


Evolutionary Features for Dynamic Link Prediction in Social Networks



Abstract
:1. Introduction
2. Dynamic Similarity Metrics
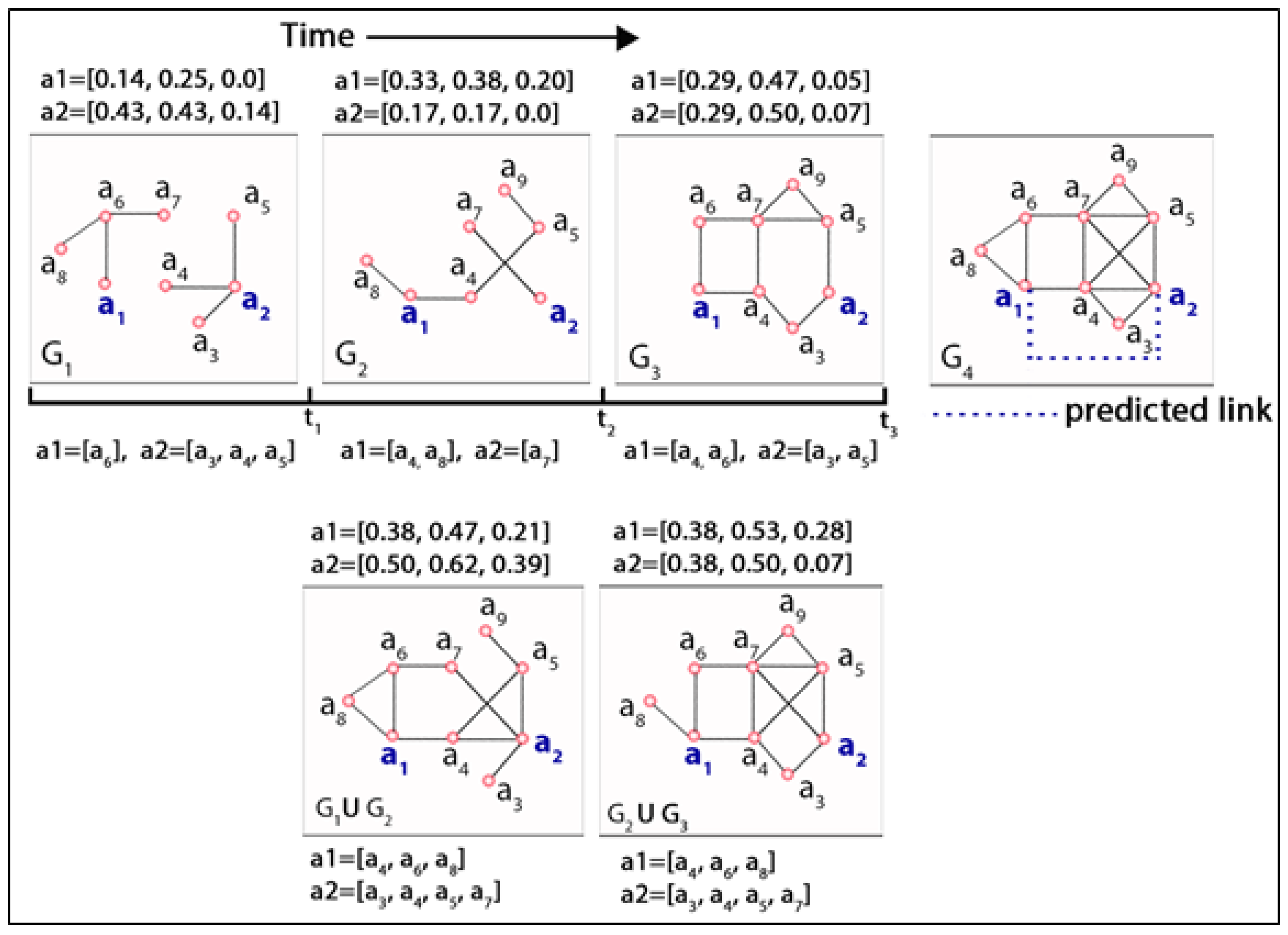
2.1. Actor-Level Evolution in a Dynamic Network
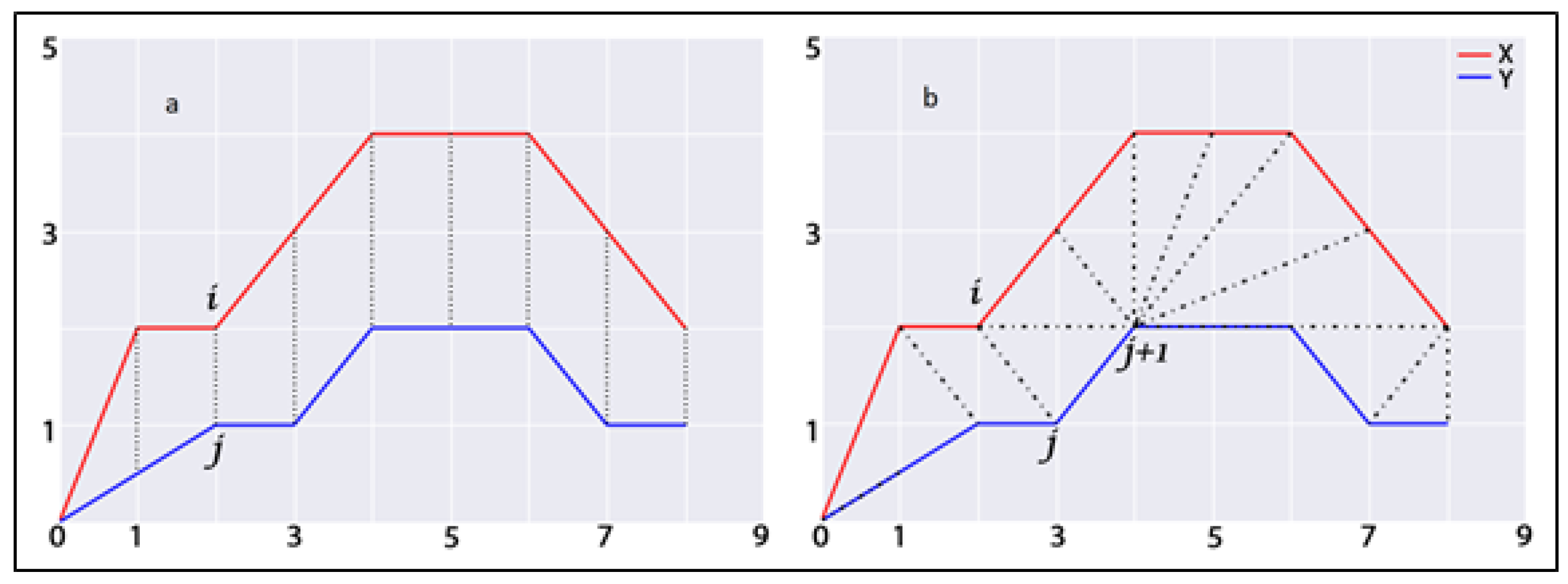
2.1.1. Structural Dynamicity
2.1.2. Neighbourhood Dynamicity
2.2. Dynamic Features
2.2.1. Temporal Similarity
2.2.2. Correlation-Based Similarity
2.2.3. Bray–Curtis Similarity
3. Network Datasets and Experimental Settings
3.1. Datasets
3.1.1. Undirected Networks
3.1.2. Directed Networks
3.1.3. Co-Authorship Networks
3.2. Supervised Link Prediction
3.3. Performance Evaluation
4. Results
4.1. Classification Performance
4.2. Feature Importance
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Opsahl, T.; Hogan, B. Growth Mechanisms in Continuously-Observed Networks: Communication in a Facebook-Like Community. CoRR. 2010. Available online: https://www.researchgate.net/profile/Tore-Opsahl/publication/47374811_Modeling_the_evolution_of_continuously-observed_networks_Communicationin_a_Facebook-like_community/links/5575a53b08aeb6d8c01985c8/Modeling-the-evolution-of-continuously-observed-networks-Communication-in-a-Facebook-like-community.pdf (accessed on 20 January 2023).
