
Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry





Abstract
:1. Introduction
2. Safety and Human Errors in Aviation
- Safety policies. It must be a proactive system that looks to identify possible risks that can compromise safety before they happen.
- Risk management. When these risks are identified, they must be properly assessed and actions must be taken to keep the risk as low as possible.
- Risk Performance Assessment. Tools and Keep Performance Indicators (KPI) must then be developed to better manage and visualize the safety goals for the whole organization.
- Quality and Safety Assurance. From the monitoring of the KPI’s, actions must be deployed to mitigate, or at least to bring again to very low levels, the risk or any potential threat to the air transport safety. These actions sometimes identify new threats, requiring new actions that must be deployed.
3. Data Implementation
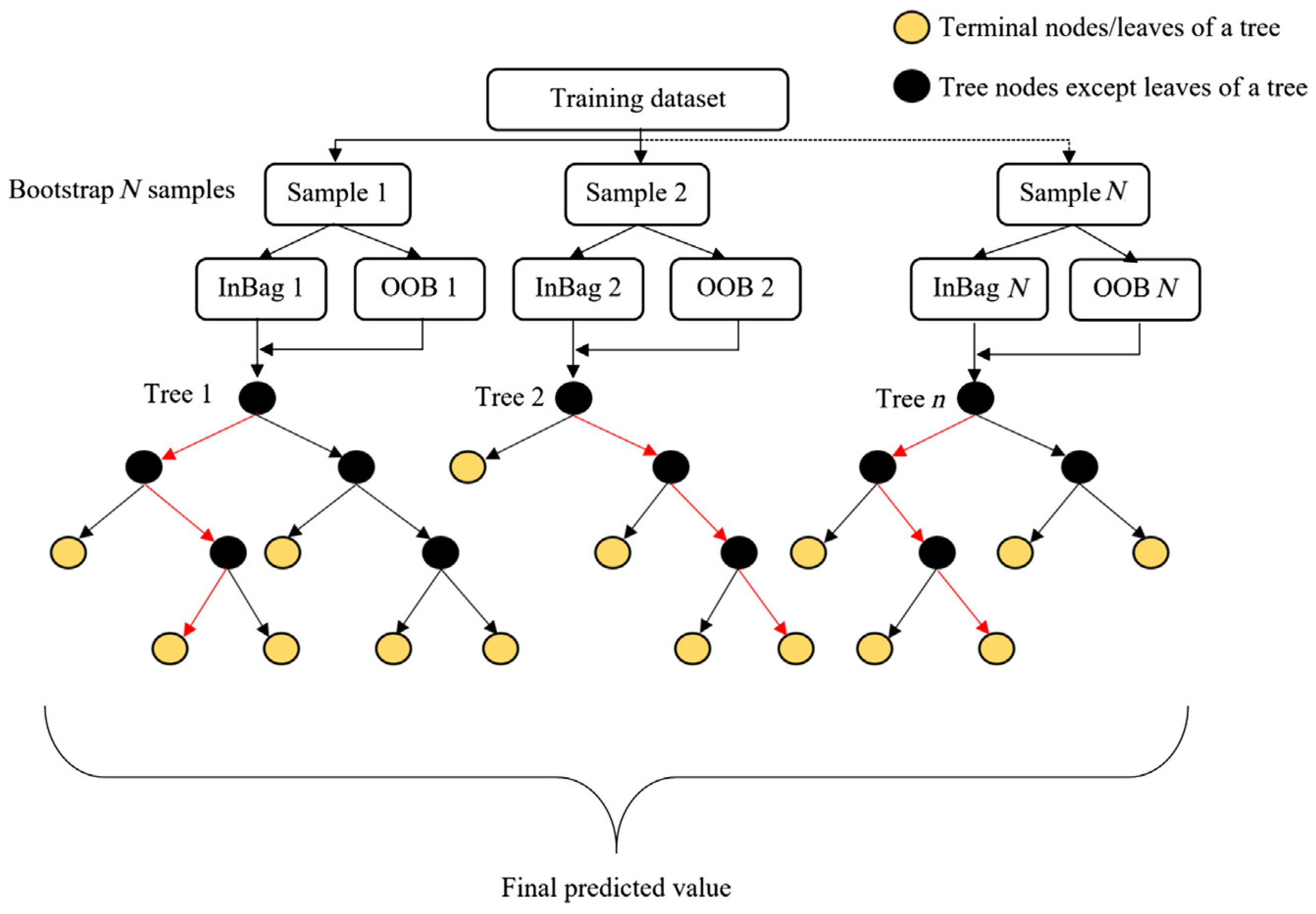
3.1. Random Forest
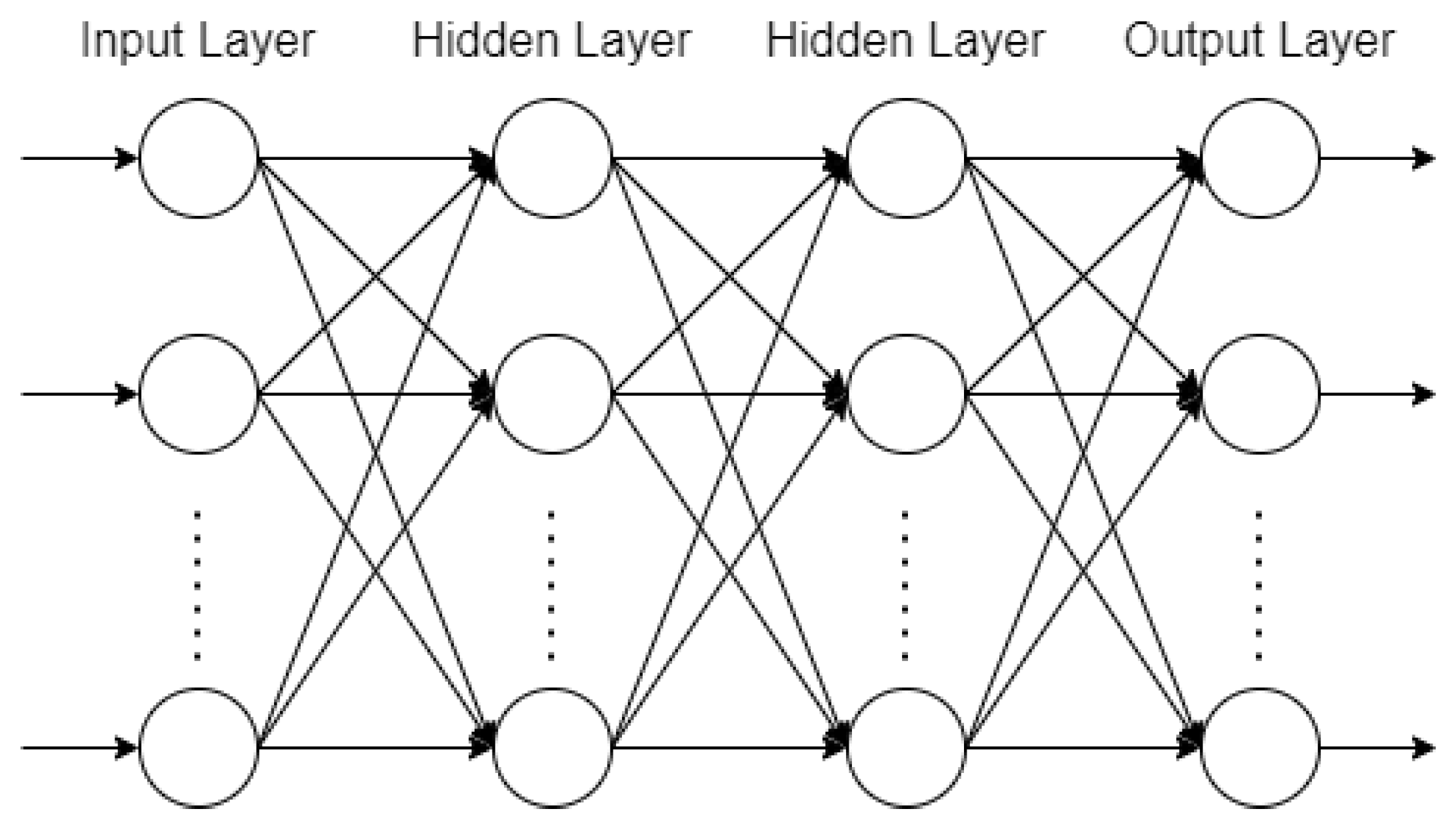
3.2. Artificial Neural Networks
3.3. Hyperparameter Tuning
3.4. Active Learning
4. Database Modeling
- Is it possible to predict whether an incident or accident produced any fatality? This is the purpose of Model 1.
