
Classification of Faults Operation of a Robotic Manipulator Using Symbolic Classifier





Abstract
:1. Introduction
The Description of Research Novelty, Investigation Hypotheses with Overall Scientific Contribution
- Is there a possibility to use the GPSC algorithm to generate SEs for the detection of fault operation of a robotic manipulator with high classification performance?
- Can the proposed algorithm achieve high classification performance on datasets that are balanced using various oversampling methods?
- Is it possible to use the GPSC algorithm with a random selection of hyperparameter values (RSHV) method, validated with 5-fold cross-validation (5FCV) to obtain SEs for the detection of fault operation of a robotic manipulator with high classification accuracy?
- Can the high performance of SEs that consist of a reduced number of input parameters be achieved?
- Investigates the possibility of obtaining a SE for robot manipulator fault operation using GPSC algorithm.
- Investigates the influence of dataset oversampling methods (OMs) on (SEs) classification performance.
- Investigates if using the GPSC algorithm with an RSHV method, validated using a 5FCV process can generate a set of robust SEs with a high detection accuracy of robot manipulator fault operation.
2. Materials and Methods
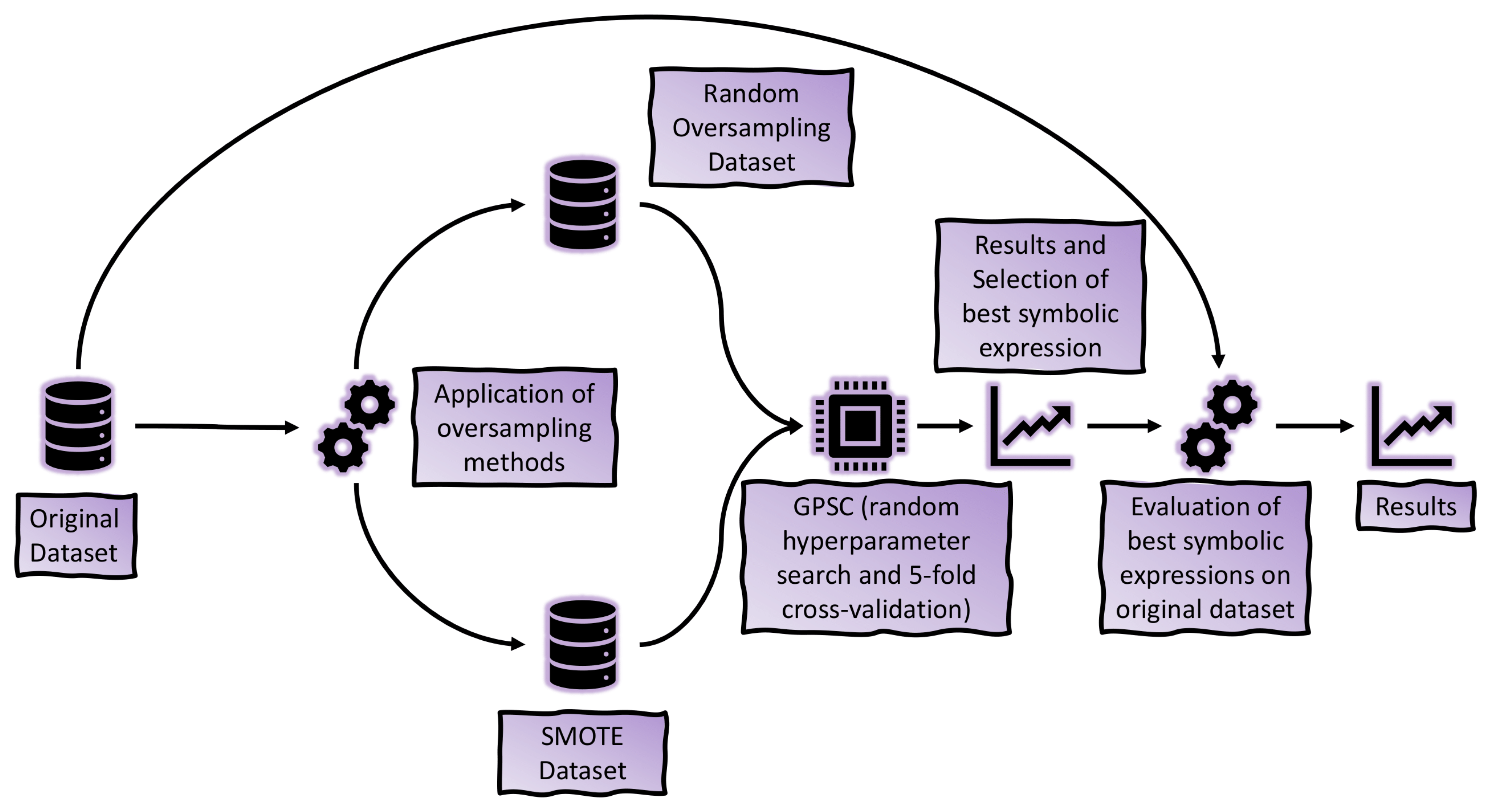
2.1. Research Methodology
2.2. Dataset Description
2.3. Dataset Balancing Methods
2.3.1. Random Oversampling
2.3.2. SMOTE
- Calculate the amount of samples N that have to be generated to obtain 1:1 class distribution;
- Application of iterative process consisting of the following steps:
- -
- A random selection of minority class sample is performed;
- -
- K nearest neighbors (by default K = 5), are searched for;
- -
- The N of K samples are randomly chosen to generate new instances using the interpolation procedure. The difference between the sample under consideration and selected neighbors is used and increased by a factor in the range of , which is appended to the sample. Using this procedure new synthetic samples are created.
