
Insider Threat Detection Using Machine Learning Approach


Abstract
:1. Introduction
- Data theft: where the attacker attempts to steal private information. Examples of activities that indicate this scenario include: accessing sensitive data at odd hours, downloading data to personal devices, or sending data outside the protected perimeter.
- Privilege abuse: a particularly difficult to detect insider attack that involves users with privileged access rights uploading harmful data or editing/deleting activity logs, creating privileged accounts without a request, deploying suspicious software, or changing security configurations.
- Privilege escalation: where a regular user attempts to gain privileges to abuse resources. Indicators of such as attack include frequent and unnecessary access requests, showing unusual interest in data and projects that a user cannot access, or installing unauthorised software.
- Sabotage: where the employee attempts to destroy data or infrastructure. Some indicators of this attack include sending emails with attachments to competitors, deleting accounts intentionally, failing to create backups, or making changes to data that no one requested.
2. Literature Review
2.1. Machine Learning
2.2. Deep Learning
2.2.1. Recurrent Neural Networks
2.2.2. Convolutional Neural Networks
3. Materials and Methods
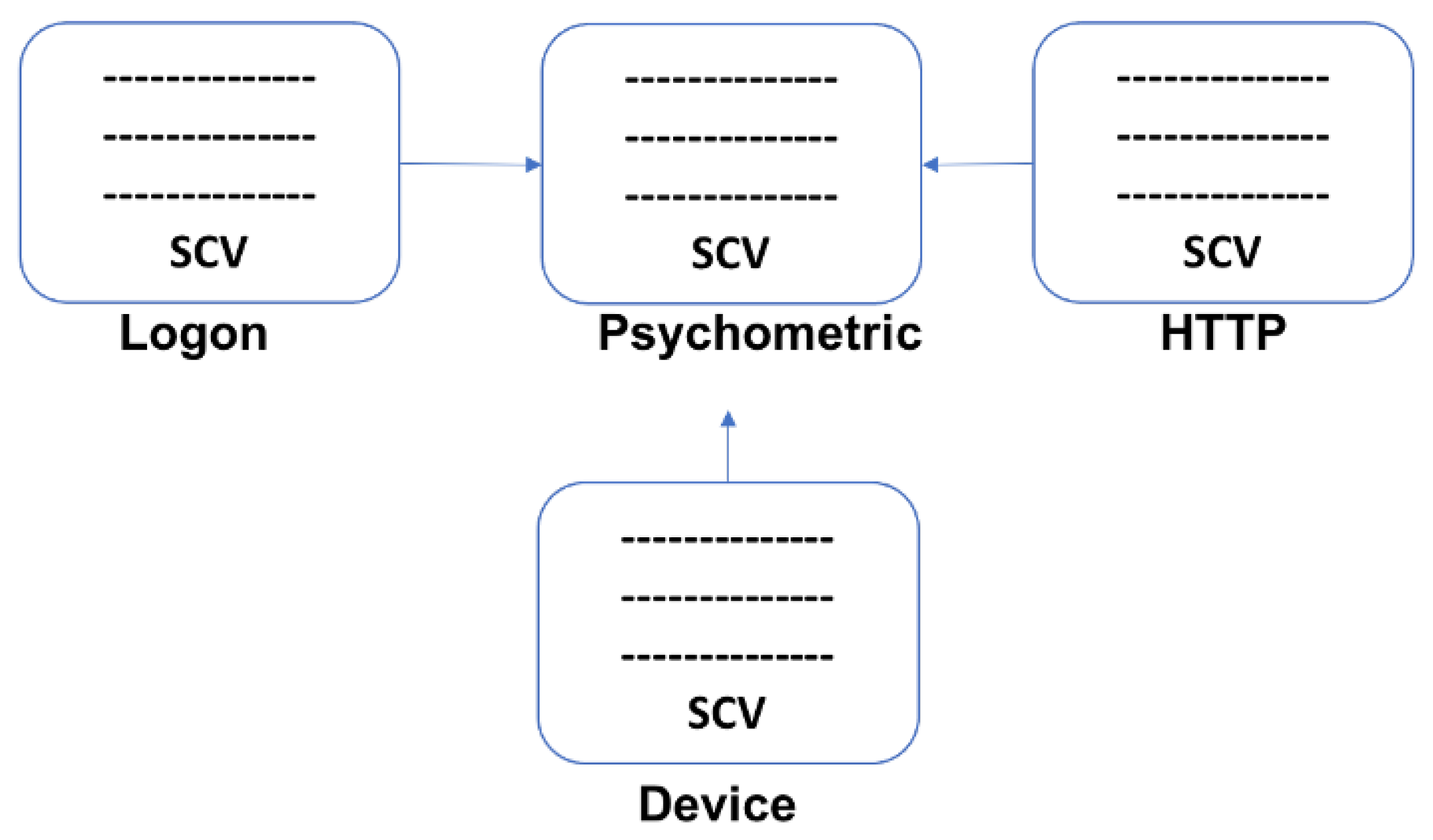
3.1. Dataset
- A user who never worked after hours or used removable drives starts logging in after hours, using a removable drive, uploading information to wikileaks.org, and then leaves the company shortly after;
- A user begins searching for career opportunities on job search websites and contacting potential employers. Before leaving the office, they use a thumb drive to take data (at a rate noticeably higher than their prior actions);
- A dissatisfied system administrator downloads a key logger and transfers it to his supervisor’s computer using a thumb drive. The following day, he logs into his company’s network as his boss and sends out an alarming mass email, causing widespread concern, and immediately leaves the organisation.
