

An Electroglottograph Auxiliary Neural Network for Target Speaker Extraction




Abstract
:1. Introduction
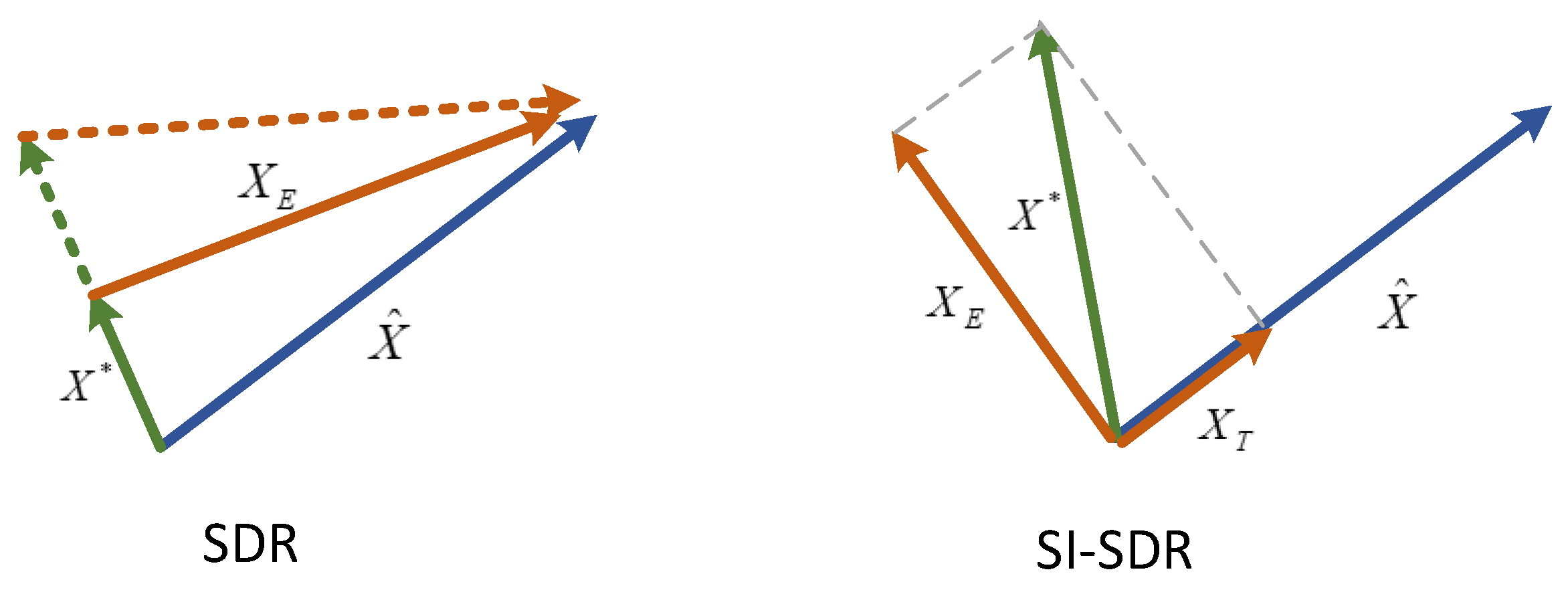
2. Related Works
3. Materials and Methods
3.1. Materials
3.2. Methods
3.2.1. The Configuration of SpeakerBeam
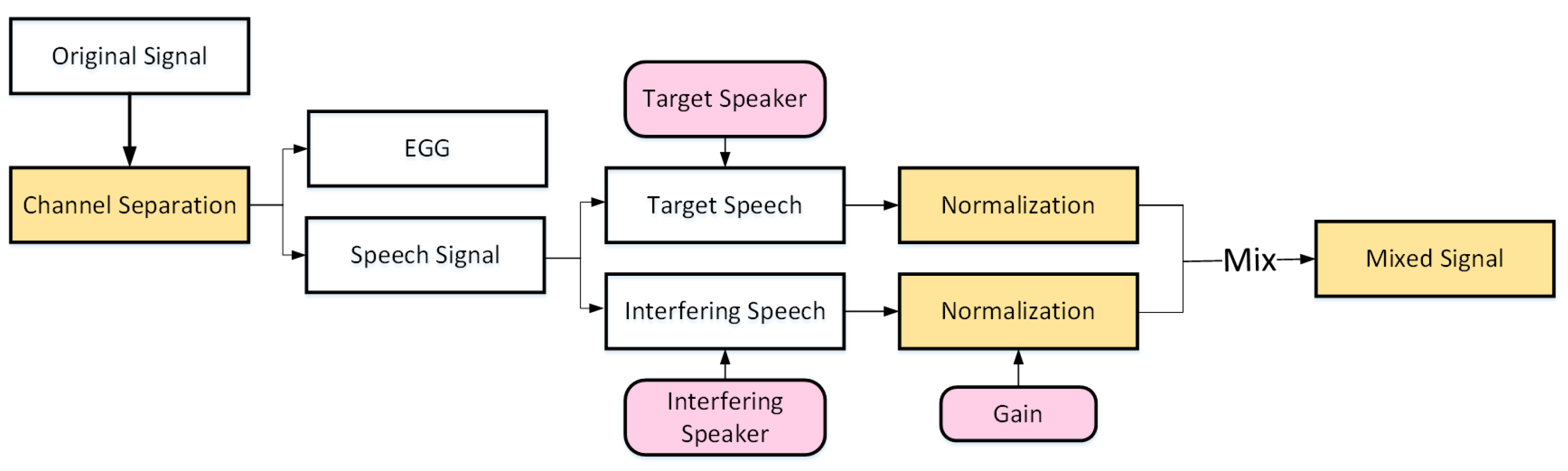
3.2.2. The Processing of the Datasets
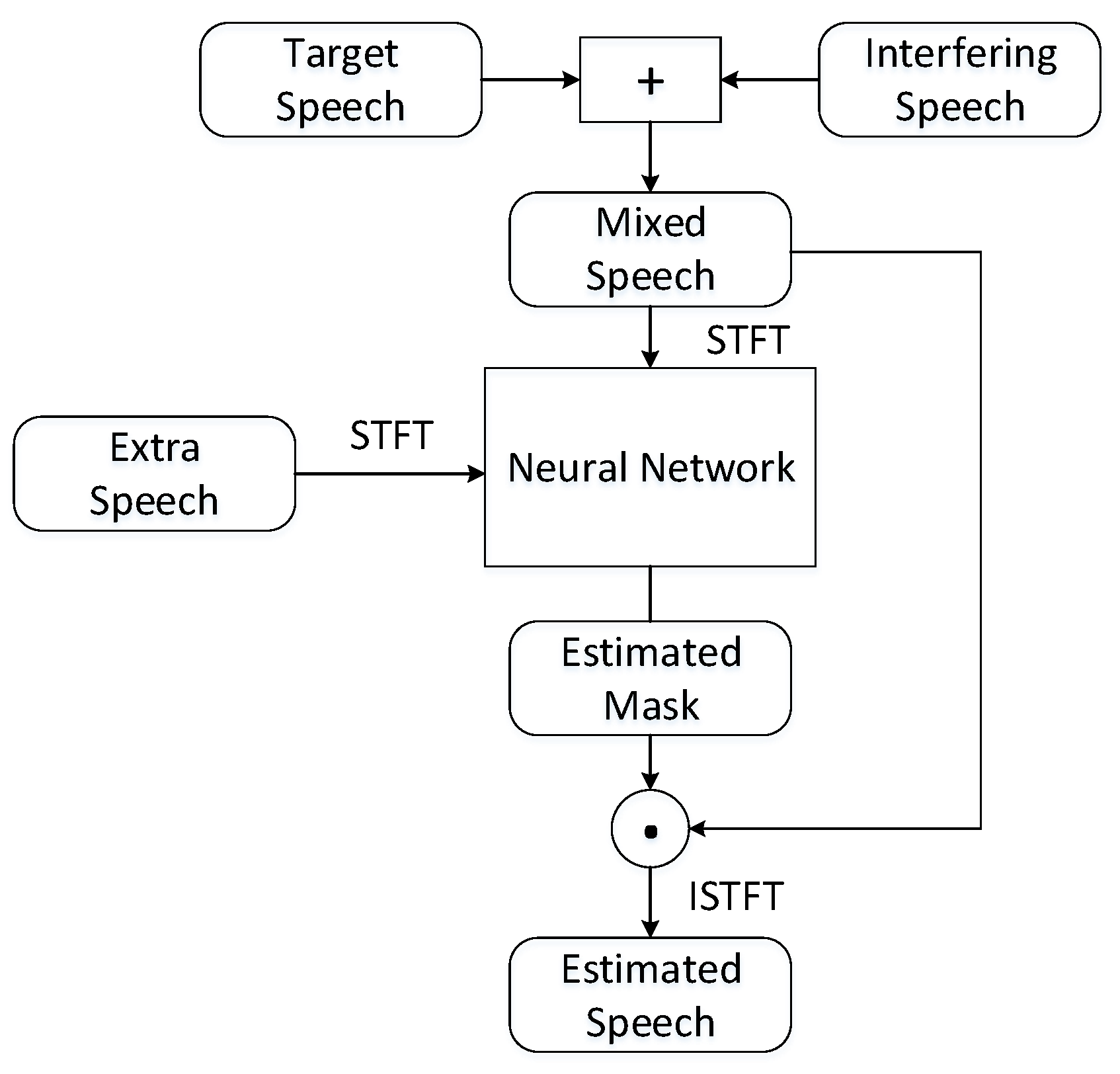
3.2.3. Model for Electroglottograph Speech Extraction
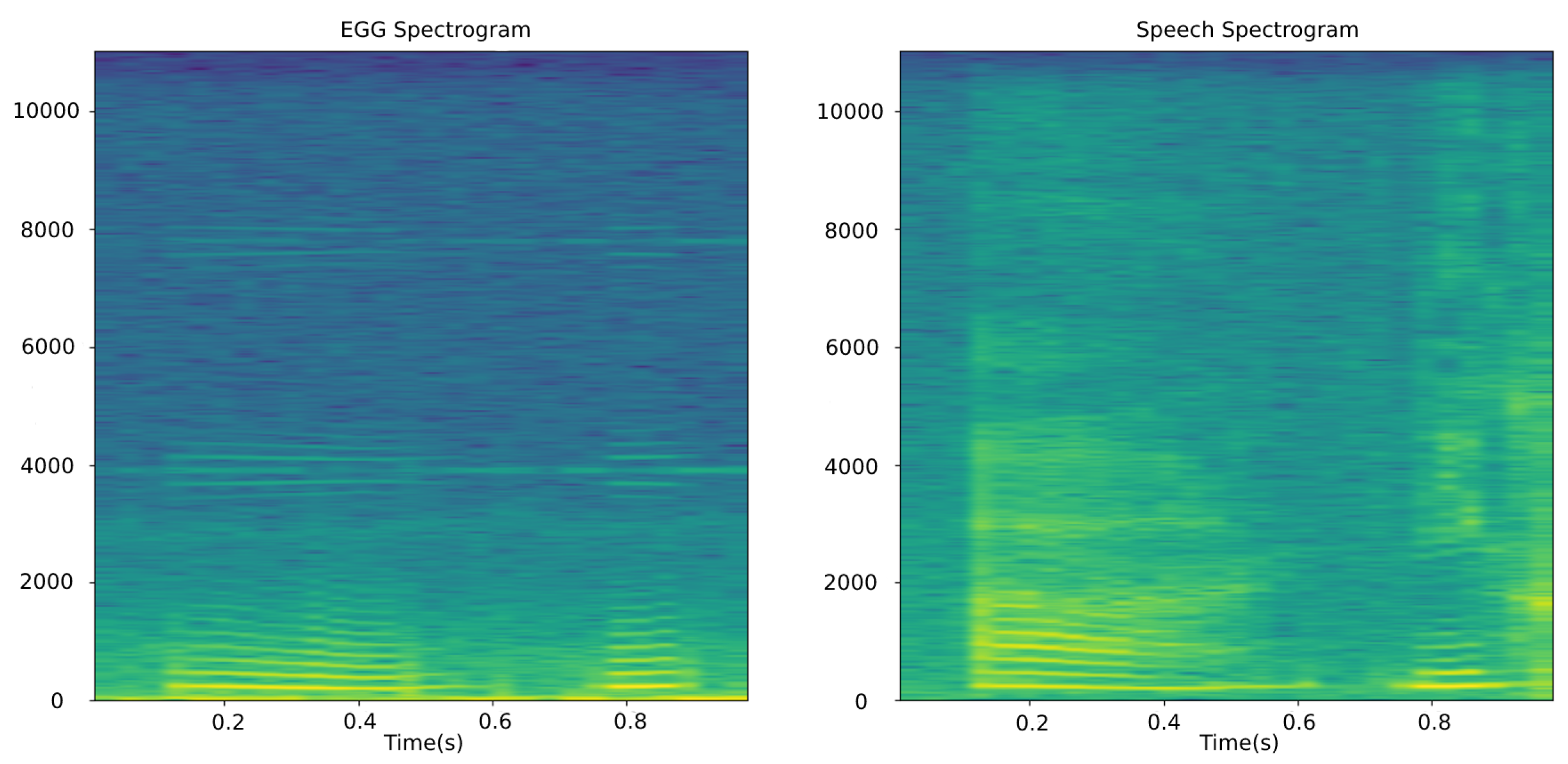
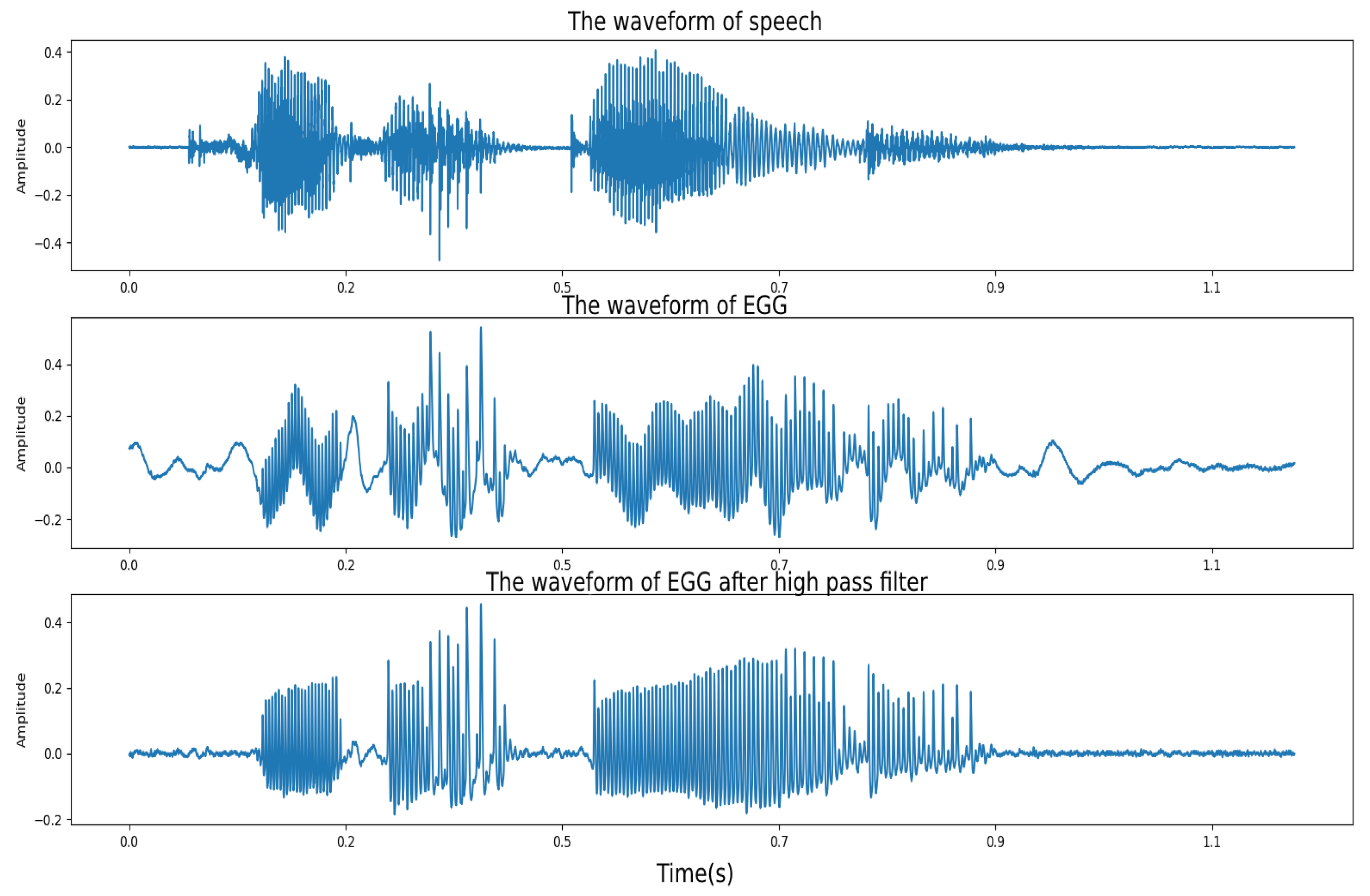
3.2.4. The Electroglottograph Pre_Processing Algorithm
4. Experiments and Results
4.1. Experiments
4.1.1. Datasets
4.1.2. Experimental Settings
4.2. Results
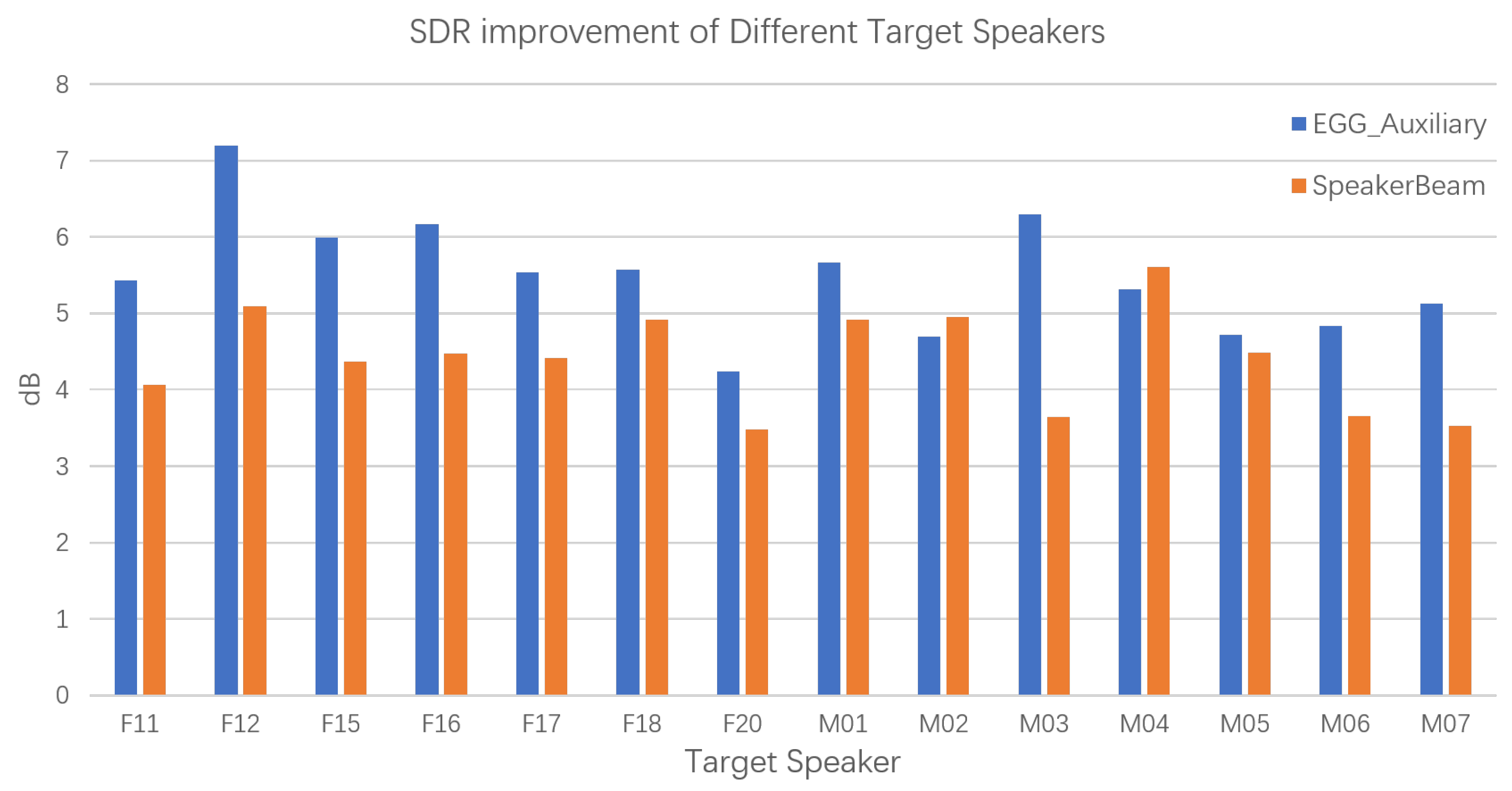
4.2.1. Comparison to SpeakerBeam
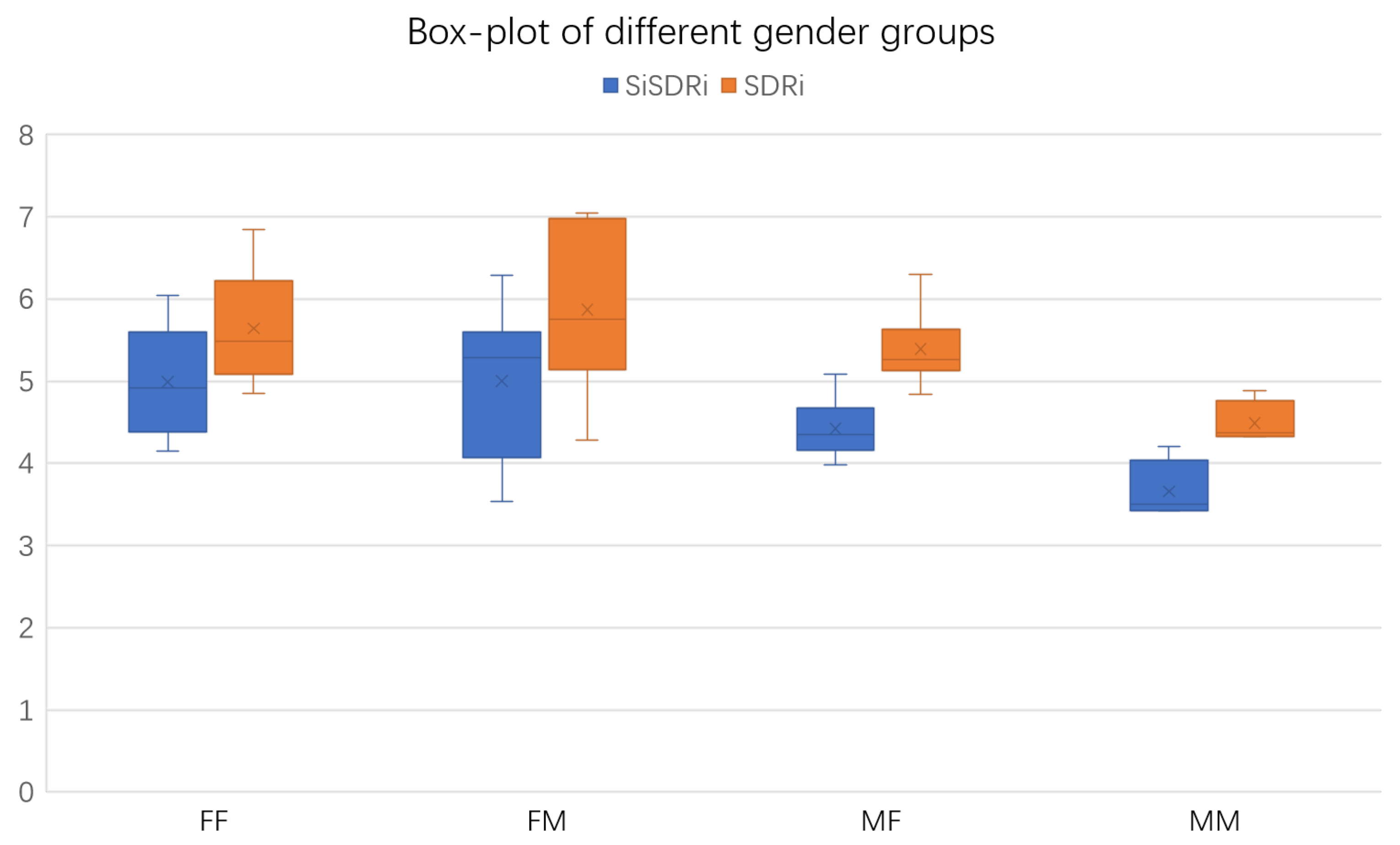
4.2.2. Comparison between Genders
4.2.3. Comparisons between Different SNRs

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR (dB) | −5 | −2.5 | 0 | 2.5 | 5 |
|---|---|---|---|---|---|
| SDR (Mixed Speech) | −3.99 | −1.41 | 1.07 | 3.10 | 6.11 |
| SDR (Prediction) | 5.98 | 6.74 | 6.95 | 8.87 | 11.35 |
| SISDR (Mixed Speech) | −4.00 | −1.41 | 1.07 | 4.08 | 6.11 |
| SISDR (Prediction) | 4.70 | 6.74 | 7.35 | 9.45 | 11.08 |
| SDRi | 9.97 | 8.15 | 6.95 | 5.77 | 5.25 |
| SISDRi | 8.70 | 7.15 | 6.29 | 5.37 | 4.97 |



5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haykin, S.; Chen, Z. The Cocktail Party Problem. Neural Comput. 2005, 17, 1875–1902. [Google Scholar] [CrossRef] [PubMed]
