1. Introduction
In recent years, sensor technologies have been significantly developed to help generate large data at a relatively low cost [
1]. The fields of the Internet of Things (IoT) [
2], precision medicine [
3], and industry 4.0 [
4] produce advanced, large temporally annotated data. The analysis of this large temporal data, as it is, is a dilemma for researchers and data scientists. Thus, it encourages the reduction of large time-series data into smaller series and captures ample characteristics of primary data to improve the analysis. The resulting time series is the basis of machine learning applications, such as analysis of heartbeat [
5] and respiratory rate [
6], identification of high-risk patients who are at increased risk of infection [
7], optimization of a production line [
8], or incident detection over cloud [
9]. The reduction of large data to feature-based representation is crucial, as the implementation of the machine learning algorithm is straightforward, but the selection of well-discriminating features is a challenging task [
10].
Time-series data are a sequence of measurements/observations sequentially taken in time [
11]. In the context of stress, time-series data are referred to as a collection of data points over a period that measures the psychological or physiological responses of an individual to any applied stressor. These data points are collected at regular intervals (per second, per minute, or hour) and include measurements of respiratory rate, heart rate, cortisol levels, blood pressure, or a self-reporting stress level. The time-series data are analysed to understand the stress patterns over time, which provides better insights into how an individual’s stress levels change in response to different stressors and interventions. The learnings can be then used to develop algorithms or classification models to predict individuals’ stress conditions based on their response to stress.
Considering
as a set of time-series data, where
. To use
set as an input to supervised or unsupervised classification algorithms, each time-series
must be mapped to a well-defined feature vector with
dimensions (
) [
12]. The most efficient and effective way of feature extraction is to characterize the time-series data into a distribution of data, stationarity, correlation properties, entropy, and non-linear time-series analysis [
13,
14,
15,
16]. The extraction of only significant features is vital for both regression and classification tasks, as the irrelevant features will weaken the algorithm’s ability to generalize beyond the training set and causes overfitting [
17].
Stress can be defined as a disturbance in the homeostatic balance of the body. Activation of the stress response triggers the sympathetic nervous system and inhibition of the parasympathetic system, which causes the release of stress hormones. These hormones change the heart rate, blood supply to muscles, and respiratory rate and increase cognitive activities to cope with stressors. These stress-specific responses are commonly used to quantitively assess or monitor stress [
18,
19,
20,
