1. Introduction
With the rapid development of media, the amount of video data is increasing exponentially in real life. Therefore, the research topic of video understanding has received much attention [
1,
2,
3], especially temporal action localization (TAL), which is a fundamental task in the field of video understanding. TAL aims to predict the semantic labels of actions and their corresponding start and end times, which provides convenience for the development of various applications such as video recommendation, security monitoring, and sports analysis.
To solve TAL tasks better, many two-stage and one-stage methods have been proposed [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. The two-stage TAL methods [
7,
17] follow a proposal-then-classification paradigm, where generating high-quality action proposals is fundamental for their high-level performance. Different from two-stage methods, one-stage ones [
8,
18] aim to localize actions in a single shot without requiring any action proposals. Many one-stage methods are anchor-based and adjust predefined anchors to perform action localization [
8]. However, because the anchors are fixed, the anchor-based approaches lack flexibility in adapting to various action classes. Recently, to capture semantic information better, many anchor-free methods [
5,
10] have been proposed to localize actions. Specifically, they classify each time step in videos and generate behavior boundaries. In addition, recently many anchor-free methods have adopted Transformer [
19] as their backbone, because Transformer with self-attention mechanisms can better capture and model information for video sequences.
However, methods leveraging global self-attention (e.g., [
9]) may ignore local variances, which may potentially result in poor performance. To solve this problem, local self-attention mechanisms have been employed in some methods (e.g., [
