


Near-Infrared Spectroscopy Coupled with a Neighborhood Rough Set Algorithm for Identifying the Storage Status of Paddy

Abstract
:1. Introduction
2. Materials and Methods
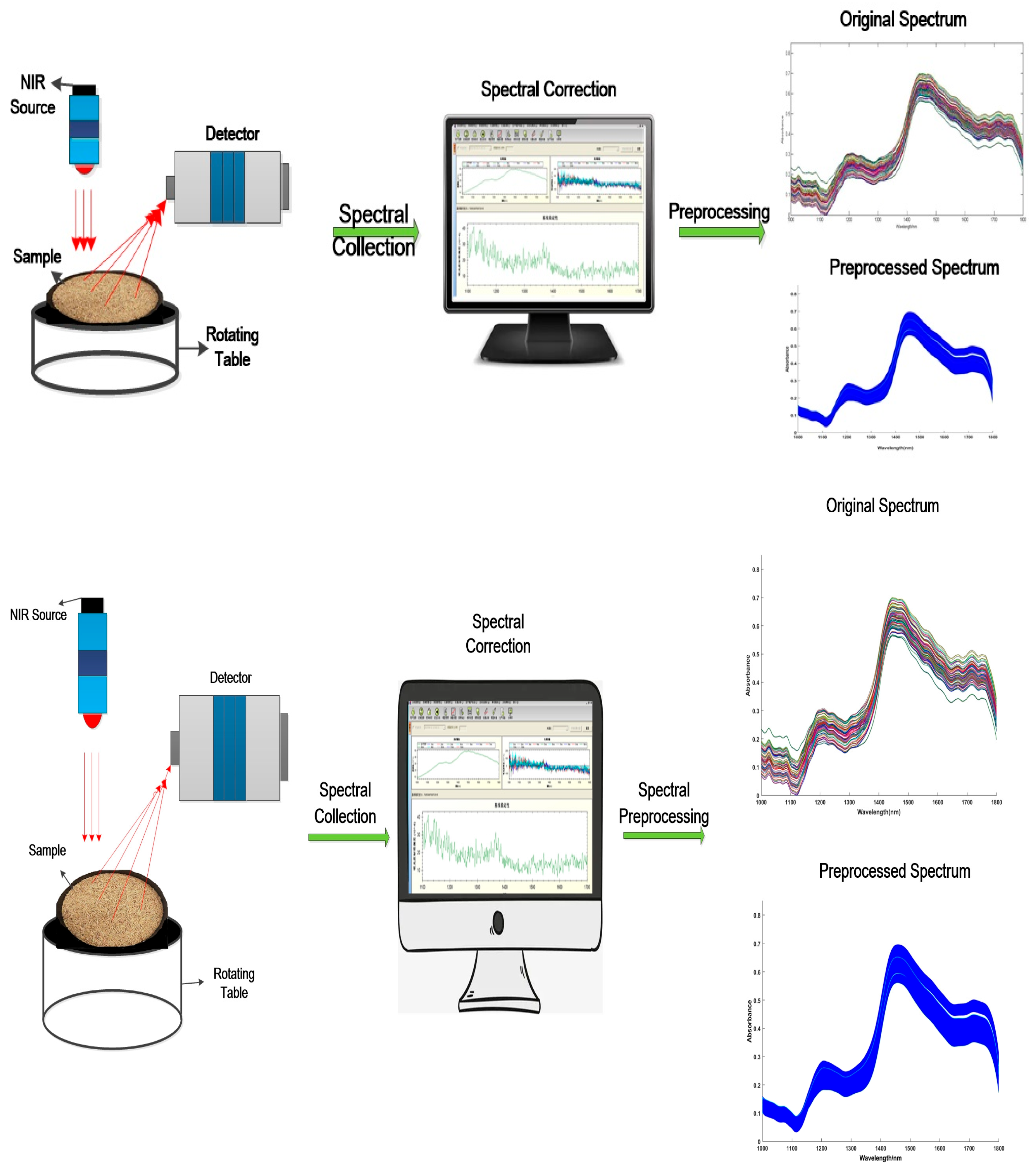
2.1. Sample Preparation
2.2. Near-Infrared Spectrometer
2.3. Spectral Feature Selection Algorithms
2.3.1. Neighborhood Rough Set
2.3.2. Successive Projections Algorithm
2.3.3. Variable Combination Population Analysis
2.4. Classification Models
2.4.1. Random Forest
2.4.2. Extreme Learning Machine
2.4.3. Soft Independent Modeling of Class Analogy
2.5. Model Evaluation
3. Results and Discussion
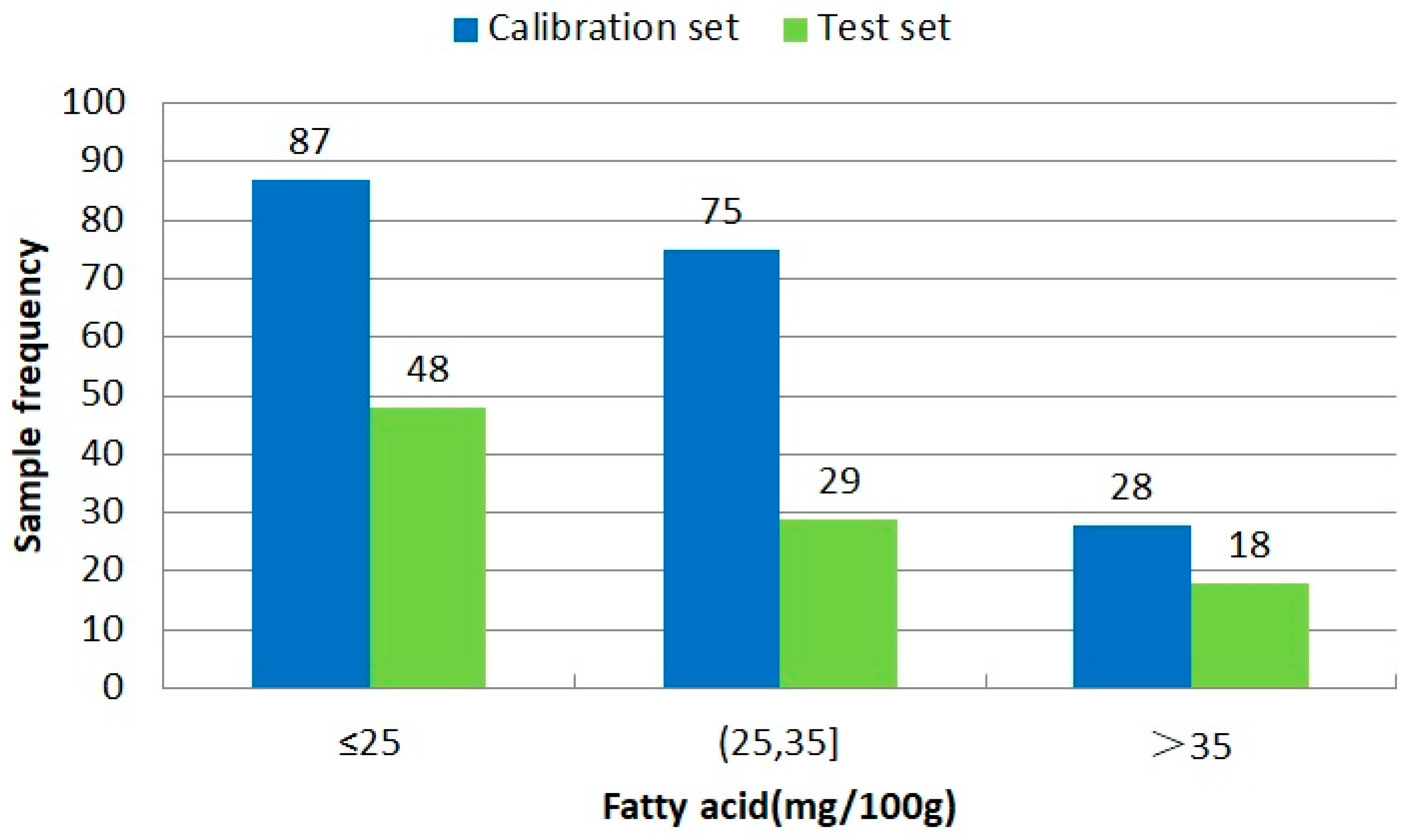
3.1. Analysis of Measured Fatty Acid
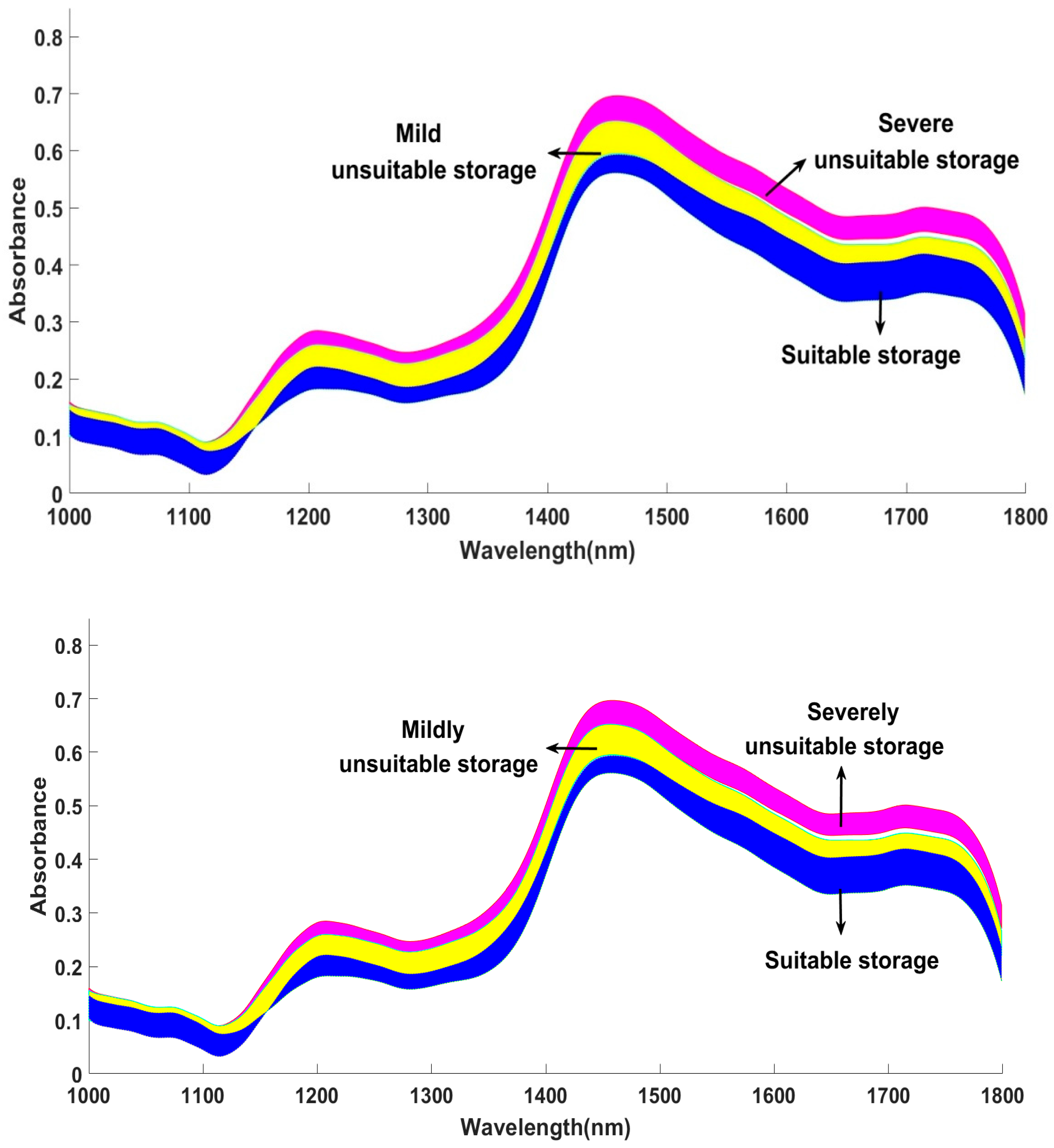
3.2. Analysis of Spectral Characteristics
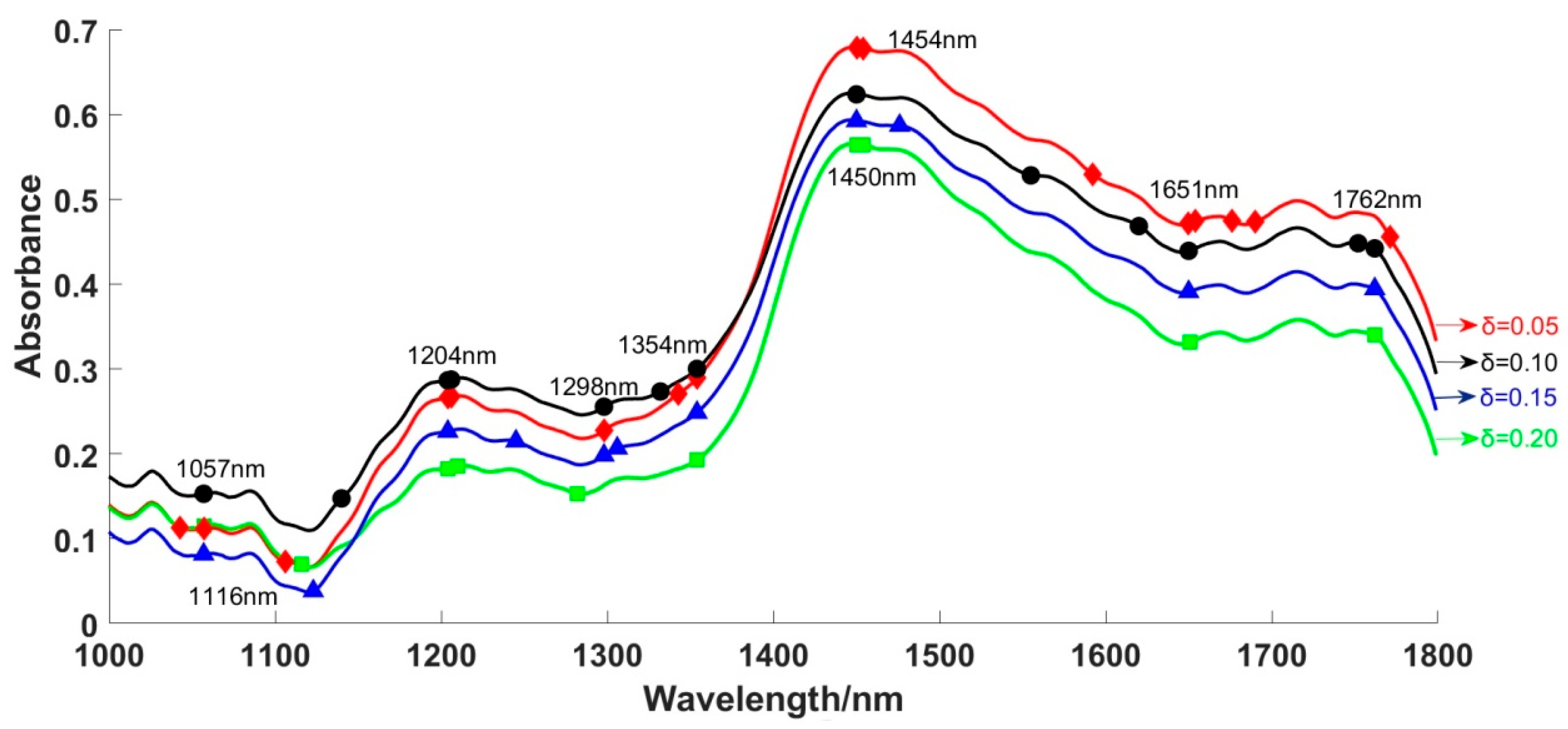
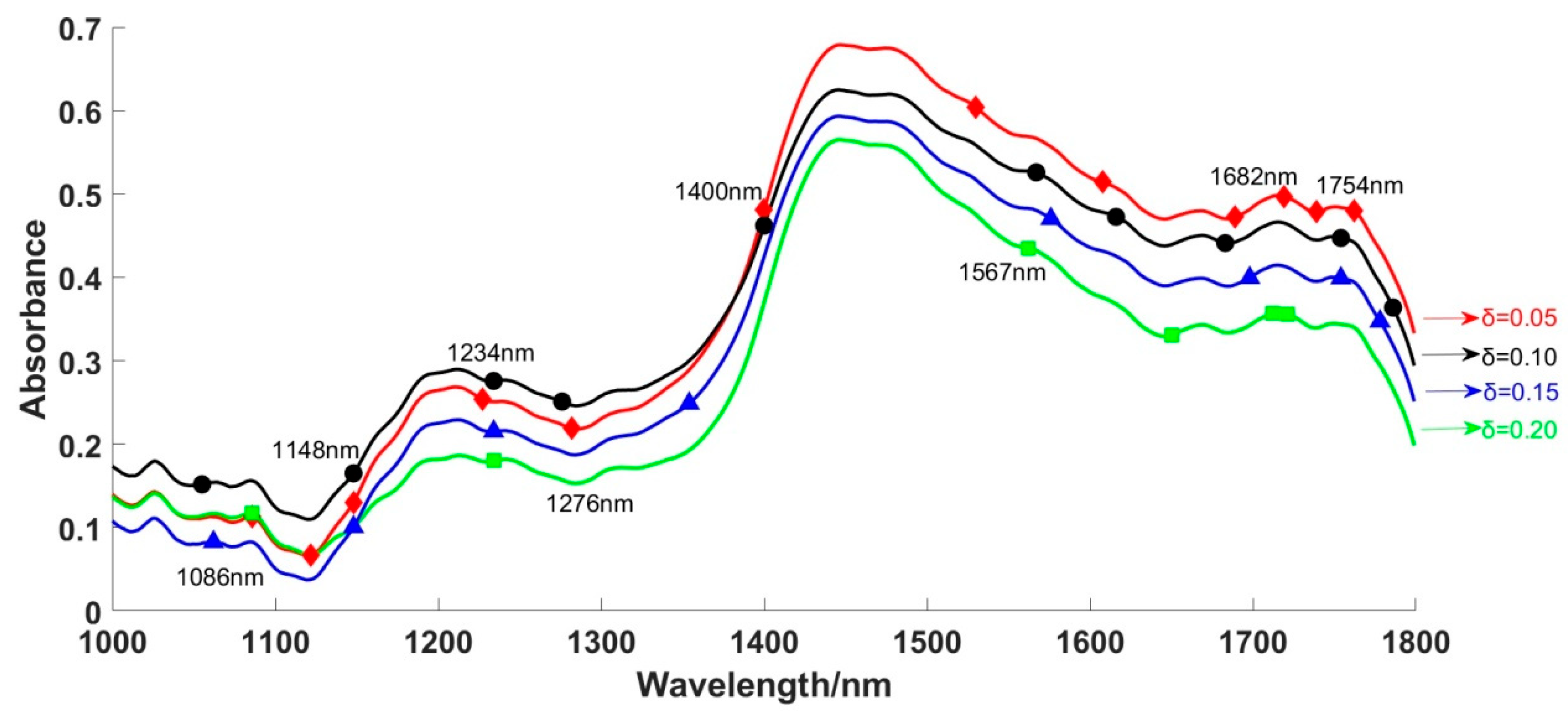
3.3. Feature Wavelengths Based on NRS
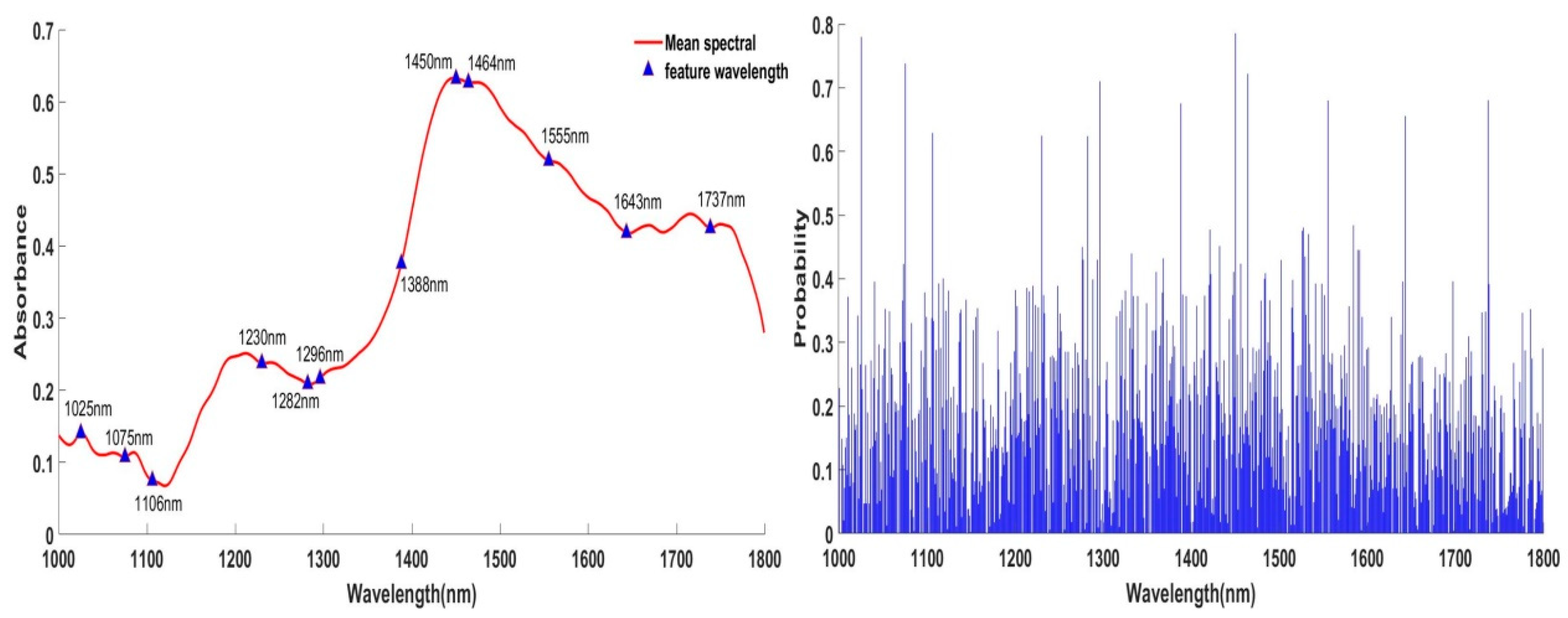
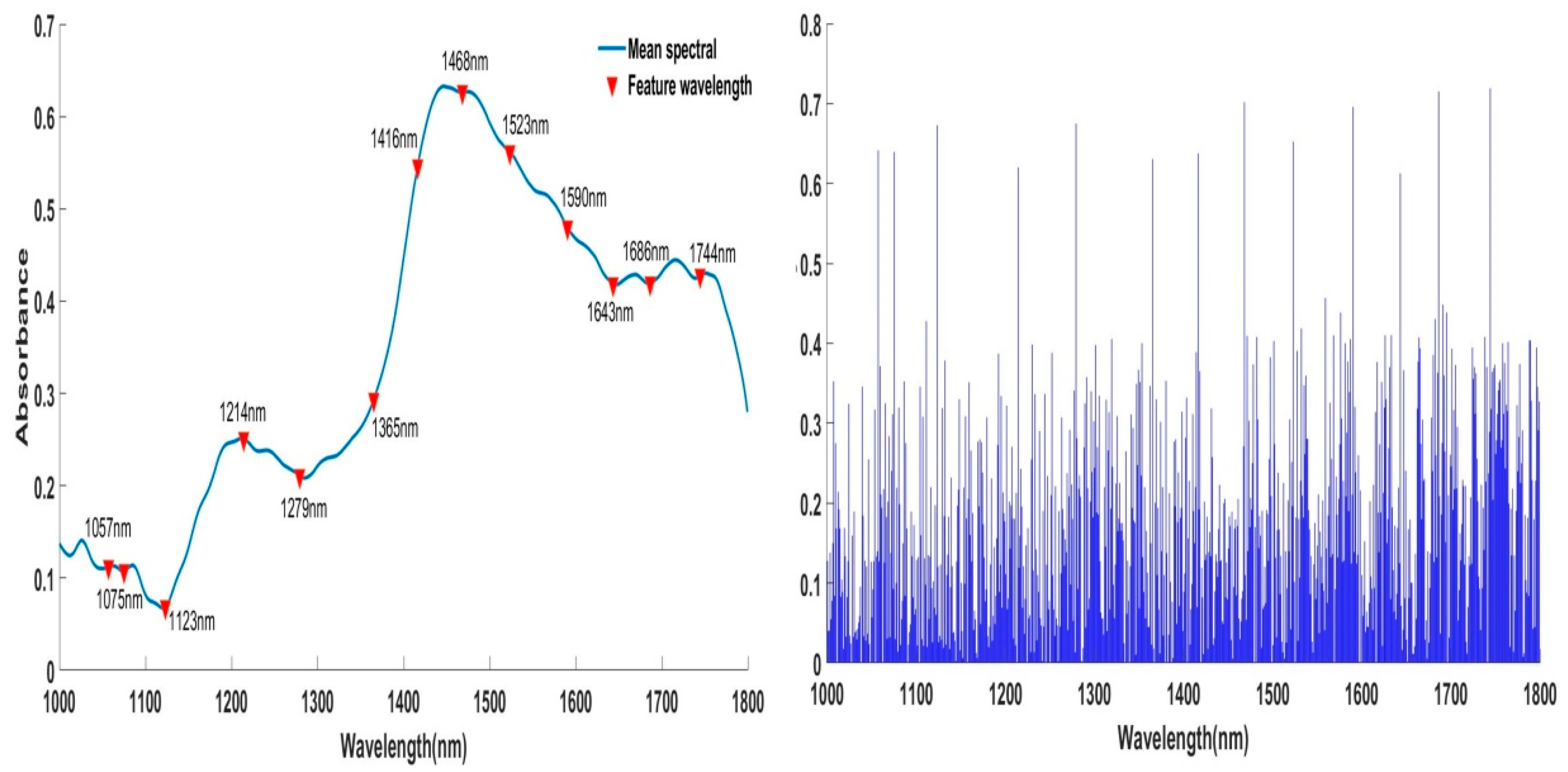
3.4. Feature Wavelengths Based on SPA and VCPA
3.5. Classification Model Construction
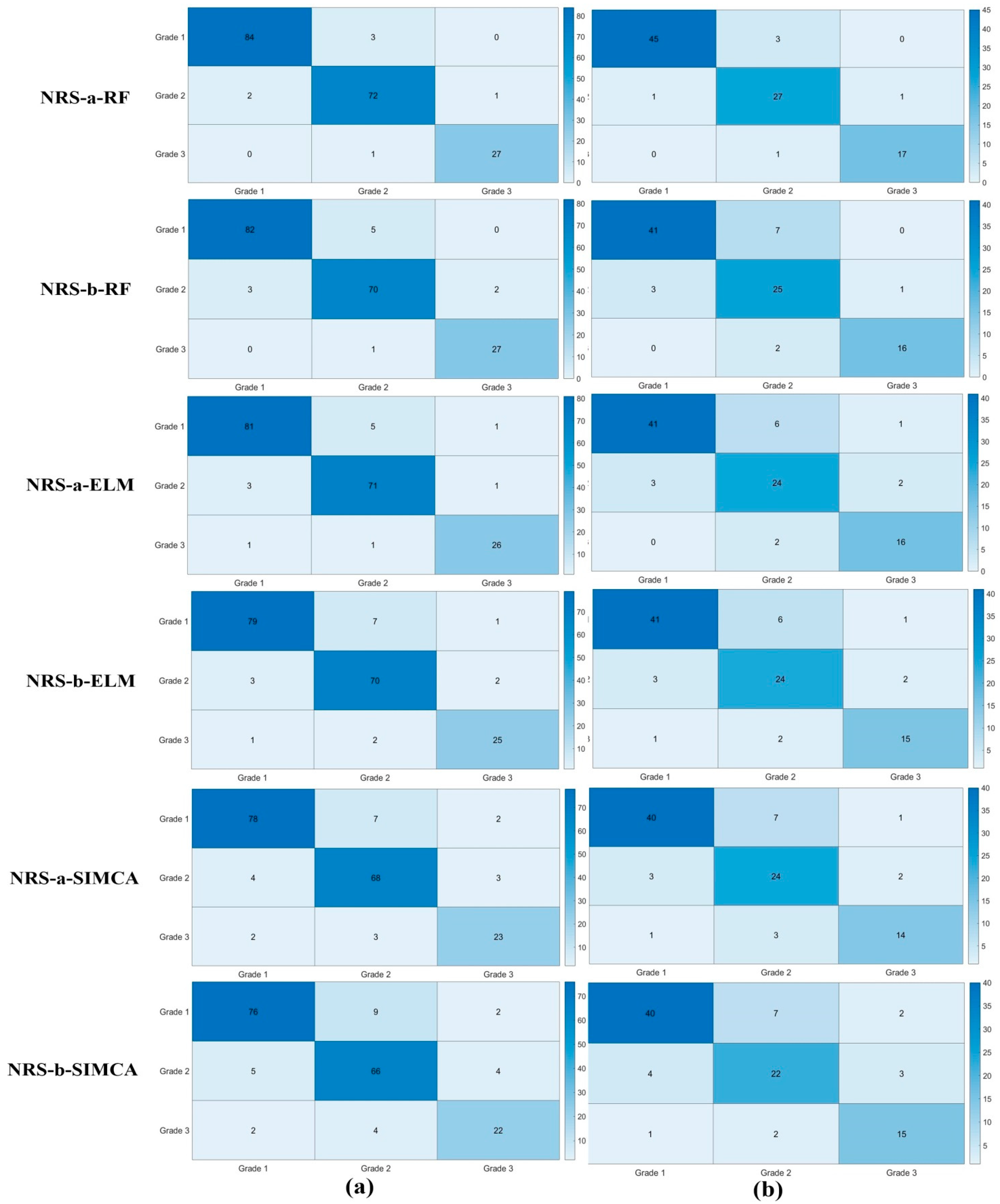
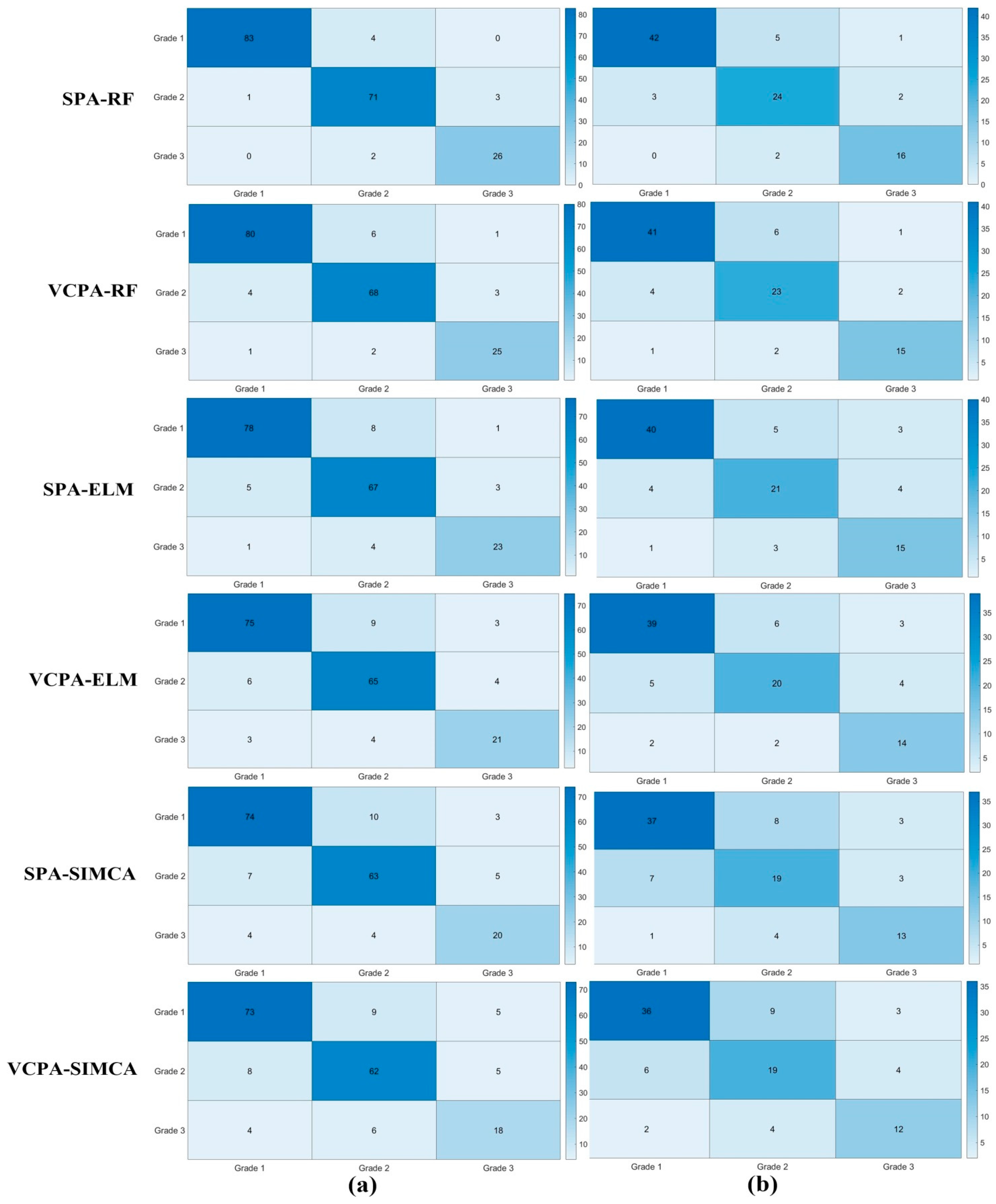
3.5.1. Identification Results Based on NRS with Classifiers
3.5.2. Identification Results Based on SPA and VCPA with Classifiers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pei, P.; Xiong, K.; Wang, X.; Sun, B.; Zhao, Z.; Xu, J.; Jin, X.; Ye, H.; Xiao, J.; Kong, J. Modelling the effect of environmental factors on the growth of Aspergillus parasiticus and mycotoxin production in paddy during storage. J. Stored Prod. Res. 2021, 93, 101846. [Google Scholar] [CrossRef]