2.4. Genetic Programming Symbolic Classifier
- With the obtained expression, model the predicted output class for all training data points;
- Calculate the Sigmoid function of the generated output:
- The log-loss function is calculated with the predicted and real training data points, per:with y representing the real dataset output and is the output of the sigmoid function.
2.5. Training Procedure of the GPSC Algorithm
- Random hyperparameter selection;
- Training the GPSC algorithm with the randomly selected hyperparameters;
- Evaluating obtained SEs and testing if all EMs are above 0.99. If they are above 0.99 the process is terminated, otherwise, the process is repeated.
2.6. GPSC Evaluation Methods
2.6.1. Evaluation Metrics
2.6.2. Evaluation Methodology
2.7. Computational Resources
- Hardware
- -
- Intel i7-4770
- -
- 16 GB DDR3 RAM
- Software
- -
- Python 3.9.13
- *
- imblearn 0.9.1
- *
- scikit.learn 1.2.0
- *
- gplearn 0.4.2
3. Results
3.1. The Results Obtained on Balanced Datasets Using the GPSC Algorithm
3.2. Evaluating Best Models
- Use the variables from the non-augmented dataset inside the expressions to obtain the predicted outputs;
- Apply the sigmoid function Equation (2) on that output, to transform the output of this function to an integer value;
- Compare the obtained values with the original target values from the dataset and obtain evaluation metric values.
4. Discussion
5. Conclusions
- The GPSC algorithm can be applied to obtain the models that detect the faulty operation of the robot manipulator and show high-performance metrics;
- The investigation showed that with the application of OMs, the balance between class samples was reached, and using these types of datasets in GPSC generated high-performing models. So the conclusion is that dataset OMs have some influence on the classification accuracy of obtained results;
- Conducted research demonstrating that by using a balanced dataset with the SMOTE method in the GPSC algorithm with RSHVs and 5FCV, the best SEs in terms of high mean evaluation metric values with low standard deviation can be obtained. When the aforementioned SEs were applied to the initial imbalanced dataset the results of EMs slightly deviate from those obtained on the SMOTE dataset.
- The GPSC algorithm as applied procured a set of the best SEs that can be used to obtain a robust solution;
- This investigation also showed that not all variables are necessary to detect the faulty operation of a robotic manipulator. In this case, a total of 26 input variables are not required which is a great reduction in the experimental measurement of these variables.
- The entire GPSC model does not have to be stored. No matter how long the equation is it still requires lower computational resources than the entire CNN or DNN. The aforementioned CNN or DNN can not be simply transformed into a form of SE.
- The generated SEs with GPSC in some cases do not require all dataset input variables. However, other machine learning methods require all input variables that were used to train them.
