
Dynamic Response Threshold Model for Self-Organized Task Allocation in a Swarm of Foraging Robots


Abstract
:1. Introduction
2. Methods
2.1. Attractor Selection Model (ASM)
2.2. Dynamical Response Threshold Model (DRTM)
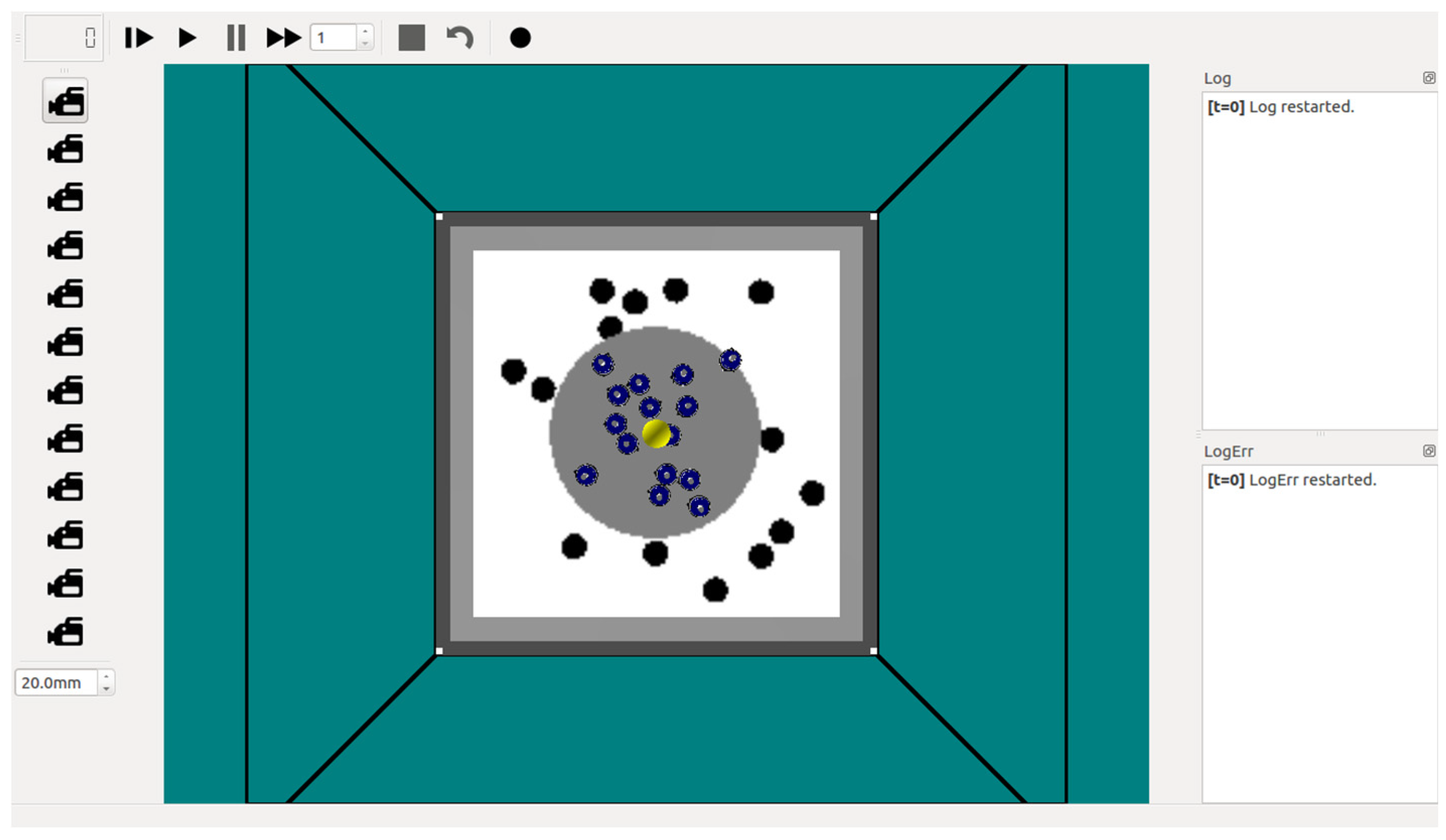
2.3. Simulation Setup
2.4. Performance Measures
3. Results
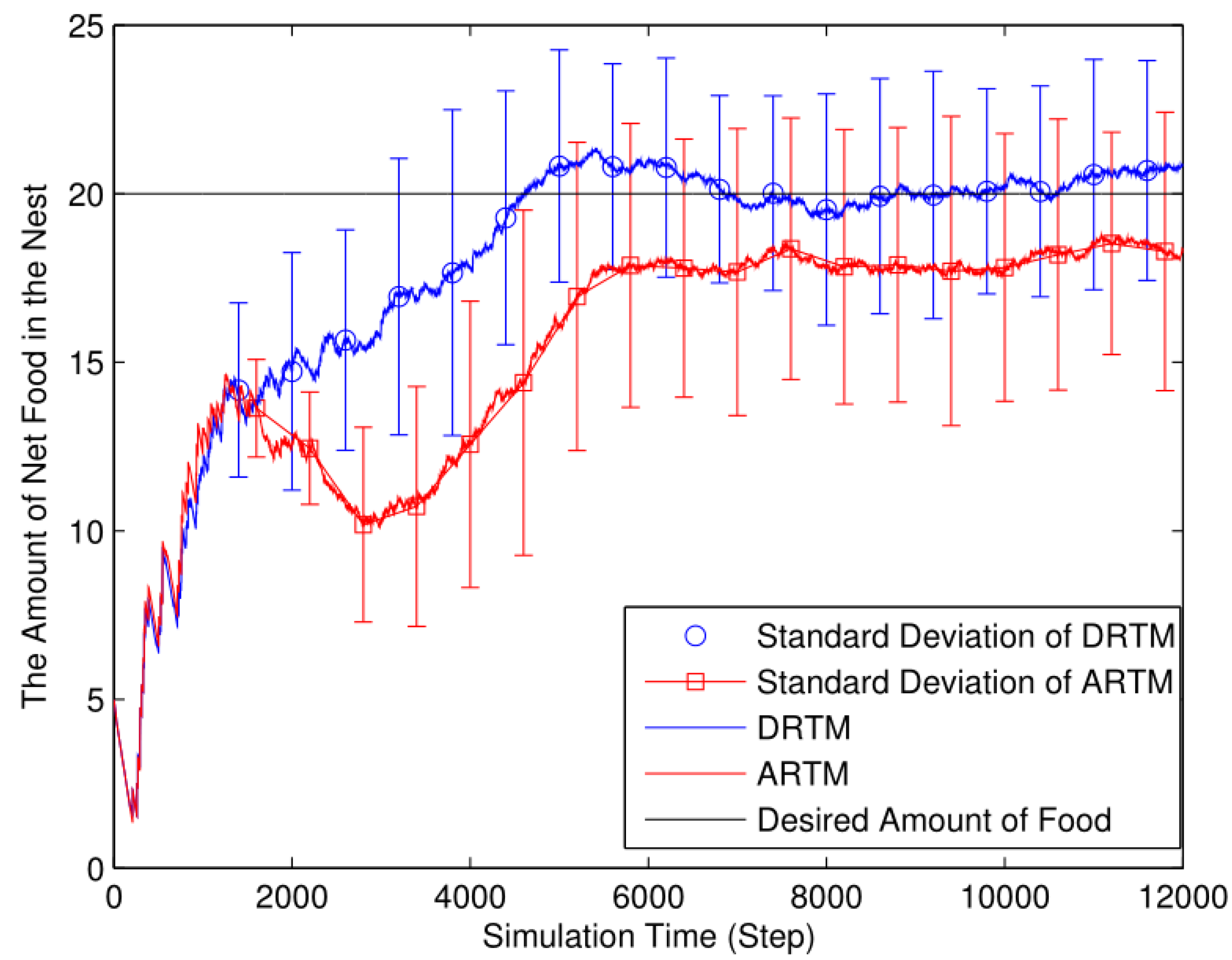
3.1. Simulation Experiment
3.2. Experiments with Actual Robots
4. Discussion
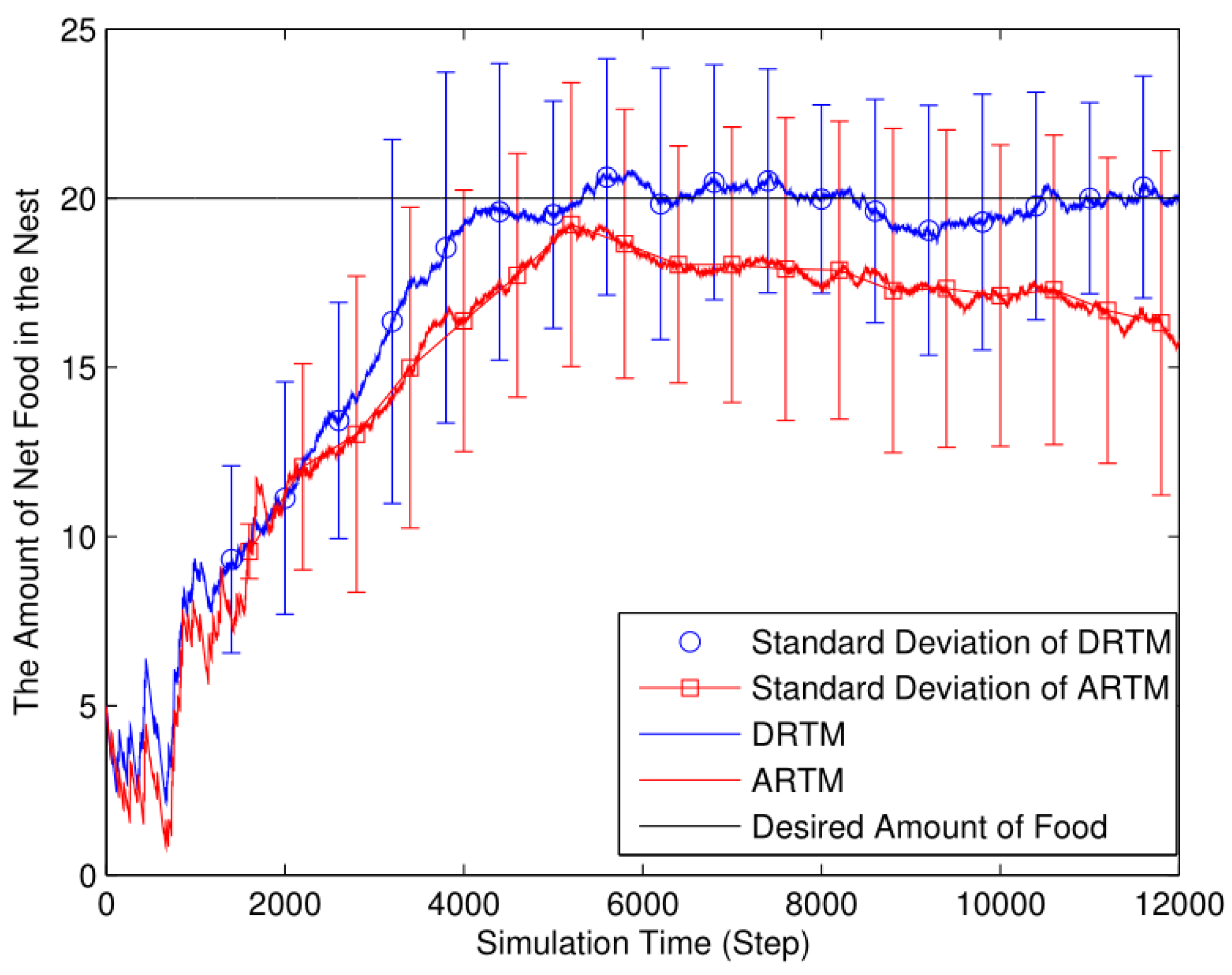
4.1. Different Numbers of Food Tokens
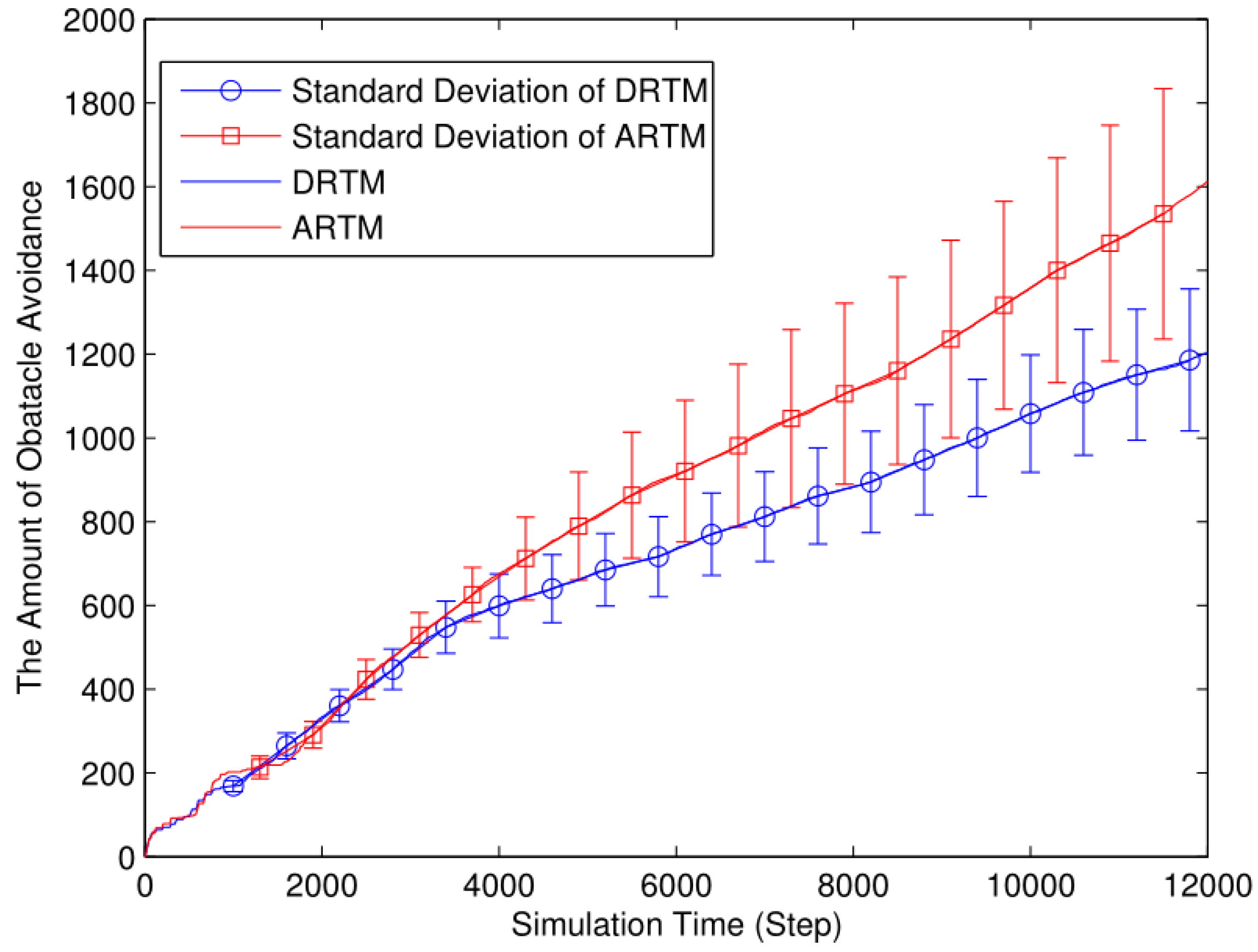
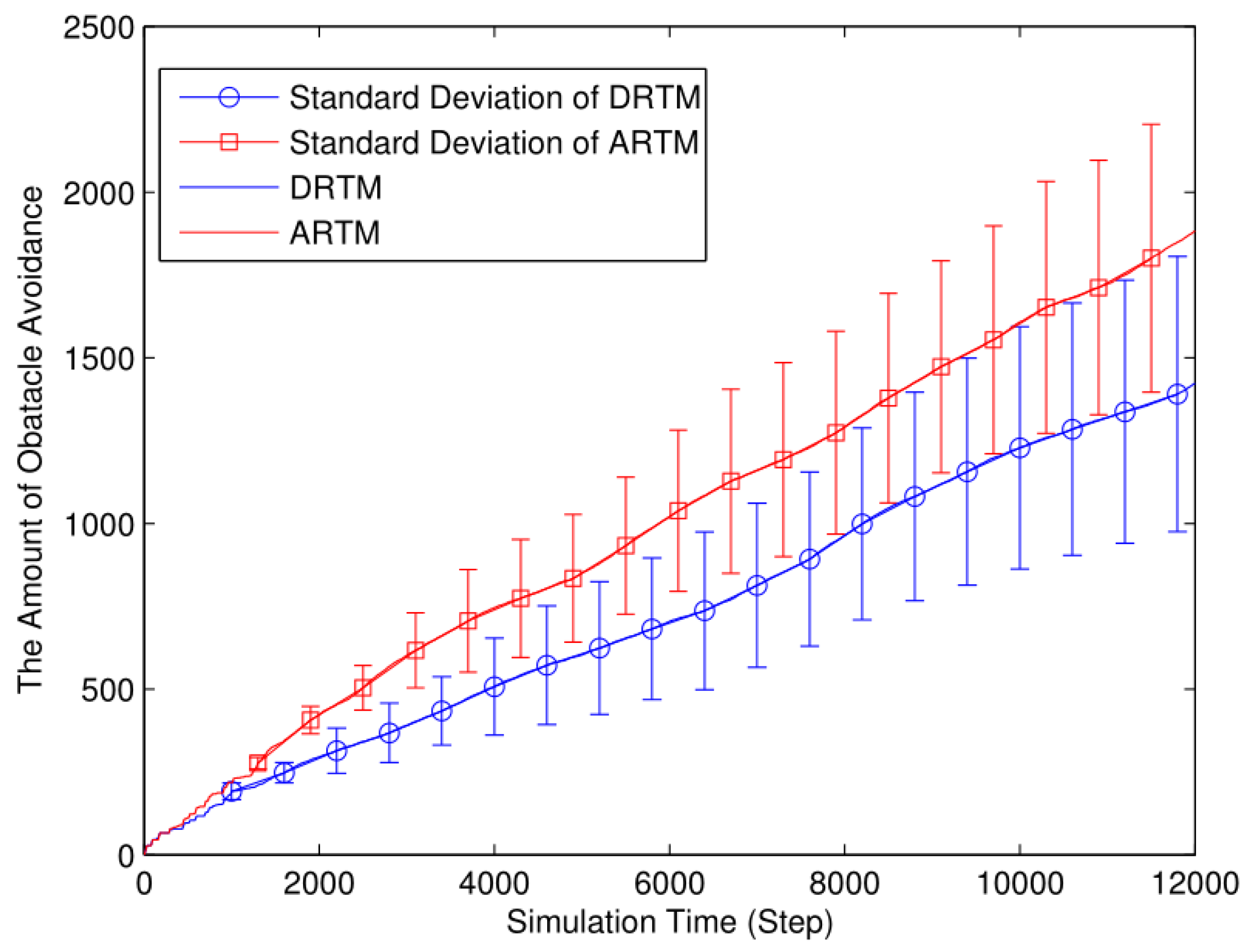
4.2. Different Energy Consumption Due to Obstacle Avoidance
4.3. Different Numbers of Robots
4.4. Different Sizes of Foraging Arena
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shaw, S.; Wenzel, E.; Walker, A.; Sartoretti, G.A. ForMIC: Foraging via Multiagent RL with Implicit Communication. IEEE Robot. Autom. Lett. 2022, 7, 4877–4884. [Google Scholar] [CrossRef]
- Ordaz-Rivas, E.; Rodriguez-Linan, A.; Torres-Trevino, L. Autonomous foraging with a pack of robots based on repulsion, attraction and influence. Auton. Robot. 2021, 45, 919–935. [Google Scholar] [CrossRef]
- Adams, S.; Ornia, D.J.; Mazo, M. A self-guided approach for navigation in a minimalistic foraging robotic swarm. Auton. Robot. 2023. [Google Scholar] [CrossRef]
