
BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network




Abstract
:1. Introduction
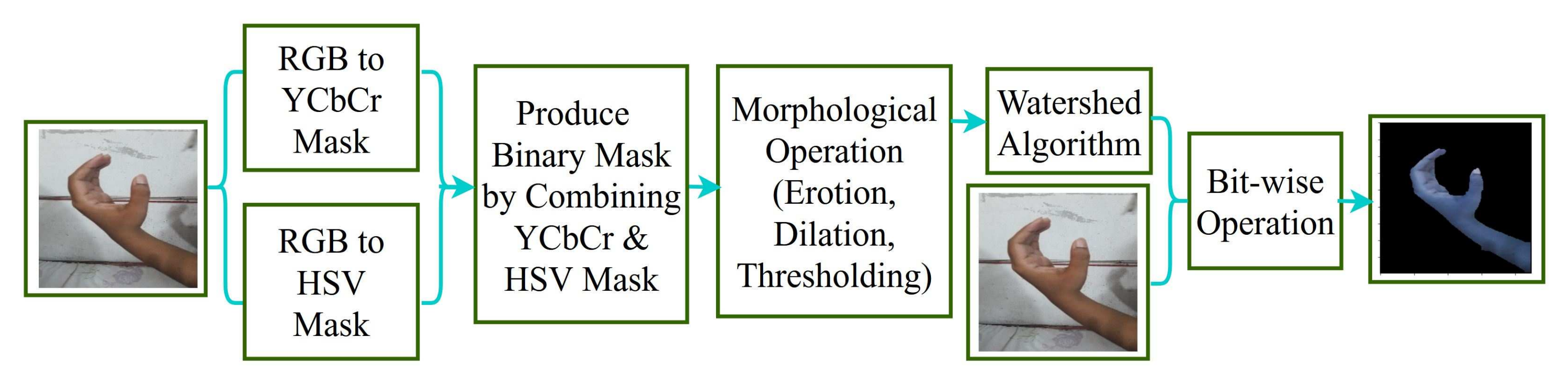
- We proposed concatenated segmentation techniques to solve light illumination, uncontrolled environment and background noise. Segmentation techniques consist of YCbCr, HSV, morphology and watershed algorithms.
- We used seven augmentation approaches to generate diverse sign images such as rotated, translated, scaled, flipped from the input image in order to enlarge the dataset, deal with inefficient deep learning model training and keep the model image diversity invariant.
- Finally, we developed a modified robust CNN architecture after adjusting hyperparameters called BenSignNet to increase the generalization property of the system. This makes its image diversity invariant and produces a good performance for diverse BSL datasets such as 38 BdSL, KU-BdSL, and Ishara-Lipi datasets. Based on our knowledge, the proposed BenSignNet is more effective and efficient than the previously reported BSL system. After that, proposed model could be used for rapidly detecting BSL for Bengali DHH community.
2. Related Work
2.1. Literary Review on Bengali Sign Language (BSL)
2.2. Literary Review on Others Sign Language
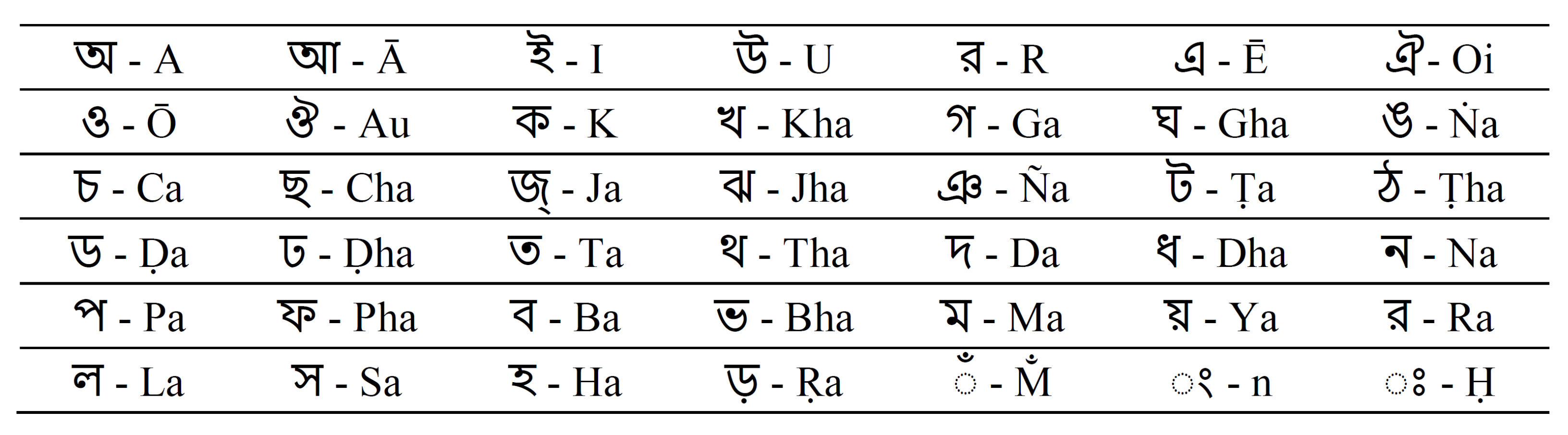
3. Dataset Description
3.1. 38 BdSL Dataset
3.2. KU-BdSL
3.3. Ishara-Lipi Dataset
4. Proposed System
- i
- Input images are resized to 124 × 124 from the original images, and, therefore, the images are divided into training and test datasets
- ii
- Concatenate segmentation technique applied to remove redundant background.
