
MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media



 , and
, and
Abstract
:1. Introduction
2. Related Work
2.1. ML Approaches
2.2. Lexical Approaches
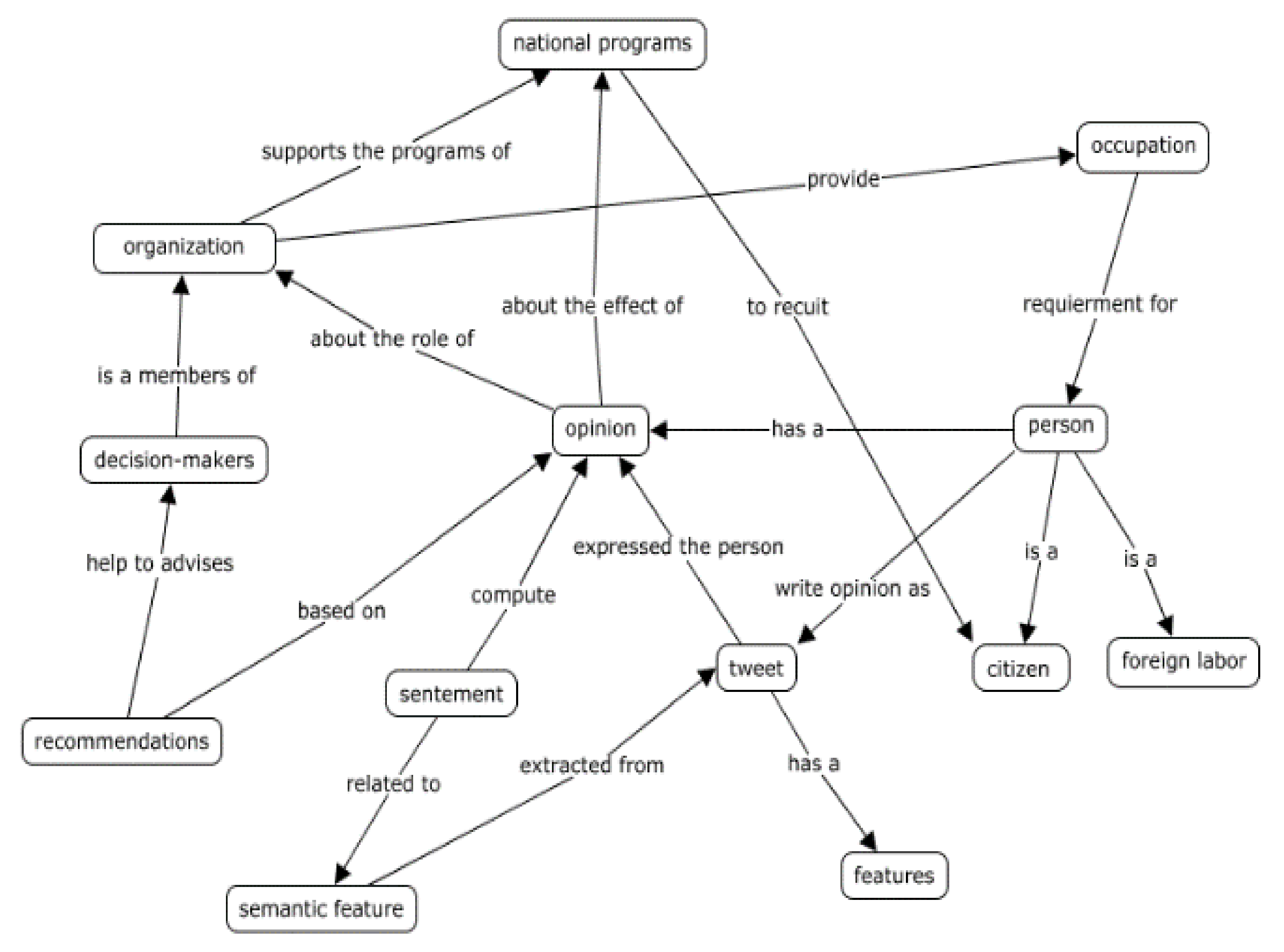
3. Multifactor Lexical Dialectical Arabic Sentiment Analysis (MULDASA)
3.1. Building Sentiment Analysis Corpus
3.2. Domain Analysis and Feature Extraction
3.3. Construction of Arabic Sentiment LX
- POS (P): sentiment score (SC) (intensity) = 0.5
- NEG (N): sentiment SC (intensity) = −0.5
- Very POS (VP): sentiment SC (intensity) = 1.0
- Very NEG (VN): sentiment SC (intensity) = −1.0
3.4. Feature–Sentiment Association
3.5. Computing Sentiment SC
| Algorithm 1: TT SC Calculation |
| Let TT = tweet; LX = lexicons; SC = sentiment score; W = word 1. Inputs: TT, LXs 2. Output: Sentiment SC 3. Set SC←0 4. W←Tokenize(TT) 5. FOR EACH W in words DO 6. IF W in POS-LX THEN 7. SC←SC + 0.5 8. ELS IF W in VeryPos-LX THEN 9. SC←SC + 1.0 10. ELSE IF W in NEG-LX THEN 11. SC←SC − 0.5 12. ELS IF W in VeryNeg-LX THEN 13. SC←SC − 1.0 14. Label←Classify-TT(SC) 15. RETURN SC and Label (VN, N, P, VP) |
3.6. Strategies to Enhance the Basic Sentiment Analysis Approach
3.6.1. Negations
| Algorithm 2: TT-SC Computation with Negation |
