
Comparison of ML/DL Approaches for Detecting DDoS Attacks in SDN



Abstract
:1. Introduction
2. Related Work
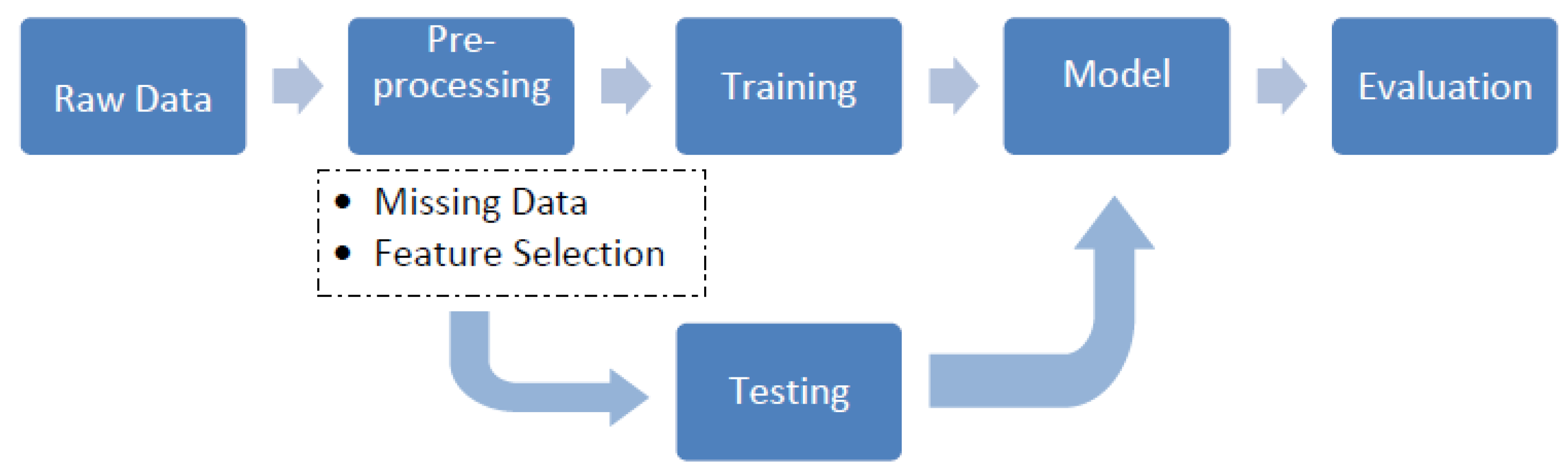
3. Method
3.1. Dataset (DS)
3.2. Pre-Processing
3.2.1. Missing Data
3.2.2. Feature Selection
3.3. ML/DL Classifiers
3.3.1. Support Vector Machine (SVM)
3.3.2. K-Nearest Neighbor (KNN)
3.3.3. Decision Tree (DT)
3.3.4. Multilayer Perceptron (MLP)
3.3.5. Convolutional Neural Network (CNN)
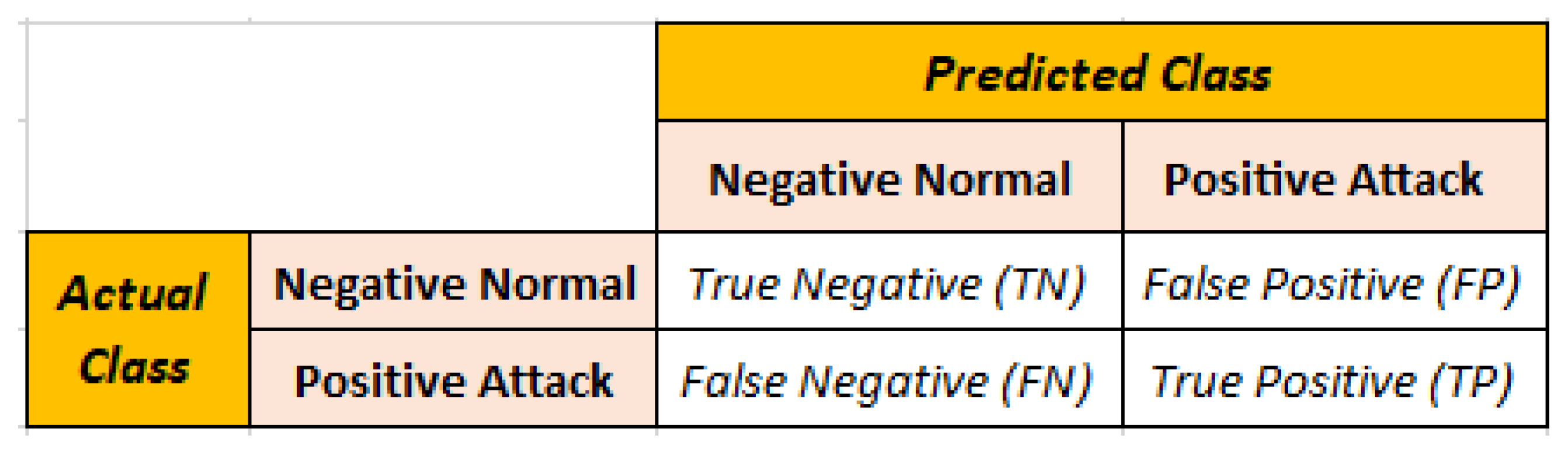
4. Measures of Performance
- Accuracy (A) measures how well it predicts the future, encompassing both positive and negative outcomes:
- Precision (P) is the proportion of all normal state predictions that are right for a given network state:
- The accuracy and recall levels are measured using the F-Measure (F):
- The Matthews correlation coefficient (MCC) is a contingency matrix technique of generating the Pearson product–moment correlation coefficient between actual and expected values. This alternative measure is unaffected by the problem of imbalanced datasets:
5. Discussion and Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ali, T.E.; Morad, A.H.; Abdala, M.A. Load balance in data center sdn networks. Int. J. Electr. Comput. Eng. 2018, 8, 3086–3092. [Google Scholar]
- Ali, T.E.; Abdala, M.A.; Morad, A.H. SDN implementation in data center network. J. Commun. 2019, 14, 223–228. [Google Scholar] [CrossRef]
- Ali, T.E.; Morad, A.H.; Abdala, M.A. Traffic management inside software-defined data center networking. Bull. Electr. Eng. Inform. 2020, 9, 2045–2054. [Google Scholar] [CrossRef]
- Yin, D.; Zhang, L.; Yang, K. A DDoS attack detection and mitigation with software-defined Internet of Things framework. IEEE Access 2018, 6, 24694–24705. [Google Scholar] [CrossRef]
- Zargar, S.T.; Joshi, J.; Tipper, D. A survey of defense mechanisms against distributed denial of service (DDoS) flooding attacks. IEEE Commun. Surveys Tutor. 2013, 15, 2046–2069. [Google Scholar] [CrossRef] [Green Version]
