1. Introduction
Tunnel technology offers numerous benefits, such as breaking firewall restrictions, forcing data to a specified address, hiding private network addresses, providing secure encrypted channels, etc. Tunnel technology is widely used [
1], with applications including proxy services, remote access, intrusion control, traffic stealing, etc.
By installing tunnel clients, users can indirectly forward data packets by bypassing IP blocks by using the proxy service, which mimics socks5. Remote access means building a negotiatory channel between the private network and the company network and then accessing secret data or applications. Intrusion control mainly includes establishing C&C communication [
2], stealing private data, realizing long-term control, guarding, etc. Among the specific methods used are malicious Trojan, Botnet, ransomware, and advanced persistent threat (APT) [
3] techniques, etc. In traffic stealing, web traffic is encapsulated in free DNS [
4], ICMP, and other data packets to deceive the network billing system. Tunnel technology is advancing, its threats are increasing with time, and the identification and classification of tunnel traffic in a network are especially critical.
In order to detect and classify tunnel traffic, we must find discriminative features between normal traffic and tunnel traffic. Recently, in spite of dramatic progress having been made in detecting encrypted traffic, the detection of tunnel remains difficult (or is inaccurate). Actually, tunnel traffic is often encrypted, and so transferring the source problem into the target problem is beneficial. Due to its concealment and camouflage, which are inherently unique, it poses the following challenges to current researchers. These issues are different from those of encrypted traffic detection [
5].
We must identify whether it is tunnel traffic. A network communication protocol is easy to identify; however, identifying whether it is encapsulated as a tunneling protocol is much more difficult. Additionally, most traffic is encrypted, and the encryption algorithms obscure plaintext features, thereby reducing the randomness of the original message to a great extent. Furthermore, some software can mask tunnel traffic characteristics as normal traffic characteristics by morphing and padding packets, which makes identification more difficult.
We must identify a passenger protocol for the tunnel. To avoid censorship, tunnel traffic may be mixed between multiple passenger protocols, such as FTP-DNS, DNS-HTTPS, TELNET-HTTP, and SMTP-TLS. To identify each passenger protocol in the specific tunnel, it is necessary to have an accurate command of multilayer protocols so that lower traffic heterogeneity within the same tunnel renders the tasks more complex.
We must identify applications and behavior in tunnel traffic. Further, there are several specific granularities used to identify different applications and their behaviors in tunnel techniques. These include ongoing applications, service benign/malicious behaviors of the same application, webpages, and content parameters related to the same webpage, etc. A tunnel’s traffic is extremely homogeneous, and the application traffic in that tunnel is the same quintuple, so determining its beginning and ending times is difficult, and tunnel noise also makes fine-grained identification difficult.
To clarify the search status of solving the problems and challenges mentioned above, we have made two contributions.
The first thing we have done is focus on three challenges of tunnel traffic detection from the perspective of protocol classification within the TCP/IP protocol stack, which is different from the closely related topics of encrypted traffic detection in detail. A new method of tunnel traffic identification and classification is presented based on the combination of traditional and machine learning detection methods within seven protocols: HTTP, HTTPS, DNS, SSH, TCP, ICMP and IPSec. We use the thesis database (scopus database, occasionally assisted by web of science) and use a certain keyword (such as HTTP/HTTPS/DNS/TCP/ICMP/IPSec tunnel traffic detection, traffic detection, etc.) to search and determine a large range of initial related literature review papers (LRPs) [
6]. The simplest way is to filter the paper’ date (we have been looking for papers for nearly 20 years), publishing platform, field and so on with the filter that comes with the database, including journal article and conference paper. By browsing abstracts, keywords and the objective statements of pieces of literature, we can determine their relevance. Then, the results of rough reading, based on inductive coding and of intensive reading, based on co-occurrence analysis, are presented. The papers are selected based on three main criteria: whether they (i) provide new techniques or ideas on tunnel detection, (ii) i they have a high degree of completion and reproducibility, and (iii) if they have an ability to solve three challenges above.
Second, five evaluation indices are used to evaluate the three typical tunnel detection methods from over the past ten years using AHP (analytical hierarchy process). Additionally, we also conclude by exploring and analyzing the direction of tunnel identification and detection.
Figure 1 summarizes our work.
Figure 1.
Our review of tunnel detection process.
Figure 1.
Our review of tunnel detection process.
We first introduce the broad and narrow concepts of tunnel technology. We then arrange them as protocols and mainstream application frameworks, including anonymous networks, proxies, and VPN technology.
1.1. Broad & Narrow Tunnel
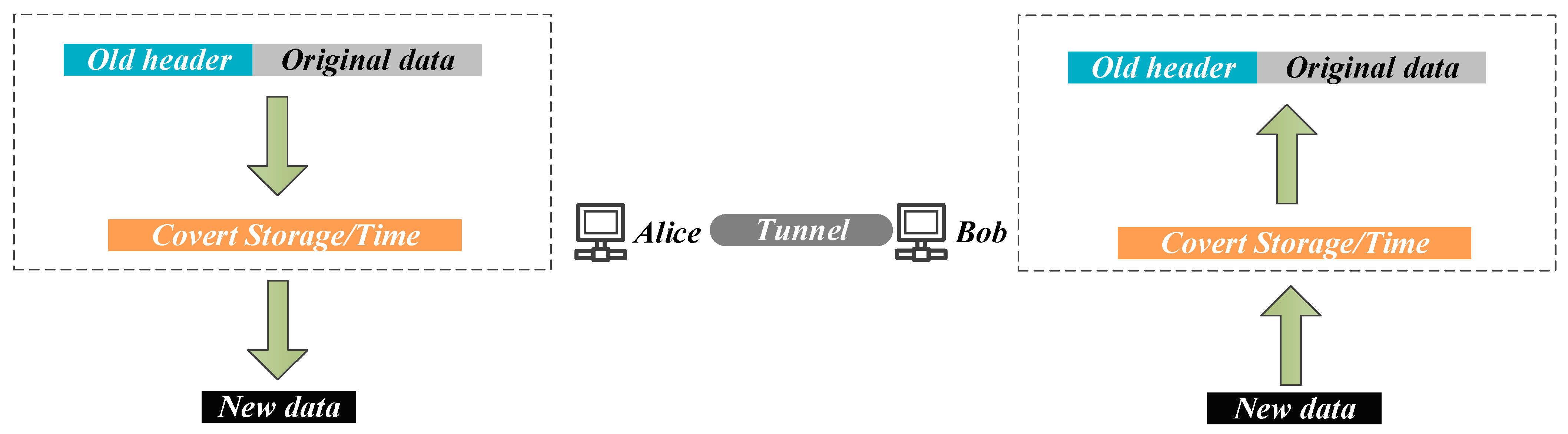
Broad Tunnel. Simmons [
7] proposed a general tunnel as a classic prisoner communication model in 1983 and described a network tunnel in detail. As shown in
Figure 2, the OSI computer network model is based on a classic prisoner communication model. In this model, Alice and Bob communicate through two networked machines. Despite the fact that their communication data appears to be sent through an open communication channel, they can create a private tunnel that is only visible to them. This generalized tunnel is formally defined as
. For any kind of tunnel
, there is
.
represents the hidden tunnel of network storage. As the most commonly used tunnel, this tunnel is also the tunnel most discussed in our paper because it changes the header fields and payloads of various network protocols to hide information. Both communication parties will only deal with keywords and optional parameters with this tunnel, specified ahead of time, and any keywords or optional parameters not specified in the protocol will be automatically discarded. It is also beneficial for covert communication to hide more information in the message payload.
is a network time covert tunnel which encodes covert information based on a control time interval. For example, data packets’ delivery times are directly changed, but data packet timestamps are changed indirectly. In this tunnel, data packet arrival time depends on network stability. As time jitter, packet disorder, and loss often lead to decoding failure, we are not focusing on these tunnels.
