
Trajectory Generation and Optimization Using the Mutual Learning and Adaptive Ant Colony Algorithm in Uneven Environments


Abstract
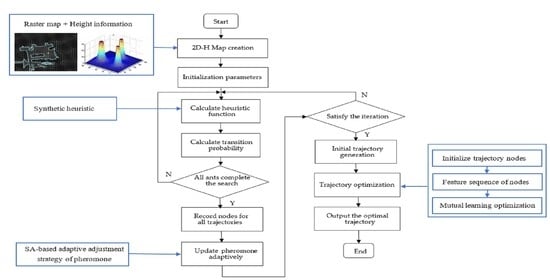
:
1. Introduction
- The 2D-H raster map is proposed to simulate the uneven outdoor environment. The height information in the three-dimensional environment is stored in the 2D plane;
- A hybrid scheme using mutual learning and adaptive ant colony optimization is proposed in this paper. The global robot trajectory planning problem is divided into two consecutive parts: the trajectory generation part and the trajectory optimization part;
- An improved adaptive ant colony algorithm is proposed to generate the initial trajectory. Considering the height information of the map, a comprehensive heuristic function including length, height, and smoothness is designed. Then, a new pheromone adaptive update strategy is proposed through an improved simulated annealing function to speed up the convergence of the algorithm.
- A new trajectory optimization algorithm based on mutual learning is proposed to optimize the generated initial trajectory. Firstly, feature ablation experiments are carried out for each turning point to obtain the safety feature sequence of each turning point. Then, each point learns from other points to gradually eliminate the points that do not affect the trajectory safety to optimize the trajectory length and smoothness. Finally, the shortest sequence of key points affecting trajectory safety is obtained. Therefore, the algorithm optimizes the final trajectory in terms of smoothness, length, and stability.
2. Environment Description and Problem Formulation
2.1. Environment Description
2.2. Problem Formulation
3. Improved Adaptive Ant Colony Algorithm
3.1. Basic Ant Colony Optimization
3.2. Improved Heuristic Function
3.3. SA-Based Adaptive Adjustment Strategy of Pheromones
4. Mutual Learning-Based Trajectory Optimization Algorithm
| Algorithm 1. Mutual learning-based Trajectory Optimization Algorithm |
| 1: input turning point set |
| 2: initialize point set as feature individual by (13)(14) |
| 3: calculate the reward and punishment function by (15)(16)(17) |
| 4: for = 1 to n do |
| 5: for = 1 to n do |
| 6: if is not more than then |
| 7: learns feature zero through , and calculate |
| 8: will be updated to by (18) |
| 9: else |
| 10: learns feature zero through , and calculate |
| 11: will be updated to by (18) |
| 12: end if |
| 13: end for |
| 14: end for |
| 15: if is equal to the initial trajectory then |
| 16: the optimal trajectory is initial trajectory , number of turns is |
| 17: else |
| 18: calculate the length of the optimal trajectory and the number of turns by (19)(20) |
| 19: end if |
| 20: output the number of turns: |
| 21: output the shortest trajectory: |
5. A Hybrid Scheme Using MuL-ACO for Trajectory Generation and Optimization
- Step 1:
- Establish a 2D-H grid map based on the uneven environment and initialize the parameters. Set the starting point S, the end point E, the number of ants k, the maximum number of iterations , pheromone heuristic factor α, expected heuristic factor β, pheromone intensity coefficient Q, and the initial pheromone .
- Step 2:
- Trajectory selection. Calculate the heuristic function by Equation (6). The ant is placed at the starting point and the probability of transferring to the next node is calculated by Equation (2). All trajectory nodes from the starting point to the current point are stored in the Tabu list.
- Step 3:
- Determine whether all the ants have completed the trajectory search in this generation. If it is, go to step 4, otherwise, return to step 2.
- Step 4:
- Record the nodes of the trajectory walked by all ants and find the optimal trajectory in this iteration.