- Lee, D.; Lu, Q.; Au, T.C. Dynamic Robot Chain Networks for Swarm Foraging. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4965–4971. [Google Scholar]
- Obute, S.O.; Kilby, P.; Dogar, M.R.; Boyle, J.H. Swarm Foraging Under Communication and Vision Uncertainties. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1446–1457. [Google Scholar] [CrossRef]
- Yang, D. Research on Intelligent Logistics Warehousing System Design and Operation Strategy Optimization; Economy & Management Publishing House: Beijing, China, 2023. [Google Scholar]
- Loftus, J.C.; Perez, A.; Sih, A. Task syndromes: Linking personality and task allocation in social animal groups. Behav. Ecol. 2021, 32, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Swain, A.; Williams, S.D.; Felice, L.J.; Hobson, E.A. Interactions and information: Exploring task allocation in ant colonies using network analysis. Anim. Behav. 2022, 189, 69–81. [Google Scholar] [CrossRef]
- Liu, C.; Kroll, A. A Centralized Multi-Robot Task Allocation for Industrial Plant Inspection by Using A* and Genetic Algorithms. In Proceedings of the Artificial Intelligence and Soft Computing: 11th International Conference, ICAISC, Zakopane, Poland, 29 April–3 May 2012; pp. 466–474. [Google Scholar]