10]), which may result in the loss of some global information. Additionally, both global and local self-attention methods have been found to conflate the embeddings of segments within a given attention range, and thereby may reduce the discriminative quality of these features [
20]. To pursue high performance, preserving the most salient traits of local clip embeddings is crucial [
21].
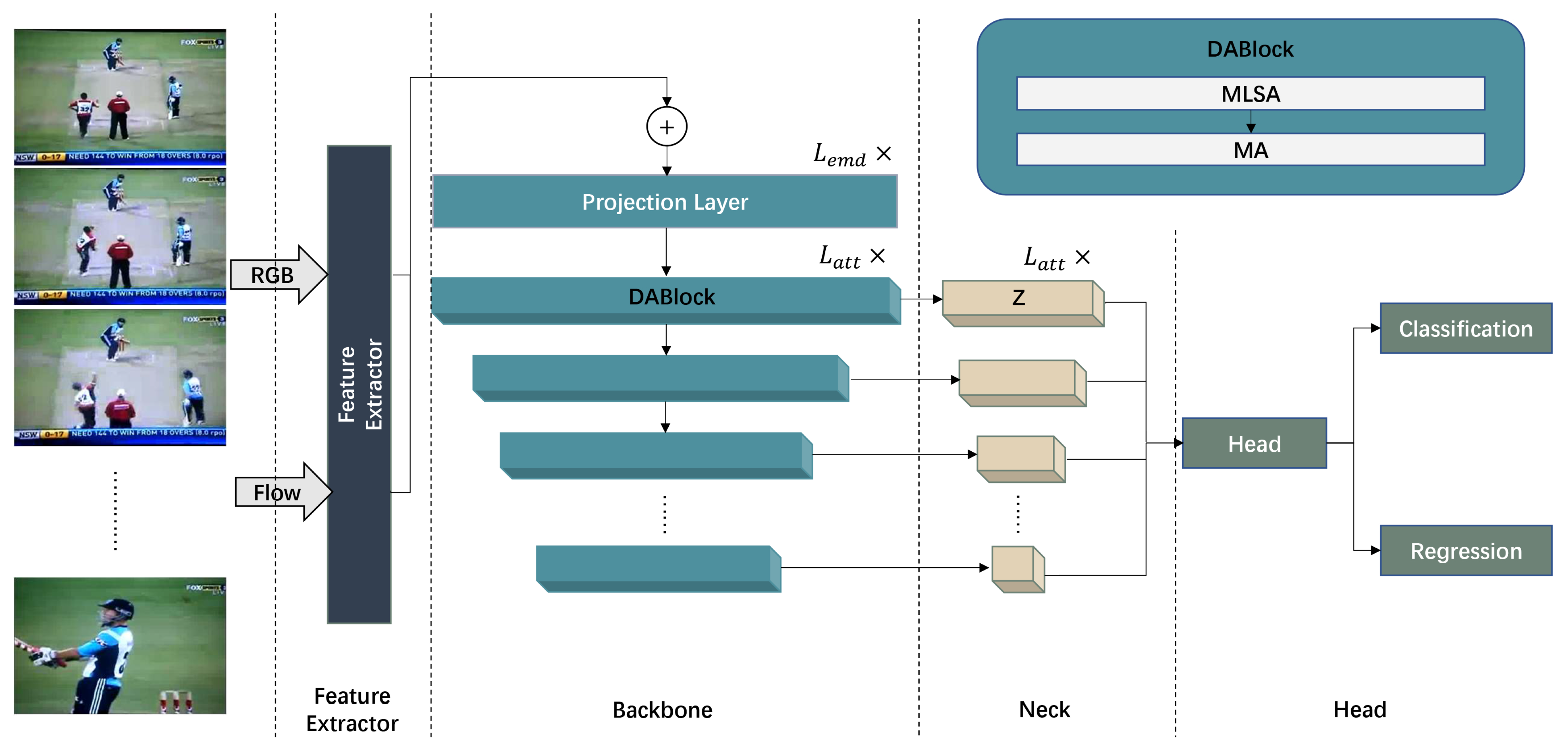
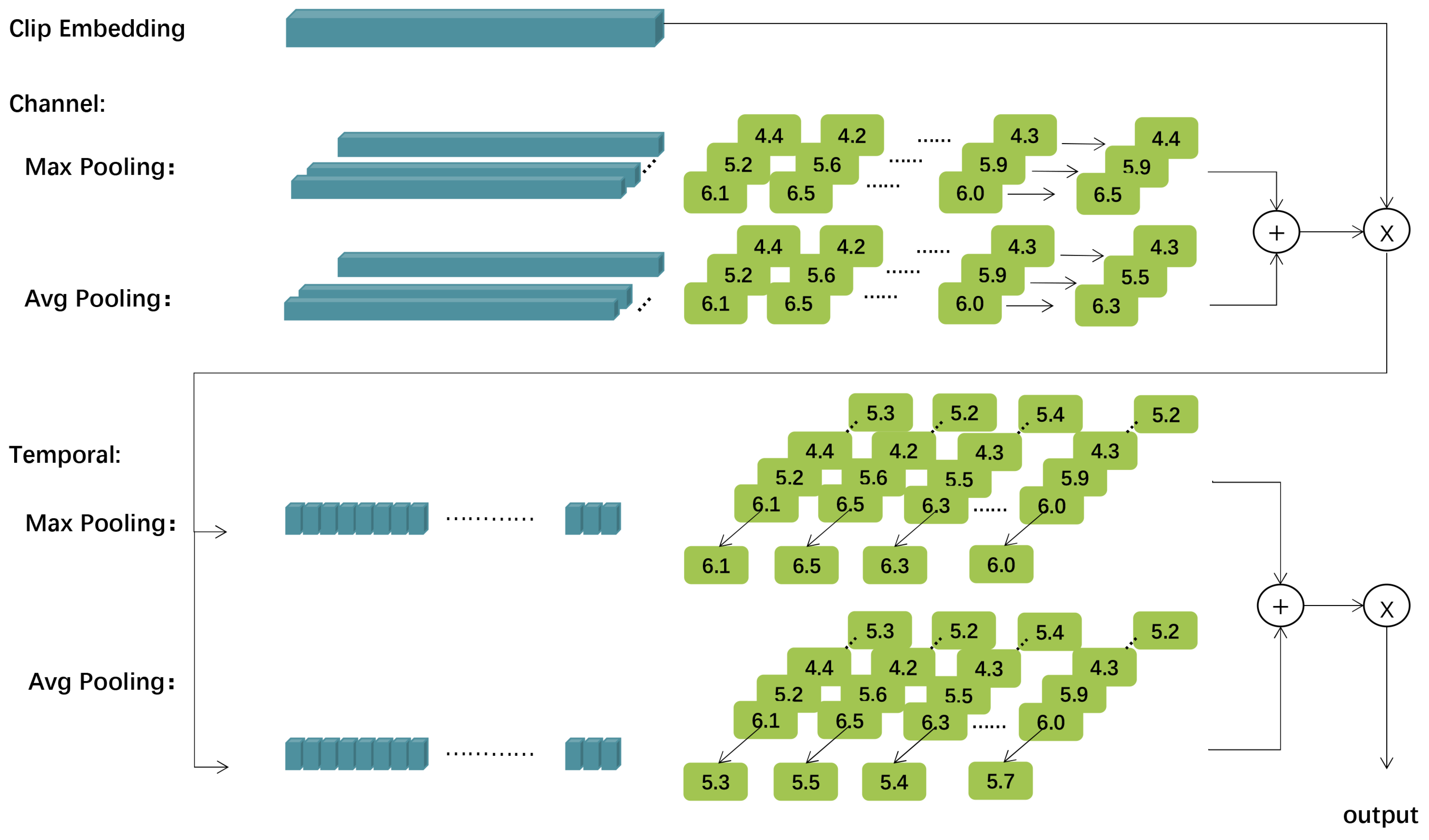
Therefore, to facilitate more comprehensive modeling of temporal information, we propose a model named the double attention network (DANet), comprising more advanced blocks, e.g., double attention block (DABlock), featurized image pyramid (FIP), and classification and regression head (CRHead). Specifically, to model both global and local information simultaneously and maintain the most salient traits of local clip embeddings, we design two attention mechanisms for DABlock, namely multi-headed local self-attention (MLSA) and max-average pooling attention (MA). Among these, MLSA only models local temporal context, while MA extracts information from local clip embeddings and aggregates global information. Specifically, MA retains the most critical features from local embeddings by using max-pooling and also aggregates global features by average-pooling and generates corresponding attention weights (see
Section 3.2 for more details). Adopting these kind of attention mechanisms can help preserve all the discriminative information of local clip embeddings. In addition, we adopt the FIP as the neck of model to focus better local changes and use CRHead to predict the semantic labels of actions (see
Section 3.3 and
Section 3.4 for more details).
To assess the performance of DANet, we conduct extensive experiments on two TAL task datasets, namely THUMOS14 [
22] and ActivityNet1.3 [
23] datasets. On the THUMOS14 dataset, DANet achieves a mean average precision (mAP) of 66.56%, a mAP of 78.2% at the time Intersection over Union (tIoU) = 0.4, and a mAP of 58.7% at tIoU = 0.6. Compared with the state-of-the-art method ActionFormer [
