
TMVDPatch: A Trusted Multi-View Decision System for Security Patch Identification

 , , and
, , and
Abstract
:1. Introduction
- We first propose a trusted multi-view security patch identification system called TMVDPatch. The system adopts a multi-view evidence fusion strategy. Based on the subjective uncertainty learned from each view, the evidence is weighted by the Grey Relational Analysis method to provide credible and interpretable decisions, thereby achieving efficient and scientific security patch identification.
- We propose a representation method for the semantic and syntactic information of security patches. The method regards the multi-view evidence, including control dependency information, data dependency information and description information, so as to comprehensively represent the semantic and syntax information of security patches. Compared to learning from commit message alone, the multi-view representation method shows an excellent ability in control-dependent and data-dependent complementary information.
- We conduct a large number of experiments on the model hyperparameter settings and importance evaluation. The results demonstrate the capability boundary of TMVDPatch and the robustness of the model to the hyperparameter settings.
- We conduct related experiments on PatchDB, a large-scale real patch dataset. The results show that the TMVDPatch model outperforms other models in all metrics, achieving an accuracy of 85.29% and a F1 score of 0.9001. The superiority of TMVDPatch in terms of accuracy, scientificity and reliability is clearly verified.
2. Background and Related Work
2.1. Security Patch Identification
| Listing 1. Example of security patch for an integer underflow vulnerability (CVE-2019-13602). |
 |
| Listing 2. An example of non-security patch in FFmpeg. |
 |
2.2. Multi-View Learning
2.3. Uncertainty and the Theory of Evidence
- Grey Relational Analysis can preprocess multi-view data, reducing data dimensionality and noise.
- Evidence theory can dynamically integrate multi-view data, considering the uncertainty and weight of each view.
- The performance and robustness of multi-view classification can be enhanced, as well as the confidence and interpretability of the decision.
3. Motivation
- Related work mainly regards commit messages and code changes as ordinary text, and conducts research based on text classification technology in natural language processing. Although these methods have been proved their effectiveness to a certain extent through experiments, they have not really learned the essential information of security patches. As described in Section 2.1, we may reasonably come to the conclusion that the key of source code patch analysis is to learn the syntax and semantics of code patches, rather than simply treating them as ordinary text. Intuitively, how to learn the control dependency and data dependency in the source code is crucial for learning the essential information of security patches.
- In recent years, the methods of code2vec and seq2vec have provided a new direction for this field. They build an AST abstract syntax tree by parsing the source code, and convert it into a text sequence by expanding the paths between the leaf nodes. The related work [10] is carried out on this basis, and conducts experiments in the JAVA datasets. However, in the experiment of C source code, we find that the generated AST syntax tree is too large, and this method has certain limitations. This means that the AST abstract syntax tree parsing of C source code will obtain a large number of text sequences after expansion. Moreover, it is difficult to learn the patch information completely and effectively from the results of sampling randomly(extracting a small number of text sequences from a large number of sequences). Meanwhile, it is difficult to directly learn the changes of the data dependencies and control dependencies via the path of the child nodes of the AST abstract syntax tree.
- Currently in the work of security patch identification, the main ensemble methods are vector concatenation and voting algorithms. However, these ensemble methods are too subjective and do not take into account consistency and complementarity between different features. Therefore, they do not have the interpretability of the identification results. In the field of patch analysis, how to make use of consistency and complementarity between different views, to find the inherent pattern of patch commit to improve the effectiveness of security patch identification is deemed scientific in this paper. Therefore, we may reasonably come to the conclusion that, in addition to the identification results, what should be known is the confidence and interpretability of the identification results.
