
Rock Image Classification Based on EfficientNet and Triplet Attention Mechanism

Abstract
:Featured Application
Abstract
1. Introduction
- Deep learning methods were introduced to eliminate the dependence of traditional methods and machine learning methods on human intervention, so as to realize end-to-end automatic identification of rock images without requiring additional manual operations.
- A rock image classification model was constructed based on EfficientNet, which overcomes the issue of parameter redundancy and scattered attention in previous deep learning models, as well as achieving an efficient and attention-focused network structure through Neural Architecture Search, resulting in higher model accuracy compared to its predecessors.
- In view of the problem that EfficientNet neglects spatial attention information of rock images, the triplet attention mechanism [21] was introduced to improve EfficientNet and enhance its ability to extract effective rock features, further improving the accuracy of the rock classification model.
- The transfer learning method was utilized in the training process to accelerate the model convergence and significantly enhance its training performance, so as to obtain a classification model with higher accuracy using fewer rock images and less training time.
2. Materials
- (1)
- Collect rock fragments: Geological personnel collect rock fragments at the wellhead or drilling rig, using manual or mechanical tools for collection.
- (2)
- Prepare samples: After collecting rock fragments, preliminary processing such as cleaning and sieving is necessary to remove impurities and unwanted parts and obtain a sufficient number of samples of the same rock type.
- (3)
- Capture images: For each rock fragment sample, capture its image using an industrial camera or other equipment. During image capture, it is important to keep the sample in the same position and angle to ensure the comparability and repeatability of the images.
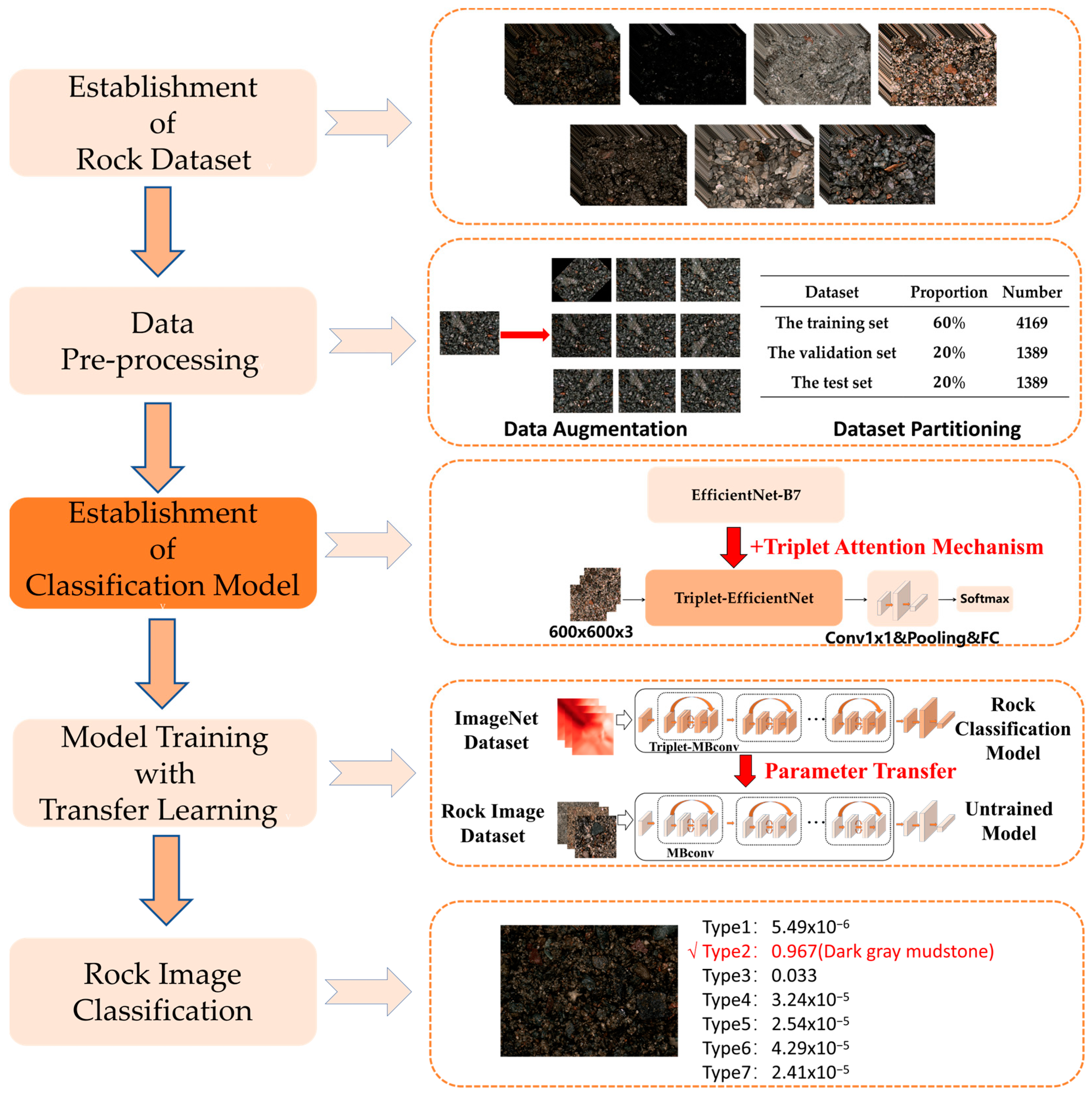
3. Method
| Algorithm 1: A Rock-type Classification Method Based on EfficientNet and Triplet Attention Mechanism |
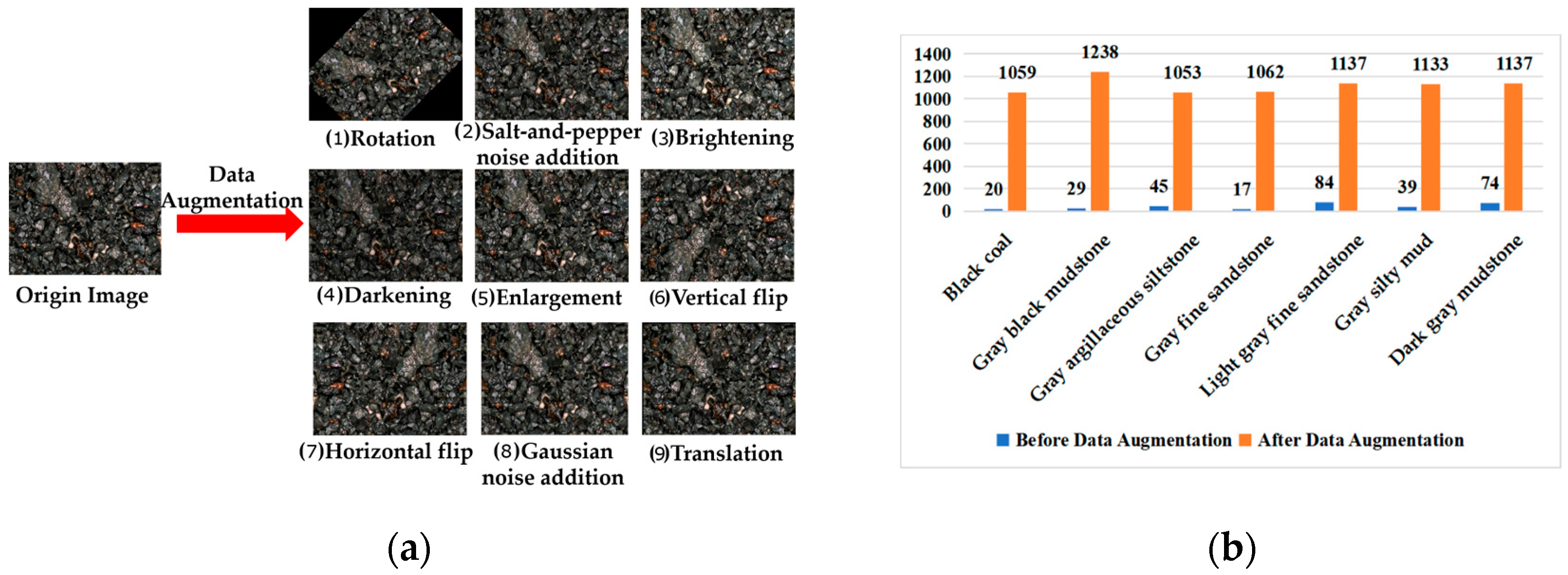
| Input: 315 rock images containing seven types of rocks 1: Perform data pre-processing. 2: Randomly apply the following nine data augmentation operations to each image: Rotation, Salt-and-pepper noise addition, Brightening, Darkening, Enlargement, Vertical flip, Horizontal flip, Gaussian noise addition, and Translation. (The number of rock images is augmented to 6949 after augmentation.) 3: Divide the augmented images randomly into a training set, a validation set, and a test set with a ratio of 60%, 20%, and 20%. (The number of samples for them is 4169, 1389, and 1389.) 4: Construct a rock-type classification model based on EfficientNet and a triplet attention mechanism. 5: Select the EfficientNet-B7 model as the baseline model. 6: Replace each SE attention module of the EfficientNet-B7 model with the triplet attention module to construct the Triplet-Efficient model. 