



TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning

Abstract
:1. Introduction
- We point out the limitation of using simple compression methods to obtain the fixed-length tag-based vector that represents multi-aspect user preferences or item features. To this end, we develop a new tag-aware recommendation algorithm which introduces the attention network to adaptively learn the importance of different features.
- We combine a generalized linear model and a deep neural network so as to take advantages of both low-level and high-level feature interactions.
- We perform extensive experiments on two real-world datasets, demonstrating the rationality and effectiveness of the proposed TRAL.
2. Related Work
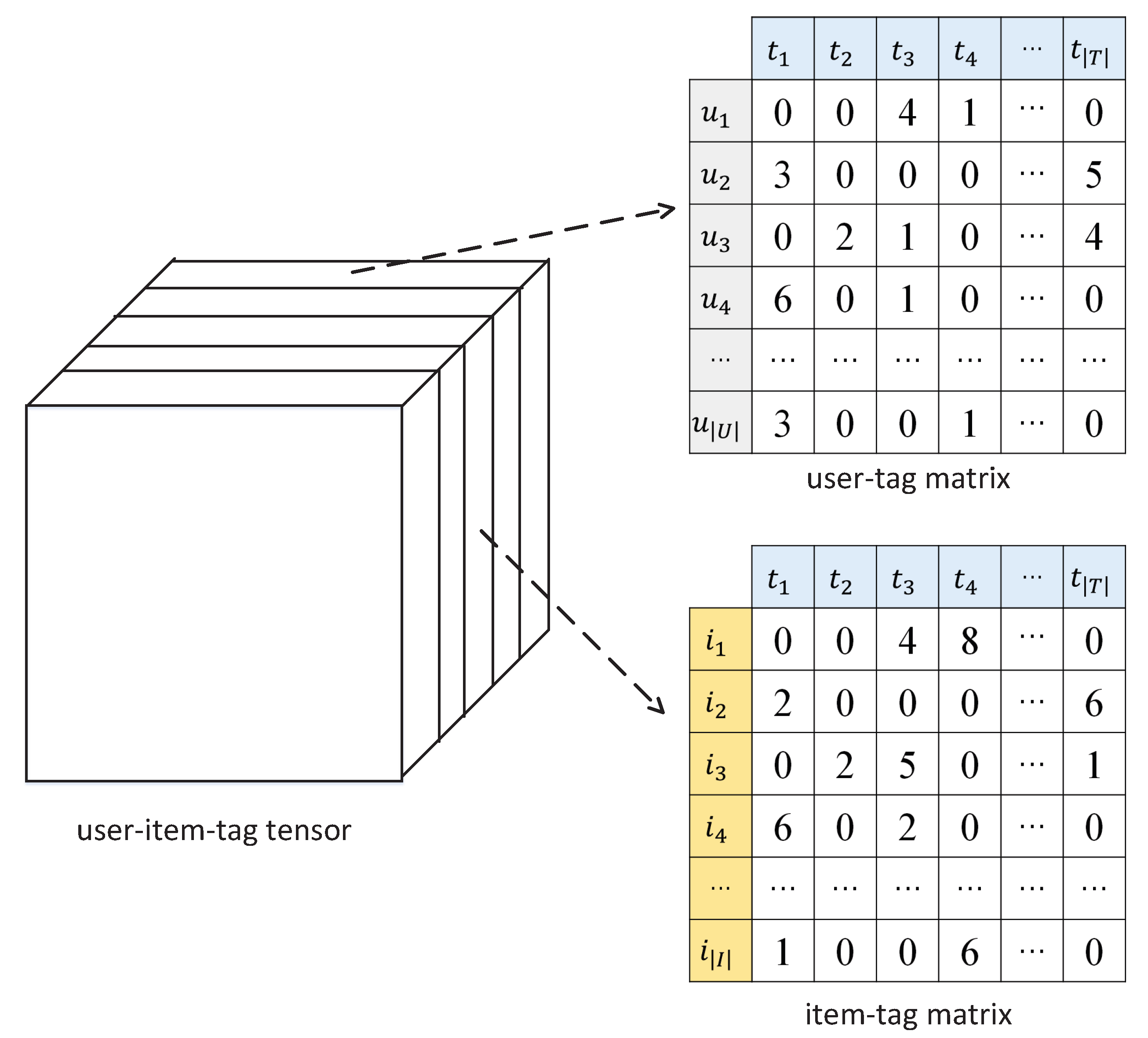
3. Preliminaries
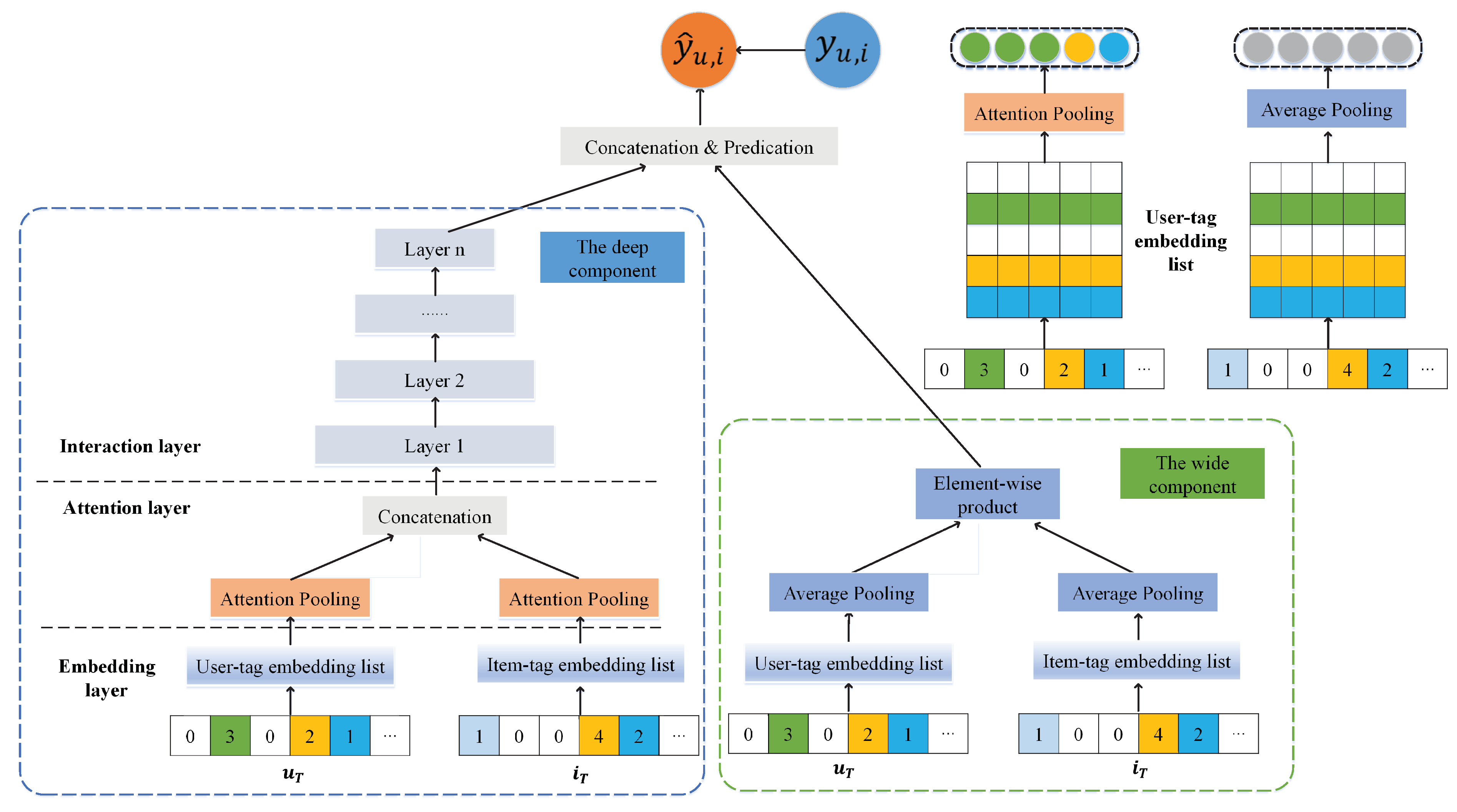
4. Method
4.1. The Deep Component
4.1.1. Embedding Layer
4.1.2. Attention Layer
4.1.3. Interaction Layer
4.2. The Wide Component
4.3. Joint Optimization
5. Experiments
5.1. Dataset Description and Evaluation Metrics
- Delicious is a dataset obtained from the Delicious social bookmarking system, which allows users to annotate web bookmarks with various tags. In this dataset, bookmarks are regarded as items to be recommended.
