

A Novel Computationally Efficient Approach for Exploring Neural Entrainment to Continuous Speech Stimuli Incorporating Cross-Correlation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experiments
2.2. EEG Acquisition and Preprocessing
2.3. Speech Feature Extraction
2.4. Detrended Cross-Correlation and EEG Analysis
2.4.1. Detrended Cross-Correlation Computation
2.4.2. Forward Model Computation
2.4.3. Model Training and Performance Evaluation
2.4.4. Model Significance Evaluation
2.4.5. Comparisons of Computational Efficiency and Cross-Validation Performance
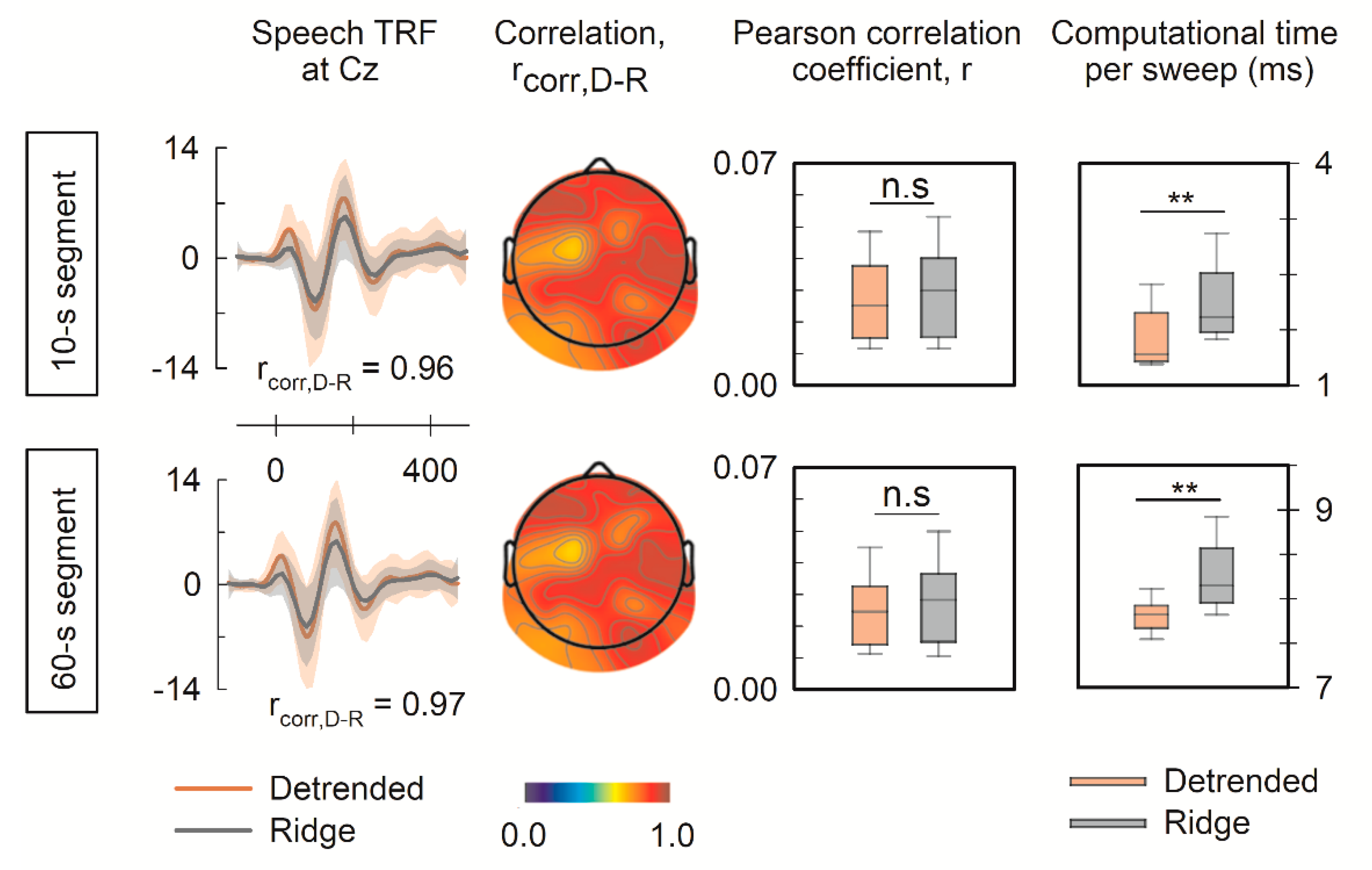
3. Results
3.1. Performance of the Univariate Forward Model
3.2. Performance of the Multivariate Forward Model
3.3. Significance of the Detrended Cross-Correlation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Gaudet, I.; Hüsser, A.; Vannasing, P.; Gallagher, A. Functional brain connectivity of language functions in children revealed by EEG and MEG: A systematic review. Front. Hum. Neurosci. 2020, 14, 62. [Google Scholar] [CrossRef] [PubMed]
- Gui, P.; Jiang, Y.; Zang, D.; Qi, Z.; Tan, J.; Tanigawa, H.; Jiang, J.; Wen, Y.; Xu, L.; Zhao, J.; et al. Assessing the depth of language processing in patients with disorders of consciousness. Nat. Neurosci. 2020, 23, 761–770. [Google Scholar] [CrossRef] [PubMed]
- Shain, C.; Blank, I.A.; van Schijndel, M.; Schuler, W.; Fedorenko, E. fMRI reveals language-specific predictive coding during naturalistic sentence comprehension. Neuropsychologia 2020, 138, 107307. [Google Scholar] [CrossRef]
- Loiselle, D.L. Event-related potentials: A methods handbook. Neurology 2006, 67, 1729. [Google Scholar] [CrossRef]
- Martin, B.A.; Tremblay, K.L.; Korczak, P. Speech evoked potentials: From the laboratory to the clinic. Ear Hear. 2008, 29, 285–313. [Google Scholar] [CrossRef] [PubMed]
- Maddox, R.K.; Lee, A.K.C. Auditory brainstem responses to continuous natural speech in human listeners. eNeuro 2018, 5. [Google Scholar] [CrossRef] [PubMed]
- Marmarelis, V.Z. Nonlinear Dynamic Modeling of Physiological Systems; Wiley: Hoboken, NJ, USA, 2004; pp. 1–541. [Google Scholar]
- Boer, E.D.; Kuyper, P. Triggered correlation. IEEE Trans. Biomed. Eng. 1968, BME-15, 169–179. [Google Scholar] [CrossRef] [PubMed]
- Boynton, G.M.; Engel, S.A.; Glover, G.H.; Heeger, D.J. Linear systems analysis of functional magnetic resonance imaging in human V1. J. Neurosci. 1996, 16, 4207–4221. [Google Scholar] [CrossRef] [PubMed]
- Coppola, R. A system transfer function for visual evoked potentials. In Human Evoked Potentials: Applications and Problems; Lehmann, D., Callaway, E., Eds.; Springer: Boston, MA, USA, 1979; pp. 69–82. [Google Scholar]