- iii
- The augmentation technique was applied to the training dataset to increase the size of the dataset without changing the semantic meaning.
- iv
- A novel BenSignNet model is proposed for feature extraction and classification. This model is evaluated with the three datasets mentioned above.
4.1. Segmentation
4.1.1. Binary Mask from YCbCr and HSV
4.1.2. Morphological Operation
4.1.3. Watershed Algorithm
4.2. Augmentation Techniques
4.3. Feature Extraction and Classification Techniques
4.3.1. Basic Concepts of Convolutional Neural Network (CNN)
Convolutional Layer
Pooling Layer
Overfitting and Underfitting Control Layers
Activation and Loss Function
Output Layer
4.3.2. BenSignNet: The Proposed CNN Architecture
5. Result and Discussion
5.1. Experimental Setup
5.2. Evaluation Metrics
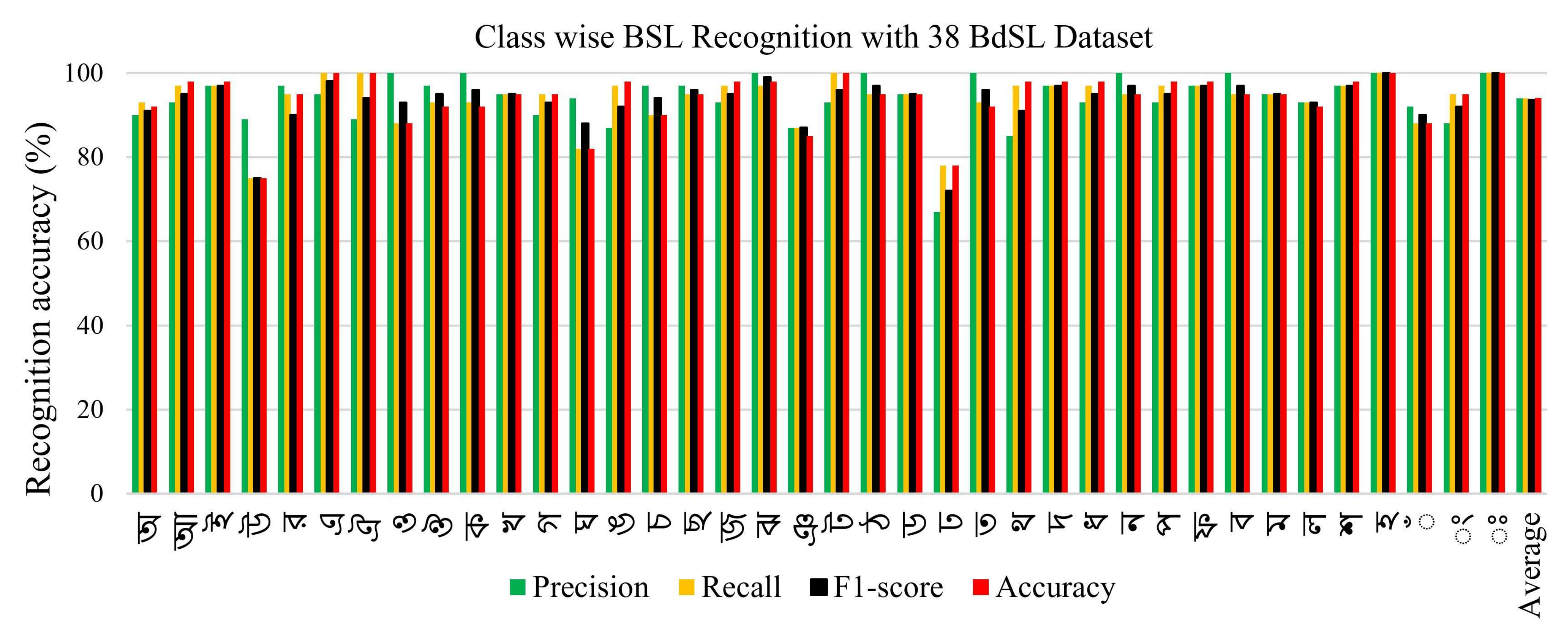
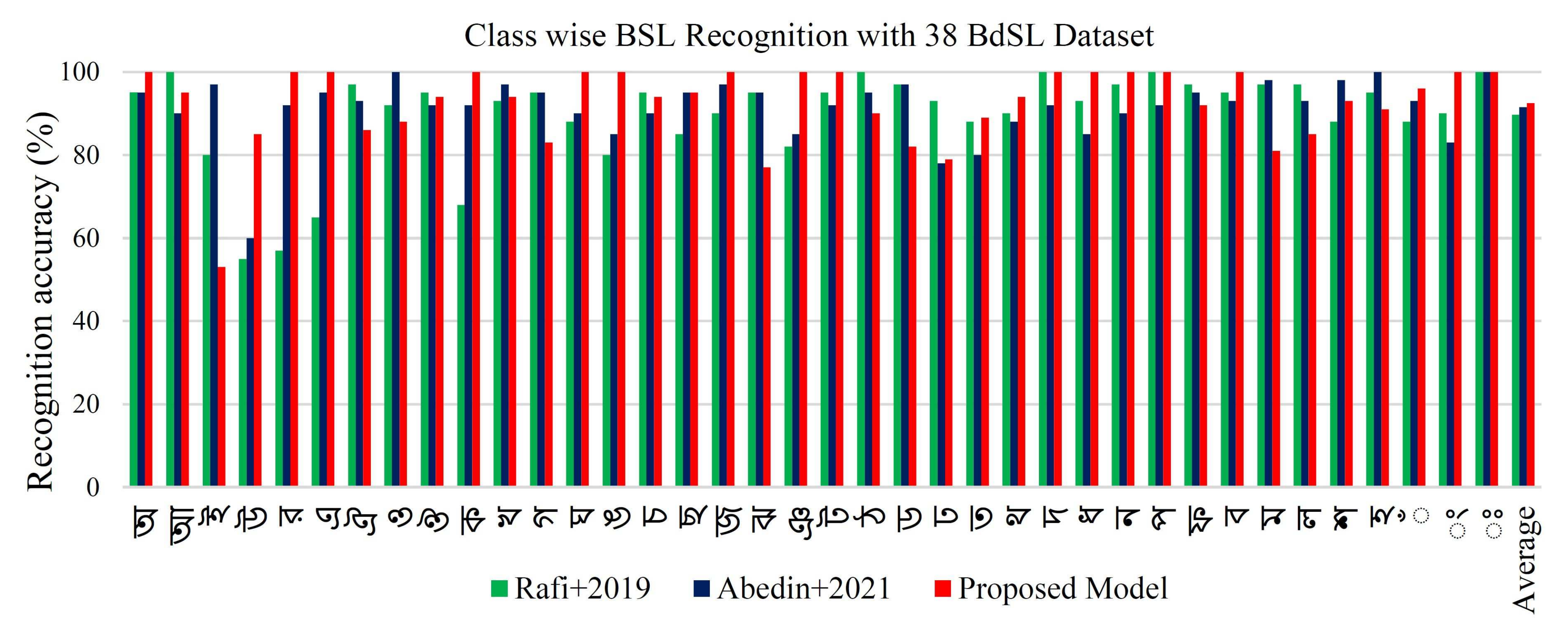
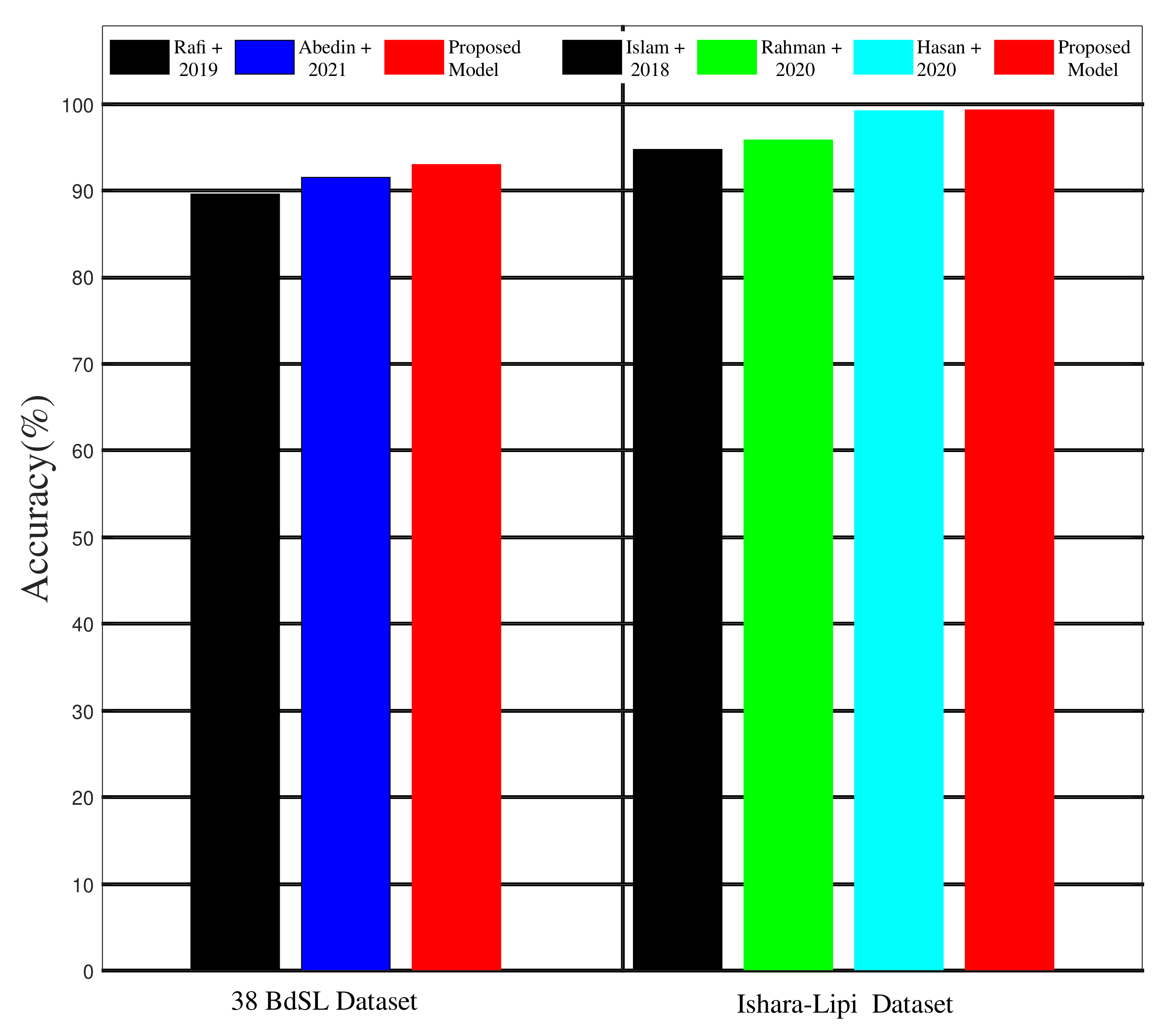
5.3. Performance Evaluation with 38 BdSL Dataset
5.4. Performance Evaluation with KU-BdSL Dataset
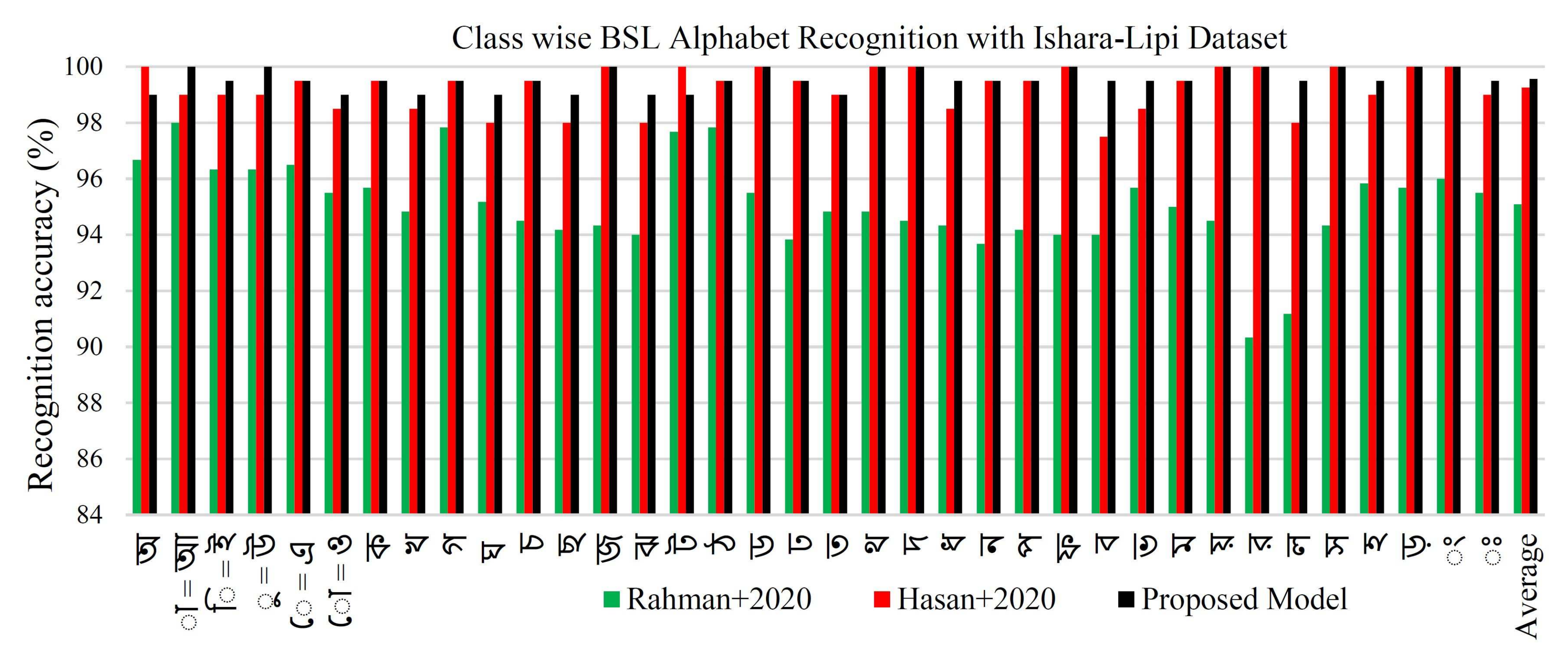
5.5. Performance Evaluation with Ishara-Lipi Dataset
5.6. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2019, 10, 131–153. [Google Scholar] [CrossRef]
- Murray, J.; Snoddon, K.; Meulder, M.; Underwood, K. Intersectional inclusion for deaf learners: Moving beyond General Comment No. 4 on Article 24 of the United Nations Convention on the Rights of Persons with Disabilities. Int. J. Incl. Educ. 2018, 24, 691–705. [Google Scholar] [CrossRef]
- Tarafder, K.; Akhtar, N.; Zaman, M.; Rasel, M.; Bhuiyan, M.R.; Datta, P. Disabling hearing impairment in the Bangladeshi population. J. Laryngol. Otol. 2015, 129, 126–135. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Li, Z.; Liu, H.; Cao, T.; Liu, S. Data-driven Online Learning Engagement Detection via Facial Expression and Mouse Behavior Recognition Technology. J. Educ. Comput. Res. 2020, 58, 63–86. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Li, Y.F.; Chen, Z.; Zhang, Z.; Liu, S. Flexible FTIR Spectral Imaging Enhancement for Industrial Robot Infrared Vision Sensing. IEEE Trans. Ind. Inform. 2020, 16, 544–554. [Google Scholar] [CrossRef]
- Rajan, R.G.; Leo, M.J. American sign language alphabets recognition using hand crafted and deep learning features. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, Tamilnadu, 26–28 February 2020; pp. 430–434. [Google Scholar]
- Kudrinko, K.; Flavin, E.; Zhu, X.; Li, Q. Wearable sensor-based sign language recognition: A comprehensive review. IEEE Rev. Biomed. Eng. 2020, 14, 82–97. [Google Scholar] [CrossRef]
- Sharma, S.; Singh, S. Vision-based sign language recognition system: A Comprehensive Review. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, Tamilnadu, 26–28 February 2020; pp. 140–144. [Google Scholar]