- Brown, J.A.; Bidelman, G.M. Familiarity of Background Music Modulates the Cortical Tracking of Target Speech at the & ldquo; Cocktail Party & rdquo. Brain Sci. 2022, 12, 1320. [Google Scholar] [CrossRef] [PubMed]
- Christian, Y.; Darmawan, I. Rindik rod sound separation with spectral subtraction method. J. Phys. Conf. Ser. 2021, 1810, 012018. [Google Scholar] [CrossRef]
- Amarjouf, M.; Bahja, F.; Martino, J.D.; Chami, M.; Elhaj, E.H.I. Denoising Esophageal Speech using Combination of Complex and Discrete Wavelet Transform with Wiener filter and Time Dilated Fourier Cepstra. In Proceedings of the 4th International Conference on Computing and Wireless Communication Systems (ICCWCS 2022), Tangier, Morocco, 21–23 June 2022. [Google Scholar]
- Luo, Y. A Time-domain Generalized Wiener Filter for Multi-channel Speech Separation. arXiv 2021, arXiv:2112.03533. [Google Scholar]
- Roux, J.L.; Hershey, J.R.; Weninger, F. Deep NMF for speech separation. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015. [Google Scholar]
- Wisdom, S.; Powers, T.; Pitton, J.; Atlas, L. Deep recurrent NMF for speech separation by unfolding iterative thresholding. In Proceedings of the 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017. [Google Scholar]
- Kłosowski, P. A Rule-Based Grapheme-to-Phoneme Conversion System. Appl. Sci. 2022, 12, 2758. [Google Scholar] [CrossRef]
- Brown, G.J.; Cooke, M. Computational auditory scene analysis. Comput. Speech Lang. 1994, 8, 297–336. [Google Scholar] [CrossRef]
- Dana, B.; Israel, N.; Joel, S. Auditory Streaming as an Online Classification Process with Evidence Accumulation. PLoS ONE 2015, 10, e0144788. [Google Scholar]