- Carvalho, M.O.; Fradinho, P.; Martins, M.J.; Magro, A.; Raymundo, A.; de Sousa, I. Paddy rice stored under hermetic conditions: The effect of relative humidity, temperature and storage time in suppressing Sitophilus zeamais and impact on rice quality. J. Stored Prod. Res. 2019, 80, 21–27. [Google Scholar] [CrossRef]
- Tao, L.; Qin, W.; Wei, Z.; Li, X.; Zhang, H. Effects of small-scale storage on the cooking property and fatty acid profile of sea rice paddy. Appl. Food Res. 2022, 2, 100175. [Google Scholar] [CrossRef]
- Chai, Q.; Li, Y.; Li, X.; Wu, W.; Peng, H.; Jia, R.; Sun, Q. Assessment of variation in paddy microbial communities under different storage temperatures and relative humidity by Illumina sequencing analysis. Food Res. Int. 2019, 126, 108581. [Google Scholar] [CrossRef] [PubMed]
- Covele, G.; Gulube, A.; Tivana, L.; Ribeiro-Barros, A.I.; Carvalho, M.O.; Ndayiragije, A.; Nguenha, R. Effectiveness of hermetic containers in controlling paddy rice (Oryza sativa L.) storage insect pests. J. Stored Prod. Res. 2020, 89, 101710. [Google Scholar] [CrossRef]
- Collins, P.J.; Falk, M.G.; Nayak, M.K.; Emery, R.N.; Holloway, J.C. Monitoring resistance to phosphine in the lesser grain borer, Rhyzopertha dominica, in Australia: A national analysis of trends, storage types and geography in relation to resistance detections. J. Stored Prod. Res. 2017, 70, 25–36. [Google Scholar] [CrossRef]
- Yu, L.; Li, G.; Li, M.; Xu, F.; Beta, T.; Bao, J. Genotypic variation in phenolic acids, vitamin E and fatty acids in whole grain rice. Food Chem. 2016, 197, 776–782. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Du, Y.; Mao, Z.; Zhang, Z.; Li, P.; Cao, C. Grain starch, fatty acids, and amino acids determine the pasting properties in dry cultivation plus rice cultivars. Food Chem. 2022, 373, 131472. [Google Scholar] [CrossRef]