3.2. Data Pre-Processing
3.3. Feature Extraction
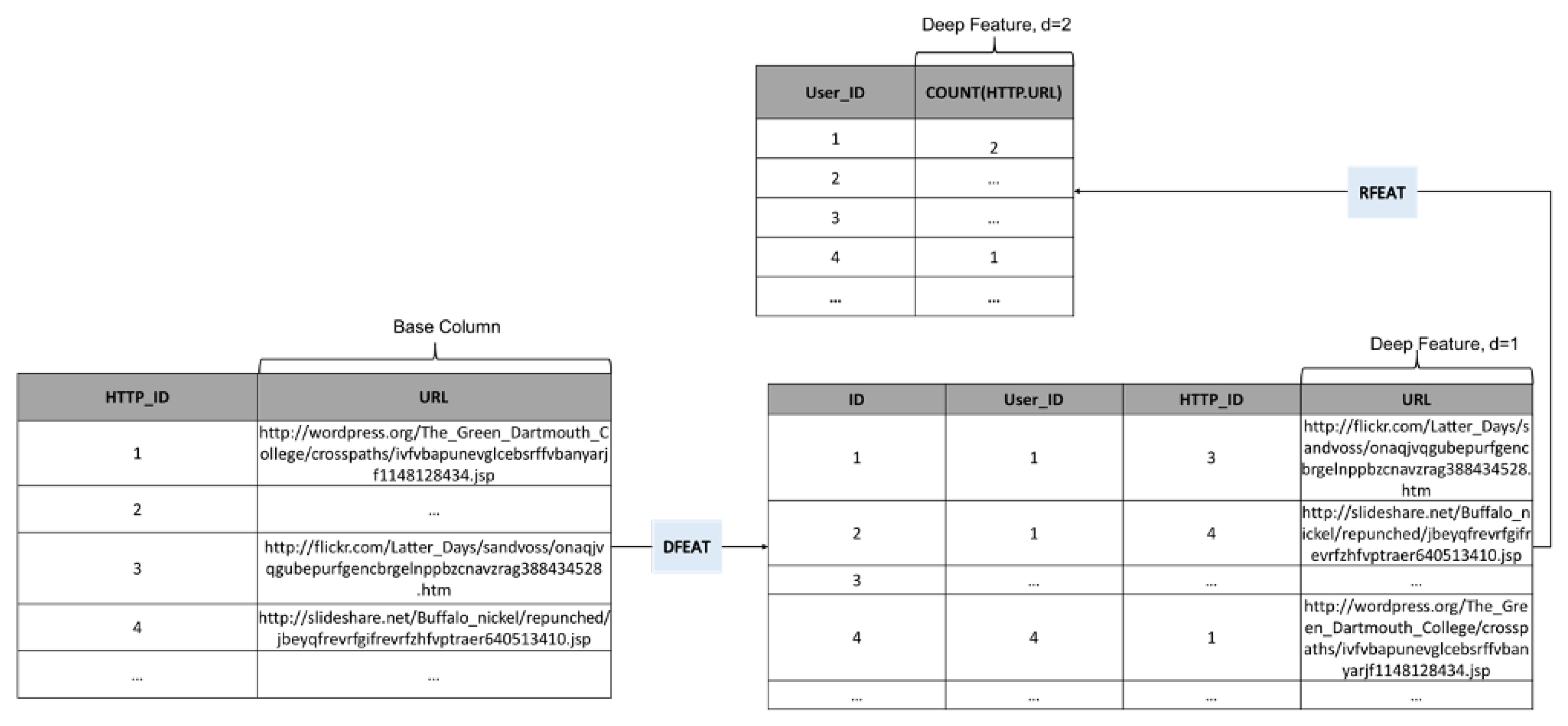
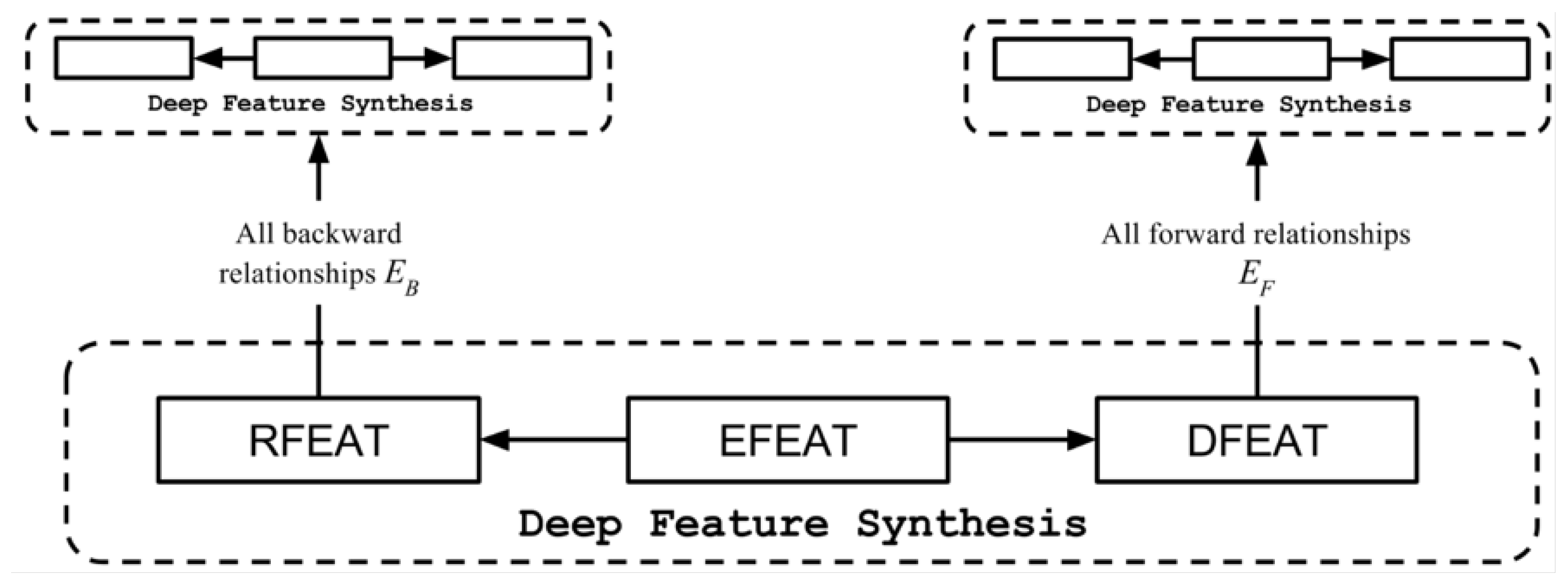
3.3.1. Deep Feature Synthesis
3.3.2. PCA
3.3.3. SMOTE
3.4. Insider Threat Models
3.4.1. Anomaly Detection Models
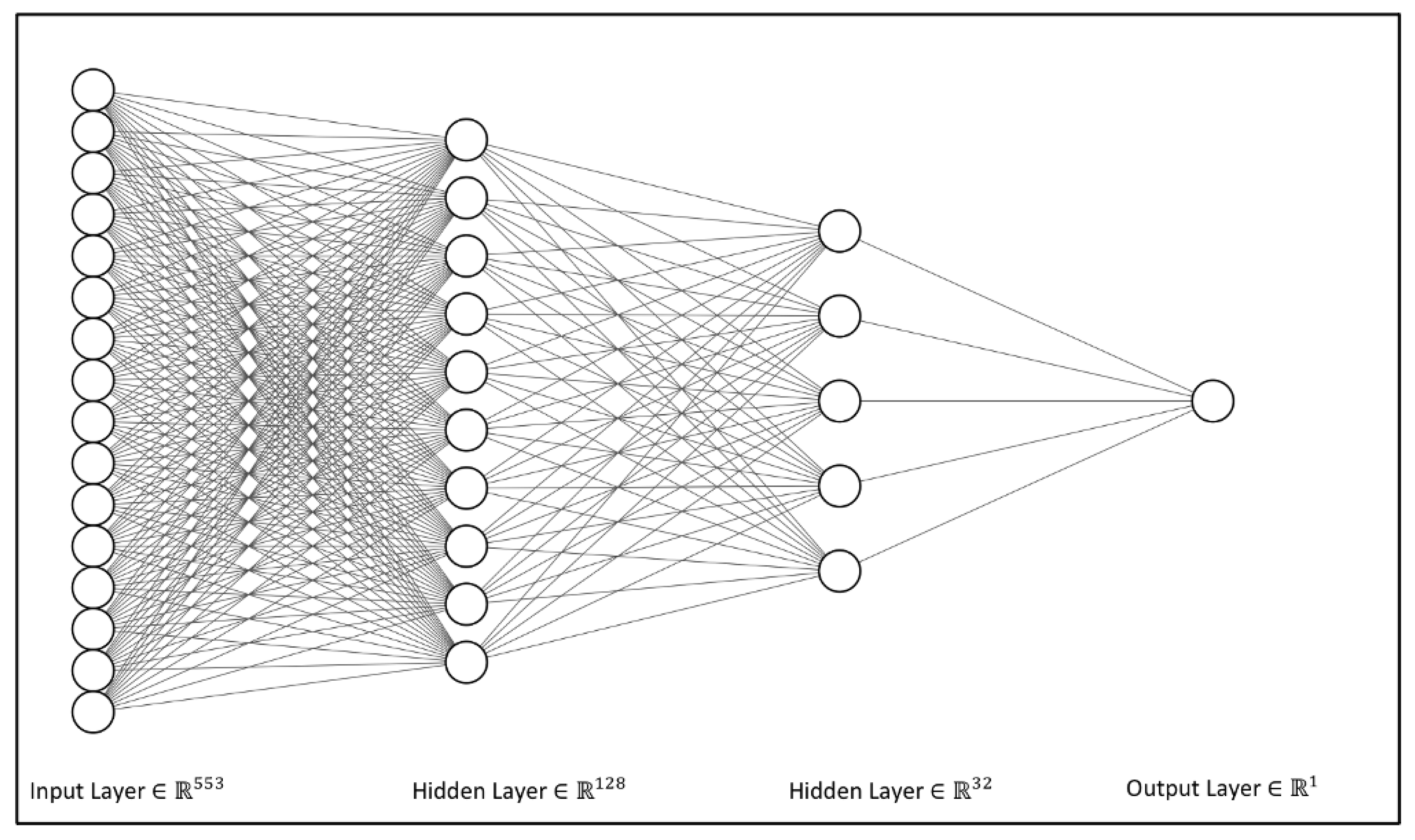
3.4.2. Classification Models
3.5. Evaluation
- TP: predicted abnormal activity is an abnormal activity;
- FP: predicted normal activity is an abnormal activity;
- FN: predicted abnormal activity is a normal activity;
- TN: predicted normal activity is a normal activity.
4. Experimental Results
4.1. Anomaly Detection
4.2. Classification
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Greatest Threat. Available online: https://www.darkreading.com/vulnerabilities—threats/greatest-threat/d/d-id/1269416 (accessed on 19 December 2022).
