1. Introduction
Driven by the rapid surge in social interactions on global online platforms, social network analysis has gained momentum. Concurrently, the security of social media has garnered increased attention. Online social networks involve user–entity interactions and hold significant user privacy data. Yet, network propagation or user-defined controls might hinder complete data acquisition. To address this, we explore integrating link prediction research to comprehensively capture network structure and protect user interactions. Link prediction is a well-explored area in social network analysis, with a growing focus on heterogeneous information social networks. These networks are crucial due to diverse node-link types, mirroring contemporary social networks. Here, we concentrate on this network paradigm where nodes represent individuals and links embody their social interactions [
1]. To achieve a holistic network structure and integrity of user interaction data, effective methods for predicting unobserved links become imperative.
Various methods for predicting links in heterogeneous networks have been proposed, including traditional ones and network embedding approaches. Traditional methods usually create probabilistic models to represent network connections and calculate the likelihood of links forming between nodes. Alternatively, they use structural node similarities and network topologies to fit models or predict likelihoods of links based on predefined principles. In contrast, network embedding methods take advantage of the powerful learning ability of neural networks and show significant performance enhancement. These existing methods have achieved good results in homogeneous social networks but do not perform well in heterogeneous information social networks. Unlike homogeneous social networks with a single type of node and link [
2,
3], heterogeneous information social networks make it difficult to collect a sufficient number of different observation samples to learn different features between different link types [
4,
5], thus leading to inaccurate predictions of unobserved links.
To achieve our research objectives of designing a versatile model capable of accurately predicting various types of unobserved links in heterogeneous information networks, several key challenges need to be addressed. First and foremost, we must tackle the task of capturing the individual features of different node types and leveraging the acquired type-specific priori knowledge. The second challenge pertains to the fusion of feature representations from diverse enhancing predictive experts. Given the crucial importance of feature representations for different types of unobserved links, an effective fusion mechanism must be devised to amalgamate the link feature representations offered by distinct enhancing predictive experts. The third challenge involves assessing the trustworthiness value of each enhancing predictive expert, indicative of the reliability of the link feature representations they provide.
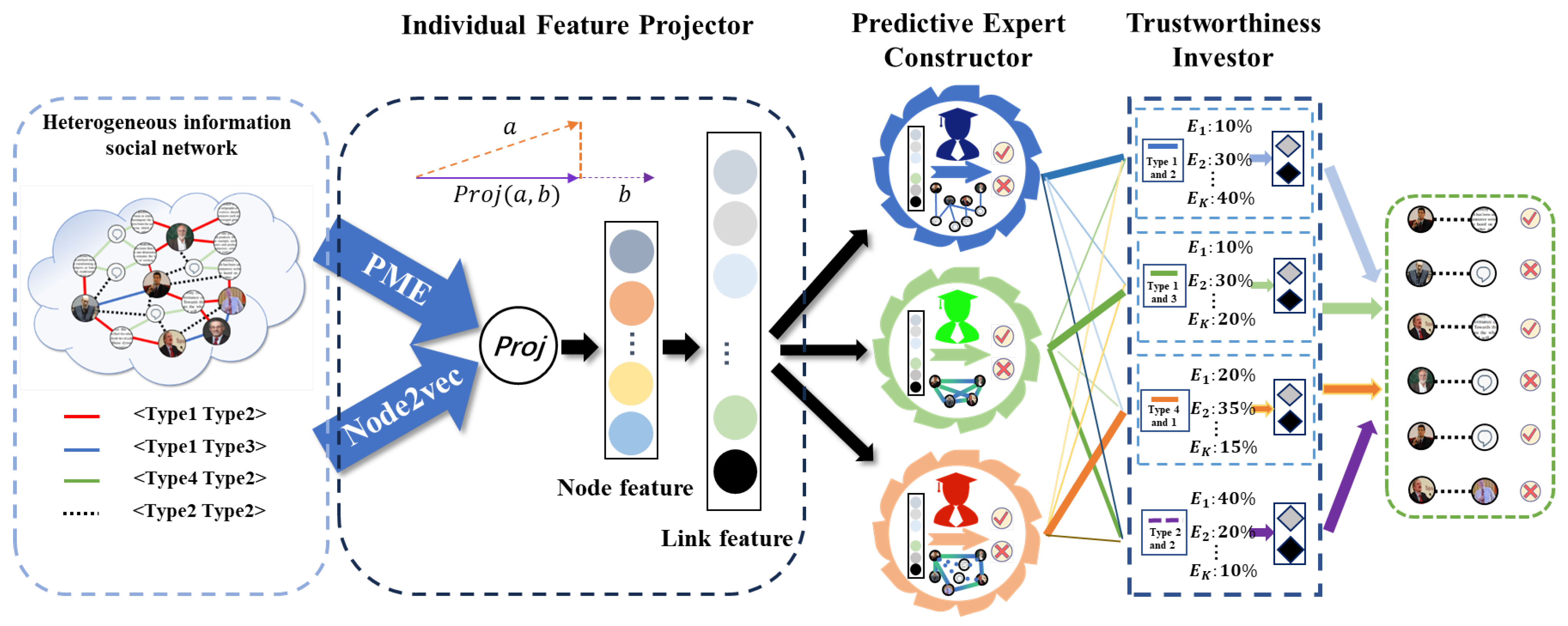