- The development of the RSHVs method is a time-consuming process that requires changing each hyperparameter value and running GPSC execution to investigate its influence on the performance of the algorithm;
- The ParsCoef is the most sensitive for tuning. A small change in its value can have a great impact on the GPSC performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Dataset Additional Information
Appendix A.1. Dataset Statistics and GPSC Variable Representation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Variable | Mean | Std | Min | Max | GPSC Variable | Dataset Variable | Mean | Std | Min | Max | GPSC Variable |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | 0.721382 | 0.448804 | 0 | 1 | y | −10.9136 | 70.98129 | −524 | 400 | ||
| 5.429806 | 54.7229 | −254 | 353 | −5.7905 | 66.34445 | −492 | 433 | ||||
| 1.045356 | 44.96064 | −338 | 219 | −4.35421 | 17.17883 | −150 | 64 | ||||
| −37.7624 | 369.2985 | −3617 | 361 | −1.57451 | 47.21401 | −389 | 339 | ||||
| −5.23974 | 117.2394 | −450 | 686 | −2.28942 | 36.62957 | −343 | 190 | ||||
| 7.358531 | 111.824 | −286 | 756 | −62.5702 | 403.8498 | −2792 | 151 | ||||
| −1.77322 | 25.55332 | −137 | 149 | −8.7581 | 70.60608 | −567 | 410 | ||||
| 3.481641 | 48.37184 | −246 | 337 | −7.83369 | 62.94308 | −487 | 437 | ||||
| −0.1987 | 39.63278 | −360 | 205 | −2.77322 | 13.33397 | −83 | 88 | ||||
| −58.1361 | 399.9206 | −3261 | 146 | 0.416847 | 34.27027 | −248 | 338 | ||||
| −7.9892 | 86.15365 | −467 | 605 | −3.30022 | 36.81007 | −353 | 188 | ||||
| −7.49028 | 64.08104 | −271 | 261 | −51.7041 | 340.3173 | −2788 | 89 | ||||
| −1.3067 | 15.80375 | −69 | 135 | −9.11015 | 68.56809 | −563 | 408 | ||||
| 2.598272 | 42.13289 | −247 | 331 | −5.28726 | 62.68289 | −502 | 462 | ||||
| −2.32829 | 42.9849 | −367 | 276 | −3.19654 | 12.09228 | −89 | 97 | ||||
| −61.5961 | 379.1127 | −3281 | 132 | −1.35853 | 65.97879 | −492 | 448 | ||||
| −7.47084 | 85.93531 | −535 | 620 | −7.42765 | 51.87442 | −364 | 185 | ||||
| −2.60691 | 74.5475 | −427 | 476 | −110.994 | 510.0633 | −3234 | 94 | ||||
| −1.33693 | 15.03959 | −66 | 144 | −8.0108 | 78.76645 | −558 | 404 | ||||
| 3.153348 | 39.23666 | −249 | 337 | −7.22678 | 75.12606 | −576 | 454 | ||||
| −1.11447 | 45.40036 | −364 | 354 | −4.47948 | 22.87002 | −199 | 81 | ||||
| −67.635 | 428.3144 | −3292 | 107 | −4.43844 | 88.33604 | −883 | 460 | ||||
| −6.33693 | 84.95088 | −495 | 567 | −8.48812 | 55.64501 | −364 | 187 | ||||
| −3.24406 | 75.36126 | −633 | 464 | −134.477 | 575.1008 | −3451 | 179 | ||||
| −1.76026 | 17.14544 | −88 | 161 | −3.31102 | 105.7364 | −540 | 1016 | ||||
| 0.717063 | 43.43762 | −251 | 351 | −5.80994 | 89.37178 | −568 | 458 | ||||
| 0.667387 | 52.38475 | −368 | 438 | −4.75378 | 26.98989 | −233 | 86 | ||||
| −79.6004 | 479.6485 | −3348 | 107 | −5.47516 | 89.50921 | −851 | 462 | ||||
| −12.0842 | 105.922 | −824 | 536 | −7.26134 | 53.43668 | −352 | 181 | ||||
| −8.77754 | 85.63418 | −725 | 406 | −140.566 | 586.8129 | −3275 | 126 | ||||
| −2.21166 | 19.82233 | −128 | 201 | −7.3067 | 83.26654 | −516 | 400 | ||||
| −0.55508 | 38.56243 | −262 | 324 | −10.2613 | 82.56735 | −567 | 471 | ||||
| −2.2635 | 40.62626 | −320 | 254 | −4.15767 | 19.97507 | −197 | 93 | ||||
| −57.8942 | 417.1217 | −3051 | 418 | −1.66307 | 69.58861 | −480 | 460 | ||||
| −3.56371 | 89.31248 | −672 | 747 | −5.21598 | 48.83071 | −343 | 212 | ||||
| −2.42549 | 67.07047 | −468 | 389 | −133.618 | 559.7376 | −3226 | 92 | ||||
| −1.60259 | 23.169 | −162 | 244 | −7.85745 | 87.05328 | −527 | 531 | ||||
| −2.69762 | 41.83346 | −389 | 338 | −7.89201 | 78.53241 | −600 | 466 | ||||
