1. Introduction
For software maintenance, software developers utilize issue-tracking systems to quickly incorporate user requirements into their software products. While using the software products, users report bugs, feature suggestions, and other comments by creating issue reports. Developers can refer to the issue reports to make changes to the software products. However, the number of issue reports rapidly increases. In the case of active open-source software projects, hundreds of issue reports are accumulated daily. Manually managing such issue reports requires a significant amount of effort from developers.
Researchers have conducted studies on automatically classifying issue reports to systematically manage issue reports [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. Some of them [
1,
2,
3,
6,
7,
9] focused on classifying issue reports into a few categories, such as bug or non-bug. For example, Kallis et al. [
7] employed FastText to classify issue reports into three categories: Bug, Enhancement, and Question. Other studies attempt to classify issue reports into more categories [
5,
8,
10]. However, all of those studies solely utilized a single modality, thereby missing out on the potential benefits of incorporating heterogeneous information from issue reports. As a result, those models struggled to attain a comprehensive understanding of the issue report due to the limitations imposed by the scarcity of information. Consequently, such a single modality hinders the potential for substantial enhancements in issue classification performance.
In this paper, we notice that issue reports contain various types of information, including textual titles, body contents, images, videos, and code.
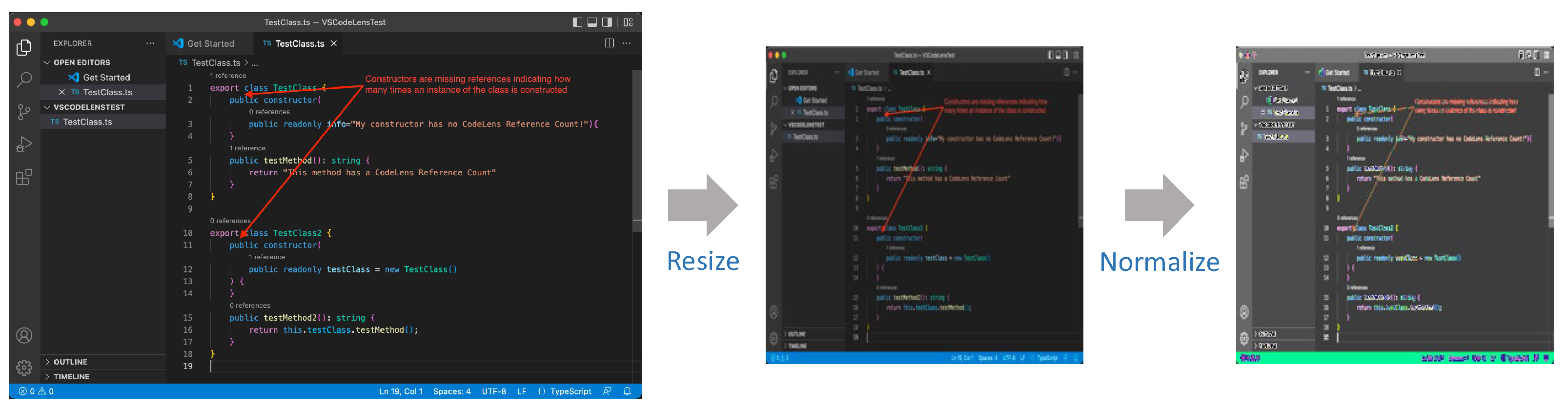
Figure 1 demonstrates an issue report that contains text, code, and images together. This is an example of an issue report in VS Code with issue number #147154. We expect that not only text data but also image and code data of issue reports can contribute to the performance of the issue classification, because the additional data can elaborate the representations of issue reports. Therefore, we propose MulDIC, a multimodal deep learning-based issue classification model that uses text, image, and code data of issue reports.
To evaluate the proposed model MulDIC, we conducted experiments to examine whether the proposed multimodal model, MulDIC, which combines text, image, and code data can improve the performance of issue classification. For the experiments, we selected four projects with many issue reports: VS Code, Kubernetes, Flutter, and Roslyn. With the four projects, we compared the performance of our proposed multimodal model with that of the state-of-the-art unimodal model proposed by Cho et al. [
10]. Our experimental results showed that our proposed approach achieved a higher F1-score by 5.07% to 14.12% compared to the existing method, improving the issue report classification performance in all projects.
