



Graph-Augmentation-Free Self-Supervised Learning for Social Recommendation

Abstract
:1. Introduction
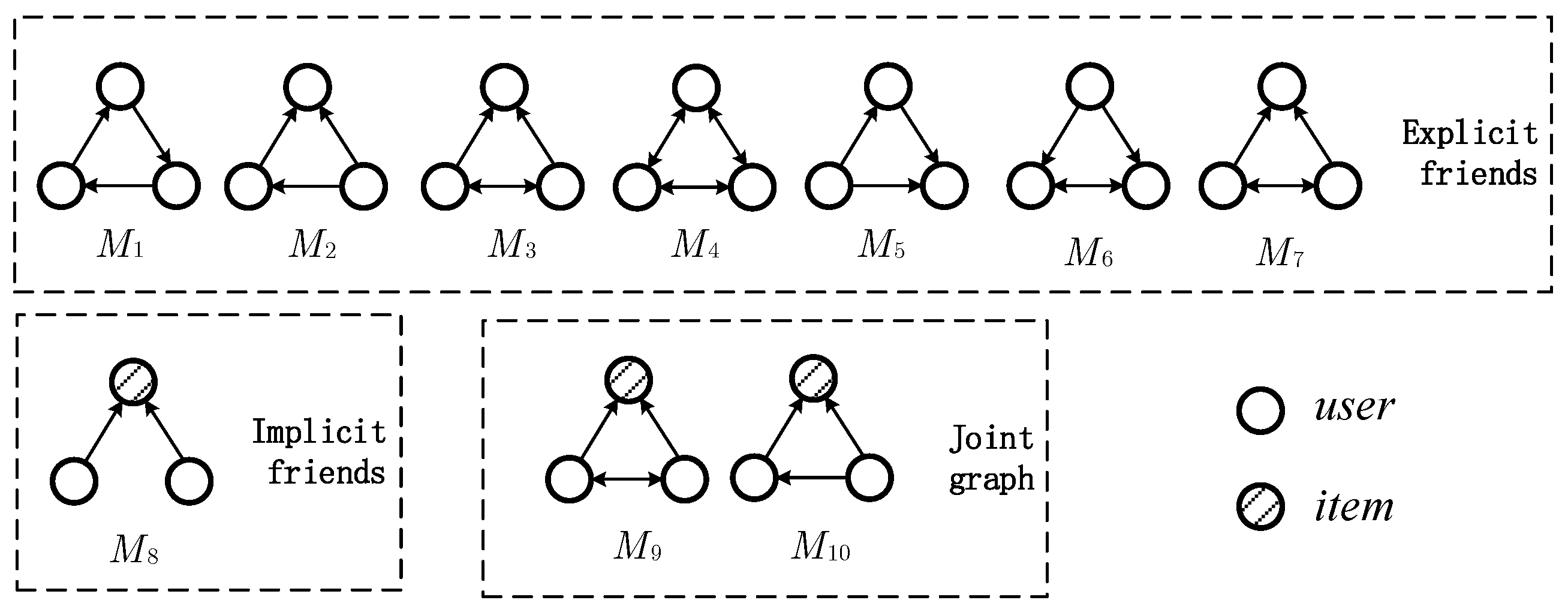
- We designed a high-order heterogeneous graph based on motifs, integrated social relations and item ratings, comprehensively modeled relational information in the network, and undertook modeling through graph convolution to capture high-order relations between users;
- We incorporated the cross-layer self-supervised contrastive learning task without graph augmentation into network training, enabling it to run more efficiently while ensuring the reliability of recommendations;
- We conducted extensive experiments with multiple real datasets, and the comparative results showed that the proposed model was superior and that the model was effective in ablation experiments.
2. Related Work
2.1. Graph-Based Recommendation
2.2. Self-Supervised Contrastive Learning
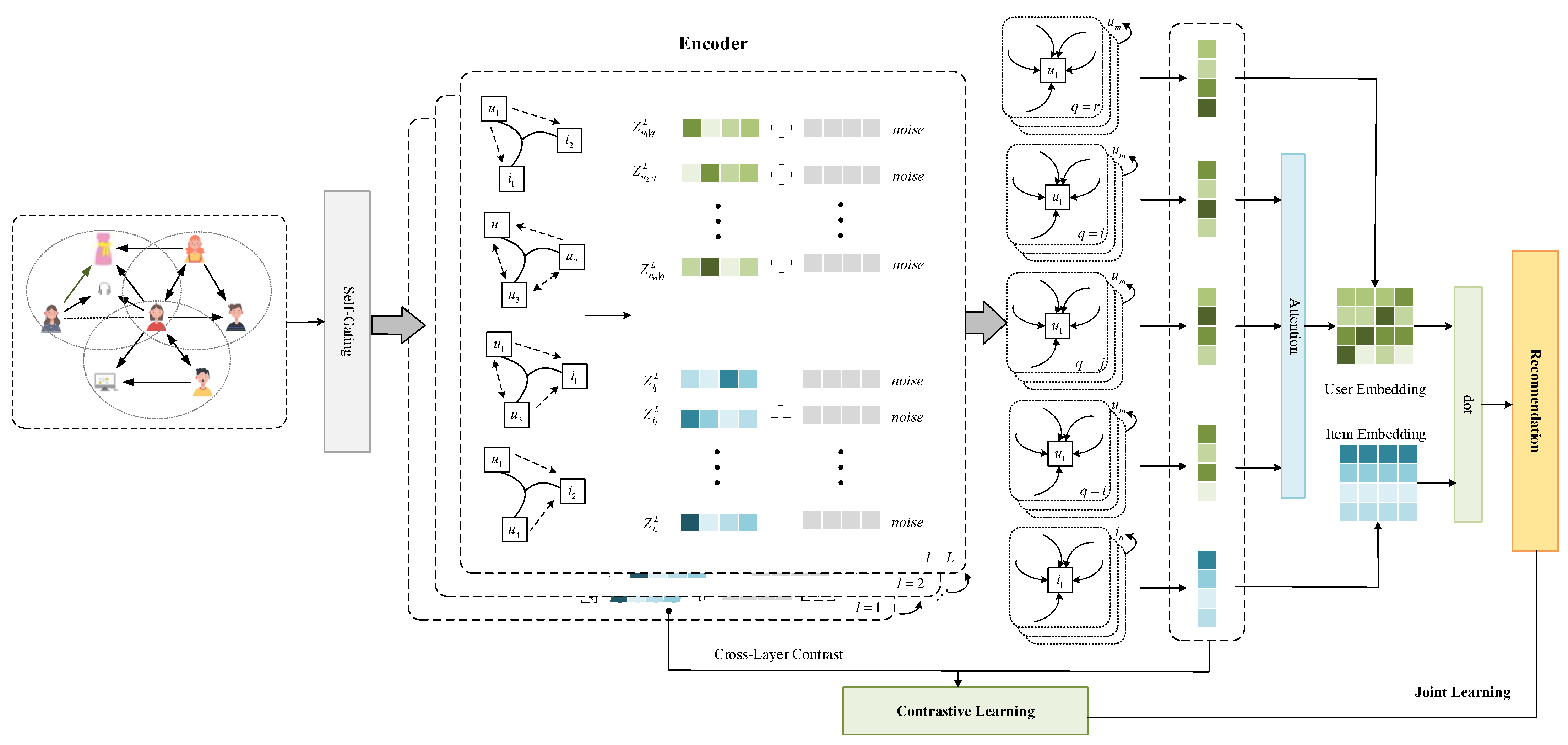
3. Proposed Model
3.1. Preliminaries
3.2. High-Order Social Information Exploitation
3.3. Graph Collaborative Filtering BackBone
3.4. Graph-Augmentation-Free Self-Supervised Learning
3.5. Complexity Analysis
4. Experiments and Results
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Baselines
- MF-based collaborative filtering models;
- BPR [23]: a popular recommendation model based on Bayesian personalized ranking;
- SBPR [28]: an MF-based social recommendation model that extends BPR and utilizes social relations to model the relative order of candidate items;
- GNN-based collaborative filtering frameworks;
- NGCF [7]: a complex GCN-based recommendation model that generates user/item representations by aggregating feature embeddings with high-order connection information;
- LightGCN [20]: a general recommendation model based on GCN, improved on the basis of NGCF by removing linear changes and activation functions;