| 1. Inputs: TT, LX 2. Output: Sentiment SC 3. Initialize SC←0 4. window_list←generate-Window(TT, 1)//generate a window with size 1 5. FOR EACH previous_W, W in window_list DO 6. IF W in POS-LX AND previous_W in negation_list THEN 7. SC←SC − 0.5 8. ELS IF W in VeryPos-LX AND previous_W in negation_list THEN 9. SC←SC − 1.0 10. ELSE IF W in NEG-LX AND previous_W in negation_list THEN 11. SC←SC + 0.5 12. ELS IF W in VeryNeg-LX AND previous_W in negation_list THEN 13. SC←SC + 1.0 Label←Classify-TT(SC) 14. RETURN SC and Label (VN, N, P, VP) |
3.6.2. Determining Sentiment Intensity
| Algorithm 3: TT-SC Computation with Intensification |
| 1. Inputs: A TT, LX 2. Output: Sentiment SC 3. Initialize SC←0 4. window_list←generate-Window(TT, 2)//generate a window with size 2 5. FOR EACH previous_w, w, next_w in window_list DO 6. IF w is POS-LX THEN 7. SC←SC + 0.5 8. IF previous_w in intensification_list OR next_w in intensification_list THEN 9. SC←SC + 0.5 10. ELSIF w in VeryPos-LX THEN 11. SC←SC + 1.0 12. IF previous_w in intensification_list OR next_w in intensification_list THEN 13. SC ← SC + 0.5 14. ELSEIF w is NEG-LX THEN 15. SC←SC − 0.5 16. IF previous_w in intensification_list OR next_w in intensification_list THEN 17. SC←SC − 0.5 18. ELSIF w is VeryNeg-LX THEN 19. SC←SC − 1.0 20. IF previous_w in intensification_list OR next_w in intensification_list THEN 21. SC←SC − 0.5 22. Label←Classify-TT(SC) 23. RETURN SC and Label (VN, N, P, VP) |
3.6.3. Emoji
3.6.4. Considering Special Linguistic Phrases Affecting Sentiments
- Supplications
- b.
- Proverbs
- c.