Consequently, we propose an approach named the “Enhancing Predictive Expert Method” (EPEM), composed of three components: the individual feature projector, the predictive expert constructor, and the trustworthiness investor. The individual feature projector acquires individual feature representations of distinct node and link types, thereby guiding the prediction of unobserved links. The predictive expert constructor generates multiple enhancing predictive experts based on the individual feature projector, obtaining fused individual feature representations for unobserved links. This fusion assists in distinguishing different link types, thus enhancing prediction accuracy. The trustworthiness investor assesses the reliability of each enhancing predictive expert, amalgamating fusion predictions from diverse experts. The fusion mechanism operates on the principle that enhancing predictive experts with higher trustworthiness levels provides dependable predictions. Experiments on three heterogeneous social network datasets (Facebook [
6], DBLP [
7], and MovieLens [
8]) show an accuracy improvement of 6.23%, 5.37%, and 3.39%, respectively, compared to current state-of-the-art methods. The main contributions of this study are summarized as follows:
The proposed EPEM presents a comprehensive approach for predicting unobserved links and augmenting network interaction information within heterogeneous information social networks. It possesses the capability to enhance feature representations for various link types. Additionally, it seamlessly integrates with other efficient feature representation algorithms, further enhancing prediction accuracy.
EPEM leverages multiple enhancing predictive experts to discriminate among different link types, thereby providing an efficient and accurate solution for feature representations of diverse link types. This approach bolsters the discrimination capacity for distinct link types, ultimately leading to more precise predictions.
During the fusion process of predictive representations from numerous enhancing predictive experts, we incorporate the notion of a trustworthiness investor to assign trustworthiness values to each expert. Experimental validation attests to the effectiveness of our proposed EPEM, achieving performance that surpasses the current state-of-the-art approaches.
2. Related Work
Over the past few decades, significant strides have been made in the realm of social network analysis. Heterogeneous information social networks, which encompass diverse types of interactions modeled through distinct node and link categories, have garnered increasing attention within the domain of link prediction [
9]. In contrast to homogeneous networks characterized by uniform node and link types, heterogeneous information social networks differentiate between various categories of social interactions, introducing novel challenges for link prediction and addressing security concerns related to network structure completion and safeguarding user interaction data.
Existing link prediction methods can be broadly categorized into three types: similarity-based traditional computational methods, embedding representation-based methods, and graph neural network-based methods.