- Liben-Nowell, D.; Kleinberg, J. The link prediction problem for social networks. In Proceedings of the Twelfth International Conference on Information and Knowledge Management, New Orleans, LA, USA, 3–8 November 2003; pp. 556–559. [Google Scholar]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.J.; Chen, Y.; Li, Y.; Han, J. A supervised link prediction method for dynamic networks. J. Intell. Fuzzy Syst. 2016, 31, 291–299. [Google Scholar] [CrossRef]
- Daud, N.N.; Ab Hamid, S.H.; Saadoon, M.; Sahran, F.; Anuar, N.B. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716. [Google Scholar] [CrossRef]
- Lande, D.; Fu, M.; Guo, W.; Balagura, I.; Gorbov, I.; Yang, H. Link prediction of scientific collaboration networks based on information retrieval. World Wide Web 2020, 23, 2239–2257. [Google Scholar] [CrossRef]
- Wang, H.; Le, Z. Seven-layer model in complex networks link prediction: A survey. Sensors 2020, 20, 6560. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Cui, J.; Zhang, J.; Pei, X.; Sun, G. Transmission characteristic and dynamic analysis of COVID-19 on contact network with Tianjin city in China. Phys. A Stat. Mech. Its Appl. 2022, 608, 128246. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M.E. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar] [CrossRef] [Green Version]
- Mamitsuka, H. Mining from protein–protein interactions. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 400–410. [Google Scholar] [CrossRef]
- Cannistraci, C.V.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Yan, G.; Zhou, T.; Hu, B.; Fu, Z.Q.; Wang, B.H. Efficient routing on complex networks. Phys. Rev. E 2006, 73, 046108. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Feng, X.; Wang, R.C. Adaptive spray routing for opportunistic networks. Int. J. Smart Sens. Intell. Syst. 2013, 6, 95. [Google Scholar]
- Liu, Z.; Ma, J.; Zeng, Y. Secrecy transfer for sensor networks: From random graphs to secure random geometric graphs. Int. J. Smart Sens. Intell. Syst. 2013, 6, 77. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Wang, J.; Tu, M.; Zhang, Y.; Yan, Y. Enhancing link prediction using gradient boosting features. In Proceedings of the International Conference on Intelligent Computing, Lanzhou, China, 2–5 August 2016; pp. 81–92. [Google Scholar]
- Tylenda, T.; Angelova, R.; Bedathur, S. Towards time-aware link prediction in evolving social networks. In Proceedings of the 3rd Workshop on Social Network Mining and Analysis, Paris, France, 28 June 2009; pp. 1–10. [Google Scholar]
- Li, X.; Du, N.; Li, H.; Li, K.; Gao, J.; Zhang, A. A deep learning approach to link prediction in dynamic networks. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; pp. 289–297. [Google Scholar]
- Zhang, T.; Zhang, K.; Lv, L.; Li, X. Temporal link prediction using node centrality and time series. Int. J. Fut. Comput. Commun. 2020, 9, 62–65. [Google Scholar] [CrossRef]
- Wu, X.; Wu, J.; Li, Y.; Zhang, Q. Link prediction of time-evolving network based on node ranking. Knowl.-Based Syst. 2020, 195, 105740. [Google Scholar] [CrossRef]
- Chi, K.; Yin, G.; Dong, Y.; Dong, H. Link prediction in dynamic networks based on the attraction force between nodes. Knowl.-Based Syst. 2019, 181, 104792. [Google Scholar] [CrossRef]
- Chen, H.; Li, J. Exploiting structural and temporal evolution in dynamic link prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 427–436. [Google Scholar]
- Zhu, Y.; Liu, S.; Li, Y.; Li, H. TLP-CCC: Temporal link prediction based on collective community and centrality feature fusion. Entropy 2022, 24, 296. [Google Scholar] [CrossRef]