- Interjections
4. Results and Discussion
4.1. Analysis of Experimental Findings
4.2. Evaluation against Similar Work on Dialectal ASA
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Beltagy, S.R.; Khalil, T.; Halaby, A.; Hammad, M. Combining lexical features and a supervised learning approach for Arabic sentiment analysis. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Konya, Turkey, 3–9 April 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Albogamy, F.; Ramsay, A. POS tagging for Arabic tweets. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 7–9 September 2015. [Google Scholar]
- Govindarajan, M. Approaches and Applications for Sentiment Analysis: A Literature Review. In Data Mining Approaches for Big Data and Sentiment Analysis in Social Media; IGI: New York, NY, USA, 2022; pp. 1–23. [Google Scholar]
- Duwairi, R.M.; Qarqaz, I. A framework for Arabic sentiment analysis using supervised classification. Int. J. Data Min. Model. Manag. 2016, 8, 369–381. [Google Scholar]
- Mehmood, M.; Ayub, E.; Ahmad, F.; Alruwaili, M.; Alrowaili, Z.A.; Alanazi, S.; Rizwan, M.H.; Naseem, S.; Alyas, T. Machine learning enabled early detection of breast cancer by structural analysis of mammograms. Comput. Mater. Contin. 2021, 67, 641–657. [Google Scholar] [CrossRef]
- Gouda, W.; Almurafeh, M.; Humayun, M.; Jhanjhi, N.Z. Detection of COVID-19 Based on Chest X-rays Using Deep Learning. Healthcare 2022, 10, 343. [Google Scholar] [CrossRef] [PubMed]
- Al Shamsi, A.A.; Abdallah, S. Text mining techniques for sentiment analysis of Arabic dialects: Literature review. Adv. Sci. Technol. Eng. Syst. J. 2021, 6, 1012–1023. [Google Scholar] [CrossRef]
- Abd-Elhamid, L.; Elzanfaly, D.; Eldin, A.S. Feature-based sentiment analysis in online Arabic reviews. In Proceedings of the 2016 11th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 20–21 December 2016. [Google Scholar]
- Mataoui, M.H.; Zelmati, O.; Boumechache, M. A proposed lexicon-based sentiment analysis approach for the vernacular Algerian Arabic. Res. Comput. Sci. 2016, 110, 55–70. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; Alsalman, A.; Al-Ohali, Y. Sentiment analysis of arabic tweets: Feature engineering and a hybrid approach. arXiv 2018, arXiv:1805.08533. [Google Scholar]
- Ahmed, A.; Ali, N.; Alzubaidi, M.; Zaghouani, W.; Abd-alrazaq, A.A.; Househ, M. Freely Available Arabic Corpora: A Scoping Review. Comput. Methods Programs Biomed. 2022, 2, 100049. [Google Scholar] [CrossRef]
- Al-Harbi, W.A.; Emam, A. Effect of Saudi dialect pre-processing on Arabic sentiment analysis. Int. J. Adv. Comput. Technol. 2015, 4, 91–99. [Google Scholar]
- Al-Thubaity, A.; Alharbi, M.; Alqahtani, S.; Aljandal, A. A Saudi dialect Twitter Corpus for sentiment and emotion analysis. In Proceedings of the 2018 21st Saudi computer society national computer conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018. [Google Scholar]
- Assiri, A.; Emam, A.; Al-Dossari, H. Towards enhancement of a lexicon-based approach for Saudi dialect sentiment analysis. J. Inf. Sci. 2018, 44, 184–202. [Google Scholar] [CrossRef]
- Alahmary, R.M.; Al-Dossari, H.Z.; Emam, A.Z. Sentiment analysis of Saudi dialect using deep learning techniques. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019. [Google Scholar]
- Alwakid, G.; Osman, T.; Hughes-Roberts, T. Challenges in sentiment analysis for Arabic social networks. Procedia Comput. Sci. 2017, 117, 89–100. [Google Scholar] [CrossRef]
- Azmi, A.M.; Alzanin, S.M. Aara’—A system for mining the polarity of Saudi public opinion through e-newspaper comments. J. Inf. Sci. 2014, 40, 398–410. [Google Scholar] [CrossRef]
- Itani, M.; Roast, C.; Al-Khayatt, S. Corpora for sentiment analysis of Arabic text in social media. In Proceedings of the 2017 8th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 4–6 April 2017. [Google Scholar]