Traditional similarity-based computational methods. With a long developmental history, traditional similarity-based computational methods have exhibited commendable results in link prediction within homogeneous social networks. These methods can be classified into several subcategories: Firstly, node similarity-based models frequently leverage fundamental node attributes to define structural similarities among nodes, such as common topological relationships between nodes [
10,
11], as well as first-order and second-order neighbor features [
12]. Secondly, probability models [
13,
14] abstract the underlying network structure using existing network attributes, constructing models with a defined number of parameters via objective function optimization and estimating the likelihood of nonexistent link existence through conditional probability. Finally, maximum likelihood-based methods aim to maximize the probability of observed structure existence, often adhering to certain organizational and probabilistic principles [
15]. However, the computational complexity of maximum likelihood increases exponentially with a substantial rise in node count (exceeding 10,000), and its computational demands on the model become excessive, rendering it unsuitable for scalability to large-scale network datasets [
16].
Network embedding representation methods. While traditional methods still apply to such networks, they do not fully capture the diverse network features, leading to incomplete information gathering, compromised network structure, and potential security issues. Therefore, network embedding representation methods have emerged as a viable solution to address these challenges. Compared to traditional link prediction techniques, embedding representation methods exhibit enhanced performance by leveraging neural network capabilities. For instance, Negi et al. [
17] treat link prediction in heterogeneous networks as a multi-task and metric learning problem, learning specific distance metrics for distinct link types. Their approach also accounts for task relevance, non-reinforcing feature robustness, and network distribution characteristics. Similarly, Zhao et al. [
18] introduce a novel multi-view adversarial completion model that leverages topological logical structures within each view through relational spaces. This model enhances the semantic representation of nodes by aggregating neighborhood information from synchronized views. Chai et al. [
19] use the fully connected network (FCN) adjacency matrix for low-rank representation, capturing local structures through FCN interactions. The new objective function penalizes the nuclear norm of the reconstructed network adjacency matrix. Le et al. [
20] present a novel model that adjusts users across information networks using a seed set of known anchor links. The model integrates four embedding techniques to learn from the same latent space and employs an aggregation method to achieve the final network alignment embedding matrix.
Graph neural network-based methods. With the rapid advancement of graph neural networks (GNNs), graph neural network-based methods have applied GNNs to link prediction, including by Zhang et al. [
3], who propose a heuristic learning paradigm based on GNNs for extracting local subgraphs around target edges. Che et al. [
21] propose a model named TALP, which is a unified framework that aims to predict anchored links between node pairs. TALP aligns anchored user nodes, learns type-aware vectors and type-fusion vectors associated with each user node using attention learning of graphs subsidiarily, and obtains an n-tuple representation of each user node. Liu et al. [
22] introduce a link prediction approach that integrates GNNs with capsule networks. They use a conversion block to transform node embeddings generated by GNNs into edge feature maps, reframing the link prediction as a graph classification problem. These methods utilize the effective capacity of GNN-based models to extract structural features and heterogeneous information with more complexity.
Although existing link prediction methods have shown promise by focusing on heterogeneous graph construction or adversarial learning for different link types, which have shown promising results, they tend to overlook the feature variability among different types of links, resulting in inaccurate representation of individual features and consequently limited prediction performance. To solve the problem, this research aims to extract individual features of different link types while eliminating common features, utilize existing features from observed links to guide the prediction of unobserved links, and propose a novel link prediction method for heterogeneous information social networks.
3. Problem Definition
A heterogeneous information social network is an information network containing diverse node and link types [
4], represented as an indirect graph
. Here,
V signifies the node set, encompassing
N node types.
E symbolizes the link set connecting nodes in
V, spanning
K link types. Excluded unobserved links from
E are denoted as
. Among these,
comprises testing links, selected at random with a ratio of
from the unobserved link set
U, while the rest are considered training links. The objective of link prediction in heterogeneous information social networks involves determining a predictive function
, with
, presenting the prediction results for the existence of testing links in the subsequent function. Taking an example link
l, we initially derive its feature representation by processing the node feature representation for each constituent node. Our task simplifies into constructing a model to predict the existence label
for link
l. In the following section, we propose a combined link representation utilizing PME [
12] and node2vec to obtain precise link feature representation [
23].
