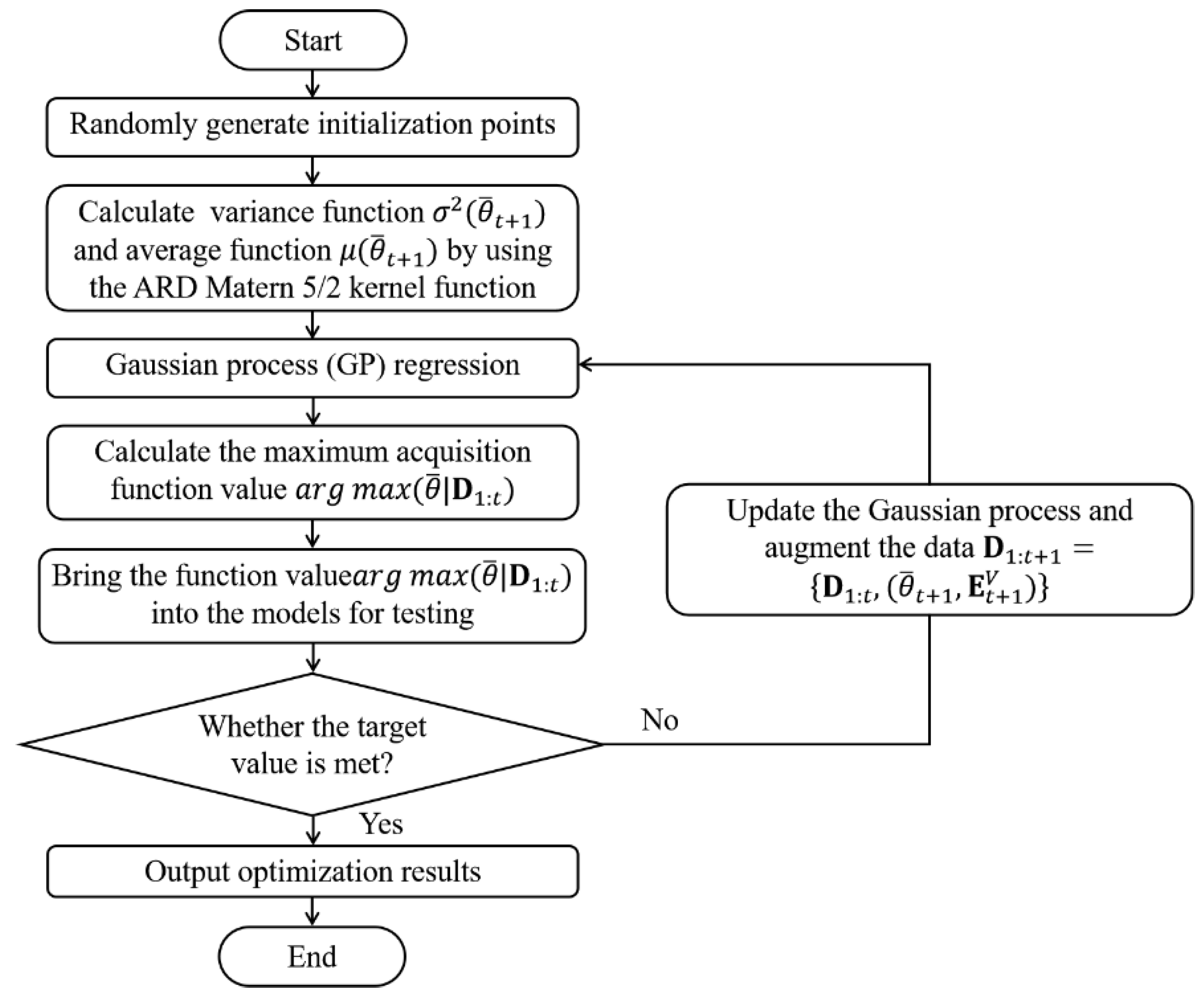
3.2. Bayesian Optimization
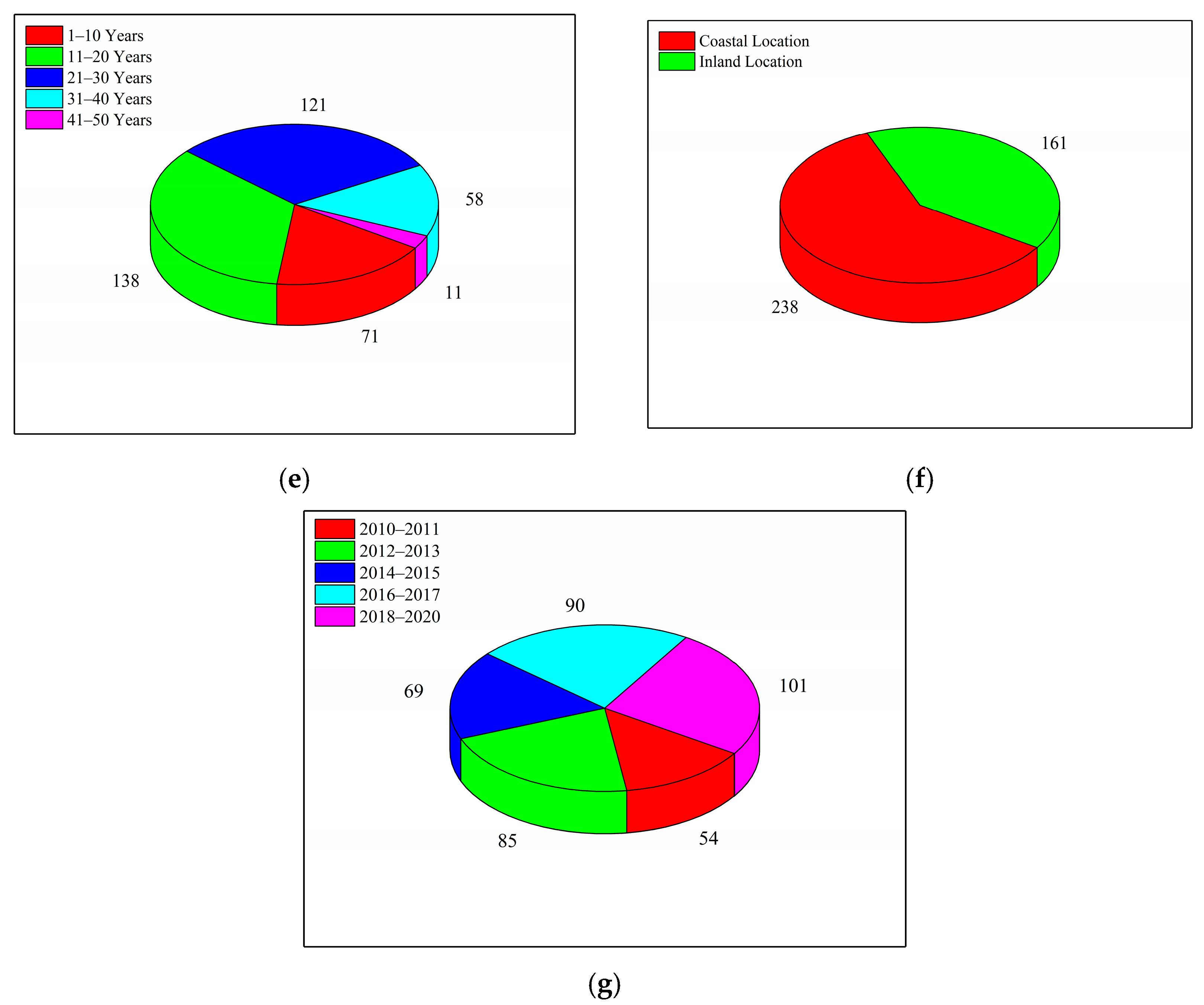
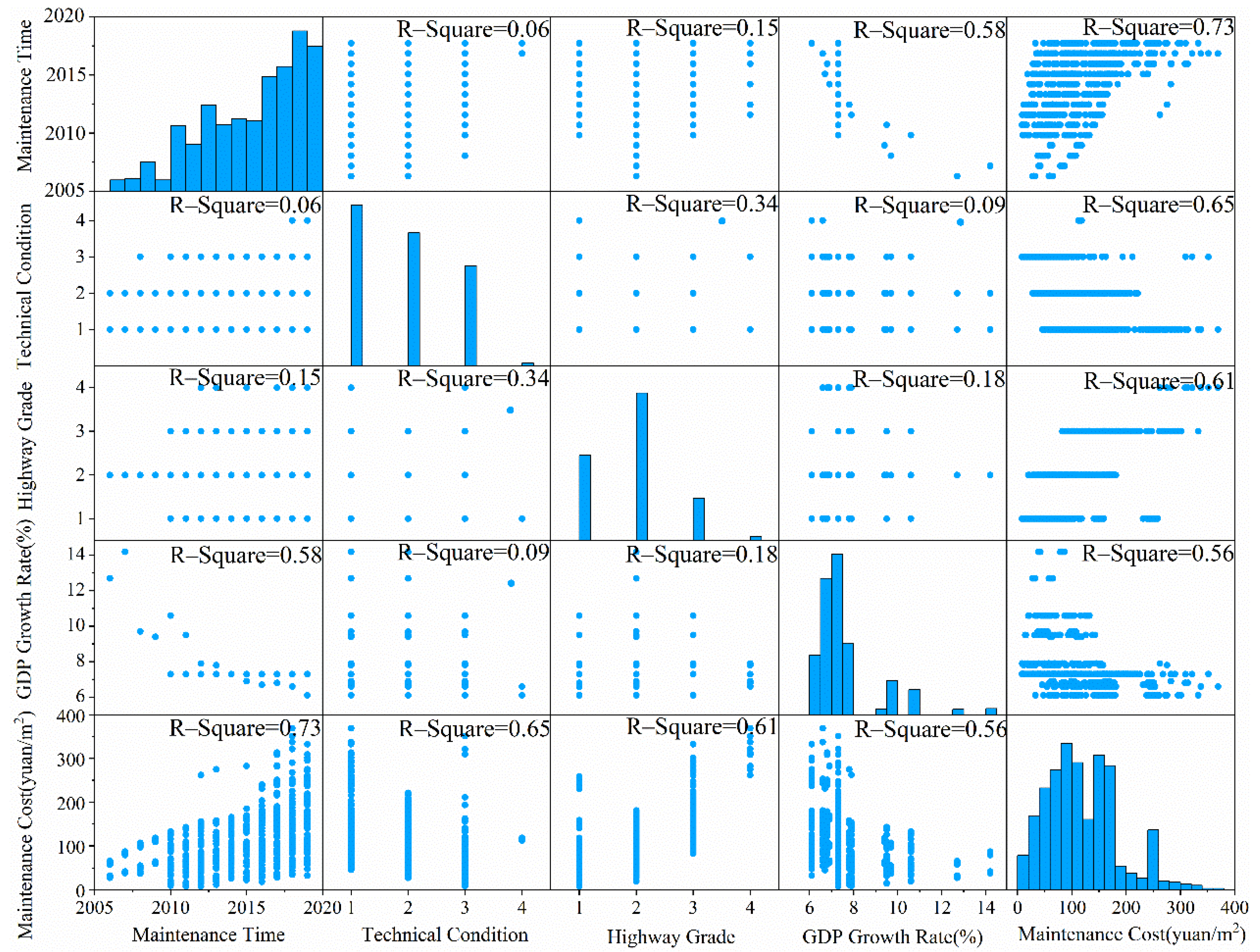
3.3. Exploratory Data Analysis
3.4. Sample Screening
- (a)
- When ;
- (b)
- When ;
- (c)
- When .
3.5. The Fully-Connected ANN Model
- (1)
- The connection weight value and threshold are initialized based on random values.
- (2)