10], for average mAP and mAP at tIoU of 0.4 and 0.6, respectively, our method outperforms ActionFormer by over one percentage point. In addition, DANet also outperforms all two-stage methods such as AFSD [
5], PBRNet [
24], and GTAN [
8], as well as the other one-stage methods such as RTD-Net [
25], ContextLoc [
26], BMN-CSA [
27], and MUSES [
6]. In addition, through conducting comprehensive ablation studies, we not only demonstrate the effectiveness of MLSA and MA, but also investigate the impact of some hyper-parameters on the experimental results, such as the number of projection layers, path aggregation, and the adopted normalization method (see
Section 4.3).
The key contributions of this work are as follows:
To enable comprehensive contextual modeling of temporal information, we propose a model named DANet comprising MLSA and MA. MLSA models temporal context by local self-attention. MA aggregates global feature information.
To preserve the salient characteristics of local clip embeddings, MA returns discriminative features by using max-pooling in both channel and temporal dimensions as well as generates attention weights.
Compared with other methods, DANet achieves the best performance on THUMOS14 and ActivityNet1.3 datasets. In addition, ablation studies demonstrate the effectiveness of MLSA and MA as well as the adopted hyper-parameters.
4. Experiments and Results
In this section, we first introduce the datasets used to assess the performance of DANet and the experimental setups in
Section 4.1. Next, we compare DANet with existing state-of-the-art methods on THUMOS14 [
22] and ActivityNet1.3 [
23] datasets. Subsequently, we conduct extensive ablation studies to analyze the effectiveness of the proposed MLSA and MA, the number of projection layers, and the other hyper-parameters adopted in
Section 4.3. Finally, in
Section 4.4, we provide visualizations of our experimental results to gain a more comprehensive understanding of the effectiveness of the proposed approach.