The contributions of our study are as follows:
- 1.
We propose the first multimodal model that combines text, image, and code modalities for issue classification tasks.
- 2.
We evaluate the effectiveness of our proposed multimodal model by comparing a text-based unimodal model in issue classification tasks.
- 3.
We analyze the effect of image and code modality by experimenting with a combination of several different modalities.
- 4.
We make the code and datasets we used for our experiment available on GitHub.
The remainder of this paper is organized as follows.
Section 2 introduces the related works.
Section 3 proposes our approach.
Section 4 describes the experimental setup.
Section 5 presents the experimental results and discusses the results.
Section 6 concludes the paper.
4. Experimental Setup
4.1. Research Questions
We aim to investigate whether a multimodal model can improve the performance of issue classification through our experiments. Specifically, we focus on the data types in the issue reports, namely, text, image, and code, to determine if each data type contributes to the improvement. To guide our research, we formulated the following detailed research questions:
- 1.
RQ1. Does a multimodal model that combines text and image improve the performance of issue classification?
- 2.
RQ2. Does a multimodal model that combines text and code data improve the performance of issue classification?
- 3.
RQ3. Does a multimodal model that combines text, image, and code data improve the performance of issue classification?
4.2. Datasets
4.2.1. Project Selection
For our experiment, we selected open-source projects publicly available on GitHub. The reason for choosing open-source projects on GitHub is that GitHub provides an integrated issue management system, and users frequently submit issue reports on this platform. We investigated active projects on GitHub and sorted them based on the number of issue reports. After sorting many projects based on the number of issues, we manually investigated the top 100 projects. Among these projects, we investigated the labels attached to issue reports, and we chose projects that maintain ‘bug’ and ‘feature’ labels or the corresponding labels. We specifically chose projects that had issue reports labeled as either ‘bug’ or ‘feature’ since our proposed model aims to perform binary classification of issue reports into these classes.
Additionally, we verified whether issue reports simultaneously contained text, image, and code because we considered multimodal techniques for issue classification (as shown in
Figure 1). Selecting issue reports that contain all three types of data is important to examine the impact of each data type on issue classification for the same issue report.
We finally chose the top four projects that met our selection criteria. The four projects are VS Code, Kubernetes, Flutter, and Roslyn.
Table 1 presents the number of issue reports per label for each project on GitHub. The total number of issue reports for each selected project is as follows: VS Code (160,218 issues), Kubernetes (115,035 issues), Flutter (118,576 issues), and Roslyn (66,464 issues). Among them, the number of issue reports with the labels ‘bug’ or ‘feature’ is as follows: VS Code (48,427 issues), Kubernetes (18,243 issues), Flutter (23,004 issues), and Roslyn (16,706 issues).
Each project’s issue reports have unique characteristics. In the case of VS Code, the issue reports primarily focus on development environment-related issues, with many reports addressing problems encountered during task execution. For Kubernetes, many issue reports are related to container management and orchestration. Furthermore, there are specific platform-related issues that are reported when running Kubernetes. In Flutter’s case, many issue reports pertain to mobile app development, covering topics such as UI, compatibility, and app performance. Lastly, in the case of Roslyn, there is a significant number of issue reports related to C# and VB.NET code analysis. These reports include problems such as static code analysis, code optimization, and the discovery of potential bugs. In this experiment, we collected data from projects with these heterogeneous characteristics.
4.2.2. Data Collection
The process of collecting issue reports for each project, namely, VS Code, Kubernetes, Flutter, and Roslyn, was as follows. We collected issue reports labeled as ‘bug’ or ‘feature’. We collected these labels to compare the classification performance of our proposed model with that of the existing method, a CNN−based approach that showed good performance (Cho et al. [
10]). Additionally, we collected issue reports for each project that had at least one image and at least one code snippet present. The ‘Original Data’ column of
Table 2 represents the collected data.