4. Methodology
This section presents the framework of our proposed EPEM, consisting of three main components: the individual feature projector, predictive expert constructor, and trustworthiness investor, as shown in
Figure 1. The individual feature projector is responsible for learning individual feature representations of different types of links by eliminating common features, which is crucial to ensure the effectiveness of the subsequent fusion process. Meanwhile, the predictive expert constructor generates enhancing predictive experts based on the learned feature representations from the individual feature projector, aiming to obtain fused feature representations of links. The trustworthiness investor plays a critical role in assigning trustworthiness values to each enhancing predictive expert. The trustworthiness assignment follows the principle that the more credible predictive expert has a higher trustworthiness value. Finally, the prediction labels of unobserved links are determined based on the weighting of the prediction results of multiple enhancing predictive experts and their corresponding trustworthiness values. In the following sections, we will elaborate on each of the three components of EPEM.
4.1. Individual Feature Projector
The individual feature projector in the EPEM framework considers two different aspects when obtaining node feature representations: common features and unique features of links. Common features refer to the association formed purely based on the topological structure of links between nodes, without considering the potential attribute differences among nodes. Unique features encapsulate the special characteristics of different link types.
We firstly approach heterogeneous nodes as if they were homogeneous nodes concerning their structure, focusing solely on the structural attributes between nodes, and we leverage node2vec to derive link feature representations, which serve as common features for nodes
i and
j, denoted as
and
, respectively. Subsequently, we employ PME to generate type-specific priori feature representations for nodes
i and
j, designated as
and
, respectively. This encompasses the attribute information intrinsic to each link type and serves as the individual feature of distinct link types. Ultimately, to emphasize the distinctive traits of various link types and reinforce the capacity to effectively discriminate between them, we fuse the individual features and common feature representations of nodes via orthogonal projection as follows.
where
is a projection function which can joint vector
a and
b.
According to the aforementioned function
, we obtain the projection representation
of node
i as follows.
where
represents the unique feature representation and
represents the common one, respectively. The individual projection representation
of each node
i is obtained by orthogonal projection function as follows.
Finally, by aggregating the unique and common feature representations, we obtain the feature representation
of link
by combining the projection feature representations of nodes
i and
j in (
4).
4.2. Predictive Expert Constructor
After obtaining different types of link representations, we propose a predictive expert constructor that generates multiple enhancing predictive experts during the training process. The predictive expert constructor initially generates
K predictive experts for all types of links in the heterogeneous information social network, denoting the
kth predictive expert as
, where
represents the set of all contained parameters.
denotes the specific parameter set for the
kth enhancing predictive expert. The prediction process of the
kth predictive expert for the existence likelihood of link
l is as follows.
where
represents the predictive representation of link
l in the
kth predictive expert. Based on the
, the model uses cross-entropy to quantify the predictive power of this enhancing predictive expert for link
l, as follows.
Here,
, if the
kth enhancing predictive expert predicts that link
l exists, then
; otherwise,
. The larger the value of
, the better the prediction of link
l by the
kth expert, and the purpose of the
kth expert is to maximize the prediction of the
kth type of link. The model labels the link set of the
kth type as
, then the prediction loss function of the corresponding enhancing predictive expert of the
kth type is as follows.
The model minimizes the prediction loss
by solving for the optimal parameters
and
by the process shown below.
Meanwhile, to learn the individual features of different types of links and to preserve the type independence of each enhancing predictive expert, the model needs to further reduce the type correlation between them while generating experts of the respective link types. Let the correlation loss between experts of type
and experts of type
be defined as follows.
When the value of
is large, the difference in type-specific features learned by the
and
type experts is also large, which is beneficial for each enhancing predictive expert to learn the corresponding type of link feature. As there are
K types of links in total, there are also
K enhancing predictive experts. The overall related predict expert loss
is defined as follows.
where
represents the overall link set.
represents the set of all contained parameters, and
denotes the specific parameter set for aggregated enhancing predictive experts when computing
, respectively.
