
Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks

Abstract
:1. Introduction
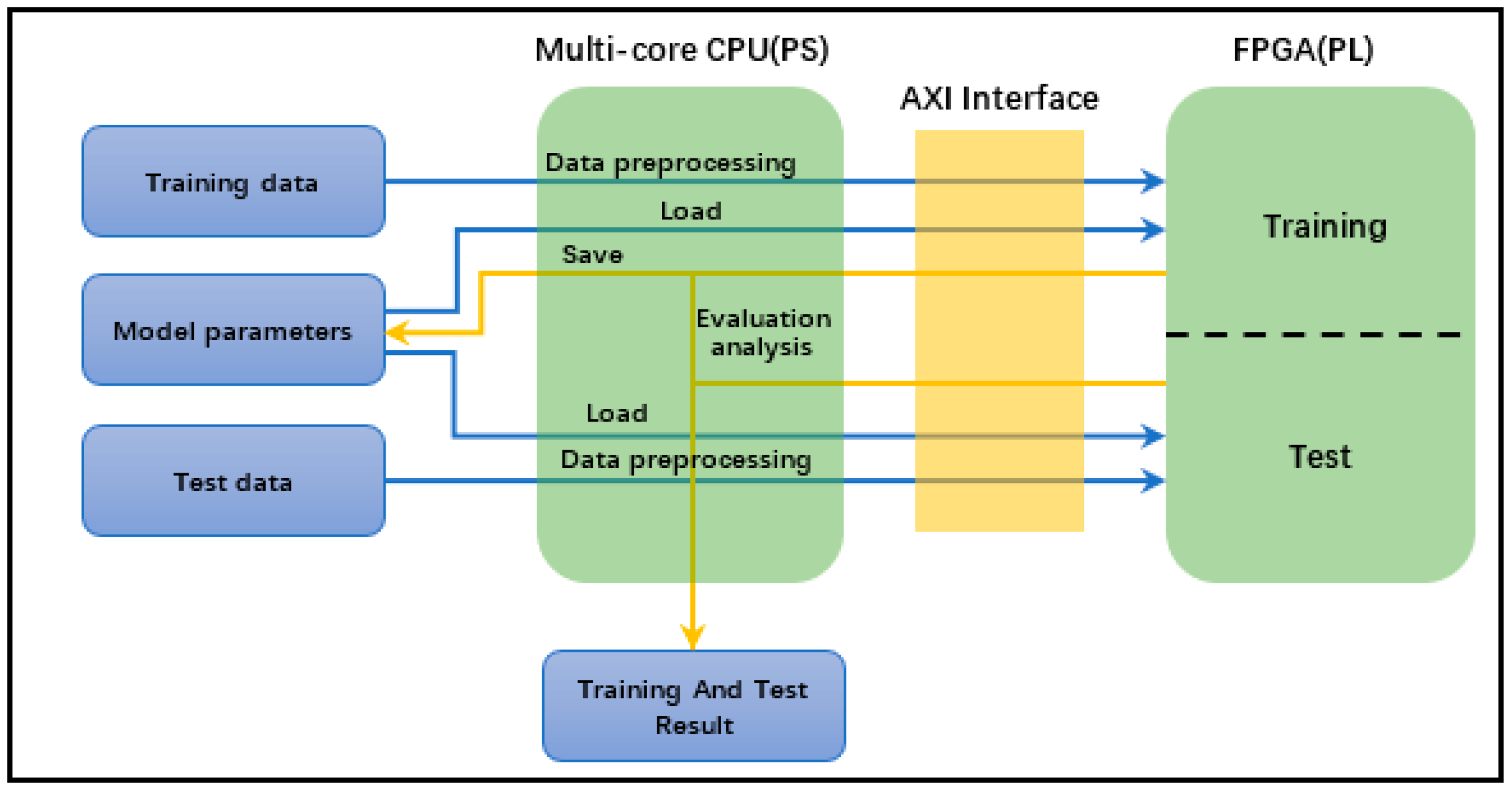
- Based on the features of HA SoC, a new neural network implementation method is proposed to balance a load of software and hardware by introducing the co-design of software and hardware. Considering the flexibility of software and the parallel processing ability of hardware, the integrated neural network training and inference process is realized.
- In this implementation, PL is used to realize the training and inference process of the neural network, and PS is used to realize the scheduling of the whole process of training and inference including data preprocessing.
- Pipelining and parallelism are weighed within PL in terms of limited logical resources, according to the data flow structure of training and inference. On the premise of ensuring the forward inference and training accuracy of the neural network, the training process of the neural network is accelerated as much as possible.