- If an occurrence was fatal, is it possible to estimate the percentage of people killed? This is the purpose of Model 2.
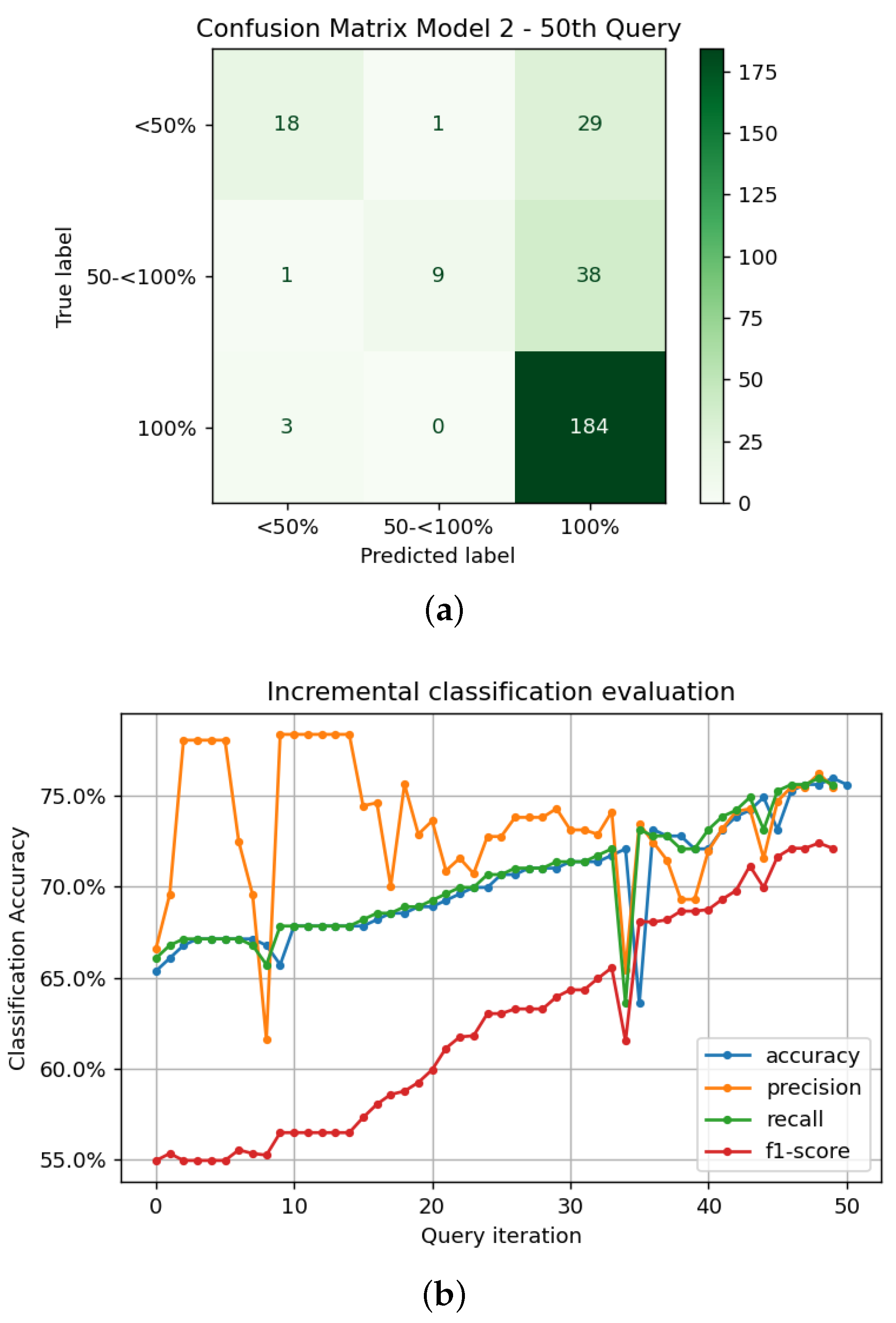
5. Results
- Random forests used 1000 trees, and nodes were expanded until all leaves were pure.