For VS Code, we collected a total of 2331 data samples. Among them were 1351 samples labeled as ‘bug’ and 980 samples labeled as ‘feature’. In the case of Kubernetes, we collected 1014 data samples, with 866 samples labeled as ‘bug’ and 148 samples labeled as ‘feature’. As for Flutter, we collected 2820 data samples, consisting of 2061 ‘bug’ samples and 759 ‘feature’ samples. Lastly, we collected 1604 data samples for Roslyn, including 1341 bug and 263 feature samples.
4.2.3. Data Sampling
The collected data showed significant class imbalance across all projects. Such data imbalance can negatively impact the classification process by ignoring the characteristics of the minority class and biasing towards the majority class [
41,
42]. To address this issue, we can consider upsampling and downsampling. Downsampling reduces the quantity of data in the majority category to match the number of samples in the minority category. Downsampling offers advantages such as (1) freedom from overfitting compared to upsampling and (2) reduced computation time. Additionally, there is a high probability that users will not re-report issue reports related to outdated data. Therefore, (3) the loss of information due to data removal is not significant. Therefore, to mitigate the data imbalance problem, we apply downsampling. We retain all the data from the ‘feature’ class, while for the ‘bug’ class, we use a subset of the most recent data, matching the number of samples in the ‘feature’ class. The resulting dataset used for each experiment is as shown in the fourth column of
Table 2, with an equal number of samples for each label. We used an 80:20 training/test split on this dataset. For example, out of 1960 issue reports, 1568 were used as a training set, and 392 were used as a testing set for the VS Code project.
4.3. Models
In the experiment, we compared the existing unimodal deep learning model that utilizes only text data with MulDIC which is our proposed multimodal deep learning model. We aimed to investigate the contributions of image and code data in issue report classification by conducting three experiments: Text-Image, Text-Code, and Text-Image-Code. In these experiments, we used the Text Only model, which solely relies on text data, as the baseline for comparison. The experiment involves four models: Text Only, MulDIC, MulDIC, and MulDIC. In the rest of this paper, MulDIC refers to MulDIC. We will provide detailed descriptions of each model in the following subsections.
4.3.1. Unimodal Model
Text Only
The Text Only model utilizes only the text data from issue reports to classify them into bug or feature categories. The model uses downsampled issue report data for each project, as shown in
Table 2. We used the Text Only model as the baseline for comparison with the multimodal models.
4.3.2. Multimodal Models
MulDIC
The MulDIC model utilizes text and image data from issue reports to classify them into bug or feature categories. Similarly to the baseline model, the model uses each project’s downsampled issue report data. We compared the performance of the Text Only model (baseline), which uses only text data, and the MulDIC model, which uses text and image data.
MulDIC
The MulDIC model utilizes text and code data from issue reports to classify them. Similarly, we employed downsampled issue report data for model training. We compared the performance of the Text Only model (baseline) and the MulDIC model, which utilizes text and code data.
MulDIC
The MulDIC model represents the final proposed model in this study, which utilizes the text, image, and code data from issue reports. Similarly, we employed each project’s downsampled issue report data for classification into relevant labels. We compared the performance of the Text Only model (baseline) and the MulDIC model, which utilizes text, image, and code data. Additionally, we compared the performance of the MulDIC model with that of the MulDIC and MulDIC models.
4.4. Experimental Design
In this study, we conducted experiments to find answers to the research question set in
Section 4.1. To accomplish this, we compared three proposed models (MulDIC
, MulDIC
, and MulDIC
) with the baseline model (Text Only). We conducted all experiments on a per-project basis.
First, we performed modality-specific pre-processing on the sampled data to train the baseline and proposed models (see
Section 3.2). We used the pre-processed data as input for each model, and the data used by each model are consistent across modalities. After inputting the data into the model, we extracted features for each modality (refer to
Section 3.3). In the case of the three proposed multimodal models, we combined the extracted features from each modality (see
Section 3.4). Next, we classified the received feature vectors into their respective classes and measured their performance by comparing the results to the ground truth (see
Section 3.5). We performed this process for all models and compared the results obtained to evaluate the effectiveness of the proposed models.
To evaluate the value of multimodal models utilizing image and code data, we compared the classification performance of three proposed models with the baseline model. In the MulDIC and MulDIC models, we assessed the individual contributions of image and code data. In the MulDIC model, we examined the value of using image and code together. Furthermore, we compared the MulDIC model with the MulDIC and MulDIC models to evaluate the effectiveness of leveraging heterogeneous modalities.