- Karan, B.; Narayan, D.; Hiremath, P. Detection of ddos attacks in software defined networks. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; pp. 265–270. [Google Scholar]
- Meti, N.; Narayan, D.G.; Baligar, V.P. Detection of distributed denial of service attacks using machine learning algorithms in software defined networks. In Proceedings of the IEEE Conference on Advances in Computing, Communications and Informatics, Udupi, India, 13–16 September 2017; pp. 1366–1371. [Google Scholar]
- Zekri, M.; El Kafhali, S.; Aboutabit, N.; Saadi, Y. DDoS attack detection using machine learning techniques in cloud computing environments. In Proceedings of the IEEE Conference of Cloud Computing Technologies and Applications, Rabat, Morocco, 24–26 October 2017; pp. 1–7. [Google Scholar]
- Tuan, N.N.; Hung, P.H.; Nghia, N.D.; Tho, N.V.; Phan, T.V.; Thanh, N.H. A ddos attack mitigation scheme in isp networks using machine learning based on sdn. Electronics 2020, 9, 413. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, K.S.; Tripathy, B.K.; Naik, K.; Ramasubbareddy, S.; Balusamy, B.; Khari, M.; Burgos, D. An evolutionary svm model for ddos attack detection in software defined networks. IEEE Access 2020, 8, 132502–132513. [Google Scholar] [CrossRef]
- Bakker, J.N.; Ng, B.; Seah, W.K. Can machine learning techniques be effectively used in real networks against DDoS attacks? In Proceedings of the IEEE Conference on Computer Communication and Networks, Hangzhou, China, 30 July– 2 August 2018. [Google Scholar]
- Polat, H.; Polat, O.; Cetin, A. Detecting ddos attacks in software-defined networks through feature selection methods and machine learning models. Sustainability 2020, 12, 1035. [Google Scholar] [CrossRef] [Green Version]
- Dong, S.; Sarem, M. Ddos attack detection method based on improved knn with the degree of ddos attack in software-defined networks. IEEE Access 2019, 8, 5039–5048. [Google Scholar] [CrossRef]