- Neural networks used one hidden layer with a rectified linear unit activation function, and several neurons were found by trial and error as a compromise between performance and overfitting. Model 1 had 13 neurons in the hidden layer, and two neurons in the output layer with a sigmoid activation function, its purpose being a binary classification. Model 2 had 15 neurons in the hidden layer, and three neurons in the output layer with a softmax activation function, which is a usual choice when finding a probability [35].
5.1. Performance Criteria
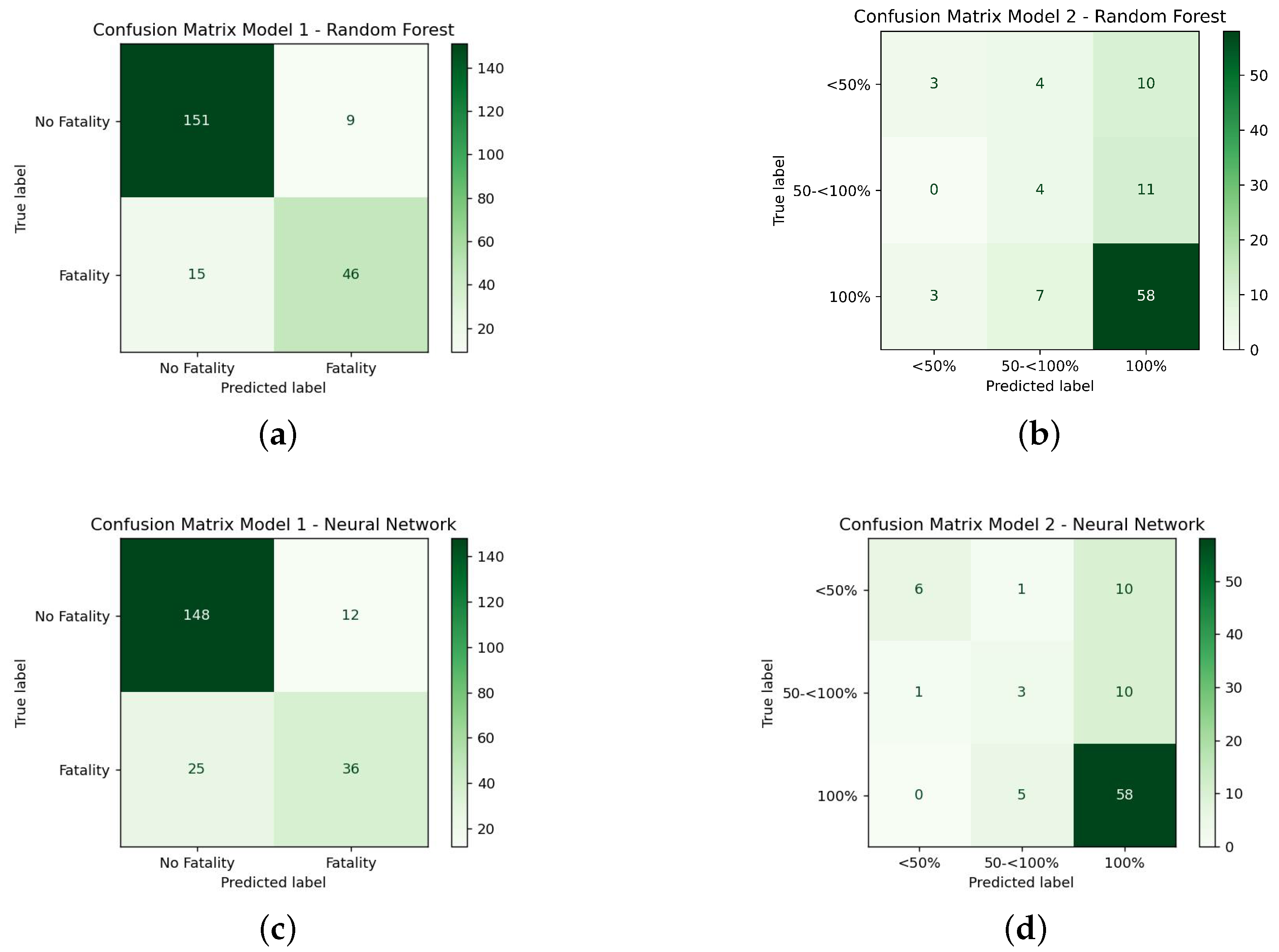
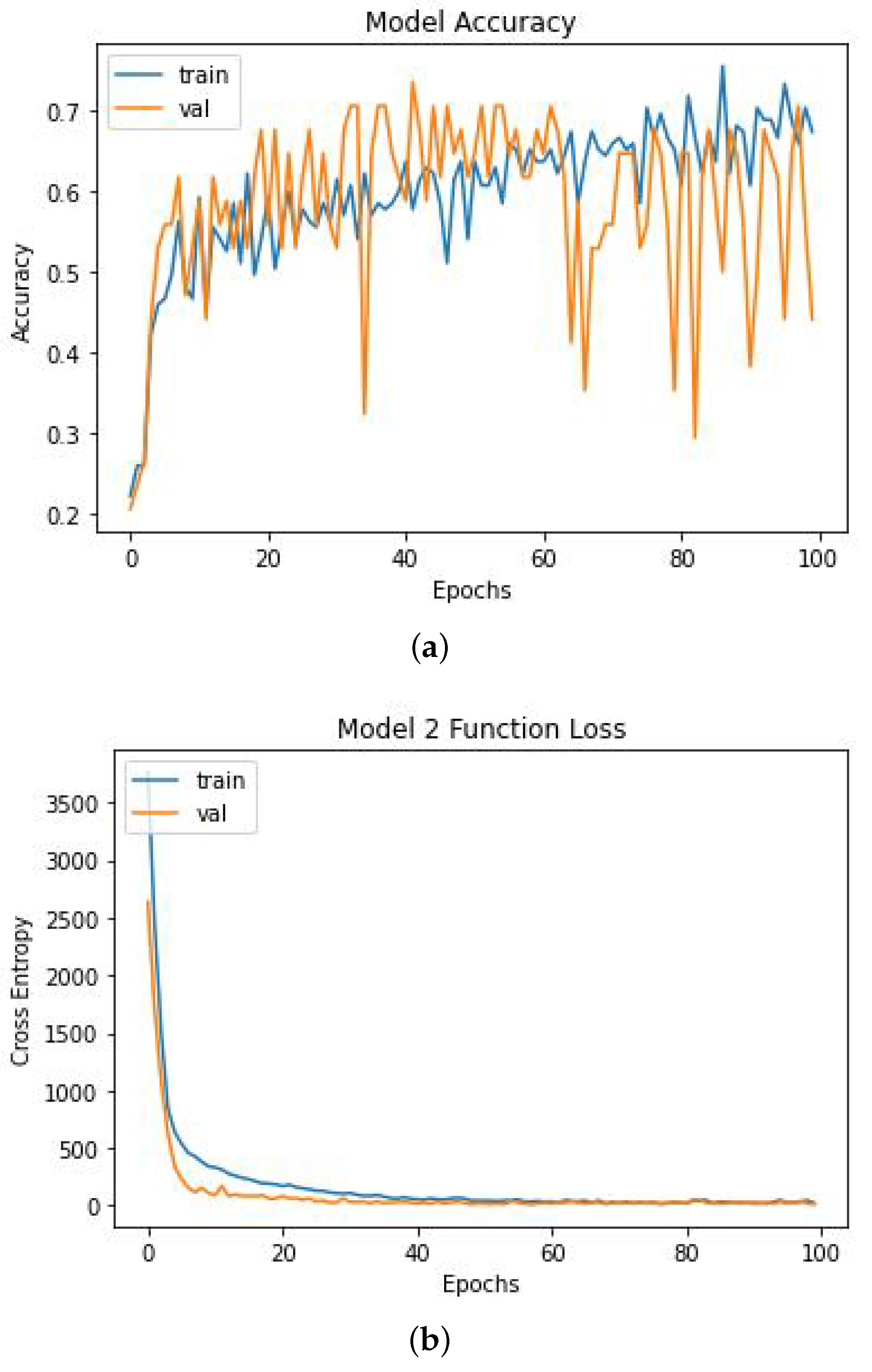
5.2. Model Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Santos, L.F.; Melicio, R. Stress, Pressure and Fatigue on Aircraft Maintenance Personal. Int. Rev. Aerosp. Eng. 2019, 12, 35–45. [Google Scholar] [CrossRef]
- ICAO. Safety Management Manual, 3rd ed.; DOC 9859 AN/474; International Civil Aviation Organization: Montreal, QC, Canada, 2013. [Google Scholar]
- Pereira, D.P.; Gomes, I.L.; Melicio, R.; Mendes, V.M. Planning of Aircraft Fleet Maintenance Teams. Aerospace 2021, 8, 140. [Google Scholar] [CrossRef]
- Wiegmann, D.A.; Shappell, S.A. A Human Error Approach to Aviation Accident Analysis; Ashgate Publishing Ltd.: Farnham, UK, 2003. [Google Scholar]
- Mazareanu, E. Passenger AIR Traffic Each Year. 2021. Available online: https://www.statista.com/statistics/564717/airline-industry-passenger-traffic-globally/ (accessed on 10 February 2023).