21]. The statistical analysis of different physiological parameters including muscle activation, skin conductance, skin temperature, brain signals, respiratory rate, heart rate, and their variations, and classification analysis leading to shortlisting of respiratory rate and heart rate was illustrated in [
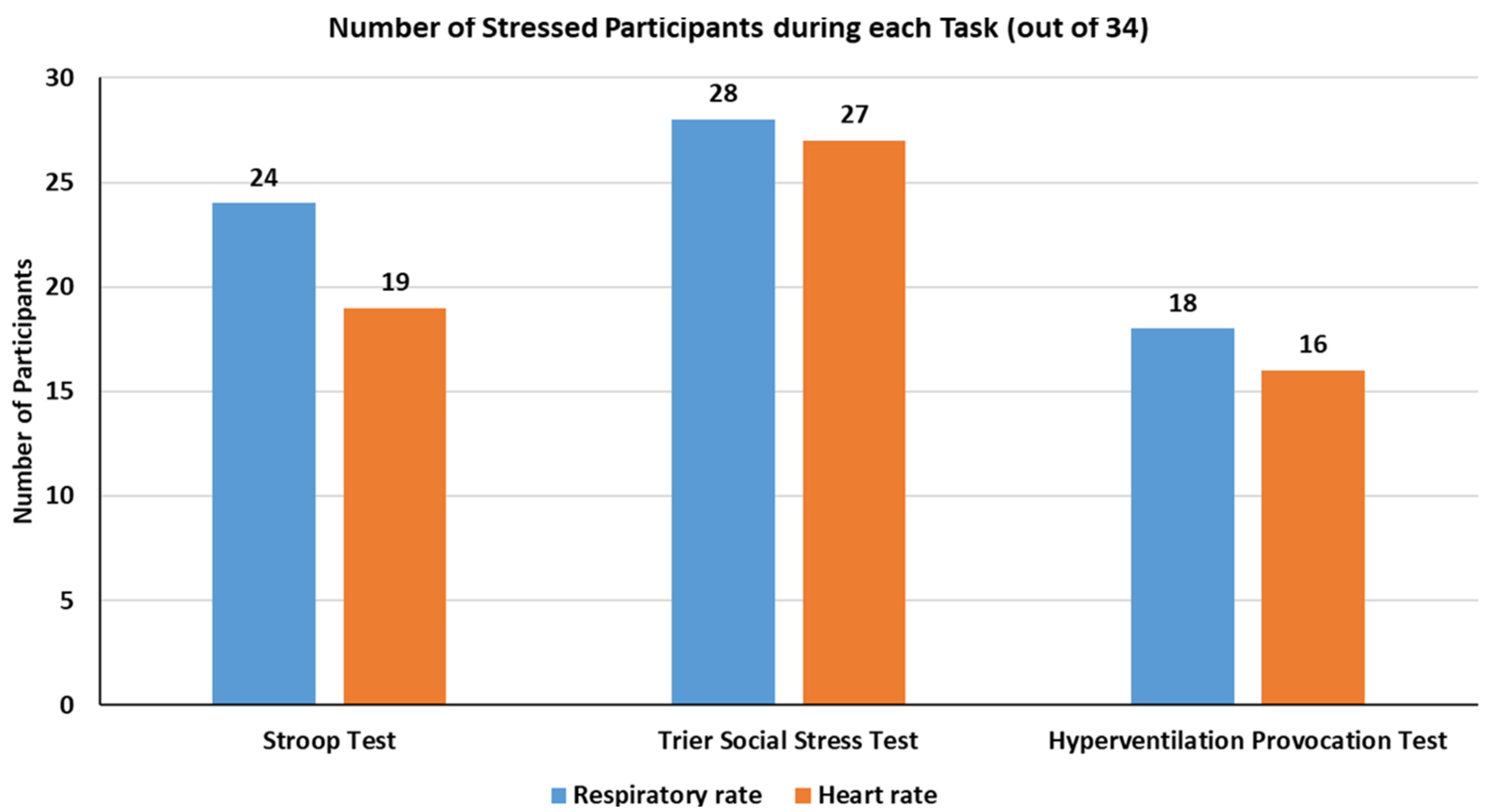
22] and also used by [
23,
24].
1.1. Related Work
Many existing stress classification studies have used trivial feature extraction and selection methods. These studies use either raw data (data collected through the sensors) [
25,
26] or common features of the collected data [
27,
28,
29], such as rate of change, mean, standard deviation, variance, mean absolute deviation, and skewness. This set of features does not fully describe the characteristics of the dataset and is also unable to be generalised to another time-series dataset. This is because the underlying patterns and characteristics of a particular dataset are specific to itself and cannot be applied to another dataset. Furthermore, the abovementioned features are also affected by the conditions under which data are collected and the pre-processing steps performed on them.
Christ et al. [
12] proposed tsfresh, a machine-learning time-series feature extraction library that has been used in several studies. The library uses a method called AutoTS (Automatic Time-Series Feature Extraction) and is based on some pre-defined feature estimation algorithms. It estimates the trends, seasonality, periodicity, and volatility of the time-series data and applies the feature selection method to select the most relevant features for further modelling or analysis. Several studies have used the tsfresh library for feature engineering. Ouyang et al. [
30] used the tsfresh feature extraction library to detect anomalous power consumption by users. They extracted 794 features that were used as input to the supervised binary classification (to detect abnormalities). However, the authors did not perform any feature selection, which makes their approach computationally expensive and not feasible to be implemented in real-time. Zhang et al. [
31] proposed unsupervised anomaly detection using DBSCAN and feature engineering. The authors used the tsfresh library in their feature engineering process. They performed features selected based on Maximum-Relevance Minimum-redundancy and variance technique along with Maximal Information Coefficient. However, the proposed approach works best with historical data (as the calculation of relevance, redundancy, and information coefficients is performed on complete data) and cannot be applied to real-world or streaming data. In the field of healthcare, Liu et al. [
32] recommended a solution for the classification of flawed sensors using tsfresh feature extraction and selection. The algorithm automatically calculated and selected features using univariate hypothesis tests with a controlled false discovery rate [
33]. The selected features were fed into a Long-Short-Term Memory (LSTM) model for classification. However, the extracted features were still over hundreds of features.
