


Multi-Task Learning for Building Extraction and Change Detection from Remote Sensing Images


Abstract
:1. Introduction
- We propose an MTL framework based on an advanced transformer-based backbone and lightweight BE and CD heads.
- We provide benchmark results to validate design details, including backbone choice and pre-training strategies of our proposed solutions using open datasets.
- We achieved a score of 81.8214 in the “BE and CD in optical images” subject of the 2021 Gaofen challenge, which is a few tenths of points behind the first place.
2. Materials and Methods
2.1. Backbones for Representation Learning
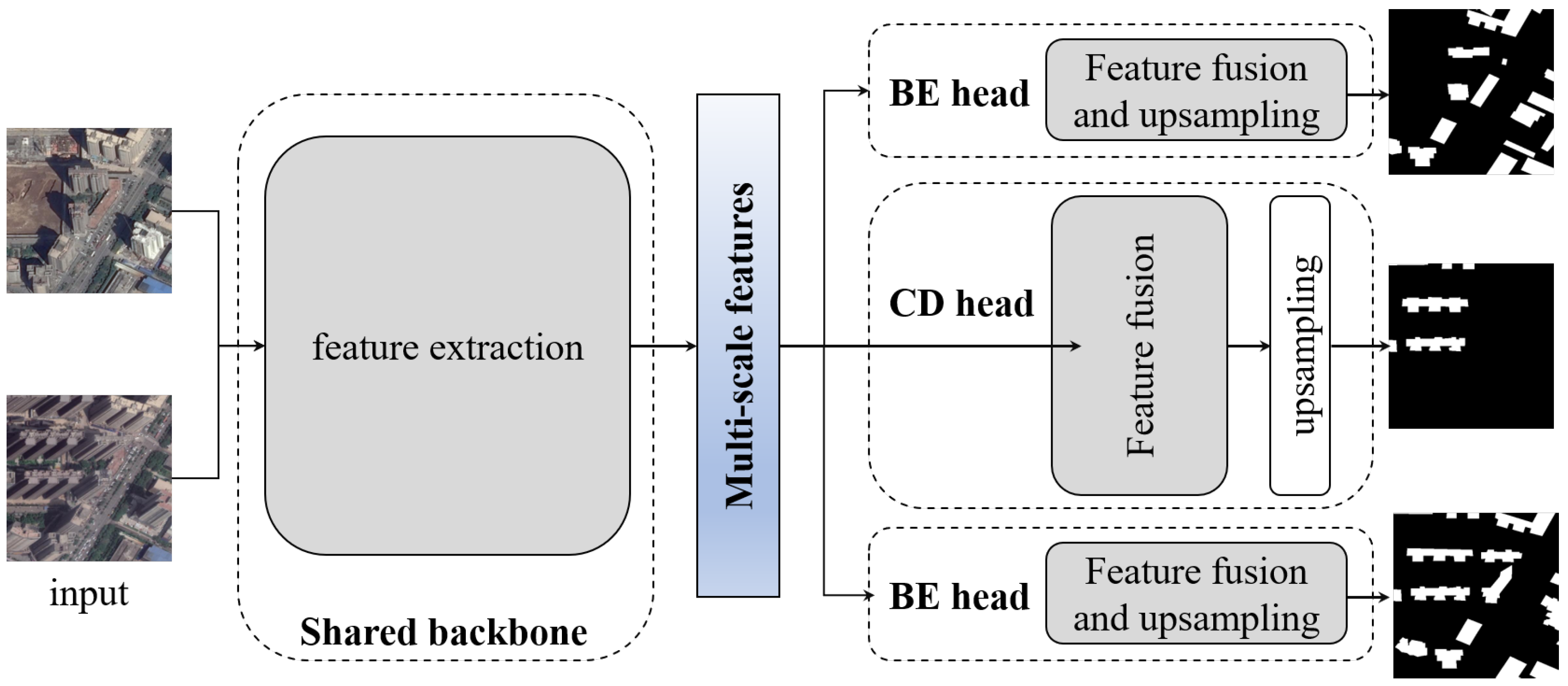
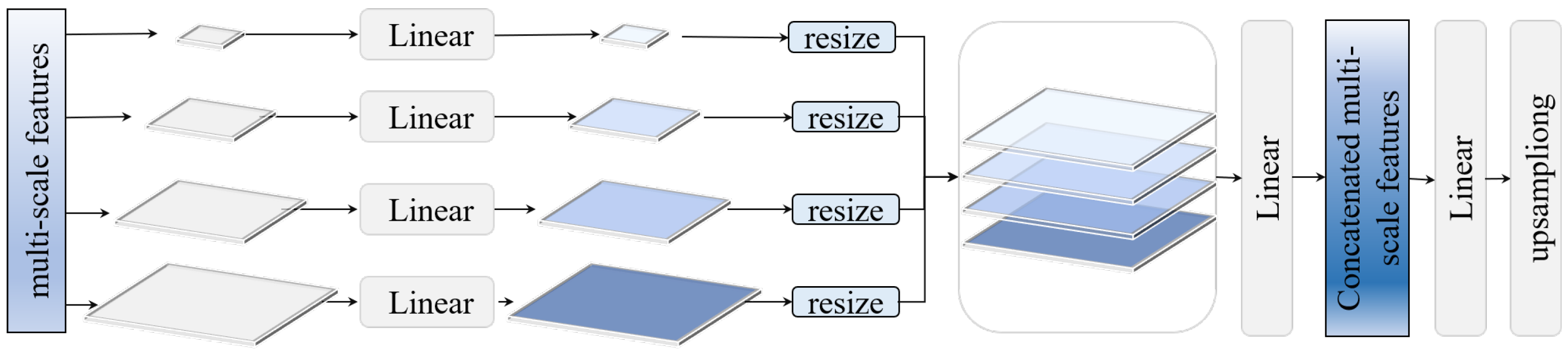
2.2. Network Heads for Building Extraction and Change Detection
3. Experimental Setup
3.1. Datasets
3.2. Implementation Details
3.3. Baseline Methods and Metrics
- UNet for BE. A standard ResNeXt101-based UNet, which is a typical network for semantic segmentation tasks, is used as a BE baseline method [12].
- Foreground-Aware Relation Network (FarSeg) for BE. The encoder of FarSeg consists of a ResNet-based backbone to produce pyramidal feature maps with a strategy similar to that of the feature pyramid network (FPN) and a foreground-scene relation module to improve the embedings with associating geospatial scene-relevant context. The decoder recovers the spatial size of the relation-enhanced multi-scale feature maps. The foreground-scene relation sub-network refines each level of the pyramidal feature maps using a relation map, a similarity matrix calculated with the scene embedding and the foreground representation. The geospatial scene embedding, a 1-D feature vector, was produced by an additional branch in the backbone via global context aggregation, and the foreground represents the multi-scale features.
- Siam-UNet and Siam-UNet++ for CD. Siamese-UNet is mainly composed by two main parts: the siamese network for feature extraction from multi-temporal inputs and the decoder for analyzing embedding differences [25]. In the feature extraction step, images of two different periods are processed by the two branches within the siamese network with shared weights. Siam-UNet ++ uses UNet++ as the backbone network, with the advantages of capturing fine-grained details by exploiting multiple nested and dense skip connections to obtain multi-scale features and reduce the pseudo-changes induced by scale variances [22].
- ChangeStar for single task CD and MTL of BE&CD. ChangeStar [40] consists of a dense prediction model for feature extraction and a ChangeMixin module to detect object change. The ChangeMixin module consists of a temporal swap module (TSM) and a shallow FCN involving combinations of Convolution-BatchNorm-ReLU. The TSM module takes bi-temporal feature maps from the backbone (FarSeg) as input, which are then concatenated in the channel axis in two different temporal orders; the two respective outputs from TSM are subsequently used as inputs to two FCNs with shared weights. Notably, the ChangeStar can be constructed for simultaneous BE and CD if a regression module is introduced for BE probability estimation using the extracted semantic features. Here, we use the FarSeg as the semantic segmentation model, which helps achieve the best CD result in [40].