Narrow Tunnel. In a narrow tunnel, the passenger protocol is encapsulated in a payload and transmitted to the channel. This is purely responsible for the protocol encapsulation and decapsulation of data packets like the edge of the network topology. Our paper formally defines this narrow tunnel as
in
Figure 3. Moreover, the encryption of
is more prevalent.
1.2. Classification
1.2.1. Encapsulation Protocol
Using the five-layer model of the TCP/IP protocol stack in
Table 1, we propose a method of dividing tunnel traffic from protocol classification at each layer.
1.2.2. Tunnel Application Frameworks
Anonymous Networks
An anonymous network protects the privacy of users’ communication in an open network setting. Due to its enhanced security, deployment, availability, and flexibility, Tor, a typical application of a P2P [
8,
9] structure, is widely used by anonymous users. In this scheme, data packets are forwarded at the entry node and bundled into nested layers of encrypted packets of similar size at the entry node. After routing and decrypting these data packets, the data are sent to a destination node.
Proxy
Proxy is a typical representative of , transferring data between client and server. Client requests are sent to proxy servers, which access the targeted website instead of the client, load its content, and then transmit the loaded content back to the client. As a result of Chrome browser’s data compression proxy technology, web page loading speeds can be increased, which reduces bandwidth consumption.
VPN
In VPN, the initial plaintext data (including the data to be transmitted, source/destination IP) are encrypted by the VPN client and then a signature is attached. To re-package the data packet, a new data header is added (including the new IP address, the VPN device’s security information, and some initialization parameters) and it is sent via a “specific path” over the public network. When data arrives at VPN server, they are unsealed and decrypted after checking signature.
Relationships
Tor and VPN differ in how they guarantee data anonymity. As a result of the fixed IP address between the VPN client and the VPN server during VPN communication, both client and server can tell which real IP address is sending which data packet to what destination address. However, Tor does not rely on a single server. Rather, it chooses a random relay node and it updates more frequently than VPN. Thus, all nodes in the path cannot obtain the information completely. As a result, Tor can be considered a distributed VPN network if only its start and exit nodes are considered.
Whether to secure data transmission is the difference between a proxy and a VPN. The final effect of using a user VPN or proxy server is the same, i.e., hiding one’s real IP from the website or server of interest. Proxy servers are suitable for users who wish to access websites blocked by their region but do not want to conceal their operations on the Internet. When users need to visit a website for a long time or perform sensitive operations, such as sending personal information over open Wi-Fi, VPNs are typically used.
2. Taxonomy
From a traffic fingerprint perspective, plaintext tunnel traffic may contain a specific string. Statistically, even encrypted tunnel traffic has different temporal and spatial characteristics than normal traffic. As shown in
Table 2, traditional methods of tunnel traffic detection and current popular methods based on machine learning are summarized in this section.
2.1. Traditional Detection
As tunnel traffic becomes increasingly difficult to identify using the port [
10] alone as the criterion, fingerprint-based methods as well as behavior feature (statistical feature) methods will become more popular for unencrypted tunnel traffic identification [
11].
In a data packet, fingerprints are non-random features, such as keywords found in DNS request fields QNAME and RDATA, as well as headers like Host, Connection, and Content-type in HTTP requests. A variety of fingerprint-based detection technologies are available, including threshold matching and MD5 matching. In these simple judgment methods, we can quickly and accurately identify when the database capacity is adequate, otherwise, we are highly likely to make mistakes. In text-like data analysis, N-gram word frequency models (also known as unigrams and bigrams) and implicit Markov models (HMMs) are important. Combined with the Markov property, we can identify tunnel traffic by predicting the value of normal traffic based on a specific string in a fixed field.
As a representation method, behavior features are detected by using the data element information of statistical data packets/streams (hereinafter called statistical features). Statistics (average, maximum, minimum, variance, etc.) are used in probability statistics, statistical distributions (Poisson distribution, Zipf distribution, etc.), and cluster analyses. An abnormal user behavior model can be observed from data analysis by comparing its threshold with a normal behavior model.
2.2. Machine Learning Detection
Since tunnel technology is densely cultured and complex, fingerprint-based methods have required maintaining a huge database with limited patterns, and statistical feature methods have not been able to deal with traffic camouflage dynamically in recent years. Tunnel traffic detection has gained new vitality with the advent of machine learning (ML).
There are three types of ML: supervised, unsupervised, and semi-supervised. In supervised learning, accuracy is measured by constantly comparing prediction results to training data. Supervised learning includes decision trees such as C4.5, RF (random forest), SVM (support vector machine), etc. Additionally, its training process requires a great deal of manual labels and selecting features is highly dependent on expert knowledge. Unsupervised learning, also known as clustering, distinguishes between categories based on unlabeled data in large datasets. In reality, this method is simpler, but its accuracy is not high due to the large amount of unlabeled raw tunnel traffic in real networks. Moreover, semi-supervised learning, which combines advantages from both supervised and unsupervised learning, is more accurate than unsupervised learning, and manual involvement is reduced to some extent.
Since deep neural networks do not extract features in the training process, which can automatically learn high-dimensional abstract data (called E2E), they are extremely popular for the classification of tunnel traffic on large scales. RNN (recurrent neural network), LSTM (short- and long-term memory networks), etc., can handle the temporal features of tunnel traffic well, CNN (convolutional neural networks) can handle the spatial features of tunnel traffic well, and the GAN (generative adversarial network) can be used to alleviate class imbalance in datasets. A deeper and more complex network model structure also means that parameter adjustment is more time-consuming.
Table 2.
Traditional and ML models of tunnel detection.
Table 2.
Traditional and ML models of tunnel detection.
| Traditional | ML |
|---|
| Fingerprint | Statistic | Supervised | Unsupervised | Semi-Supervised |
|---|
| ■Match [12,13,14,15,16,17,18,19,20,21,22,23,24] | ■Markov [25,26] | ■SVM [16,21,27,28,29,30,31,32,33] | ■CAE [34] | ■VAE [35] |
| ■N-gram [28,36,37] | ■MaMPF [38] | ■Decision Tree (C4.5/5.0) [29,32,33,39,40,41,42,43] | ■OLDBSC [44] | ■Bi-GRU [35] |
| ■MD5[24] | ■KNN [40,43,45,46] | ■RF [29,37,43,47,48] | | |
| ■Degree Distribution [49] | ■Naïve Bayes [17,27,32,48] | ■LSTM [50,51] | | |
| | ■MNB [52] | ■Bi-LSTM [53,54] | | |
| | ■k-means [55,56,57] | ■CNN [34,50,58,59] | | |
| | ■TF-IDF [60] | ■Linear Regression [29] | | |
| | ■GP [42] | ■MLP [51] | | |
| | | ■AdaBoost [42,61,62] | | |
| | | ■RIPPER [61] | | |
| | | ■RBFN [43,57] | | |
3. Encapsulation Protocol
In this section, tunnel traffic detection methods are systematically classified to focus on the above three challenges according to the five-layer model of the TCP/IP protocol stack, including HTTP, HTTPS, DNS, SSH, TCP, ICMP and IPSec.
3.1. HTTP
The existing forms of include a URL-based HTTP tunnel and an HTTP header field-based HTTP tunnel. The optional segments of HTTP messages can be altered and confused. For example, headers such as Host, Connection, Content-Type, etc., in HTTP requests can be filled out and confused. Attackers use the referer field to construct covert tunnels since it has a fixed function in normal communication. Common tunnel tools include Neo-reGeorg, Frp, HTTPTunnel, etc.