- Noever, D. Classifier Suites for Insider Threat Detection. arXiv 2019, arXiv:1901.10948. [Google Scholar]
- Cappelli, D.; Moore, A.; Trzeciak, R. The CERT Guide to Insider Threats: How to Prevent, Detect, and Respond to Information Technology Crimes (Theft, Sabotage, Fraud); Addison-Wesley: Boston, MA, USA, 2012. [Google Scholar]
- Cheng, L.; Liu, F.; Yao, D. Enterprise data breach: Causes, challenges, prevention, and future directions. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1211. [Google Scholar] [CrossRef] [Green Version]
- Kulik, T.; Dongol, B.; Larsen, P.G.; Macedo, H.D.; Schneider, S.; Tran-Jørgensen, P.W.; Woodcock, J. A survey of practical formal methods for security. Form. Asp. Comput. 2022, 34, 1–39. [Google Scholar] [CrossRef]
- Rauf, U.; Shehab, M.; Qamar, N.; Sameen, S. Formal approach to thwart against insider attacks: A bio-inspired auto-resilient policy regulation framework. Future Gener. Comput. Syst. 2021, 117, 412–425. [Google Scholar] [CrossRef]
- Krichen, M.; Lahami, M.; Cheikhrouhou, O.; Alroobaea, R.; Maâlej, A.J. Security testing of internet of things for smart city applications: A formal approach. In Smart Infrastructure and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 629–653. [Google Scholar]
- Krichen, M.; Mihoub, A.; Alzahrani, M.Y.; Adoni, W.Y.H.; Nahhal, T. Are Formal Methods Applicable To Machine Learning And Artificial Intelligence? In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 23–26 May 2022; pp. 48–53. [Google Scholar] [CrossRef]
- Larsen, K.; Legay, A.; Nolte, G.; Schlüter, M.; Stoelinga, M.; Steffen, B. Formal Methods Meet Machine Learning (F3ML). In Proceedings of the Leveraging Applications of Formal Methods, Verification and Validation. Adaptation and Learning, Rhodes, Greece, 22–30 October 2022; Margaria, T., Steffen, B., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 393–405. [Google Scholar]
- Urban, C.; Miné, A. A review of formal methods applied to machine learning. arXiv 2021, arXiv:2104.02466. [Google Scholar]
- Chen, H.; Zhang, H.; Si, S.; Li, Y.; Boning, D.; Hsieh, C.J. Robustness verification of tree-based models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Ranzato, F.; Zanella, M. Robustness verification of support vector machines. In Proceedings of the International Static Analysis Symposium, Porto, Portugal, 8–11 October 2019; Springer: Cham, Switzerland, 2019; pp. 271–295. [Google Scholar]
- Jang, M.; Ryu, Y.; Kim, J.S.; Cho, M. Against Insider Threats with Hybrid Anomaly Detection with Local-Feature Autoencoder and Global Statistics (LAGS). IEICE Trans. Inf. Syst. 2020, E103.D, 888–891. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.Y.; Cho, S.B. Web traffic anomaly detection using C-LSTM neural networks. Expert Syst. Appl. 2018, 106, 66–76. [Google Scholar] [CrossRef]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams. arXiv 2017, arXiv:1710.00811. [Google Scholar]
- Karev, D.; McCubbin, C.; Vaulin, R. Cyber Threat Hunting Through the Use of an Isolation Forest. In Proceedings of the 18th International Conference on Computer Systems and Technologies, Ruse, Bulgaria, 23–24 June 2017; Association for Computing Machinery: New York, NY, USA, 2017. CompSysTech’17. pp. 163–170. [Google Scholar] [CrossRef]
- Gavai, G.; Sricharan, K.; Gunning, D.; Hanley, J.; Singhal, M.; Rolleston, R. Supervised and Unsupervised methods to detect Insider Threat from Enterprise Social and Online Activity Data. J. Wirel. Mob. Networks Ubiquitous Comput. Dependable Appl. 2015, 6, 47–63. [Google Scholar] [CrossRef]
- Lin, L.; Zhong, S.; Jia, C.; Chen, K. Insider Threat Detection Based on Deep Belief Network Feature Representation. In Proceedings of the 2017 International Conference on Green Informatics (ICGI), Fuzhou, China, 15–17 August 2017; pp. 54–59. [Google Scholar] [CrossRef]
- Meng, F.; Lou, F.; Fu, Y.; Tian, Z. Deep Learning Based Attribute Classification Insider Threat Detection for Data Security. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 576–581. [Google Scholar] [CrossRef]