7: Build a classification model based on the Triplet-EfficientNet model as the backbone network. 8: Add 1 × 1 convolutional layer, pooling layer, fully connected layer, and softmax classifier after Triplet-EfficientNet. 9: Set the number of types for the softmax classifier to 7. |
| 10: Start model training. 11: Use the transfer learning method: load the parameters of the pre-trained model trained on ImageNet dataset into an untrained model. 12: Set training hyperparameters: set the learning rate to 0.01, the epoch to 60, and the batch size to 16. 13: Select the Swish function as the activation function, the cross entropy function as the loss function, and Adaptive Moment Estimation(Adam) as the optimizer. 14: Uniformly scale the images in the training set to the size of 600 × 600 × 3 and randomly package them into the model to start the training. 15: Train all parameters of the transferred model for 60 epochs. 16: Output the final model after training. 17: Start testing: input a randomly selected rock image. Output: The probabilities of this rock image being classified as each type of rock. (The rock type corresponding to the maximum probability is the final identification result.) |
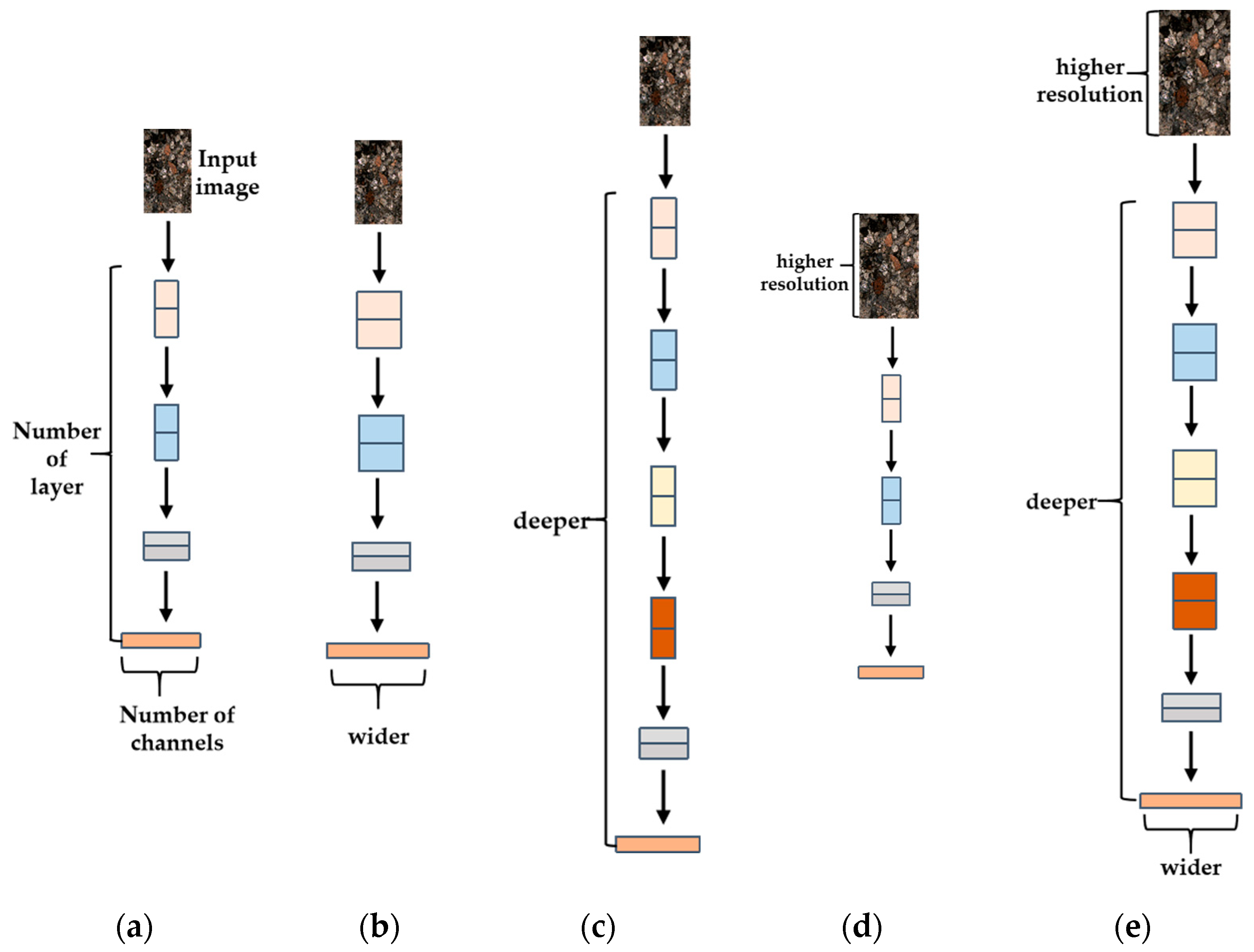
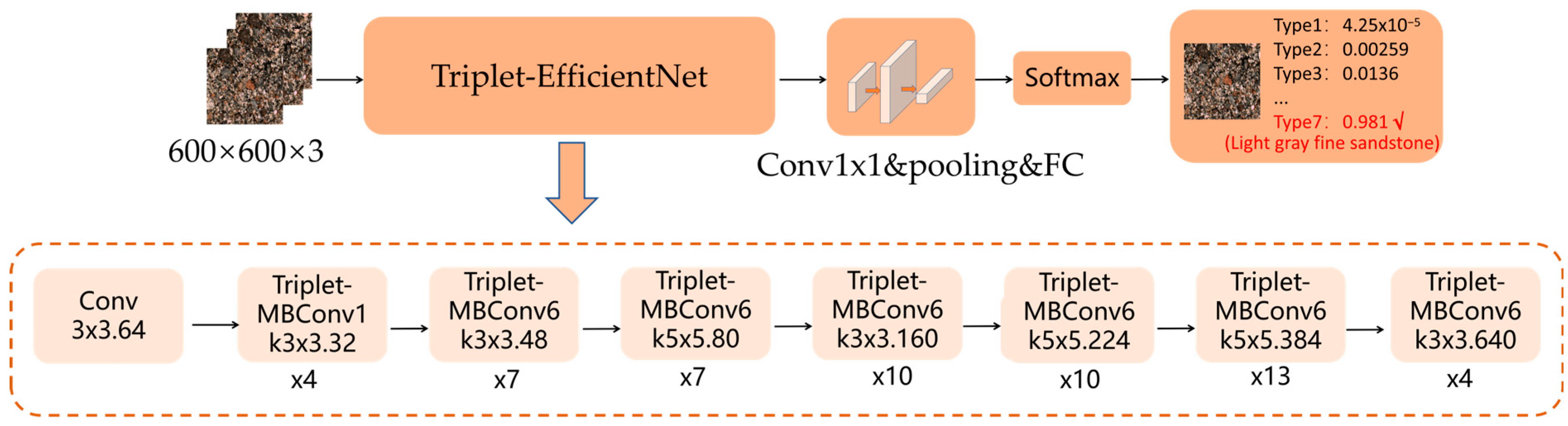
3.1. EfficientNet Neural Network
3.2. EfficientNet-B7 Model
- (1)
- Squeeze: The input feature map of size C × H × W is globally average pooled into a feature map of 1 × 1 × C, thus squeezing each two-dimensional feature channel into a single value to represent the global distribution of responses on each channel.