- Mohammed, S.S.; Hussain, R.; Senko, O.; Bimaganbetov, B.; Lee, J.; Hussain, F.; Bhuiyan, M.Z.A. A new machine learning-based collaborative DDoS mitigation mechanism in software-defined network. In Proceedings of the IEEE Conference on Wireless and Mobile Computing, Networking and Communications, Limassol, Cyprus, 15–17 October 2018. [Google Scholar]
- Niyaz, Q.; Sun, W.; Javaid, A.Y. A deep learning based DDoS detection system in software-defined networking (SDN). arXiv 2016, arXiv:1611.07400. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Chao, K.M.; Lin, H.C.; Lin, W.H.; Lo, C.C. An efficient flow control approach for SDN-based network threat detection and migration using support vector machine. In Proceedings of the IEEE Conference on e-Business Engineering, Macau, China, 4–6 November 2016; pp. 56–63. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Singapore, 8–10 August 2018; pp. 108–116. Available online: http://www.scitepress.org/DigitalLibrary/Link.aspx? (accessed on 20 November 2022).
- Ramírez-Gallego, S.; Krawczyk, B.; García, S.; Woźniak, M.; Herrera, F. A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 2017, 239, 39–57. [Google Scholar] [CrossRef]
- García, S.; Luengo, J.; Herrera, F. Tutorial on practical tips of the most influential data preprocessing algorithms in data mining. Knowl.-Based Syst. 2016, 98, 1–29. [Google Scholar] [CrossRef]
- Roy, S.S.; Mittal, D.; Biba, M.; Abraham, A. Random forest, support vector machine and nearest centroid methods for classifying network intrusion. Comput. Sci. Ser. 2016, 14, 9–17. [Google Scholar]
- WID Mining. Data mining Concept and Techniques; WID Mining: New York, NY, USA, 2006.
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative performance analysis of K-nearest neighbor (KNN) algorithm and its different variants for disease prediction. Sci. Rep. 2022, 12, 6256. [Google Scholar] [CrossRef]
- Imandoust, S.B.; Bolandraftar, M. Application of k-nearest neighbor (knn) approach for predicting economic events: Theoretical background. Int. J. Eng. Res. Appl. 2013, 3, 605–610. [Google Scholar]
- Ihsan, M.A. Reduksi Atribut Pada Algoritma K-Nearest Neighbor (KNN) Dengan Menggunakan Algoritma Genetika. Doctoral Dissertation, Universitas Sumatera Utara, Kota Medan, Indonesia, 2018. [Google Scholar]