3.1.1. Traditional Detection
The goal of most papers (in
Table 3) is to determine whether the traffic is tunnel traffic or not, and so signature-based fingerprint detection is of particular importance among them. For the detection of suspicious strings in the payload, Dharmapurikar [
12] generated hash values for strings using the same hash function. In order to identify tunnel traffic, it must maintain a large database and have a high false negative rate. The model can detect 10,000 predefined fine strings, but has a high false negative rate. In Wang et al. [
36], two innovations were presented: Wang’s N-gram(N = 1) word frequency model calculates the average frequency of ASCII characters as one of tunnel traffic’s characteristics. First, the model is made more robust by combining it with Mahalanobis to realize unsupervised learning. Second, “Z-String” derived from byte distribution is used as a signature to represent payload, which can be stored quickly in the real-time distributed detection system. Almost a 100% detection rate and about a 0.1% false alarm rate are achieved for HTTP tunnel traffic in DARPA’99 [
63].
It is also common for tunnel traffic to be characterized by detecting the header of HTTP packets. If the user agent is filled, or if they are filled by an unknown browser, this method can also be used. Using Bortolameotti’s [
13] model, top-level and second-level domain names, constant header fields, and language fields in Host are extracted, and a module is added for dynamically updating the fingerprint database, making it more flexible. During private datasets, the model achieves a false alarm rate of 0.9%, with a detection accuracy of 97.7% on average.
As well as identifying tunnel traffic, statistical flow characteristics also describe how tunnel traffic is classified from applications and behaviors. The temporal and spatial features of a data stream are often determined by the packet size and the inter-arrival time (IAT) between successive packets. Besides these factors, various pieces of statistical information on packet length and packet intervals, such as the estimation of a round-trip time, the size of the TCP segment, and the total number of retransmissions, and simple statistical knowledge such as average, median, maximum, minimum and variance are used by researchers to create models. To determine whether traffic is tunnel traffic, Li [
64] utilized hierarchical clustering technology and a scoring mechanism model to establish a normal behavior clustering model by comparing the characteristics of normal HTTP traffic, including packet/stream time intervals. Despite being able to achieve an accuracy of more than 93.9%, this model is heavily influenced by the long HTTP traffic that transmits large files. As a measure of the randomness of data, the entropy criterion is often used to distinguish tunnel traffic, and the entropy value in tunnel traffic differs from that in normal traffic. Nasseralfoghara [
14] used the entropy of message exchange traffic. The HTTP protocol request text should contain the address of the requested page, the required method, and the parameters for that method. If its entropy value exceeds its predetermined threshold, it is classified as HTTP tunnel traffic. However, if the unintentional increase in noise changes the entropy, it incorrectly classifies the traffic as HTTP tunnel traffic.
The outbound bandwidth usage in tunnel traffic will differ from normal HTTP requests. In addition to counting outbound bandwidth usage, long streams account for a substantial share of tunnel traffic, which is important. Piraisoody [
27] introduced the concept of “occupancy rate” as a key element in the classification process, and proposed the definition of “stream groups”. HTTP tunnel applications such as audio, video, and file transfer software are classified based on parameters such as download rate, bytes per stream, bytes per packet, and “occupancy rate,” with a high accuracy rate of at least 70% in private datasets.
3.1.2. Machine Learning
To avoid the problem that the exponential growth of feature dimensions makes the accuracy of the N-gram model lower when n > 2, Perdisci [
28] used a feature clustering algorithm to reduce the dimensions in different feature spaces and multiple single-class SVM classifiers to vote in different feature spaces, making the model extremely accurate at detecting HTTP tunnel traffic. Thus, the author achieved an FPR of 10
−5 in DARPA’99 data [
63]. The URL and payload string were extracted using a deep neural network model built with Bi-LSTM (bi-directional long and short-term memory). In private datasets, experiments [
53] have shown that the accuracy of identifying tunnel traffic can reach 90%. With CNN and LSTM, Wong [
50] developed a deep learning model for detecting URL-based HTTP tunnels. In privately balanced datasets, the best model averages 95% accuracy. However, the model it cannot handle seriously unbalanced datasets.
He [
54] combined classical classifiers with bagging, boosting, etc., with classical classifiers such as C4.5. The packet payload size, variance, packet count, data stream length, and IAT of adjacent packets can be used to identify whether the traffic is HTTP tunnel traffic.
It is also possible to classify passenger protocols in tunnel traffic using detection methods based on ML. Based on private datasets, Ding’s [
39] method can identify tunnel traffic and distinguish SMTP-HTTP and P2P-HTTP passenger protocols with 95% accuracy. What is remarkable is that the model is 100% accurate at identifying gray pigeon traffic. According to Wang [
16], it is necessary to analyze the second-order statistical correlations between consecutive packets, including the packet distribution difference in HTTP sessions and the entropy in N-RPP and N-RMI distances. An SVM classifier can distinguish tunnel traffic from non-tunnel traffic and identify FTP-HTTP, SMTP-HTTP, and POP3-HTTP passenger protocols. HTTP tunnel traffic is recognized with an average accuracy of 82.5% on private datasets.
Table 3.
Summary of HTTP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 3.
Summary of HTTP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Statistic | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Dharmapurikar [12] | 2003 | Private | T | √ | | √ | | √ | |
Payload
|
Strings
|
Match
|
| Wang [36] | 2004 | Public | T | √ | | | √ | √ | |
Payload
|
Strings
|
N-gram + Mahalanobis
|
| Perdisci [28] | 2009 | Public | ML | √ | | | √ | √ | |
Payload
|
Strings
|
N-gram + SVM
|
| Ding [39] | 2011 | Private | T | | √ | √ | √ | √ | √ |
Payload
| Size + Duration | C4.5 |
| Wang [16] | 2013 | Private | ML | | √ | √ | | √ | √ |
Payload
| Size + Duration |
Match + SVM
|
| Piraisoody [27] | 2013 | Private | T | | √ | √ | √ | √ | √ |
Payload
| Size + Duration + occupancy | Naïve Bayes + SVM |
| Li [64] | 2014 | Private | T | | √ | √ | √ | √ | √ |
Payload
| Size + Duration | Hierarchical Clustering + Scoring Mechanism |
| Bortolameotti [13] | 2017 | Private | T | √ | | | √ | √ | |
Head
|
Host + Language + User-Agent
|
Match
|
| Yu [53] | 2018 | Private | ML | | √ | √ | | | √ |
Payload
|
Strings
| Bi-LSTM |
| He [54] | 2019 | Private | ML | | √ | √ | | | √ |
Payload
| Duration | Bi-LSTM |
| Wong [50] | 2019 | Private | ML | | √ | √ | | | √ |
Field
| URL | CNN + LSTM |
| Nasseralfoghara [14] | 2020 | Private | T | | √ | | √ | √ | |
Head
|
Request Method + URL
|
Match
|
3.2. HTTPS
HTTPS protocol adds an SSL/TLS layer between the transport layer and HTTP protocol, supporting encryption, authentication and integrity checking, and which is mainly used to realize secure HTTP data transmission. As opposed to HTTP tunnel traffic detection, HTTPS traffic is encrypted, and the hidden message content makes fixed string matches and character statistics ineffective. This section emphasizes the spatial–temporal characteristics of plaintext packets as well as their interaction during SSL/TLS handshakes. There are two tunnel modes of HTTPS, the first one is , and the second one is VPN, i.e., a typical HTTPS tunnel, which is an encryption . We also separately summarize the methods of ML used to detect VPN traffic. Tools that can be used to build HTTPS tunnels include abptts, Shadowsocks Obfs, reGeorg, etc.