4.1. Datasets and Experimental Setups
To assess the performance of the proposed DANet better, in this section, we adopt mean average precision (mAP) and time Intersection over Union (tIoU) as metrics, following the prior studies [
9,
10]. The time Intersection over Union (tIoU) measures the degree of overlap between two temporal windows using the 1D Jaccard index. Specifically, the mAP is commonly used to assess the effectiveness of methods at various temporal intersections across all datasets. In addition, the mAP metric computes the average precision across all action categories given a tIoU threshold, while the average mAP is obtained by averaging multiple tIoUs.
In addition, there are two datasets used in this section, namely THUMOS14 and ActivityNet1.3. The THUMOS14 and ActivityNet1.3 datasets are well-established benchmark datasets in the field of action recognition, renowned for their diverse and challenging video content. These datasets have garnered substantial recognition and have been extensively utilized in numerous prior research studies [
5,
9,
10]. Specifically, the THUMOS14 dataset consists of 413 untrimmed videos and 20 action categories for our experimentation. The dataset is divided into a training set and a test set. The training set comprises 200 videos and the test set includes 213 videos, which contain 3007 and 3358 action instances, respectively. Notably, the average duration of an action instance is 5 s. To extract features from our videos, following [
39], we employ a pre-trained 3D CNN network, e.g., I3D model [
37]. Our process involves extracting a number of
J RGB frames and a number of
J optical flows from each video, and then feeding a number of 16 consecutive frames into I3D. Before the final fully connected layer, we extract 1024-dimensional RGB features and 1024-dimensional flow features, which are then merged into 2048-dimensional features and used as input of our model. In our experiment, the following hyper-parameters are used: the input dimension is set to 2048, the batch size is set to 1, and the maximum sequence length is set to 12,672. By conducting preliminary experiments, the level of the feature pyramid is set to 6, the training epoch is set to 30, and the linear warm-up epoch is set to 5 (see
Section 4.3.7 for more details about warm-up). Finally, the initial learning rate is set to 1 × 10
−4, and the weight decay is set to 0.05, following a prior study [
10]. We use mAP@[0.3:0.1:0.7] to evaluate our model, referring to computing the corresponding mAP at each tIoU interval from 0.3 to 0.7 with an interval of 0.1.
ActivityNet1.3 is a vast action-oriented dataset comprising 200 activity categories and over 20,000 videos, totaling 600+ h. Following the prior studies [
4,
7,
40], we train our model on the training set. Similar to THUMOS14, we utilize features extracted from the I3D model [
37]. The features are extracted from non-overlapping clips of 16 frames and a stride of 16 frames. By conducting preliminary experiments, the training epoch is set to 15, the linear warm-up epoch is set to 5, the learning rate is set to
, the mini-batch size is set to 16, and the weight decay is set to
. We use mAP@[0.5:0.05:0.95] to evaluate our model, referring to computing the corresponding mAP at each tIoU interval from 0.5 to 0.95 with an interval of 0.05.
The experiments are conducted on a workstation with a single NVIDIA GeForce RTX 3090 card, and Intel(R) Xeon(R) Gold 6254 CPU @ 3.10 GHz.
4.2. Performance Comparison
To assess the performance of DANet comprehensively, we choose nineteen benchmarking models, including thirteen two-stage models (e.g., BMN [
7], G-TAD [
40], MUSES [
6], VSGN [
41]) and six one-stage methods (e.g., AFSD [
5], TadTR [
9], ActionFormer [
10]).
As shown in
Table 1, DANet achieves an average mAP of 66.5%, a mAP of 78.2% at tIoU = 0.4, and a mAP of 58.7% at tIoU = 0.6 on the THUMOS14 dataset. Compared with the state-of-the-art ActionFormer, DANet’s average mAP is more than 1% higher. In addition, there is an increase of over 1% at tIoU of 0.4 and 0.6, respectively. Compared with TadTR, DANet’s average mAP is more than 9% higher and has significant improvements at various tIoU levels. In addition, compared with the other existing two-stage methods and other one-stage methods, DANet outperforms all of them. The experimental results demonstrate the effectiveness of our proposed method.
