1. Introduction
With the breakthrough development of information technology, how to process data with secured and rapid characteristics has become a major concern [
1]. Inspired by DNA structure, a novel computing paradigm using a biological molecule to carry genetic information is designed to ensure the feasibility of computing at a molecular level with impressive characterizations of programmability and high-throughput coding, which not only males it possible to replace traditional silicon-based facilities by biological tools [
2], but also provides an alternative way to consider computing with more than 0 and 1. Therefore, DNA computing [
3], as a popular computing model with considerable potential to meet the security requirement, has nowadays become a hot spot in the data processing domain.
In hardware-based data processing design, DNA logic gates are designed in combination with digital circuits, acting as basic components to form complex DNA circuits. For example, Zhang et al. [
4] propose an entropy-driven incision-assisted recovery strategy for reactants in the DNA loop, which can recover reactants in the catalytic loop and improve their recoverability, creating more effective DNA circuits for molecular transformation and synthetic biology. Unlike most artificially catalyzed DNA loops, Yang et al. [
5] develop a catalytic DNA logic circuit regulated by DNase, which is controlled by a covalent modification strategy and demonstrates a great potential in more complex computing by building complex cascade circuits.
In algorithm-based data computing design, molecular programming is built on the basis of DNA circuits with powerful modularity. For example, Zhang et al. [
6] design a DNA molecular computing platform to analyze miRNA profiles in serum samples, achieving an intelligent diagnosis of cancer. Later, Ma et al. [
7] design and implement various types of a DNA computing system, which verifies the feasibility of using DNA computing for intelligent diagnoses in fields of biology and biomedicine.
Despite various designs of clinical applications, DNA computing is popular for building a encryption application, due to its reliable encryption performance and parallel processing capability. Specifically, we could roughly divide encryption methods into two types, i.e., diffusion encryption and permutation encryption. Diffusion encryption refers to the process of spreading information throughout the ciphertext, thus increasing unbreakability of the encryption algorithm. More precisely, diffusion encryption maps each bit of the plaintext to multiple bits in the ciphertext. Any change in a plaintext bit should correspond to variations in multiple bits of the ciphertext, successfully achieving a correlation between the plaintext and ciphertext. Permutation encryption encrypts the plaintext by replacing each bit with a different bit, which reorders the information of the plaintext to hide content, instead of altering values of each bit in the plaintext. The key process of the permutation encryption is to establish a one-to-one mapping between each bit of the plaintext and ciphertext, thus achieving a confusion effect of information.
In fact, the quantity of algorithms have been proposed for data encrypting based on DNA computing. For example, Khan et al. [
8] propose DNAact Ran, a DNA computing-based sequence analysis engine, which could accurately detect a ransomware attack with their designed constraints and kmer frequency vector. Combining DNA computing with chaotic systems, Zou et al. [
9] involve the DNA-based strand displacement strategy with the chaotic system, where the generated chaotic sequence greatly improves the unbreakability of their encryption system, owing to its capability to stand with statistical attacks. Most recently, Namasudra et al. [
10] propose a DNA computing-based access control algorithm, where 1024 random keys are fed into the DNA computing system for the user’s secret data encryption, significantly improving the security capability of the control model.
Inspired by the idea of utilizing DNA computing to encrypt, we aim to encrypt high-dimensional image data in this paper. Compared with text structure data, the image is characterized with high-dimensional and unstructured proptoses, which have two major difficulties in designing proper encryption algorithms. First, how to achieve an unbreakable capability for image data with less encoding complexity, since a more complex encoding strategy generally promotes encryption performance. Second, since the image is equipped with a natural property of high-dimensional complexity, how algorithms could involve such a property for for encoding. In other words, images are a natural source of randomness, where adjacent pixels marked with a considerable amount of redundant information demonstrate strong correlations. Therefore, the characteristic of smooth variation between pixels can be leveraged to speed up the image encryption process.
To address the above difficulties, we develop a novel hash encoding-based DNA computing algorithm to effectively encrypt high-dimensional image data, which consists of the DNA hash encoding module and content-aware encrypting module. The hash algorithm is unique in encrypting, which outputs a fixed-length output with data as complicated as possible. Moreover, it shares several impressive characteristics, such as a small computing burden with a simple function calculation; unidirectionality without possible ways to reverse the input data through hash results, tampering resistance where small modification would greatly vary the output results; and anti-collision capability, which guarantees that the unique output could be gained with different inputs. Inspired by these properties, we involve hash encoding into DNA computing inside the proposed DNA hash encoding module, thus boosting the encryption capability of high-dimensional data with a small computation burden. Considering high-dimensional image data as a natural source to encode with less complexity, a content-aware encrypting module is proposed to map between image content and encryption results with several simple but effective functions, thus offering new ways to encrypt images based on DNA computing.