- (2)
- Excitation: A fully connected neural network is used to nonlinearly transform the squeezed map, generating activated weights through ReLU and Sigmoid activation functions.
- (3)
- Scale: The activated weights are used to weight each channel in the input feature map by performing dot multiplication.
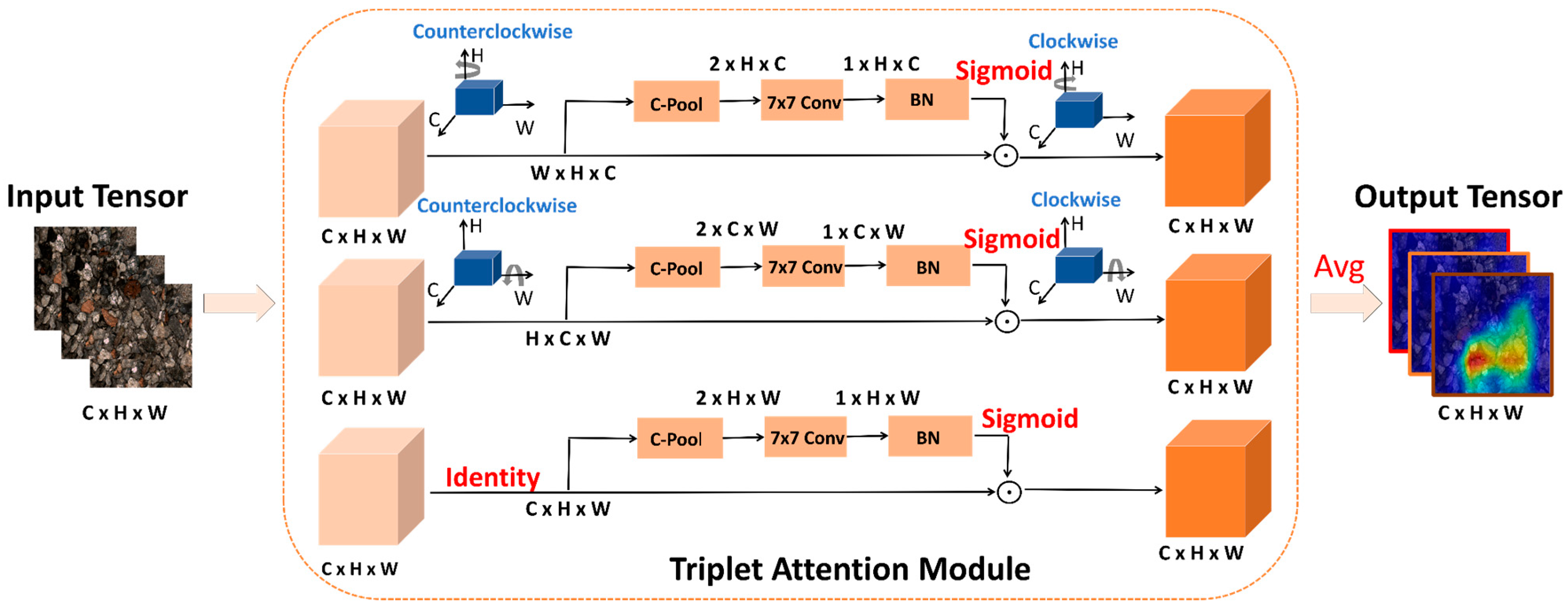
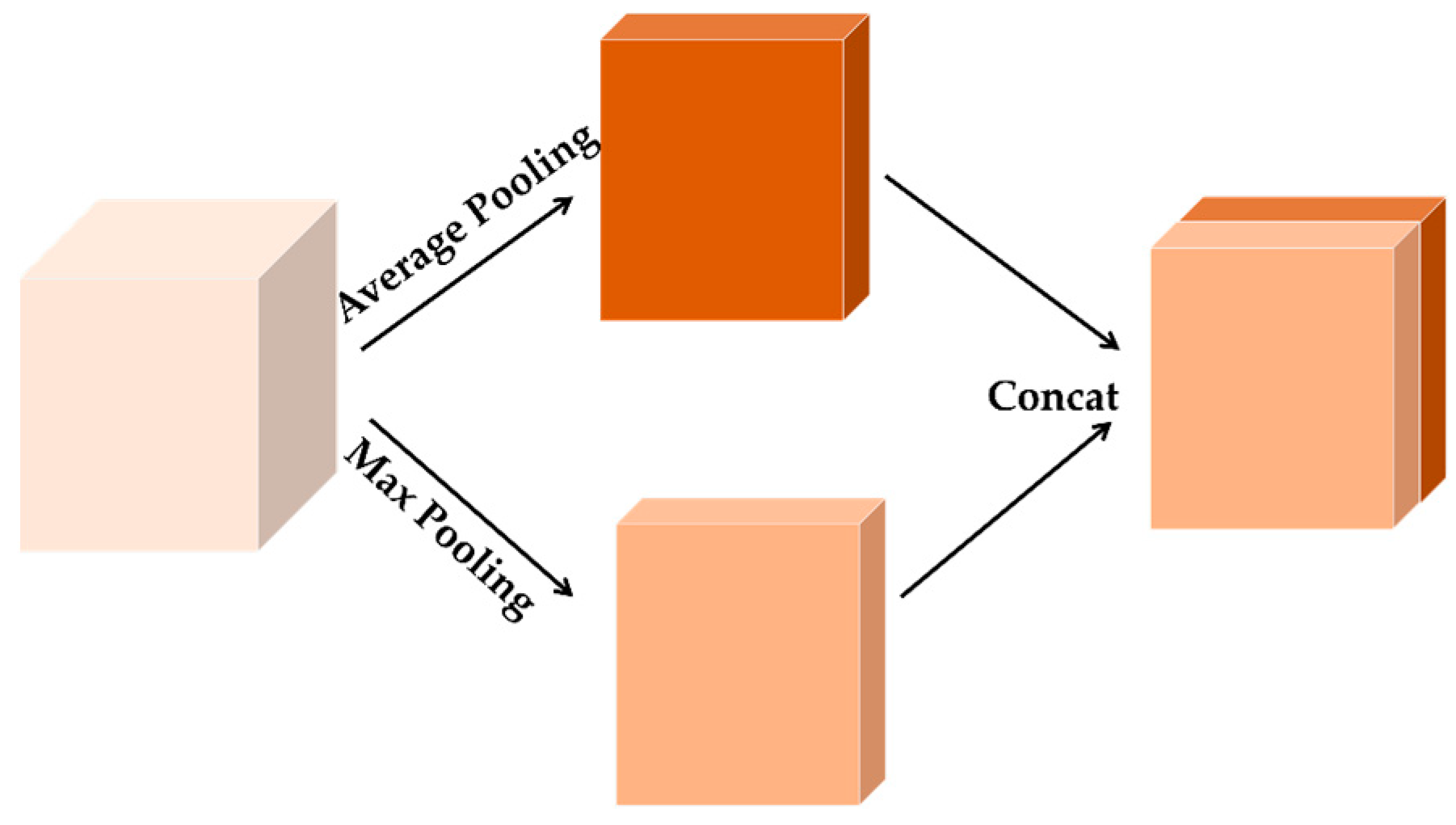
3.3. Triplet Attention Mechanism
3.4. Classification Model Based on Triplet-EfficientNet
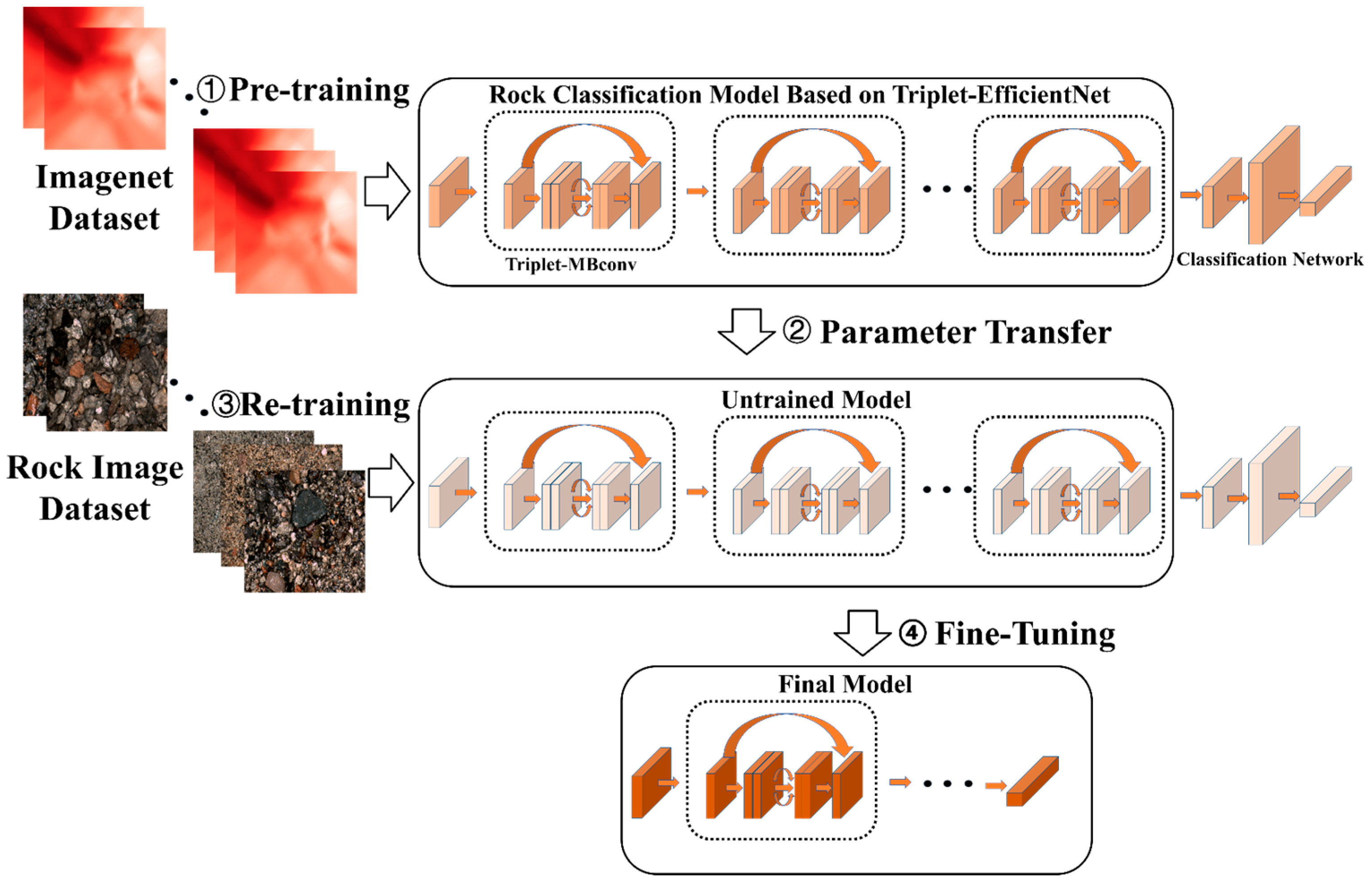
3.5. Transfer Learning
4. Experiments and Results
4.1. Data Pre-Processing
4.1.1. Data Augmentation
4.1.2. Dataset Partitioning
4.2. Experiment Details
4.3. Evaluation Metrics
4.4. Results Analysis
4.4.1. The Effectiveness of Data Augmentation
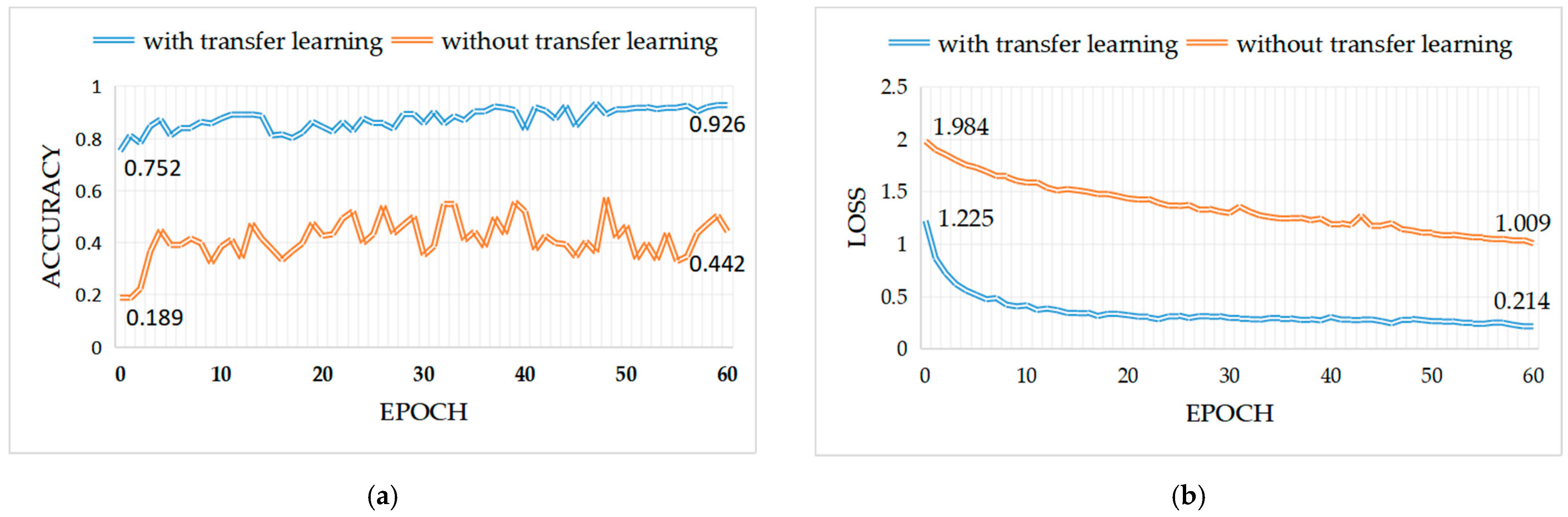
4.4.2. The Effectiveness of Transfer Learning
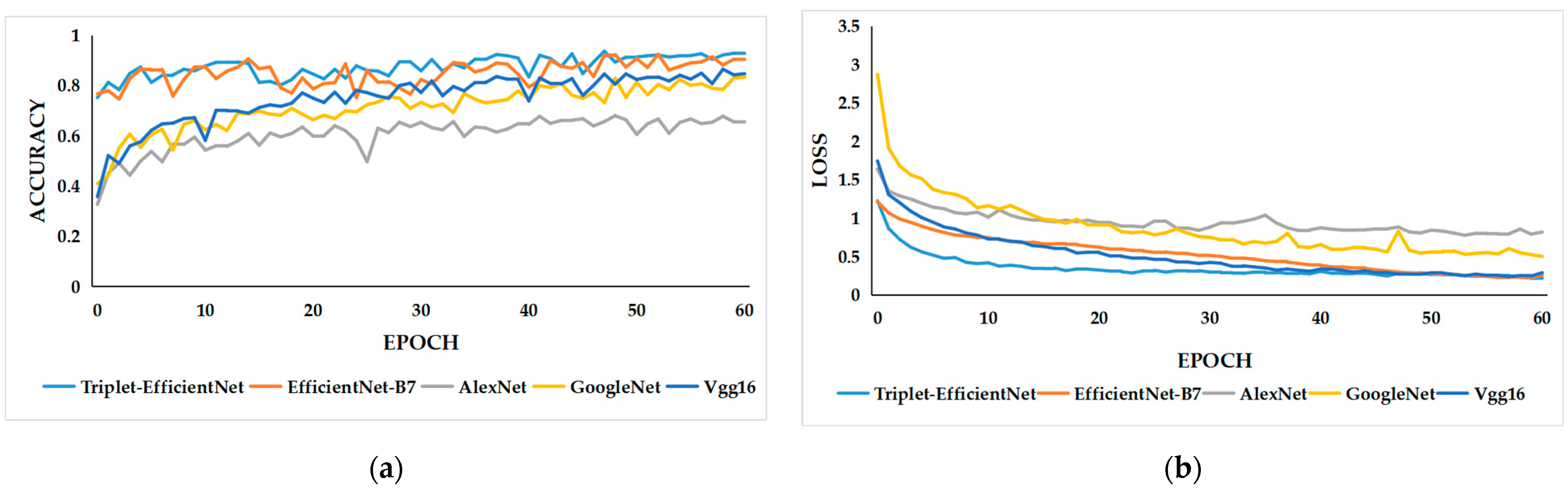
4.4.3. Evaluation of Model Training Performance
4.4.4. Performance Comparison for Different Models
4.4.5. Reality Testing
4.4.6. Comprehensive Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fu, G.; Yan, J.; Zhang, K.; Hu, H.; Luo, F. Current status and progress of lithology identification technology. Prog. Geophys. 2017, 32, 26–40. [Google Scholar]
- Zhang, S.; Bogus, S.M.; Lippitt, C.D.; Kamat, V.; Lee, S. Implementing Remote-Sensing Methodologies for Construction Research: An Unoccupied Airborne System Perspective. J. Constr. Eng. Manag. 2022, 148, 3122005. [Google Scholar] [CrossRef]
- Guo, Q.; Zhou, Y.; Cao, S.; Qiu, Z.; Xu, Z.; Zhang, Y. Study on Mineralogy of Guangning Jade. Acta Sci. Nat. Univ. Sunyatseni 2010, 49, 146–151. [Google Scholar]
- Młynarczuk, M.; Górszczyk, A.; Ślipek, B. The application of pattern recognition in the automatic classification of microscopic rock images. Comput. Geosci. 2013, 60, 126–133. [Google Scholar] [CrossRef]