- DiffNET++ [29]: a GNN-based social recommendation method that simultaneously simulates the recursive dynamic social diffusion of user space and item space;
- Recommendation with hypergraph neural networks;
- MHCN [9]: a social recommendation method based on a motif-based hypergraph. It aggregates high-level user information through hypergraph convolutional multi-channel embedding and utilizes auxiliary tasks to maximize the mutual information between nodes and graphs and generate self-supervised signals;
- HyperRec [13]: this method leverages the hypergraph structure to model the relationship between users and their interactive items by considering multi-order information in dynamic environments;
- HCCF [14]: a hypergraph-guided self-supervised learning recommendation model that jointly captures local and global collaborations through a hypergraph-enhanced cross-view contrastive learning architecture;
- Self-supervised learning for recommendation;
- SEPT [25]: a social recommendation model that utilizes multiple views to generate supervisory signals;
- SGL [8]: the most typical self-supervised comparative learning recommendation model, which uses structural perturbation to generate comparative views and maximizes the consistency between nodes. The experiment in this study used the structural perturbation method involving missing edges;
- BUIR [30]: this method adopts two encoders that learn from each other and randomly generates augmented views for supervised training;
- SimGCL [10]: the latest self-supervised contrastive learning recommendation model. It uses the no-image-enhancement method and only adds the final embedding obtained by adding uniform noise in the embedding space for comparison;
- NCL [31]: a prototypal structural contrastive learning recommendation model.