- Step 5:
- Adjust the pheromone volatilization factor ρ adaptively, according to Equations (10) and (11). Update the pheromone by Equation (4). Re-zero the taboo table.
- Step 6:
- Determine whether the maximum number of iterations is reached. If it is, go to step 7, otherwise, return to step 2.
- Step 7:
- Initial trajectory generation. Obtain the optimal trajectory node and total height.
- Step 8:
- Trajectory optimization. The trajectory optimization algorithm based on mutual learning, such as Algorithm 1, is used to optimize the initial trajectory. Calculate the optimal trajectory including length, height, and number of turns.
6. Experiment
6.1. Simulation Experiment A
6.2. Simulation Experiment B
6.3. Simulation Experiment C
6.4. Simulation Experiment D
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACO | adaptive ant colony optimization |
| MuL-ACO | mutual learning and adaptive ant colony optimization |
| MH-ACO | multiple heuristics adaptive ant colony optimization |
| MF-ACO | multi-factor adaptive ant colony optimization |
| SA | simulated annealing |
| RGB-D | Red Green Blue-Depth |
| APF | artificial potential field method |
| GA | genetic algorithms |
| PSO | particle swarm optimization |
| GWO | grey wolf optimizer |
| IAACA | improved adaptive ant colony algorithm |
| MLTO | Mutual learning-based Trajectory Optimization Algorithm |
| SSA | sparrow search algorithm |
References
- Rubio, F.; Valero, F.; Llopis-Albert, C. A review of mobile robots: Concepts, methods, theoretical framework, and applications. Int. J. Adv. Robot. Syst. 2019, 16, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Lindemann, R.A.; Bickler, D.B.; Harrington, B.D.; Ortiz, G.M.; Voothees, C.J. Mars exploration rover mobility development. IEEE Robot. Autom. Mag. 2006, 13, 72–82. [Google Scholar] [CrossRef]
- Ward, C.C.; Iagnemma, K. A dynamic-model-based wheel slip detector for mobile robots on outdoor terrain. IEEE Trans. Robot. 2008, 24, 821–831. [Google Scholar] [CrossRef]
- Ganganath, N.; Cheng, C.T.; Chi, K.T. Finding energy-efficient paths on uneven terrains. In Proceedings of the 2014 10th France-Japan/8th Europe-Asia Congress on Mecatronics (MECATRONICS2014-Tokyo), Tokyo, Japan, 27–29 November 2014; pp. 383–388. [Google Scholar]
- Mei, Y.; Lu, Y.H.; Hu, Y.C.; Lee, C.G. Energy-efficient motion planning for mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; pp. 4344–4349. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. High-precision depth estimation with the 3d lidar and stereo fusion. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2156–2163. [Google Scholar]
- Hara, Y.; Tomono, M. Moving object removal and surface mesh mapping for path planning on 3D terrain. Adv. Robot. 2020, 6, 375–387. [Google Scholar] [CrossRef]
- Shin, J.; Kwak, D.; Kwak, K. Model Predictive Path Planning for an Autonomous Ground Vehicle in Rough Terrain. Int. J. Control Autom. 2021, 6, 2224–2237. [Google Scholar] [CrossRef]