- Wang, D.; Brown, G. Computational Auditory Scene Analysis: Principles, Algorithms and Applications. IEEE Trans. Neural Netw. 2008, 19, 199. [Google Scholar]
- Mill, R.W.; B?Hm, T.M.; Bendixen, A.; Winkler, I.; Denham, S.L.; Sporns, O. Modelling the Emergence and Dynamics of Perceptual Organisation in Auditory Streaming. PLoS Comput. Biol. 2013, 9, e1002925. [Google Scholar] [CrossRef] [Green Version]
- Cheng, S.; Shen, Y.; Wang, D. Target Speaker Extraction by Fusing Voiceprint Features. Appl. Sci. 2022, 12, 8152. [Google Scholar] [CrossRef]
- Higuchi, T.; Ito, N.; Yoshioka, T.; Nakatani, T. Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar]
- Buchner, H.; Aichner, R.; Kellermann, W. A generalization of blind source separation algorithms for convolutive mixtures based on second-order statistics. IEEE Trans. Speech Audio Process. 2005, 13, 120–134. [Google Scholar] [CrossRef]
- Vincent, E.; Barker, J.; Watanabe, S.; Roux, J.L.; Nesta, F.; Matassoni, M. The second ’CHiME’ Speech Separation and Recognition Challenge: Datasets, tasks and baselines. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Al-Barhan, H.A.; Elyass, S.M.; Saeed, T.R.; Hatem, G.M.; Ziboon, H.T. Modified Speech Separation Deep Learning Network Based on Hamming window. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1076, 012059. [Google Scholar] [CrossRef]
- Nandal, P. Speech Separation Using Deep Learning; Sustainable Communication Networks and Application. In Proceedings of the International Conference on Security and Communication Networks (ICSCN), Erode, India, 6–7 August 2020. [Google Scholar]