- Samaranayake, M.D.W.; Abeysekera, W.K.S.M.; Hewajulige, I.G.N.; Somasiri, H.P.P.S.; Mahanama, K.R.R.; Senanayake, D.M.J.B.; Premakumara, G.A.S. Fatty acid profiles of selected traditional and new improved rice varieties of Sri Lanka. J. Food Compos. Anal. 2022, 112, 104686. [Google Scholar] [CrossRef]
- Hu, X.; Fang, C.; Zhang, W.; Lu, L.; Guo, Z.; Li, S.; Chen, M. Change in volatiles, soluble sugars and fatty acids of glutinous rice, japonica rice and indica rice during storage. LWT 2023, 174, 114416. [Google Scholar] [CrossRef]
- Mittal, S.; Dutta, M.K.; Issac, A. Non-destructive image processing based system for assessment of rice quality and defects for classification according to inferred commercial value. Measurement 2019, 148, 106969. [Google Scholar] [CrossRef]
- Yang, D.; He, D.; Lu, A.; Ren, D.; Wang, J. Combination of spectral and textural information of hyperspectral imaging for the prediction of the moisture content and storage time of cooked beef. Infrared Phys. Technol. 2017, 83, 206–216. [Google Scholar] [CrossRef]
- Awanthi, M.G.G.; Jinendra, B.M.S.; Navaratne, S.B.; Navaratne, C.M. Adaptation of visible and short wave Near Infrared (VIS-SW-NIR) common PLS model for quantifying paddy hardness. J. Cereal Sci. 2019, 89, 102795. [Google Scholar] [CrossRef]
- Feng, H.; Zhang, Z.; Gao, X.; Guo, X.; Li, Y.; Li, Z.; Hu, Y.; Li, W. Rapid quality assessment of Succus Bambusae oral liquid based on near infrared spectroscopy and chemometrics. Ind. Crops Prod. 2022, 189, 115862. [Google Scholar] [CrossRef]