- Keshmiri, S.; Payandeh, S. A centralized framework to multi-robots formation control: Theory and application. International Workshop on Collaborative Agents. In Proceedings of the Collaborative Agents—Research and Development, Toronto, ON, Canada, 31 August 2009; pp. 85–98. [Google Scholar]
- Chitta, S.; Jones, E.G.; Ciocarlie, M.; Hsiao, K. Mobile manipulation in unstructured environments: Perception, planning, and execution. IEEE Robot. Autom. Mag. 2012, 19, 58–71. [Google Scholar] [CrossRef]
- Arif, M.U.; Haider, S. A Flexible Framework for Diverse Multi-Robot Task Allocation Scenarios Including Multi-Tasking. ACM Trans. Auton. Adapt. Syst. 2022, 16, 1–23. [Google Scholar] [CrossRef]
- Jin, B.; Liang, Y.; Han, Z.; Hiraga, M.; Ohkura, K. A hierarchical training method of generating collective foraging behavior for a robotic swarm. Artif. Life Robot. 2022, 27, 137–141. [Google Scholar] [CrossRef]
- Kreiger, M.; Billeter, J. The call of duty: Self-organized task allocation in a population of up to twelve mobile robots. Robot. Auton. Syst. 2000, 30, 65–84. [Google Scholar] [CrossRef]
- Liu, W.; Winfield, A.F. Modeling and optimization of adaptive foraging in swarm robotic systems. Int. J. Robot. Res. 2010, 29, 1743–1760. [Google Scholar] [CrossRef]