4.5. Evaluation Metrics
The evaluation metrics used to measure the classification performance are Precision, Recall, and F1-score. We calculated these metrics for each class and utilized the weighted average based on the data distribution of each class. We calculated each evaluation metric as follows:
In the above equations, represents the i-th class, which consists of two categories: ‘bug’ and ‘feature’. is the ratio of issues predicted as correctly out of all the issues predicted as . is the ratio of issues correctly predicted as out of all the actual issues. F1-score is the harmonic mean of Precision and Recall.
5. Results
We present the overall results of the experiments conducted in this study in
Figure 8. According to
Figure 8, the multimodal model MulDIC
which combined all three different kinds of data, text, image, and code showed the highest F1-score. We will discuss the details of the results in the following subsections.
5.1. RQ1. Results of the Text-Image Experiment
We first conducted the experiment that compared the Text Only model with the multimodal model that combined text and image data of issue reports.
Table 3 shows the result. In
Table 3, the “Project” column represents the target projects for the experiments, and “Model” indicates the experimental models. The “Precision”, “Recall”, and “F1-score” columns represent the performance evaluation metrics for each experimental model, with all values expressed in percentage (%) and rounded to two decimal places. Additionally, we highlighted the highest scores for each project in bold. The first row per each project in
Table 3 corresponds to the Precision, Recall, and F1-score values of the Text Only model. The second row per each project in
Table 3 corresponds to the Precision, Recall, and F1-score values of the the multimodal model MulDIC
which combined text and image data.
With regard to the Precision values that are shown in the third column of
Table 3, the Text Only model yielded a Precision of 68.45% and the MulDIC
model a Precision of 79.60% for the VS Code project. The difference was 11.15%. In the case of Kubernetes, the Text Only model yielded a Precision of 66.91%, while the MulDIC
model a Precision of 68.35%. The difference was 1.44%. For Flutter, the Text Only model yielded a Precision of 67.70%, while the MulDIC
model yielded a Precision of 69.79%. The difference was 2.09%. For Roslyn, the Text Only model yielded a Precision of 62.92%, while the MulDIC
model yielded a Precision of 66.13%. The difference was 3.21%. The MulDIC
model outperformed the Text Only model across four different projects in terms of Precision.
With regard to the Recall values that are shown in the fourth column of
Table 3, the Text Only model achieved a Recall of 68.27% for VS Code, 66.10% for Kubernetes, 67.66% for Flutter, and 62.86% for Roslyn. In comparison, the MulDIC
model achieved a Recall of 77.92% for VS Code, 68.33% for Kubernetes, 69.41% for Flutter, and 66.04% for Roslyn. The MulDIC
model made improvements in Recall of 9.65%, 2.23%, 1.75%, and 3.18% for VS Code, Kubernetes, Flutter, and Roslyn, when compared to the Text Only model.
With regard to the F1-scores that are shown in the fifth column of
Table 3, the Text Only model achieved an F1-score of 68.36% for VS Code, 66.50% for Kubernetes, 67.68% for Flutter, and 62.89% for Roslyn. In comparison, the MulDIC
model achieved an F1-score of 78.75% for VS Code, 68.34% for Kubernetes, 69.60% for Flutter, and 66.08% for Roslyn. The MulDIC
model made improvements in F1-score of 10.39%, 1.84%, 1.92%, and 3.19% for VS Code, Kubernetes, Flutter, and Roslyn, when compared to the Text Only model.
These results indicate that the image data in issue reports are helpful in the issue classification task. This means that images are useful information for classifying issue reports. Therefore, when the model considers the text and image data of an issue report together, it gains a better understanding of the issue report.
5.2. RQ2. Results of the Text-Code Experiment
Second, we conducted the experiment that compared the Text Only model with the multimodal model which combined text and code data of issue reports.
Table 4 showed the result. The second row of
Table 4 per each project corresponds to the results of the Text-Code experiment.