2. Related Work
3. Method
3.1. Integrated Architecture of Neural Network Training and Inference
3.2. Training and Inference of Neural Networks
4. Core Algorithm and Implementation
4.1. Structure Design of Convolution Layer
| Algorithm 1: Convolution. |
| w: Data width h: Data height k: Convolutional kernel dimension input: Convolutional layer input data kernel: Convolution kernel parameters out: Convolutional layer output data |
| 1. for(int i = 0; i < w − k + 1; i++) 2. for(int j = 0; j < h − k + 1; j++){ 3. out [i × (h − k + 1) + j] = 0; 4. for(int col = i; col < i + 3; col++) 5. for(int row = j; row < j + 3; row++) 6. out [i × (h − k + 1) + j]+ = input [col x h + row] × kernel[(col − i) × k + (row − j)]; } |
| Algorithm 2: OverturnKernel. |
| k: Convolutional kernel dimension input_matrix: Convolution kernel before rotation out_matrix: Rotated convolution kernel |
| 1. for(int i = 0; i < k; i++) 2. for(int j = 0; j < k; j++) 3. output_matrix[(k − 1 − i) × k + (k − 1 − j)] = input_matrix[i × k + j]; |
| Algorithm 3: Padding. |
| w: The width of the matrix to be filled stride: Each edge is filled with dimensions input_matrix: The matrix to be filled out_matrix: The filled matrix |
| 1. for(int i = 0; i < w + 2 × stride; i++) 2. for(int j = 0; j < w + 2 × stride; j++){ 3. if((i >= stride)&&(j >= stride)&&(i < stride + w)&&(j < stride + w)) 4. output_matrix[i × (w + 2 × stride) + j] = input_matrix[(i − stride) × w + (j − stride)]; 5. else 6. output_matrix[i × (w + 2 × stride) + j] = 0; } |
4.2. Structure Design of the Fully Connected Layer
4.2.1. Fully Connected Layer Multiplication Structure
| Algorithm 4: MatrixMultiPLy. |
| h: Fully connected input vector dimension h_out: Fully connected output vector dimension input_matrix: Fully connected input vectors para_layer: Fully connected weight matrix out_matrix: Fully connected output vectors |
| 1. for(int j = 0; j < h_out; j++){ 2. output_matrix[j] = 0; 3. for(int i = 0; i < h; i++) 4. output_matrix[j] += input_matrix[i] × para_layer[i × h_out + j]; } |
| Algorithm 5: CalculateMatrixGrad. |
| w: Fully connected weight matrix width h: Fully connected weight matrix height input_matrix: Fully connected weight matrix grad: Fully connected output gradient out_matrix: Fully connected input gradient |
| 1. for(int i = 0; i < w; i++){ 2. output_matrix[i] = 0;//Gradient clear, easy to add 3. for(int j = 0; j < h; j++) 4. output_matrix[i] += input_matrix[i × h + j] × grad[j]; } |
| Algorithm 6: MatrixBackPropagationMultiPLy. |
| w: Fully connected weight matrix width h: Fully connected weight matrix height input_matrix: Fully connected input gradient grad: Fully connected output gradient rgrad: Fully connected weight matrix gradient |
| 1. for(int i = 0; i < w; i++) 2. for(int j = 0; j < h; j++) 3. rgrad[i × h + j] = input_matrix[i] × grad[j]; |
4.2.2. Activation Function Structure at the Full Connection Layer
| Algorithm 7: Relu. |
| h: The height of the column vector to be activated input_matrix: The column vector to be activated output_matrix: Activate the rear column vector |
| 1. for(int j = 0; j < h; j++) 2. Output_matrix [j] = Max (input_matrix [j], input_matrix [j] × 0.05); |
| Algorithm 8: ReluBackPropagation. |
| h: The height of the column vector to be activated input_matrix: Activate the rear column vector grad: Gradient after activation output_matrix: The gradient before activation |
| 1. for(int i = 0; i < w; i++) 2. if(input_matrix[i] > 0) 3. output_matrix[i] = 1 × grad[i]; 4. else 5. Output_matrix [I] = 0.05 × grad [I]; |
4.3. Structure Design of the Pooling Layer
| Algorithm 9: MaxPool2d. |
| w: The width of the data before pooling h: The height of the data before pooling k: The dimensions of the pooled kernel input_matrix: Data before pooling output_matrix: Pooled data locate_matrix: The position matrix in pooling |
| 1. for(int i = 0; i < w/k; i++) 2. for(int j = 0; j < h/k; j++){ 3. int max_num = −999; 4. for(int col = i × k; col < (i + 1) × k; col++) 5. for(int row = j × k; row < (j + 1) × k; row++) 6. if(input_matrix[col × h + row] > max_num){ 7. max_num = input_matrix[col × h + row]; 8. locate_matrix[i × (h/k) + j] = col × h + row; 9. } 10. output_matrix[i × (h/k) + j] = max_num; } |