- LastFM is a dataset collected from Last.fm online music system, where users are encouraged to tag music artists they have listened. In this dataset, artists are treated as items to be recommended.
5.2. Baselines and Parameter Settings
- CCF: CCF uses hierarchical clustering to obtain different tag clusters, each of which can be viewed as the representation of a certain topic area [3]. Cluster-based feature vectors for users and items are generated and the relevance relation between them can be estimated.
- ACF: ACF introduces the deep autoencoders to derive tag-based user latent features, on which user-based CF is performed to provide recommendations [5].
- NCF: It is a general framework to employ neural network architectures for CF [11]. By replacing the inner product with a MLP, NCF can learn non-linear interactions between users and items.
- DSPR: DSPR adopts MLPs with shared parameters to extract latent features for users and items based on tagging information [24]. Deep-semantic similarities between target users and their relative items can be computed to generate the ranked recommendation list.
- TRSDL: It is a tag-aware recommendation method, which introduces pre-trained word embeddings to represent tag information and learns latent features of users and items via deep structures [10].
- BPR-T: It is a ranking-based collaborative filtering model which incorporates the tag mapping scheme and the Bayesian ranking optimization [20].
- STEM: STEM establishes a new social tag expansion model to tackle the problem of tag sparsity, thereby improving the recommendation accuracy [22].