The model needs to minimize the overall prediction loss and maximize the type-specific loss, allowing the enhancing predictive expert to better predict the corresponding type of link. The final loss is defined as follows.
Here,
refers to the balancing parameter between the prediction loss,
, and the average type-specific loss,
.
represent the final optimized parameters of predictive expert, and the proposed EPEM calculates the final loss
for link prediction based on the results obtained from prediction experts with optimal prediction parameters. The enhancing predictive expert,
, utilizes individual feature projector to obtain feature representations of different types of links. The goal is to find the optimal parameter set
that minimizes the final loss,
, in this process, which is represented as follows.
4.3. Trustworthiness Investor
When the model generates the corresponding enhancing predictive expert for each type of link, it also needs to fully utilize the additional feature information of the specific type of link representation from other types of experts. By fusing the prediction labels of different types of experts for this type of link, the prediction accuracy can be improved. Each enhancing predictive expert network layer is followed by a fully connected layer with a softmax function to predict the existence likelihoods of unobserved links.The predictive existence label provided by the
kth enhancing predictive expert
is obtained as follow.
where
denotes the initial predictive likelihood value of link
l according to individual feature projection process, and
denotes the threshold that determines the predictive existence label of link
l of the
kth predictive expert.
Each predictive expert uniformly assigns trustworthiness to estimated existence likelihoods of unobserved links, as predicted by enhancing predictive experts. Trustworthiness ratings are iteratively exchanged between the experts and the unobserved links’ existence labels. The trustworthiness of an expert depends on a weighted combination of the trustworthiness of previously estimated existence labels and the expert’s own trustworthiness. This iterative trustworthiness exchange process continues until all unobserved links have been reevaluated.
Under our assumption, each enhancing predictive expert equally trusts all existence likelihoods of its predicted unobserved links. Trustworthiness of an existence label for an unobserved link grows non-linearly. Predictions from highly trusted experts are considered more credible, thus enhancing the trustworthiness of those experts.
Let
represent the predicted existence label by the
kth expert for unobserved link
l. If
, the link’s existence likelihood is high, while
denotes low likelihood. Initial trustworthiness of an expert’s existence label prediction is set at
, where
is the count of unobserved links predicted as 1 by the
kth expert. In each iteration, an expert’s trustworthiness is updated using a weighted sum of trustworthiness from previous labels. The updated existence label trustworthiness
is determined uniformly from the expert’s trustworthiness. This iterative process continues until convergence.
The trustworthiness of the existence likelihood of each unobserved link is obtained by (
16).
The notation
is used to denote the set of all enhancing predictive experts that predict the existence of link
l. Formula (
16) represents an “investment” approach. The reason for selecting this weight allocation method is that the prediction of the presence or absence of links is binary, similar to the outcome of an investment being either a win or a loss. This allocation method is logically straightforward and effective. It is worth mentioning that for the trustworthiness calculation Formulas (
15) and (
16), the convergence goal is to ensure that the difference between adjacent trustworthiness values is less than a threshold
. In our experiments, we used a threshold of
, which ensures the accuracy of the algorithm in obtaining trustworthiness values and facilitates a quick convergence.
Once the trustworthiness of each enhancing predictive expert has been determined, the final feature
of link
l can be represented by Equation (
17).
The feature vector
serves as the input for a predictive network layer that employs a multi-layer perception (MLP) network with a softmax output layer. The final predictive network layer within the Enhancing Predictive Expert Model (EPEM) is specifically tailored for predicting invalid links within heterogeneous information social networks.
We use
as the actual existence label and
for the prediction label of link
l. The loss function uses a binary cross-entropy loss [
24] in (
19).