4. Experimental Results
4.1. Ablation Studies for Optimal Multi-Task Learning Setups
4.1.1. Building Extraction via Single Task Learning
4.1.2. Change Detection via Single Task Learning
4.2. Quantitative Assessment of Multi-Task Learning
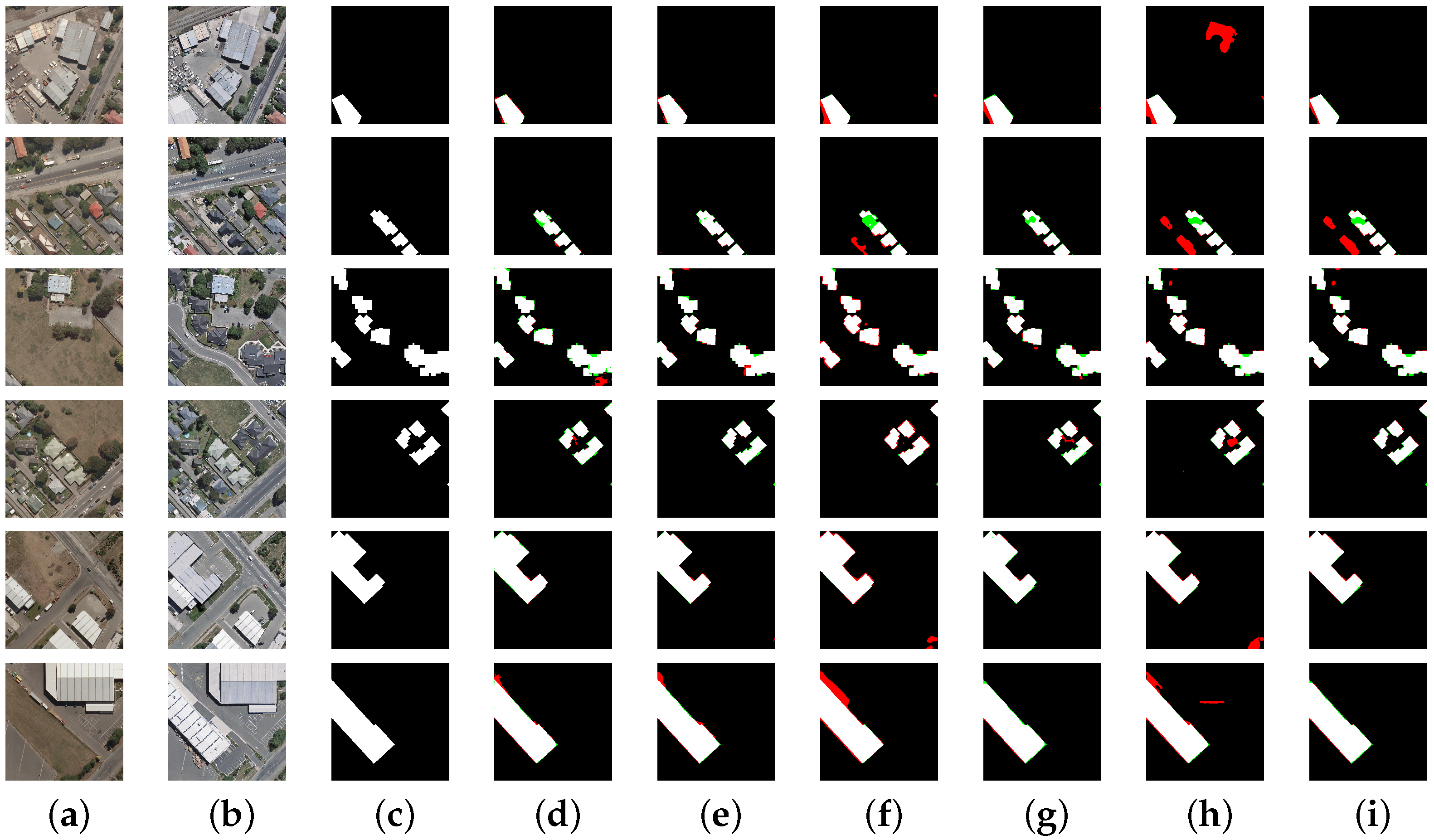
4.3. Qualitative Assessment
4.4. Experimental Results: Fourth Place in the 2021 Gaofen Challenge
5. Discussion
5.1. Benefits of Multi-Task Learning
5.2. Effectiveness of Pre-Trained Weights for CD
5.3. Transfer Performance to a Unseen CD Dataset
5.4. Comments and Further Improvements
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SOTA | state-of-the-art |
| BE | building extraction |
| CD | change detection |
| RS | remote sensing |
| MTL | multi-task learning |
| WHU-CD | the Wuhan University building (WHU) change detection dataset |
| DL | deep learning |
| CNN | the convolutional neural network |
| FCN | the fully convolutional network |
| SCD | semantic change detection |
| RNN | the recurrent neural network |
| GAN | the generative adversarial network |
| VHR | very high-resolution |
| MLP | multilayer perceptron |
| Swin_L | the large version of Swin |
| GT | ground truth |
| TSM | temporal swap module |
| FarSeg | Foreground-Aware Relation Network |
| FPN | feature pyramid network |
References
- You, Y.; Cao, J.; Zhou, W.Y. A survey of change detection methods based on remote sensing images for multi-source and multi-objective scenarios. Remote Sens. 2020, 12, 2460. [Google Scholar] [CrossRef]
- Thorsten, H.; Claudia, K. Object detection and image segmentation with deep learning on earth observation data: A review-part I: Evolution and recent trends. Remote Sens. 2020, 10, 1667. [Google Scholar]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change Detection From Very-High-Spatial-Resolution Optical Remote Sensing Images: Methods, applications, and future directions. IEEE Geosci. Remote Sens. Mag. 2021, 4, 68–101. [Google Scholar] [CrossRef]
- Huiwei, J.; Min, P.; Yuanjun, Z.; Haofeng, X.; Zemin, H.; Jingming, L.; Xiaoli, M.; Xiangyun, H. A Survey on Deep Learning-Based Change Detection from High-Resolution Remote Sensing Images. Remote Sens. 2022, 7, 1552. [Google Scholar]
- Xia, C.; Pan, Z.; Li, Y.; Chen, J.; Li, H. Vision-based melt pool monitoring for wire-arc additive manufacturing using deep learning method. Int. J. Adv. Manuf. Technol. 2022, 120, 551–562. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef]
- Sicong, L.; Yongjie, Z.; Qian, D.; Lorenzo, B.; Alim, S.; Xiaohua, T.; Yanmin, J.; Chao, W. A Shallow-to-Deep Feature Fusion Network for VHR Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410213. [Google Scholar]
- Yongjie, Z.; Sicong, L.; Qian, D.; Hui, Z.; Xiaohua, T.; Michele, D. A Novel Multitemporal Deep Fusion Network (MDFN) for Short-Term Multitemporal HR Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10691–10704. [Google Scholar]
- Sicong, L.; Yongjie, Z.; Qian, D.; Alim, S.; Xiaohua, T.; Michele, D. A Novel Feature Fusion Approach for VHR Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 464–473. [Google Scholar]
- Nicolas, A.; Bertrand, L.S.; Sébastien, L. Joint Learning from Earth Observation and OpenStreetMap Data to Get Faster Better Semantic Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1552–1560. [Google Scholar]