In addition, we also assess the performance of all methods on the ActivityNet1.3 dataset, shown in
Table 2. Our model achieves an average mAP of 36.5, with a mAP of 54.6% at tIoU = 0.5, 37.7% at tIoU = 0.75, and 8.6% at tIoU = 0.95. Compared with existing methods, our model does not show significant improvements in mAP on the THUMOS14 dataset, but still produces competitive results. The variation in results between the THUMOS14 and ActivityNet1.3 datasets can be attributed to several factors. These datasets differ in terms of video content, annotation quality, duration, and the types of activities they contain. These variations pose different challenges for models, leading to differences in performance. Compared with ActionFormer, our model achieves a 0.4% increase in mAP at tIoU = 0.95, while, compared with TadTR, our model achieves a 4% increase in average mAP. Additionally, our model shows competitive results when compared with other one-stage and two-stage methods. Specifically, in both
Table 1 and
Table 2, all models share the exact same hyper-parameters and dataset divisions.
Our explanation for the superior performance of DANet is that we utilize our proposed DABlock to facilitate contextual modeling of temporal information at both local and global levels simultaneously and maintain the most crucial features from embeddings, which enables the model to predict the temporal boundaries of action instances with greater accuracy, thus improving the overall mAP of the model.
In addition, the computational complexity of DANet is a crucial aspect to consider in assessing its feasibility and scalability. In terms of computational complexity, DANet operates at an acceptable level, given its ability to effectively handle long-term dependencies. The primary computational burden arises from the temporal attention mechanisms, which involve calculating attention weights between each time step in the input sequence. To mitigate this computational overhead, we employ optimization techniques such as parallel computing and efficient data structures. By leveraging parallelization across multiple processors or GPUs, we distribute the attention calculations and reduce the overall runtime. In addition, we utilize optimized data structures, such as sparse matrices, to store and process attention weights efficiently.
4.3. Ablation Study
