
Intrusion Detection for Industrial Control Systems Based on Improved Contrastive Learning SimCLR


 ,
,  ,
,
Abstract
:1. Introduction
- (1)
- An intrusion detection model for industrial control systems based on improved comparative learning SimCLR is proposed, and the data enhancement is improved by adding random noise, sequence inversion, and random sampling of the Synthetic Minority Over-sampling Technique (SMOTE) algorithm to the original industrial control traffic data. The other one uses only the SMOTE algorithm. The other one uses only the SMOTE algorithm to replace the original data with the same multiplicity of sampling.
- (2)
- The asymmetric network structure is adopted on top of the original model, which enables different networks to perform feature extraction for different types of data.
- (3)
- The feature projection structure is improved by using feature cross-fusion to cross-fuse two feature vectors and using a jump join between the first and last linear layer to add the two vectors before and after the projection, which increases the similarity between positive and negative examples and makes the similarity between positive and negative examples more distant.
2. Theoretical Basis
2.1. SMOTE Algorithm
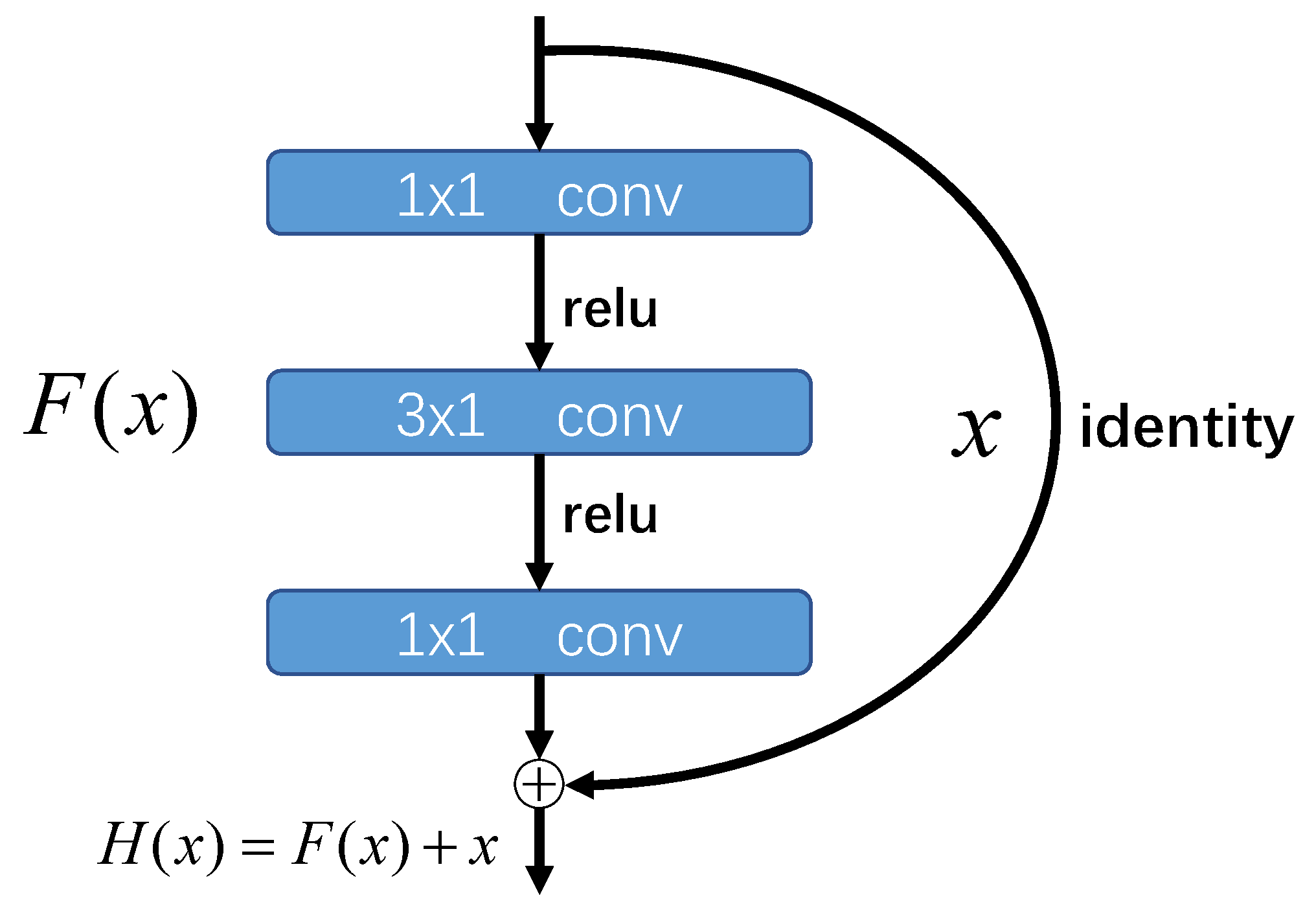
2.2. Residual Network
2.3. LayerNorm
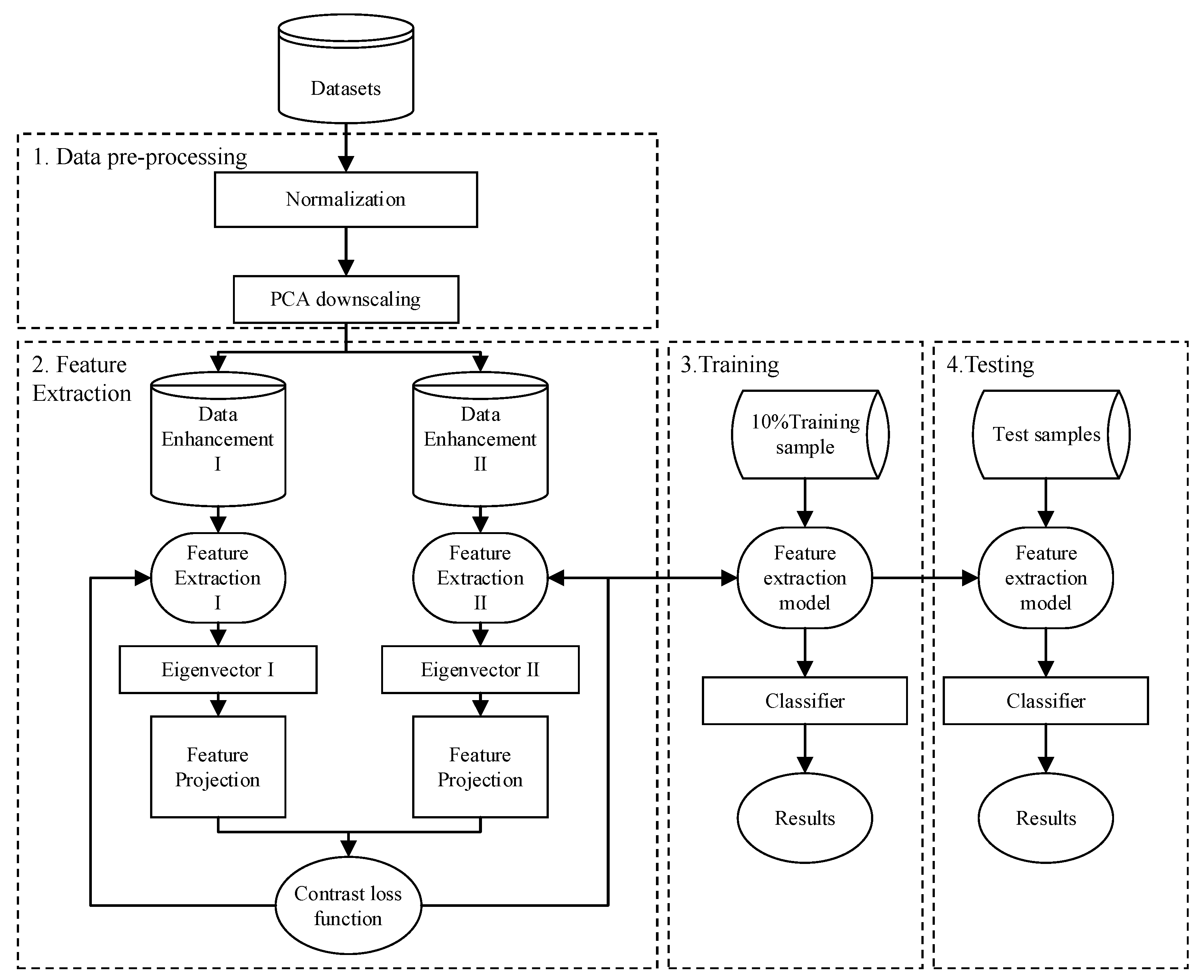
3. Contrastive Learning-Based Intrusion Detection Model for Industrial Control Systems
3.1. Data Pre-Processing
3.1.1. Normalization
3.1.2. PCA Downscaling
3.2. Training Contrast Learning Models
3.2.1. Data Enhancement
3.2.2. Feature Extraction
3.2.3. Feature Projection
3.2.4. Contrast Loss Function
3.3. Supervised Training of Fine-Tuned Models
4. Experiments and Results Analysis
4.1. Experimental Data Set
4.2. Model Evaluation Metrics