- Agassounon, W.; Martinoli, A. Efficiency and robustness of threshold-based distributed allocation algorithms in multi-agent systems. In Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, Bologna, Italy, 15–19 July 2002; pp. 1090–1097. [Google Scholar]
- Castello, E.; Yamamoto, T.; Nakamura, Y.; Ishiguro, H. Task allocation for a robotic swarm based on an adaptive response threshold model. In Proceedings of the 2013 13th International Conference on Control, Automation and Systems (ICCAS), Gwangju, Republic of Korea, 20–23 October 2013; pp. 259–266. [Google Scholar]
- Buchanan, E.; Alden, K.; Pomfret, A.; Timmis, J.; Tyrrell, A.M. A study of error diversity in robotic swarms for task partitioning in foraging tasks. Front. Robot. AI 2023, 9, 904341. [Google Scholar] [CrossRef]
- Brutschy, A.; Pini, G.; Pinciroli, C.; Birattari, M.; Dorigo, M. Self-organized task allocation to sequentially interdependent tasks in swarm robotics. Auton. Agents Multi-Agent Syst. 2014, 28, 101–125. [Google Scholar] [CrossRef]
- Pitonakova, L.; Crowder, R.; Bullock, S. Task allocation in foraging robot swarms: The role of information sharing. In Proceedings of the Fifteenth International Conference on the Synthesis and Simulation of Living Systems (ALIFE XV), Cancún, Mexico, 4–8 July 2016; MIT Press: Cambridge, MA, USA; pp. 306–313. [Google Scholar]