| −4.25918 | 38.11985 | −382 | 192 | −3.67819 | 20.93429 | −248 | 101 | ||||
| −62.5767 | 440.9198 | −3557 | 126 | −3.2419 | 60.06207 | −497 | 342 | ||||
| −4.06695 | 71.7687 | −547 | 472 | −3.55076 | 49.50523 | −343 | 242 | ||||
| −6.91577 | 63.1772 | −429 | 601 | −104.626 | 483.9425 | −2955 | 95 | ||||
| −2.99352 | 13.10753 | −91 | 83 | −9.93521 | 87.94631 | −599 | 462 | ||||
| −1.47732 | 41.89043 | −262 | 340 | −9.946 | 76.72955 | −646 | 466 | ||||
| −1.99352 | 37.24492 | −331 | 190 | −2.90281 | 14.6582 | −91 | 108 | ||||
| −57.879 | 389.6659 | −2795 | 97 |
Appendix B. The Best SEs
- Division function
- Square root
- Natural logarithm
References
- Polic, M.; Maric, B.; Orsag, M. Soft robotics approach to autonomous plastering. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 482–487. [Google Scholar]
- Bonci, A.; Cen Cheng, P.D.; Indri, M.; Nabissi, G.; Sibona, F. Human-robot perception in industrial environments: A survey. Sensors 2021, 21, 1571. [Google Scholar] [CrossRef] [PubMed]
- Anđelić, N.; Car, Z.; Šercer, M. Neural Network-Based Model for Classification of Faults During Operation of a Robotic Manipulator. Tehnički Vjesn. 2021, 28, 1380–1387. [Google Scholar]
- Mellit, A.; Kalogirou, S. Artificial intelligence and internet of things to improve efficacy of diagnosis and remote sensing of solar photovoltaic systems: Challenges, recommendations and future directions. Renew. Sustain. Energy Rev. 2021, 143, 110889. [Google Scholar] [CrossRef]
- Rafique, F.; Fu, L.; Mai, R. End to end machine learning for fault detection and classification in power transmission lines. Electr. Power Syst. Res. 2021, 199, 107430. [Google Scholar] [CrossRef]
- Theodoropoulos, P.; Spandonidis, C.C.; Giannopoulos, F.; Fassois, S. A Deep Learning-Based Fault Detection Model for Optimization of Shipping Operations and Enhancement of Maritime Safety. Sensors 2021, 21, 5658. [Google Scholar] [CrossRef]
- Dang, H.L.; Kim, J.; Kwak, S.; Choi, S. Series DC arc fault detection using machine learning algorithms. IEEE Access 2021, 9, 133346–133364. [Google Scholar] [CrossRef]
- Belhadi, A.; Djenouri, Y.; Srivastava, G.; Jolfaei, A.; Lin, J.C.W. Privacy reinforcement learning for faults detection in the smart grid. Ad Hoc Netw. 2021, 119, 102541. [Google Scholar] [CrossRef]
- Tayyab, S.M.; Chatterton, S.; Pennacchi, P. Fault detection and severity level identification of spiral bevel gears under different operating conditions using artificial intelligence techniques. Machines 2021, 9, 173. [Google Scholar] [CrossRef]
- Dou, Z.; Sun, Y.; Wu, Z.; Wang, T.; Fan, S.; Zhang, Y. The architecture of mass customization-social Internet of Things system: Current research profile. ISPRS Int. J. Geo-Inf. 2021, 10, 653. [Google Scholar] [CrossRef]
- Zhu, J.; Gong, Z.; Sun, Y.; Dou, Z. Chaotic neural network model for SMISs reliability prediction based on interdependent network SMISs reliability prediction by chaotic neural network. Qual. Reliab. Eng. Int. 2021, 37, 717–742. [Google Scholar] [CrossRef]
- Eski, I.; Erkaya, S.; Savas, S.; Yildirim, S. Fault detection on robot manipulators using artificial neural networks. Robot. Comput.-Integr. Manuf. 2011, 27, 115–123. [Google Scholar] [CrossRef]
- Caccavale, F.; Cilibrizzi, P.; Pierri, F.; Villani, L. Actuators fault diagnosis for robot manipulators with uncertain model. Control Eng. Pract. 2009, 17, 146–157. [Google Scholar] [CrossRef]
- Yan, Z.; Tan, J.; Liang, B.; Liu, H.; Yang, J. Active Fault-Tolerant Control Integrated with Reinforcement Learning Application to Robotic Manipulator. In Proceedings of the 2022 American Control Conference (ACC), Atlanta, GA, USA, 8–10 June 202; pp. 2656–2662.