5.3. Performance Comparison
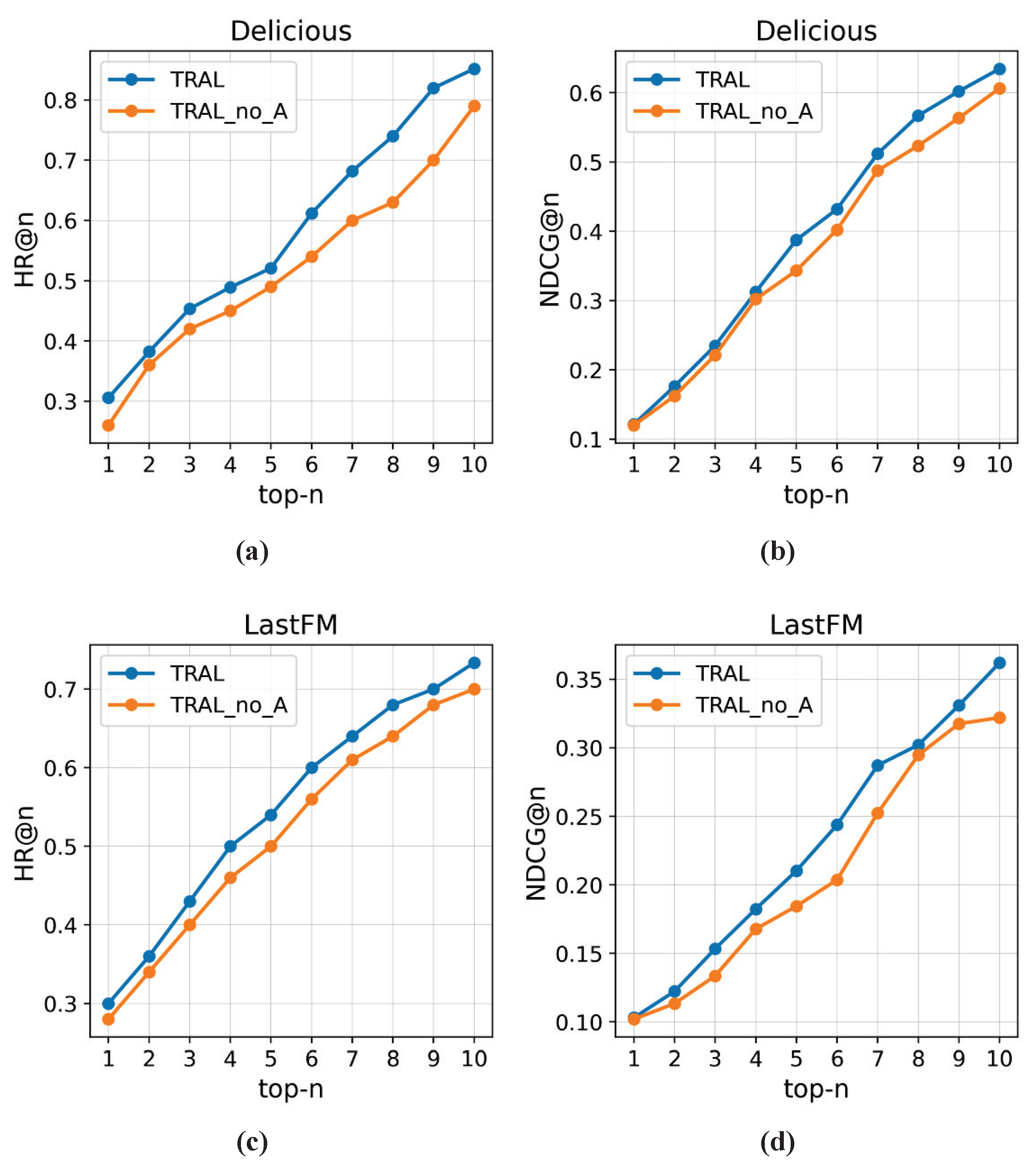
5.4. Ablation Studies
5.4.1. Effect of the Attention Network
5.4.2. Effect of Combining the Two Components
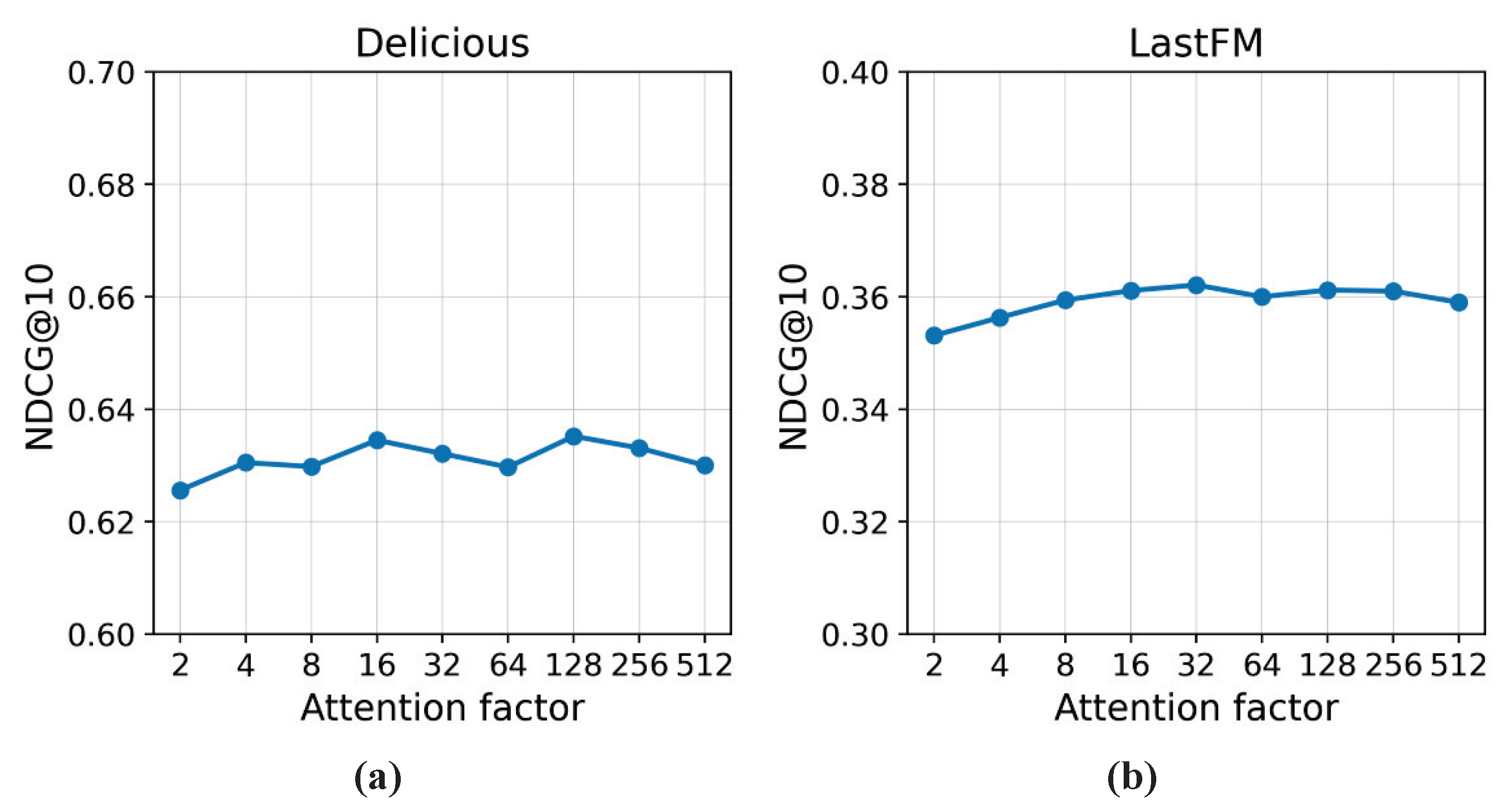
5.5. Parameter Analysis
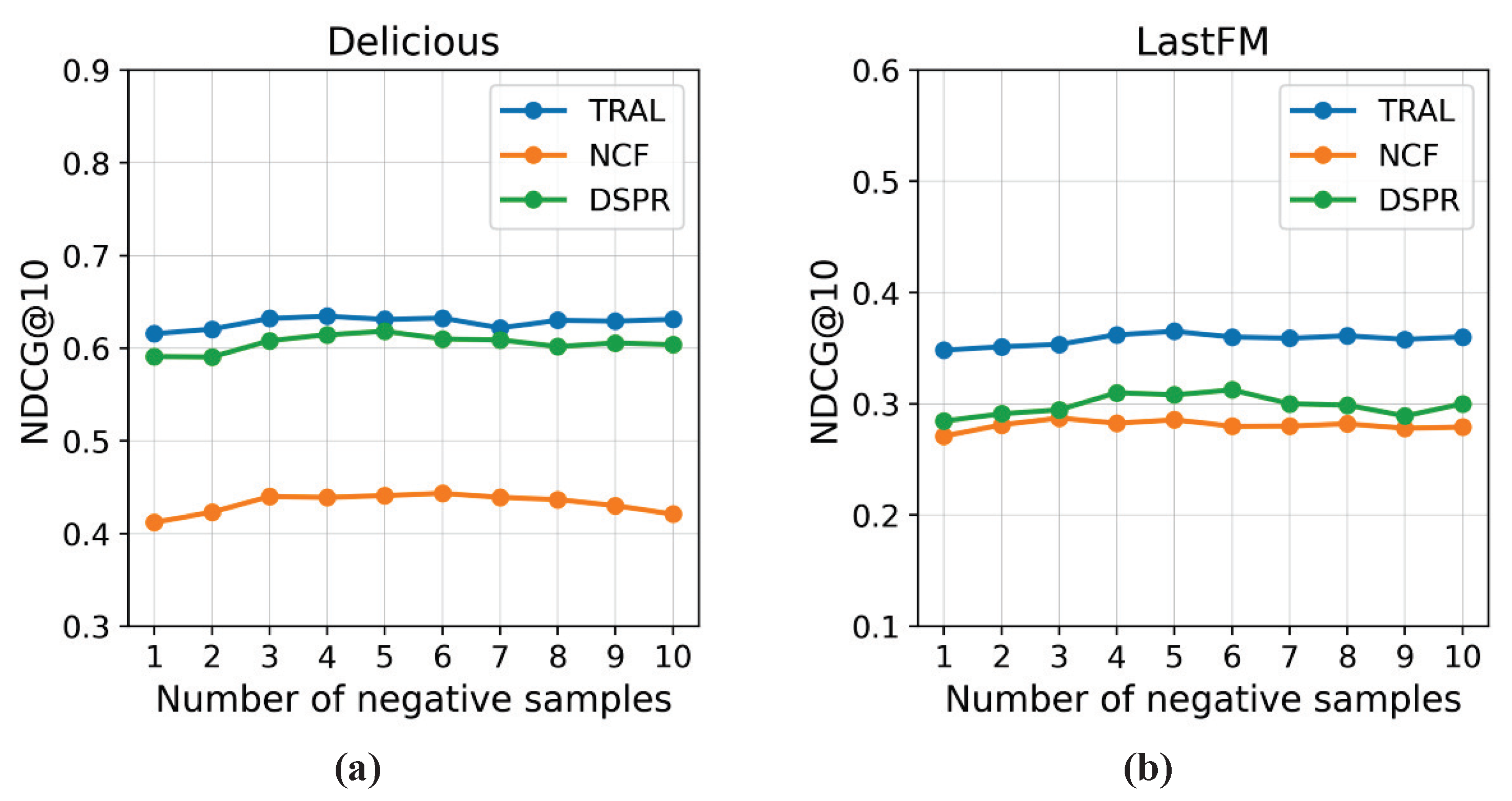
5.5.1. Number of Negative Samples
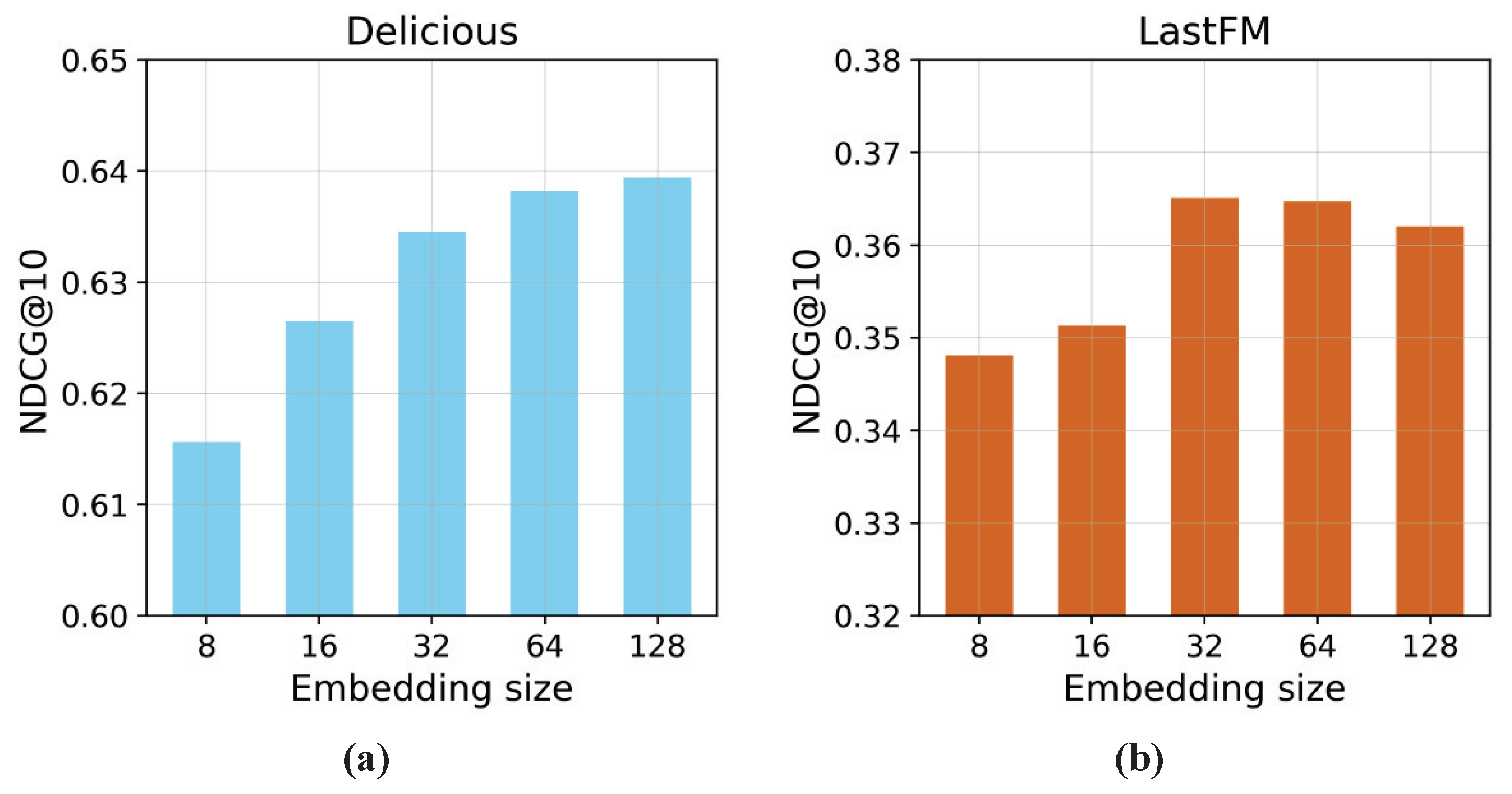
5.5.2. Embedding Size
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Zhang, Z.K.; Zhou, T.; Zhang, Y.C. Tag-aware recommender systems: A state-of-the-art survey. J. Comput. Sci. Technol. 2011, 26, 767–777. [Google Scholar] [CrossRef] [Green Version]
- Shepitsen, A.; Gemmell, J.; Mobasher, B.; Burke, R. Personalized recommendation in social tagging systems using hierarchical clustering. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 259–266. [Google Scholar]
- Tso-Sutter, K.H.; Marinho, L.B.; Schmidt-Thieme, L. Tag-aware recommender systems by fusion of collaborative filtering algorithms. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 1995–1999. [Google Scholar]
- Zuo, Y.; Zeng, J.; Gong, M.; Jiao, L. Tag-aware recommender systems based on deep neural networks. Neurocomputing 2016, 204, 51–60. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Zhao, S.; Du, N.; Nauerz, A.; Zhang, X.; Yuan, Q.; Fu, R. Improved recommendation based on collaborative tagging behaviors. In Proceedings of the 13th International Conference on Intelligent User Interfaces, Gran Canaria, Spain, 13–16 January 2008; pp. 413–416. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar]