The Precision values of the MulDIC model were 68.11% for VS Code, 79.97% for Kubernetes, 68.68% for Flutter, and 66.06% for Roslyn. The MulDIC model demonstrated a Precision improvement of 13.06%, 0.98%, and 3.14% for Kubernetes, Flutter, and Roslyn, compared to the Text Only model. However, when it comes to the VS Code project, the Precision value of the Text Only model is 0.34% higher than that of the MulDIC model.
The Recall values of MulDIC were 67.77% for VS Code, 78.33% for Kubernetes, 68.42% for Flutter, and 66.04% for Roslyn. The MulDIC model made improvements in Recall of 12.23%, 0.76%, and 3.18% for Kubernetes, Flutter, and Roslyn, respectively, when compared to the Text Only model. However, in VS Code, the performance of MulDIC is 0.50% lower than the Text Only model.
The F1-score values MulDIC were 67.94% for VS Code, 79.14% for Kubernetes, 68.55% for Flutter, and 66.05% for Roslyn. For Kubernetes, Flutter, and Roslyn, the MulDIC model showed an improvement of 12.64%, 0.87%, and 3.16% in the F1-score compared to the Text Only model. However, in the case of VS Code, The F1-score of MulDIC is −0.42% lower than that of the Text Only model.
We also compared the performance of MulDIC with that of MulDIC. In terms of Precision, MulDIC outperformed MulDIC in Kubernetes with 11.62% difference, while MulDIC outperformed MulDIC over the other three projects, VS Code, Flutter, and Roslyn with 11.49%, 1.11%, and 0.07% differences. MulDIC and MulDIC followed the same trend in terms of Recall and F1-score.
These results indicate that the code data in the issue reports can contribute to the issue classification task. This implies that code also provides valuable information for classifying issue reports. Consequently, integrating the text and code data of an issue report in the model enhances its comprehension of the issue report.
5.3. RQ3. Results of the Text-Image-Code Experiment
The fourth row of
Table 5 per each project corresponds to the results of the Text-Image-Code experiment.
First, when compared to the Text Only model, all of the Precision, Recall, and F1-score values of the MulDIC model are higher than those of the Text Only model. The MulDIC models showed Precision improvements of 11.95%, 14.34%, 9.15%, and 5.03% for VS Code, Kubernetes, Flutter, and Roslyn. MulDIC demonstrated Recall improvements of 11.43%, 13.90%, 8.00%, and 5.07% for VS Code, Kubernetes, Flutter, and Roslyn. MulDIC made F1-score improvements of 11.69%, 14.12%, 8.57%, and 5.05% for VS Code, Kubernetes, Flutter, and Roslyn.
Second, when compared to the MulDIC model, all of the Precision, Recall, and F1-score values of the MulDIC model are still higher than those of MulDIC. The Precision improvements of MulDIC are 0.80%, 12.90%, 7.06%, and 1.82% for VS Code, Kubernetes, Flutter, and Roslyn. The Recall improvements are 1.78%, 11.67%, 6.25%, and 1.89% for VS Code, Kubernetes, Flutter, and Roslyn. The F1-score improvements are 1.30%, 12.28%, 6.65%, and 1.86% for VS Code, Kubernetes, Flutter, and Roslyn.
Last, when compared to the MulDIC model, the Precision, Recall, and F1-score values of the MulDIC model are higher than those of MulDIC across all projects, VS Code, Kubernetes, Flutter, and Roslyn. The Precision improvements of MulDIC are 12.29%, 1.28%, 8.17%, and 1.89% for VS Code, Kubernetes, Flutter, and Roslyn. The Recall improvements are 11.93%, 1.67%, 7.24%, and 1.89% for VS Code, Kubernetes, Flutter, and Roslyn. The F1-score improvements are 12.11%, 1.48%, 7.70%, and 1.89% for VS Code, Kubernetes, Flutter, and Roslyn.
These findings indicate that incorporating multiple modalities leads to significant performance improvements. The results of this experiment demonstrate the synergistic effect of using heterogeneous modalities in classifying issue reports.
5.4. Results of Statistical Testing
As shown in
Table 5, the MulDIC
model exhibited the highest performance across all projects in this experiment. This indicates the potential to generalize and apply this model to various open-source projects on GitHub. In this section, we conducted a Mann–Whitney U-test [
43] to verify the statistical significance of the results by comparing the classification accuracy levels between the MulDIC
model and the baseline model for all projects. Since the data in the experiment results did not follow a normal distribution, we adopted the non-parametric statistical test, Mann–Whitney U-test. The hypotheses set for this test are as follows:
H0 (null hypothesis). The averaged performance of a unimodal model is equal to that of a multimodal model.