- Labella, T.H.; Dorigo, M.; Deneubourg, J.L. Division of labor in a group of robots inspired by ants’ foraging behavior. ACM Trans. Auton. Adapt. Syst. (TAAS) 2006, 1, 4–25. [Google Scholar] [CrossRef]
- Bonabeau, E.; Theraulaz, G.; Deneubourg, J.L. Fixed response thresholds and the regulation of division of labor in insect societies. Bull. Math. Biol. 1998, 60, 753–807. [Google Scholar] [CrossRef]
- Bonabeau, E. Adaptive task allocation inspired by a model of division of labor in social insects. In Biocomputing and Emergent Computation; Proceedings of BCEC97; World Scientific: Singapore, 1997; pp. 36–45. [Google Scholar]
- Lee, W.; Vaughan, N.; Kim, D. Task Allocation Into a Foraging Task With a Series of Subtasks in Swarm Robotic System. IEEE Access 2020, 8, 107549–107561. [Google Scholar] [CrossRef]
- Lope, J.D.; Maravall, D.; Quinonez, Y. Self-organizing techniques to improve the decentralized multi-task distribution in multi-robot systems. Neurocomputing 2015, 163, 47–55. [Google Scholar] [CrossRef]
- Kanakia, A.; Klingner, J.; Correll, N. A Response Threshold Sigmoid Function Model for Swarm Robot Collaboration. In Distributed Autonomous Robotic Systems; Springer: Tokyo, Japan, 2016. [Google Scholar]
- Castello, E.; Yamamoto, T.; Nakamura, Y.; Ishiguro, H. Foraging optimization in swarm robotic systems based on an adaptive response threshold model. Adv. Robot. 2014, 28, 1343–1356. [Google Scholar] [CrossRef]