To sum up, the contributions of this paper are three-fold:
The proposed method combines the impressive characteristics of DNA computing and the hash function to realize an unbreakable image encryption with less computation burden.
A novel DNA-based hash encoding module is proposed, which involves the hash function to construct mappings from high-dimensional image data to DNA bases.
Considering correlations between adjacent pixels as natural sources of complexity, the proposed content-aware encrypting module sunccesfully generates random DNA sequences with chaos properties, which adopts non-linear functions originating from correlations of pixles as source of complexity.
The rest of this paper is organized as follows.
Section 2 reviews the related work.
Section 3 first presents an overview on algorithm structure, and then presents detailed steps of encryption and decryption.
Section 4 conducts several experiments, including an analysis on the key space, histogram, pixel correlation, information entropy, sensitivity and computation cost. Finally,
Section 5 concludes the paper and demonstrates the prospect.
3. Methods
We provide a detailed description of the proposed method with three parts, i.e., the overall framework, DNA hash encoding module and content-aware encryption module.
3.1. Overall Framework
We begin with an introduction to a basis of DNA computing in encryption. DNA bases are classified into four types, namely, adenine (A), thymine (T), cytosine (C) and guanine (G). It is worth noting that the former two types are complementary pairs, and so are the latter two types. We then describe rules for DNA-based sequence encoding, which uses a binary encoding idea to represent the input sequence under rules shown in
Table 1 with four bases, i.e., A, C, G and T. With the aid of encoding rules of
Table 1, we can convert binary sequence into a DNA-based encoding form for further computation. For example, under rule 2, A, C, G and T are represented as 00, 01, 10, and 11, respectively. If a pixel in the input image refers to 179 in gray levels and its binary representation is 10110011, its corresponding DNA-based encoding sequence should be G-T-A-T under rule 2. During decoding, if a DNA-based encoding sequence is G-A-T-C under rule 2, its corresponding binary value should be 10001101.
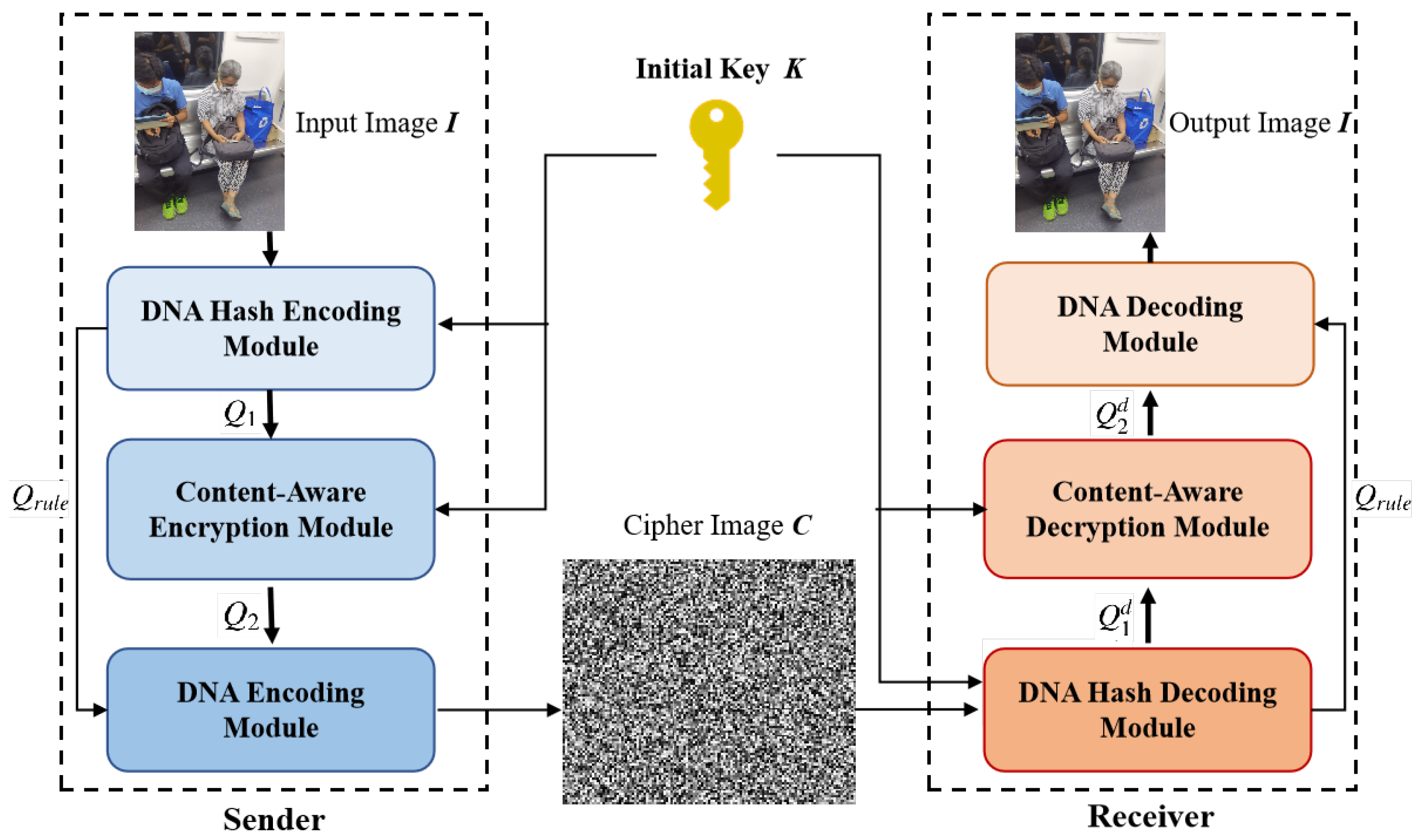
We then demonstrate the overall framework in
Figure 1, which consists of sender and receiver structures. Specifically, the whole process of encryption inside the sender can be described as follows:
Step 1. Feed the initial key K and the input image I into the DNA hash encoding module, which computes the rule selection sequence and DNA-encoded Sequence .
Step 2. K and are regarded as input of Content-aware Encryption module, which computes new sequence with permutation and diffusion, thus encoding complexity for high unbreakability.
Step 3. and are fed into the DNA encoding module, which encodes by utilizing to generate a binary bitstream under DNA encoding rules. Afterwards, we transfer the generated bitstream as a ciphered image C with .
Step 4. Transmit C from the sender to the receiver via Internet.
The whole process of decryption inside the receiver can be described as follows:
Step 5. Regarding C as input, the receiver sends it to DNA hash decoding module with the initial key K, thus generating the rule selection sequence and a DNA-based decoding sequence . It is noted that we keep the rule selection sequence exactly the same to ensure the consistency of decryption content.
Step 6. Feed K and into the content-aware decryption module for the reversed permutation and diffusion, thus generating a reversed DNA-based decoding sequence .
Step 7. Feed and into the DNA decoding module, which uses as the rule selector to decode into the binary bitstream . Finally, we transfer into the output image I for computation. Note that the input and output image should remain the same due to the general principles of encryption.
3.2. Design of DNA Hash Encoding Module
The DNA hash encoding module is designed to transform image data into a DNA-encoded form with different DNA bases, which could involve significant properties of the hash function, i.e., fixed-length output, small computing burden, tampering resistance and anti-collision ability. Such property help improve the unbreakability of the proposed method with low computing cost.
As shown in
Table 1, there only exist eight encoding patterns that satisfy the “complementary” rule, where each two bits satisfys the condition that there XOR results should be true. For example, if 00 and 01 are encoded as A and C, respectively, 11 and 10 should be encoded as T and G, respectively. There are only eight encoding rules obtained through this combination, and they are all listed in
Table 1. Based on the analysis of the “complementary” rule, we convert image data into a bit stream with the size of 3 bits to describe 8 different mapping rules, where the 2 bit is mapped as one DNA base for the encoding basis. Meanwhile, two more 8-bit streams are designed at the beginning of the stream to record the length and width of the original image, which could help restore the input image after encryption in a proper way.