4.1.3. Metrics
4.1.4. Settings
4.2. Recommendation Performance
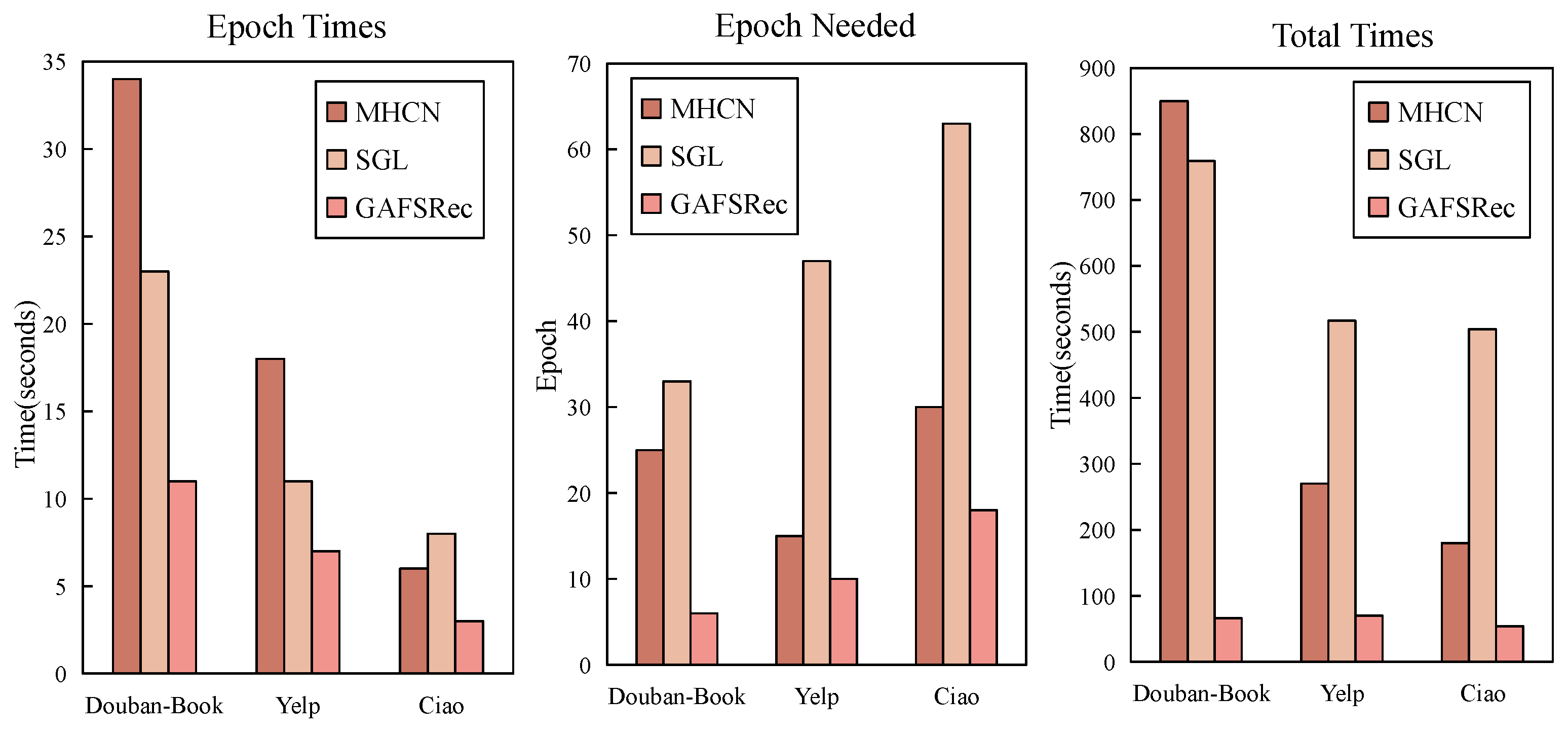
4.2.1. Comparison of Training Efficiency
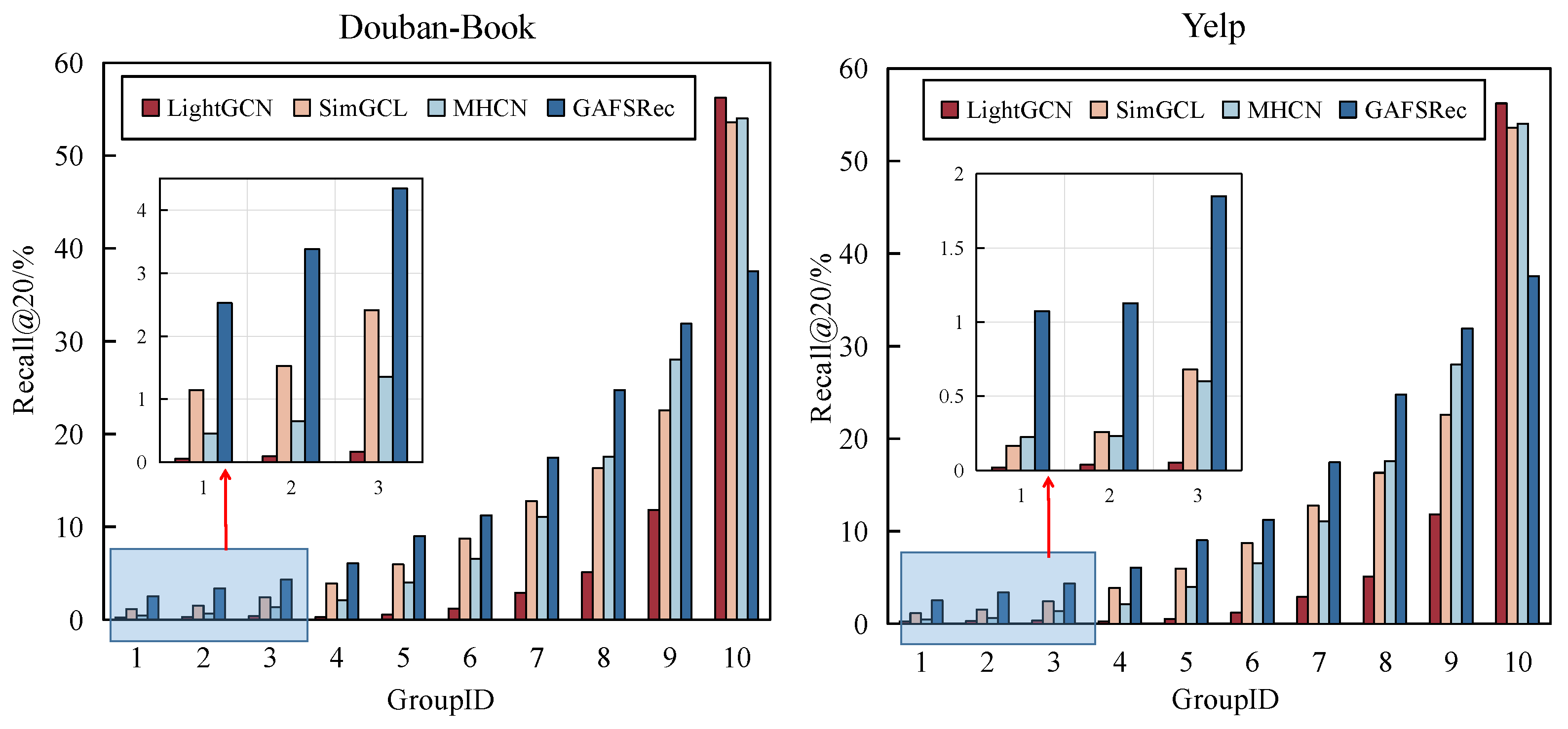
4.2.2. Comparison of Ability to Promote Long-Tail Items
4.3. Ablation Study
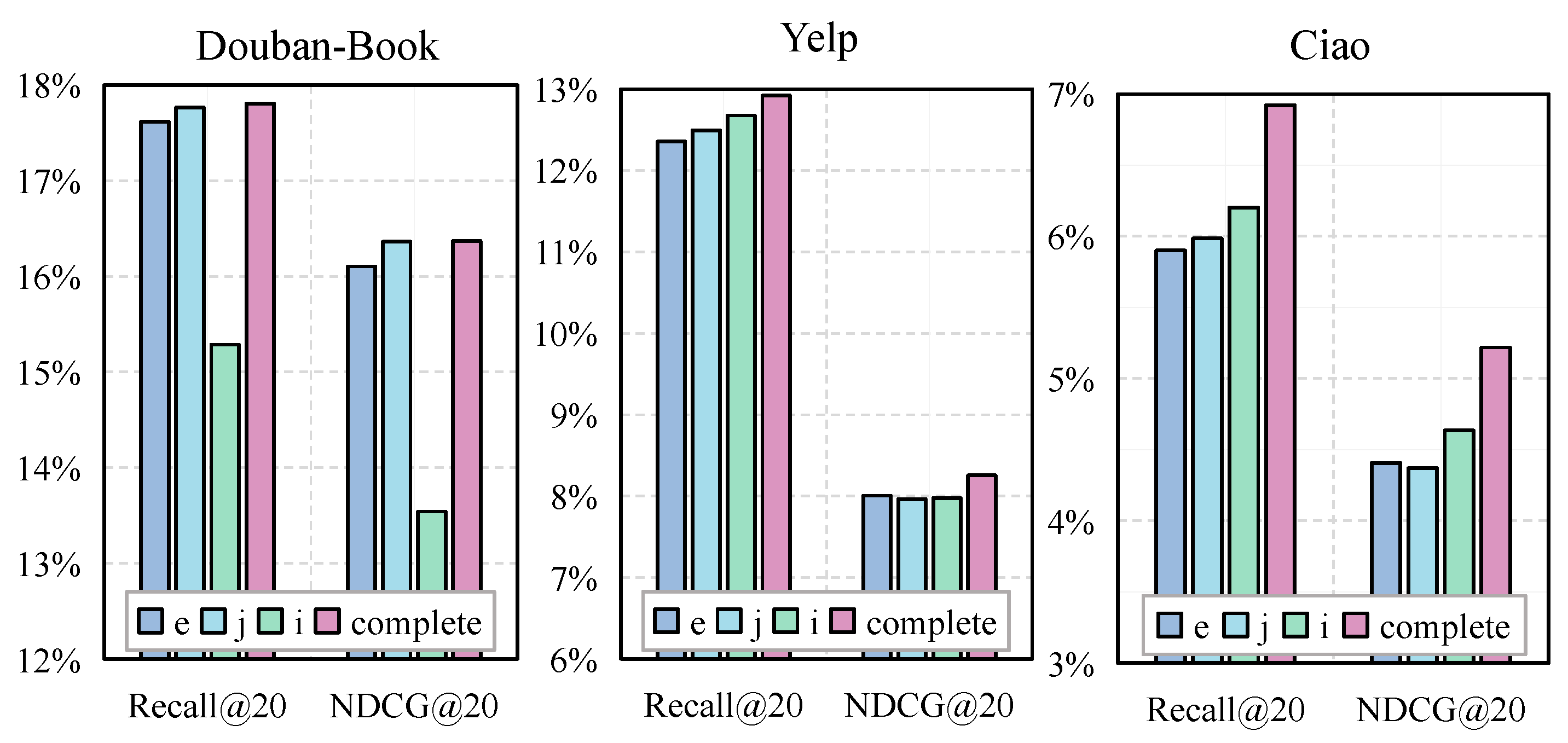
4.3.1. Investigation of Multi-Graph Setting
4.3.2. Investigation of Contrastive Learning Setting
- Removing social recommendation for contrastive learning tasks (without CL);
- Disabling cross-layer comparison and using the final embedding of each layer embedding to add uniform noise and construct two sets of views for comparison of the learning task recommendations (CL-c).