- Liu, C.; Inoue, N.; Shinoda, K. Joint training of speaker separation and speech recognit ion based on deep learning. In Proceedings of the ASJ 2017 Autumn Meeting, Tokyo, Japan, 25 September 2017. [Google Scholar]
- Elminshawi, M.; Mack, W.; Chakrabarty, S.; Habets, E. New Insights on Target Speaker Extraction. arXiv 2022, arXiv:2202.00733. [Google Scholar]
- Ji, X.; Yu, M.; Zhang, C.; Su, D.; Yu, D. Speaker-Aware Target Speaker Enhancement by Jointly Learning with Speaker Embedding Extraction. In Proceedings of the ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Zhang, C.; Yu, M.; Weng, C.; Yu, D. Towards Robust Speaker Verification with Target Speaker Enhancement. arXiv 2021, arXiv:2103.08781. [Google Scholar]
- Pan, Z.; Ge, M.; Li, H. A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker Extraction. arXiv 2022, arXiv:2203.16843. [Google Scholar]
- Wang, F.L.; Lee, H.S.; Tsao, Y.; Wang, H.M. Disentangling the Impacts of Language and Channel Variability on Speech Separation Networks. arXiv 2022, arXiv:2203.16040. [Google Scholar]
- Hershey, J.R.; Chen, Z.; Roux, J.L.; Watanabe, S. Deep clustering: Discriminative embeddings for segmentation and separation. arXiv 2016, arXiv:1508.04306. [Google Scholar]
- Yu, D.; Kolbk, M.; Tan, Z.H.; Jensen, J. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Yousefi, M.; Hansen, J. Single-channel speech separation using Soft-minimum Permutation Invariant Training. arXiv 2021, arXiv:2111.08635. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Luo, Y.; Han, C.; Li, J.; Yoshioka, T.; Zhou, T.; Delcroix, M.; Kinoshita, K.; Boeddeker, C.; Qian, Y. Dual-Path RNN for Long Recording Speech Separation. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021. [Google Scholar]