- Song, S.; Jo, S. Online inspection path planning for autonomous 3D modeling using a micro-aerial vehicle. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 6217–6224. [Google Scholar]
- Nam, T.H.; Shim, J.H.; Cho, Y.I. A 2.5 D map-based mobile robot localization via cooperation of aerial and ground robots. Sensors 2017, 17, 2730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A simultaneous localization and mapping (SLAM) framework for 2.5 D map building based on low-cost LiDAR and vision fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef] [Green Version]
- Asvadi, A.; Peixoto, P.; Nunes, U. Detection and tracking of moving objects using 2.5 d motion grids. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 788–793. [Google Scholar]
- Patle, B.K.; Pandey, A.; Parhi, D.R.K.; Jagadeesh, A. A review: On path planning strategies for navigation of mobile robot. Def. Technol. 2019, 15, 582–606. [Google Scholar] [CrossRef]
- Barraquand, J.; Langlois, B.; Latombe, J.C. Numerical potential field techniques for robot path planning. IEEE Trans. Syst. Man Cybern. 1992, 22, 224–241. [Google Scholar] [CrossRef]
- Li, G.; Tong, S.; Cong, F.; Yamashita, A.; Asama, H. Improved artificial potential field-based simultaneous forward search method for robot path planning in complex environment. In Proceedings of the 2015 IEEE/SICE International Symposium on System Integration (SII), Nagoya, Japan, 11–13 December 2015; pp. 760–765. [Google Scholar]
- Zhang, G.L.; Hu, X.M.; Chai, J.F.; Zhao, L.; Yu, T. Summary of path planning algorithm and its application. Mod. Mach. 2011, 5, 85–90. [Google Scholar]
- Haldurai, L.; Madhubala, T.; Rajalakshmi, R. A study on genetic algorithm and its applications. Int. J. Comput. Sci. Eng. 2016, 4, 139. [Google Scholar]
- Syed, U.A.; Kunwar, F.; Iqbal, M. Guided Autowave Pulse Coupled Neural Network (GAPCNN) based real time path planning and an obstacle avoidance scheme for mobile robots. Robot. Auton. Syst. 2014, 62, 474–486. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.W.; Zhang, J.H. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013, 103, 172–185. [Google Scholar] [CrossRef]
- Brand, M.; Masuda, M.; Wehner, N.; Yu, X.H. Ant colony optimization algorithm for robot path planning. In Proceedings of the 2010 International Conference on Computer Design and Applications, Qinhuangdao, China, 25–27 June 2010; pp. 3–436. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimedia Tools and Applications. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Li, W.; Meng, X.; Huang, Y.; Fu, Z.H. Multipopulation cooperative particle swarm optimization with a mixed mutation strategy. Inform. Sci. 2020, 529, 179–196. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, D.; Zhang, T.; Zhang, J.; Wang, J. A new path plan method based on hybrid algorithm of reinforcement learning and particle swarm optimization. Eng. Comput. 2021, 39, 993–1019. [Google Scholar] [CrossRef]