3.2.1. Traditional Detection
For
, an SSL/TLS handshake fingerprint (including supported cipher suites, TLS extensions, etc.) is mostly focused on detecting tunnel traffic in HTTP header (as shown in
Table 4). According to Durumeric et al. [
15], certificate authority-based detection can be improved by examining the trust relationships between root/intermediate authorities and leaf certificates extracted by the Web server.
Besides identifying tunnel traffic, classifying the applications in tunnel based on features such as the length of certificate packets, IAT, and an SSL/TLS handshake session is popular. In Herrmann’s [
52] model, traffic features were only determined by the normalized frequency distribution of IP packet sizes in the stream using Multinomial Naïve Bayes (MNB). As a result of TF-IDF transformation, HTTPS tunnel traffic can be identified with 97% accuracy in private datasets. Korczyński [
25] labeled SSL/TLS handshake state, established first-order homogeneous Markov fingerprints and judged 12 applications within HTTPS tunnel traffic based on their convergence toward the normal traffic state. In private datasets, the accuracy rate is above 97%, but two disadvantages occur with this method. First, IP can only be resolved into a domain name model through DNS, and second, the efficiency and accuracy of this method will decrease as packet numbers increase.
In order to increase the diversity and multi-attribute quality of traffic characteristics, Sun [
17] used a hybrid method in the first byte of handshake-based messages to identify HTTPS tunnel traffic. With fine granularity, Liu [
38] proposed using Markov Probability Fingerprints (MaMPF) to identify tunnel traffic applications. MaMPF can calculate the power law distribution and relative probability of all 18 applications modeling for each application in order to avoid the overfitting caused by excessive packet length. MaMPF achieves 96.4% TPR and 0.2% FPR in private datasets.
3.2.2. Machine Learning
As part of the detection methods, ML includes not only detecting tunnel traffic, but also identifying the application involved. Specifically, Draper-Gil [
40] and Anderson [
29] examined spatio-temporal characteristics, including in/out bytes, packet sizes, packet numbers, packet length, time series, distribution of bytes, etc.
It has always been important to monitor VPN traffic under HTTPS tunnels due to its role as an indicator of HTTPS tunnel traffic. Draper-Gil [
40] used only time-related features along with C4.5 and KNN to achieve an accuracy rate of over 80% in the ISCXVPN2016 public datasets [
65]. Guo [
34] proposed two models based on deep learning: CAE (convolutional automatic coding) and CNN, which separated traffic into VPN and non-VPN traffic, and further identified VPN traffic generated by six different applications. By using the unsupervised algorithm of CAE, they can extract the hidden layer features from the traffic samples to generate conversation images. CNN excels at extracting two-dimensional local features. The CAE-based model has the best recognition effect in the selected datasets, with an overall recognition accuracy rate of 98.77%; CNN is the best for all six types of application traffic. In ISCXVPN2016, Parchekani [
51] classified VPN and non-VPN traffic based on E2E with MLP and LSTM, achieving an overall recognition accuracy rate of 92.92%.
Table 4.
Summary of HTTPS tunnel detection. Summary of HTTPS tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 4.
Summary of HTTPS tunnel detection. Summary of HTTPS tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Behavior | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Herrmann [52] | 2009 | Private | T | | √ | √ | | √ | |
Payload
| Size | MNB |
| Sun [17] | 2010 | Private | T | √ | √ | √ | | √ | √ |
Handshake + Payload
| Size + Duration |
Match + Bayes
|
| Durumeric [15] | 2013 | Private | T | √ | | √ | | √ | | Handshake | Entities |
Match
|
| Korczyński [25] | 2014 | Public | T | √ | | √ | | √ | | Handshake | ClientHello |
Markov
|
| Draper-Gil [40] | 2016 | Public | ML | | √ | √ | | | √ |
Payload
| Duration | C4.5 + KNN |
| Anderson [29] | 2017 | Private | ML | | √ | | √ | √ | |
Payload
| Size + Duration | Linear Regression + L1/L2-logistic regression + RF + SVM + Decision Tree + Multi-layer Perceptron |
| Liu [38] | 2018 | Private | T | | √ | √ | | | √ |
Payload
| Duration + Order |
MaMPF
|
| Guo [34] | 2020 | Public | ML | | √ | √ | √ | √ | |
Payload
| Size + Duration | CAE + CNN |
| Parchekani [51] | 2020 | Public | ML | | √ | √ | √ | √ | √ | Payload | Size + Duration | MLP + LSTM |
3.3. DNS
In a DNS tunnel, the DNS server checks its database for the address to be resolved when it receives a DNS request. If no records are found in the database, the server sends the request to the specified domain. According to known analysis of the DNS protocol, the QNAME field in the query area and the RDATA field in the response area are the highest frequency areas where features are embedded. In terms of analyzing from DNS traffic, extracting resource records such as TXT, A, AAAA, and MX and observing the access count of resource records are common methods.
The parser depends on the number of resource records specified in the header to determine the parsed data, and the last record is considered to have reached the end. As a result, DNS packets can be tipped with any amount of data, and RawUDP is where the information is embedded at high frequency. The statistical distribution of DNS tunnel traffic is very different from that of normal domain. The former obeys random distribution, while the latter obeys Zipf distribution. A number of studies have been conducted on detecting DNS tunnels by analyzing the statistical information in DNS packets, such as domain name length and entropy. Tools such as NSTX, DNSCat, and Iodine have been used to detect DNS tunnels.
3.3.1. Traditional Detection
In traditional detection methods (in
Table 5), most researchers focus on whether it is tunnel traffic or not. Because most DNS tunnel detection data are text-like, word frequency analysis is a good starting point. The statistical distributions of domain names in data packets were analyzed by Burghouwt [
49] as features for detecting and identifying DNS tunnel traffic. N-gram (N generally takes 1 or 2) word frequency modeling is used to identify tunnel traffic. The abnormal degree distribution of the visited domain in the message was detected by Burghouwt [
49] without requiring any statistical information about message content and traffic. Using graph theory, the author calculated the degree distribution of domains based on the number of computers connected to different domains over a specified time period. Abnormal domains can be distinguished from normal domains to identify DNS tunnels, and their FPR is 0.073% in private datasets.
There has been a significant interest in detecting DNS tunnel traffic based on the time and space statistical characteristics of packets/streams, such as the number of packets/streams, the number of bytes, and the duration of streams. These features have been used by Marchal [
55]. The average TTL value of domain records, total number of domain name requests during the observation period, request ratio in each time period, whether the domain name is blacklisted, and other characteristics were also extracted by Marchal [
55].
There is also a high degree of entropy detection in DNS tunnel traffic. Meanwhile, Karasaridis [
18] determined whether the packet size distribution was met with cross entropy, and then defined a distance function to measure entropy, which controlled the threshold range to identify DNS tunnel traffic effectively.
3.3.2. Machine Learning
Most of machine learning detection has been conducted to detect whether traffic is tunnel traffic, while Wang [
48] introduced eight features to analyze five kinds of DNS tunnel behaviors. Bilge [
41] has integrated the above statistical features. To describe different attributes of DNS names and how they are queried, Bilge [
41] used 15 DNS traffic features, nine of which were not previously proposed, including time-based features, DNS response-based features, TLL change features, and domain name features. When combined with a decision tree, this method can identify DNS tunnel traffic accurately, resulting in fewer false alarms than 1% and a 98% accuracy rate.
Wang [
60] and Palau [
58] developed a way to solve domain name text detection lightly to reduce storage overhead and computational complexity. A domain name specificity score, enhanced TF-IDF, and other algorithms were used by Wang [
60] to detect DNS tunnel traffic in private datasets, with 99.92% accuracy in detecting DNS tunnel traffic. It is worth noting that Palau [
58] proposed a detection method based on CNN with a simple structure called 1D-CNN that detects 99% of normal domains and 92% of tunnel domains, even though its structure is simple. D’Angelo [
59] also used 2D-CNN with a straightforward network structure to detect tunnel traffic. They used a 24-dimensional matrix to represent 22 different features, including request/response type, etc.