- Marmarelis, P.Z.; Marmarelis, V.Z. Analysis of Physiological Systems: The White-Noise Approach; Plenum Press: New York, NY, USA, 1978. [Google Scholar]
- Ringach, D.; Shapley, R. Reverse correlation in neurophysiology. Cogn. Sci. 2004, 28, 147–166. [Google Scholar] [CrossRef]
- Abrams, D.A.; Nicol, T.; Zecker, S.; Kraus, N. Right-hemisphere auditory cortex is dominant for coding syllable patterns in speech. J. Neurosci. 2008, 28, 3958–3965. [Google Scholar] [CrossRef]
- Ahissar, E.; Nagarajan, S.; Ahissar, M.; Protopapas, A.; Mahncke, H.; Merzenich, M.M. Speech comprehension is correlated with temporal response patterns recorded from auditory cortex. Proc. Natl. Acad. Sci. USA 2001, 98, 13367–13372. [Google Scholar] [CrossRef] [PubMed]
- Aiken, S.J.; Picton, T.W. Human cortical responses to the speech envelope. Ear Hear. 2008, 29, 139–157. [Google Scholar] [CrossRef] [PubMed]
- Lalor, E.C.; Pearlmutter, B.A.; Reilly, R.B.; McDarby, G.; Foxe, J.J. The VESPA: A method for the rapid estimation of a visual evoked potential. NeuroImage 2006, 32, 1549–1561. [Google Scholar] [CrossRef] [PubMed]
- Lalor, E.C.; Power, A.J.; Reilly, R.B.; Foxe, J.J. Resolving precise temporal processing properties of the auditory system using continuous stimuli. J. Neurophysiol. 2009, 102, 349–359. [Google Scholar] [CrossRef]
- Crosse, M.J.; Di Liberto, G.M.; Bednar, A.; Lalor, E.C. The multivariate temporal response function (mTRF) toolbox: A MATLAB toolbox for relating neural signals to continuous stimuli. Front. Hum. Neurosci. 2016, 10, 604. [Google Scholar] [CrossRef] [PubMed]
- Theunissen, F.E.; Sen, K.; Doupe, A.J. Spectral-temporal receptive fields of nonlinear auditory neurons obtained using natural sounds. J. Neurosci. 2000, 20, 2315–2331. [Google Scholar] [CrossRef] [PubMed]
- Theunissen, F.E.; David, S.V.; Singh, N.C.; Hsu, A.; Vinje, W.E.; Gallant, J.L. Estimating spatio-temporal receptive fields of auditory and visual neurons from their responses to natural stimuli. Network 2001, 12, 289–316. [Google Scholar] [CrossRef] [PubMed]
- Machens, C.K.; Wehr, M.S.; Zador, A.M. Linearity of cortical receptive fields measured with natural sounds. J. Neurosci. 2004, 24, 1089–1100. [Google Scholar] [CrossRef]