- Kim, T.; Park, N.K.; Cho, H.; Kang, P. Insider Threat Detection Based on User Behavior Modeling and Anomaly Detection Algorithms. Appl. Sci. 2019, 9, 4018. [Google Scholar] [CrossRef] [Green Version]
- Sharma, B.; Pokharel, P.; Joshi, B. User Behavior Analytics for Anomaly Detection Using LSTM Autoencoder–Insider Threat Detection. In Proceedings of the 11th International Conference on Advances in Information Technology, Bangkok, Thailand, 1–3 July 2020; ACM: Bangkok, Thailand, 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Orizio, R.; Vuppala, S.; Basagiannis, S.; Provan, G. Towards an Explainable Approach for Insider Threat Detection: Constraint Network Learning. In Proceedings of the 2020 International Conference on Intelligent Data Science Technologies and Applications (IDSTA), San Antonio, TX, USA, 5–7 September 2022; pp. 42–49. [Google Scholar] [CrossRef]
- Tian, Z.; Shi, W.; Tan, Z.; Qiu, J.; Sun, Y.; Jiang, F. Deep Learning and Dempster-Shafer Theory Based Insider Threat Detection. Mob. Netw. Appl. 2020, 1–10. [Google Scholar] [CrossRef]
- Haidar, D.; Gaber, M.M. Data Stream Clustering for Real-Time Anomaly Detection: An Application to Insider Threats. In Clustering Methods for Big Data Analytics: Techniques, Toolboxes and Applications; Nasraoui, O., Ben N’Cir, C.E., Eds.; Unsupervised and Semi-Supervised Learning; Springer International Publishing: Cham, Switzerland, 2019; pp. 115–144. [Google Scholar] [CrossRef] [Green Version]
- Yuan, F.; Cao, Y.; Shang, Y.; Liu, Y.; Tan, J.; Fang, B. Insider Threat Detection with Deep Neural Network. In Proceedings of the ICCS, Wuxi, China, 11–13 June 2018. [Google Scholar] [CrossRef]
- Raval, M.S.; Gandhi, R.; Chaudhary, S. Insider Threat Detection: Machine Learning Way. In Versatile Cybersecurity; Conti, M., Somani, G., Poovendran, R., Eds.; Advances in Information Security; Springer International Publishing: Cham, Switzerland, 2018; pp. 19–53. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.M.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the ESANN, Bruges, Belgium, 22–23 April 2015. [Google Scholar]
- Kwon, D.; Natarajan, K.; Suh, S.C.; Kim, H.; Kim, J. An Empirical Study on Network Anomaly Detection Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1595–1598. [Google Scholar] [CrossRef]
- Koutsouvelis, V.; Shiaeles, S.; Ghita, B.; Bendiab, G. Detection of Insider Threats using Artificial Intelligence and Visualisation. In Proceedings of the 2020 6th IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020; pp. 437–443. [Google Scholar] [CrossRef]
- Sheykhkanloo, N.M.; Hall, A. Insider Threat Detection Using Supervised Machine Learning Algorithms on an Extremely Imbalanced Dataset. Int. J. Cyber Warf. Terror. 2020, 10, 1–26. [Google Scholar] [CrossRef]
- Singh, M.; Mehtre, B.M.; Sangeetha, S. User Behavior Profiling using Ensemble Approach for Insider Threat Detection. In Proceedings of the 2019 IEEE 5th International Conference on Identity, Security, and Behavior Analysis (ISBA), Hyderabad, India, 22–24 January 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar] [CrossRef]
- Ren, Y.; Wu, Y. Convolutional deep belief networks for feature extraction of EEG signal. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 2850–2853. [Google Scholar] [CrossRef]
- Al-Mhiqani, M.N.; Ahmad, R.; Zainal Abidin, Z. An Integrated Imbalanced Learning and Deep Neural Network Model for Insider Threat Detection. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 2021. [Google Scholar] [CrossRef]
- Gayathri, R.G.; Sajjanhar, A.; Xiang, Y.; Ma, X. Multi-class Classification Based Anomaly Detection of Insider Activities. arXiv 2021, arXiv:2102.07277. [Google Scholar]
- Mohammed, M.A.; Kadhem, S.M.; Maisa’a, A.A. Insider Attacker Detection Using Light Gradient Boosting Machine. Tech-Knowledge 2021, 1, 48–66. [Google Scholar]