Thus, further research is required to obtain a well-generalizable feature engineering algorithm that can calculate and provide well-distinguishable features from large time-series data for an accurate and efficient classification (monitoring) system.
1.2. Motivation and Contribution
For extremely large data, the current automated feature estimation algorithms are not able to capture sufficient valuable information about the feature dynamics [
34]. The research aims of this study are to implement and explore the efficacy of the heart rate and respiratory rate signal-based (time-series) features extraction algorithm for accurate stress classification, using a stress-predict dataset [
35]. The study also determines the best (well-distinguishable) time-series feature from respiratory and heart rate signals for accurate stress monitoring. The algorithm calculates several time-series features using the tsfresh library and then performs anomaly detection (leading to feature reduction) using principal component analysis (PCA) and correlation co-efficient analysis (Pearson, Spearman, and Kendall) to shortlist the most discriminative features.
For validation of the proposed method, a combination of different extracted features is fed into supervised linear, ensemble, and clustering classifiers. The proposed method of time-series features estimation/extraction and feature selection, due to its fast computation and selection of well-distinguishable stress features, can potentially be deployed on photoplethysmography (PPG) sensor-based watches and can detect the anomalies (stress) in real-time.
The rest of the paper is organised as follows.
Section 2 discusses the stress-predict dataset and methods implemented for time-series features extraction and selection;
Section 3 reports the detailed analysis and results of supervised machine learning classification and provides discussion around the results;
Section 4 concludes the paper and provides future direction towards the development of the reliable stress-monitoring device.
3. Results and Discussions
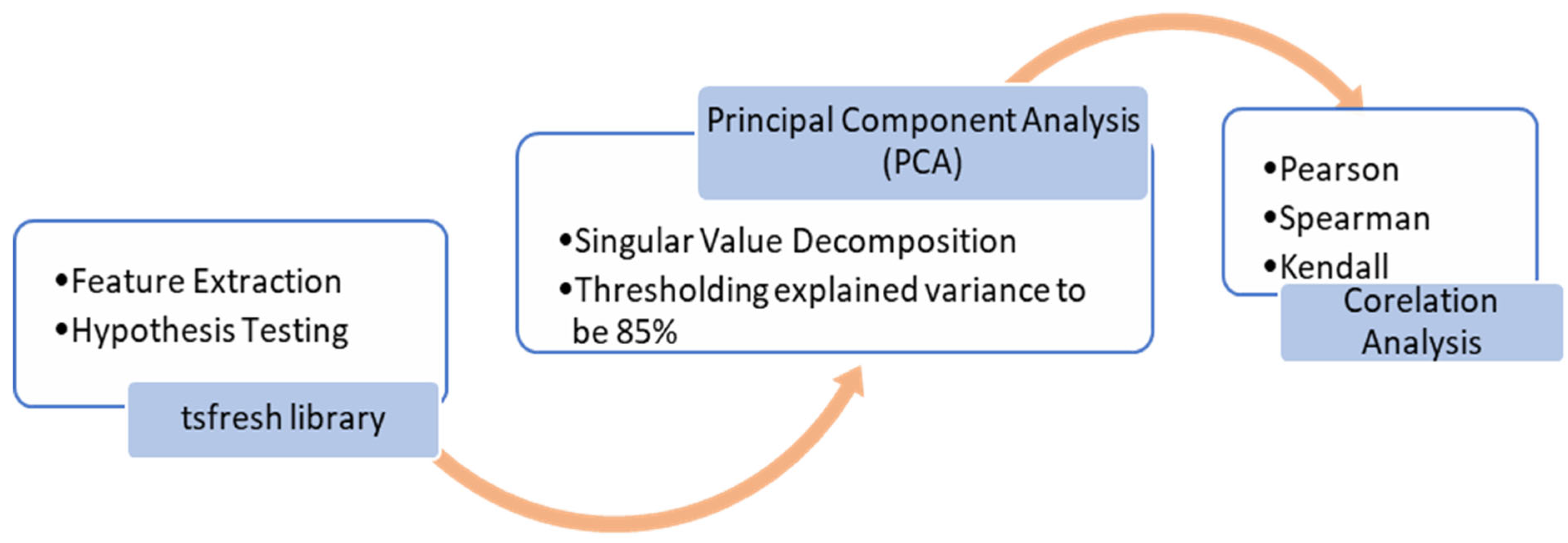
Figure 3 demonstrates the steps of feature extraction and shortlisting. For the stress-predict dataset, the tsfresh library calculates 1578 trends, seasonality, periodicity, and volatility-based features for heart rate (789) and respiratory rate (789) signals, combined. The hypothesis test (
p-value) is performed within the library to check the independence between each feature and label (target variable) and selects 314 features out of 1578 features. For further dimensionality reduction, PCA using singular value decomposition (SVD) was performed. For comparison, PCA resulted in 37 features when implemented on a full feature set (1578), while selecting only 19 features with the feature set obtained after Kruskal-Wallis’s hypothesis test (314). As the selected features might still have correlated features, a correlation analysis was performed using Pearson, Kendall, and Spearman methods to determine the most specific features of heart rate and respiratory rate signals to accurately distinguish stress conditions.