- AlSalman, H. An improved approach for sentiment analysis of arabic tweets in twitter social media. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020. [Google Scholar]
- Atoum, J.O.; Nouman, M. Sentiment analysis of Arabic jordanian dialect tweets. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Hasan, A.A.; Fong, A.C. Sentiment analysis based fuzzy decision platform for the Saudi stock market. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018. [Google Scholar]
- Al-Twairesh, N.; Al-Khalifa, H.; Al-Salman, A.; Al-Ohali, Y. Arasenti-tweet: A corpus for arabic sentiment analysis of saudi tweets. Procedia Comput. Sci. 2017, 117, 63–72. [Google Scholar] [CrossRef]
- Al-Moslmi, T.; Albared, M.; Al-Shabi, A.; Omar, N.; Abdullah, S. Arabic senti-lexicon: Constructing publicly available language resources for Arabic sentiment analysis. J. Inf. Sci. 2018, 44, 345–362. [Google Scholar] [CrossRef]
- Aloqaily, A.; Al-Hassan, M.; Salah, K.; Elshqeirat, B.; Almashagbah, M. Sentiment analysis for arabic tweets datasets: Lexicon-based and machine learning approaches. J. Theor. Appl. Inf. Technol. 2020, 98, 612–623. [Google Scholar]
- Pak, A.; Paroubek, P. Twitter as a corpus for sentiment analysis and opinion mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 19–21 May 2010. [Google Scholar]
- Alwakid, G.; Osman, T.; Hughes-Roberts, T. Towards improved saudi dialectal Arabic stemming. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019. [Google Scholar]
- Khalil, H.; Osman, T. Challenges in information retrieval from unstructured arabic data. In Proceedings of the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Carletta, J. Assessing agreement on classification tasks: The kappa statistic. arXiv 1996, arXiv:cmp-lg/9602004. [Google Scholar]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2018, 26, 522–531. [Google Scholar] [CrossRef]
- Ibrahim, H.S.; Abdou, S.M.; Gheith, M. Sentiment analysis for modern standard Arabic and colloquial. arXiv 2015, arXiv:1505.03105. [Google Scholar] [CrossRef]
- Duwairi, R.M.; Alshboul, M.A. Negation-aware framework for sentiment analysis in Arabic reviews. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015. [Google Scholar]
- Hamouda, A.; El-taher, F.E.-Z. Sentiment analyzer for arabic comments system. Int. J. Adv. Comput. Sci. Appl. 2013, 99–104. [Google Scholar]
- Badaro, G.; Baly, R.; Hajj, H.; El-Hajj, W.; Shaban, K.B.; Habash, N.; Al-Sallab, A.; Hamdi, A. A survey of opinion mining in Arabic: A comprehensive system perspective covering challenges and advances in tools, resources, models, applications, and visualizations. ACM Trans. Asian Low-Resour. Lang. Inf. Processing 2019, 18, 1–52. [Google Scholar] [CrossRef] [Green Version]
- De Marneffe, M.-C.; Manning, C.D.; Potts, C. “Was it good? It was provocative”. Learning the meaning of scalar adjectives. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 11–16 July 2010. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. arXiv 2017, arXiv:1708.00524. [Google Scholar]
- Abdellaoui, H.; Zrigui, M. Using tweets and emojis to build tead: An Arabic dataset for sentiment analysis. Comput. Sist. 2018, 22, 777–786. [Google Scholar] [CrossRef]
- Al-Azani, S.; El-Alfy, E.-S.M. Combining emojis with Arabic textual features for sentiment classification. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018. [Google Scholar]
- Kralj Novak, P.; Smailović, J.; Sluban, B.; Mozetič, I. Sentiment of emojis. PLoS ONE 2015, 10, e0144296. [Google Scholar] [CrossRef] [PubMed]
- Mohammad, S. A practical guide to sentiment annotation: Challenges and solutions. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, San Diego, CA, USA, 16 June 2016. [Google Scholar]
- Shamsudin, N.F.; Basiron, H.; Sa’aya, Z. Lexical based sentiment analysis-Verb, adverb & negation. J. Telecommun. Electron. Comput. Eng. JTEC 2016, 8, 161–166. [Google Scholar]
- الكلم الطيب-موسوعة الفوائد والحكم والأدعية والأذكار والأقوال المأثورة. Available online: Kalemtayeb.com (accessed on 13 July 2019).