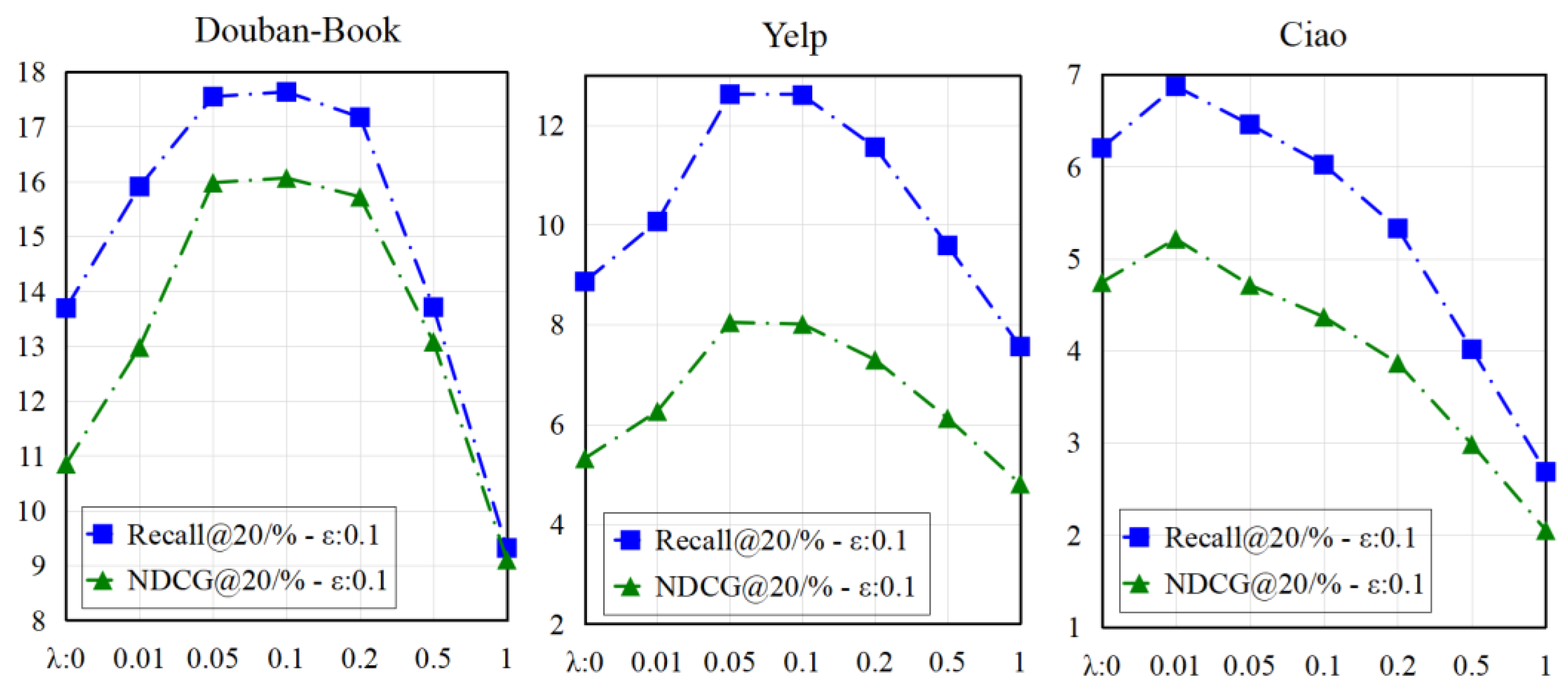
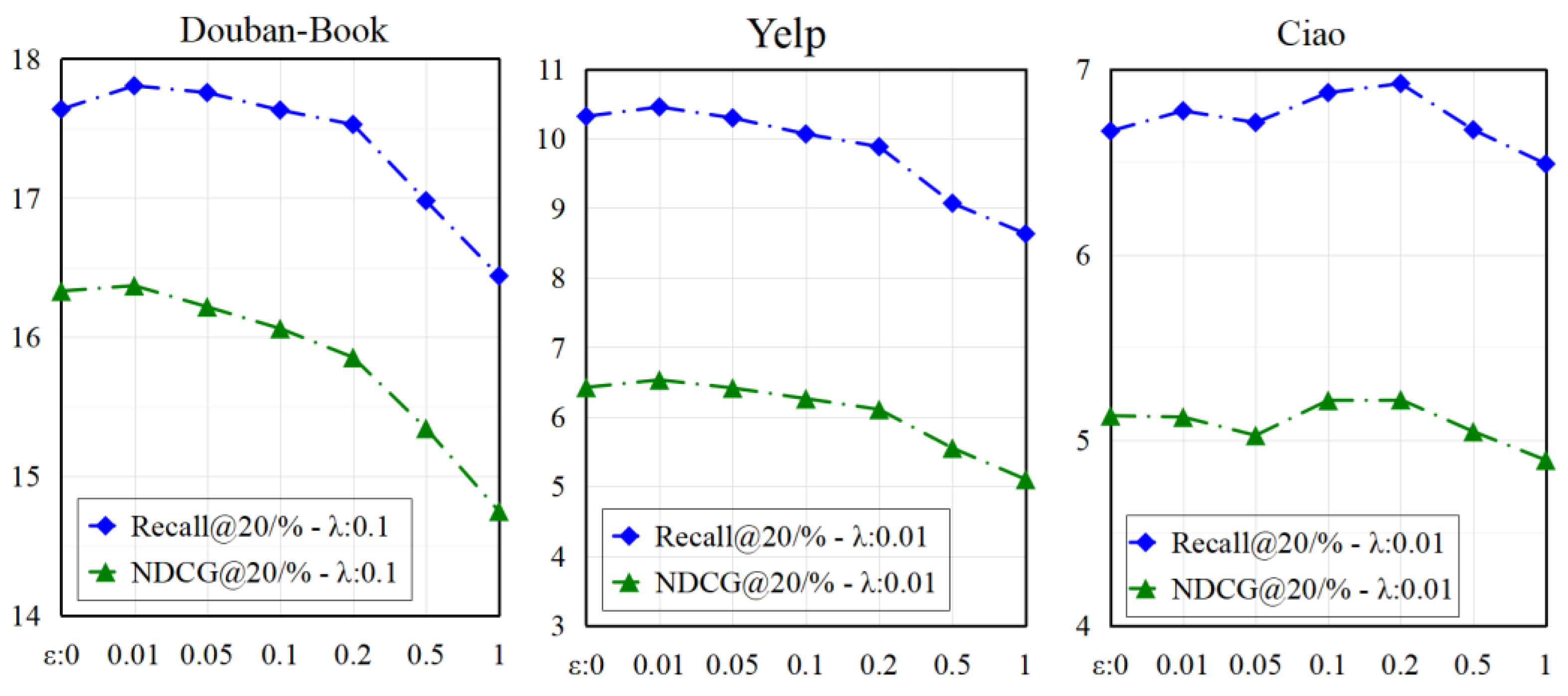
4.4. Parameter Sensitivity Analysis
4.4.1. Influence of λ and ε
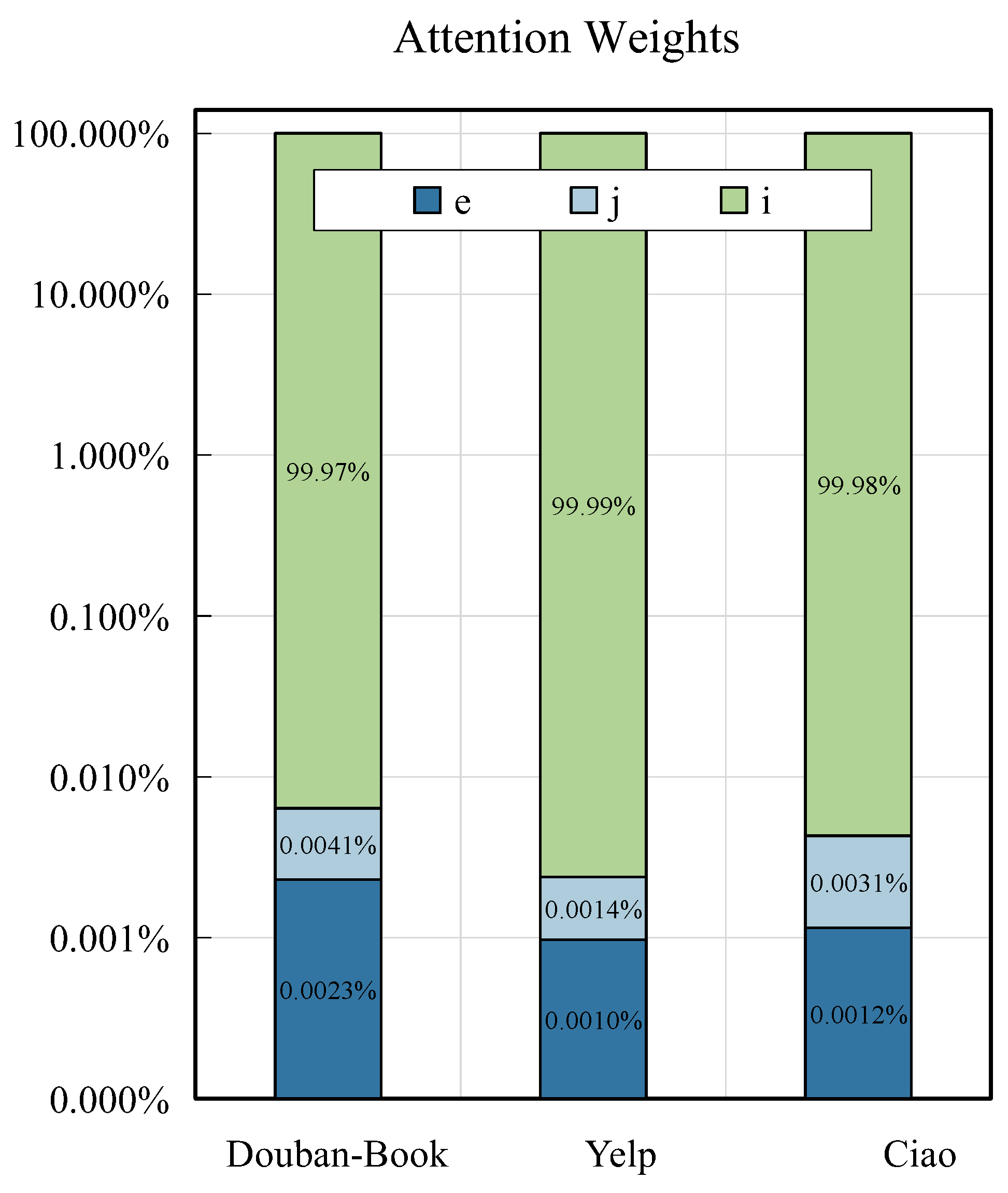
4.4.2. Layer Selection for Contrasting
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef] [Green Version]
- Cialdini, R.B.; Goldstein, N.J. Social influence: Compliance and conformity. Annu. Rev. Psychol. 2004, 55, 591–621. [Google Scholar] [CrossRef] [PubMed]
- Sarwar, B.M. Sparsity, Scalability, and Distribution in Recommender Systems; University of Minnesota: Minneapolis, MN, USA, 2001. [Google Scholar]
- Chen, J.; Dong, H.; Wang, X.; Feng, F.; Wang, M.; He, X. Bias and debias in recommender system: A survey and future directions. ACM Trans. Inf. Syst. 2020, 41, 1–39. [Google Scholar] [CrossRef]
- Tang, J.; Gao, H.; Liu, H. mTrust: Discerning multi-faceted trust in a connected world. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 93–102. [Google Scholar]
- Gao, C.; Lei, W.; Chen, J.; Wang, S.; He, X.; Li, S.; Li, B.; Zhang, Y.; Jiang, P. CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System. arXiv 2022, arXiv:2204.01266. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-supervised multi-channel hypergraph convolutional network for social recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 413–424. [Google Scholar]
- Yu, J.; Yin, H.; Xia, X.; Chen, T.; Cui, L.; Nguyen, Q.V.H. Are graph augmentations necessary? simple graph contrastive learning for recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1294–1303. [Google Scholar]
- Xia, L.; Xu, Y.; Huang, C.; Dai, P.; Bo, L. Graph meta network for multi-behavior recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 757–766. [Google Scholar]
- Huang, C.; Chen, J.; Xia, L.; Xu, Y.; Dai, P.; Chen, Y.; Bo, L.; Zhao, J.; Huang, J.X. Graph-enhanced multi-task learning of multi-level transition dynamics for session-based recommendation. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4123–4130. [Google Scholar] [CrossRef]
- Wang, J.; Ding, K.; Hong, L.; Liu, H.; Caverlee, J. Next-item recommendation with sequential hypergraphs. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 1101–1110. [Google Scholar]
- Xia, L.; Huang, C.; Xu, Y.; Zhao, J.; Yin, D.; Huang, J. Hypergraph contrastive collaborative filtering. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 70–79. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Yu, J.; Yin, H.; Xia, X.; Chen, T.; Li, J.; Huang, Z. Self-supervised learning for recommender systems: A survey. arXiv 2022, arXiv:2203.15876. [Google Scholar]