- Wang, Q.; Sridhar, P.; Moreno, I.L.; Muckenhirn, H. Targeted voice separation by speaker conditioned on spectrogram masking. arXiv 2020, arXiv:1810.04826. [Google Scholar]
- Zmolikova, K.; Delcroix, M.; Kinoshita, K.; Higuchi, T.; Cernocky, J. Optimization of Speaker-Aware Multichannel Speech Extraction with ASR Criterion. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Žmolíková, K.; Delcroix, M.; Kinoshita, K.; Ochiai, T.; Nakatani, T.; Burget, L.; Černocký, J. SpeakerBeam: Speaker Aware Neural Network for Target Speaker Extraction in Speech Mixtures. IEEE J. Sel. Top. Signal Process. 2019, 13, 800–814. [Google Scholar] [CrossRef]
- Delcroix, M.; Zmolikova, K.; Ochiai, T.; Kinoshita, K.; Araki, S.; Nakatani, T. Compact Network for Speakerbeam Target Speaker Extraction. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6965–6969. [Google Scholar] [CrossRef]
- Xiao, T.; Mo, J.; Hu, W.; Chen, D.; Wu, Q. Single-channel speech separation method based on attention mechanism. J. Phys. Conf. Ser. 2022, 2216, 012049. [Google Scholar] [CrossRef]
- Ochiai, T.; Delcroix, M.; Kinoshita, K.; Ogawa, A.; Nakatani, T. Multimodal SpeakerBeam: Single Channel Target Speech Extraction with Audio-Visual Speaker Clues. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Delcroix, M.; Ochiai, T.; Zmolikova, K.; Kinoshita, K.; Tawara, N.; Nakatani, T.; Araki, S. Improving Speaker Discrimination of Target Speech Extraction With Time-Domain Speakerbeam. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 691–695. [Google Scholar] [CrossRef] [Green Version]