Essentially, the proposed DNA hash encoding module plays a crucial role in encryption, which randomly employs various sets of complementary rules to encode each pixel. We demonstrate the overall encoding process of it during encryption in
Figure 2. The detailed steps of the encoding and decoding process inside the DNA hash encoding module are also listed with pseudo codes in Algorithms 1 and 2. First, we adopt the SHA256 algorithm to generate two important parameters, i.e., initial key value and initializing factor. To effectively improve the security of the cryptosystem, we then feed the computing factor
p into the PWLCM, generating the rule selection sequence with the following equation:
It’s noted that
, which enables variety in outcome with little modification in key values, whi ch is highly resistant to attack. Finally, we use the rule selection sequence to help encode the bitstream, which serves as DNA rules to encode pixels with DNA-based rules as shown in
Table 1.
| Algorithm 1: DNA hash encoding process |
| | Input: Initial Key K, Plain Image I |
| | Output: Rule Selection Sequence , DNA encoded Sequence |
| 1 | original height and original width of I; |
| 2 | Randomly generate and , where and ; |
| 3 | Convert the integer numbers and into a l6 bit binary bitstream ; |
| 4 | Convert the plain image I into a binary bitstream ; |
| 5 | Randomly generate a binary bitarray whose length is ; |
| 6 | (where ⊕ indicates concatenate operation); |
| 7 | ; |
| 8 | SHA256(K); |
| 9 | ; |
| 10 | ; |
| 11 | ; |
| 12 | ; |
| 13 | For (t = 0 to ); |
| 14 | ; |
| 15 | ; |
| 16 | ; |
| 17 | Introduce the DNA encoding table T; |
| 18 | For (t = 0 to ); |
| 19 | ; |
| 20 | Output Rule Selection Sequence , DNA encoded sequence ; |
| Algorithm 2: DNA Decoding Process |
| | Input: Rule Selection Sequence , DNA Encoded Sequence |
| | Output: Cipher Image C |
| 1 | ; |
| 2 | DNA Encoding Table; |
| 3 | For (t = 0 to ); |
| 4 | ; |
| 5 | Change cipher bit array into cipher image C; |
| 6 | Output Cipher Image C; |
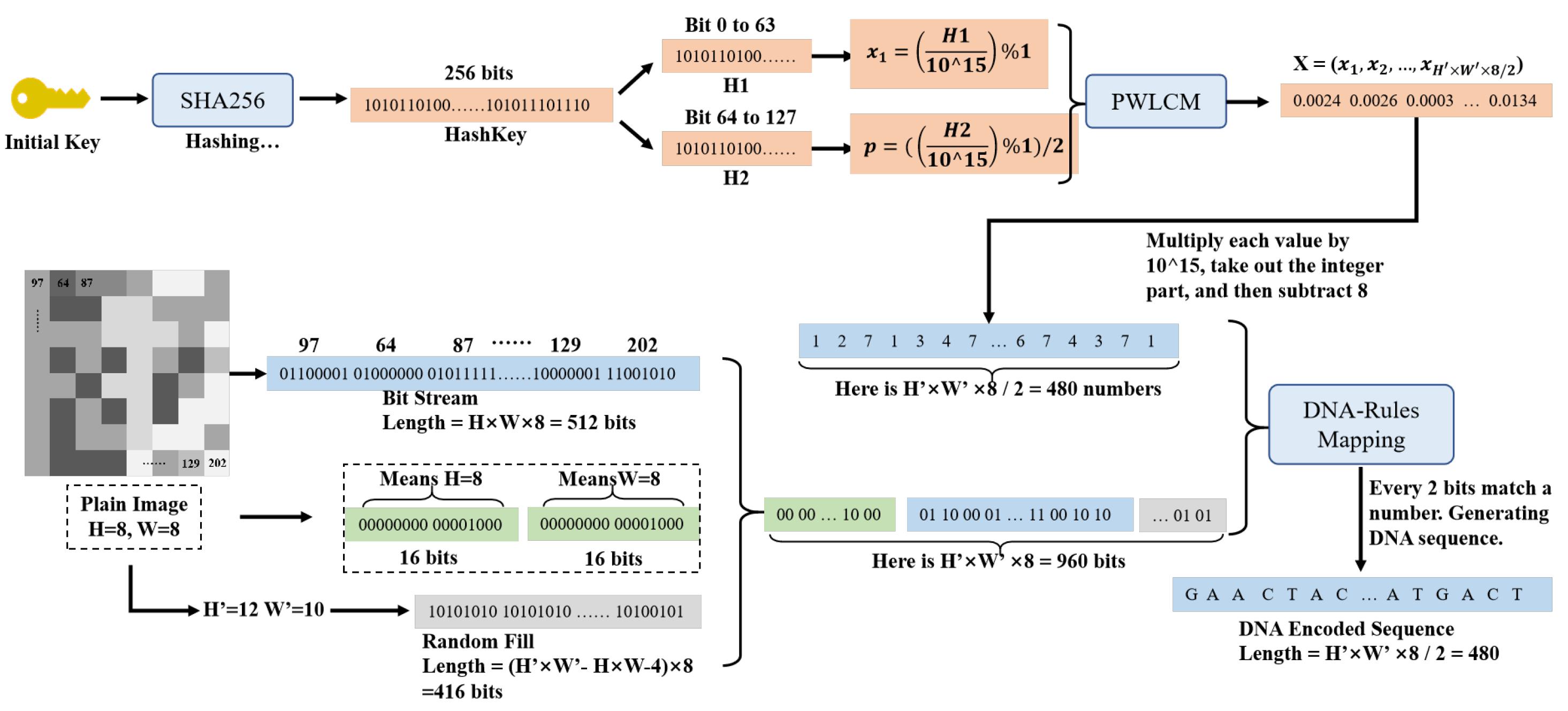
For readers’ convenience, we further offer a step-by-step explanation of hash encoding in
Figure 3, which performs an encryption process on a sample image, as follows:
Step 1. Obtain the height and width of the original image, where H and W equals 8 for the sample image. Convert the original image to a bitstream containing 512 bits of data.
Step 2. Save the original height and width as 16-bit data. For example, if H is 8, its corresponding bitstream is 00000000 00001000. Therefore, we use 32 bits of data to save the original height and width for further restoration.