- Xiao, F.; Chen, J.; Hou, W.; Wang, Z. Identification and extraction of Ag-Au mineralization associated geochemical anomaly in Pangxitong district, southern part of the Qinzhou-Hangzhou Metallogenic Belt, China. Acta Petrol. Sin. 2017, 33, 779–790. [Google Scholar]
- Xu, Z.; Ma, W.; Lin, P.; Shi, H.; Liu, T.; Pan, D. Intelligent Lithology Identification Based on Transfer Learning of Rock Images. J. Basic Sci. Eng. 2021, 29, 1075–1092. [Google Scholar]
- Lippitt, C.D.; Zhang, S. The impact of small unmanned airborne platforms on passive optical remote sensing: A conceptual perspective. Int. J. Remote Sens. 2018, 39, 4852–4868. [Google Scholar] [CrossRef]
- Marmo, R.; Amodio, S.; Tagliaferri, R.; Ferreri, V.; Longo, G. Textural identification of carbonate rocks by image processing and neural network: Methodology proposal and examples. Comput. Geosci. 2005, 31, 649–659. [Google Scholar] [CrossRef]
- Singh, N.; Singh, T.; Tiwary, A.; Sarkar, K.M. Textural identification of basaltic rock mass using image processing and neural network. Comput. Geosci. 2010, 14, 301–310. [Google Scholar] [CrossRef]
- Yen, H.H.; Tsai, H.Y.; Wang, C.C.; Tsai, M.C.; Tseng, M.H. An Improved Endoscopic Automatic Classification Model for Gastroesophageal Reflux Disease Using Deep Learning Integrated Machine Learning. Diagnostics 2022, 12, 2827. [Google Scholar] [CrossRef]
- Dimitrovski, I.; Kitanovski, I.; Kocev, D.; Simidjievski, N. Current trends in deep learning for Earth Observation: An open-source benchmark arena for image classification. ISPRS J. Photogramm. Remote Sens. 2023, 197, 18–35. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, Y. Artificial intelligence identification of ore minerals under microscope based on deep learning algorithm. Acta Petrol. Sin. 2018, 34, 3244–3252. [Google Scholar]