In this subsection, we conduct ablation studies to investigate the effectiveness of our proposed model and hyper-parameter settings on THUMOS14 using mAP.
4.3.1. The Effectiveness of MLSA and MA
In this subsection, we conduct the ablation study to investigate the impact of MLSA and MA. To establish a solid baseline, we initially employ a commonly used 1D convolutional network to model the temporal relationships of each backbone layer. Then we adopt the traditional Transformer Encoder with global self-attention to conduct modeling. Next, we use MLSA only for backbone without adopting MA. Finally, we adopt the final design, namely DABlock proposed in
Section 3.2, which can extract both global and local features simultaneously.
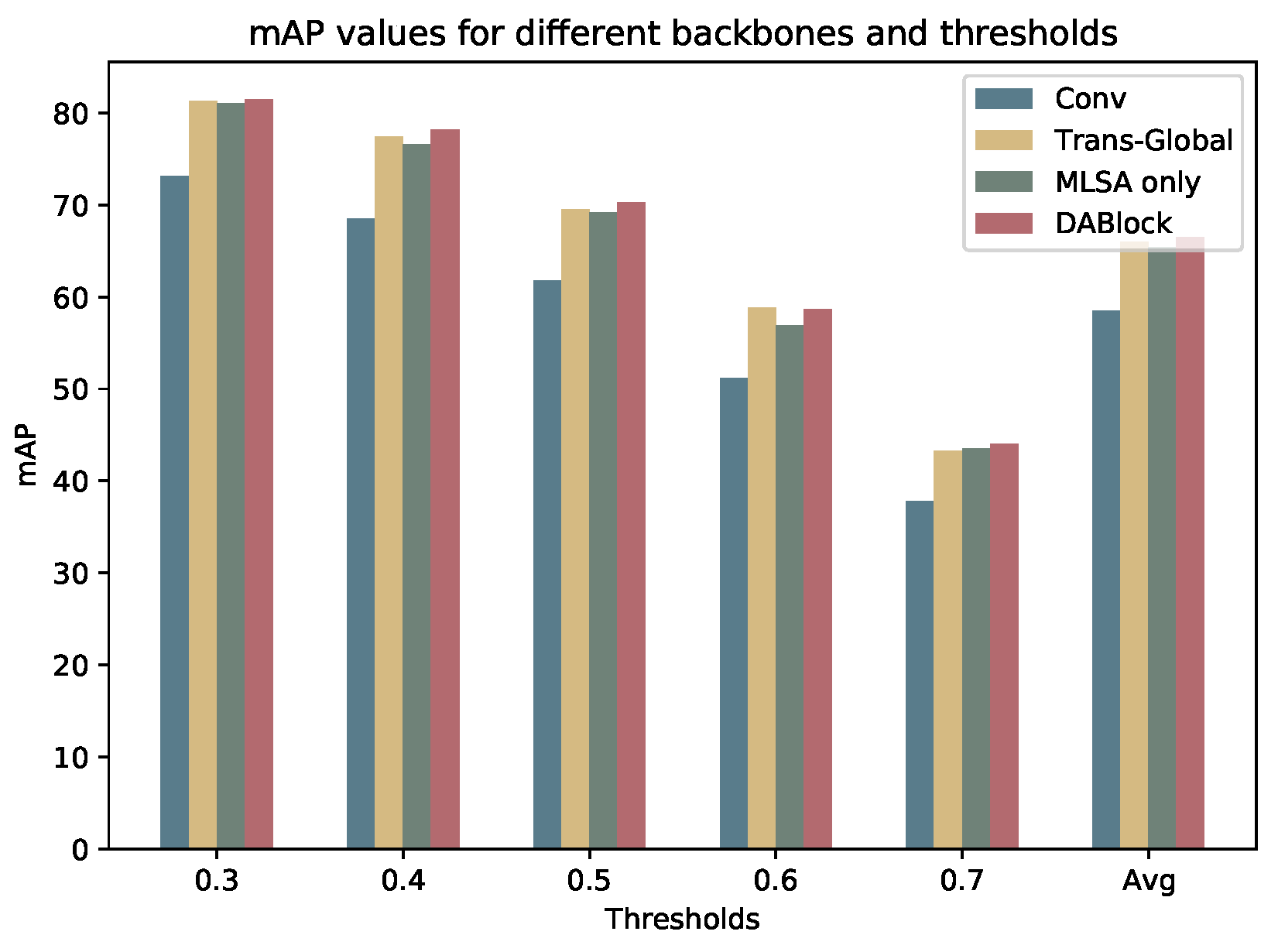
As shown in
Table 3, DABlock consisting of MLSA and MA outperforms the other structures, achieving an overall average mAP of 66.5%.
Figure 3 is the visualization of the effectiveness of MLSA and MA. In addition, convolution has the poorest performance, which demonstrates that Transformer is more suitable for TAL tasks, compared with convolution. In addition, compared with DANet, the global self-attention-based Transformer performs poorer. The plausible reason for this is that global self-attention makes the boundary blurred. When using MLSA only, the feature in time step,
t, may discard the connection with the global background. The proposed structure simultaneously focuses on the local changes between adjacent frames and models the global temporal relationship. In addition, DABlock preserves the most informative feature in local clip embedding, which helps to solve the TAL task better.
4.3.2. The Effectiveness of the Number of Projection Layers
We conduct the ablation study to investigate the impact of the number of projection layers,
, whose results are presented in
Table 4. We find an average mAP of 66.5% when the number of projection layers is set to two and observe stable mAP values when the number of layers is less than five. Notably, a poor performance of 25.7% mAP is attained when
is set to five. Through analysis, we conclude that, starting from
= 2, an increase in the number of convolution layers leads to a further transformation of features from local to global representations. Therefore, as the number of layers deepens, it becomes more challenging to process the local features further, resulting in decreased performance.