4.3. Parameter Setting
4.4. Experimental Results and Analysis
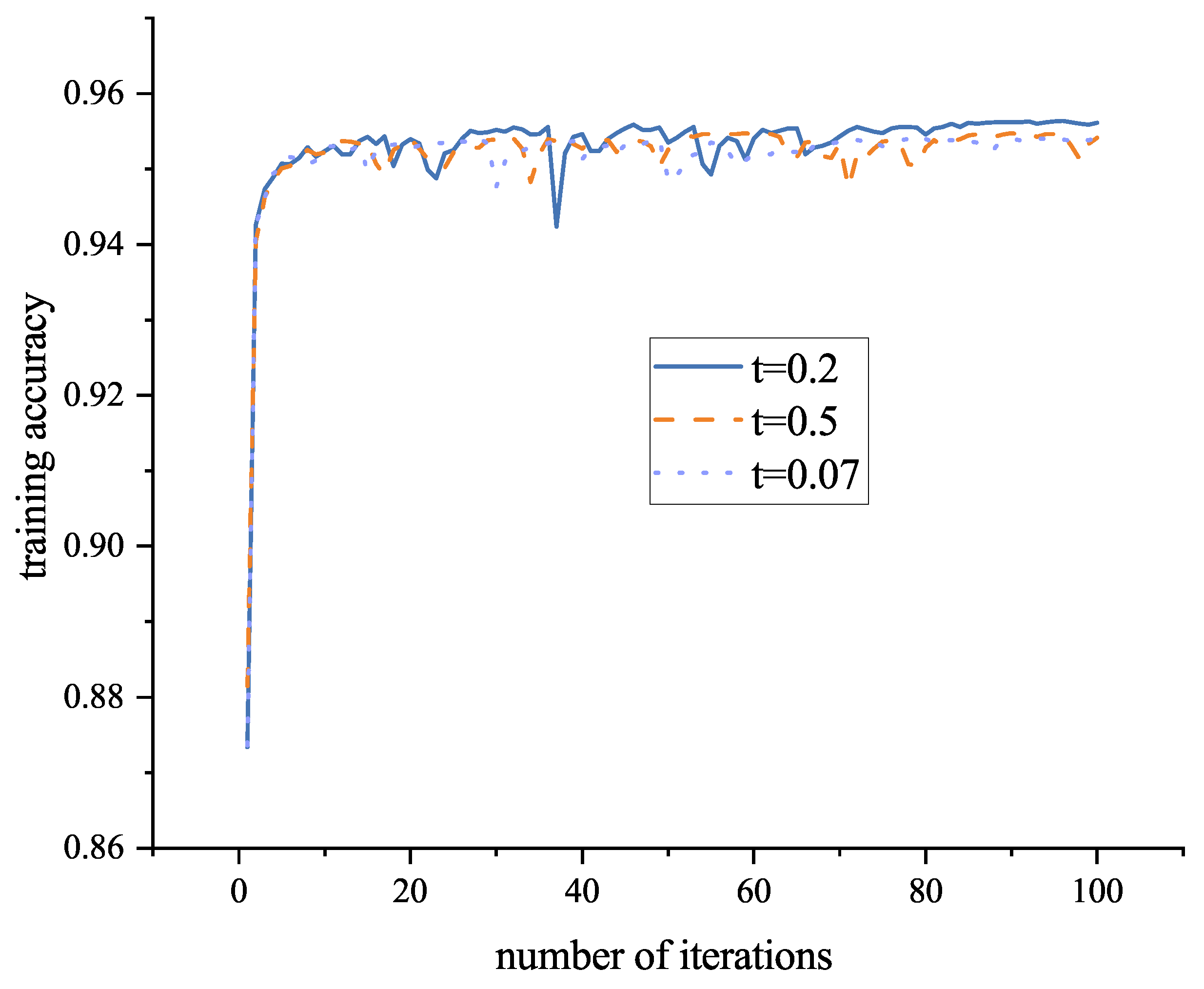
4.4.1. Comparison of Experimental Results with Different Temperature Coefficients
4.4.2. Comparison of Experimental Results of Different Data Enhancement Methods
4.4.3. Comparison of Experimental Results of Different Classification Models
4.4.4. Experimental Results for Different Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alanen, J.; Linnosmaa, J.; Malm, T.; Papakonstantinou, N.; Ahonen, T.; Heikkilä, E.; Tiusanen, R. Hybrid ontology for safety, security, and dependability risk assessments and Security Threat Analysis (STA) method for industrial control systems. Reliab. Eng. Syst. Saf. 2022, 220, 108270. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Rhode, M.; Burnap, P.; Wedgbury, A. Adversarial attacks on machine learning cybersecurity defences in industrial control systems. J. Inf. Secur. Appl. 2021, 58, 102717. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, Q.G.; Feng, G.; Shi, Y.; Vasilakos, A.V. A survey on attack detection, estimation and control of industrial cyber–physical systems. ISA Trans. 2021, 116, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Corallo, A.; Lazoi, M.; Lezzi, M.; Luperto, A. Cybersecurity awareness in the context of the Industrial Internet of Things: A systematic literature review. Comput. Ind. 2022, 137, 103614. [Google Scholar] [CrossRef]
- Li, B.; Wu, Y.; Song, J.; Lu, R.; Li, T.; Zhao, L. DeepFed: Federated deep learning for intrusion detection in industrial cyber–physical systems. IEEE Trans. Ind. Inform. 2020, 17, 5615–5624. [Google Scholar] [CrossRef]
- Roy, S.; Li, J.; Choi, B.J.; Bai, Y. A lightweight supervised intrusion detection mechanism for IoT networks. Future Gener. Comput. Syst. 2022, 127, 76–285. [Google Scholar] [CrossRef]