- The output of each unit of the hidden layer and the output layer is calculated according to the parameters selected by the input mode and output mode. In this study, the ReLU [46] is used as the activation function of the hidden layer. The Tanh [47] is used as the activation function of the output layer.
- (3)
- The new connection weights and thresholds are calculated using the Equations (13)–(16). The modification of the neuron threshold:where and are the threshold values of the j-th node in the hidden layer and the k-th node in the output layer, respectively and are errors of the j-th node in the hidden layer and the k-th node in the output layer respectively. is the learning rate of the t-th training iteration.
- (4)
- Return to the second step to train the neural network and update the learning input mode continuously until the number of training times reaches the preset value. The basic flow of the above calculation process is shown in Figure 5:
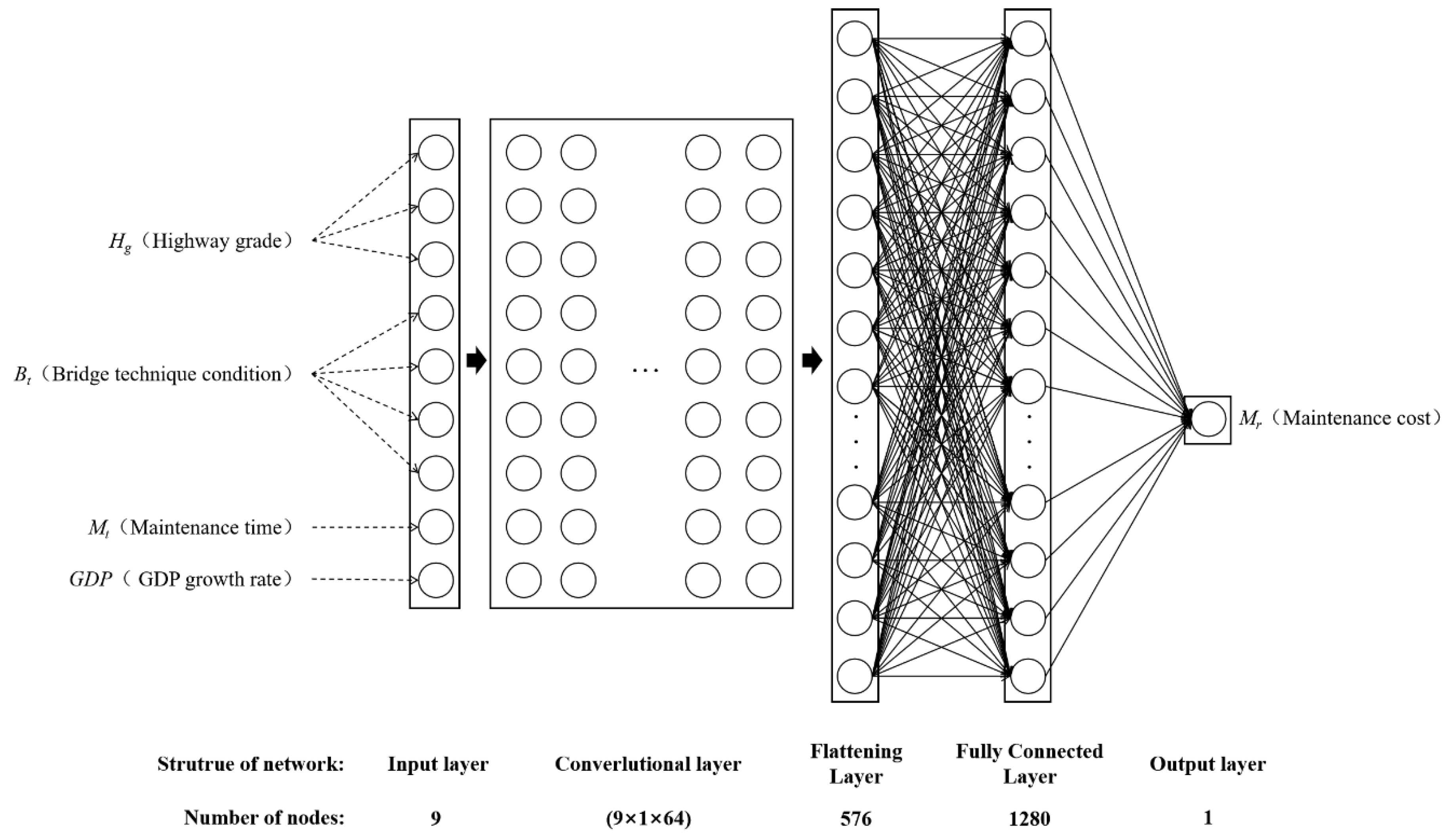
3.6. CNN Model
4. Implementation Results of a Fully-Connected ANN and CNN
4.1. Influencing Factors of Bridge Maintenance Costs
4.2. Sample Classification Based on Selected Indicators
4.3. Sample Screening Based on Isolation Forest
4.4. Structure of the Sample Database