4.3.3. The Effectiveness of the Adopted Normalization
In this subsection, we investigate the effectiveness of different types of layer normalization on MLSA. Transformer architecture adopts the traditional Post-LN [
50], which involves performing the layer normalization operation after multi-headed and residual connections within the Transformer block. Different Post-LN and Pre-LN [
50] operations occur before multi-headed attention. Finally, DeepNorm [
51] aims to achieve both superior performance and training stability by upscaling the residual connection before conducting the layer normalization process.
The results are presented in
Table 5. It is evident that Pre-LN yields the highest average mAP of 66.5%, followed by Post-LN, which obtains an average mAP of 65.3%, while DeepNorm achieves an average mAP of 64.7%. Therefore, the adopted Pre-LN is reasonable.
4.3.4. The Effectiveness of the Number of Attention Layers
To investigate the effectiveness of the number of DABlock layers,
, we design five configurations, namely
= 3, 4, 5, 6, and 7, whose results are presented in
Table 6. As
increases gradually, the number of downsamplings increases, leading to the representation of higher-level temporal semantic information in the feature maps. The experimental results demonstrate that the model achieves the best performance when
is set to 6.
4.3.5. The Effectiveness of Path Aggregation
To investigate the implications of the neck design on model performance, two kinds of feature pyramid structures are tested in this subsection. Specifically, in Design1, we adopt FIP, which does not have path aggregation, i.e., the head is directly connected to its layer. In Design2, we adopt the feature pyramid network [
52], which includes path aggregation between layers. Path aggregation refers to the process of combining information from different layers in a neural network. In Design1, where path aggregation is not employed, there is a lack of integration between low-level and high-level semantic information. As a result, certain boundary information remains distinct and is not blurred.
As shown in
Table 7, when adopting Design1, the average mAP is 66.4%. In addition, when adopting Design2, the average mAP reduces by 39.5%, compared with Design1. Therefore, the adopted FIP is reasonable.
4.3.6. The Effectiveness of Loss Function
This subsection delves into the impact of loss functions on model performance. Given the regression-based nature of TAL, our analysis focuses on the effect of various regression losses on model efficacy.
The IoU loss [
53] regresses the four boundary coordinates of a candidate box as a single entity, leading to efficient and accurate regression with excellent scale invariance. In our model, this two-dimensional loss is compressed into one-dimensional space. The Generalized Intersection over Union (GIoU) loss [
54] computes the area of the smallest convex closure, C, between two shapes (like rectangle boxes), A and B, and then calculates the ratio of the area excluding A and B in C to the original area of C. Finally, the original IoU is subtracted from this ratio to obtain the generalized IoU value. The Distance-IoU (DIoU) loss [
55] calculates the normalized distance between the center points of two boundary boxes to address the issues of insufficient precision in boundary box regression and slow convergence rate. The Control Distance-IoU (CDIoU) loss [
56] mainly contributes to improving the regression accuracy of boundary boxes effectively.
We evaluate the four aforementioned regression losses and the results are presented in
Table 8. The experimental results show that, when DIoU is adopted, the average mAP increases 0.4% and 0.8%, respectively, compared with GIoU adopted and CDIoU adopted. Therefore, our design of loss function is reasonable.
4.3.7. The Effectiveness of Warm-Up Epochs
In this subsection, we investigate the impact of the number of warm-up epochs on the overall experimental performance. Warm-up epochs serve as a practical strategy to strike a balance between stability and exploration. They allow the model to improve its performance progressively by effectively utilizing the available training data without comprising convergence or stability. At the beginning of the training, the model is trained with a small learning rate to help it become familiar with the data. Subsequently, the learning rate gradually increases until the set initial learning rate. After a certain number of iterations, the learning rate begins to gradually decrease.
To find out the most suitable number of warm-up epochs, we alter the warm-up epochs between 2 and 8 in our experiment, whose results are presented in
Table 9. The results demonstrate that, when the warm-up epoch is set to 5, the most favorable outcomes are produced. Therefore, our predefined parameter value, i.e., warm-up epoch = 5, is reasonable.
4.4. Visualization
Figure 4 presents the visualization of the proposal generated by our DANet, and compares the predicted results with the ground truth. This action instance is sourced from the THUMOS14 dataset and comprises a skateboarding action of approximately five seconds. It is evident that the temporal offset between our predicted boundary times and ground truth does not exceed one second.