- Singh, M.; Mehtre, B.M.; Sangeetha, S. Insider Threat Detection Based on User Behaviour Analysis. In Proceedings of the Machine Learning, Image Processing, Network Security and Data Sciences, Silchar, India, 30–31 July 2020; Bhattacharjee, A., Borgohain, S.K., Soni, B., Verma, G., Gao, X.Z., Eds.; Communications in Computer and Information Science. Springer: Singapore, 2020; pp. 559–574. [Google Scholar] [CrossRef]
- Rastogi, N.; Ma, Q. DANTE: Predicting Insider Threat using LSTM on system logs. arXiv 2021, arXiv:2102.05600. [Google Scholar]
- Gayathri, G.R.; Sajjanhar, A.; Xiang, Y. Image-Based Feature Representation for Insider Threat Classification. Appl. Sci. 2020, 10, 4945. [Google Scholar] [CrossRef]
- Aldairi, M.; Karimi, L.; Joshi, J. A Trust Aware Unsupervised Learning Approach for Insider Threat Detection. In Proceedings of the 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), Los Angeles, CA, USA, July 30–1 August 2019; pp. 89–98. [Google Scholar] [CrossRef]
- Kim, D.W.; Hong, S.S.; Han, M.M. A study on Classification of Insider threat using Markov Chain Model. KSII Trans. Internet Inf. Syst. 2018, 12, 1887–1898. [Google Scholar]
- Le, D.C.; Nur Zincir-Heywood, A. Machine learning based Insider Threat Modelling and Detection. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Washington, DC, USA, 8–12 April 2019; pp. 1–6. [Google Scholar]
- Al-Mhiqani, M.N.; Ahmad, R.; Zainal Abidin, Z.; Yassin, W.; Hassan, A.; Abdulkareem, K.H.; Ali, N.S.; Yunos, Z. A Review of Insider Threat Detection: Classification, Machine Learning Techniques, Datasets, Open Challenges, and Recommendations. Appl. Sci. 2020, 10, 5208. [Google Scholar] [CrossRef]
- Lo, O.; Buchanan, W.J.; Griffiths, P.; Macfarlane, R. Distance Measurement Methods for Improved Insider Threat Detection. Secur. Commun. Netw. 2018, 2018, e5906368. [Google Scholar] [CrossRef]
- Yuan, S.; Wu, X. Deep Learning for Insider Threat Detection: Review, Challenges and Opportunities. arXiv 2020, arXiv:2005.12433. [Google Scholar] [CrossRef]
- Hermans, M.; Schrauwen, B. Training and Analysing Deep Recurrent Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Wang, G.; Hao, J.; Ma, J.; Huang, L. A new approach to intrusion detection using Artificial Neural Networks and fuzzy clustering. Expert Syst. Appl. 2010, 37, 6225–6232. [Google Scholar] [CrossRef]
- Anomaly Detection at Multiple Scales. Available online: https://www.darpa.mil/program/anomaly-detection-at-multiple-scales (accessed on 28 March 2022).
- Statistical Methods for Computer Intrusion Detection. Available online: http://www.schonlau.net/intrusion.html (accessed on 28 March 2022).
- Insider Threat Test Dataset; Software Engineering Institute: Pittsburgh, PA, USA, 2016.
- Glasser, J.; Lindauer, B. Bridging the Gap: A Pragmatic Approach to Generating Insider Threat Data. In Proceedings of the 2013 IEEE Security and Privacy Workshops, San Francisco, CA, USA, 23–24 May 2013; pp. 98–104. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kanter, J.M.; Veeramachaneni, K. Deep feature synthesis: Towards automating data science endeavors. In Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Primitives | Featuretools. Available online: https://primitives.featurelabs.com/ (accessed on 7 November 2022).
- Principal Component Analysis for Special Types of Data. In Principal Component Analysis; Jolliffe, I.T. (Ed.) Springer: New York, NY, USA, 2002; pp. 338–372. [Google Scholar] [CrossRef]
- Tuning the Hyper-Parameters of an Estimator. Available online: https://scikit-learn.org/stable/modules/grid_search.html (accessed on 17 May 2022).
- Nicolaou, A.; Shiaeles, S.; Savage, N. Mitigating Insider Threats Using Bio-Inspired Models. Appl. Sci. 2020, 10, 5046. [Google Scholar] [CrossRef]
- Pantelidis, E.; Bendiab, G.; Shiaeles, S.; Kolokotronis, N. Insider Threat Detection using Deep Autoencoder and Variational Autoencoder Neural Networks. In Proceedings of the 2021 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 26–28 July 2021; pp. 129–134. [Google Scholar] [CrossRef]