- Ibrahim, H.S.; Abdou, S.M.; Gheith, M. Idioms-proverbs lexicon for modern standard Arabic and colloquial sentiment analysis. arXiv 2015, arXiv:1506.01906. [Google Scholar]
- Ortigosa, A.; Martín, J.M.; Carro, R.M. Sentiment analysis in Facebook and its application to e-learning. Comput. Hum. Behav. 2014, 31, 527–541. [Google Scholar] [CrossRef]
- Khalil, M.I.; Tehsin, S.; Humayun, M.; Jhanjhi, N.Z.; AlZain, M.A. Multi-Scale Network for Thoracic Organs Segmentation. Comput. Mater. Contin. 2022, 70, 3251–3265. [Google Scholar] [CrossRef]
- Aldayel, H.K.; Azmi, A.M. Arabic tweets sentiment analysis—A hybrid scheme. J. Inf. Sci. 2016, 42, 782–797. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Acronyms | Used for |
|---|---|
| Tweets | TTs |
| ASA | Arabic sentiment analysis |
| SVM | Support vector machine |
| MULDASA | Multifactorial lexical sentiment analysis algorithm |
| MSA | Modern standard Arabic |
| NB | Naïve Bayes |
| DA | Dialectical Arabic |
| ML | Machine language |
| IAA | Interannotator agreement |
| DT | decision trees |
| NB | naïve Bayes |
| KNN | k-nearest neighbors |
| DMNB | Discriminative multinomial naïve Bayes |
| BOW | Bag-of-words |
| POS | Positive |
| NEG | Negative |
| ML | Machine learning |
| LX | Lexicons |
| Dataset | NEG TTs | POS TTs |
|---|---|---|
| Total TTs | 4996 | 2004 |
| Total words | 33,945 | 16,383 |
| Average word count per TT (tokens) | 10.03 | 7.56 |
| Character count per TT | 39.97 | 58.89 |
| Basic Term | Synonym Suite | Dialect | ||
|---|---|---|---|---|
| Word | Polarity | Word | Polarity | |
| جيد Good +0.5 | حلو رائع | +0.5 +1 | زين روعه | +0.5 +0.5 |
| سيئ Bad −0.5 | رديء قبيح | −1 −0.5 |