Step 3. Randomly generate a new height and width, where both values should be larger but twice as small as the the original ones. For display, we set the new height and width to 12 and 10, respectively.
Step 4. It is noted that there exist bits of data for encoding, where the first 32 bits represent the original height and width, and the other 512 bits refer to image content. It’s noted that 416 bits remain unused, where they are randomly filled to make up a total 960-bit bitstream for further computation.
Step 5. We generate a 256-bit bit sequence HashKey through the SHA256 hash algorithm based on the input initial key. Note that and can be viewed as 64-bit numbers for computing.
Step 6. With and , we calculate and .
Step 7. Then, and p are fed into the PWLCM function to generate a sequence, where numbers are generated. Each of them is multiplied by , modulared with 8, achieving results with a rule sequence containing 480 numbers.
Step 8. We further match 960 bits of original data with rule sequence, where we match every 2 bits of data with 1 rule number based on DNA mapping rules in
Table 1. After converting, we could obtain results as a DNA hash-encoded sequence, which would be sent to the content-aware encryption module for permutation and diffusion.
3.3. Content-Aware Encryption Module
The content-aware encryption enhancing module is designed to reorganize the data structure by highly non-linear functions, originating from correlations between adjacent pixels and patches. It is noted that DNA operations could vary to form more diversified expressions, thus greatly improving the variability of encrypted sequences. Moreover, the inherent complexity of DNA operations can be enhanced by utilizing the relevance between neighboring pixels, borrowing non-linear equations from neighboring pixels and patches. Therefore, the proposed module is designed to naturally involve the complexity of the image, greatly boosting the difficulty of the cracking.
We demonstrate the structure design of the proposed module in
Figure 4, where the DNA-encoded sequence and rule selection sequence are regarded as inputs for the module. Essentially, we design a reversible permutation and diffusion algorithm to combine both forms of complexity for better unbreakability. Both algorithms could be directly applied on the input image without additional transmission cost via Internet or LAN. Furthermore, we have designed several computation operations that satisfy the commutative law, namely ADD, SUB and XOR, which not only ensures the variance of DNA sequences, but also shares the same parameters to reduce unnecessary transmission costs in LAN.