- Matsuno, T.; Huang, J.; Fukuda, T. Fault detection algorithm for external thread fastening by robotic manipulator using linear support vector machine classifier. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3443–3450. [Google Scholar]
- Piltan, F.; Prosvirin, A.E.; Sohaib, M.; Saldivar, B.; Kim, J.M. An SVM-based neural adaptive variable structure observer for fault diagnosis and fault-tolerant control of a robot manipulator. Appl. Sci. 2020, 10, 1344. [Google Scholar] [CrossRef]
- Khireddine, M.S.; Chafaa, K.; Slimane, N.; Boutarfa, A. Fault diagnosis in robotic manipulators using artificial neural networks and fuzzy logic. In Proceedings of the 2014 World Congress on Computer Applications and Information Systems (WCCAIS), Hammamet, Tunisia, 17–19 January 2014; pp. 1–6. [Google Scholar]
- UCI Machine Learning Repository: Robot Execution Failures Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Robot+Execution+Failures (accessed on 1 December 2022).
- Parisi, L.; RaviChandran, N. Genetic algorithms and unsupervised machine learning for predicting robotic manipulation failures for force-sensitive tasks. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 22–25. [Google Scholar]
- Koohi, T.; Mirzaie, E.; Tadaion, G. Failure prediction using robot execution data. In Proceedings of the 5th Symposium on Advances in Science and Technology, Mashhad, Iran, 12–17 May 2011; pp. 1–7. [Google Scholar]
- Liu, Y.; Wang, X.; Ren, X.; Lyu, F. Deep Convolution Neural Networks for the Classification of Robot Execution Failures. In Proceedings of the 2019 CAA Symposium on Fault Detection, Supervision and Safety for Technical Processes (SAFEPROCESS), Xiamen, China, 5–7 July 2019; pp. 535–540. [Google Scholar]
- Diryag, A.; Mitić, M.; Miljković, Z. Neural networks for prediction of robot failures. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2014, 228, 1444–1458. [Google Scholar] [CrossRef]
- Junior, J.J.A.M.; Pires, M.B.; Vieira, M.E.M.; Okida, S.; Stevan, S.L., Jr. Neural network to failure classification in robotic systems. J. Appl. Instrum. Control 2016, 4, 1–6. [Google Scholar]
- Dash, P.B.; Naik, B.; Nayak, J.; Vimal, S. Deep belief network-based probabilistic generative model for detection of robotic manipulator failure execution. Soft Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Poli, R.; Langdon, W.; Mcphee, N. A Field Guide to Genetic Programming. 2008. Available online: http://www0.cs.ucl.ac.uk/staff/W.Langdon/ftp/papers/poli08_fieldguide.pdf (accessed on 15 December 2022).
- Lopes, L.S.; Camarinha-Matos, L.M. Feature transformation strategies for a robot learning problem. In Feature Extraction, Construction and Selection; Springer: Berlin/Heidelberg, Germany, 1998; pp. 375–391. [Google Scholar]
- Camarinha-Matos, L.M.; Lopes, L.S.; Barata, J. Integration and learning in supervision of flexible assembly systems. IEEE Trans. Robot. Autom. 1996, 12, 202–219. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Car, Z. The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data. Sensors 2022, 23, 169. [Google Scholar] [CrossRef]
- Anđelić, N.; Lorencin, I.; Baressi Šegota, S.; Car, Z. The Development of Symbolic Expressions for the Detection of Hepatitis C Patients and the Disease Progression from Blood Parameters Using Genetic Programming-Symbolic Classification Algorithm. Appl. Sci. 2023, 13, 574. [Google Scholar] [CrossRef]
- Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Glučina, M. Detection of Malicious Websites Using Symbolic Classifier. Future Internet 2022, 14, 358. [Google Scholar] [CrossRef]