H1 (alternative hypothesis). The averaged performance of a unimodal model is not equal to that of a multimodal model.
Table 6 presents the test results for the individual and overall projects. The
p-values for the individual projects (VS Code, Kubernetes, Flutter) and the total project (Total) were very close to 0.00, indicating significantly lower values than the significance level criterion of 0.05 for the hypothesis test. Therefore, we rejected the null hypothesis (H0) and accepted the alternative hypothesis (H1). In other words, there is a significant difference between the baseline and proposed models, and the proposed approach is statistically significant. Furthermore, we calculated this test’s effect size [
43] to determine practical significance. The effect sizes ranged from 0.2 to 0.5 in most projects, generally considered moderate. This indicates that the difference between the proposed model and the baseline model is statistically significant and practically significant.
The test results for Roslyn showed a marginal difference, with the acceptance of the null hypothesis (H0) and a small effect size. This is understandable, considering the degree of performance improvement of the model. Roslyn had the slightest improvement among the four projects, with a 5.07% increase in the F1-score. However, in deep learning models, such a level of performance improvement and difference between models is significant. The test results for Roslyn showed a marginal difference according to the criteria of the statistical test, but in terms of performance experiments, it achieved a practically significant improvement. Additionally, the total project’s validation results and effect size indicate that the proposed model is statistically and practically significant. Therefore, we expect our proposed model to perform well when applied to other open-source projects.
6. Discussion
6.1. Synergistic Effects of Using Multiple Modalities
In our experiments, the MulDIC model, which combines information from text, image, and code data, showed the significant performance improvement of 5.07~14.12% F1-score, compared to the Text Only model. The MulDIC model showed an F1-score improvement of 1.84~10.39%, compared to the Text Only model. On the other hand, the MulDIC model showed an F1-score improvement of 12.64% for the Kubernetes project, but showed a decrease of 0.42% for the VS Code project. The MulDIC model significantly outperformed the MulDIC and MulDIC models across all projects. These results demonstrate the synergistic effect of a multimodal model. Here, the synergistic effect refers to the phenomenon where using different information sources together produces better results than using individual sources alone.
Since the three modalities of an issue report contain different information, considering them together allows us to obtain more heterogeneous and rich information. To illustrate the information of three modalities,
Figure 1 shows the contents of issue report #147154 (
https://github.com/microsoft/vscode/issues/147154, accessed on 15 August 2023). In the issue report, the textual information specifies the conditions where the bug occurs and steps to reproduce. The code information provides the code lines typed by a reporter, when s/he faced the bug. The image information shows the buggy result in the situation. The MulDIC
model uses all of these different kinds of information for classifying an issue report and successfully classifies issue report #147154 as a bug.
6.2. Discussion on the Text-Code Experiment for VS Code
As we already discussed in
Section 6.1, the MulDIC
model applied to the VS Code project showed no performance improvement. For the VS Code project, the MulDIC
model achieved an F1-score of 67.94%, while the Text Only model achieved a 68.36% F1-score. Therefore, we conjectured and investigated various factors that could be related to the inability of the MulDIC
model.