- Zhang, Y.; Li, M.; Han, S. Automatic identification and classification in lithology based on deep learning in rock images. Acta Petrol. Sin. 2018, 34, 333–342. [Google Scholar]
- Cheng, G.; Li, P. Rock thin-section image classification based on residual neural network. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 521–524. [Google Scholar]
- Chen, W.; Su, L.; Chen, X.; Huang, Z. Rock image classification using deep residual neural network with transfer learning. Front. Earth Sci. 2023, 10, 1079447. [Google Scholar] [CrossRef]
- Koeshidayatullah, A.; Al-Azani, S.; Baraboshkin, E.E.; Alfarraj, M. Faciesvit: Vision transformer for an improved core lithofacies prediction. Front. Earth Sci. 2022, 10, 992442. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Q.; Liu, S.; Pan, X.; Lu, X. A Spatial–Spectral Joint Attention Network for Change Detection in Multispectral Imagery. Remote Sens. 2022, 14, 3394. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 3139–3148. [Google Scholar]
- Okada, H. Classification of sandstone: Analysis and proposal. J. Geol. 1971, 79, 509–525. [Google Scholar] [CrossRef]
- Haimson, B.; Rudnicki, J.W. The effect of the intermediate principal stress on fault formation and fault angle in siltstone. J. Struct. Geol. 2010, 32, 1701–1711. [Google Scholar] [CrossRef]
- Vaniman, D.; Bish, D.; Ming, D.; Bristow, T.; Morris, R.; Blake, D.; Chipera, S.; Morrison, S.; Treiman, A.; Rampe, E. Mineralogy of a mudstone at Yellowknife Bay, Gale crater, Mars. Science 2014, 343, 1243480. [Google Scholar] [CrossRef]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Adv. Neural Inf. Process. Syst. 2019, 32, 103–112. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yao, Q.; Wang, M.; Chen, Y.; Dai, W.; Li, Y.F.; Tu, W.W.; Yang, Q.; Yu, Y. Taking human out of learning applications: A survey on automated machine learning. arXiv 2018, arXiv:1810.13306. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Gan, Y.; Guo, Q.; Wang, C.; Liang, W.; Xiao, D.; Wu, H. Recognizing crop pests using an improved EfficientNet model. Trans. Chin. Soc. Agric. Eng. 2022, 38, 203–211. [Google Scholar]
- Wei, Y.; Wang, Z.; Qiao, X.; Zhao, C. Lightweight rice disease identification method based on attention mechanism and EfficientNet. J. Chin. Agric. Mech. 2022, 43, 172–181. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number of Image | Type | Particle Size (mm) | Color | Shape Characteristics |
|---|---|---|---|---|
| a | Dark gray mudstone | <0.005 | Dark gray | Lamellar, Micrite structure |
| b | Black coal | <6 | Black | Granular, Asymmetrical |
| c | Gray fine sandstone | 0.05–2 | Gray | Fine grain structure, Rough surface, Uneven |
| d | Light gray fine sandstone | 0.05–2 | Light gray | Fine sand structure, Thin-layered structure |
| e | Dark gray silty mudstone | <0.005 | Dark gray | Silty argillaceous structure, Bedding structure |
| f | Gray black mudstone | <0.005 | Gray black | Cryptocrystalline structure, Massive structure |
| g | Gray argillaceous siltstone | 0.005–0.05 | Gray | Silty structure, Massive structure |
| Method | Number of Images in the Rock Dataset | Final Accuracy in the Training Set (Epoch = 60) | Top-1 Accuracy in the Test Set |
|---|---|---|---|
| Triplet-EfficientNet + Original dataset | 315 | 61.2% | 70.8% |
| Triplet-EfficientNet + Augmented dataset | 6949 | 92.6% | 93.2% |
| Model | Initial Accuracy | Initial Loss | Final Accuracy (Epoch = 60) | Final Loss (Epoch = 60) |