- Song, Y.; Cao, S.; Chu, X.; Zhou, Y.; Xu, Y.; Sun, T.; Zhou, G.; Liu, X. Non-destructive detection of moisture and fatty acid content in rice using hyperspectral imaging and chemometrics. J. Food Compos. Anal. 2023, 121, 105397. [Google Scholar] [CrossRef]
- Díaz, E.O.; Iino, H.; Koyama, K.; Kawamura, S.; Koseki, S.; Lyu, S. Non-destructive quality classification of rice taste properties based on near-infrared spectroscopy and machine learning algorithms. Food Chem. 2023, 429, 136907. [Google Scholar] [CrossRef] [PubMed]
- Anderson, J.V.; Wittenberg, A.; Li, H.; Berti, M.T. High throughput phenotyping of Camelina sativa seeds for crude protein, total oil, and fatty acids profile by near infrared spectroscopy. Ind. Crops Prod. 2019, 137, 501–507. [Google Scholar] [CrossRef]
- Arslan, M.; Zareef, M.; Elrasheid Tahir, H.; Xiaodong, Z.; Rakha, A.; Ali, S.; Shi, J.; Xiaobo, Z. Simultaneous quantitation of free fatty acid in rice by synergetic data fusion of colorimetric sensor arrays, NIR, and MIR spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 292, 122359. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Liu, T.; Chen, Q. Dynamic monitoring of fatty acid value in rice storage based on a portable near-infrared spectroscopy system. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 240, 118620. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Zhao, T.; Shen, F.; Liu, Q.; Fang, Y.; Hu, Q. Online detection of naturally DON contaminated wheat grains from China using Vis-NIR spectroscopy and computer vision. Biosyst. Eng. 2021, 201, 1–10. [Google Scholar] [CrossRef]