- Juszczyszyn, K.; Musial, K.; Budka, M. Link prediction based on subgraph evolution in dynamic social networks. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 27–34. [Google Scholar]
- Zhu, X.; Tian, H.; Cai, S. Predicting missing links via effective paths. Phys. A Stat. Mech. Its Appl. 2014, 413, 515–522. [Google Scholar] [CrossRef]
- Rahman, M.; Hasan, M.A. Link prediction in dynamic networks using graphlet. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; pp. 394–409. [Google Scholar]
- Ahmed, N.M.; Chen, L. An efficient algorithm for link prediction in temporal uncertain social networks. Inf. Sci. 2016, 331, 120–136. [Google Scholar] [CrossRef]
- Tabourier, L.; Libert, A.S.; Lambiotte, R. Predicting links in ego-networks using temporal information. EPJ Data Sci. 2016, 5, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Jaya Lakshmi, T.; Durga Bhavani, S. Temporal probabilistic measure for link prediction in collaborative networks. Appl. Intell. 2017, 47, 83–95. [Google Scholar] [CrossRef]
- Safdari, H.; Contisciani, M.; De Bacco, C. Reciprocity, community detection, and link prediction in dynamic networks. J. Phys. Complex. 2022, 3, 015010. [Google Scholar] [CrossRef]
- Ma, X.; Sun, P.; Qin, G. Nonnegative matrix factorization algorithms for link prediction in temporal networks using graph communicability. Pattern Recognit. 2017, 71, 361–374. [Google Scholar] [CrossRef]
- Chen, J.; Lin, X.; Jia, C.; Li, Y.; Wu, Y.; Zheng, H.; Liu, Y. Generative dynamic link prediction. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 123111. [Google Scholar] [CrossRef]
- Ibrahim, N.M.A.; Chen, L. Link prediction in dynamic social networks by integrating different types of information. Appl. Intell. 2015, 42, 738–750. [Google Scholar] [CrossRef]
- da Silva Soares, P.R.; Prudêncio, R.B.C. Time series based link prediction. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Choudhury, N.; Uddin, S. Evolution similarity for dynamic link prediction in longitudinal networks. In Complex Networks VIII: Proceedings of the 8th Conference on Complex Networks CompleNet 2017, Dubrovnik, Croatia, 21–24 March 2017; Springer: Dubrovnik, Croatia, 2017; pp. 109–118. [Google Scholar]
- Güneş, İ.; Gündüz-Öğüdücü, Ş.; Çataltepe, Z. Link prediction using time series of neighbourhood-based node similarity scores. Data Min. Knowl. Discov. 2016, 30, 147–180. [Google Scholar] [CrossRef]
- Rossetti, G.; Guidotti, R.; Miliou, I.; Pedreschi, D.; Giannotti, F. A supervised approach for intra-/inter-community interaction prediction in dynamic social networks. Soc. Netw. Anal. Min. 2016, 6, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Uddin, S.; Khan, A.; Piraveenan, M. A set of measures to quantify the dynamicity of longitudinal social networks. Complexity 2016, 21, 309–320. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008.
- Uddin, S.; Piraveenan, M.; Chung, K.S.K.; Hossain, L. Topological analysis of longitudinal networks. In Proceedings of the 2013 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 3931–3940. [Google Scholar]
- Uddin, S.; Hossain, L.; Murshed, S.T.; Crawford, J.W. Static versus dynamic topology of complex communications network during organizational crisis. Complexity 2011, 16, 27–36. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, K.J.; Li, Y. A link prediction method that can learn from network dynamics. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 549–553. [Google Scholar]
- Hanneman, R.A.; Riddle, M. Introduction to Social Network Methods; University of California: Riverside, CA, USA, 2005. [Google Scholar]