- Universitas Sumatera Utara. Botnet Detection Using the K-Nearest Neighbor Algorithm; Universitas Sumatera Utara: Sumatera Utara, Indonesia, 2018. [Google Scholar]
- Balogun, A.O.; Balogun, A.M.; Sadiku, P.O.; Amusa, L. An ensemble approach based on decision tree and bayesian network for intrusion detection. Comput. Sci. Ser. 2017, 15, 82–91. [Google Scholar]
- Rezaeipanah, A.; Ahmadi, G. Breast cancer diagnosis using multi-stage weight adjustment in the MLP neural network. Comput. J. 2022, 65, 788–804. [Google Scholar] [CrossRef]
- Xie, Y.; Zaccagna, F.; Rundo, L.; Testa, C.; Agati, R.; Lodi, R.; Manners, D.N.; Tonon, C. Convolutional neural network techniques for brain tumor classification (from 2015 to 2022): Review, challenges, and future perspectives. Diagnostics 2022, 12, 1850. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 539–550. [Google Scholar]
- Wang, Y.; Jia, Y.; Tian, Y.; Xiao, J. Deep reinforcement learning with the confusion-matrix-based dynamic reward function for customer credit scoring. Expert Syst. Appl. 2022, 200, 117013. [Google Scholar] [CrossRef]
- Heydarian, M.; Doyle, T.E.; Samavi, R. MLCM: Multi-label confusion matrix. IEEE Access 2022, 10, 19083–19095. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | ML/DL | Exper. | Dataset | Features | Remarks |
|---|---|---|---|---|---|
| [7] | NB,SVM,NN | Mininet | Real-time | Host connections per second | In the SDN, SVM may be used as an IDS. |
| [8] | DT | VM | Self-generated | flag, TTL, and src/dst IP | A detection time of 0.6 s and accuracy of 98% for DDoS attacks. |
| [9] | KNN,DT, NN | A real testbed | CAIDA 2007 | Ports and ICMP packets per IP | A minimally intrusive defense with a flexible monitor window period. The precision may exceed 98%. |
| [10] | SVM,KNN, RF | Mininet | NSL-KDD | Unmentioned specifics | SVM model improvement. Nearly 99% of the time, it is accurate. |