- Hu, L.; Yin, C.; Ma, S.; Liu, Z. Rapid detection of three quality parameters and classification of wine based on Vis-NIR spectroscopy with wavelength selection by ACO and CARS algorithms. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 205, 574–581. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Yuan, J.; Chang, Q.; Zhao, H.; Cao, Y. Early determination of mildew status in storage maize kernels using hyperspectral imaging combined with the stacked sparse auto-encoder algorithm. Infrared Phys. Technol. 2020, 109, 103412. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, J.; Chen, Y.; Tan, K.; Wang, L.; Yan, X. Stability analysis of hyperspectral band selection algorithms based on neighborhood rough set theory for classification. Chemom. Intell. Lab. Syst. 2017, 169, 35–44. [Google Scholar] [CrossRef]
- Zhang, X.; Mei, C.; Chen, D.; Li, J. Feature selection in mixed data: A method using a novel fuzzy rough set-based information entropy. Pattern Recognit. 2016, 56, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, H.; Chen, Y.; Tan, K.; Wang, L.; Xie, W. Neighborhood mutual information and its application on hyperspectral band selection for classification. Chemom. Intell. Lab. Syst. 2016, 157, 140–151. [Google Scholar] [CrossRef]
- Zhu, Q.; Huang, M.; Zhao, G. Apple Mealiness Detection Based on Neighborhood Rough Set and Hypersepctral Scattering Image. Trans. Chin. Soc. Agric. Mach. 2011, 42, 154–157. [Google Scholar]
- Dong, Y.; Xiang, B.; Geng, Y.; Yuan, W. Rough set based wavelength selection in near-infrared spectral analysis. Chemom. Intell. Lab. Syst. 2013, 126, 21–29. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, X.; Meng, X.; Wu, T.; Yan, X.; Luo, Q. Impact of class noise on performance of hyperspectral band selection based on neighborhood rough set theory. Chemom. Intell. Lab. Syst. 2019, 188, 37–45. [Google Scholar] [CrossRef]