- Jiao, Z.; Ma, K.; Rong, Y.; Wang, P.; Zhang, H.; Wang, S. A path planning method using adaptive polymorphic ant colony algorithm for smart wheelchairs. J. Comput. Sci-Neth. 2018, 25, 50–57. [Google Scholar] [CrossRef]
- Nie, Z.; Zhao, H. Research on robot path planning based on Dijkstra and Ant colony optimization. In Proceedings of the 2019 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Shanghai, China, 21–24 November 2019; pp. 222–226. [Google Scholar]
- Chen, S.; Yang, J.; Li, Y.; Yang, J. Multiconstrained network intensive vehicle routing adaptive ant colony algorithm in the context of neural network analysis. Complexity 2017, 25, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Li, L.I.; Hong, L.I.; Ningbo, S.H.A.N. Path planning based on improved ant colony algorithm with multiple inspired factor. Comput. Eng. Appl. 2019, 55, 219–225. [Google Scholar]
- Akka, K.; Khaber, F. Mobile robot path planning using an improved ant colony optimization. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418774673. [Google Scholar] [CrossRef] [Green Version]
- Ning, J.; Zhang, Q.; Zhang, C.; Zhang, B. A best-path-updating information-guided ant colony optimization algorithm. Inform. Sci. 2018, 433, 142–162. [Google Scholar] [CrossRef]
- Chen, X.; Kong, Y.; Fang, X.; Wu, Q. A fast two-stage ACO algorithm for robotic path planning. Neural. Comput. Appl. 2013, 22, 313–319. [Google Scholar] [CrossRef]
- Liwei, Y.; Lixia, F.; Ning, G. Multi factor improved ant colony algorithm path planning. Comput. Integr. Manuf. Syst. (CIMS) 2021, 27, 1–18. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functions | Function Expressions | Range | ||
|---|---|---|---|---|
| Sphere | [−5.12, 5.12] | 10 | 0 | |
| Rastrigin | [−5.12, 5.12] | 10 | 0 | |
| Ackley | [−5.12, 5.12] | 10 | 0 |
| Name | Map NO. | Length | Iterations | Turns | Height Difference | Time (s) |
|---|---|---|---|---|---|---|
| GA | a | 28.7 | 32 | 10 | 5.6 | 9.2 |
| b | 29.7 | 38 | 9 | 5.4 | 12.5 | |
| c | 28.5 | 37 | 8 | 4.2 | 10.7 | |
| d | 28.1 | 31 | 5 | 5.3 | 10.4 | |
| e | 28.6 | 39 | 7 | 6.7 | 12.6 | |
| f | 29.0 | 34 | 6 | 4.1 | 9.5 | |
| SSA | a | 29.6 | 28 | 9 | 4.3 | 0.7 |
| b | 29.9 | 25 | 9 | 5.7 | 0.9 | |
| c | 30.7 | 26 | 7 | 3.1 | 0.5 | |
| d | 31.4 | 37 | 6 | 2.8 | 0.8 | |
| e | 28.9 | 21 | 10 | 7.2 | 0.6 | |
| f | 29.3 | 23 | 6 | 7.5 | 0.6 | |
| MuL-ACO | a | 32.4 | 7 | 5 | 0.9 | 1.4 |
| b | 29.8 | 6 | 6 | 1.2 | 1.3 | |
| c | 28.0 | 8 | 2 | 0.3 | 1.5 | |
| d | 27.9 | 9 | 3 | 0.5 | 1.7 | |
| e | 28.7 | 6 | 3 | 0.4 | 1.3 | |
| f | 28.2 | 7 | 2 | 2.1 | 1.6 |
| Map NO. | Name | Start Point | End Point |
|---|---|---|---|
| 1 | X-type | (0.5, 0.5) | (25.0, 23.0) |
| 2 | Z-type | (1.0, 24.0) | (25.0, 10.0) |
| 3 | Complex1 | (0.5, 0.5) | (26.0, 23.0) |
| 4 | Complex2 | (0.5, 0.5) | (29.0, 24.0) |
| 5 | Complex3 | (1.0, 0.5) | (29.0, 27.0) |
| 6 | Vortex | (28.0, 20.0) | (13.0, 15.0) |
| Name | Map NO. | Length | Iterations | Turns | Height Difference | Time (s) |
|---|---|---|---|---|---|---|
| ACO | 1 | 60.80 | 40 | 38 | 7.59 | 2.02 |
| 2 | 67.41 | 39 | 25 | 16.71 | 2.73 | |