- Castello, E.; Yamamoto, T.; Libera, F.D.; Liu, W.; Winfield, A.F.T.; Nakamura, Y.; Ishiguro, H. Adaptive foraging for simulated and real robotic swarms: The dynamical response threshold approach. Swarm Intell. 2016, 10, 1–31. [Google Scholar] [CrossRef]
- Kanakia, A.; Touri, B.; Correll, N. Modeling multi-robot task allocation with limited information as global game. Swarm Intell. 2016, 10, 147–160. [Google Scholar] [CrossRef]
- Lu, Q.; Griego, A.D.; Fricke, G.M.; Moses, M.E. Comparing Physical and Simulated Performance of a Deterministic and a Bio-inspired Stochastic Foraging Strategy for Robot Swarms. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9285–9291. [Google Scholar]
- Di, K.; Zhou, Y.; Yan, F.; Jiang, J.; Yang, S.; Jiang, Y. A Foraging Strategy with Risk Response for Individual Robots in Adversarial Environments. ACM Trans. Intell. Syst. Technol. 2022, 13, 83. [Google Scholar] [CrossRef]
- Miletitch, R.; Reina, A.; Dorigo, M.; Trianni, V. Emergent naming conventions in a foraging robot swarm. Swarm Intell. 2022, 16, 211–232. [Google Scholar] [CrossRef]
- Khaluf, Y.; Birattari, M.; Rammig, F. Analysis of long-term swarm performance based on short-term experiments. Soft Comput. 2016, 20, 37–48. [Google Scholar] [CrossRef]