- Tsimenidis, S.; Lagkas, T.; Rantos, K. Deep learning in IoT intrusion detection. Journal of network and systems management. J. Netw. Syst. Manag. 2022, 30, 1–40. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Al-Turjman, F.; Kumar, M.; Stephan, T.; Mostarda, L. Capturing-the-invisible (CTI): Behavior-based attacks recognition in IoT-oriented industrial control systems. IEEE Access 2020, 8, 104956–104966. [Google Scholar] [CrossRef]
- Chen, Y.; Su, S.; Yu, D.; He, H.; Wang, X.; Ma, Y.; Guo, H. Cross-Domain Industrial Intrusion Detection Deep Model Trained With Imbalanced Data. IEEE Internet Things J. 2022, 10, 584–596. [Google Scholar] [CrossRef]
- Khan, M.A. HCRNNIDS: Hybrid Convolutional Recurrent Neural Network-Based Network Intrusion Detection System. Processes 2021, 9, 834. [Google Scholar] [CrossRef]
- Hu, Y.; Li, H.; Luan, T.H.; Yang, A.; Sun, L.; Wang, Z.; Wang, R. Detecting stealthy attacks on industrial control systems using a permutation entropy-based method. Future Gener. Comput. Syst. 2020, 108, 1230–1240. [Google Scholar] [CrossRef]
- Ling, J.; Zhu, Z.; Luo, Y.; Wang, H. An intrusion detection method for industrial control systems based on bidirectional simple recurrent unit. Comput. Electr. Eng. 2021, 91, 107049. [Google Scholar] [CrossRef]
- Wang, C.; Wang, B.; Liu, H.; Qu, H. Anomaly detection for industrial control system based on autoencoder neural network. Wirel. Commun. Mob. Comput. 2020, 2020, 8897926. [Google Scholar]