- Xu, Z.; Lukasiewicz, T.; Chen, C.; Miao, Y.; Meng, X. Tag-aware personalized recommendation using a hybrid deep model. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Liang, N.; Zheng, H.T.; Chen, J.Y.; Sangaiah, A.K.; Zhao, C.Z. Trsdl: Tag-aware recommender system based on deep learning–intelligent computing systems. Appl. Sci. 2018, 8, 799. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Nakamoto, R.; Nakajima, S.; Miyazaki, J.; Uemura, S. Tag-based contextual collaborative filtering. IAENG Int. J. Comput. Sci. 2007, 34, 2. [Google Scholar]
- Marinho, L.B.; Schmidt-Thieme, L. Collaborative tag recommendations. In Data Analysis, Machine Learning and Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 533–540. [Google Scholar]
- Zhen, Y.; Li, W.J.; Yeung, D.Y. TagiCoFi: Tag informed collaborative filtering. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 69–76. [Google Scholar]
- Chen, C.; Zheng, X.; Wang, Y.; Hong, F.; Chen, D. Capturing semantic correlation for item recommendation in tagging systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, Arizona, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Deng, Z. Tag recommendation based on bayesian principle. In Proceedings of the International Conference on Advanced Data Mining and Applications, Chongqing, China, 19–21 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 191–201. [Google Scholar]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. Tag recommendations based on tensor dimensionality reduction. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 43–50. [Google Scholar]
- Li, H.; Diao, X.; Cao, J.; Zhang, L.; Feng, Q. Tag-aware recommendation based on Bayesian personalized ranking and feature mapping. Intell. Data Anal. 2019, 23, 641–659. [Google Scholar] [CrossRef]