Siby [
37] focused on DoH [
66] (DNS over HTTPS) in order to detect encrypted DNS tunnel traffic because traditional website fingerprint features are insufficient for describing DoH traffic. As a result, when it is combined with RF, it introduces N-grams with TLS record lengths as new features and is able to identify DNS tunnel traffic with 84% accuracy in private datasets. A variational autoencoder (VAE) [
67] was proposed by Ding [
35] as an E2E model for learning long sequential and structural information beyond the capability of traditional machine learning methods. VAE used bidirectional Gated Recurrent Units (Bi-GRU) as encoders and decoders to automatically extract latent feature representations from raw traffic. Semi-supervised training is used to train the model on normal traffic patterns. The accuracy rate is over 99% on the CIRA-CIC-DoHBrw-2020 dataset [
68]. Moreover, the complexity of their model from the number of parameters and consuming time are all obviously less than others [
69].
Table 5.
Summary of DNS tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 5.
Summary of DNS tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Statistic | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Burghouwt [49] | 2010 | Private | T | √ | | | √ | √ | |
Payload
| Domain |
Degree distributuion
|
| Bilge [41] | 2011 | Public | ML | | √ | √ | √ | √ | √ |
Payload
| Domain + TTL + Duration + Answer |
Decision Tree
|
| Marchal [55] | 2012 | Private | T | | √ | √ | √ | √ | √ |
Payload
| Domain + TTL + Duration |
k
-means
|
| Wang [60] | 2019 | Private | ML | | √ | | √ | √ | |
Payload
| Domain |
TF-IDF
|
| Siby [37] | 2019 | Public | ML | | √ | √ | | √ | | Handshake |
TLS
|
N-gram + RF
|
| Palau [58] | 2020 | Public | ML | | √ | √ | | √ | √ | Payload | Domain | CNN |
| Ding [35] | 2021 | Public | ML | | √ | √ | | √ | √ | Payload | Size + Duration | VAE + Bi-GRU |
| D’Angelo [59] | 2022 | Private | ML | | √ | | √ | √ | | Header + Payload | Size + Record | CNN |
| Wang [48] | 2022 | Private | ML | | √ | √ | √ | √ | √ | Header + Payload | Domain + Size + Duration | RF + KNN |
3.4. SSH
The SSH protocol provides users with secure remote login or other network services through encryption in unsecured networks. As a result, plaintext features are made obsolete in a dense stream of information. To identify SSH tunnel traffic, statistical features and machine learning methods have become mainstream, along with the identification of passenger protocols, applications, or services.
3.4.1. Traditional Detection
It is possible to identify SSH tunnel traffic among the detection methods (in
Table 6), as well as to classify passenger protocols and applications in traffic using statistical features. With fine granularity, Alshammari [
61] and Maiolini [
56] classified SSH tunnel traffic applications and services. Ashammari [
61] used AdaBoost and RIPPER to identify SSH tunnel traffic with 95% accuracy in public datasets. The classification covers 11 applications/services, including local tunnels, remote tunnels, FTP, and Shell, with the accuracy of 99% and false alarm rates of 0.7%. According to Maiolini [
56], the
k-means clustering analysis is used for real-time traffic classification, which results in an accuracy of 99.5% for SSH tunnel traffic and 99.88% for SCP-SSH, SFTP-SSH, and HTTP-SSH passenger protocols in tunnels. Although these two methods are lightweight, their disadvantages include their confusion when there are similar applications or services in the tunnel traffic, such as HTTP and FTP, and the model will become less accurate as more protocols are added.
3.4.2. Machine Learning
In addition to detecting passengers, ML is capable of classifying their protocols and applications. Agghey [
43], Alshammari [
42], Jian [
44], Pradhan [
57] and Hynek [
62] have all selected features to train from including packet size, forward/backward average IAT of the first few packets of flows. Without using IP, port number, and payload, Alhammari [
42] used C4.5, genetic programming (GP) and AdaBoost classifiers to classify SSH tunnel encrypted traffic. Experiments are conducted in public and private datasets using 39 packet header features (IP header length, checksum, etc.) and 22 flow-based features. In the best case, GP can achieve 98% accuracy, and it can also be classified by applications in tunnel traffic such as SCP, SFTP, Shell, X11 session, Telnet, etc. At its best, C4.5 can achieve 100% accuracy. An unsupervised clustering algorithm On-Line Density-Based Spatial Clustering (OLDBSC) was proposed by Jian [
44] to resolve the problems of large computation and high memory consumption. Instead of clustering the entire stream’s features, the best priority feature algorithm is used to find an optimal feature set for a sub-stream and then to map the applications that have the highest probability to the application types using the best priority feature algorithm. This method is capable of identifying SSH tunnel traffic as well as classifying applications and identifying unknown application types in traffic. The accuracy rate in private datasets is as high as 99%.
Table 6.
Summary of SSH tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 6.
Summary of SSH tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Statistic | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Alshammari [61] | 2007 | Public | T | | √ | √ | √ | √ | √ |
Payload
| Size + Duration | AdaBoost + RIPPER |
| Maiolini [56] | 2009 | Private | T | | √ | √ | √ | √ | √ |
Payload
| Size + Duration + Direction |
k
-means
|
| Jian [44] | 2010 | Private | ML | | √ | √ | √ | √ | √ |
Payload
| Size + Duration + Direction |
OLDBSC
|
| Alshammari [42] | 2011 | Private | ML | | √ | | √ | √ | √ |
Payload + Head
| Size + Duration |
C4.5 + GP + AdaBoost
|
| Pradhan [57] | 2018 | Public | ML | | √ | √ | √ | √ | √ |
Payload + Head
| Size + Duration + Number |
k
-means + RBFN
|
| Hynek [62] | 2020 | Private | ML | | √ | √ | √ | √ | √ |
Payload
| Size + Duration |
AdaBoost
|
| Agghey [43] | 2021 | Public | ML | | √ | √ | √ | √ | √ | Payload | Size + Duration + Number + Port | KNN + NB + RF+ Decision Tree |
3.5. TCP
TCP tunnel is a common form in the transport layer. Based on , it is possible to hide information in IHL, checksum, ISN, and IP ID field. In addition, is also used as a common form of TCP tunnel by changing the time interval sequence of packets, network jitter and network delay.
3.5.1. Traditional Detection
Most fingerprint detection methods (as shown in
Table 7) analyze tunnel construction in a theoretical manner, without an actual detection model. As such, they can only determine whether it is tunnel traffic. According to Zseby [
19], TCP acknowledgment and sequence number fields and ISNs are common methods for building covert tunnels.
Statistical feature detection methods can identify both tunnel traffic and passenger protocol. Gianvecchio [
20] detected hidden time channels based on entropy and modified conditional entropy. The author focused on four typical
: IPCTC, TRCTC, MBCTC and JitterBug. To detect these above, they combined fine-binned and coarse-binned estimation of corrected conditional entropy. The corrected conditional entropy can detect the
with abnormal regularity, while the entropy test can detect the hidden time tunnel with small changes throughout the distribution. It is possible to achieve 100% detection using a combination of the two methods. To detect hidden communication in TCP flows under passenger protocols such as HTTP, FTP, TELNET, SSH and SMTP, Zhai [
26] proposed a detection method based on maximum a posteriori probability MAP, a Markov chain description of TCP handshake behavior. For small traffic windows of private datasets, the algorithm is 100% accurate.
