
Polarformer: Optic Disc and Cup Segmentation Using a Hybrid CNN-Transformer and Polar Transformation

Abstract
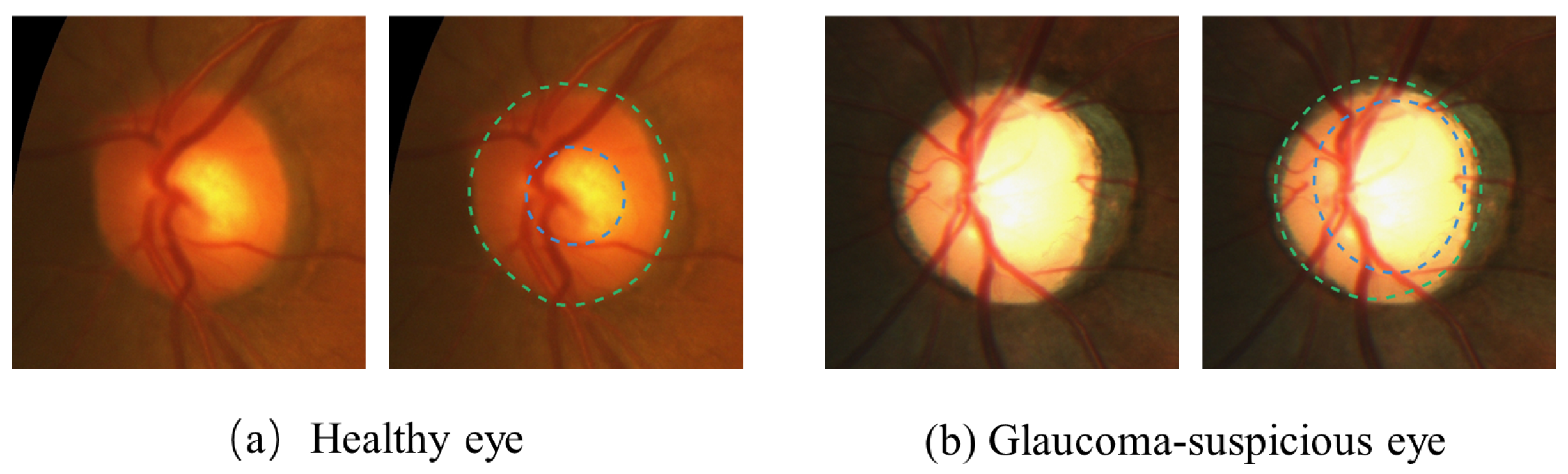
:1. Introduction
2. Related Work
2.1. Optic Disc and Cup Segmentation
2.2. Polar Transformation Networks
2.3. Transformer Models
3. The Proposed Method
3.1. Learnable Polar Transformation Module
3.1.1. Polar Origin Detector
3.1.2. Polar Converter
3.2. CNN-Transformer Module
3.2.1. Feature Pyramids Network
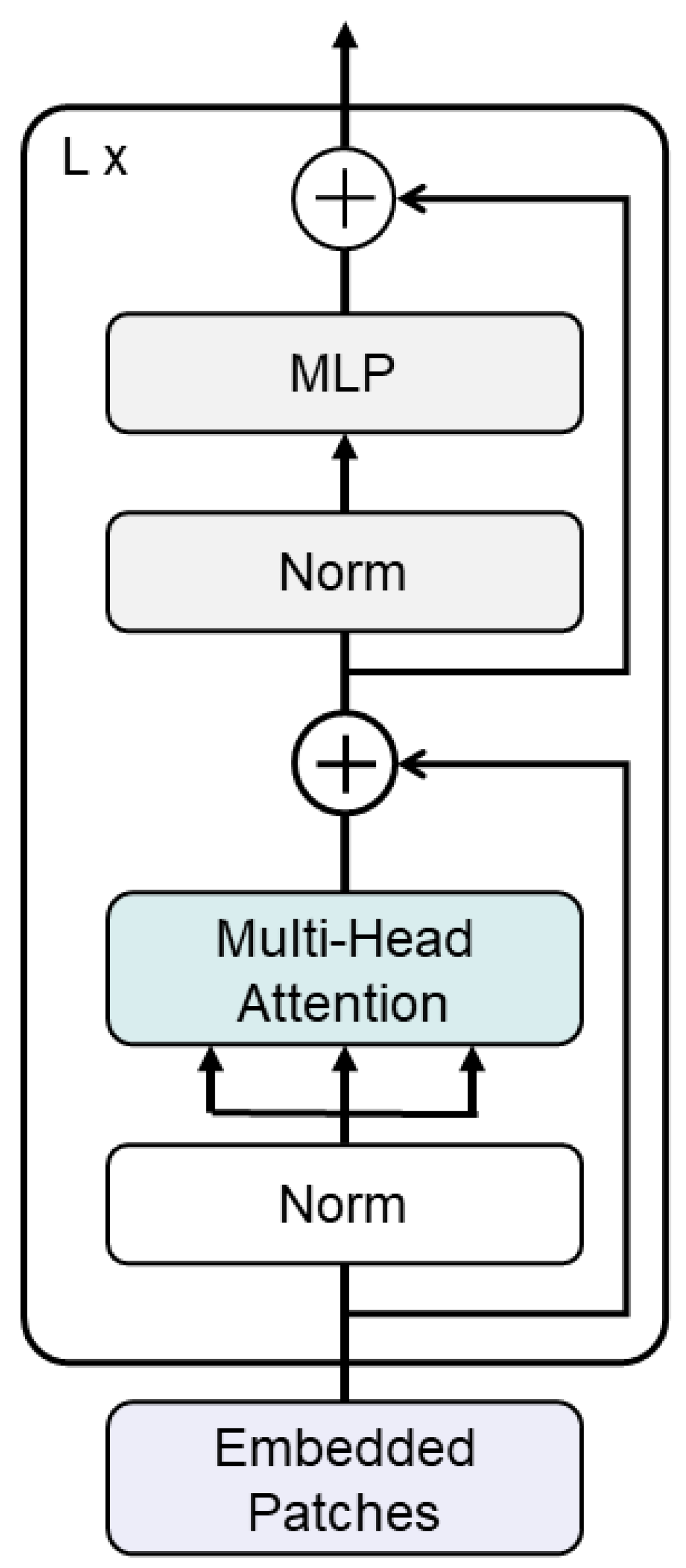
3.2.2. Transformer Module
4. Experiments and Results
4.1. Datasets and Evaluation Metrics
Evaluation Metrics
4.2. Implementation Details
4.3. Comparisons with the State of the Art
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Almazroa, A.; Burman, R.; Raahemifar, K.; Lakshminarayanan, V. Optic disc and optic cup segmentation methodologies for glaucoma image detection: A survey. J. Ophthalmol. 2015, 2015, 180972. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, L.; Wang, Z.; Wu, J.; Huang, Y.; Lyu, J.; Cheng, P.; Wu, J.; Tang, X. Bsda-net: A boundary shape and distance aware joint learning framework for segmenting and classifying octa images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 65–75. [Google Scholar]
- Aquino, A.; Gegúndez-Arias, M.E.; Marín, D. Detecting the optic disc boundary in digital fundus images using morphological, edge detection, and feature extraction techniques. IEEE Trans. Med. Imaging 2010, 29, 1860–1869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bekkers, E.J.; Loog, M.; ter Haar Romeny, B.M.; Duits, R. Template matching via densities on the roto-translation group. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 452–466. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakravarty, A.; Sivaswamy, J. Joint optic disc and cup boundary extraction from monocular fundus images. Comput. Methods Programs Biomed. 2017, 147, 51–61. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Sui, X.; Luo, X.; Xu, X.; Liu, Y.; Goh, R. Medical image segmentation using squeeze-and-expansion transformers. arXiv 2021, arXiv:2105.09511. [Google Scholar]
- Sevastopolsky, A. Optic disc and cup segmentation methods for glaucoma detection with modification of U-Net convolutional neural network. Pattern Recognit. Image Anal. 2017, 27, 618–624. [Google Scholar] [CrossRef] [Green Version]