- Zhang, Z.K.; Zhou, T.; Zhang, Y.C. Personalized recommendation via integrated diffusion on user–item–tag tripartite graphs. Phys. A Stat. Mech. Its Appl. 2010, 389, 179–186. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.; Huo, Y.; Tang, J.; Zeng, Y.; Chen, B. Exploiting relational tag expansion for dynamic user profile in a tag-aware ranking recommender system. Inf. Sci. 2021, 545, 448–464. [Google Scholar] [CrossRef]
- Pan, X.; Zeng, X.; Ding, L. Topic optimization–incorporated collaborative recommendation for social tagging. Data Technol. Appl. 2022, 1–20. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, C.; Lukasiewicz, T.; Miao, Y.; Meng, X. Tag-aware personalized recommendation using a deep-semantic similarity model with negative sampling. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1921–1924. [Google Scholar]
- Huang, R.; Wang, N.; Han, C.; Yu, F.; Cui, L. TNAM: A tag-aware neural attention model for Top-N recommendation. Neurocomputing 2020, 385, 1–12. [Google Scholar] [CrossRef]
- Chen, B.; Ding, Y.; Xin, X.; Li, Y.; Wang, Y.; Wang, D. AIRec: Attentive intersection model for tag-aware recommendation. Neurocomputing 2021, 421, 105–114. [Google Scholar] [CrossRef]
- Ahmadian, S.; Ahmadian, M.; Jalili, M. A deep learning based trust-and tag-aware recommender system. Neurocomputing 2022, 488, 557–571. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar] [CrossRef]
- Liu, H. Resource recommendation via user tagging behavior analysis. Clust. Comput. 2019, 22, 885–894. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar]