- An, A.; Shan, N.; Chan, C.; Cercone, N.; Ziarko, W. Discovering rules for water demand prediction: An enhanced rough-set approach. Eng. Appl. Artif. Intell. 1996, 9, 645–653. [Google Scholar] [CrossRef]
- Yang, X.; Chen, H.; Li, T.; Wan, J.; Sang, B. Neighborhood rough sets with distance metric learning for feature selection. Knowl.-Based Syst. 2021, 224, 107076. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhan, B.; Zhang, Y.; Li, R.; Li, J. Nondestructive firmness measurement of the multiple cultivars of pears by Vis-NIR spectroscopy coupled with multivariate calibration analysis and MC-UVE-SPA method. Infrared Phys. Technol. 2020, 104, 103154. [Google Scholar] [CrossRef]
- Yun, Y.-H.; Wang, W.-T.; Deng, B.-C.; Lai, G.-B.; Liu, X.-b.; Ren, D.-B.; Liang, Y.-Z.; Fan, W.; Xu, Q.-S. Using variable combination population analysis for variable selection in multivariate calibration. Anal. Chim. Acta 2015, 862, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- De Braekeleer, K.; De Maesschalck, R.; Hailey, P.A.; Sharp, D.C.A.; Massart, D.L. On-line application of the orthogonal projection approach (OPA) and the soft independent modelling of class analogy approach (SIMCA) for the detection of the end point of a polymorph conversion reaction by near infrared spectroscopy (NIR). Chemom. Intell. Lab. Syst. 1999, 46, 103–116. [Google Scholar] [CrossRef]
- Parikh, R.; Mathai, A.; Parikh, S.; Sekhar, G.C.; Thomas, R. Understanding and using sensitivity, specificity and predictive values. Indian J. Ophthalmol. 2008, 56, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Wu, N.; Jiang, H.; Bao, Y.; Zhang, C.; Zhang, J.; Song, W.; Zhao, Y.; Mi, C.; He, Y.; Liu, F. Practicability investigation of using near-infrared hyperspectral imaging to detect rice kernels infected with rice false smut in different conditions. Sens. Actuators B Chem. 2020, 308, 127696. [Google Scholar] [CrossRef]