4.5. Topology of the Fully-Connected ANN Model and CNN Model
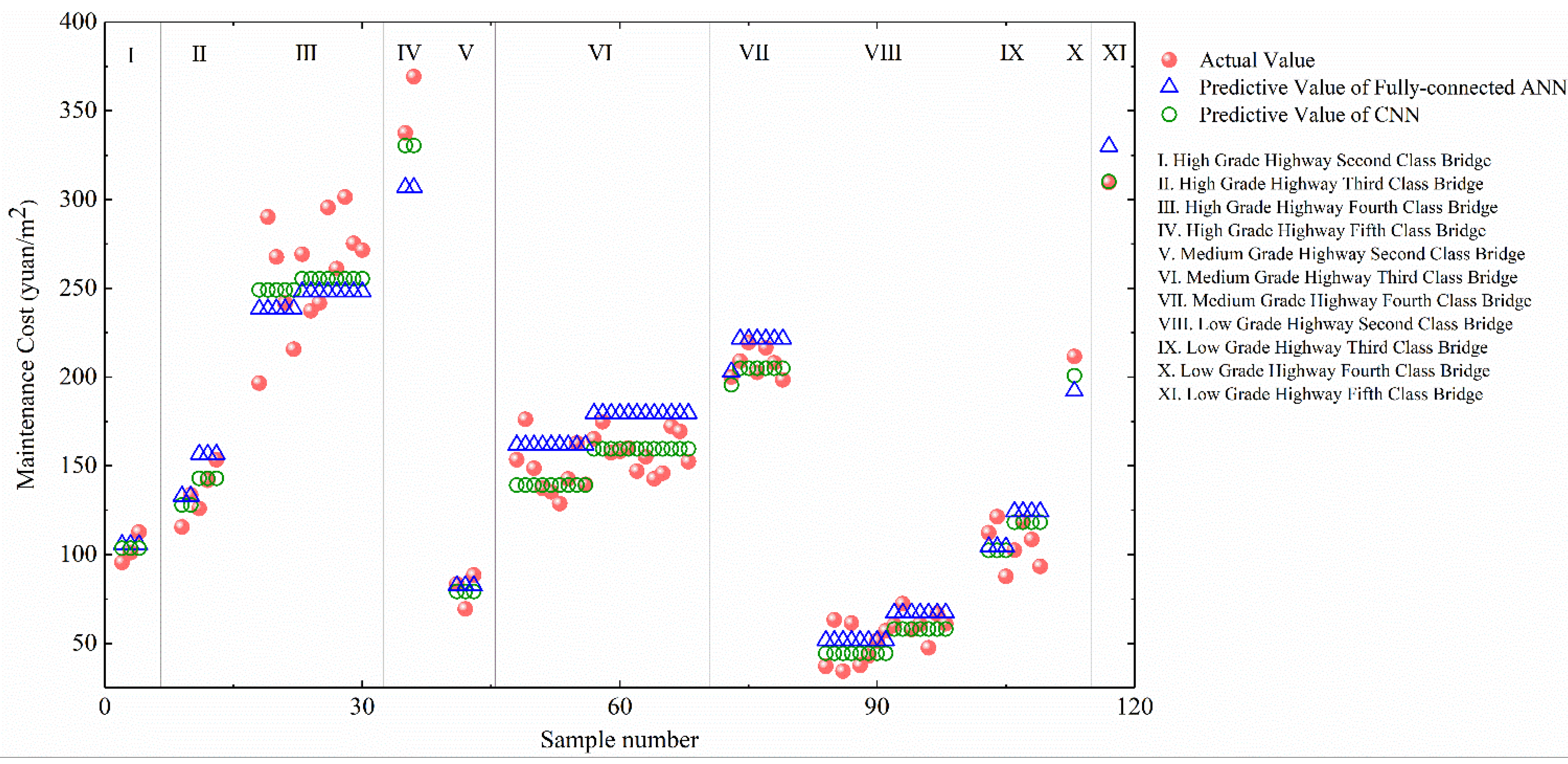
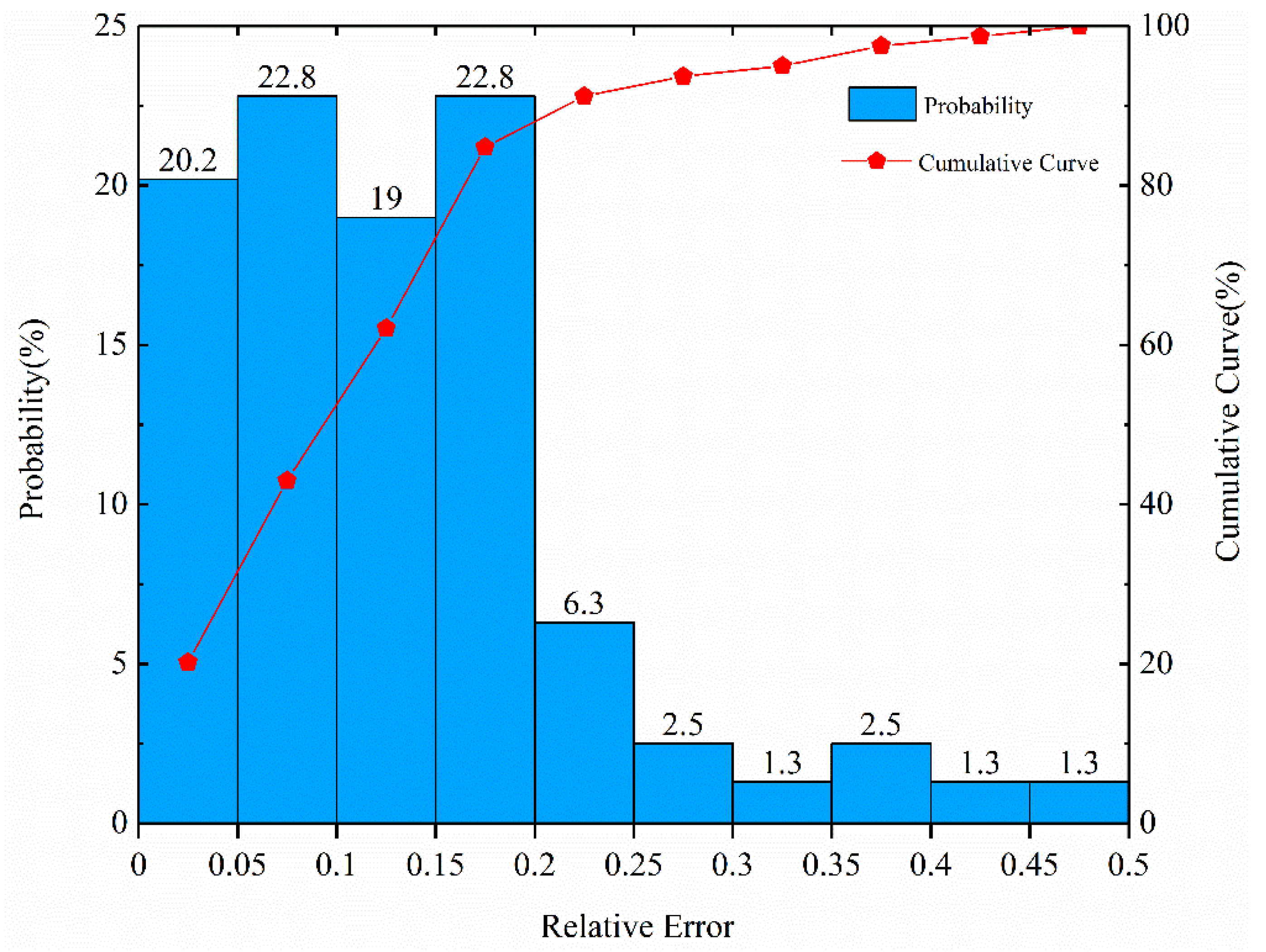
4.6. Accuracy Analysis of Prediction Model
5. Conclusions
6. Prospect
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Society of Civil Engineers. Report Card for America’s Infrastructure; ASCE: Reston, VA, USA, 2021; Available online: https://www.asce.org/ (accessed on 26 February 2022).