3.1. Correlation Analysis
Table 5 summarises the number of calculated and selected features at each stage.
Correlation analysis shortlisted similar features, even though they were provided with a different number of features (Filtered, PCA on full, and PCA on filtered features). The selected features are tabulated and described in
Table 6 and detailed in [
58].
It can be noted that all three (Pearson, Kendall, and Spearman) correlation analysis methods resulted in shortlisting the number of peaks within the time series, specifically for respiratory rate, as the most well-distinguishable feature for accurate stress monitoring. This finding is perfectly correlated with the previously published literature [
6,
22,
35] and is true, as the breathing pattern is supposed to significantly vary during stress conditions when compared to baseline/normal conditions.
As most of the shortlisted features belong to the respiratory rate signal, this study also performed a univariable time-series correlation analysis on the heart rate signal (only feeding the heart rate signal along with labels to the algorithm) to determine the most specific heart rate-related features. The Pearson, Kendall, and Spearman correlation analysis method determined that the ‘number_cwt_peaks_n_5′ feature (number of peaks that are at enough of a width scale (here, five) and have high signal-to-noise ratio) is the most specific feature of heart rate signal to distinguish stress from the baseline readings.
3.2. Machine Learning Classifications
For classification analysis, the commonly used statistical features (mean, standard deviation, median, median absolute deviation) and the shortlisted features after correlation analysis were used to train supervised machine learning classifiers. For supervised learning, logistic regression, random forest, and K-nearest neighbours (KNN) were selected from linear, ensemble, and clustering models, respectively. The results of each classification analysis are reported as follows.