- Sturm, B.L. Classification accuracy is not enough. J. Intell. Inf. Syst. 2013, 41, 371–406. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R. Area under the receiver operating characteristic curve. In Applied Logistic Regression, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013; pp. 173–182. [Google Scholar]
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [Green Version]





| Reference | Methods | Results |
|---|---|---|
| [19] | GA-SOM, SOM | |
| [20] | Naive Bayes, Boosted Naive Bayes, Bagged Naive Bayes, SVM, Boosted SVM, Bagged SVM, Decision Table (DT), Boosted DT, Bagged DT, Decision Tree (DTr), Boosted (DTr), Bagged DTr, Plurality Voting, Stacking Meta Decision Trees, Stacking Ordinary Decision Trees | |
| [21] | DCNN | |
| [22] | NN with Bayesian regularization | |
| [23] | MLP | |
| [24] | DBN, C-support vector classifier, logistic regression, decision tree classifier, K-Nearest Neighbor Classifier, MLP, AdaBoost Classifier, Random Forrest Classifier, Bagging Classifier, Voting Classifier | |
| [3] | SNN |
| Dataset Balancing Method Name | Number of Minority Class Samples | Number of Majority Class Samples | Total Number of Samples |
|---|---|---|---|
| Random Oversampling | 334 | 334 | 668 |
| SMOTE | 334 | 334 | 668 |
| GPSC Hyperparameter | Range |
|---|---|
| PopSize | 100–1000 |
| NumGens | 100–300 |
| TourSize | 100–300 |
| InitDepth | 3–12 |
| Cross | 0.001–1 |
| SubMute | 0.001–1 |
| HoistMute | 0.001–1 |
| PointMute | 0.001-1 |
| StopCrit | – |
| MaxSamp | 0.99–1 |
| ConstRange | −10,000–10,000 |
| ParsCoef | – |
| Dataset Variation | GPSC Hyperparameters |
|---|---|
| Random Oversampling | 172, 293, 161, (4, 7), 0.1, 0.49, 0.36, 0.032, , 0.99, (−280.17, 5256.88), |
| SMOTE | 850, 227, 270, (6, 11), 0.39, 0.13, 0.23, 0.23, , 0.99, (−7689.72, 8984.85), |
| Dataset Type | Average CPU Time per Simulation [min] | Length of SEs | |||||
|---|---|---|---|---|---|---|---|
| Random Oversampling | 100 | 729/368/78/119/159 | |||||
| SMOTE | 544/430/354/387/334 |
| Evaluation Metric | Mean Value | Standard Deviation |
|---|---|---|
| 0.9978 | ||
| 0.998 | ||
| 1.0 | 0 | |
| 0.997 | ||
| 0.9985 |
| Reference | Methods | Results |
|---|---|---|
| [19] | GA-SOM, SOM | |
| [20] | Naive Bayes, Boosted Naive Bayes, Bagged Naive Bayes, SVM, Boosted SVM, Bagged SVM, Decision Table (DT), Boosted DT, Bagged DT, Decision Tree (DTr), Boosted (DTr), Bagged DTr, Plurality Voting, Stacking Meta Decision Trees, Stacking Ordinary Decision Trees | |
| [21] | DCNN | |
| [22] | NN with Bayesian regularization | |
| [23] | MLP | |
| [24] | DBN, C-support vector classifier, logistic regression, decision tree classifier, K-Nearest Neighbor Classifier, MLP, AdaBoost Classifier, Random Forrest Classifier, Bagging Classifier, Voting Classifier | |
| [3] | SNN | |
| This paper | GPSC | 99.78%, 0.998%, 100%, 99.7% 99.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anđelić, N.; Baressi Šegota, S.; Glučina, M.; Lorencin, I. Classification of Faults Operation of a Robotic Manipulator Using Symbolic Classifier. Appl. Sci. 2023, 13, 1962. https://doi.org/10.3390/app13031962
Anđelić N, Baressi Šegota S, Glučina M, Lorencin I. Classification of Faults Operation of a Robotic Manipulator Using Symbolic Classifier. Applied Sciences. 2023; 13(3):1962. https://doi.org/10.3390/app13031962
Chicago/Turabian StyleAnđelić, Nikola, Sandi Baressi Šegota, Matko Glučina, and Ivan Lorencin. 2023. "Classification of Faults Operation of a Robotic Manipulator Using Symbolic Classifier" Applied Sciences 13, no. 3: 1962. https://doi.org/10.3390/app13031962
APA StyleAnđelić, N., Baressi Šegota, S., Glučina, M., & Lorencin, I. (2023). Classification of Faults Operation of a Robotic Manipulator Using Symbolic Classifier. Applied Sciences, 13(3), 1962. https://doi.org/10.3390/app13031962