شين تعيس | −0.5 −1 |
| (i) Original TT | تعبنا من الانتظار و الواسطات الكثيره خربت علينا .. أستمتعوا بجمال الجو هالفتره |
| Translation in English | “We were harmed by nepotism. Fraud is obvious to the selection; therefore, it’s best to go to sleep.” |
| (ii) Stemmed TT | تعب من انتظار و واسطه كثيرخرب علينا استمتع جمال جو فتره |
| (iii) Feature–sentiment association |  |
| English | Arabic |
|---|---|
| Very | جدا/وافر/كثير/واجد/وايد/عديد |
| Absolutely | طبعاً/من قلب/واضح/أكيد |
| Extremely | مره/بزياده/حيل |
| TTs | Translation in English |
|---|---|
| حددوا ماهي مسببات رفضكم أعداد مره كثيره من المتقدمين للوظيفه | Which are the reasons for rejecting a lot of applicants? |
| عيال ديرتنا حيل فازعين لعمل الخير | Residents have a strong desire to do excellent. |
| Label | Emoji | Label | Emoji |
|---|---|---|---|
| VP |  | N |  |
| P |  | VN |  |
| TT | هالفرصه ياعيال الوطن و شبابه لا تفوتونها   خلك على علم بالسعوده الرهيبه واغتنم الفرص لتسمو بوطنك و تعرف على حقك كمواطن☝ خلك على علم بالسعوده الرهيبه واغتنم الفرص لتسمو بوطنك و تعرف على حقك كمواطن☝ |
| Translation in English | Gain knowledge about the great Saudi scheme and avail benefit of the opportunity to promote your country and have a better understanding of your privileges This is a fantastic offer. Don’t be hesitant. This is a fantastic offer. Don’t be hesitant. |
| Annotation | POS TT by all annotators |
| Emoji |  |
| TT | يارب السعاده والتوفيق و البشارات التي تسر و سخر لنا الناس الصالحه الذين يتفانون لايجاد الحلول لمشاكلنا و نجد وظائف |
| Translation | Oh God, bring us joy, unify us, grant us positive news, and let honest individuals strive hard to fix our issues by hiring us. |