- Cadenazzi, T.; Dotelli, G.; Rossini, M.; Nolan, S.; Nanni, A. Cost and environmental analyses of reinforcement alternatives for a concrete bridge. Struct. Infrastruct. Eng. 2020, 16, 787–802. [Google Scholar] [CrossRef]
- Zhou, J.; Zheng, D. Strategic Thinking on Safeguarding Bridge Safety in China. China Eng. Sci. 2017, 19, 27–37. [Google Scholar] [CrossRef]
- MOT—Ministry of Transport of the People’s Republic of China. Statistical Bulletin on the Development of the Transportation Industry; Ministry of Transport of the People’s Republic of China: Beijing, China, 2020. Available online: http://www.gov.cn/xinwen/2021-05/19/content_5608523.htm (accessed on 26 February 2022).
- Wang, Z.F.; Dai, G.H. Maintenance Strategies of Historical Bridges in China. Appl. Mech. Mater. 2012, 178–181, 2264–2267. [Google Scholar] [CrossRef]
- Barone, G.; Frangopol, D.; Soliman, M. Optimization of Life-Cycle Maintenance of Deteriorating Bridges with Respect to Expected Annual System Failure Rate and Expected Cumulative Cost. J. Struct. Eng. 2014, 140, 04013043. [Google Scholar] [CrossRef] [Green Version]
- Sabatino, S.; Frangopol, D.M.; Dong, Y. Sustainability-informed maintenance optimization of highway bridges considering multi-attribute utility and risk attitude. Eng. Struct. 2015, 102, 310–321. [Google Scholar] [CrossRef]
- Ghodoosi, F.; Abu-Samra, S.; Zeynalian, M.; Zayed, T. Maintenance Cost Optimization for Bridge Structures Using System Reliability Analysis and Genetic Algorithms. J. Constr. Eng. Manag. 2018, 144, 04017116. [Google Scholar] [CrossRef]
- Lee, J.H.; Choi, Y.; Ann, H.; Jin, S.Y.; Lee, S.-J.; Kong, J.S. Maintenance Cost Estimation in PSCI Girder Bridges Using Updating Probabilistic Deterioration Model. Sustainability 2019, 11, 6593. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Kaul, H.; Kapoor, S.; Veliou, E.; Zhou, B.; Lee, S. New Methodology for Transportation Investment Decisions with Consideration of Project Interdependencies. Transp. Res. Rec. 2012, 2285, 36–46. [Google Scholar] [CrossRef]
- Shi, X.; Zhao, B.; Yao, Y.; Wang, F. Prediction Methods for Routine Maintenance Costs of a Reinforced Concrete Beam Bridge Based on Panel Data. Adv. Civ. Eng. 2019, 2019, 5409802. [Google Scholar] [CrossRef] [Green Version]
- Miyamoto, A.; Kawamura, K.; Nakamura, H. Bridge Management System and Maintenance Optimization for Existing Bridges. Comput. Aided Civ. Infrastruct. Eng. 2000, 15, 45–55. [Google Scholar] [CrossRef]
- Mohammad, B.S.; Yasser, M.; Maria, A.H. Prediction of maintenance cost for road construction equipment: A case study. Can. J. Civ. Eng. 2016, 43, 125–136. [Google Scholar]
- Echaveguren, T.; De Concepción, U.; Dechent, P. Allocation of bridge maintenance costs based on prioritization indexes. Rev. Construcción 2019, 18, 568–578. [Google Scholar] [CrossRef]
- Yong, H.Y.; Yuan, H.J.; Xuan, C.W. Pavement Performance Prediction Methods and Maintenance Cost Based on the Structure Load. Procedia Eng. 2016, 137, 41–48. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-S.; Huang, F.-M.; Guo, T.; Song, Y.-H. Residual life evaluation of prestressed reinforced concrete highway bridges under coupled corrosion-fatigue actions. Adv. Steel Constr. 2015, 11, 372–382. [Google Scholar] [CrossRef] [Green Version]
- Testa, R.B.; Yanev, B.S. Bridge maintenance level assessment. Comput. Aided Civ. Infrastruct. Eng. 2002, 17, 358–367. [Google Scholar] [CrossRef]
- JTG B01-2014; Technical Standard of Highway Engineering. China Communications Press Co., Ltd.: Beijing, China, 2019.
- JTG 5210-2018; Highway Performance Assessment Standards. China Communications Press Co., Ltd.: Beijing, China, 2018.