- Umer, M.A.; Junejo, K.N.; Jilani, M.T.; Mathur, A.P. Machine learning for intrusion detection in industrial control systems: Applications, challenges, and recommendations. Int. J. Crit. Infrastruct. Prot. 2022, 38, 100516. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. Proc. Int. Conf. Mach. Learn. 2020, 119, 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; Volume 2021, pp. 15750–15758. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Wang, S.; Dai, Y.; Shen, J.; Xuan, J. Research on expansion and classification of imbalanced data based on SMOTE algorithm. Sci. Rep. 2021, 11, 24039. [Google Scholar] [CrossRef] [PubMed]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Data Type | Data Enhancement Methods | Feature Extraction Network | Feature Projection | Loss Function |
|---|---|---|---|---|---|
| Our Model | One-dimensional sequences | Add Gaussian noise, sequence inversion, SMOTE sampling | ResNet | LayerNorm | InfoNCE |
| Original Models | Two-dimensional images | Random cropping, random color transformation, etc. | ResNet | BatchNorm | InfoNCE |
| Symbols | Description |
|---|---|
| Data after normalization | |
| x | Un-normalized data |
| The minimum value in a piece of data | |
| The maximum value in a piece of data | |
| X | Raw data |
| Data after SMOTE algorithm enhancement | |
| Add Gaussian noise to the data | |
| Data after sequence inversion | |
| New data after merging | |
| Feature extraction vector 1 | |
| Feature extraction vector 2 | |
| Contrast loss values | |
| Logarithmic operations | |
| Exponential arithmetic | |
| S | Calculate similarity |
| Data without data enhancement | |
| Positive sample after data enhancement | |
| K | Number of samples |
| Negative samples after data enhancement | |
| Temperature coefficient: used to adjust the discrimination of difficult negative samples |
| Type of Attacks | Abbreviation |
|---|---|
| Normal | Normal |
| Naïve Malicious Response Injection | NMRI |
| Complex Malicious Response Injection | CMRI |