- Cantador, I.; Brusilovsky, P.; Kuflik, T. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 387–388. [Google Scholar]
- Bayer, I.; He, X.; Kanagal, B.; Rendle, S. A generic coordinate descent framework for learning from implicit feedback. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1341–1350. [Google Scholar]
- Elkahky, A.M.; Song, Y.; He, X. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 278–288. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation systems: Algorithms, challenges, metrics, and business opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Han, X.; Jiang, Z.; Liu, N.; Hu, X. G-Mixup: Graph Data Augmentation for Graph Classification. arXiv 2022, arXiv:2202.07179. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Users | #Items | #Tags | #Assignments |
|---|---|---|---|---|
| Delicious | 1843 | 65,877 | 3508 | 339,744 |
| LastFM | 1808 | 12,212 | 2305 | 175,641 |
| MLP and Attention Learning | embedding size of tags | 32 |
| embedding size of tag frequency | 8 | |
| size of hidden layers | [80, 40, 20] | |
| attention factor | 16 | |
| Training Process | optimizer | Adam |
| learning rate | 0.001 | |
| maximum number of iterations | 300 | |
| batch size | 256 | |
| regularization | norm | |
| number of negative samples | 4 |
| Dataset | Delicious | LastFM | ||||||
|---|---|---|---|---|---|---|---|---|
| Metrics | HR@10 | NDCG@10 | HR@20 | NDCG@20 | HR@10 | NDCG@10 | HR@20 | NDCG@20 |
| CCF | 0.6103 | 0.3851 | 0.6346 | 0.4123 | 0.5420 | 0.2548 | 0.5618 | 0.2652 |
| ACF | 0.6524 | 0.4216 | 0.6812 | 0.4520 | 0.5624 | 0.2651 | 0.5816 | 0.2764 |