- Shiqing, W.; Shunping, J. Graph Convolutional Networks for the Automated Production of Building Vector Maps From Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar]
- Olaf, R.; Philipp, F.; Thomas, B. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ze, L.; Yutong, L.; Yue, C.; Han, H.; Yixuan, W.; Zheng, Z.; Stephen, L.; Baining, G. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–18 October 2021; pp. 10012–10022. [Google Scholar]
- Xin, C.; Chunping, Q.; Wenyue, G.; Anzhu, Y.; Xiaochong, T.; Michael, S. Multiscale feature learning by transformer for building extraction from satellite images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Chunping, Q.; He, L.; Wenyue, G.; Xin, C.; Anzhu, Y.; Xiaochong, T.; Michael, S. Transferring transformer-based models for cross-area building extraction from remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4104–4116. [Google Scholar]
- Weijia, L.; Conghui, H.; Jiarui, F.; Juepeng, Z.; Haohuan, F.; Le, Y. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source GIS data. Remote Sens. 2019, 11, 403. [Google Scholar]
- Zhuo, Z.; Yanfei, Z.; Junjue, W.; Ailong, M. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4095–4104. [Google Scholar]
- Jian, K.; Zhirui, W.; Ruoxin, Z.; Xian, S.; Ruben, F.; Antonio, P. PiCoCo: Pixelwise Contrast and Consistency Learning for Semisupervised Building Footprint Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10548–10559. [Google Scholar]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework With Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6106–6120. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images. Remote Sens. 2021, 12, 2161. [Google Scholar] [CrossRef]
- Guo, H.; Du, B.; Zhang, L.; Su, X. A coarse-to-fine boundary refinement network for building footprint extraction from remote sensing imagery. Isprs J. Photogramm. Remote Sens. 2022, 183, 40–252. [Google Scholar] [CrossRef]
- Daifeng, P.; Yongjun, Z.; Haiyan, G. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar]
- Lichao, M.; Lorenzo, B.; Xiao, Z.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar]
- Hongruixuan, C.; Chen, W.; Bo, D.; Liangpei, Z.; Le, W. Change Detection in Multisource VHR Images via Deep Siamese Convolutional Multiple-Layers Recurrent Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1–17. [Google Scholar]
- Rodrigo, D.C.; Bertrand, S.L.; Alexandre, B. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25TH IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Huiwei, J.; Xiangyun, H.; Kun, L.; Jinming, Z.; Jinqi, G.; Mi, Z. PGA-SiamNet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar]
- Daifeng, P.; Lorenzo, B.; Yongjun, Z.; Haiyan, G.; Pengfei, H. Scdnet: A Novel Convolutional Network For Semantic Change Detection In High Resolution Optical Remote Sensing Imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102465. [Google Scholar]
- Xin, Y.; Lei, H.; Yongmei, Z.; Yunqing, L. MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 4528. [Google Scholar]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual Task Constrained Deep Siamese Convolutional Network Model. IEEE Geosci. Remote Sens. Lett. 2021, 18, 811–815. [Google Scholar] [CrossRef]
- Lebedev, A.M.; Vizilter, Y.; Vygolov, V.O.; Knyaz, A.V.; Rubis, Y.A. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. ISPRS- Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef] [Green Version]