| Malicious State Command Injection | MSCI |
| Malicious Parameter Command Injection | MPCI |
| Malicious Function Code Injection | MFCI |
| Denial of Service | DoS |
| Reconnaissance | Recon |
| Model | Acc | Precision | Recall | F1 |
|---|---|---|---|---|
| Our Model | 0.957 | 0.981 | 0.940 | 0.960 |
| ResNet | 0.932 | 0.947 | 0.915 | 0.930 |
| Attention-LSTM | 0.947 | 0.953 | 0.923 | 0.937 |
| CNN-LSTM | 0.928 | 0.939 | 0.896 | 0.916 |
| Model | Training Time |
|---|---|
| Our Model | 196.32 s |
| ResNet | 477.73 s |
| Attention-LSTM | 210.83 s |
| CNN-LSTM | 472.13 s |
| Model | Acc | Precision | Recall | F1 |
|---|---|---|---|---|
| Our Model | 0.989 | 0.984 | 0.963 | 0.973 |
| ResNet | 0.978 | 0.965 | 0.960 | 0.962 |
| Attention-LSTM | 0.980 | 0.976 | 0.961 | 0.968 |
| CNN-LSTM | 0.967 | 0.962 | 0.958 | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Li, F.; Zhang, L.; Yang, A.; Hu, Z.; He, M. Intrusion Detection for Industrial Control Systems Based on Improved Contrastive Learning SimCLR. Appl. Sci. 2023, 13, 9227. https://doi.org/10.3390/app13169227
Li C, Li F, Zhang L, Yang A, Hu Z, He M. Intrusion Detection for Industrial Control Systems Based on Improved Contrastive Learning SimCLR. Applied Sciences. 2023; 13(16):9227. https://doi.org/10.3390/app13169227
Chicago/Turabian StyleLi, Chengcheng, Fei Li, Liyan Zhang, Aimin Yang, Zhibin Hu, and Ming He. 2023. "Intrusion Detection for Industrial Control Systems Based on Improved Contrastive Learning SimCLR" Applied Sciences 13, no. 16: 9227. https://doi.org/10.3390/app13169227
APA StyleLi, C., Li, F., Zhang, L., Yang, A., Hu, Z., & He, M. (2023). Intrusion Detection for Industrial Control Systems Based on Improved Contrastive Learning SimCLR. Applied Sciences, 13(16), 9227. https://doi.org/10.3390/app13169227