- Yanagida, T.; Ueda, M.; Murata, T.; Esaki, S.; Ishii, Y. Brownian motion, fluctuation and life. Biosystems 2007, 88, 228–242. [Google Scholar] [CrossRef]
- Kashiwagi, A.; Urabe, I.; Kaneko, K.; Yomo, T. Adaptive response of a gene network to environmental changes by fitness-induced attractor selection. PLoS ONE 2006, 1, e49. [Google Scholar] [CrossRef] [Green Version]
- Daganzo, C.F.; Lehe, L.J. Traffic flow on signalized streets. Transp. Res. Part B Methodol. 2016, 90, 56–69. [Google Scholar] [CrossRef]
- Pradhan, A.; Boavida, M.; Fontanelli, D. A Comparative Analysis of Foraging Strategies for Swarm Robotics using ARGoS Simulator. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 30–35. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Detect Attractors | ASM’s Input: A(t) | Robot’s Motion |
|---|---|---|---|
| SW | No | 0 | random walk |
| SW | Yes | 1 | approach to the food |
| SW | No | 0 | random walk |
| SW | Yes | 1 | approach to the light |
| Compare | t-Value | Two-Tailed P | Significance |
|---|---|---|---|
| Ft | 3.1918 | 0.0019 | YES |
| MT | 2.2899 | 0.0242 | YES |
| Nf | Ea | Nr | L | ||
|---|---|---|---|---|---|
| Section | |||||
| 4.1 | 20 | 10 | 20 | 4 | |
| 5.1 | 25 | 10 | 20 | 4 | |
| 5.2 | 20 | 20 | 20 | 4 | |
| 5.3 | 20 | 10 | 30 | 4 | |
| 5.4 | 20 | 10 | 20 | 3 | |
| Compare | t-Value | Two-Tailed P | Significance | ||