- Podder, K.K.; Chowdhury, M.E.H.; Tahir, A.M.; Mahbub, Z.B.; Khandakar, A.; Hossain, M.S.; Kadir, M.A. Bangla Sign Language (BdSL) Alphabets and Numerals Classification Using a Deep Learning Model. Sensors 2022, 22, 574. [Google Scholar] [CrossRef]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Rehman, A.; Nobanee, H.; Shabir, H. Improved Deep Convolutional Neural Network to Classify Osteoarthritis from Anterior Cruciate Ligament Tear Using Magnetic Resonance Imaging. J. Pers. Med. 2021, 11, 1163. [Google Scholar] [CrossRef]
- Rafi, A.M.; Nawal, N.; Bayev, N.S.; Nima, L.; Shahnaz, C.; Fattah, S.A. Image-based bengali sign language alphabet recognition for deaf and dumb community. In Proceedings of the 2019 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, 17–20 October 2019; pp. 1–7. [Google Scholar]
- Jim, A.M.J.; Rafi, I.; AKON, M.Z.; Nahid, A.A. KU-BdSL: Khulna University Bengali Sign Language Dataset. Mendeley Data. Version 1. 2021. Available online: https://data.mendeley.com/datasets/scpvm2nbkm/1 (accessed on 8 February 2022). [CrossRef]
- Islam, M.S.; Mousumi, S.S.S.; Jessan, N.A.; Rabby, A.S.A.; Hossain, S.A. Ishara-lipi: The first complete multipurposeopen access dataset of isolated characters for bangla sign language. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- Hoque, M.T.; Rifat-Ut-Tauwab, M.; Kabir, M.F.; Sarker, F.; Huda, M.N.; Abdullah-Al-Mamun, K. Automated Bangla sign language translation system: Prospects, limitations and applications. In Proceedings of the 2016 5th International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; pp. 856–862. [Google Scholar]
- Islalm, M.S.; Rahman, M.M.; Rahman, M.H.; Arifuzzaman, M.; Sassi, R.; Aktaruzzaman, M. Recognition Bangla Sign Language using Convolutional Neural Network. In Proceedings of the 2019 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 22–23 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y.F. ARHPE: Asymmetric Relation-aware Representation Learning for Head Pose Estimation in Industrial Human-machine Interaction. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Xiong, N.N. Learning Knowledge Graph Embedding With Heterogeneous Relation Attention Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inform. 2021. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Zhang, Z.; Lin, K.; Shen, X.; Xiong, N.N.; Wang, J. Multi-perspective social recommendation method with graph representation learning. Neurocomputing 2022, 468, 469–481. [Google Scholar] [CrossRef]