3.2.1. Standard Statistical Features
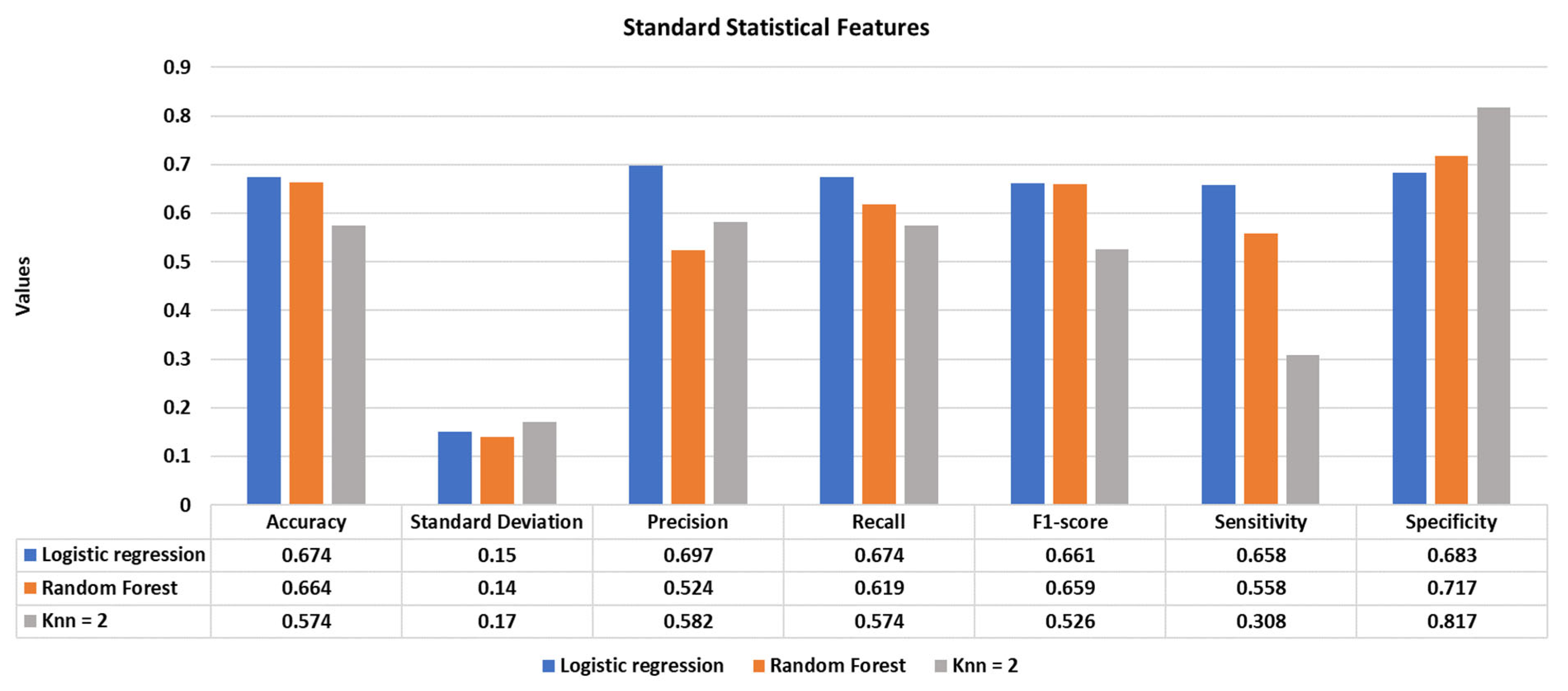
Using standard statistical features, the highest classification performance was achieved using the logistic regression model with an accuracy of 67.4%.
Figure 4 illustrates the accuracy, standard deviation, precision, recall, f1-score, specificity, and sensitivity of the reported classifiers.
3.2.2. Selected Features after Correlation Analysis
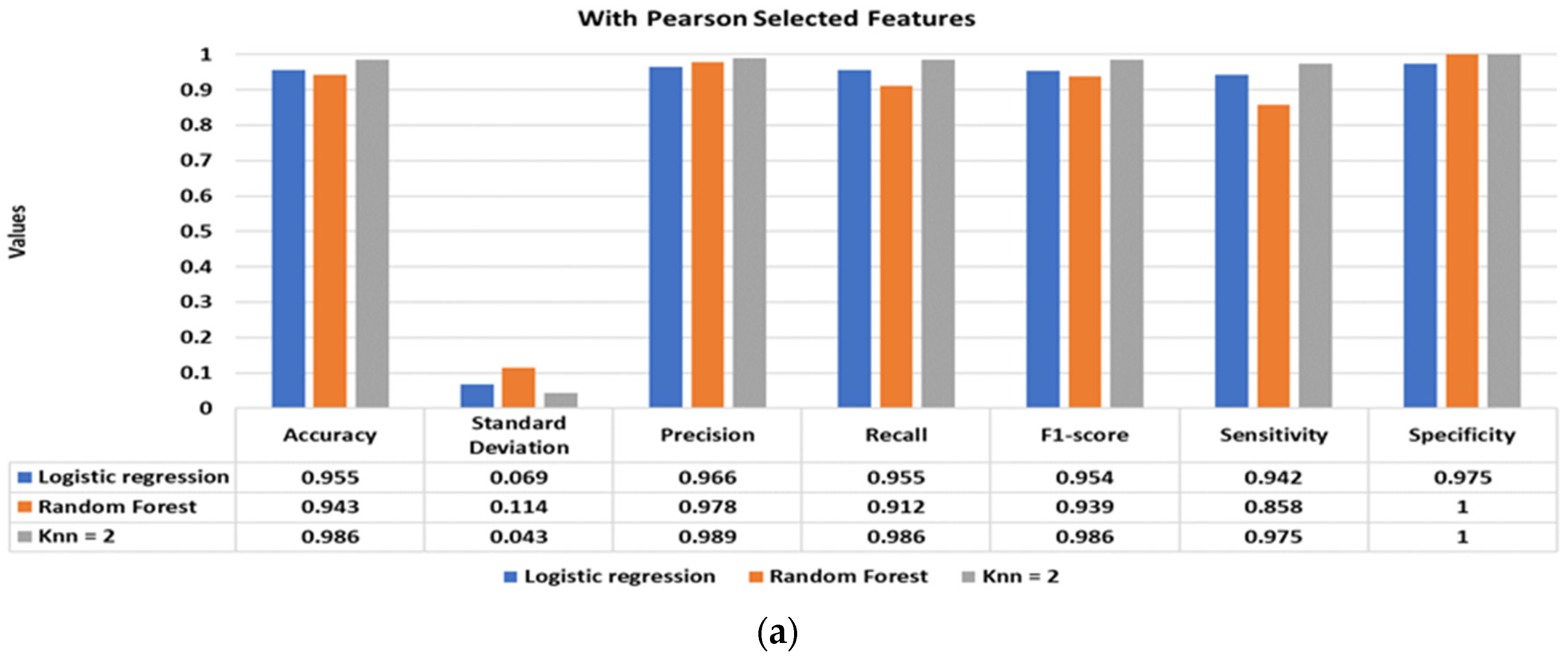
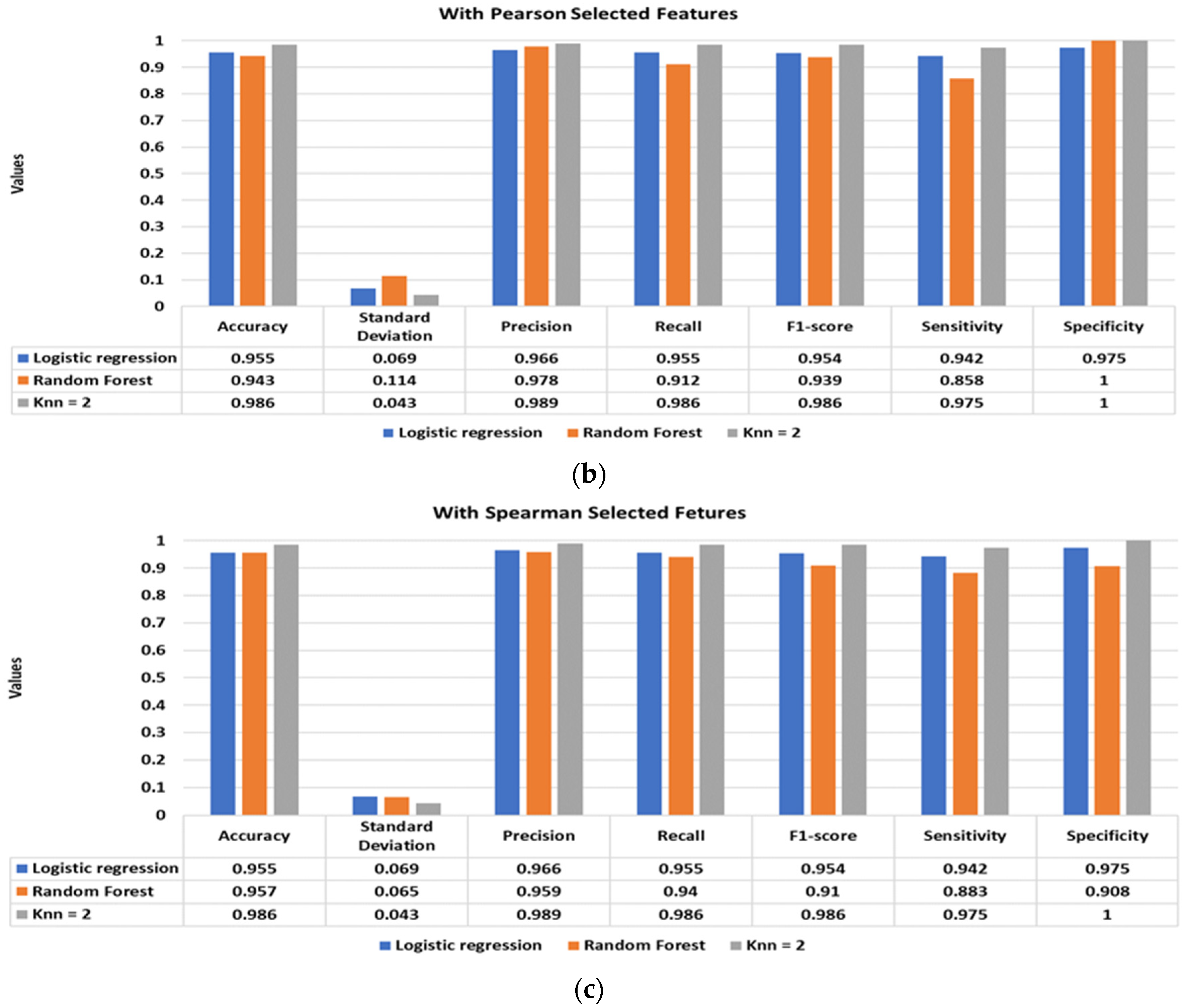
Figure 5 illustrates the classification performance of the supervised classifiers using Pearson (
Figure 5a), Kendall (
Figure 5b), and Spearman (
Figure 5c) selected features. The inclusion of the shortlisted features with the standard statistical features significantly improves the classification performance. The best classification performance is achieved using Pearson and Spearman-based features, with a classification accuracy of 98.6% using the KNN classifier. Moreover, the other performance matrices, such as standard deviation, precision, recall, f1-score, sensitivity, and specificity, of the models have also drastically improved, achieving values well above 95%.
3.3. Summary
Automated feature extraction and selection do help in the development of a highly accurate classification model that could be generalizable to new, unseen time-series data. Time-series feature engineering is a substantial component of machine learning classification analytics. The irrelevant features within the training dataset make the model overfitted to a specific dataset and are not well generalizable. Thus, systematic time-series feature engineering allows automation of the overall classification process and a reduction in the difficulties faced during manual feature estimation and selection.