|---|---|---|---|---|
| AlexNet | 32.7% | 1.638 | 65.5% | 0.818 |
| GoogleNet | 40.9% | 2.870 | 83.3% | 0.501 |
| VGG16 | 35.7% | 1.744 | 84.6% | 0.289 |
| EfficientNet-B7 (+SE attention mechanism) | 75.2% | 1.225 | 90.4% | 0.255 |
| Triplet-EfficientNet (+Triplet attention mechanism) | 76.6% | 1.215 | 92.6% | 0.214 |
| Model | Input Image Size | Top-1 Accuracy | Parameters | FLOPs |
|---|---|---|---|---|
| AlexNet [31] | 600 × 600 | 71.9% | 61 MB | 5 G |
| GoogleNet [18] | 600 × 600 | 80.6% | 13 MB | 10 G |
| VGG16 [19] | 600 × 600 | 88.1% | 138 MB | 110 G |
| ResNet34 [15] | 600 × 600 | 86.3% | 36 MB | 26 G |
| EfficientNet-B7 [26] (+SE attention mechanism) | 600 × 600 | 92.0% | 66 MB | 38 G |
| CA-EfficientNet [32] (+Coordinate attention mechanism) | 600 × 600 | 92.6% | 67 MB | 39 G |
| Triplet-EfficientNet (+Triplet attention mechanism) | 600 × 600 | 93.2% | 64 MB | 36 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Su, L.; Wu, J.; Chen, Y. Rock Image Classification Based on EfficientNet and Triplet Attention Mechanism. Appl. Sci. 2023, 13, 3180. https://doi.org/10.3390/app13053180
Huang Z, Su L, Wu J, Chen Y. Rock Image Classification Based on EfficientNet and Triplet Attention Mechanism. Applied Sciences. 2023; 13(5):3180. https://doi.org/10.3390/app13053180
Chicago/Turabian StyleHuang, Zhihao, Lumei Su, Jiajun Wu, and Yuhan Chen. 2023. "Rock Image Classification Based on EfficientNet and Triplet Attention Mechanism" Applied Sciences 13, no. 5: 3180. https://doi.org/10.3390/app13053180
APA StyleHuang, Z., Su, L., Wu, J., & Chen, Y. (2023). Rock Image Classification Based on EfficientNet and Triplet Attention Mechanism. Applied Sciences, 13(5), 3180. https://doi.org/10.3390/app13053180