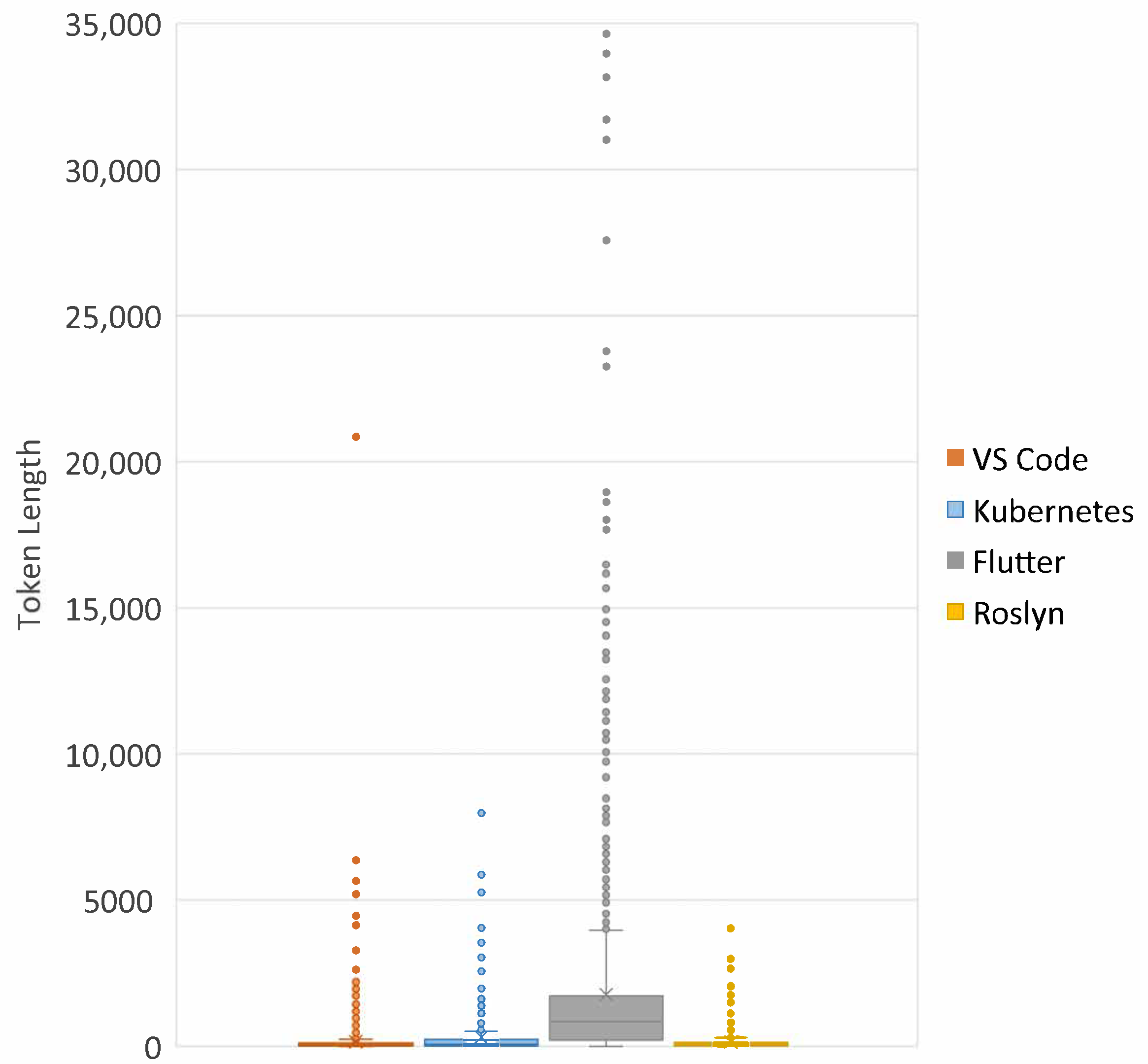
First, we investigated the token length of code data, because we set the maximum input length of code data to the value corresponding to each project’s third quartile of the token length of the entire code data. If the input token length is short, the model cuts off substantial data, resulting in significant data loss. On the other hand, if the length is long, the model can create excessively sparse vectors, which can hinder training efficiency. We investigated the statistics of token length for code data across different projects in the form of a boxplot, as shown in
Figure 9. A different color represents each project, and the vertical axis represents the length of the tokens. We found that the IQR (InterQuartile Range) of VS Code is the smallest among the projects, so we estimated that VS Code had less data loss than other projects. We concluded that the token length of code data is not the factor that affected the exceptional case.
Second, when we trained the issue classification models used in our experiments, we assigned the same learning weights to each modality of text, image, and code. This arbitrary weight assignment can be a factor affecting the model performance. For instance, in the case of the VS Code project, if the textual data may be much more informative than the code data, then the Text Only model can achieve a high performance compared to the MulDIC model. In addition, typically, a multimodal model shares information through interconnections between modalities. If the connectivity among modalities is weak, it can decrease the model performance. Therefore, we conjecture that our weight assignment affected the connectivity among modalities and so the MulDIC model for the VS Code project had a weak connectivity between the text and code modalities, hindering the synergistic effect.