| NCF | 0.6836 | 0.4435 | 0.6970 | 0.4712 | 0.5961 | 0.2872 | 0.6108 | 0.3056 |
| DSPR | 0.8041 | 0.6182 | 0.8166 | 0.6315 | 0.6854 | 0.3125 | 0.7012 | 0.3204 |
| TRSDL | 0.7925 | 0.6012 | 0.8104 | 0.6214 | 0.7052 | 0.3356 | 0.7126 | 0.3468 |
| BPR-T | 0.7123 | 0.5556 | 0.7492 | 0.5725 | 0.6532 | 0.3173 | 0.6750 | 0.3325 |
| STEM | 0.7458 | 0.5423 | 0.7643 | 0.5680 | 0.6726 | 0.3027 | 0.6953 | 0.3252 |
| TRAL | 0.8518 | 0.6345 | 0.8618 | 0.6505 | 0.7336 | 0.3621 | 0.7582 | 0.3820 |
| Imp. | 5.9% | 2.6% | 5.5% | 3.0% | 4.0% | 7.9% | 6.4% | 10.2% |
| Dataset | Delicious | LastFM | ||
|---|---|---|---|---|
| Metrics | HR@10 | NDCG@10 | HR@10 | NDCG@10 |
| TRS-w | 0.6125 | 0.3420 | 0.5671 | 0.2683 |
| TRS-d | 0.8093 | 0.5052 | 0.6924 | 0.3458 |
| TRS-w-a | 0.6340 | 0.3654 | 0.6021 | 0.2735 |
| TRAL | 0.8518 | 0.6345 | 0.7336 | 0.3621 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, Y.; Liu, S.; Zhou, Y.; Liu, H. TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning. Appl. Sci. 2023, 13, 814. https://doi.org/10.3390/app13020814
Zuo Y, Liu S, Zhou Y, Liu H. TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning. Applied Sciences. 2023; 13(2):814. https://doi.org/10.3390/app13020814
Chicago/Turabian StyleZuo, Yi, Shengzong Liu, Yun Zhou, and Huanhua Liu. 2023. "TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning" Applied Sciences 13, no. 2: 814. https://doi.org/10.3390/app13020814
APA StyleZuo, Y., Liu, S., Zhou, Y., & Liu, H. (2023). TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning. Applied Sciences, 13(2), 814. https://doi.org/10.3390/app13020814