4. Design and Implementation
4.1. Overall Design
4.2. Data Collection and Prepocessing
4.3. Code Parsing
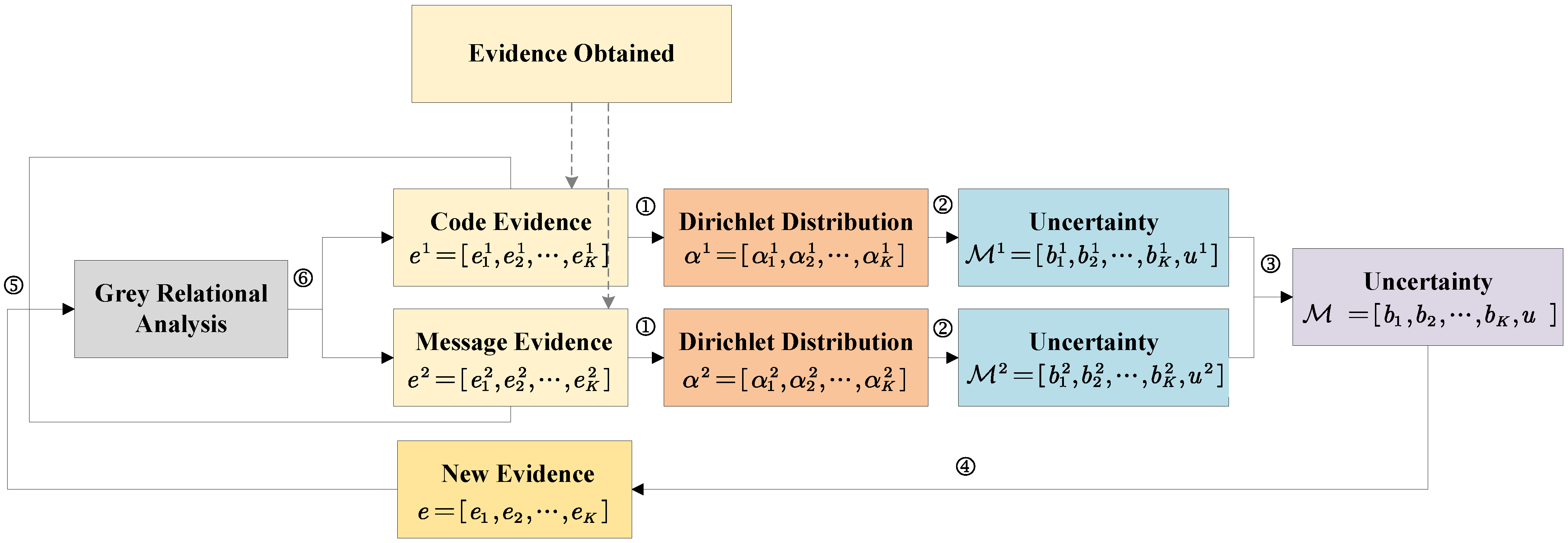
4.4. Evidence Obtained
4.5. Trusted Multi-View Decision Rule
4.6. Model Training
5. Experiments and Results
5.1. Dataset and Experimental Environment
5.2. Evaluation Metrics
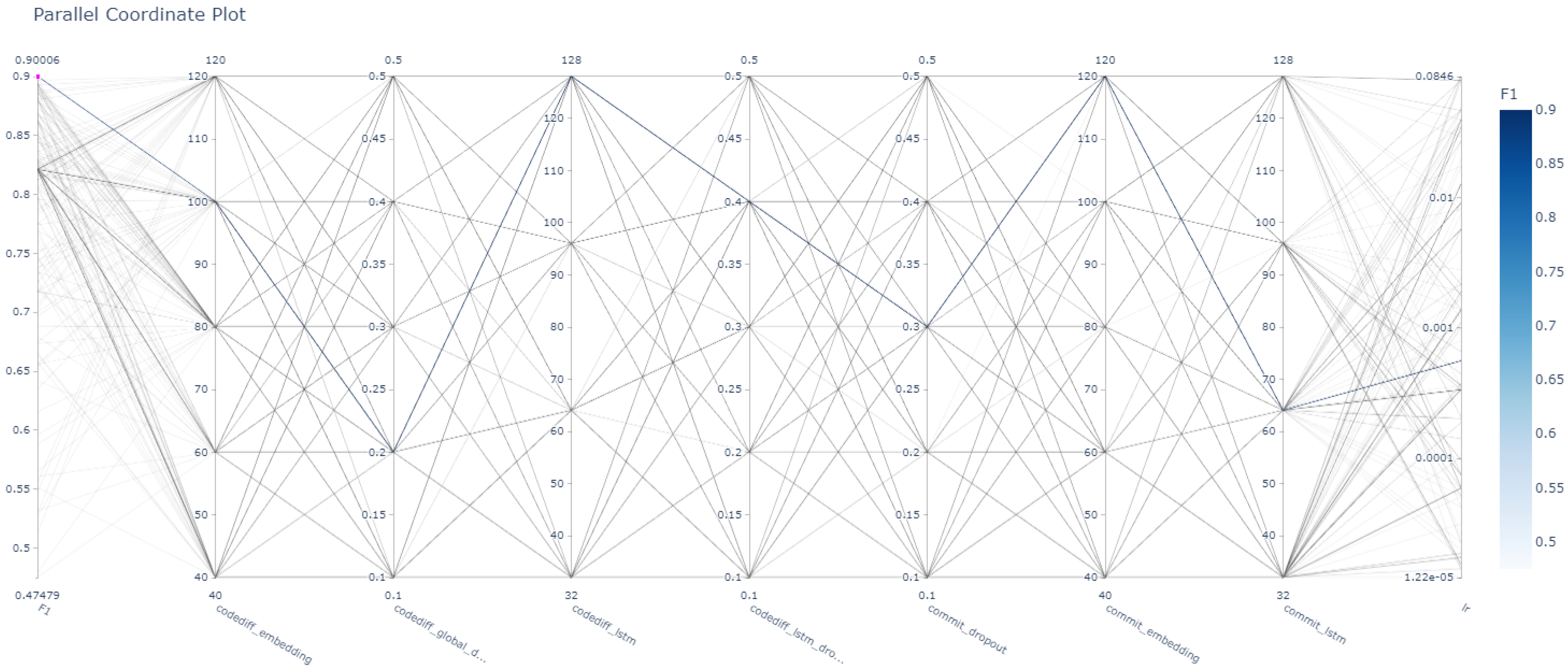
5.3. Hyperparameters Tuning
5.4. Model Comparison
5.5. Ensemble Methods
6. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
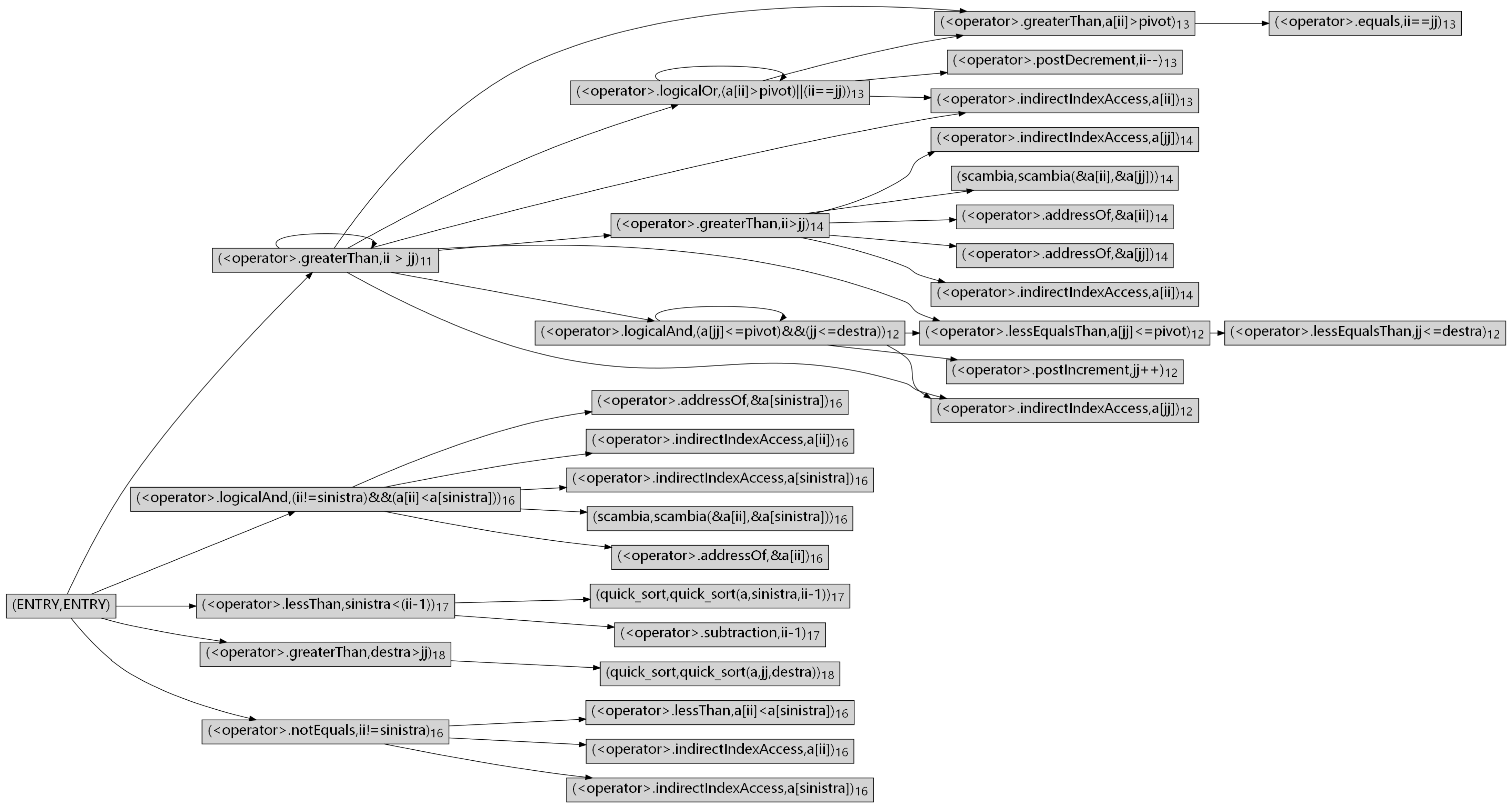
Appendix A. Control Dependence Graph
| Listing A1. An example of quick sort. |
 |


References
- Snyk. The State of Open Source Security Report 2020. 2020. Available online: https://go.snyk.io/SoOSS-Report-2020.html (accessed on 19 January 2023).
- Snyk. Addressing Cybersecurity Challenges in Open Source Software. 2022. Available online: https://snyk.io/reports/open-source-security/ (accessed on 19 January 2023).
- ARMIS. Log4j Vulnerability. 2021. Available online: https://www.armis.com/log4j (accessed on 19 January 2023).
- ARMIS. The Long Tail Matters with Apache Log4j. 2021. Available online: https://www.armis.com/blog/he-long-tail-matters-with-apache-log4j/ (accessed on 19 January 2023).
- Github. The State of the Octovers. 2019. Available online: https://octoverse.github.com/2019/ (accessed on 19 January 2023).