| Annotation | POS-TT by 2 annotators and a NEG-TT by 1 annotator |
| Source | Individual expression |
| Distinct phrases | يا رب السعاده/التوفيق/البشارات/سخر لنا الناس الصالحه Ya rab alsaada/altawfik/albasharat/sakhar lana alnas alsaliha |
| TT | الله يزيل كل المعوقات .. الين متى و حنا مالنا قيمه؟ ? |
| Translation | Oh God, removes all obstacles until when we are devalued? |
| Annotation | NEG-TTs by all annotators |
| Source | Individual expression |
| Distinct phrases | الله يبهدلهم |
| POS Sentiment Supplication | NEG Sentiment Supplication |
|---|---|
| الله يوفقك god help you | حسبي الله و نعم الوكيل God is my suffice and the best deputy |
| بارك الله فيك god bless you | أعوذ بالله I seek refuge in God |
| POS Sentiment Proverbs | Translation in English | NEG Sentiment Proverbs | Translation in English |
|---|---|---|---|
| من صبر نال | Person who is patient will be the winner | لامن شاف و لا من درى | Uncensored |
| TT | تعبت من الكلام ولا حياه لمن تنادي |
| Translation in English | We’re fed up with begging and shouting for help, but nobody seems to care. |
| Annotation | NEG-TTs by all annotators |
| Distinct phrases | ولا حياه لمن تنادي wala hiah liman tanadi |
| TT | ما اسباب عدم الاكتراث لمطالبنا و هي نفسها منذ سنوات. . إلى متى ؟ ؟ |
| Translation in English | What reasons of ignoring us? We’ve been requesting these for years. How long do you think it will take? |
| Annotation | NEG-TTs by all annotators |
| Distinct phrases | إلى متى/؟. |
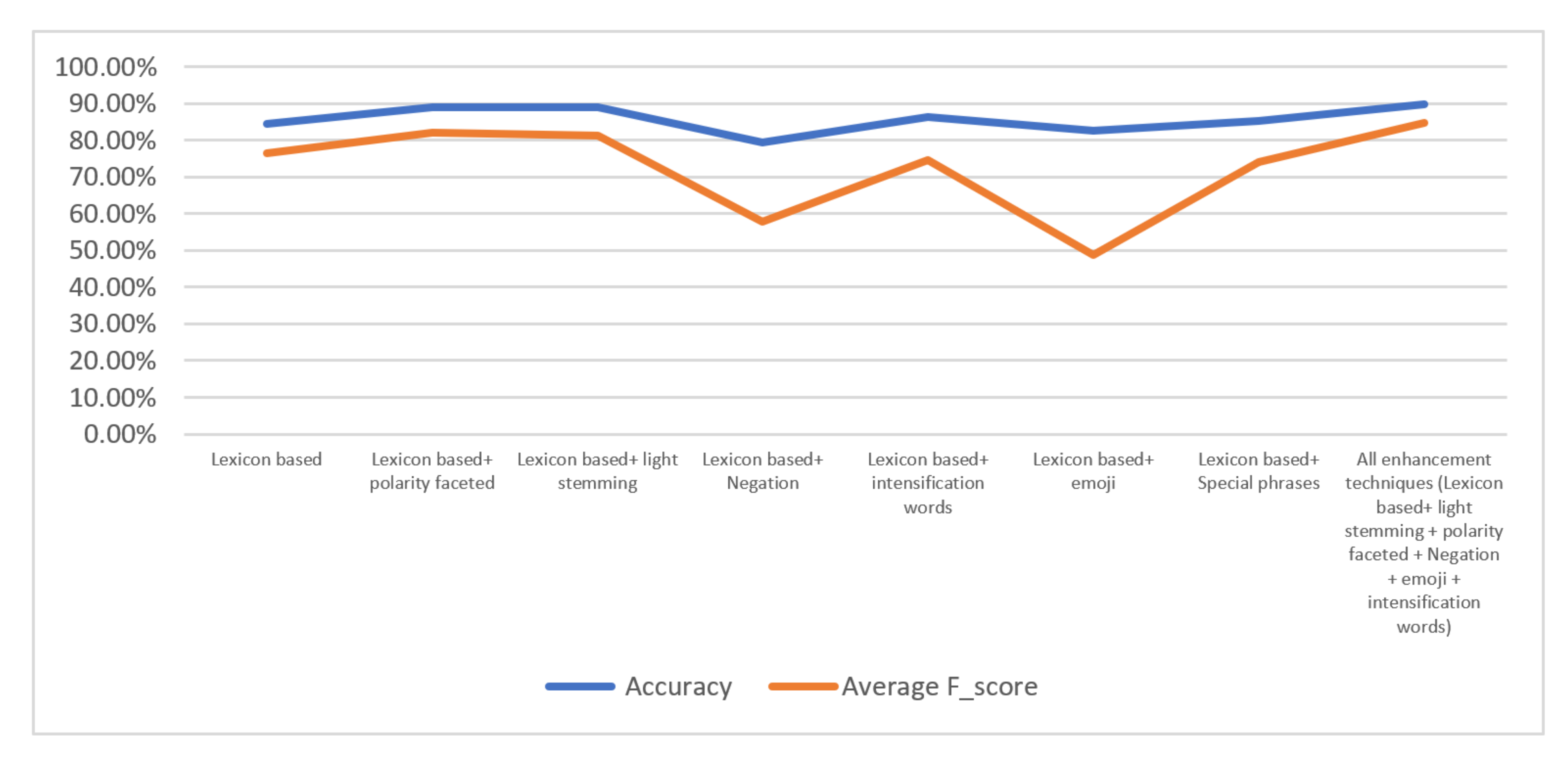
| Method | Average Accuracy | Average F-SC |
|---|---|---|
| LX-based | 84.34% | 76.47% |
| LX-based + polarity | 88.94% | 82.14% |