- Dias, N.G.; Santos, L.F.; Melicio, R. Aircraft Maintenance Professionals: Stress, Pressure and Fatigue. In Proceedings of the 9th EASN International Conference on Innovation in Aviation and Space, Athens, Greece, 3–6 September 2019; Volume 304, pp. 1–7. [Google Scholar]
- Kharoufah, H.; Murray, J.; Baxter, G.; Wild, G. A review of human factors causations in commercial air transport accidents and incidents: From to 2000–2016. Prog. Aerosp. Sci. 2018, 99, 1–13. [Google Scholar] [CrossRef]
- EASA. ICAO Annex 19. In Safety Management, International Standards and Recommended Practices; European Aviation Safety Agency: Cologne, Germany, 2016. [Google Scholar]
- Reason, J. Human Error; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Li, G.; Baker, S.P. Correlates of pilot fatality in general aviation crashes. Aviat. Space Environ. Med. 1999, 70, 305–309. [Google Scholar] [PubMed]
- Bazargan, M.; Guzhva, V.S. Impact of gender, age and experience of pilots on general aviation accidents. Accid. Anal. Prev. 2011, 43, 962–970. [Google Scholar] [CrossRef] [PubMed]
- Boyd, D.D. Causes and risk factors for fatal accidents in non-commercial twin engine piston general aviation aircraft. Accid. Anal. Prev. 2015, 77, 113–119. [Google Scholar] [CrossRef] [PubMed]
- de Sant’Anna, D.A.L.M.; de Hilal, A.V.G. The impact of human factors on pilots’ safety behavior in offshore aviation companies: A brazilian case. Saf. Sci. 2021, 140, 105272. [Google Scholar] [CrossRef]