- JTG D60-2015; General Specifications for Design of Highway Bridges and Culverts. China Communications Press Co., Ltd.: Beijing, China, 2015.
- Bacha, E.L. A three-gap model of foreign transfers and the GDP growth rate in developing countries. J. Dev. Econ. 1990, 32, 279–296. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Guo, Y.; Zhang, Y. Forecasting China’s GDP growth using dynamic factors and mixed-frequency data. Econ. Model. 2017, 66, 132–138. [Google Scholar] [CrossRef]
- NBS—National Bureau of Statistics of China. China Statistical Yearbook; National Bureau of Statistics of China: Beijing, China, 2020. Available online: http://www.stats.gov.cn/tjsj/ndsj/ (accessed on 26 February 2022).
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Kingsbury, B. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Processing Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Sun, D.; Wen, H.; Wang, D.; Xu, J. A random forest model of landslide susceptibility mapping based on hyperparameter optimization using Bayes algorithm. Geomorphology 2020, 362, 107201. [Google Scholar] [CrossRef]
- Tang, Z.; Mei, Z.; Liu, W.; Xia, Y. Identification of the key factors affecting Chinese carbon intensity and their historical trends using random forest algorithm. J. Geogr. Sci. 2020, 30, 743–756. [Google Scholar] [CrossRef]
- Richard, C.D.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by Random Forest. R News 2002, 2, 18–22. Available online: https://www.researchgate.net/publication/228451484 (accessed on 26 February 2022).
- Mostafaei, M.; Javadikia, H.; Naderloo, L. Modeling the effects of ultrasound power and reactor dimension on the biodiesel production yield: Comparison of prediction abilities between response surface methodology (RSM) and adaptive neuro-fuzzy inference system (ANFIS). Energy 2016, 115, 626–636. [Google Scholar] [CrossRef]
- Mathern, A.; Steinholtz, O.S.; Sjöberg, A.; Önnheim, M.; Ek, K.; Rempling, R.; Gustavsson, E.; Jirstrand, M. Multi-objective constrained Bayesian optimization for structural design. Struct. Multidiscip. Optim. 2020, 63, 689–701. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Edward, C.; Nickisch, H. Gaussian Processes for Machine Learning (GPML) Toolbox. J. Mach. Learn. Res. 2010, 11, 3011–3015. [Google Scholar]
- Calandra, R.; Gopalan, N.; Seyfarth, A.; Peters, J.; Deisenroth, M.P. Bayesian Gait Optimization for Bipedal Locomotion, International Conference on Learning and Intelligent Optimization; Springer: Lake Tahoe, NV, USA, 2014; Available online: https://link.springer.com/chapter/10.1007/978-3-319-09584-4_25 (accessed on 26 February 2022).
- Liang, X. Image-based post disaster inspection of reinforced concrete bridge systems using deep learning with Bayesian optimization. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 415–430. [Google Scholar] [CrossRef]
- Zhang, Y.-M.; Wang, H.; Mao, J.-X.; Xu, Z.-D.; Zhang, Y.-F. Probabilistic Framework with Bayesian Optimization for Predicting Typhoon-Induced Dynamic Responses of a Long-Span Bridge. J. Struct. Eng. 2021, 147, 04020297. [Google Scholar] [CrossRef]
- Urminder, S.; Manhoi, H.; Karin, D.; Syrkin, W.E. MetaOmGraph: A workbench for interactive exploratory data analysis of large expression datasets. Nucleic Acids Res. 2020, 48, e23. [Google Scholar]
- Xiao, C.; Ye, J.; Esteves, R.M.; Rong, C. Using Spearman’s correlation coefficients for exploratory data analysis on big dataset. Concurr. Comput. Pract. Exp. 2016, 28, 3866–3878. [Google Scholar] [CrossRef]
- Xu, X.; Ren, Y.; Huang, Q.; Fan, Z.-Y.; Tong, Z.-J.; Chang, W.-J.; Liu, B. Anomaly detection for large span bridges during operational phase using structural health monitoring data. Smart Mater. Struct. 2020, 29, 045029. [Google Scholar] [CrossRef]
- Zhang, Y.-M.; Wang, H.; Wan, H.-P.; Mao, J.-X.; Xu, Y.-C. Anomaly detection of structural health monitoring data using the maximum likelihood estimation-based Bayesian dynamic linear model. Struct. Health Monit. 2020, 20, 2936–2952. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Liu, F.T.; Ting, K.M. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=4781136 (accessed on 26 February 2022).