- Wang, X.; Sun, K.; Batcheller, A.; Jajodia, S. Detecting “0-day” vulnerability: An empirical study of secret security patch in OSS. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 485–492. [Google Scholar]
- Zhou, Y.; Siow, J.K.; Wang, C.; Liu, S.; Liu, Y. SPI: Automated Identification of Security Patches via Commits. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2021, 31, 1–27. [Google Scholar] [CrossRef]
- Sawadogo, A.D.; Bissyandé, T.F.; Moha, N.; Allix, K.; Klein, J.; Li, L.; Traon, Y.L. Learning to catch security patches. arXiv 2020, arXiv:2001.09148. [Google Scholar]
- Sabetta, A.; Bezzi, M. A practical approach to the automatic classification of security-relevant commits. In Proceedings of the 2018 IEEE International conference on software maintenance and evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 579–582. Available online: https://research.com/conference/icsme-2018 (accessed on 19 January 2023).
- Cabrera Lozoya, R.; Baumann, A.; Sabetta, A.; Bezzi, M. Commit2vec: Learning distributed representations of code changes. SN Comput. Sci. 2021, 2, 1–16. [Google Scholar] [CrossRef]
- Hoang, T.; Kang, H.J.; Lo, D.; Lawall, J. Cc2vec: Distributed representations of code changes. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June–19 July 2020; pp. 518–529. [Google Scholar]
- Hoang, T.; Lawall, J.; Oentaryo, R.J.; Tian, Y.; Lo, D. PatchNet: A tool for deep patch classification. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montréal, QC, Canada, 25–31 May 2019; pp. 83–86. Available online: https://conf.researchr.org/home/icse-2019 (accessed on 19 January 2023).
- Wang, X.; Wang, S.; Feng, P.; Sun, K.; Jajodia, S.; Benchaaboun, S.; Geck, F. PatchRNN: A Deep Learning-Based System for Security Patch Identification. In Proceedings of the MILCOM 2021–2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021; pp. 595–600. [Google Scholar]
- Machiry, A.; Redini, N.; Camellini, E.; Kruegel, C.; Vigna, G. Spider: Enabling fast patch propagation in related software repositories. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–20 May 2020; pp. 1562–1579. [Google Scholar]
- Tan, X.; Zhang, Y.; Mi, C.; Cao, J.; Sun, K.; Lin, Y.; Yang, M. Locating the Security Patches for Disclosed OSS Vulnerabilities with Vulnerability-Commit Correlation Ranking. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2021; pp. 3282–3299. [Google Scholar]
- Wang, X.; Wang, S.; Feng, P.; Sun, K.; Jajodia, S. Patchdb: A large-scale security patch dataset. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; pp. 149–160. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. Proc. ACM Program. Lang. 2019, 3, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Daumé, H. A co-training approach for multi-view spectral clustering. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, DC, USA, 28 June–2 July 2011; pp. 393–400. [Google Scholar]
- Xue, Z.; Du, J.; Du, D.; Lyu, S. Deep low-rank subspace ensemble for multi-view clustering. Inf. Sci. 2019, 482, 210–227. [Google Scholar] [CrossRef]
- Bach, F.R.; Jordan, M.I. Kernel independent component analysis. J. Mach. Learn. Res. 2002, 3, 1–48. [Google Scholar]
- Lai, P.L.; Fyfe, C. Kernel and nonlinear canonical correlation analysis. Int. J. Neural Syst. 2000, 10, 365–377. [Google Scholar] [CrossRef] [PubMed]
- Akaho, S. A kernel method for canonical correlation analysis. arXiv 2006, arXiv:cs/0609071. [Google Scholar]