- Zhao, H.; Xu, X.; Song, Y.; Lee, D.L.; Chen, Z.; Gao, H. Ranking users in social networks with motif-based pagerank. IEEE Trans. Knowl. Data Eng. 2019, 33, 2179–2192. [Google Scholar] [CrossRef] [Green Version]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3558–3565. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L.B. Bayesian personalized ranking from implicit feedback. In Proceedings of the Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Yu, J.; Yin, H.; Gao, M.; Xia, X.; Zhang, X.; Viet Hung, N.Q. Socially-aware self-supervised tri-training for recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 2084–2092. [Google Scholar]
- Yin, H.; Wang, Q.; Zheng, K.; Li, Z.; Yang, J.; Zhou, X. Social influence-based group representation learning for group recommendation. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 566–577. [Google Scholar]
- Tao, Y.; Li, Y.; Zhang, S.; Hou, Z.; Wu, Z. Revisiting Graph based Social Recommendation: A Distillation Enhanced Social Graph Network. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2830–2838. [Google Scholar]
- Zhao, T.; McAuley, J.; King, I. Leveraging social connections to improve personalized ranking for collaborative filtering. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 261–270. [Google Scholar]
- Wu, L.; Li, J.; Sun, P.; Hong, R.; Ge, Y.; Wang, M. Diffnet++: A neural influence and interest diffusion network for social recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4753–4766. [Google Scholar] [CrossRef]
- Lee, D.; Kang, S.; Ju, H.; Park, C.; Yu, H. Bootstrapping user and item representations for one-class collaborative filtering. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 317–326. [Google Scholar]
- Lin, Z.; Tian, C.; Hou, Y.; Zhao, W.X. Improving Graph Collaborative Filtering with Neighborhood-Enriched Contrastive Learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2320–2329. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Motif | Matrix Computation | |
|---|---|---|
| Douban-Book | Yelp | Ciao | |
|---|---|---|---|
| Users (U-I graph) | 12,859 | 19,539 | 7375 |
| Users (U-U graph) | 12,748 | 30,934 | 7317 |
| Items | 22,294 | 22,228 | 105,114 |
| Feedback | 598,420 | 450,884 | 284,086 |
| Valid user pairs | 48,542,437 | 51,061,951 | 5,052,316 |
| Social pairs | 169,150 | 864,157 | 111,781 |
| Valid social pairs | 77,508 | 368,405 | 56,267 |