|---|---|---|---|---|---|
| Section | |||||
| 5.1 | Ft | 4.9663 | 2.89 × 10−6 | YES | |
| MT | 2.7761 | 6.59 × 10−3 | YES | ||
| 5.2 | Ft | 3.2744 | 1.46 × 10−3 | YES | |
| MT | 2.3803 | 0.0192 | YES | ||
| 5.3 | Ft | 4.7869 | 6.00 × 10−6 | YES | |
| MT | 3.9267 | 1.60 × 10−4 | YES | ||
| 5.4 | Ft | 2.1899 | 0.0310 | YES | |
| MT | 2.6984 | 8.21 × 10−3 | YES | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, B.; Zhang, Z.; Song, Y.; Yuan, X.; Xu, Q. Dynamic Response Threshold Model for Self-Organized Task Allocation in a Swarm of Foraging Robots. Appl. Sci. 2023, 13, 9107. https://doi.org/10.3390/app13169107
Pang B, Zhang Z, Song Y, Yuan X, Xu Q. Dynamic Response Threshold Model for Self-Organized Task Allocation in a Swarm of Foraging Robots. Applied Sciences. 2023; 13(16):9107. https://doi.org/10.3390/app13169107
Chicago/Turabian StylePang, Bao, Ziqi Zhang, Yong Song, Xianfeng Yuan, and Qingyang Xu. 2023. "Dynamic Response Threshold Model for Self-Organized Task Allocation in a Swarm of Foraging Robots" Applied Sciences 13, no. 16: 9107. https://doi.org/10.3390/app13169107
APA StylePang, B., Zhang, Z., Song, Y., Yuan, X., & Xu, Q. (2023). Dynamic Response Threshold Model for Self-Organized Task Allocation in a Swarm of Foraging Robots. Applied Sciences, 13(16), 9107. https://doi.org/10.3390/app13169107