- Sudipan, S.; Francesca, B.; Lorenzo, B. Building Change Detection in VHR SAR Images via Unsupervised Deep Transcoding. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1917–1929. [Google Scholar]
- Jian, K.; Zhirui, W.; Ruoxin, Z.; Junshi, X.; Xian, S.; Ruben, F.; Antonio, P. DisOptNet: Distilling Semantic Knowledge from Optical Images for Weather-independent Building Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar]
- Chenxiao, Z.; Peng, Y.; Deodato, T.; Liangcun, J.; Boyi, S.; Li, H.; Guangchao, L. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. Isprs J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar]
- Tongfei, L.; Maoguo, G.; Di, L.; Qingfu, Z.; Hanhong, Z.; Fenlong, J.; Mingyang, Z. Building Change Detection for VHR Remote Sensing Images via Local-Global Pyramid Network and Cross-Task Transfer Learning Strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar]
- Hao, C.; Zhenwei, S. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar]
- Mengxi, L.; Qian, S.; Andrea, M.; Da, H.; Xiaoping, L.; Liangpei, Z. Super-Resolution-Based Change Detection Network With Stacked Attention Module for Images With Different Resolutions. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar]
- Jiahao, C.; Junfu, F.; Mengzhen, Z.; Yuke, Z.; Chen, S. MSF-Net: A Multiscale Supervised Fusion Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE Access 2022, 10, 30925–30938. [Google Scholar]
- Song, A.; Choi, J. Fully Convolutional Networks with Multiscale 3D Filters and Transfer Learning for Change Detection in High Spatial Resolution Satellite Images. Remote Sens. 2020, 12, 799. [Google Scholar] [CrossRef]
- Liu, J.; Chen, K.; Xu, G.; Sun, X.; Yan, M.; Diao, W.; Han, H. Convolutional Neural Network-Based Transfer Learning for Optical Aerial Images Change Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 127–131. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, A.; Zhang, L.; Zhong, Y. Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15173–15182. [Google Scholar]
- Wang, N.; Li, W.; Tao, R.; Du, Q. Graph-based block-level urban change detection using Sentinel-2 time series. Remote Sens. Environ. 2022, 274, 112993. [Google Scholar] [CrossRef]
- Yuanxin, Y.; Liang, Z.; Bai, Z.; Chao, Y.; Miaomiao, S.; Jianwei, F.; Zhitao, F. Feature Decomposition-Optimization-Reorganization Network for Building Change Detection in Remote Sensing Images. Remote Sens. 2022, 14, 722. [Google Scholar]
- Bai, B.; Fu, W.; Lu, T.; Li, S. Edge-Guided Recurrent Convolutional Neural Network for Multitemporal Remote Sensing Image Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Guo, H.; Shi, Q.; Marinoni, A.; Du, B.; Zhang, L. Deep building footprint update network: A semi-supervised method for updating existing building footprint from bi-temporal remote sensing images. Remote Sens. Environ. 2021, 264, 112589. [Google Scholar] [CrossRef]
- Ying, S.; Xinchang, Z.; Jianfeng, H.; Haiying, W.; Qinchuan, X. Fine-Grained Building Change Detection From Very High-Spatial-Resolution Remote Sensing Images Based on Deep Multitask Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Enze, X.; Wenhai, W.; Zhiding, Y.; Anima, A.; Jose, A.M.; Ping, L. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Annu. Conf. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Alex, K.; Yarin, G.; Roberto, C. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Shunping, J.; Shiqing, W.; Meng, L. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Pang, S.; Zhang, A.; Hao, J.; Liu, F.; Chen, J. SCA-CDNet: A robust siamese correlation-and-attention-based change detection network for bitemporal VHR images. Int. J. Remote Sens. 2021, 43, 1–22. [Google Scholar] [CrossRef]