Specifically, we describe the calculation process of the DNA Sequence Permutation algorithm in Algorithm 3, which is built on the following four parameters:
where
a,
b,
c and
are preset parameters equaling 10,
, 28 and
, respectively. It is noted that such a calculation process ensures the chaos property of the proposed module. Afterwards, four parameters are sent into the Hyper Chaotic Lorenz System (HCLS) to generate the permutation control sequence
, where HCLS is a highly nonlinear dynamical system, being sensitive to the initial values for unpredictability.
| Algorithm 3: DNA Sequence Permutation Process |
| | Input: Initial Key K, DNA Encoded Sequence |
| | Output: DNA Permutation Sequence |
| 1 | DNA ADD Table; |
| 2 | DNA XOR Table; |
| 3 | ; |
| 4 | ; |
| 5 | For (i = 1 to ); |
| 6 | ; |
| 7 | ; |
| 8 | SHA256(); |
| 9 | SHA256(K); |
| 10 | ; |
| 11 | ; ; ; ; |
| 12 | ; |
| 13 | ; |
| 14 | ; |
| 15 | ; |
| 16 | Put into HCLS to generate a sequence by iterating; |
| 17 | ; |
| 18 | If (This is the encryption process); |
| 19 | ; |
| 20 | Else; |
| 21 | ; |
| 22 | For ( to j); |
| 23 | ; |
| 24 | ; |
| 25 | Output DNA Permutation Sequence ; |
Similarly, we describe the calculation process of the DNA Sequence diffusion algorithm in Algorithm 4. Specifically, we first calculate key parameters
and
p based on values of
and
transmitted from the last module. Then, we input these parameters into the PWLCM algorithm to generate a diffusion control sequence. With the input rule selection sequence, we adopt DNA rules to map from numbers to DNA bases, thus generating DNA diffusion sequence. Finally, we apply DNA-based calculations on the generated permutation sequence and diffusion sequence, thus obtaining the merged sequence as the final output of the DNA permutation and diffusion sequence.
| Algorithm 4: DNA Sequence Diffusion Process |
| | Input: Initial Key K, Rule Selection Sequence , Permutated Sequence |
| | Output: Permutated and Diffused Sequence |
| 1 | Convert the plain image I into a binary bitstream ; |
| 2 | length ; |
| 3 | SHA256(K); |
| 4 | ; ; |
| 5 | ; |
| 6 | ; |
| 7 | For (t = 0 to ); |
| 8 | ; |
| 9 | ; |
| 10 | ; |
| 11 | DNA Encoding Table; |
| 12 | For (i = 0 to ); |
| 13 | ; |
| 14 | DNA ADD Operation Table; |
| 15 | DNA SUB Operation Table; |
| 16 | DNA XOR Operation Table; |
| 17 | If (in encryption process); |
| 18 | ; |
| 19 | ; |
| 20 | For (i = 0 to ); |
| 21 | If; |
| 22 | ; ; |
| 23 | Else; |
| 24 | ;; |
| 25 | Elif (in decryption process); |
| 26 | For (i = to 0); |
| 27 | If; |
| 28 | ;; |
| 29 | Else; |
| 30 | ;; |
| 31 | ; |
| 32 | ; |
| 33 | Output Permutated and Diffused Sequence ; |
4. Experiment and Analysis
We firstly introduce the experiment settings and implementation details. Then, we perform variants of the analysis to verify the resistance against different attacks. Afterwards, we perform ablation and computation analysis to evaluate performance. Finally, the comparison experiments are conducted.
4.1. Experiment Settings and Implementation Details
We deploy the proposed encryption system in TCP/IP environment. We connected two computers through the Tenda-AC71200M router, thus forming a simple wireless LAN environment. Specifically, the original image is provided by a laptop (sender) and encrypted into a cipher image by the proposed method. Then, the cipher image is transmitted to another laptop (receiver) via IP Messenger protocol and decrypted into a plain image.
It is noted that we use two computers with the same configurations to simulate the sender and receiver. Both computers are equipped with an Intel Core i5-12400F CPU, NVIDIA RTX 3060Ti GPU, and 16GB memory. Additionally, the encryption method is implemented based on Python 3.8, and the initial key is set to ‘GOOD-LUCK’.
4.2. Key Space Analysis
Key space is defined as the size of a key range, i.e., the number of keys, where different encryption algorithms have their own specific key space. Essentially, we should ensure that the key space is large enough to withstand brute force attacks. Specifically, we can calculate that the size of the key space of the proposed method is . Obviously, such a large key space ensures the capability to resist brute force attacks.
4.3. Histogram Analysis
The statistical analysis attack refers to the fact that attackers can obtain a quantity of information by analyzing the distribution of image pixel values. To verify the effectiveness of the proposed method against the statistical analysis attack, we compare the pixel value distribution of the original and cipher image. As shown in
Figure 5a–e, the histogram of the original image fluctuates greatly, where attackers can easily construct effective attack strategies.