- Tan, J.H.; Acharya, U.R.; Bhandary, S.V.; Chua, K.C.; Sivaprasad, S. Segmentation of optic disc, fovea and retinal vasculature using a single convolutional neural network. J. Comput. Sci. 2017, 20, 70–79. [Google Scholar] [CrossRef] [Green Version]
- Cheng, P.; Lin, L.; Huang, Y.; Lyu, J.; Tang, X. Prior guided fundus image quality enhancement via contrastive learning. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 521–525. [Google Scholar]
- Huang, Y.; Zhong, Z.; Yuan, J.; Tang, X. Efficient and robust optic disc detection and fovea localization using region proposal network and cascaded network. Biomed. Signal Process. Control 2020, 60, 101939. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, Y.; Fu, D.; Huang, Z.; Tong, H. Optic disc segmentation in fundus images using adversarial training. IET Image Process. 2019, 13, 375–381. [Google Scholar] [CrossRef]
- Mohan, D.; Kumar, J.H.; Seelamantula, C.S. High-performance optic disc segmentation using convolutional neural networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4038–4042. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, Z.; Fu, H.; Dai, H.; Shen, J.; Pang, Y.; Shao, L. Et-net: A generic edge-attention guidance network for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 442–450. [Google Scholar]
- Yin, P.; Wu, Q.; Xu, Y.; Min, H.; Yang, M.; Zhang, Y.; Tan, M. PM-Net: Pyramid multi-label network for joint optic disc and cup segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 129–137. [Google Scholar]
- Salehinejad, H.; Valaee, S.; Dowdell, T.; Barfett, J. Image augmentation using radial transform for training deep neural networks. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3016–3020. [Google Scholar]
- Liu, Q.; Hong, X.; Ke, W.; Chen, Z.; Zou, B. DDNet: Cartesian-polar dual-domain network for the joint optic disc and cup segmentation. arXiv 2019, arXiv:1904.08773. [Google Scholar]
- Zahoor, M.N.; Fraz, M.M. Fast optic disc segmentation in retina using polar transform. IEEE Access 2017, 5, 12293–12300. [Google Scholar] [CrossRef]
- Jiang, R.; Mei, S. Polar coordinate convolutional neural network: From rotation-invariance to translation-invariance. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 355–359. [Google Scholar]