- Socher, R.; Fei-Fei, L. Connecting modalities: Semi-supervised segmentation and annotation of images using unaligned text corpora. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 966–973. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International conference on machine learning. PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 1247–1255. [Google Scholar]
- Wang, W.; Arora, R.; Livescu, K.; Bilmes, J. On deep multi-view representation learning. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1083–1092. [Google Scholar]
- Han, Z.; Zhang, C.; Fu, H.; Zhou, J.T. Trusted multi-view classification. arXiv 2021, arXiv:2102.02051. [Google Scholar]
- Han, Z.; Zhang, C.; Fu, H.; Zhou, J.T. Trusted Multi-View Classification with Dynamic Evidential Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2551–2566. [Google Scholar] [CrossRef] [PubMed]
- Kull, M.; Perello Nieto, M.; Kängsepp, M.; Silva Filho, T.; Song, H.; Flach, P. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Bai, Y.; Mei, S.; Wang, H.; Xiong, C. Don’t just blame over-parametrization for over-confidence: Theoretical analysis of calibration in binary classification. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 566–576. [Google Scholar]
- Tang, H. A novel fuzzy soft set approach in decision making based on grey relational analysis and Dempster–Shafer theory of evidence. Appl. Soft Comput. 2015, 31, 317–325. [Google Scholar] [CrossRef]
- Kuo, Y.; Yang, T.; Huang, G.W. The use of grey relational analysis in solving multiple attribute decision-making problems. Comput. Ind. Eng. 2008, 55, 80–93. [Google Scholar] [CrossRef]
- Ng, D.K. Grey system and grey relational model. ACM Sigice Bull. 1994, 20, 2–9. [Google Scholar] [CrossRef]
- Yang, C.C.; Chen, B.S. Supplier selection using combined analytical hierarchy process and grey relational analysis. J. Manuf. Technol. Manag. 2006, 17, 926–941. [Google Scholar] [CrossRef]
- Jøsang, A. Subjective Logic; Springer: Berlin/Heidelberg, Germany, 2016; Volume 3. [Google Scholar]
- Oren, N.; Norman, T.J.; Preece, A. Subjective logic and arguing with evidence. Artif. Intell. 2007, 171, 838–854. [Google Scholar] [CrossRef] [Green Version]
- Gao, W.; Zhang, G.; Chen, W.; Li, Y. A trust model based on subjective logic. In Proceedings of the 2009 Fourth International Conference on Internet Computing for Science and Engineering, Washington, DC, USA, 21–22 December 2009; pp. 272–276. [Google Scholar]
- Jøsang, A. Generalising Bayes’ theorem in subjective logic. In Proceedings of the MFI 2016, Baden-Baden, Germany, 19–21 September 2016. pp. 462–469.
- Van Der Heijden, R.W.; Kopp, H.; Kargl, F. Multi-source fusion operations in subjective logic. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 1990–1997. [Google Scholar]
- Sentz, K.; Ferson, S. Combination of Evidence in Dempster-Shafer Theory. 2002. Available online: https://www.osti.gov/biblio/800792 (accessed on 19 January 2023).
- Minka, T. Estimating a Dirichlet Distribution. 2000. Available online: url:https://www.semanticscholar.org/paper/Estimating-a-Dirichlet-distribution-Minka/51fec0515b11cabc2be4832eab43ca5f6ff387d1 (accessed on 19 January 2023).
- Lin, J. On the Dirichlet Distribution; Department of Mathematics and Statistics, Queens University: Kingston, ON, Canada, 2016. [Google Scholar]
- Sensoy, M.; Kaplan, L.; Kandemir, M. Evidential deep learning to quantify classification uncertainty. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Joern. Joern Documentation. 2022. Available online: https://docs.joern.io/home/ (accessed on 19 January 2023).