| Candidate user pairs | 165,353,881 | 381,772,521 | 54,390,625 |
| Valid ratio | 29.357% | 13.375% | 9.289% |
| Valid social ratio | 45.822% | 42.632% | 50.337% |
| Social density | 0.104% | 0.090% | 0.209% |
| Rating density | 0.209% | 0.104% | 0.037% |
| Social diffusity level | 1.561 | 3.187 | 5.419 |
| Valid social density | 0.160% | 0.721% | 1.114% |
| Dataset | Metric | BPR | SBPR | NGCF | LightGCN | DiffNET++ | HyperRec | MHCN | HCCF | BUIR | SLRec | SGL | SimGCL | NCL | GAFSRec | Improvement |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Douban-Book | Recall@20 | 0.0889 | 0.0918 | 0.1167 | 0.0936 | 0.0988 | 0.1394 | 0.1487 | 0.1666 | 0.0982 | 0.1400 | 0.1617 | 0.1629 | 0.1650 | 0.1781 | 6.90% |
| NDCG@20 | 0.0682 | 0.0717 | 0.0943 | 0.0770 | 0.0791 | 0.1260 | 0.1329 | 0.1421 | 0.0793 | 0.1263 | 0.1412 | 0.1422 | 0.1416 | 0.1637 | 15.17% | |
| Yelp | Recall@20 | 0.0554 | 0.0665 | 0.0891 | 0.0820 | 0.0852 | 0.1120 | 0.1174 | 0.1157 | 0.0834 | 0.1126 | 0.1146 | 0.1145 | 0.1148 | 0.1292 | 12.37% |
| NDCG@20 | 0.0289 | 0.0403 | 0.0533 | 0.0472 | 0.0496 | 0.0690 | 0.0746 | 0.0750 | 0.0482 | 0.0696 | 0.0732 | 0.0729 | 0.0741 | 0.0826 | 10.26% | |
| Ciao | Recall@20 | 0.0412 | 0.0312 | 0.0517 | 0.0555 | 0.0477 | 0.0591 | 0.0629 | 0.0647 | 0.0528 | 0.0602 | 0.0635 | 0.0642 | 0.0625 | 0.0692 | 7.07% |
| NDCG@20 | 0.0310 | 0.0252 | 0.0379 | 0.0426 | 0.0352 | 0.0400 | 0.0483 | 0.0502 | 0.0419 | 0.0468 | 0.0492 | 0.0501 | 0.0494 | 0.0522 | 3.88% |
| Dataset | Method | BPR | SBPR | NGCF | LightGCN | DiffNET++ | MHCN | HCCF | SGL | SimGCL | NCL | GAFSRec | Improvement |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Douban-Book | Recall@20 | 0.0754 | 0.1045 | 0.1135 | 0.1108 | 0.1105 | 0.1755 | 0.1877 | 0.1929 | 0.1924 | 0.1725 | 0.1972 | 2.79% |
| NDCG@20 | 0.0388 | 0.0879 | 0.0644 | 0.0631 | 0.0590 | 0.1043 | 0.1098 | 0.1154 | 0.1164 | 0.1024 | 0.1233 | 5.94% | |
| Yelp | Recall@20 | 0.0619 | 0.0696 | 0.0881 | 0.0881 | 0.0917 | 0.1258 | 0.1271 | 0.1322 | 0.1212 | 0.1150 | 0.1330 | 5.89% |
| NDCG@20 | 0.0296 | 0.0427 | 0.0415 | 0.0402 | 0.0420 | 0.0610 | 0.0662 | 0.0709 | 0.0625 | 0.0571 | 0.0669 | 11.57% | |
| Ciao | Recall@20 | 0.0416 | 0.0413 | 0.0576 | 0.0544 | 0.0519 | 0.0638 | 0.0638 | 0.0605 | 0.0627 | 0.0635 | 0.0731 | 14.51% |
| NDCG@20 | 0.0209 | 0.0251 | 0.0330 | 0.0324 | 0.0308 | 0.0340 | 0.0331 | 0.0338 | 0.0339 | 0.0338 | 0.0374 | 9.82% |
| Dataset | Douban-Book | Yelp | Ciao | |||
|---|---|---|---|---|---|---|
| Metric | Recall | NDCG | Recall | NDCG | Recall | NDCG |