- Kim, J.; Jung, W.; Kim, H.; Lee, J. Cycnn: A rotation invariant cnn using polar mapping and cylindrical convolution layers. arXiv 2020, arXiv:2007.10588. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 3058. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Ali, R.; Sheng, B.; Li, P.; Chen, Y.; Li, H.; Yang, P.; Jung, Y.; Kim, J.; Chen, C.P. Optic disk and cup segmentation through fuzzy broad learning system for glaucoma screening. IEEE Trans. Ind. Inform. 2020, 17, 2476–2487. [Google Scholar] [CrossRef]
- Segman, J.; Rubinstein, J.; Zeevi, Y.Y. The canonical coordinates method for pattern deformation: Theoretical and computational considerations. IEEE TPAMI 1992, 14, 1171–1183. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1213. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Orlando, J.I.; Fu, H.; Breda, J.B.; van Keer, K.; Bathula, D.R.; Diaz-Pinto, A.; Fang, R.; Heng, P.A.; Kim, J.; Lee, J.; et al. Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med. Image Anal. 2020, 59, 101570. [Google Scholar] [CrossRef]
- Sivaswamy, J.; Krishnadas, S.R.; Datt Joshi, G.; Jain, M.; Syed Tabish, A.U. Drishti-GS: Retinal image dataset for optic nerve head(ONH) segmentation. In Proceedings of the 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI), Beijing, China, 28 April–2 May 2014; pp. 53–56. [Google Scholar] [CrossRef] [Green Version]
- Fumero, F.; Alayon, S.; Sanchez, J.L.; Sigut, J.; Gonzalez-Hernandez, M. RIM-ONE: An Open Retinal Image Database for Optic Nerve Evaluation. In Proceedings of the 2011 24th International Symposium on Computer-Based Medical Systems, Bristol, UK, 27–30 June 2011; IEEE Computer Society: Piscataway, NJ, USA, 2011. CBMS ’11. pp. 1–6. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1055–1059. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Luo, L.; Xue, D.; Pan, F.; Feng, X. Joint optic disc and optic cup segmentation based on boundary prior and adversarial learning. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 905–914. [Google Scholar] [CrossRef] [PubMed]
- Pachade, S.; Porwal, P.; Kokare, M.; Giancardo, L.; Mériaudeau, F. NENet: Nested EfficientNet and adversarial learning for joint optic disc and cup segmentation. Med. Image Anal. 2021, 74, 102253. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 263–273. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Firdaus-Nawi, M.; Noraini, O.; Sabri, M.; Siti-Zahrah, A.; Zamri-Saad, M.; Latifah, H. DeepLabv3+ _encoder-decoder with Atrous separable convolution for semantic image segmentation. Pertanika J. Trop. Agric. Sci 2011, 34, 137–143. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RIM-ONE v3 | DRISHTI-GS | REFUGE | |||