- Shappell, S.A.; Wiegmann, D.A. The Human Factors Analysis and Classification System–HFACS; Civil Aeromedical Institute: Oklahoma City, OK, USA, 2000. [Google Scholar]
- Shappell, S.A.; Wiegmann, D.A. US naval aviation mishaps, 1977-92: Differences between single-and dual-piloted aircraft. Aviat. Space Environ. Med. 1996, 67, 65–69. [Google Scholar]
- Kelly, D.; Efthymiou, M. An analysis of human factors in fifty controlled flight into terrain aviation accidents from 2007 to 2017. J. Saf. Res. 2019, 69, 155–165. [Google Scholar] [CrossRef]
- Rashid, H.; Place, C.; Braithwaite, G.R. Eradicating root causes of aviation maintenance errors: Introducing the AMMP. Cogn. Technol. Work 2014, 16, 71–90. [Google Scholar] [CrossRef]
- Rashid, H.; Place, C.; Braithwaite, G. Helicopter maintenance error analysis: Beyond the third order of the HFACS-ME. Int. J. Ind. Ergon. 2010, 40, 636–647. [Google Scholar] [CrossRef]
- Li, F.; Chen, C.H.; Zheng, P.; Feng, S.; Xu, G.; Khoo, L.P. An explorative context-aware machine learning approach to reducing human fatigue risk of traffic control operators. Saf. Sci. 2020, 125, 104655. [Google Scholar] [CrossRef]
- Qiao, W.; Liu, Y.; Ma, X.; Liu, Y. A methodology to evaluate human factors contributed to maritime accident by mapping fuzzy FT into ANN based on HFACS. Ocean Eng. 2020, 197, 106892. [Google Scholar] [CrossRef]
- Madeira, T.; Melicio, R.; Valério, D.; Santos, L. Machine learning and natural language processing for prediction of human factors in aviation incident reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Zhang, X.; Mahadevan, S. Ensemble machine learning models for aviation incident risk prediction. Decis. Support Syst. 2018, 116, 48–63. [Google Scholar] [CrossRef]