- Porter, M.D.; Smith, R. Network neighbourhood analysis. In Proceedings of the 2010 IEEE International Conference on Intelligence and Security Informatics, Vancouver, BC, Canada, 23–26 May 2010; pp. 31–36. [Google Scholar]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef] [Green Version]
- Müller, M. Dynamic time warping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Chi, K.T.; Liu, J.; Lau, F.C. A network perspective of the stock market. J. Empir. Financ. 2010, 17, 659–667. [Google Scholar]
- Bray, J.R.; Curtis, J.T. An ordination of the upland forest communities of southern Wisconsin. Ecol. Monogr. 1957, 27, 326–349. [Google Scholar] [CrossRef]
- Ricotta, C.; Podani, J. On some properties of the Bray–Curtis dissimilarity and their ecological meaning. Ecol. Complex. 2017, 31, 201–205. [Google Scholar] [CrossRef]
- Legendre, P.; Legendre, L. Numerical Ecology, New York; Elsevier: New York, NY, USA, 2012. [Google Scholar]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. Networkrepository: A graph data repository with visual interactive analytics. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 25–30. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Yang, Y.; Lichtenwalter, R.N.; Chawla, N.V. Evaluating link prediction methods. Knowl. Inf. Syst. 2015, 45, 751–782. [Google Scholar] [CrossRef] [Green Version]
- Schütze, H.; Manning, C.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Boyd, K.; Costa, V.S.; Davis, J.; Page, D. Unachievable region in precision–recall space and its effect on empirical evaluation. arXiv 2012, arXiv:1206.4667. [Google Scholar]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Wang, L.; Pan, L.; Yao, K. Link prediction based on common-neighbors for dynamic social network. Procedia Comput. Sci. 2016, 83, 82–89. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Metric | Equation | Description |
|---|---|---|
| Temporal similarity of structural dynamicity measured using Dynamic Time Warping (DTW) Technique | ||
| Temporal similarity of neighbourhood dynamicity measured using Dynamic Time Warping (DTW) Technique | ||
| Correlation between structural dynamicity of two non-connected actors computed using Pearson correlation | ||
| Correlation between neighbourhood dynamicity of two non-connected actors computed using Pearson correlation | ||
| Similarity by the abundance of structural and neighbourhood dynamicity between two non-connected actors computed using Bray–Curtis dissimilarity measure |
| Dataset | Actors | Links | Training Duration | Testing Duration | Sampling Interval | SINs | ||
|---|---|---|---|---|---|---|---|---|
| Start | End | Start | End | |||||
| 96 | 1,086,404 | 14 September 2004 | 31 January 2005 | 1 February 2005 | 5 May 2005 | 1 day | 140 | |
| 7 days | 20 | |||||||
| 30 days | 5 | |||||||
| 167 | 82,927 | 2 January 2010 | 31 July 2010 | 1 August 2010 | 30 September 2010 | 1 day | 186 | |
| 7 days | 31 | |||||||
| 30 days | 8 | |||||||
| 1899 | 61,734 | 24 March 2004 | 31 May 2004 | 1 June 2004 | 26 October 2004 | 1 day | 45 | |
| 7 days | 7 | |||||||
| 30 days | 3 | |||||||
| 11,715 | 42,698 | 1 January 2007 | 31 March 2007 | 1 April 2007 | 30 April 2007 | 1 day | 90 | |
| 7 days | 13 | |||||||
| 30 days | 3 | |||||||
| 14,370 | 39,124 | 14 September 2010 4 a.m. | 14 October 2010 4 a.m. | 14 October 2010 4 a.m. | 15 October 2010 4 a.m. | 6 h | 121 | |
| 12 h | 61 | |||||||
| 24 h | 31 | |||||||
| 6798 | 290,597 | 1 October 1993 | 31 December 1998 | 1 January 1999 | 10 December 1999 | 1 year | 6 | |
| 16,959 | 2,322,259 | 15 March 1992 | 31 December 1998 | 1 January 1999 | 31 December 1999 | 1 year | 7 | |