3.5.2. Machine Learning
Machine learning detection methods typically use SVMs with excellent pattern classification performances, but most of them are used to detect whether tunnel traffic is present, and little research is available on tunnel traffic protocol and application behavior. To study covert tunnels and distinguish between normal TCP traffic and tunnel traffic, Shrestha [
30] used the IP header’s identification and the TCP header’s serial number field.
In addition to the header fields of the IP and TCP headers, machine learning is also an objective method for analyzing the regularity and inner correlation. The regularity or correlation between continuous packets will be changed if the information in the TCP header is hidden. Using kernel density estimation, variation coefficient, fractal entropy and autocorrelation coefficient, Fu [
31] further transformed these features into an eigen-vector matrix.
Table 7.
Summary of TCP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 7.
Summary of TCP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Statistic | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Gianvecchio [20] | 2010 | Public | T | | √ | | √ | | √ |
Payload
| Corrected Conditional Entropy | Match |
| Zhai [26] | 2013 | Private | T | | √ | | √ | √ | √ |
Field
| Flag |
Markov
|
| Shrestha [30] | 2015 | Private | ML | | √ | | √ | √ | √ |
Field
| Kolmorov–Smirnov Test Score (K–S score) + Regularity Score + Entropy + Corrected Conditional Entropy (CCE) |
SVM
|
| Zseby [19] | 2016 | Private | T | √ | | | √ | √ | √ |
Head + Field
| Time-Related Properties |
Match
|
| Fu [31] | 2018 | Private | ML | | √ | | √ | √ | √ |
Payload + Field
| Kernel Density Estimation + Variation Coefficient + Fragility Entropy + Autocorrelation Coefficient |
SVM
|
3.6. ICMP
The principle of ICMP is to encapsulate IP traffic in the data field of ICMP request packet and send it to the ICMP server, which unpacks and forwards IP traffic. In order to establish an ICMP tunnel, packets are encapsulated in an ICMP reply packet and sent back to the client. ICMP tunnels can be built using icmptunnel, ptunnel or icmpsh.
3.6.1. Traditional Detection
Among the traditional detection methods (in
Table 8), most papers focus on detecting whether ICMP tunnel traffic is present, without paying much attention to fine-grained classification. A simple string scan of “passwd”, “root”, “tmp”, “ls”, and “dir” was used to complete Singh’s [
70] preliminary detection in the unencrypted ICMP tunnel. While this method has low overhead and high speed, there are a few disadvantages to its use, including the need to maintain a database of suspicious strings regularly, as well as a high false negative rate. As characteristics of ICMP tunnel traffic matching, Govil [
22] defined 89 field types (such as AS MPLS label, IPv6 address, and AS number related to data) and found that hiding data in ICMP tunnels is also common practice by using byte of payload.
ICMP tunnel traffic can be identified by marking abnormally large and often persistent or burst packets to proxy nodes. According to Barbhuiya [
23], ICMP tunnel traffic can be detected by detecting traffic congestion in gateways according to bandwidth utilization, processing all unreachable messages from hosts and networks in the network, establishing a protocol for unreachable messages, etc. The paper presents only theory, not experimental data. To identify normal traffic or ICMP tunnel traffic, Sayadi [
24] first compared the number of packet bytes, then checked the ICMP message rate, ICMP sequence number, and fast random pattern matching in the feature library or MD5 hash verification.
3.6.2. Machine Learning
Machine learning detection methods include detecting whether tunnel traffic is the majority, while few people pay attention to fine-grained classified traffic. From the original packets, Sohn [
21] extracted 13-dimension features from the ICMP payload, 15-dimension features from the 2-dimension features from the ICMP payload, and 4 bytes from the ICMP header. The SVM was able to detect ICMP hidden tunnels with almost 99% accuracy. A model proposed by Cho [
47] combining RF with ICMP checksum status, identifier, serial number, and data has a higher accuracy (over 99.9%) than the SVM and Naïve Bayes models.
Table 8.
Summary of ICMP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
Table 8.
Summary of ICMP tunnel detection. T represents traditional method. ML represents machine learning method. I represents detecting with coarse content. II represents detecting in a specific location.
| Ref. | Year | Datasets | T/ML | Fingerprint | Statistic | Flow | Packet | Spatial | Temporal | Ⅰ | Ⅱ | Model |
|---|
| Sohn [21] | 2003 | Private | ML | | √ | | √ | √ | |
Payload + Head
| Size + Flag | SVM |
| Singh [70] | 2003 | Public | T | √ | | | √ | √ | |
Payload
| String | Match |
| Govil [22] | 2007 | Private | T | √ | | | √ | √ | √ |
Field
| MPLS + AS | Match |
| Barbhuiya [23] | 2012 | Private | T | | √ | √ | √ | | √ |
Payload
| Duration | Match |
| Sayadi [24] | 2017 | Private | T | √ | √ | | √ | √ | √ |
Payload
| Size + Rate + SEQ |
Match + MD5
|
| Cho [47] | 2019 | Private | ML | | √ | | √ | √ | | Payload + Field | SEQ + Flag | RF |
3.7. IPSec
IPsec security architecture includes three basic protocols: AH (Authentication Header) protocol provides information source verification and integrity assurance for IP packets, ESP (Encapsulated Security Payload) protocol provides encryption assurance, and ISAKMP protocol provides shared security information when both parties communicate. IPSec tunnel mode is mostly IPSec VPN, which is a kind of encrypted . Due to the limited number of existing studies, this section only presents the methods of machine learning detection in this mode.
Machine Learning
An important part of reading ciphertext is extracting sensitive features that are different from plaintext. With EFM (Estimated Feature Method), Okada [
32] selected 29 strong correlation features with thresholds greater than 0.7 and then compared the accuracy of SVM, Naïve Bayes, and C4.5. The best EFM using SVM was found to identify IPSec tunnel traffic with 97.2% accuracy.
IPSec tunnel traffic can also be used to identify protocols and applications at a fine-grained level. Okada [
32] approximated each encrypted tunnel traffic feature through Gaussian distribution by using a Naïve Bayes classifier. When mixed with HTTP, FTP, SMTP and SSH passenger protocols, this method improves IPSec tunnel traffic protocol identification accuracy by 28.5%. In order to reduce computation, Kumano [
33] first used C4.5 to classify the encryption types of tunnel traffic. The author then used a small number of data packets to represent the flow characteristics and combined SVM to identify the tunnel traffic applications. It is possible to achieve 92.5% accuracy when using private datasets. KNN was chosen by Zhao [
46], a decision followed by binary classification of tunnel traffic noise and then multi-classification of tunnel traffic. In private datasets, TMT-RF achieves the best classification performance of 93% by dividing overlapping traffic into multiple segments and making predictions. It does not take time to find the dividing point but divides the traffic into many segments and makes predictions.
4. Evaluation
In this section, we first use AHP to quantitatively evaluate the methods and reviews of detecting tunnel traffic. This method aims to take a complex target of a decision-making problem as a system, decomposes the target into multiple targets or criteria, and calculates the correlation through qualitative indicators as a systematic method for multi-scheme optimization decision making. In the process of AHP, there are generally four steps which are shown in
Figure 4.
- i.
Construct hierarchical evaluation model:
- ✓
Target layer: optimal paper selection/rank.
- ✓
Criteria layer: innovation, granularity of distinguishing applications and behaviors, completion (including accuracy rate, precision rate, recall rate, F1, etc.), computational complexity (time complexity and space complexity) and reproducibility (in
Section 4.1); protocol categories, granularity of distinguishing applications and behaviors, diversity of detection methods, computational complexity of methods (time complexity and space complexity) and compatibility (in
Section 4.2).