- Xing, G.; Sun, Y.; He, F.; Wei, P.; Wu, S.; Ren, H.; Chen, Z. Analysis of Human Factors in Typical Accident Tests of Certain Type Flight Simulator. Sustainability 2023, 15, 2791. [Google Scholar] [CrossRef]
- Stroeve, S.; Kirwan, B.; Turan, O.; Kurt, R.E.; van Doorn, B.; Save, L.; Jonk, P.; de Maya, B.N.; Kilner, A.; Verhoeven, R.; et al. SHIELD Human Factors Taxonomy and Database for Learning from Aviation and Maritime Safety Occurrences. Safety 2023, 9, 14. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Larose, D.T.; Larose, C.D. Discovering Knowledge in Data: An Introduction to Data Mining; John Wiley & Sons: Hoboken, NJ, USA, 2014; Chapters 8–9; pp. 165–208. [Google Scholar]
- Hemmati-Sarapardeh, A.; Larestani, A.; Nait Amar, M.; Hajirezaie, S. Intelligent models. In Applications of Artificial Intelligence Techniques in the Petroleum Industry; Gulf Professional Publishing: Brian Romer, Chennai, India, 2020; Chapter 2; pp. 23–50. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1999; Chapters 1 and 4; pp. 23, 178–278. [Google Scholar]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Technical Report 1648; Department of Computer Sciences, University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Ranter, H.; Lujan, F.I. Aviation Safety Network. 2016. Available online: https://aviation-safety.net/about/ (accessed on 10 February 2023).