- Baken, R.J. Electroglottography. J. Voice 1992, 6, 98–110. [Google Scholar] [CrossRef]
- Herbst, C.T. Electroglottography—An Update. J. Voice 2020, 34, 503–526. [Google Scholar] [CrossRef] [PubMed]
- Childers, D.; Krishnamurthy, A. A critical review of electroglottography. Crit. Rev. Biomed. Eng. 1985, 12, 131–161. [Google Scholar] [PubMed]
- Chen, L.; Ren, J.; Chen, P.; Mao, X.; Zhao, Q. Limited text speech synthesis with electroglottograph based on Bi-LSTM and modified Tacotron-2. Appl. Intell. 2022, 52, 15193–15209. [Google Scholar] [CrossRef]
- Fourcin, A.; Abberton, E.; Miller, D.; Howells, D. Laryngograph: Speech pattern element tools for therapy, training and assessment. Int. J. Lang. Commun. Disord. 1995, 30, 101–115. [Google Scholar] [CrossRef]
- Bous, F.; Ardaillon, L.; Roebel, A. Semi-supervised learning of glottal pulse positions in a neural analysis-synthesis framework. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2020. [Google Scholar]
- Cangi, M.E.; Ylmaz, G. Test-Retest Reliability of Electroglottography Measurement. J. Acad. Res. Med. 2021, 11, 126–136. [Google Scholar] [CrossRef]
- Chen, P.; Chen, L.; Mao, X. Content Classification With Electroglottograph. J. Phys. Conf. Ser. 2020, 1544, 012191. [Google Scholar] [CrossRef]
- Chen, L.; Ren, J.; Mao, X.; Zhao, Q. Electroglottograph-Based Speech Emotion Recognition via Cross-Modal Distillation. Appl. Sci. 2022, 12, 4338. [Google Scholar] [CrossRef]