|---|---|---|---|---|---|---|
| U-Net | 0.837 | 0.948 | 0.830 | 0.945 | 0.835 | 0.951 |
| U-Net3+ | 0.843 | 0.955 | 0.833 | 0.952 | 0.837 | 0.959 |
| DeepLabV3+ | 0.857 | 0.961 | 0.842 | 0.951 | 0.855 | 0.943 |
| AttU-Net | 0.852 | 0.965 | 0.845 | 0.950 | 0.857 | 0.964 |
| M-Net | 0.862 | 0.952 | 0.859 | 0.948 | 0.864 | 0.952 |
| PraNet | 0.856 | 0.961 | 0.841 | 0.953 | 0.857 | 0.966 |
| nnU-Net | 0.865 | 0.966 | 0.862 | 0.960 | 0.876 | 0.965 |
| SETR | 0.877 | 0.965 | 0.880 | 0.954 | 0.878 | 0.955 |
| TransU-Net | 0.874 | 0.954 | 0.883 | 0.944 | 0.877 | 0.964 |
| BGA-Net | 0.872 | 0.967 | 0.898 | 0.975 | ✗ | ✗ |
| NENet | ✗ | ✗ | 0.840 | 0.963 | ✗ | ✗ |
| Polarformer(R101) | 0.888 | 0.968 | 0.893 | 0.974 | 0.890 | 0.975 |
| Polarformer(eff-B4) | 0.895 | 0.972 | 0.901 | 0.977 | 0.892 | 0.974 |
| Model | DRISHTI-GS | REFUGE | RIM-ONE v3 | |||
|---|---|---|---|---|---|---|
| ResNet-101 | Eff-B4 | ResNet-101 | Eff-B4 | ResNet-101 | Eff-B4 | |
| Baseline | 0.881 | 0.870 | 0.873 | 0.876 | 0.868 | 0.872 |
| w/o POD | 0.887 | 0.890 | 0.884 | 0.887 | 0.882 | 0.885 |
| w/o Transformer | 0.878 | 0.882 | 0.885 | 0.880 | 0.879 | 0.882 |
| Polarformer | 0.893 | 0.901 | 0.890 | 0.893 | 0.888 | 0.895 |
| Method | REFUGE | |
|---|---|---|
| U-Net (R101 scratch) | 0.825 | 0.948 |
| U-Net (R101 pretrain) | 0.835 | 0.951 |
| Ours (R101 scratch) | 0.881 | 0.960 |
| Ours (R101 pretrain) | 0.892 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Li, Z.; Yang, D.; Hu, H.; Guo, H.; Liu, H. Polarformer: Optic Disc and Cup Segmentation Using a Hybrid CNN-Transformer and Polar Transformation. Appl. Sci. 2023, 13, 541. https://doi.org/10.3390/app13010541
Feng Y, Li Z, Yang D, Hu H, Guo H, Liu H. Polarformer: Optic Disc and Cup Segmentation Using a Hybrid CNN-Transformer and Polar Transformation. Applied Sciences. 2023; 13(1):541. https://doi.org/10.3390/app13010541
Chicago/Turabian StyleFeng, Yaowei, Zhendong Li, Dong Yang, Hongkai Hu, Hui Guo, and Hao Liu. 2023. "Polarformer: Optic Disc and Cup Segmentation Using a Hybrid CNN-Transformer and Polar Transformation" Applied Sciences 13, no. 1: 541. https://doi.org/10.3390/app13010541
APA StyleFeng, Y., Li, Z., Yang, D., Hu, H., Guo, H., & Liu, H. (2023). Polarformer: Optic Disc and Cup Segmentation Using a Hybrid CNN-Transformer and Polar Transformation. Applied Sciences, 13(1), 541. https://doi.org/10.3390/app13010541