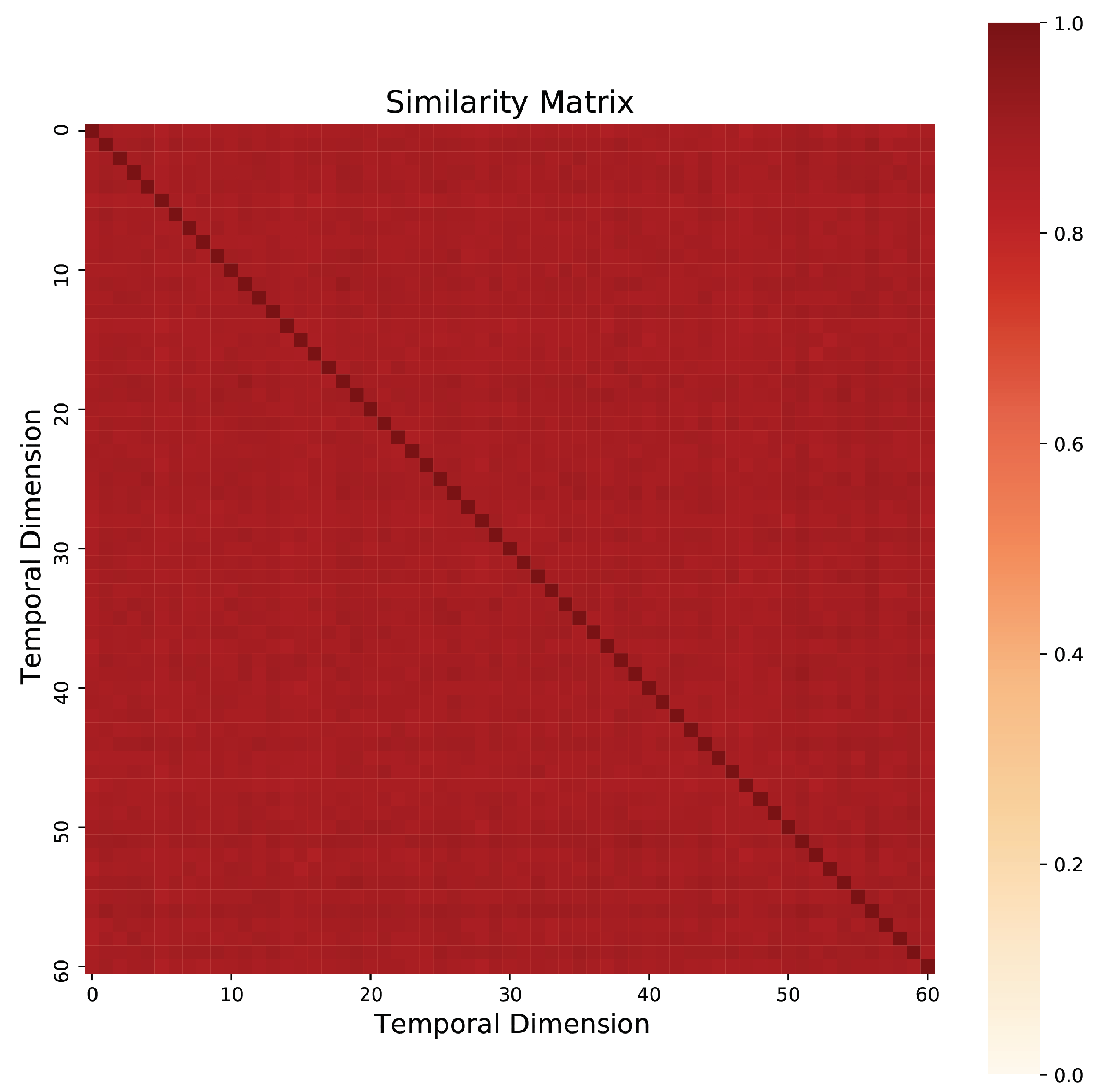
Figure 5 illustrates the high degree of similarity between adjacent frames in the video, which underscores the importance of enhancing local sensitivity.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}