- Jing, S.; Mao, X.; Chen, L.; Zhang, N. Annotations and consistency detection for Chinese dual-mode emotional speech database. J. Bjing Univ. Aeronaut. Astronaut. 2015, 41, 1925. [Google Scholar]
- Atal, B. A pattern recognition approach to voiced-unvoiced-silence classification with applications to speech recognition. IEEE Trans. Acoust. Speech Signal Process. 2003, 24, 201–212. [Google Scholar] [CrossRef]
- molíková, K.; Delcroix, M.; Kinoshita, K.; Higuchi, T.; Nakatani, T. Speaker-Aware Neural Network Based Beamformer for Speaker Extraction in Speech Mixtures. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Li, C.; Qian, Y. Deep Audio-Visual Speech Separation with Attention Mechanism. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Fan, C.; Tao, J.; Liu, B.; Yi, J.; Wen, Z.; Liu, X. Deep Attention Fusion Feature for Speech Separation with End-to-End Post-filter Method. arXiv 2020, arXiv:2003.07544. [Google Scholar]
- Chen, L.; Mao, X.; Yan, H. Text-Independent Phoneme Segmentation Combining EGG and Speech Data. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1029–1037. [Google Scholar] [CrossRef]
- Attrapadung, N.; Hamada, K.; Ikarashi, D.; Kikuchi, R.; Matsuda, T.; Mishina, I.; Morita, H.; Schuldt, J. Adam in Private: Secure and Fast Training of Deep Neural Networks with Adaptive Moment Estimation. arXiv 2021, arXiv:2106.02203. [Google Scholar] [CrossRef]









| Gender Distribution | Length Distribution | |||
|---|---|---|---|---|
| Male | Female | <1 s | ≥1 s, <2 s | ≥2 s |