- Kaushik Deb, D.; Khan, M.I.; Mony, H.P.; Chowdhury, S. Two-handed sign language recognition for bangla character using normalized cross correlation. Glob. J. Comput. Sci. Technol. 2012, 12, 1–7. [Google Scholar]
- Karmokar, B.C.; Alam, K.M.R.; Siddiquee, M.K. Bangladeshi sign language recognition employing neural network ensemble. Int. J. Comput. Appl. 2012, 58, 43–46. [Google Scholar]
- Rahaman, M.A.; Jasim, M.; Ali, M.H.; Hasanuzzaman, M. Real-time computer vision-based Bengali sign language recognition. In Proceedings of the 2014 17th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–23 December 2014; pp. 192–197. [Google Scholar]
- Rahaman, M.A.; Jasim, M.; Ali, M.H.; Hasanuzzaman, M. Computer vision based bengali sign words recognition using contour analysis. In Proceedings of the 2015 18th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2015; pp. 335–340. [Google Scholar]
- Uddin, M.A.; Chowdhury, S.A. Hand sign language recognition for bangla alphabet using support vector machine. In Proceedings of the 2016 International Conference on Innovations in Science, Engineering and Technology (ICISET), Dhaka, Bangladesh, 28–29 October 2016; pp. 1–4. [Google Scholar]
- Yasir, F.; Prasad, P.W.C.; Alsadoon, A.; Elchouemi, A.; Sreedharan, S. Bangla Sign Language recognition using convolutional neural network. In Proceedings of the 2017 International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT), Kannur, India, 6–7 July 2017; pp. 49–53. [Google Scholar]
- Hoque, O.B.; Jubair, M.I.; Islam, M.S.; Akash, A.F.; Paulson, A.S. Real time bangladeshi sign language detection using faster r-cnn. In Proceedings of the 2018 International Conference on Innovation in Engineering and Technology (ICIET), Dhaka, Bangladesh, 27–28 December 2018; pp. 1–6. [Google Scholar]
- Islam, M.S.; Sultana Sharmin, S.; Jessan, N.; Rabby, A.S.A.; Abujar, S.; Hossain, S. Ishara-Bochon: The First Multipurpose Open Access Dataset for Bangla Sign Language Isolated Digits. In Recent Trends in Image Processing and Pattern Recognition, Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition, Solapur, India, 21–22 December 2019; Springer: Singapore, 2019. [Google Scholar]
- Rahaman, M.A.; Jasim, M.; Ali, M.; Hasanuzzaman, M. Bangla language modeling algorithm for automatic recognition of hand-sign-spelled Bangla sign language. Front. Comput. Sci. 2020, 14, 143302. [Google Scholar] [CrossRef]
- Hasan, M.M.; Srizon, A.Y.; Hasan, M.A.M. Classification of Bengali sign language characters by applying a novel deep convolutional neural network. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 1303–1306. [Google Scholar]
- Urmee, P.P.; Al Mashud, M.A.; Akter, J.; Jameel, A.S.M.M.; Islam, S. Real-time bangla sign language detection using xception model with augmented dataset. In Proceedings of the 2019 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Bangalore, India, 15–16 November 2019; pp. 1–5. [Google Scholar]