- Junkang, X.; Hao, X.; Hui, Y.; Biao, W.; Penghai, W.; Jaewan, C.; Lixiao, C.; Yanlan, W. Multi-Feature Enhanced Building Change Detection Based on Semantic Information Guidance. Remote Sens. 2021, 13, 41–71. [Google Scholar]
- Xueli, P.; Ruofei, Z.; Zhen, L.; Qingyang, L. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7296–7307. [Google Scholar]
- Kaiming, H.; Haoqi, F.; Yuxin, W.; Saining, X.; Ross, G. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on CVPR, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Input Size | Output Size (Equivalent Size) | |
|---|---|---|---|
| Patch partition | 512 × 512 × 3 | 128 × 128 × 3 | |
| Linear embedding | 16,384 × 192 (128 × 128 × 192) | ||
| stage 1 | Swin transformer block ×2 | 16,384 × 192 | 16,384 × 192 (128 × 128 × 192) |
| stage 2 | Patch merging | 4096 × 384 | |
| Swin transformer block ×2 | 4096 × 384 | 4096 × 384 (64 × 64 × 384) | |
| stage 3 | Patch merging | 4096 × 384 | 1024 × 768 |
| Swin transformer block ×18 | 1024 × 768 | 1024 × 768 (32 × 32 × 768) | |
| stage 4 | Patch merging | 1024 × 768 | 256 × 1536 |
| Swin transformer block ×2 | 256 × 1536 | 256 × 1536 (16 × 16 × 1536) |
| Network | IoU | Precision | Recall | F1 |
|---|---|---|---|---|
| UNet | 89.89 | 96.42 | 93.00 | 94.68 |
| FarSeg | 90.52 | 97.02 | 93.12 | 95.03 |
| Ours | 91.65 | 97.19 | 94.15 | 95.65 |
| Model | Pretrain | IoU | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Siam-UNet | ImageNet | 59.77 | 78.80 | 71.23 | 74.82 |
| Siam-UNet++ | ImageNet | 62.07 | 71.67 | 82.25 | 76.59 |
| ChangeStar | ImageNet | 62.20 | 73.59 | 80.08 | 76.70 |
| Ours | ImageNet | 64.15 | 84.89 | 72.10 | 78.16 |
| ChangeStar | WHU-CD | 70.46 | 78.84 | 86.88 | 82.67 |
| Ours | WHU-CD | 72.44 | 86.74 | 81.47 | 84.02 |
| Model | IoU | Precision | Recall | F1 | |
|---|---|---|---|---|---|
| ChangeStar | BE | 90.00 | 97.14 | 92.44 | 94.73 |
| CD | 78.33 | 89.03 | 86.70 | 87.85 | |
| Ours | BE | 91.38 | 97.21 | 93.85 | 95.50 |
| CD | 81.86 | 91.27 | 88.81 | 90.02 | |
| Model | IoU | Precision | Recall | F1 |
|---|---|---|---|---|
| ChangeStar | 56.16 | 69.11 | 74.98 | 71.92 |
| Ours | 58.65 | 63.49 | 88.50 | 73.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, D.; Qiu, C.; Yu, A.; Quan, Y.; Liu, B.; Chen, X. Multi-Task Learning for Building Extraction and Change Detection from Remote Sensing Images. Appl. Sci. 2023, 13, 1037. https://doi.org/10.3390/app13021037
Hong D, Qiu C, Yu A, Quan Y, Liu B, Chen X. Multi-Task Learning for Building Extraction and Change Detection from Remote Sensing Images. Applied Sciences. 2023; 13(2):1037. https://doi.org/10.3390/app13021037
Chicago/Turabian StyleHong, Danyang, Chunping Qiu, Anzhu Yu, Yujun Quan, Bing Liu, and Xin Chen. 2023. "Multi-Task Learning for Building Extraction and Change Detection from Remote Sensing Images" Applied Sciences 13, no. 2: 1037. https://doi.org/10.3390/app13021037
APA StyleHong, D., Qiu, C., Yu, A., Quan, Y., Liu, B., & Chen, X. (2023). Multi-Task Learning for Building Extraction and Change Detection from Remote Sensing Images. Applied Sciences, 13(2), 1037. https://doi.org/10.3390/app13021037