| 743 | 3926 | 1550 | 7839 | 1974 |
| Training Sets | Test Sets | |||||
|---|---|---|---|---|---|---|
| Speakers | Mixtures | Target | Speakers | Mixtures | Target | |
| CDESD | 20 | 63,000 | 9000 | 20 | 7000 | 1000 |
| EMO-DB | 10 | 16,200 | 3240 | 10 | 1800 | 360 |
| Model | Training Dataset | SDRi (dB) | SISDRi (dB) |
|---|---|---|---|
| SpeakerBeam | CDESD | 3.43 | 4.39 |
| EGG_Aux | CDESD | 4.55 | 5.25 |
| Pre_EGG_Aux | CDESD | 4.58 | 5.28 |
| Model | Training Dataset | SDRi (dB) | SISDRi (dB) |
|---|---|---|---|
| SpeakerBeam | EMODB | 2.28 | 0.99 |
| Pre_EGG_Aux | EMODB | 3.69 | 2.71 |
| Model | FF | MM | FM | MF |
|---|---|---|---|---|
| SpeakerBeam | 3.12 | 2.46 | 3.55 | 4.58 |
| Pre_EGG_Aux | 5.12 | 3.46 | 5.37 | 4.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Mo, Z.; Ren, J.; Cui, C.; Zhao, Q. An Electroglottograph Auxiliary Neural Network for Target Speaker Extraction. Appl. Sci. 2023, 13, 469. https://doi.org/10.3390/app13010469
Chen L, Mo Z, Ren J, Cui C, Zhao Q. An Electroglottograph Auxiliary Neural Network for Target Speaker Extraction. Applied Sciences. 2023; 13(1):469. https://doi.org/10.3390/app13010469
Chicago/Turabian StyleChen, Lijiang, Zhendong Mo, Jie Ren, Chunfeng Cui, and Qi Zhao. 2023. "An Electroglottograph Auxiliary Neural Network for Target Speaker Extraction" Applied Sciences 13, no. 1: 469. https://doi.org/10.3390/app13010469
APA StyleChen, L., Mo, Z., Ren, J., Cui, C., & Zhao, Q. (2023). An Electroglottograph Auxiliary Neural Network for Target Speaker Extraction. Applied Sciences, 13(1), 469. https://doi.org/10.3390/app13010469