- Wiegmann, D.A.; Shappell, S.A. A Human Error Analysis of Commercial AVIATION Accidents Using the Human Factors Analysis and Classification System (HFACS); Technical Report; Office of Aviation Medicine, FAA: Daytona Beach, Florida, USA, 2001. [Google Scholar]
- Schmidt, J.; Schmorrow, D.; Hardee, M. A preliminary human factors analysis of naval aviation maintenance related mishap. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2000, 44, 775–778. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Deng, W.; Du, J. Noisy Softmax: Improving the Generalization Ability of DCNN via Postponing the Early Softmax Saturation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4021–4030. [Google Scholar]
- Castelli, M.; Vanneschi, L.; Largo, Á.R. Supervised Learning: Classification. In Encyclopedia of Bioinformatics and Computational Biology; Ranganathan, S., Gribskov, M., Nakai, K., Schönbach, C., Eds.; Academic Press: Oxford, UK, 2019; pp. 342–349. [Google Scholar]
- Zarei, E.; Yazdi, M.; Abbassi, R.; Khan, F. A hybrid model for human factor analysis in process accidents: FBN-HFACS. J. Loss Prev. Process Ind. 2019, 57, 142–155. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Severity | |||||
|---|---|---|---|---|---|
| Risk | Catastrophic | Danger | Major | Minor | Insignificant |
| Probability | A | B | C | D | E |
| Frequent—5 | 5A | 5B | 5C | 5D | 5E |
| Occasional—4 | 4A | 4B | 4C | 4D | 4E |
| Remote—3 | 3A | 3B | 3C | 3D | 3E |
| Improbable—2 | 2A | 2B | 2C | 2D | 2E |
| Extremely improbable—1 | 1A | 1B | 1C | 1D | 1E |
| Factor According to HFACS/HFACS-ME | Number of Cases |
|---|---|
| Adverse Mental State | 73 |
| Adverse Physiological State | 19 |
| Crew Resource Management | 11 |
| Dated/Uncertififed Equipment | 67 |
| Decision Error | 62 |
| Exceptional Violation | 20 |
| Fail to Correct Known Problem | 12 |
| Inaccessible | 2 |
| Inadequate Design | 42 |
| Inadequate Documentation | 36 |
| Inadequate Supervision | 63 |
| Inappropriate Operations | 76 |
| Infraction | 1 |
| Lighting | 1 |
| Operational Process | 12 |
| Perceptual Error | 131 |
| Personal Readiness | 134 |
| Physical Environment | 216 |
| Physical/Mental Limitations | 18 |
| Plan Inappropriate Operation | 1 |
| Resource Management | 9 |
| Routine | 114 |
| Routine Violation | 39 |
| Rule | 72 |
| Skill | 29 |
| Skill-Based Error | 104 |
| Supervisory Violation | 15 |
| Technological Environment | 19 |
| Training | 4 |
| Uncorrected Problem | 8 |
| Predicted | True Class | |
|---|---|---|
| Class | 0 | 1 |
| 0 | True Negative | False Negative |
| 1 | False Positive | True Positive |
| Type of Learning | Precision | Recall | F1-Score | Accuracy | ||
|---|---|---|---|---|---|---|
| Random Forest | Class | No Fatality | 0.92 | 0.94 | 0.93 | 0.90 |
| Fatality | 0.84 | 0.77 | 0.80 | |||
| Averages | Macro | 0.88 | 0.86 | 0.87 | ||
| Weighted | 0.89 | 0.90 | 0.89 | |||
| Multilayer Perceptron | Class | No Fatality | 0.89 | 0.92 | 0.90 | 0.83 |
| Fatality | 0.75 | 0.59 | 0.66 | |||
| Averages | Macro | 0.80 | 0.76 | 0.77 | ||
| Weighted | 0.83 | 0.83 | 0.83 |
| Type of Learning | Classes | Precision | Recall | Macro F1-Score |
|---|---|---|---|---|
| Random | Below 50% | 0.43 | 0.18 | 0.41 |
| Forest | 50%–<50% | 0.21 | 0.21 | |
| Active | Below 50% | 0.75 | 0.38 | 0.72 |
| Learning | 50%–<50% | 0.75 | 0.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogueira, R.P.R.; Melicio, R.; Valério, D.; Santos, L.F.F.M. Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry. Appl. Sci. 2023, 13, 4069. https://doi.org/10.3390/app13064069
Nogueira RPR, Melicio R, Valério D, Santos LFFM. Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry. Applied Sciences. 2023; 13(6):4069. https://doi.org/10.3390/app13064069
Chicago/Turabian StyleNogueira, Rui P. R., Rui Melicio, Duarte Valério, and Luís F. F. M. Santos. 2023. "Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry" Applied Sciences 13, no. 6: 4069. https://doi.org/10.3390/app13064069
APA StyleNogueira, R. P. R., Melicio, R., Valério, D., & Santos, L. F. F. M. (2023). Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry. Applied Sciences, 13(6), 4069. https://doi.org/10.3390/app13064069