| LX-based + light stemming | 88.99% | 81.16% |
| LX-based + negation | 79.53% | 57.70% |
| LX-based + intensification words | 86.37% | 77.53% |
| LX-based + emoji | 82.63% | 48.70% |
| LX-based + special phrases | 85.39% | 76.99% |
| All improvement strategies (LX-based + light stemming + polarity + negation + emoji + intensification words) | 89.80% | 86.32% |
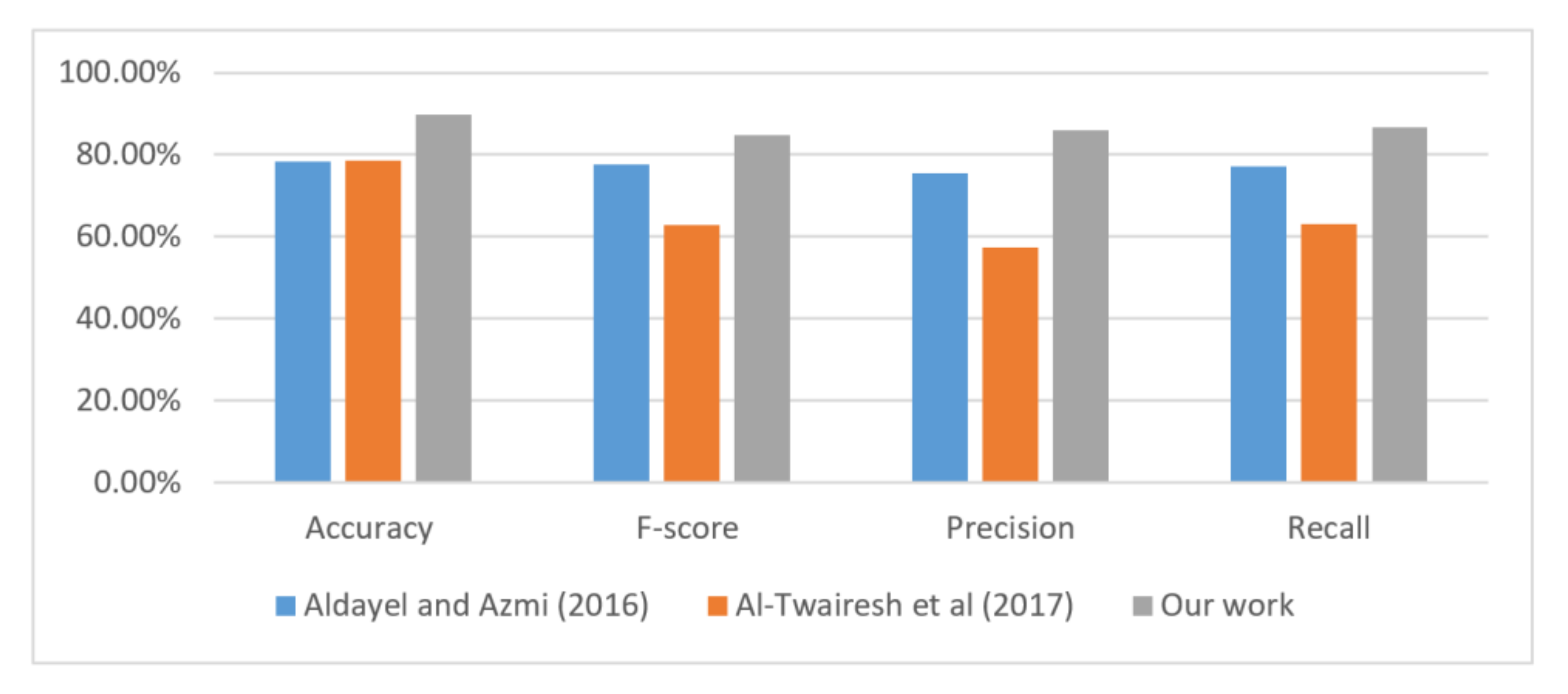
| Research | Corpus | Domain | Accuracy | F-SC | Precision | Recall |
|---|---|---|---|---|---|---|
| Aldayel [46] | 1103 TTs | Multidomain (social issues) | 78.22% | 77.64% | 75.49 | 77.02 |
| Al-Twairesh [22] | 4700 TTs | Multidomain | 78.61% | 62.94% | 57.30 | 63.17 |
| MULDASA | 7000 TTs | Specific domain (unemployment) | 89.80% | 84.70% | 86% | 86.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwakid, G.; Osman, T.; Haj, M.E.; Alanazi, S.; Humayun, M.; Sama, N.U. MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media. Appl. Sci. 2022, 12, 3806. https://doi.org/10.3390/app12083806
Alwakid G, Osman T, Haj ME, Alanazi S, Humayun M, Sama NU. MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media. Applied Sciences. 2022; 12(8):3806. https://doi.org/10.3390/app12083806
Chicago/Turabian StyleAlwakid, Ghadah, Taha Osman, Mahmoud El Haj, Saad Alanazi, Mamoona Humayun, and Najm Us Sama. 2022. "MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media" Applied Sciences 12, no. 8: 3806. https://doi.org/10.3390/app12083806
APA StyleAlwakid, G., Osman, T., Haj, M. E., Alanazi, S., Humayun, M., & Sama, N. U. (2022). MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media. Applied Sciences, 12(8), 3806. https://doi.org/10.3390/app12083806