In the context of stress classification, feature engineering plays a vital role in improving classification performance. The careful selection and estimation of the time-series features do help in achieving higher classification accuracy with better interpretability of the classifier’s decision and achieved results. The dimensionality reduction also helps the predictive model to be computationally efficient, especially if required to run on resource-constrained devices.
A comparison of the proposed correlation-based feature extraction algorithm with other existing methods is shown below (
Table 7).
4. Conclusions
In this study, three-fold feature extraction and selection steps are proposed. In the first step, the tsfresh library is used to calculate 1578 time-series features of heart rate and respiratory rate (789 features each) signals, which are then shortlisted to 314 features after the hypothesis test. In the second stage, PCA is applied to further reduce the feature dimensions from 314 to only 19 feature components. To detect and eliminate the most correlated features with the estimated feature list, a correlation analysis (with a threshold coefficient value of ±0.4) is performed using three different methods. The Pearson, Kendall, and Spearman correlation analysis determined the count of peaks within the respiratory rate reading to be the best and well-distinguishable feature among all other heart rate and respiratory rate-related features. For the univariate (heart rate signal) analysis, the number of CWT peaks was the most specific feature to distinguish the stress state from the baseline state.
Furthermore, this study also trained and validated different supervised machine-learning classification models using the stratified 10-fold cross-validation technique. The performance of the classification models was measured in terms of classification accuracy, standard deviation (of the model’s accuracy), precision, recall, f1-score, sensitivity, and specificity. The general statistical features (mean, standard deviation, median, mean absolute deviation) that have been frequently used in the literature give only an accuracy of 67.4%. The proposed correlation-based time-series feature selection algorithm resulted in more accurate classification performance compared to conventional statistical features. The time-series correlation analysed feature set, when used in conjunction with the statistical features, significantly improved the performance of the classifiers and resulted in high-stress classification accuracies; the highest being 98.6% using the KNN classifier.
Future work includes the translation of the proposed algorithm as an online feature learning system for real-time scenarios. The objective will be to update the selected features based on the updated data received. This would eventually lead to a more robust and accurate stress detection system. Additionally, there is a need for dynamic thresholding for PCA, as different time-series features (like heart rate, respiratory rate, skin conductance, muscle activation, and skin temperature) have different PCA subspaces. Thus, they require the estimation of best-suited thresholding levels when applying PCA. Furthermore, a comparison of other supervised and unsupervised machine learning classification models is also the prospect of future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}