| Top 20 | ||||||
| Without CL | 15.318% | 13.371% | 9.926% | 6.175% | 5.704% | 4.265% |
| CL-c | 17.716% | 16.716% | 12.870% | 8.152% | 6.644% | 4.942% |
| CL-ours | 17.806% | 16.370% | 12.922% | 8.256% | 6.922% | 5.219% |
| Top 40 | ||||||
| Without CL | 15.958% | 11.379% | 14.123% | 7.147% | 8.633% | 5.402% |
| CL-c | 23.038% | 18.055% | 18.178% | 9.815% | 8.987% | 5.737% |
| CL-ours | 22.943% | 17.724% | 18.516% | 10.045% | 8.821% | 5.628% |
| Datasets | Douban-Book | Yelp | Ciao | ||||
|---|---|---|---|---|---|---|---|
| Metric | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | |
| One layer | 1 | 17.570% | 15.866% | 12.739% | 8.127% | 6.647% | 4.982% |
| Two layers | 1 | 17.806% | 16.370% | 13.002% | 8.272% | 6.922% | 5.219% |
| 2 | 17.001% | 15.660% | 12.280% | 8.153% | 6.675% | 5.080% | |
| Three layers | 1 | 17.557% | 15.915% | 12.729% | 8.137% | 6.550% | 4.986% |
| 2 | 17.392% | 15.832% | 12.671% | 8.090% | 6.494% | 5.006% | |
| 3 | 16.170% | 14.745% | 12.202% | 7.846% | 6.456% | 4.941% | |
| Four layers | 1 | 17.035% | 15.432% | 12.427% | 7.966% | 6.303% | 4.877% |
| 2 | 16.900% | 15.417% | 12.385% | 7.888% | 6.217% | 4.856% | |
| 3 | 15.835% | 14.482% | 11.860% | 7.624% | 5.998% | 4.634% | |
| 4 | 15.276% | 13.807% | 11.211% | 7.084% | 6.159% | 4.783% | |
| Five layers | 1 | 16.761% | 15.037% | 12.057% | 7.676% | 6.129% | 4.714% |
| 2 | 16.724% | 15.137% | 11.985% | 7.636% | 6.035% | 4.685% | |
| 3 | 15.687% | 14.210% | 11.490% | 7.324% | 5.911% | 4.703% | |
| 4 | 15.132% | 13.685% | 10.962% | 6.952% | 5.924% | 4.664% | |
| 5 | 14.121% | 12.245% | 10.634% | 6.640% | 5.957% | 4.623% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, N.; Ma, X.; Liu, H.; Tang, X.; Wang, L. Graph-Augmentation-Free Self-Supervised Learning for Social Recommendation. Appl. Sci. 2023, 13, 3034. https://doi.org/10.3390/app13053034
Xiang N, Ma X, Liu H, Tang X, Wang L. Graph-Augmentation-Free Self-Supervised Learning for Social Recommendation. Applied Sciences. 2023; 13(5):3034. https://doi.org/10.3390/app13053034
Chicago/Turabian StyleXiang, Nan, Xiaoxia Ma, Huiling Liu, Xiao Tang, and Lu Wang. 2023. "Graph-Augmentation-Free Self-Supervised Learning for Social Recommendation" Applied Sciences 13, no. 5: 3034. https://doi.org/10.3390/app13053034
APA StyleXiang, N., Ma, X., Liu, H., Tang, X., & Wang, L. (2023). Graph-Augmentation-Free Self-Supervised Learning for Social Recommendation. Applied Sciences, 13(5), 3034. https://doi.org/10.3390/app13053034