- Crosse, M.J.; Zuk, N.J.; Di Liberto, G.M.; Nidiffer, A.R.; Molholm, S.; Lalor, E.C. Linear modeling of neurophysiological responses to speech and other continuous stimuli: Methodological considerations for applied research. Front. Neurosci. 2021, 15, 705621. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J.; Lim, D.; Lee, K.; Jeon, A.; Jung, E. Development of Korean standard sentence lists for sentence recognition tests. Audiol. Speech Res. 2008, 4, 161–177. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Greenwood, D.D. A cochlear frequency-position function for several species—29 years later. J. Acoust. Soc. Am. 1990, 87, 2592–2605. [Google Scholar] [CrossRef] [PubMed]
- Gröger, J.P.; Fogarty, M.J. Broad-scale climate influences on cod (Gadus morhua) recruitment on Georges Bank. ICES J. Mar. Sci. 2011, 68, 592–602. [Google Scholar] [CrossRef]
- Roehri, N.; Lina, J.M.; Mosher, J.C.; Bartolomei, F.; Benar, C.G. Time-frequency strategies for increasing high-frequency oscillation detectability in intracerebral EEG. IEEE Trans. Biomed. Eng. 2016, 63, 2595–2606. [Google Scholar] [CrossRef] [PubMed]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications (Springer Texts in Statistics); Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Polge, R.J.; Mitchell, E.M. Impulse response determination by cross correlation. IEEE Trans. Aerosp. Electron. Syst. 1970, AES–6, 91–97. [Google Scholar] [CrossRef]
- Browne, M.W. Cross-validation methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [PubMed]
- Di Liberto, G.M.; O’Sullivan, J.A.; Lalor, E.C. Low-frequency cortical entrainment to speech reflects phoneme-level processing. Curr. Biol. 2015, 25, 2457–2465. [Google Scholar] [CrossRef] [PubMed]
- Power, A.J.; Foxe, J.J.; Forde, E.J.; Reilly, R.B.; Lalor, E.C. At what time is the cocktail party? A late locus of selective attention to natural speech. Eur. J. Neurosci. 2012, 35, 1497–1503. [Google Scholar] [CrossRef]
- Kong, Y.Y.; Mullangi, A.; Ding, N. Differential modulation of auditory responses to attended and unattended speech in different listening conditions. Hear. Res. 2014, 316, 73–81. [Google Scholar] [CrossRef]
- Olguin, A.; Cekic, M.; Bekinschtein, T.A.; Katsos, N.; Bozic, M. Bilingualism and language similarity modify the neural mechanisms of selective attention. Sci. Rep. 2019, 9, 8204. [Google Scholar] [CrossRef] [PubMed]
- Ding, N.; Chatterjee, M.; Simon, J.Z. Robust cortical entrainment to the speech envelope relies on the Spectro-temporal fine structure. NeuroImage 2014, 88, 41–46. [Google Scholar] [CrossRef] [PubMed]
- Martin, S.; Brunner, P.; Holdgraf, C.; Heinze, H.J.; Crone, N.E.; Rieger, J.; Schalk, G.; Knight, R.T.; Pasley, B.N. Decoding spectrotemporal features of overt and covert speech from the human cortex. Front. Neuroeng. 2014, 7, 14. [Google Scholar] [CrossRef] [PubMed]