- Le, D.C.; Zincir-Heywood, N. Exploring anomalous behaviour detection and classification for insider threat identification. Int. J. Netw. Manag. 2021, 31, e2109. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Method | Learn | Data | Results | Type | Balancing |
|---|---|---|---|---|---|---|
| [2] | Random forest | S | r4.2 | acc: 98% | Classification | Under/Over sampling |
| [16] | iForest | U | - | AUC: 82% | Anomaly detection | - |
| [22] | constraint network | U | r4.2 | acc: 99.91% FPR 0.06% P: 99.84% F1: 55.00% | Anomaly detection | - |
| [39] | CNN | S | r4.2 | acc: 99% P: 99.32% R: 99.32% | Classification | Random under sampling |
| [19] | LSTM | U | r6.2 | TPR: 92.46% FPR: 6.8% P: 95.12% acc: 93.85% | Anomaly detection | - |
| [23] | attention-LSTM | U | r6.2 | R: 95.79% FAR: 4.67% acc: 95.47% | Anomaly detection | - |
| [38] | RNN-LSTM | U | r6.2 | acc: 93% | Classification | - |
| [35] | XGBoost RF, MLP, 1DCNN | S | r4.2 | P: 83% R: 76% | Classification | GAN |
| [23] | attention-LSTM | U | r6.2 | R: 95.79% FAR: 4.67% acc: 95.47% | Anomaly detection | - |
| [37] | CNN-LSTM | S | r6.2 | AUC: 90.47% | Classification | - |
| Version | Employees | Insiders | Activities |
|---|---|---|---|
| r4.2 | 1000 | 70 | 32,770,227 |
| r6.2 | 2500 | 5 | 135,117,169 |
| File | Feature Description |
|---|---|
| logon.csv (logon/logoff activities) | ID, date, user, PC, activity |
| device.csv (external storage device usage) | ID, date, user, PC, activity (connect/disconnect) |
| email.csv (email traffic) | ID, date, user, PC, to, cc, bcc, form, size, attachment count, content |
| http.csv (HTTP traffic) | ID, date, user, PC, URL, content |
| file.csv (file operations) | ID, date, user, PC, filename, content |
| psychometric.csv (psychometric score) | ID, user, openness, conscientiousness, extraversion, agreeableness, neuroticism |
| Feature Name | Feature Description |
|---|---|
| Weekday_Logon_After | Employees log on outside of working hours on weekdays |
| Weekday_Logon_Normal | Employees log on during working hours on weekdays |
| Weekend_Logon | Employees log on during weekends |
| url_Count | The number of URLs visited by an employee in a day |
| Model | Precision | Recall | F1 − Score | Accuracy |
|---|---|---|---|---|
| OCSVM | 0.94 | 0.86 | 0.89 | 0.86 |
| iForest | 0.92 | 0.91 | 0.88 | 0.91 |
| Model | Precision | Recall | F1 − Score | Accuracy |
|---|---|---|---|---|
| NN | 0.98 | 0.95 | 0.96 | 0.95 |
| SVM | 1.00 | 1.00 | 1.00 | 1.00 |
| AdaBoost | 0.98 | 0.94 | 0.95 | 0.94 |
| RandomForest | 0.95 | 0.72 | 0.81 | 0.72 |
| Model | Precision | Recall | F1 − Score | Accuracy |
|---|---|---|---|---|
| NN | 0.94 | 0.97 | 0.96 | 0.97 |
| SVM | 1.00 | 1.00 | 1.00 | 1.00 |
| AdaBoost | 0.99 | 0.98 | 0.98 | 0.98 |
| RandomForest | 0.94 | 0.97 | 0.96 | 0.97 |
| Model | Accuracy | F1 − Score | Recall | Precision |
|---|---|---|---|---|
| CNN [29] | 100% | n/a | n/a | n/a |
| Bio-Inspired models [57] | n/a | 100% | n/a | 70% |
| Autoencoder [58] | 92% | 96% | 96% | 94% |
| DBN-OCSVM [39] | 87.79% | n/a | n/a | n/a |
| DNN [16] | 96% | 95% | n/a | n/a |
| Generative adversarial network [17] | n/a | n/a | 76% | n/a |
| Light Gradient Boosting [40] | 99.47% | 92.26% | n/a | 0.83% |
| CNN [29] | 99% | 99.3% | 99.32% | 99.29% |
| Random forest [59] | 98% | n/a | n/a | 99.32% |
| Our method | 100% | 100% | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bin Sarhan, B.; Altwaijry, N. Insider Threat Detection Using Machine Learning Approach. Appl. Sci. 2023, 13, 259. https://doi.org/10.3390/app13010259
Bin Sarhan B, Altwaijry N. Insider Threat Detection Using Machine Learning Approach. Applied Sciences. 2023; 13(1):259. https://doi.org/10.3390/app13010259
Chicago/Turabian StyleBin Sarhan, Bushra, and Najwa Altwaijry. 2023. "Insider Threat Detection Using Machine Learning Approach" Applied Sciences 13, no. 1: 259. https://doi.org/10.3390/app13010259
APA StyleBin Sarhan, B., & Altwaijry, N. (2023). Insider Threat Detection Using Machine Learning Approach. Applied Sciences, 13(1), 259. https://doi.org/10.3390/app13010259