- ✓
Scheme layer: Paper 1, Paper 2, Paper 3, …, Paper i, …, Paper n.
- ii.
Construct judgment matrix
The construction of a judgment matrix is performed to compare each element with each other and determine the weight of each criterion layer compared to the target layer. In short, we do this to judge the indicators of the criterion layer in pairs, and usually we use the 1–9 scalar method to designate them (as shown in
Table 9).
For elements, we can obtain pairwise comparison judgment matrix: , which satisfies: . ( means that compared with , ’s importance degree).
- iii.
Hierarchical single sorting and consistency check
Then, the weights are calculated, the vectors of each row of
are geometrically averaged, and the results are normalized to obtain the weights of each evaluation index and feature vector
. We calculate a weight vector and maximum characteristic root
, where
is the order of the judgment matrix:
Finally, we calculate the consistency indicator
and consistency ratio
. (The average random consistency indicator
is obtained by arithmetic average after repeated calculation of the characteristic root of random judgment matrix for more than 500 times. This can be obtained by looking up public information, and so this paper will not repeat it here.):
When it is less than 0.1, it is generally considered that the consistency of the judgment matrix is acceptable. The meaning of consistency test is used to determine whether there are logical problems in the constructed judgment matrix, for example, if the judgment matrix is constructed with , and , if it is judged that is equivalent to as 3 ( is slightly more important than ) and that is equivalent to as 1/3 ( is slightly more important than ). When judging that is equivalent to , according to the above logic, is supposed to be more important than . If we mistakenly fill in as equivalent to as 3 when constructing the judgment matrix ( is slightly more important than ), then there will be a logical error.
- iv.
Hierarchical total sorting and consistency check
In the previous section, we obtained the weight vector of the second layer (criterion layer) in relation to the first layer (target layer). Next, we need to obtain the weight vector of the third layer (scheme layer) to each element of the second layer (criterion layer).
Because there are
schemes in our scheme layer (Paper 1, Paper 2, Paper 3, …, Paper i, …, Paper n), innovation, granularity of distinguishing applications and behaviors, completion (including accuracy rate, precision rate, recall rate, F1, etc.), computational complexity (time complexity and space complexity) and reproducibility (in
Section 4.1) are compared in pairs. For example, the first n-order matrix is formed by comparing the completion of Paper 1 with the completion of Paper 2 and Paper 3, and so we should construct five n-order matrices (
) subjectively according to the content of the papers. Therefore, after we calculate the weight vector of each matrix and consistency check, we also should calculate the weight and consistency check of the total ranking of levels. That is to say, we must calculate the weight vector of the scheme layer to the target layer.
Here, the weight of Paper 1 to the total target, that is to say, the weight of completion, reproducibility, computational complexity, innovation and distinguishing applications (in
Section 4.1) of Paper 1, Paper 2 and Paper i is multiplied by the weight vector of the fifth-order matrix
to obtain the weight at the target level. Then, the ranking of papers’ contribution degree is obtained.
4.1. Contribution of Detections
According to the background information, expert experience and engineering practice knowledge of tunnel traffic detection, we have selected the most suitable criteria. Our evaluation of tunnel detection papers (in
Section 3) is based on their innovation, granularity of distinguishing applications and behaviors, completion (including accuracy rate, precision rate, recall rate, F1, etc.), computational complexity (time complexity and space complexity) and reproducibility. Additionally, we have given them a subjective judgment matrix
. In
Table 10, the weight ranking of these five indicators can be calculated and their results can be obtained by the above four steps according to
Figure 4. Our results are shown in
Figure 5a–f. In
Figure 5, we rank the papers describing tunnel traffic detection papers from the point of view of protocol (HTTP, HTTPS, DNS, SSH, TCP, ICMP and IPSec) according to AHP method, and the contribution decreases from top to bottom. This provides a more concise and convenient way for more scholars exploring in the field of tunnel detection and saves a lot of time and energy.
Table 10.
Evaluation indicators of tunnel detection.
Table 10.
Evaluation indicators of tunnel detection.
| | Completion | Reproducibility | Complexity | Innovation | Distinguish Application |
|---|
| Rank | 1 | 2 | 3 | 4 | 5 |
| Weight | 0.4292 | 0.2782 | 0.1841 | 0.0648 | 0.0437 |
Figure 5.
Rank of contribution of 6 protocols in tunnel detection. (a) Contribution of HTTP tunnel conferences, (b) Contribution of HTTPS tunnel conferences, (c) Contribution of DNS Tunnel references, (d) Contribution of SSH tunnel conferences, (e) Contribution of CTP tunnel conferences and (f) Contribution of ICMP tunnel conferences.
Figure 5.
Rank of contribution of 6 protocols in tunnel detection. (a) Contribution of HTTP tunnel conferences, (b) Contribution of HTTPS tunnel conferences, (c) Contribution of DNS Tunnel references, (d) Contribution of SSH tunnel conferences, (e) Contribution of CTP tunnel conferences and (f) Contribution of ICMP tunnel conferences.
4.2. Contribution of Reviews
We summarize some related reviews on tunnel detection in
Table 11. Zander [
45] summarized the tunnel protocols between the application layer and the network layer, such as HTTP, DNS, SSH and ICMP, etc., and also summarized the idea of detecting
traffic by using time stamp, packet arrival interval and
with payload. Dakhane [
71] introduced TCP tunnel in detail to
and identified tunnel traffic from the message field. However, the protocol and detection methods described in this review are too monotonous and not suitable for most of the current situations. TCP tunnel traffic detection methods in
and
were summarized by Goher [
72], who briefly classified the applications in tunnel traffic. By using statistics and machine learning, Wendzel [
73] identified tunnel traffic using 109 technologies that hide protocol information through tunnels, simplified them into 11 patterns, and used statistics to identify tunnel traffic. Although they gave a variety of patterns, they failed to give a formal representation or give a specific detection method for each or fixed patterns. Carrara [
74] regarded the tunnel from an attacker’s perspective. By using bandwidth and entropy as metrics, the attacker can identify tunnel traffic by determining the probability of passing through the tunnel. Although this review has a novel angle, it failed to give an actual detection method, and as time goes by, the attack patterns of attackers may be updated iteratively. Yassine [
75] summarized the
detection methods of embedded data in DNS requests and responses based on machine learning. Besides that, Wang [
76] introduced a plethora of literature, including rule-based and model-based methods. However, they only identified whether the tunnel traffic or not in DNS tunnel and failed to give fine-grained classification methods. At present, this kind of detection is not enough for all kinds of behaviors mixed in tunnel traffic. According to Elsadig [
77], tunnel traffic identification is affected by three problems: the rapid advancement of network technology, switching techniques, and micro-protocols. A comprehensive analysis of traffic’s metadata features and RF performance was performed by Mazel [
78], who summarized the methods for detecting and classifying tunnel passenger protocols and tunnel applications. Based on the analysis of concealment, robustness, and transmission efficiency, Tian [
79] proposed three new network tunnels among streaming media, blockchain, and IPv6, described possible tunnel forms and provided a new idea for tunnel detection. This is a new summary of tunnel transmission environments, and so we should focus on a more novel detection environment to obtain better results.
According to the background information, expert experience and engineering practice knowledge of tunnel traffic detection, we have also selected the most suitable criteria, including five indicators: protocol categories, granularity of distinguishing applications and behaviors, diversity of detection methods, computational complexity of methods (time complexity and space complexity) and compatibility. Additionally, we have given them a subjective judgment matrix,
. In
Table 12, the weight ranking of these five indicators is presented and their results can be obtained by performing the above four steps according to
Figure 4.