- Kapur, J.N.; Kesavan, H.K. Entropy Optimization Principles and their Applications; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Program Language | Labeled Data | Open Source Dataset | Open Source Code | Method | Object of Study |
|---|---|---|---|---|---|---|---|
| [6] | 2019 | C/C++ | 3272 | ✗ | ✗ | Heuristics | Code Diff |
| [7] | 2021 | C/C++ | 40,523 | Part | ✗ | Deep learning | Commit Message & Code Diff |
| [8] | 2020 | C/C++ | 9247 | ✓ | ✓ | Heuristics | Commit Message & Code Diff |
| [9] | 2018 | JAVA | 2715 | ✓ | ✗ | Classic Machine Learning | Commit Message & Code Diff |
| [10] | 2021 | JAVA | 1950 | Part | ✗ | Deep learning | The prior and posterior versions of source code in the commit |
| [11] | 2020 | C/C++ | 82,403 | Invalidation | ✓ | Deep learning | code diff |
| [12] | 2019 | C/C++ | 82,403 | Invalidation | ✓ | Deep learning | Commit Message & Code Diff |
| [13] | 2021 | C/C++ | 38,041 | ✓ | ✓ | Deep learning | Commit message & The prior and posterior versions of source code in the commit |
| [14] | 2020 | C/C++ | 341,767 | ✗ | ✗ | Symbolic Interpretation | The prior and posterior versions of source code in the commit |
| [15] | 2021 | C/C++ | 3,329,286 Sample Pairs | ✗ | ✗ | Heuristics | Commit Message & Code Diff |
| View | Hyper-Parameter | Search Space | Best Value |
|---|---|---|---|
| Code Diff | codediff_embedding | [40,120] | 100 |
| codediff_global_dropout | [0.1,0.5] | 0.2 | |
| codediff_lstm | [32,128] | 128 | |
| codediff_lstm_dropout | [0.1,0.5] | 0.4 | |
| Commit Message | commit_dropout | [0.1,0.5] | 0.3 |
| commit_embedding | [40,120] | 120 | |
| commit_lstm | [32,128] | 64 | |
| Overall | lr | [0.00001, 0.1] | 0.000557 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| SV-CMS | 0.7391 | 0.7617 | 0.9099 | 0.8293 |
| SV-CDP | 0.7013 | 0.7020 | 0.9922 | 0.8222 |
| SQ-CDP | 0.6954 | 0.7012 | 0.9803 | 0.8176 |
| SQ-A | 0.7798 | 0.7909 | 0.9296 | 0.8546 |
| PatchRNN | 0.8357 | 0.7572 | 0.7366 | 0.7468 |
| TMVDPatch | 0.8529 | 0.8542 | 0.9511 | 0.9001 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| 0.7798 | 0.7877 | 0.9362 | 0.8555 | |
| 0.7329 | 0.8409 | 0.7601 | 0.7985 | |
| 0.7574 | 0.8100 | 0.8520 | 0.8302 | |
| 0.7736 | 0.8503 | 0.8109 | 0.8301 | |
| 0.7615 | 0.7783 | 0.9195 | 0.8430 | |
| TMVD-NG | 0.8400 | 0.8502 | 0.9350 | 0.8906 |
| TMVDPatch | 0.8529 | 0.8542 | 0.9511 | 0.9001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Pang, J.; Shan, Z.; Yue, F.; Liu, F.; Xu, J.; Wang, J.; Liu, W.; Liu, G. TMVDPatch: A Trusted Multi-View Decision System for Security Patch Identification. Appl. Sci. 2023, 13, 3938. https://doi.org/10.3390/app13063938
Zhou X, Pang J, Shan Z, Yue F, Liu F, Xu J, Wang J, Liu W, Liu G. TMVDPatch: A Trusted Multi-View Decision System for Security Patch Identification. Applied Sciences. 2023; 13(6):3938. https://doi.org/10.3390/app13063938
Chicago/Turabian StyleZhou, Xin, Jianmin Pang, Zheng Shan, Feng Yue, Fudong Liu, Jinlong Xu, Junchao Wang, Wenfu Liu, and Guangming Liu. 2023. "TMVDPatch: A Trusted Multi-View Decision System for Security Patch Identification" Applied Sciences 13, no. 6: 3938. https://doi.org/10.3390/app13063938
APA StyleZhou, X., Pang, J., Shan, Z., Yue, F., Liu, F., Xu, J., Wang, J., Liu, W., & Liu, G. (2023). TMVDPatch: A Trusted Multi-View Decision System for Security Patch Identification. Applied Sciences, 13(6), 3938. https://doi.org/10.3390/app13063938