| 3 | 41.2 | 38 | 22 | 7.36 | 1.41 | |
| 4 | 43.60 | 32 | 17 | 6.48 | 1.63 | |
| 5 | 43.0 | 30 | 14 | 7.45 | 1.71 | |
| 6 | —— | —— | —— | —— | —— | |
| MH-ACO | 1 | 56.82 | 27 | 15 | 2.29 | 2.30 |
| 2 | 66.30 | 21 | 13 | 9.31 | 2.53 | |
| 3 | 44.21 | 28 | 14 | 6.72 | 1.54 | |
| 4 | 43.40 | 25 | 8 | 5.10 | 1.72 | |
| 5 | 43.60 | 23 | 12 | 1.55 | 1.74 | |
| 6 | 78.40 | 19 | 31 | 8.15 | 2.57 | |
| MF-ACO | 1 | 54.27 | 15 | 10 | 3.44 | 1.93 |
| 2 | 74.10 | 12 | 14 | 9.98 | 2.87 | |
| 3 | 44.57 | 23 | 15 | 5.54 | 1.96 | |
| 4 | 43.41 | 18 | 9 | 3.33 | 2.28 | |
| 5 | 46.80 | 13 | 7 | 4.38 | 2.39 | |
| 6 | 73.62 | 16 | 22 | 6.93 | 2.54 | |
| MuL-ACO | 1 | 46.38 | 6 | 2 | 1.51 | 2.11 |
| 2 | 60.21 | 5 | 6 | 5.34 | 2.65 | |
| 3 | 42.88 | 5 | 9 | 2.18 | 1.61 | |
| 4 | 39.70 | 7 | 2 | 0.42 | 1.52 | |
| 5 | 43.10 | 8 | 3 | 1.56 | 1.55 | |
| 6 | 55.93 | 9 | 7 | 5.88 | 2.83 |
| Name | Map (with Different Start and End Points) | Length | Iterations | Turns | Height Difference | Time (s) |
|---|---|---|---|---|---|---|
| ACO | a | 34.80 | 37 | 11 | 6.81 | 1.51 |
| b | 35.80 | 25 | 16 | 7.44 | 1.40 | |
| c | 31.62 | 23 | 12 | 3.63 | 1.53 | |
| d | 38.60 | 15 | 21 | 11.02 | 1.52 | |
| MH-ACO | a | 41.80 | 23 | 5 | 0.34 | 1.63 |
| b | 35.20 | 17 | 5 | 1.49 | 1.53 | |
| c | 32.80 | 14 | 8 | 2.65 | 1.55 | |
| d | 41.00 | 11 | 8 | 0.38 | 1.66 | |
| MF-ACO | a | 36.60 | 17 | 7 | 2.40 | 2.20 |
| b | 36.20 | 13 | 6 | 2.07 | 2.10 | |
| c | 32.20 | 9 | 4 | 3.23 | 2.24 | |
| d | 40.20 | 10 | 4 | 4.33 | 2.13 | |
| MuL-ACO | a | 40.09 | 11 | 3 | 0.39 | 1.38 |
| b | 34.84 | 9 | 3 | 1.49 | 1.12 | |
| c | 30.89 | 10 | 3 | 3.04 | 1.24 | |
| d | 39.42 | 6 | 4 | 0.38 | 1.50 |
| Name | Map NO. | Length | Turns |
|---|---|---|---|
| (un)MuL-ACO | a | 41.6 | 7 |
| b | 42.0 | 9 | |
| c | 40.8 | 11 | |
| d | 40.2 | 8 | |
| e | 40.8 | 7 | |
| f | 42.6 | 6 | |
| MuL-ACO | a | 39.2 | 2 |
| b | 39.1 | 3 | |
| c | 38.6 | 4 | |
| d | 38.3 | 3 | |
| e | 39.5 | 2 | |
| f | 39.3 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, F.; Yu, W.; Xiao, K.; Liu, C.; Liu, W. Trajectory Generation and Optimization Using the Mutual Learning and Adaptive Ant Colony Algorithm in Uneven Environments. Appl. Sci. 2022, 12, 4629. https://doi.org/10.3390/app12094629
Qu F, Yu W, Xiao K, Liu C, Liu W. Trajectory Generation and Optimization Using the Mutual Learning and Adaptive Ant Colony Algorithm in Uneven Environments. Applied Sciences. 2022; 12(9):4629. https://doi.org/10.3390/app12094629
Chicago/Turabian StyleQu, Feng, Wentao Yu, Kui Xiao, Chaofan Liu, and Weirong Liu. 2022. "Trajectory Generation and Optimization Using the Mutual Learning and Adaptive Ant Colony Algorithm in Uneven Environments" Applied Sciences 12, no. 9: 4629. https://doi.org/10.3390/app12094629
APA StyleQu, F., Yu, W., Xiao, K., Liu, C., & Liu, W. (2022). Trajectory Generation and Optimization Using the Mutual Learning and Adaptive Ant Colony Algorithm in Uneven Environments. Applied Sciences, 12(9), 4629. https://doi.org/10.3390/app12094629