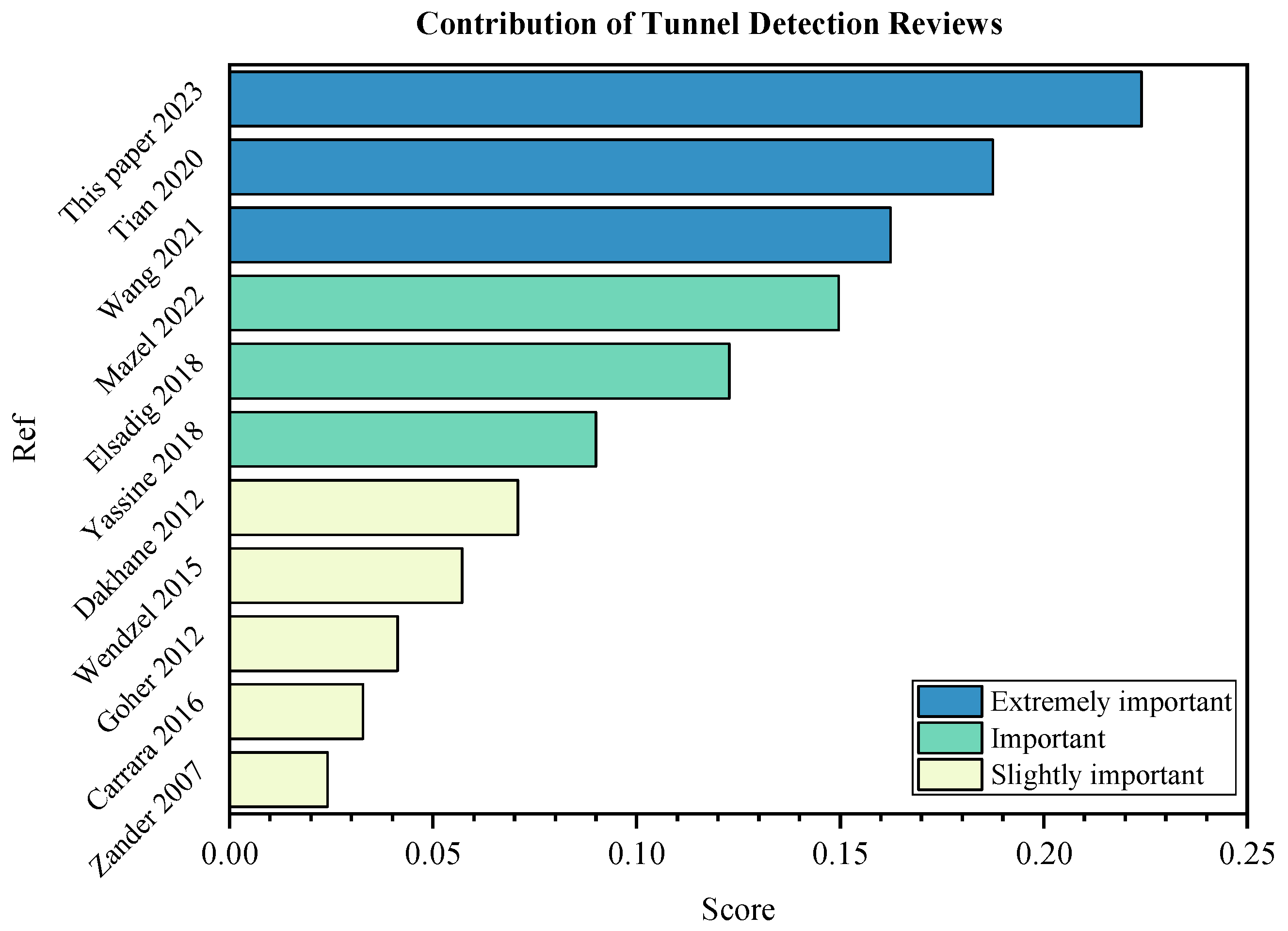
We evaluated the 10 reviews above and our paper (11 reviews in total) according to AHP according to the method in
Figure 4 and the results are shown in
Figure 6. In
Figure 6, we rank the contribution degree decreases from top to bottom according to the contribution degree of tunnel traffic detection reviews. Combined with the comprehensive analysis above, we provide a more concise and convenient way for more scholars exploring in the field of tunnel detection. Additionally, it can be found that this paper, as a review, has certain advantages in the comprehensive score of the five indicators we have given and has good reference value.
Table 12.
Evaluation indicators of tunnel detection reviews.
Table 12.
Evaluation indicators of tunnel detection reviews.
| | Protocol Category | Detection Diversity | Distinguish Application | Complexity | Compatibility |
|---|
| Rank | 1 | 2 | 3 | 4 | 5 |
| Weight | 0.4422 | 0.2824 | 0.1514 | 0.076 | 0.048 |
5. Conclusions
5.1. Datasets
Choosing abundant labeled and category balance datasets for machine learning training remains an urgent issue. There are three aspects of datasets that need to be considered.
The first is the impact of datasets from different network environments on traffic features. Even within the same network, changing the location of geographic capture will change the statistical features of the data flow, and traffic congestion will change the time features significantly. It is important to ensure the reproducibility and authenticity of datasets.
Furthermore, the unbalanced classification of training datasets is considered. Some tunnel traffic applications will generate an enormous amount of traffic, while others will generate only a very small amount. A huge imbalance in datasets will cause the training models to fail. So, datasets should be trained by selectively extracting sensitive features and suppressing unimportant ones, which reduced the class imbalance to some extent and improved classification accuracy.
Finally, there are few public datasets (raw traffic) in detecting tunnel traffic, and so the amount of labeled data is smaller. The situation of deficient data is detrimental to supervised learning. To put it another way, even though we can collect tunnel traffic from various software, all kinds of noises, mimic traffic or nothing to do with being detected behavior caused by them in order to avoid censorship, also bring trouble to classification.
5.2. Feature Engineering
Feature engineering is an important step in machine learning that deserves consideration in two ways. In general, stream-level data are not very accurately marked (packets of the same quintuple are combined into one stream). In tunnel traffic, the applications share the same quintuple, and so it is difficult to separate the streams by beginning and ending times. Trojan malware is one of the typical applications for tunnels. As such, the quintuple feature is invalid because ports are frequently changed, and so we should use quadruple or triple depending on the actual situation. Additionally, the sample includes not only tunnel traffic but also the flows generated by normal communication, these latter flows being called noise traffic.
Conversely, if features from each flow are extracted separately, correlation features between flows called host-level features may be overlooked (focusing primarily on communications between hosts, such as all traffic with hosts or all traffic with a particular IP and port of hosts). Thus, not only must the number of packages, the average packet length and IAT be aggregated, but also the number and expiration of flow-signed packages. Additionally, since malicious IP semi-connections and non-connections are distributed differently from normal IP, it is necessary to count the number of flows with Alert and the connection status of different flows.
5.3. Trend of Tunnel Detection
In this paper, we compare the number of papers published over the past decade between traditional and machine learning detection, based on the three challenges from coarse to fine in
Figure 7. We have found that among non-encrypted protocols, most people study whether there is tunnel traffic or not whereas, in encrypted protocols, most people are inclined to study passenger protocols, applications, and other fine-grained identification. The flaws brought by plaintext transmission to the tunnel are enormous, and the tunnel detection methods based on rules and features have been able to achieve good results. Tunnel detections using encryption protocols (including custom encryption protocols) often focus on hidden passenger protocols and services.
Meanwhile,
Figure 8 compares the papers that have solved these challenges over the past decade. Even though there continue to be problems, we have found that the amount of research on how to deal with these challenges is not adequate and that fine-grained identification of encrypted traffic in tunnels should be a major focus of future research. Additionally, we have also found DNS tunnel research has prevailed more than others in recent years.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