Lastly, the difference in the quality of the data can be another factor affecting the model performance. Data quality is a crucial factor affecting the model performance. However, since our experimental projects have issue reports written in different ways by different groups of contributors, the data quality will be different depending on products. Therefore, we conjecture that the low-quality nature of the source data in VS Code had a negative effect on the model.
6.3. Implication and Future Work
The implications of our study for researchers, developers, companies, or users are as follows. First, researchers can develop issue classification techniques based on the multimodal model proposed in this paper. For example, we applied the multimodal model to binary issue classification. We believe this approach can be extended to research trends involving multi-class and multi-label classification techniques. Second, developers can save time in reviewing issue reports by using automated issue classification techniques. Developers need to classify issues related to their software into related tasks for efficient maintenance. Automated issue classification can reduce developers’ time spent in reading individual issue reports and help developers to avoid misclassification of software-related issues. To be practical, high performance of issue classification is crucial, and our multimodal model demonstrates its capability to improve the performance of automated issue classification. Finally, companies can employ automated techniques to classify issue reports, which can help identify systematic issue trends of the software systems. Our multimodal model can contribute to making the trends more accurate.
In the future, we would like to explore state-of-the-art feature extraction techniques and fusion methods. First, while we used CNN−based channels to extract modality features for text, image, and code data in this paper, we observed that each modality has its own state-of-the-art feature extraction models. For example, for text data, we see that the state-of-the-art model is based on BERT, and for code data, we see that the state-of-the-art model is CodeBERT [
44]. For images, we can consider computer vision models utilizing Transformers. By adopting state-of-the-art feature extraction models, we expect to improve the performance of issue classification. Second, we would like to experiment with several multimodal fusion methods, which merge the representation vectors of the three modalities. In this paper, we employed an entry-level multimodal fusion technique, namely, element-wise multiplication, which lacks interaction between the features of modalities. In the future, we will apply the latest methods based on bilinear pooling, such as Multimodal Compact Bilinear Pooling (MCB) [
28], Multimodal Low-rank Bilinear Pooling (MLB) [
29], Multimodal Tucker Union (MUTAN) [
27], and Multimodal Factorized Bilinear Pooling (MFB) [
45].These techniques aim to optimize feature interaction while minimizing computational complexity. We will examine whether the different fusion methods can contribute to the performance of issue classification.
8. Conclusions
Issue reports contain textual and other modalities, such as images and code. With this in mind, we proposed MulDIC, a multimodal deep learning model that effectively classifies issue reports using text, image, and code data. To assess the effectiveness of MulDIC and investigate the impact of each modality on the issue report classification task, we conducted experiments. Remarkably, the MulDIC model, which utilized text, image, and code data, demonstrated superior performance with 5.07~14.12% improvement in the F1-score, compared to the baseline models. When it comes to the impact of each modality, the image modality with the text modality consistently improved the performance of issue classification tasks. Meanwhile, the code modality mostly improved the performance of issue classification tasks, but not in all of the cases. The combination of all three modalities outperformed any combinations of two modalities. These results indicate that leveraging multimodal approaches considering heterogeneous content types of issue reports can enhance the performance of issue report classification and that the combination of text, image, and code modalities can yield synergistic effects.
In future research, we plan to continue exploring additional aspects of a multimodal model by considering the characteristics of issue reports and their heterogeneous contents. First, our proposed model is limited in processing each modality using a CNN−based channel and merging the modality-specific representation vectors through element-wise multiplication. We will explore state-of-the-art multimodal models that can increase the expressive power of each modality and the combination of these text, image, and code modalities. For example, by applying state-of-the-art fusion methods for combining text, image, and code data, we could improve the performance of issue classification tasks. In addition, we could consider adding new modalities or data in future investigations. Second, we applied our proposed model to four different projects, and in one case, a combination of text and code modalities yielded lower performance than that of a Text Only modality. To increase the reliability of our study, we plan to extend our experimental data to include a large number of software projects. Applying our proposed model to more projects will yield more consistent and reliable results.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}