| [11] | DA,SVM, KNN,NB,DT | VM | ISCX data | Number of bytes and packets, flowduration (FD), NumberOfBytes over NumberOfPackets | Although ML/DL may be used in the SDN as a classifier, choosing the right characteristics for improved detection can be challenging. |
| [12] | SVM, KNN, NN, NB | VM | Self-generated | 12 features | The detection accuracy can be increased by filtering important features via feature selection prior to training. |
| [13] | SKNN, NB, SVM | Mininet | Self-generated | Length, duration, size, and speed of the flow rate | The basic KNN model may be enhanced by adding a weight value to the neighbors. From simulation, the efficiency is astounding. |
| [14] | NB | Real testbed | NSL-KDD | 25 features selected | The proposed strategy for DDoS mitigation has yielded promising results among ISPs. |
| [15] | Soft-max, NN, Autoencoder | Real testbed | Self-generated | 34 features selected | Individual DDoS attack detection accuracy can exceed 95%, and attack categorization accuracy can exceed 99%. |
| [16] | SVM | Real testbed | KDD 1999, KDD-CUP 1999 | 30 features selected | The amount of characteristics used to categorize traffic affects accuracy. |
| Algorithm | Train Accuracy % | Prediction Accuracy % | F1-Score | MCC | Training Time (s) | Predict Time (s) | Tuning Parameter |
|---|---|---|---|---|---|---|---|
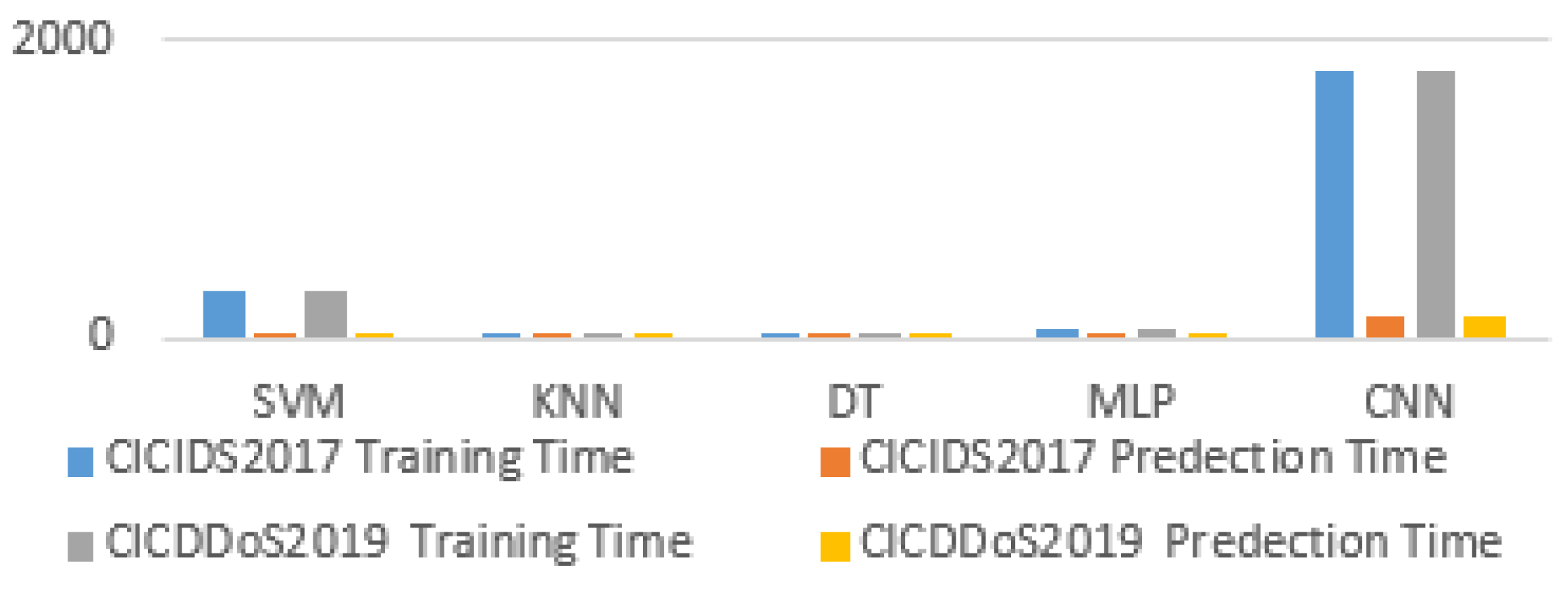
| SVM | 94.86 | 94.01 | 0.97 | 0.94 | 316.36 | 54.83 | kernel = ‘liner’, C = 1, gamma = 1, random_state = 0 |
| KNN | 90.14 | 89.16 | 0.88 | 0.802 | 0.033 | 9.46 | n_neighbors = 161, p = 2, metric = ‘euclidean’ |
| DT | 95.33 | 93.14 | 0.96 | 0.93 | 0.45 | 0.006 | max_depth = 5, random_state = 0 |
| MLP | 91.21 | 91.11 | 0.89 | 0.81 | 59.26 | 0.026 | random_state = 0, max_iter = 200, alpha = 1 |
| CNN | 95.18 | 89.61 | 0.84 | 0.96 | 1800.59 | 157.22 | Conv2D(64,(3,3), strides = (2,2), padding = ‘same’, input_shape(2,3,3), activation = ‘relu’ |
| Algorithm | Train Accuracy % | Prediction Accuracy % | F1-Score | MCC | Training Time (s) | Predict Time (s) | Tuning Parameter |
|---|---|---|---|---|---|---|---|