| Undirected Network | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| RandomForest | |||||||||
| Accuracy (%) | AUCROC | AUCPR | |||||||
| Days | 1 | 7 | 30 | 1 | 7 | 30 | 1 | 7 | 30 |
| 82.19 | 80.52 | 84.91 | 0.683 | 0.663 | 0.700 | 0.30 | 0.46 | 0.29 | |
| 76.29 | 87.47 | 88.23 | 0.714 | 0.644 | 0.724 | 0.40 | 0.32 | 0.31 | |
| 89.46 | 84.95 | 84.67 | 0.764 | 0.713 | 0.654 | 0.34 | 0.29 | 0.29 | |
| 85.03 | 84.98 | 85.33 | 0.687 | 0.636 | 0.773 | 0.39 | 0.36 | 0.43 | |
| Bagging | |||||||||
| 70.69 | 71.71 | 71.77 | 0.611 | 0.614 | 0.671 | 0.33 | 0.44 | 0.31 | |
| 77.22 | 77.69 | 75.96 | 0.656 | 0.594 | 0.603 | 0.34 | 0.27 | 0.33 | |
| 84.47 | 83.81 | 82.99 | 0.630 | 0.619 | 0.632 | 0.29 | 0.31 | 0.28 | |
| 73.11 | 72.80 | 72.22 | 0.622 | 0.588 | 0.644 | 0.35 | 0.32 | 0.39 | |
| Logistic Regression | |||||||||
| 73.30 | 72.22 | 72.68 | 0.536 | 0.613 | 0.590 | 0.26 | 0.38 | 0.22 | |
| 78.23 | 77.91 | 78.13 | 0.654 | 0.637 | 0.563 | 0.36 | 0.30 | 0.25 | |
| 85.25 | 84.73 | 84.64 | 0.628 | 0.573 | 0.619 | 0.29 | 0.26 | 0.22 | |
| 75.44 | 75.22 | 75.03 | 0.664 | 0.618 | 0.579 | 0.40 | 0.35 | 0.27 | |
| Directed Network | |||||||||
| RandomForest | |||||||||
| Hours | 6 | 12 | 24 | 6 | 12 | 24 | 6 | 12 | 24 |
| 87.87 | 87.59 | 87.03 | 0.739 | 0.712 | 0.720 | 0.36 | 0.26 | 0.26 | |
| Bagging | |||||||||
| 85.81 | 84.55 | 85.11 | 0.695 | 0.644 | 0.574 | 0.21 | 0.21 | 0.19 | |
| Logistic Regression | |||||||||
| 88.11 | 88.13 | 88.01 | 0.735 | 0.712 | 0.622 | 0.32 | 0.26 | 0.23 | |
| Co-Authorship Network (Window Size = 1 Year) | |||||||||
| RandomForest | |||||||||
| Accuracy | AUCROC | AUCPR | |||||||
| 77.90 | 0.663 | 0.49 | |||||||
| 81.49 | 0.722 | 0.18 | |||||||
| Bagging | |||||||||
| 81.35 | 0.702 | 0.56 | |||||||
| 80.95 | 0.711 | 0.32 | |||||||
| Logistic Regression | |||||||||
| 66.45 | 0.593 | 0.43 | |||||||
| 70.90 | 0.581 | 0.11 | |||||||
| Feature Name | Information Gain | Chi-Square Attribute Evaluation | Support Vector Machine Evaluator | Random Forest Evaluator | Total |
|---|---|---|---|---|---|
| 5 | 5 | 1 | 4 | 15 | |
| 2 | 2 | 5 | 1 | 10 | |
| 3 | 3 | 3 | 5 | 14 | |
| 4 | 4 | 4 | 3 | 15 | |
| 1 | 1 | 2 | 2 | 6 | |
| 5 | 5 | 3 | 3 | 16 | |
| 2 | 2 | 1 | 2 | 7 | |
| 3 | 3 | 5 | 1 | 12 | |
| 4 | 4 | 2 | 4 | 14 | |
| 1 | 1 | 4 | 5 | 11 | |
| 2 | 2 | 1 | 2 | 7 | |
| 1 | 1 | 2 | 1 | 5 | |
| 5 | 5 | 3 | 4 | 17 | |
| 4 | 4 | 5 | 5 | 18 | |
| 3 | 3 | 4 | 3 | 13 | |
| 3 | 3 | 4 | 3 | 13 | |
| 1 | 1 | 3 | 1 | 6 | |
| 5 | 5 | 5 | 5 | 20 | |
| 2 | 2 | 1 | 2 | 7 | |
| 4 | 4 | 2 | 4 | 14 | |
| 2 | 2 | 1 | 2 | 7 | |
| 1 | 1 | 2 | 1 | 5 | |
| 5 | 5 | 5 | 3 | 18 | |
| 4 | 4 | 4 | 5 | 17 | |
| 3 | 3 | 3 | 4 | 13 | |
| 2 | 2 | 3 | 1 | 8 | |
| 1 | 1 | 5 | 3 | 10 | |
| 5 | 5 | 1 | 5 | 16 | |
| 3 | 3 | 2 | 2 | 13 | |
| 4 | 4 | 4 | 4 | 16 | |
| 5 | 5 | 2 | 4 | 16 | |
| 3 | 3 | 1 | 1 | 8 | |
| 2 | 2 | 3 | 2 | 9 | |
| 1 | 1 | 5 | 5 | 12 | |
| 4 | 4 | 4 | 3 | 15 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choudhury, N.; Uddin, S. Evolutionary Features for Dynamic Link Prediction in Social Networks. Appl. Sci. 2023, 13, 2913. https://doi.org/10.3390/app13052913
Choudhury N, Uddin S. Evolutionary Features for Dynamic Link Prediction in Social Networks. Applied Sciences. 2023; 13(5):2913. https://doi.org/10.3390/app13052913
Chicago/Turabian StyleChoudhury, Nazim, and Shahadat Uddin. 2023. "Evolutionary Features for Dynamic Link Prediction in Social Networks" Applied Sciences 13, no. 5: 2913. https://doi.org/10.3390/app13052913
APA StyleChoudhury, N., & Uddin, S. (2023). Evolutionary Features for Dynamic Link Prediction in Social Networks. Applied Sciences, 13(5), 2913. https://doi.org/10.3390/app13052913