- Miao, X.; Miao, Y.; Gong, H.; Tao, S.; Chen, Z.; Wang, J.; Chen, Y.; Chen, Y. NIR spectroscopy coupled with chemometric algorithms for the prediction of cadmium content in rice samples. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 257, 119700. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Calibration Set (n = 190) | Test Set (n = 95) |
|---|---|---|
| Mean | 24.15 | 22.47 |
| Variance | 10.67 | 9.27 |
| Maximum | 67.90 | 60.21 |
| Minimum | 12.11 | 12.98 |
| Range | 12.11~67.90 | 12.98~60.21 |
| β | δ | Numbers | Optimal Wavelengths/nm |
|---|---|---|---|
| 0.75 | 0.05 | 16 | 1043, 1057, 1106, 1204, 1206 1298, 1343, 1354, 1450, 1454, 1592 1651, 1654, 1676, 1690, 1771 |
| 0.10 | 13 | 1057, 1140, 1204, 1206 1298, 1332, 1354, 1450, 1555 1620, 1650, 1752, 1762 | |
| 0.15 | 12 | 1057, 1123, 1204 1245, 1298, 1306, 1354, 1450 1458, 1476, 1651, 1762 | |
| 0.20 | 10 | 1057, 1116, 1204 1210, 1282, 1354, 1450 1454, 1651, 1762 | |
| 0.85 | 0.05 | 12 | 1086, 1122, 1148, 1227, 1282 1400, 1530, 1608, 1689, 1719, 1739, 1762 |
| 0.10 | 10 | 1055, 1148, 1234, 1276, 1400 1567, 1616, 1682, 1754, 1786 | |
| 0.15 | 8 | 1062, 1148, 1234, 1354 1576, 1698, 1754, 1778 | |
| 0.20 | 6 | 1086, 1234, 1562 1650, 1712, 1721 |
| Models | Calibration Set | Test Set |
|---|---|---|
| CCR (%) | CCR (%) | |
| NRS-a-RF | 96.31 | 93.68 |
| NRS-b-RF | 94.21 | 86.31 |
| NRS-a-ELM | 93.68 | 85.26 |
| NRS-b-ELM | 91.57 | 84.21 |
| NRS-a-SIMCA | 88.94 | 82.10 |
| NRS-b-SIMCA | 86.31 | 81.05 |