| SVM | 95.08 | 95.57 | 0.97 | 0.94 | 316.36 | 54.83 | kernel = ‘liner’, C = 1, gamma = 1, random_state = 0 |
| KNN | 91.23 | 90.61 | 0.88 | 0.802 | 0.033 | 9.46 | n_neighbors = 161, p = 2, metric = ‘euclidean’ |
| DT | 96.43 | 95.31 | 0.96 | 0.93 | 0.45 | 0.006 | max_depth = 5, random_state = 0 |
| MLP | 91.22 | 91.13 | 0.89 | 0.81 | 59.26 | 0.026 | random_state = 0, max_iter = 200, alpha = 1 |
| CNN | 97.81 | 90.09 | 0.84 | 0.96 | 1800.59 | 157.22 | Conv2D(64,(3,3), strides = (2,2), padding = ‘same’, input_shape(2,3,3), activation = ‘relu’ |
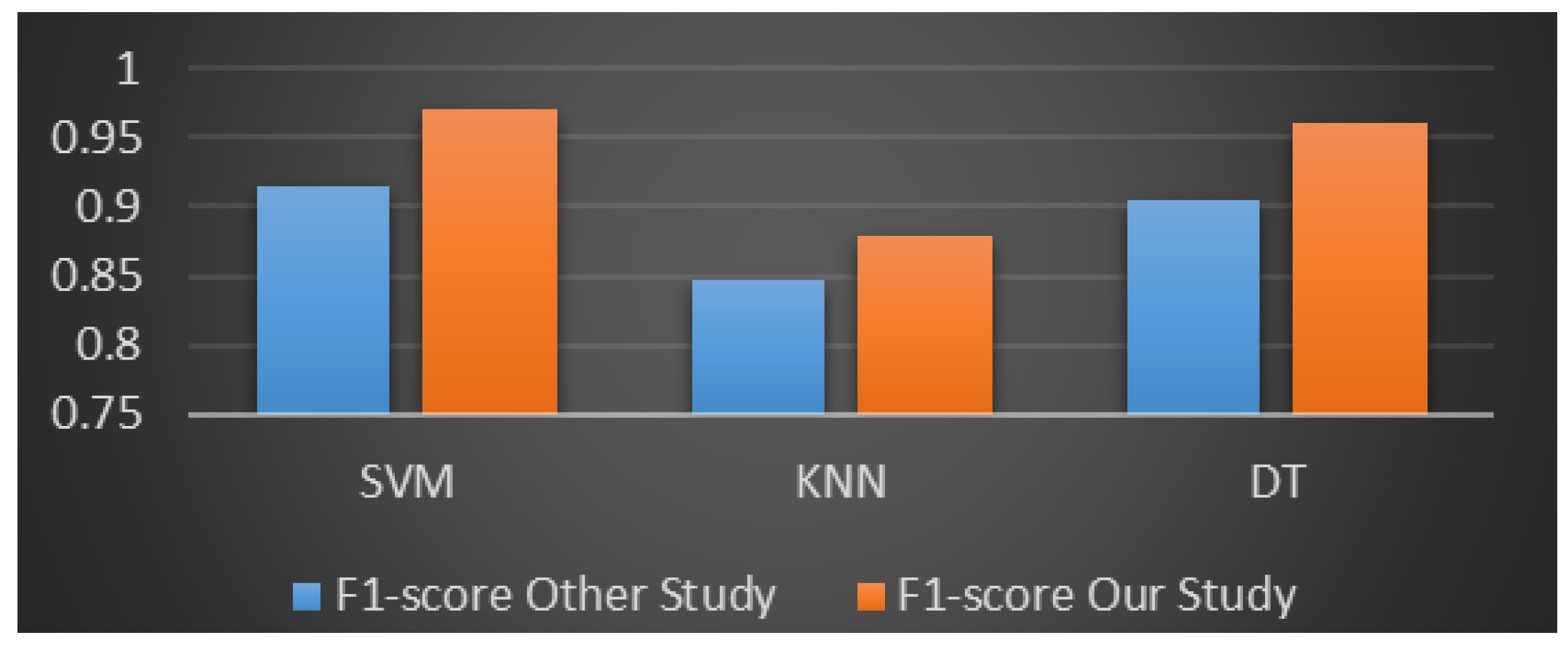
| Algo. | Ref. [8] | Ref. [9] | Ref. [10] | Ref. [11] | Ref. [12] | Ref. [13] | Ref. [14] | Ref. [15] | Ref. [16] | Ref. [17] | Our Test |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 80.12 | X | X | 94.417 | X | 92.46 | X | X | X | 94.59 | 95.08 |
| KNN | X | X | 89.21 | 88.3 | X | 89.1 | X | X | X | X | 91.23 |
| DT | X | 94.8 | 94.15 | X | X | X | X | X | X | X | 96.43 |
| Algo. | Ref. [8] | Ref. [9] | Ref. [10] | Ref. [11] | Ref. [12] | Ref. [13] | Ref. [14] | Ref. [15] | Ref. [16] | Ref. [17] | Our Test |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | X | X | X | X | 93.468 | X | X | X | X | X | 95.57 |
| KNN | X | X | X | X | 88.575 | X | X | X | X | X | 90.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, T.E.; Chong, Y.-W.; Manickam, S. Comparison of ML/DL Approaches for Detecting DDoS Attacks in SDN. Appl. Sci. 2023, 13, 3033. https://doi.org/10.3390/app13053033
Ali TE, Chong Y-W, Manickam S. Comparison of ML/DL Approaches for Detecting DDoS Attacks in SDN. Applied Sciences. 2023; 13(5):3033. https://doi.org/10.3390/app13053033
Chicago/Turabian StyleAli, Tariq Emad, Yung-Wey Chong, and Selvakumar Manickam. 2023. "Comparison of ML/DL Approaches for Detecting DDoS Attacks in SDN" Applied Sciences 13, no. 5: 3033. https://doi.org/10.3390/app13053033
APA StyleAli, T. E., Chong, Y. -W., & Manickam, S. (2023). Comparison of ML/DL Approaches for Detecting DDoS Attacks in SDN. Applied Sciences, 13(5), 3033. https://doi.org/10.3390/app13053033