Figure 5f–j shows the corresponding cipher images and pixel histograms, which proves that the encrypted image can effectively hide image information to resist statistical analysis attacks.
4.4. Pixel Correlation Analysis
Permutation and diffusion operations are used to scramble adjacent pixels between images, thus reducing the correlation between adjacent pixels and improving the security after image encryption. We can calculate the correlation coefficient between
a and
b to evaluate such correlation effects
where
,
and
are defined as the covariance, mean square and expected error, respectively.
Table 2 shows the correlation coefficients of the plain and cipher image, where we can observe that the pixel correlation has been significantly reduced by comparing between both images. Correspondingly,
Figure 6 shows the comparison of image correlation before and after encryption, which proves that the proposed method can effectively reduce the correlation in three directions.
4.5. Information Entropy Analysis
Information entropy is used to measure the uncertainty of data, where higher information entropy refers to larger complexity for cracking. Supposing the number of keys of an encryption algorithm is K-bit, the ideal information entropy should be K. To evaluate the uncertainty of the data, i.e., the diffusion performance, information entropy can be calculated as follows:
where
represents the probability of the pixel being
i.
The information entropy of five test images is 7.987421 (Poster), 7.996523 (Street), 7.989923 (Subway), 7.998615 (ID Card) and 7.988991 (Hohai University), where all the information entropy is close to 8, implying that the proposed method performs a pixel diffusion with an optimized performance.
4.6. Sensitivity Analysis
By modifying values of a few pixels and comparing results, differential attacks could help attackers to easily obtain the rules of encryption. Therefore, the cryptosystem is required to have a certain sensitivity to resist pixel modifications. We adopt a unified average changing intensity (UACI) and number of pixels change rate (NPCR) to measure such sensitivity:
where
.
I and
are the original and the modified image, respectively.
As shown in
Figure 7, we choose an 8-bit image as the plain image and use the initial key ’GOOD-LUCK’ to encrypt the image, obtaining the ’pseudo initialize factor’
. Afterwards, we change the pseudo-initialized factor to generate a new cipher image
. Moreover, we define
and
to generate another two cipher images
and
.
The average NPCR and UACI values for different images are shown in
Table 3. In fact, Wu et al. [
26] state that the expected UACI value should be 33.4635% for an image with ranging values from 0 to 255. It is noted that all results are close to the expected UACI values, which proves that the proposed is capable of resisting differential attacks.
4.7. Ablation Analysis
To verify the effectiveness of the proposed content-aware encryption module, we make an ablation analysis with “Lena” image as input, which is considered as the most commonly used test image [
27]. As shown in
Table 4, the performance without the proposed module is relatively poor, since simply adopting DNA encoding without content modeling fails in encoding as muchinformation of the input image. In fact, the proposed content-aware encryption module uses a permutation and a diffusion process to describe informative information remaining in the encoded data, greatly improving the complexity for breaking.
4.8. Comparison Experiments
For comparative experiments, we follow the rules in Wu et al. [
27], which are currently used by the vast majority of image encryption articles.
Table 5 shows the experimental results with the comparing methods. It’s noted that results achieved by other methods are directly obtained from their papers.
Essentially, correlation refers to the capability of resistance to statistical attack. Information entropy represents the capability of resistance to entropy attack; meanwhile, sensitivity represents the capability of resistance to the differential attack. It can be observed from
Table 5 that the proposed method cannot achieve the best performance on all measurements. For example, Zhang et al. [
23] has the best performance in correlation, but the worst in NPCR. Such a phenomenon means their method cannot bear a differential attack. Aouissaoui et al. [
28] has the best performance in NPCR, but the worst in entropy and correlation. Such an observation means it would fail under an entropy attack and statistical attack. The proposed method has achieved a balanced performance in three measurements, which represents it does not have as much weaknesses as the other two comparison methods by obtaining enough capability of resistance to any type of attacks. Therefore, it can be concluded that our method is competitive among these methods.
4.9. Computation Cost Analysis
We compare the computing cost of the proposed method and other DNA computing-based methods in
Table 6, thus proving its relatively low computing burden. It’s noted that we use color image with
as input. All programs are deployed with C language and tested on the same devices (two laptops with i7-9750H CPU and 8GB DDR3 RAM), thus ensuring the fairness of comparisons. It is noted that the encryption and decryption process would cost 0.491 s and 0.507 s with the proposed method, which has certain advantages when comparing to other DNA computing-based methods.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}