| Algorithm 10: MaxPooBackPropagation. |
| w: The width of the data before pooling h: The height of the data before pooling k: The dimensions of the pooled kernel input_matrix: The gradient after pooling output_matrix: The gradient before pooling locate_matrix: The position matrix in pooling |
| 1. for(int col = 0; col < w; col++) 2. for(int low = 0; low < h; low++) 3. output_matrix[col × h+low] = 0; 4. int current_locate; 5. for(int i = 0; i < w/k; i++) 6. for(int j = 0; j < h/k; j++){ 7. current_locate = locate_matrix[i × (h/k) + j]; 8. output_matrix[current_locate] = input_matrix[i × (h/k) + j]; } |
5. Experiment and Verification
5.1. Verifying the Construction of the Platform
- (1)
- The training and inference module is used to conduct a large number of computational processes of convolutional neural network training and forward inference;
- (2)
- The Zynq Ultrascale+ MPSoC module is a PS mapping within MPSoC;
- (3)
- The AXI Interconnect module connects multiple AXI memory-mapped master devices to multiple memory-mapped slave devices through the switch structure, which is mainly used as the bridge connecting S_AXI peripheral;
- (4)
- The AXI SmartConnect module is used to connect AXI peripherals to PS, mainly as a bridge connecting M_AXI in this structure;
- (5)
- The process system reset module is used to generate reset signals for PS and the other three modules.
5.2. Design of Verification Method
6. Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the ACM, Monterey, CA, USA, 22–24 February 2015. [Google Scholar]
- Colbert, I.; Daly, J.; Kreutz-Delgado, K.; Das, S. A Competitive Edge: Can FPGAs Beat GPUs at DCNN Inference Acceleration in Resource-Limited Edge Computing Applications? arXiv 2021, arXiv:2102.00294. [Google Scholar]
- He, B.; Zhang, Y. The Definitive Guide of Digital Signal Processing on Xilinx FPGA from HDL to Model and C Description; Tsinghua University Press: Beijing, China, 2014. [Google Scholar]
- Dai, Y.; Bai, Y.; Zhang, W.; Chen, X. Performance evaluation of hardware design based on Vivado HLS. Comput. Knowl. Technol. 2021, 17, 1–4. [Google Scholar]
- Venieris, S.I.; Bouganis, C. fpgaConvNet: A Framework for Mapping Convolutional Neural Networks on FPGAs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar] [CrossRef] [Green Version]
- DiCecco, R.; Lacey, G.; Vasiljevic, J.; Chow, P.; Taylor, G.; Areibi, S. Caffeinated FPGAs: FPGA framework for Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 265–268. [Google Scholar] [CrossRef] [Green Version]
- Hua, S. Design optimization of light weight handwritten digital system based on FPGA. Electron. Prod. 2020, 6–7+37. [Google Scholar]
- Bachtiar, Y.A.; Adiono, T. Convolutional Neural Network and Maxpooling Architecture on Zynq SoC FPGA. In Proceedings of the 2019 International Symposium on Electronics and Smart Devices (ISESD), Badung, Indonesia, 8–9 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ghaffari, S.; Sharifian, S. FPGA-based convolutional neural network accelerator design using high level synthesize. In Proceedings of the 2016 2nd International Conference of Signal Processing and Intelligent Systems (ICSPIS), Tehran, Iran, 14–15 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2921–2926. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-eye: A comPLete design flow for mapping CNN onto embedded FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2017, 37, 35–47. [Google Scholar] [CrossRef]
- Gschwend, D. Zynqnet: An fpga-accelerated embedded convolutional neural network. arXiv 2020, arXiv:2005.06892. [Google Scholar]
- Zheng, Y.; He, B.; Li, T. Research on the Lightweight Deployment Method of Integration of Training and Inference in Artificial Intelligence. Appl. Sci. 2022, 12, 6616. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, K.; Wang, Y.; Wang, G.; Yang, Z.; Yuan, J. FPGA Parallel Structure Design for Convolutional Neural Network (CNN) Algorithm. Microelectron. Comput. 2019, 36, 57–62. [Google Scholar]