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-Based Anomaly Detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Ahmed, S.; Lee, Y.; Hyun, S.-H.; Koo, I. Unsupervised Machine Learning-Based Detection of Covert Data Integrity Assault in Smart Grid Networks Utilizing Isolation Forest. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2765–2777. [Google Scholar] [CrossRef]
- Puggini, L.; McLoone, S. An enhanced variable selection and Isolation Forest based methodology for anomaly detection with OES data. Eng. Appl. Artif. Intell. 2018, 67, 126–135. [Google Scholar] [CrossRef] [Green Version]
- Yao, X. Evolving artificial neural networks. Proc. IEEE 1999, 87, 1423–1447. [Google Scholar]
- Ding, S.; Su, C.; Yu, J. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Xiao, Z.; Ye, S.-J.; Zhong, B.; Sun, C.-X. BP neural network with rough set for short term load forecasting. Expert Syst. Appl. 2009, 36, 273–279. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Malfliet, W. The tanh method: A tool for solving certain classes of non-linear PDEs. Math. Methods Appl. Sci. 2005, 28, 2031–2035. [Google Scholar] [CrossRef]
- Liang, F.; Shen, C.; Wu, F. An iterative BP-CNN architecture for channel decoding. IEEE J. Sel. Top. Signal Processing 2018, 12, 144–159. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Oehmcke, S.; Zielinski, O.; Kramer, O. Input quality aware convolutional LSTM networks for virtual marine sensors. Neurocomputing 2018, 275, 2603–2615. [Google Scholar] [CrossRef]
- Ding, L.; Fang, W.; Luo, H.; Love, P.E.D.; Zhong, B.; Ouyang, X. A deep hybrid learning model to detect unsafe behavior: Integrating convolution neural networks and long short-term memory. Autom. Constr. 2018, 86, 118–124. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. Comput. Sci. 2014. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Highway Grade | Highway Traffic Grade | Design Service Life |
|---|---|---|
| High | Expressway, First class highway | 20 years |
| Medium | Second class highway | 15 years |
| Low | Third class highway, Fourth class highway | 10 years |
| Weighted Mark for Overall Technical Condition of Bridges | Bridge Technical Condition Grade Dj | ||||
|---|---|---|---|---|---|
| First Class Bridge | Second Class Bridge | Third Class Bridge | Fourth Class Bridge | Fifth Class Bridge | |
| Dr | (95,100) | (80,95) | (60,80) | (40,60) | (0,40) |
| Extra-Large Bridge | Large Bridge | Medium Bridge | Small Bridge | |
|---|---|---|---|---|
| Full length (m) | (1000,+∞) | (100,1000) | (30,100) | (8,30) |
| Single span (m) | (150,+∞) | (40,150) | (20,40) | (5,20) |
| Highway Grade | Bridge Category | Training Set | Prediction Set |
|---|---|---|---|
| High | Second | 14 | 3 |
| Third | 23 | 5 | |
| Fourth | 54 | 13 | |
| Medium | Second | 5 | 2 |
| Third | 11 | 3 | |
| Fourth | 84 | 21 | |
| Fifth | 27 | 7 | |
| Low | Second | 64 | 16 |
| Third | 30 | 7 | |
| Fourth | 6 | 1 | |
| Fifth | 2 | 1 | |
| Total | 320 | 79 |
| Prediction Model | Mean Absolute Error (Yuan/m2) | Maximum Error (Yuan/m2) | Minimum Error (Yuan/m2) | Root Mean Square Error (Yuan/m2) |
| ANN | 16.8 | 59.4 | 0.2 | 19.7 |
| CNN | 12.5 | 52.6 | 0.3 | 16.7 |
| Regression model | 20.6 | 57.8 | 3.6 | 21.9 |
| Prediction Model | Average Relative Error (%) | Maximum Relative Error (%) | Minimum Relative Error (%) | Mean Absolute Percent Error (%) |
| ANN | 12.05% | 52.71% | 0.28% | 11.89% |
| CNN | 9.45% | 29.83% | 0.24% | 9.35% |
| Regression model | 15.95% | 46.51% | 3.15% | 15.22% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Yao, C.; Zhao, S.; Zhao, S.; Li, Y. A Comparative Study of a Fully-Connected Artificial Neural Network and a Convolutional Neural Network in Predicting Bridge Maintenance Costs. Appl. Sci. 2022, 12, 3595. https://doi.org/10.3390/app12073595
Wang C, Yao C, Zhao S, Zhao S, Li Y. A Comparative Study of a Fully-Connected Artificial Neural Network and a Convolutional Neural Network in Predicting Bridge Maintenance Costs. Applied Sciences. 2022; 12(7):3595. https://doi.org/10.3390/app12073595
Chicago/Turabian StyleWang, Chongjiao, Changrong Yao, Siguang Zhao, Shida Zhao, and Yadong Li. 2022. "A Comparative Study of a Fully-Connected Artificial Neural Network and a Convolutional Neural Network in Predicting Bridge Maintenance Costs" Applied Sciences 12, no. 7: 3595. https://doi.org/10.3390/app12073595
APA StyleWang, C., Yao, C., Zhao, S., Zhao, S., & Li, Y. (2022). A Comparative Study of a Fully-Connected Artificial Neural Network and a Convolutional Neural Network in Predicting Bridge Maintenance Costs. Applied Sciences, 12(7), 3595. https://doi.org/10.3390/app12073595