5. Experiments
In this section, we detail experimental datasets, classical link prediction algorithms and currently selected representative algorithms for comparative analysis, as well as the experimental setup. Subsequently, we analyze the experimental results, the parameters, and ablation experiments.
5.1. Datasets
We assessed our approach through experiments on three diverse heterogeneous information social network datasets. Each dataset was split into distinct training and testing sets, maintaining a fixed ratio
. Further specifics are detailed in
Table 1.
The
Facebook dataset [
6] comprises a page-page network with concealed sites. Its nodes signify official pages, while the links denote reciprocal “like” relationships. This dataset encompasses four node types (politicians (P), governmental organizations (G), television shows (T), and companies (C)) and six link types.
The
DBLP dataset [
7], a comprehensive computer science bibliography, was sourced from multiple publishers near the 2016 US elections. Our analysis centered on DBLP-4-Area, containing three node types (author (A), paper (P), and venue (V)) and two link types (paper-author (P-A) and paper-venue (P-V)).
The
MovieLens dataset [
8] offers data on movies, actors, and directors. Our investigation focused on a specific subset with three node types (actor (A), director (D), and movie (M)) and two link types (movie-actor (M-A) and movie-director (M-D)).
5.2. Baselines
To evaluate the effectiveness of our proposed EPEM, we compared it against several baselines. These baselines include traditional link prediction methods, network embedding methods and graph neural network-based methods, as follows:
[
25]. SVM, a machine learning model, is capable of assigning labels to objects based on a training dataset. The model is trained by using normalized structural feature representations and existence label sets.
[
18]. SLiCE is a framework that aims to bridge static representation learning methods with global information from the entire graph and local attention-driven mechanisms. This framework aims to learn contextual node representations that incorporate both local and global information.
[
12]. PME is an embedding model that is specifically designed for heterogeneous information social networks. PME builds object and relational embeddings in independent object and relational spaces, and learns embeddings by projecting nodes from the object space to the corresponding relational space and calculating similarities between projected nodes.
[
24]. HHNE is a representation learning method that aims to obtain embedding vectors of each node in heterogeneous networks. To achieve this, the method utilizes the naive active learning approach.
[
26]. HAN is a heterogeneous network embedding representation method that utilizes generative adversarial networks. The model involves training a discriminator and a generator in a minimization game, and the generator is designed to generate a better negative sample by learning the node distribution and incorporating it into the learning process of the sample features.
[
27]. SEAL is a link prediction method that utilizes graph neural networks to learn heuristics from local sub-graphs in heterogeneous information social networks. SEAL extracts the local enclosing sub-graphs around it and uses graph neural networks to learn general graph structure features for link prediction.
[
21]. TALP is a unified framework designed to predict anchored links between nodes. TALP aligns the anchored user nodes, uses the graph’s attentional learning to assist in learning the type perception vector and type fusion vector associated with each user node, and obtains the
n-tuple representation of each user node.
5.3. Implementation Details
The experimental settings of the baselines are consistent with their original configurations. Among them, SVM follows the recommended settings, distinguishes positive and negative samples with a ratio of 0.5, uses a linear kernel as the kernel function, and has a penalty factor set to 50. In the individual feature projector of our proposed EPEM, the link embedding dimension is 128. For all enhancing predictive experts, a batch size of 32 instances is used, and the training epoch is 100. In the trustworthiness investor, the number of iterations is set to 10, and the learning rate is 0.001 for all corresponding models. All methods were implemented in Python 3.7, and we implemented the EPEM in PyTorch 1.10. All experiments were performed on an NVIDIA GeForce RTX 2080 processor.
5.4. Performance Comparison
We employed Accuracy, AUC, and Precision metrics to assess the performance of EPEM, as presented in
Table 2. Our EPEM performs best on three datasets, outperforming the current best models. While predicting unobserved links of distinct types, other comparative methods typically extract shared features across all link types, disregarding the adverse effects of weakening the representation bias caused by type-priori distinctions among various types of links.