- Broderick, M.P.; Anderson, A.J.; Di Liberto, G.M.; Crosse, M.J.; Lalor, E.C. Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech. Curr. Biol. 2018, 28, 803–809.e3. [Google Scholar] [CrossRef] [PubMed]
- Brodbeck, C.; Presacco, A.; Simon, J.Z. Neural source dynamics of brain responses to continuous stimuli: Speech processing from acoustics to comprehension. Neuroimage 2018, 172, 162–174. [Google Scholar] [CrossRef] [PubMed]
- Kulasingham, J.P.; Brodbeck, C.; Presacco, A.; Kuchinsky, S.E.; Anderson, S.; Simon, J.Z. High gamma cortical processing of continuous speech in younger and older listeners. NeuroImage 2020, 222, 117291. [Google Scholar] [CrossRef] [PubMed]
- Etard, O.; Messaoud, R.B.; Gaugain, G.; Reichenbach, T. The neural response to the temporal fine structure of continuous musical pieces is not affected by selective attention. bioRxiv 2021. [Google Scholar] [CrossRef]
- Kreyszig, E. Advanced Engineering Mathematics, 5th ed.; Wiley: New York, NY, USA, 1983. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computational Time (s) | Validation Pearson Correlation | |||||
|---|---|---|---|---|---|---|
| Detrended Cross- Correlation | Ridge Regression | p-Value | Detrended Cross- Correlation | Ridge Regression | p-Value | |
| Univariate forward model | 1.09 ± 0.27 | 1.29 ± 0.33 | * | 0.024 ± 0.010 | 0.027 ± 0.009 | n.s |
| Multivariate forward model | 3.73 ± 1.56 | 21.69 ± 2.12 | ** | 0.038 ± 0.012 | 0.038 ± 0.011 | n.s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do Anh Quan, L.; Thi Trang, L.; Joo, H.; Kim, D.; Woo, J. A Novel Computationally Efficient Approach for Exploring Neural Entrainment to Continuous Speech Stimuli Incorporating Cross-Correlation. Appl. Sci. 2023, 13, 9839. https://doi.org/10.3390/app13179839
Do Anh Quan L, Thi Trang L, Joo H, Kim D, Woo J. A Novel Computationally Efficient Approach for Exploring Neural Entrainment to Continuous Speech Stimuli Incorporating Cross-Correlation. Applied Sciences. 2023; 13(17):9839. https://doi.org/10.3390/app13179839
Chicago/Turabian StyleDo Anh Quan, Luong, Le Thi Trang, Hyosung Joo, Dongseok Kim, and Jihwan Woo. 2023. "A Novel Computationally Efficient Approach for Exploring Neural Entrainment to Continuous Speech Stimuli Incorporating Cross-Correlation" Applied Sciences 13, no. 17: 9839. https://doi.org/10.3390/app13179839
APA StyleDo Anh Quan, L., Thi Trang, L., Joo, H., Kim, D., & Woo, J. (2023). A Novel Computationally Efficient Approach for Exploring Neural Entrainment to Continuous Speech Stimuli Incorporating Cross-Correlation. Applied Sciences, 13(17), 9839. https://doi.org/10.3390/app13179839