- Lu, Y.; Chen, Y.; Li, T. Construction Method of Embedded FPGA Convolutional Neural Network for Edge Computing. J. Comput. Res. Dev. 2018, 55, 551–562. [Google Scholar]
- Wu, D.; Zhang, Y.; Jia, X.; Tian, L.; Li, T.; Sui, L.; Xie, D.; Shan, Y. A high-performance CNN processor based on FPGA for MobileNets. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 136–143. [Google Scholar]
- Bai, L.; Zhao, Y.; Huang, X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.J. A high-throughput and power-efficient FPGA implementation of YOLO CNN for object detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Liu, B.; Zou, D.; Feng, L.; Feng, S.; Fu, P.; Li, J. An FPGA-based CNN accelerator integrating depthwise separable convolution. Electronics 2019, 8, 281. [Google Scholar] [CrossRef]
- Geng, T.; Wang, T.; Sanaullah, A.; Yang, C.; Xu, R.; Patel, R.; Herbordt, M. FPDeep: Acceleration and load balancing of CNN training on FPGA clusters. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 81–84. [Google Scholar]
- Lentaris, G.; Stratakos, I.; Stamoulias, I.; Soudris, D.; Lourakis, M.; Zabulis, X. High-performance vision-based navigation on SoC FPGA for spacecraft proximity operations. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1188–1202. [Google Scholar] [CrossRef]
- Ma, Z.; Ding, Y.; Wen, S.; Xie, J.; Jin, Y.; Si, Z.; Wang, H. Shoe-print image retrieval with multi-part weighted cnn. IEEE Access 2019, 7, 59728–59736. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BRAM_18K | DSP48E | FF | LUT | |
|---|---|---|---|---|
| Total | 419 | 134 | 20,962 | 36,190 |
| Utilization (%) | 96 | 37 | 14 | 51 |
| Index | BRAM_18K | DSP48E | FF | LUT |
|---|---|---|---|---|
| Total | 27 | 103 | 17,443 | 28,787 |
| Utilization (%) | 2 | 28 | 12 | 40 |
| Network | Index | BRAMs | DSP | FF | LUT | LUTRAM |
|---|---|---|---|---|---|---|
| LeNet-3.3 | Utilization Estimates | 211.5 | 127 | 20,438 | 26,199 | 5827 |
| Utilization (%) | 97.92 | 35.28 | 14.48 | 37.13 | 20.23 | |
| LeNet-2.22 | Utilization Estimates | 13.5 | 97 | 17,557 | 17,472 | 949 |
| Utilization (%) | 6.25 | 26.94 | 12.44 | 24.76 | 3.30 |
| Equipment | CPU | GPU | MPSoC | |
|---|---|---|---|---|
| Overview Information | Type and specification | Intel i5-4300U | GTX1050 | ZYNQ UltraScale + MPSoC (PL) |
| Selling price | X | 929 ¥ | 2600 ¥ | |
| Working frequency | 2.5 GHz | 1455 MHz | 100 MHz | |
| LeNet-3.3 | Average power consumption | 44 W | 75 W | 3.22 W |
| Training time/image | 55.68 ms | 24.60 ms | 19.2 ms | |
| Inference time/image | 10.14 ms | 4.08 ms | 3.31 ms | |
| LeNet-2.22 | Average power consumption | 44 W | 75 W | 3.02 W |
| Training time/image | 1.84 ms | 1.32 ms | 1.03 ms | |
| Inference time/image | 2.01 ms | 0.78 ms | 0.65 ms | |
| Type and Specification | Epoch | Lose | Learning Rate |
|---|---|---|---|
| Intel i5-4300U | 5 | 0.378564 | 0.0038268049 |
| 10 | 0.011166 | 0.0000095806 | |
| 15 | 0.011789 | 0.0000105072 | |
| 20 | 0.001402 | 0.0000002816 | |
| GTX1050 | 5 | 0.444973 | 0.0050369459 |
| 10 | 0.039344 | 0.0000815240 | |
| 15 | 0.027722 | 0.0000449574 | |
| 20 | 0.008204 | 0.0000056733 | |
| ZYNQ UltraScale + MPSoC (PL) | 5 | 0.622568 | 0.0089149121 |
| 10 | 0.112957 | 0.0004897260 | |
| 15 | 0.015632 | 0.0000169758 | |
| 20 | 0.002037 | 0.0000005311 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; He, B.; Zheng, Y. Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks. Appl. Sci. 2023, 13, 1003. https://doi.org/10.3390/app13021003
Li T, He B, Zheng Y. Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks. Applied Sciences. 2023; 13(2):1003. https://doi.org/10.3390/app13021003
Chicago/Turabian StyleLi, Tianling, Bin He, and Yangyang Zheng. 2023. "Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks" Applied Sciences 13, no. 2: 1003. https://doi.org/10.3390/app13021003
APA StyleLi, T., He, B., & Zheng, Y. (2023). Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks. Applied Sciences, 13(2), 1003. https://doi.org/10.3390/app13021003