- Abedin, T.; Prottoy, K.S.; Moshruba, A.; Hakim, S.B. Bangla sign language recognition using concatenated BdSL network. arXiv 2021, arXiv:2107.11818. [Google Scholar]
- Zhang, Z.; Li, Z.; Liu, H.; Xiong, N.N. Multi-scale Dynamic Convolutional Network for Knowledge Graph Embedding. IEEE Trans. Knowl. Data Eng. 2020, 34, 2335–2347. [Google Scholar] [CrossRef]
- Farooq, U.; Mohd Rahim, M.S.; Khan, N.S.; Rasheed, S.; Abid, A. A Crowdsourcing-Based Framework for the Development and Validation of Machine Readable Parallel Corpus for Sign Languages. IEEE Access 2021, 9, 91788–91806. [Google Scholar] [CrossRef]
- Li, D.; Liu, H.; Zhang, Z.; Lin, K.; Fang, S.; Li, Z.; Xiong, N.N. CARM: Confidence-aware recommender model via review representation learning and historical rating behavior in the online platforms. Neurocomputing 2021, 455, 283–296. [Google Scholar] [CrossRef]
- Farooq, U.; Shafry, M.; Rahim, M.; Khan, N.; Hussain, A.; Abid, A. Advances in machine translation for sign language: Approaches, limitations, and challenges. Neural Comput. Appl. 2021, 33, 14357–14399. [Google Scholar] [CrossRef]
- Sabri, M.; El Abbadi, N.K. A Review for Sign Language Recognition Techniques. In Proceedings of the 1st Babylon International Conference on Information Technology and Science (BICITS), Babil, Iraq, 28–29 April 2021. [Google Scholar]
- Wadhawan, A.; Kumar, P. Sign language recognition systems: A decade systematic literature review. Arch. Comput. Methods Eng. 2021, 28, 785–813. [Google Scholar] [CrossRef]
- Zimmerman, T.G.; Lanier, J.; Blanchard, C.; Bryson, S.; Harvill, Y. A hand gesture interface device. In Proceedings of the CHI’86 Conference Proceedings, Boston, MA, USA, 13–17 April 1986. [Google Scholar]
- Yanay, T.; Shmueli, E. Air-writing recognition using smart-bands. Pervasive Mob. Comput. 2020, 66, 101183. [Google Scholar] [CrossRef]
- Murata, T.; Shin, J. Hand gesture and character recognition based on kinect sensor. Int. J. Distrib. Sens. Netw. 2014, 10, 278460. [Google Scholar] [CrossRef]
- Sonoda, T.; Muraoka, Y. A letter input system based on handwriting gestures. Electron. Commun. Jpn. (Part III Fundam. Electron. Sci.) 2006, 89, 53–64. [Google Scholar] [CrossRef]
- Mukai, N.; Harada, N.; Chang, Y. Japanese fingerspelling recognition based on classification tree and machine learning. In Proceedings of the 2017 Nicograph International (NicoInt), Kyoto, Japan, 2–3 June 2017; pp. 19–24. [Google Scholar]
- Pariwat, T.; Seresangtakul, P. Thai finger-spelling sign language recognition using global and local features with SVM. In Proceedings of the 2017 9th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 1–4 February 2017; pp. 116–120. [Google Scholar]