| Models | Calibration Set | Test Set |
|---|---|---|
| CCR (%) | CCR (%) | |
| SPA-RF | 94.73 | 86.31 |
| VCPA-RF | 91.05 | 83.15 |
| SPA-ELM | 88.42 | 80.0 |
| VCPA-ELM | 84.73 | 76.84 |
| SPA-SIMCA | 82.63 | 72.63 |
| VCPA-SIMCA | 80.52 | 70.52 |
| Models | Actual Grade | Calibration Set | Test Set | ||
|---|---|---|---|---|---|
| Sensitivity | Specificity | Sensitivity | Specificity | ||
| NRS-a-RF | Grade1 | 0.96 | 0.98 | 0.93 | 0.97 |
| Grade2 | 0.96 | 0.96 | 0.93 | 0.93 | |
| Grade3 | 0.96 | 0.99 | 0.94 | 0.98 | |
| SPA-RF | Grade1 | 0.95 | 0.99 | 0.87 | 0.93 |
| Grade2 | 0.94 | 0.94 | 0.83 | 0.89 | |
| Grade3 | 0.92 | 0.98 | 0.88 | 0.95 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Zhou, Y.; Li, Q.; Jie, Y.; Shi, T. Near-Infrared Spectroscopy Coupled with a Neighborhood Rough Set Algorithm for Identifying the Storage Status of Paddy. Appl. Sci. 2023, 13, 11357. https://doi.org/10.3390/app132011357
Yang D, Zhou Y, Li Q, Jie Y, Shi T. Near-Infrared Spectroscopy Coupled with a Neighborhood Rough Set Algorithm for Identifying the Storage Status of Paddy. Applied Sciences. 2023; 13(20):11357. https://doi.org/10.3390/app132011357
Chicago/Turabian StyleYang, Dong, Yuxing Zhou, Qianqian Li, Yu Jie, and Tianyu Shi. 2023. "Near-Infrared Spectroscopy Coupled with a Neighborhood Rough Set Algorithm for Identifying the Storage Status of Paddy" Applied Sciences 13, no. 20: 11357. https://doi.org/10.3390/app132011357
APA StyleYang, D., Zhou, Y., Li, Q., Jie, Y., & Shi, T. (2023). Near-Infrared Spectroscopy Coupled with a Neighborhood Rough Set Algorithm for Identifying the Storage Status of Paddy. Applied Sciences, 13(20), 11357. https://doi.org/10.3390/app132011357