The Support Vector Machine (SVM) serves as a traditional machine learning method, often employed for binary classification. However, it frequently struggles to sufficiently capture diverse link representations, leading to suboptimal outcomes. Meanwhile, PME and SLiCE are embedding models, tailored to derive link features and build models for analyzing unobserved link likelihoods. However, these models do not capitalize on the type-priori knowledge acquired from observed links, potentially causing observed link features to unduly impact the representation of unobserved links.
The SEAL employs graph neural networks to create network graphs and learns from local sub-graphs of links. While this retains rich link-related features, the inability to share such features across different link types could constrain its capacity to learn unobserved link characteristics. Similarly, the Heterogeneous Adversarial Network (HAN) leverages the generative adversarial concept to combine different link feature representations. However, when applied to our datasets, the HAN method lacks precise mining of the effect of each type-priori feature representation on unobserved links.
Heterogeneous Network Embedding (HHNE) presents a unified model that addresses the challenge of embedding learning in heterogeneous networks. Although it can handle large-scale networks, it cannot directly predict unobserved links with different link feature representations. Type-Aware Link Prediction (TALP) models the influence of type and fusion information on user node alignment from local and global viewpoints. However, its type-priori knowledge extraction is not as robust as EPEM’s. EPEM enhances unobserved link prediction by effectively incorporating features from diverse observed link types, yielding optimal results across the datasets.
5.5. Parameter Analysis
In this section, we delve into the influence of the
ratio, which signifies the proportion of unobserved links within the testing dataset. Our investigation encompasses a range of
values, and we comprehensively analyze the ensuing outcomes.
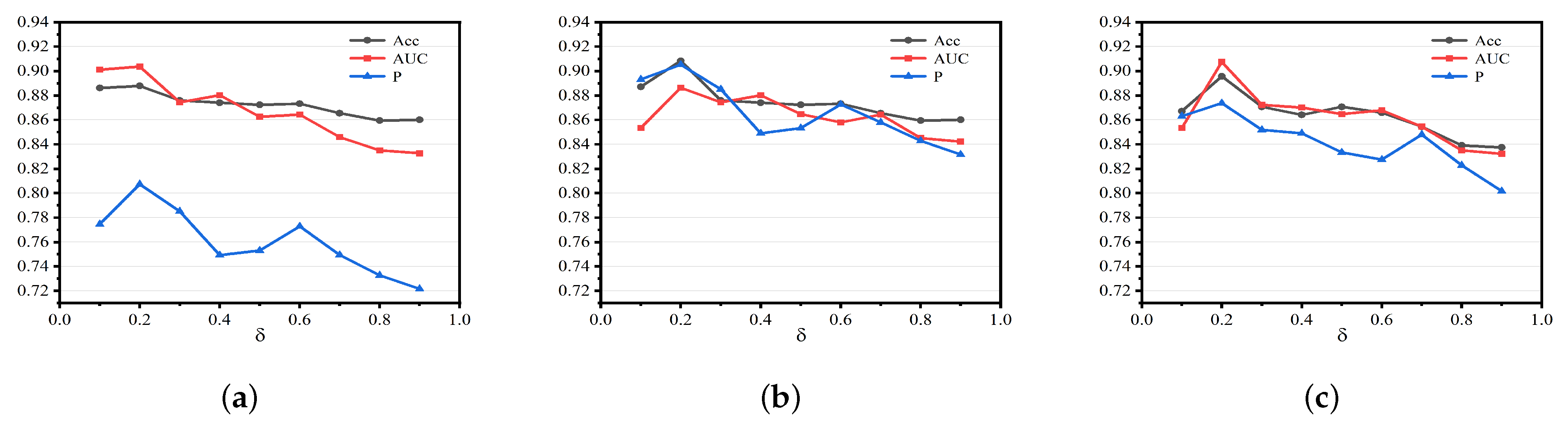
Figure 2 graphically presents EPEM’s performance across Accuracy, AUC, and Precision metrics for the newly introduced type. This evaluation spans three datasets, each featuring varying ratios of labeled links. As illustrated in
Figure 2, EPEM achieves its optimal performance at a
value of 0.2. Notably, our analysis reveals that, although diverse
values impact EPEM’s performance, the model’s efficacy remains largely stable even when the training set includes fewer unobserved links. This resilience can be attributed to EPEM’s competence in assimilating distinctive features of various link types for unobserved link prediction. Overall, these insights underscore EPEM’s adeptness at effectively forecasting unobserved links, even within scenarios characterized by limited training data samples.