- Ameen, S.; Vadera, S. A convolutional neural network to classify American Sign Language fingerspelling from depth and colour images. Expert Syst. 2017, 34, e12197. [Google Scholar] [CrossRef] [Green Version]
- Nakjai, P.; Katanyukul, T. Hand sign recognition for thai finger spelling: An application of convolution neural network. J. Signal Process. Syst. 2019, 91, 131–146. [Google Scholar] [CrossRef]
- Tolentino, L.K.S.; Juan, R.O.S.; Thio-ac, A.C.; Pamahoy, M.A.B.; Forteza, J.R.R.; Garcia, X.J.O. Static sign language recognition using deep learning. Int. J. Mach. Learn. Comput. 2019, 9, 821–827. [Google Scholar] [CrossRef]
- Hu, Y.; Zhao, H.F.; Wang, Z.G. Sign language fingerspelling recognition using depth information and deep belief networks. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1850018. [Google Scholar] [CrossRef]
- Aly, S.; Osman, B.; Aly, W.; Saber, M. Arabic sign language fingerspelling recognition from depth and intensity images. In Proceedings of the 2016 12th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 28–29 December 2016; pp. 99–104. [Google Scholar]
- Youme, S.K.; Chowdhury, T.A.; Ahamed, H.; Abid, M.S.; Chowdhury, L.; Mohammed, N. Generalization of Bangla Sign Language Recognition Using Angular Loss Functions. IEEE Access 2021, 9, 165351–165365. [Google Scholar] [CrossRef]
- Kolkur, S.; Kalbande, D.; Shimpi, P.; Bapat, C.; Jatakia, J. Human Skin Detection Using RGB, HSV and YCbCr Color Models. In Proceedings of the International Conference on Communication and Signal Processing 2016 (ICCASP 2016), Lonere, India, 26–27 December 2016. [Google Scholar] [CrossRef] [Green Version]
- Saxen, F.; Al-Hamadi, A. Color-based skin segmentation: An evaluation of the state of the art. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4467–4471. [Google Scholar]
- Rahmat, R.F.; Chairunnisa, T.; Gunawan, D.; Sitompul, O.S. Skin Color Segmentation Using Multi-Color Space Threshold. In Proceedings of the 2016 3rd International Conference On Computer And Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 15–17 August 2016. [Google Scholar]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-touch sign word recognition based on dynamic hand gesture using hybrid segmentation and CNN feature fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef] [Green Version]
- Kornilov, A.S.; Safonov, I.V. An Overview of Watershed Algorithm Implementations in Open Source Libraries. J. Imaging 2018, 4, 123. [Google Scholar] [CrossRef] [Green Version]
- Carneiro, A.C.; Silva, L.B.; Salvadeo, D.P. Efficient sign language recognition system and dataset creation method based on deep learning and image processing. In Proceedings of the Thirteenth International Conference on Digital Image Processing (ICDIP 2021), Singapore, 20–23 May 2021; Volume 11878, p. 1187803. [Google Scholar]
- Fregoso, J.; Gonzalez, C.I.; Martinez, G.E. Optimization of Convolutional Neural Networks Architectures Using PSO for Sign Language Recognition. Axioms 2021, 10, 139. [Google Scholar] [CrossRef]
- Jagtap, S.; Bhatt, C.; Thik, J.; Rahimifard, S. Monitoring Potato Waste in Food Manufacturing Using Image Processing and Internet of Things Approach. Sustainability 2019, 11, 3173. [Google Scholar] [CrossRef] [Green Version]
- Shustanov, A.; Yakimov, P. Modification of single-purpose CNN for creating multi-purpose CNN. J. Phys. Conf. Ser. 2019, 1368, 052036. [Google Scholar] [CrossRef]
- Rusiecki, A. Trimmed categorical cross-entropy for deep learning with label noise. Electron. Lett. 2019, 55, 319–320. [Google Scholar] [CrossRef]
- Sledevic, T. Adaptation of Convolution and Batch Normalization Layer for CNN Implementation on FPGA. In Proceedings of the 2019 Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 25 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Shanta, S.S.; Anwar, S.T.; Kabir, M.R. Bangla Sign Language Detection Using SIFT and CNN. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmentation Technique | Range |
|---|---|
| Zoom | 0.5–1.0 |
| Brightness range | 0.2–1.0 |
| Rotation | 0–30 degree |
| Shear | 0–10 degree |
| Width shift range | 0.2 |
| Height shift range | 0.5 |
| flip | True |
| Layer No. | Layer Name | Input Shape | Output Shape | Param |
|---|---|---|---|---|
| 1 | Conv2d_1 | 124 × 124 × 3 | 124 × 124 × 96 | 2688 |
| 2 | Dropout_1 | 124 × 124 × 96 | 124 × 124 × 96 | 0 |
| 3 | Conv2d_2 | 124 × 124 × 96 | 124 × 124 × 96 | 83,040 |
| 4 | Conv2d_3 | 124 × 124 × 96 | 62 × 62 × 96 | 83,040 |
| 5 | Dropout_2 | 62 × 62 × 96 | 62 × 62 × 96 | 0 |
| 6 | Max Pooling 2d_1 | 62 × 62 × 96 | 31 × 31 × 192 | 0 |
| 7 | Conv2d_4 | 31 × 31 × 192 | 31 × 31 × 192 | 166,080 |
| 9 | Conv2d_5 | 31 × 31 × 192 | 31 × 31 × 192 | 331,968 |
| 10 | Conv2d_6 | 31 × 31 × 192 | 16 × 16 × 192 | 331,968 |
| 11 | Dropout_3 | 16 × 16 × 192 | 16 × 16 × 192 | 0 |
| 12 | Max Pooling 2d_2 | 16 × 16 × 192 | 8 × 8 × 192 | 0 |
| 13 | Conv2d_7 | 8 × 8 × 192 | 8 × 8 × 192 | 331,968 |
| 14 | Activation (Relu) | 8 × 8 × 192 | 8 × 8 × 192 | 0 |
| 15 | Conv2d_8 | 8 × 8 × 192 | 8 × 8 × 192 | 37,056 |
| 16 | Activation (Relu) | 8 × 8 × 192 | 8 × 8 × 192 | 0 |
| 17 | Conv2d_9 | 8 × 8 × 192 | 8 × 8 × 38 | 7334 |
| 18 | Batch Normalization | 8 × 8 × 38 | 8 × 8 × 38 | 152 |
| 19 | Global Average Pooling 2D | 8 × 8 × 38 | 38 | 0 |