5.6. Ablation Experiments
The experimental findings underscore the substantial merits of the proposed EPEM, delineated across three pivotal dimensions: (1) The individual feature projector aims to capture the type-specific features of different types of nodes and links, which can discover the distinguished correlations between different types of nodes and links. (2) The predictive expert constructor furnishes enhancing predictive experts adept at leveraging the learned type-priori features of diverse link types for unobserved link prediction. (3) The trustworthiness investor orchestrates the amalgamation of prediction outputs from enhancing predictive experts based on their respective trustworthiness values.
To affirm the effectiveness of components of the EPEM, we devised three model variants, namely, EPEM-i, EPEM-p and EPEM-t. The EPEM-i model excludes the individual feature projector, the EPEM-p model inputs feature representations of disparate link types to a single enhancing predictive expert to distill their shared characteristics, and the EPEM-t model eschews the trustworthiness investor. Instead, it employs an average trustworthiness distribution for comparison against other methods in our experiments.
In this section, we elucidate the experimental outcomes of the proposed EPEM model and its variants, with results exhibited in
Figure 3. The performance comparison between EPEM-i and EPEM demonstrates the importance of capture the type-specific features of different nodes for obtaining the type-priori representations of them. The empirical observations endorse the efficacy of both the predictive expert constructor and the trustworthiness investor within our model. Even with a singular enhancing predictive expert, EPEM-p consistently outperforms the majority of compared methods, underscoring the predictive expert constructor’s efficacy. Furthermore, the trustworthiness investor’s adeptness in assigning higher trustworthiness to enhancing predictive experts of superior reliability empowers the model to deliver more targeted unobserved link predictions. Therefore, we establish both the individual feature projector, the predictive expert constructors, and the trustworthiness investor as indispensable components of the proposed EPEM model.
5.7. Time Complexity Analysis
EPEM mainly consists of three computing modules: individual feature projector, predictive expert constructor, and trustworthiness investor. In our approach, the most time-consuming part is acquiring the common and individual features of nodes and corresponding links. Compared to some graph neural network-based methods, the time complexity increases. However, when dealing with heterogeneous structural features and generating expert discriminators, the time complexity is more sensitive to the number of experts. It is directly proportional to both the number of links and the number of expert types. In our dataset, the number of experts is the same as the number of link types, so the actual time complexity is not high. The time complexity of individual feature projector is , the time complexity of predictive expert constructor is , and the time complexity of trustworthiness investor is . Therefore, the total time complexity of module aggregation is .
6. Conclusions
Link prediction can present the pre-reconstruction of an unobserved path for special node users, which is an effective means of revealing the hidden structure of social media for network security perception. However, current social networks are information-heterogeneous, with different unique link types and priori information, which brings new challenges. To this end, we propose an Enhancing Predictive Expert Method (EPEM), which consists of three parts: the individual feature projector, predictive expert constructor, and trustworthiness investor. Through the effective integration of these components, EPEM generates more accurate feature representations for distinct link types and utilizes type-priori knowledge to enhance the feature representations of distinct link types, thereby improving the prediction performance of unobserved links. The experimental results show that the EPEM method outperforms the state-of-the-art methods and demonstrates the effectiveness of each component. We hope that continued exploration and improvement will facilitate future research in fusion among multimodal information for node representation with video-based and joint-image features for prediction tasks.


 ,
, 



{kind=link}
{kind=link}
{kind=link}