| 20 | Activation (Softmax) | 38 | 38 | 0 |
| Total params: 1,375,294 Trainable params: 1,375,218 Non-trainable params: 76 | ||||
| Dataset | Before Augmentation | After Augmentation | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| 38 BdSL [11] | 8512 | 3648 | 68,096 | 3648 |
| KU-BdSL [12] | 1050 | 450 | 15,750 | 450 |
| Ishara-Lipi [13] | 1260 | 540 | 18,900 | 540 |
| Dataset | Segmented | Training (%) | Validation (%) | Testing (%) |
|---|---|---|---|---|
| 38 BdSL alphabets | no | 98.00 | 95.00 | 93.20 |
| 38 BdSL alphabets | yes | 99.99 | 96.00 | 94.00 |
| Dataset | Model Name | Segmented | Image Pixel | Training (%) | Validation (%) | Testing (%) |
|---|---|---|---|---|---|---|
| 38 BdSL | Rafi et al. [11] | No | 224 × 224 | 97.68 | 91.52 | 89.60 |
| 38 BdSL | Abedin et al. [33] | no | 60 × 60 | 98.67 | 95.28 | 91.52 |
| 38 BdSL | Proposed model (BenSignNet) | yes | 124 × 124 | 99.99 | 96.00 | 94.00 |
| Dataset | Segmented | Training (%) | Validation (%) | Testing (%) |
|---|---|---|---|---|
| KU-BdSL USLD Variant | No | 99.10 | 98.66 | 98.20 |
| KU-BdSL USLD Variant | Yes | 99.90 | 99.60 | 99.60 |
| Dataset | Segmented | Training (%) | Validation (%) | Testing (%) |
|---|---|---|---|---|
| KU-BdSL MSLD Variant | No | 99.10 | 98.66 | 98.20 |
| KU-BdSL MSLD Variant | Yes | 100 | 99.99 | 99.60 |
| Model Name | Gesture | Sample | Segmen Tation | Pixel | Model | Vectorize | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| Shanta et al. [64] | 38 | 7600 | Yes | 128 × 128 | CNN | FC | 90.63 |
| Hoque et al. [28] | 10 | 100 | No | N/A | R-CNN | FC | 98.20 |
| Proposed model | 31 | 3000 | yes | 124 × 124 | Ben SignNet | GAP | 99.60 |
| Dataset | Model Name | Segmented | Test Set |
|---|---|---|---|
| Ishara-Lipi | CNN | No | 99.10 |
| Ishara-Lipi | CNN | Yes | 99.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miah, A.S.M.; Shin, J.; Hasan, M.A.M.; Rahim, M.A. BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network. Appl. Sci. 2022, 12, 3933. https://doi.org/10.3390/app12083933
Miah ASM, Shin J, Hasan MAM, Rahim MA. BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network. Applied Sciences. 2022; 12(8):3933. https://doi.org/10.3390/app12083933
Chicago/Turabian StyleMiah, Abu Saleh Musa, Jungpil Shin, Md Al Mehedi Hasan, and Md Abdur Rahim. 2022. "BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network" Applied Sciences 12, no. 8: 3933. https://doi.org/10.3390/app12083933
APA StyleMiah, A. S. M., Shin, J., Hasan, M. A. M., & Rahim, M. A. (2022). BenSignNet: Bengali Sign Language Alphabet Recognition Using Concatenated Segmentation and Convolutional Neural Network. Applied Sciences, 12(8), 3933. https://doi.org/10.3390/app12083933