
Multi-Scale Channel Adaptive Time-Delay Neural Network and Balanced Fine-Tuning for Arabic Dialect Identification


Abstract
:1. Introduction
- We propose a dialect identification model that is based on the ECAPA-TDNN network as the backbone and that incorporates the proposed MSCA-Res2Block module, which enables multi-scale channel adaptation in TDNN. Our model improves Cavg by 22% compared to ECAPA-TDNN.
- We propose a balanced fine-tuning strategy to address data imbalance, which has potential applicability in other domains.
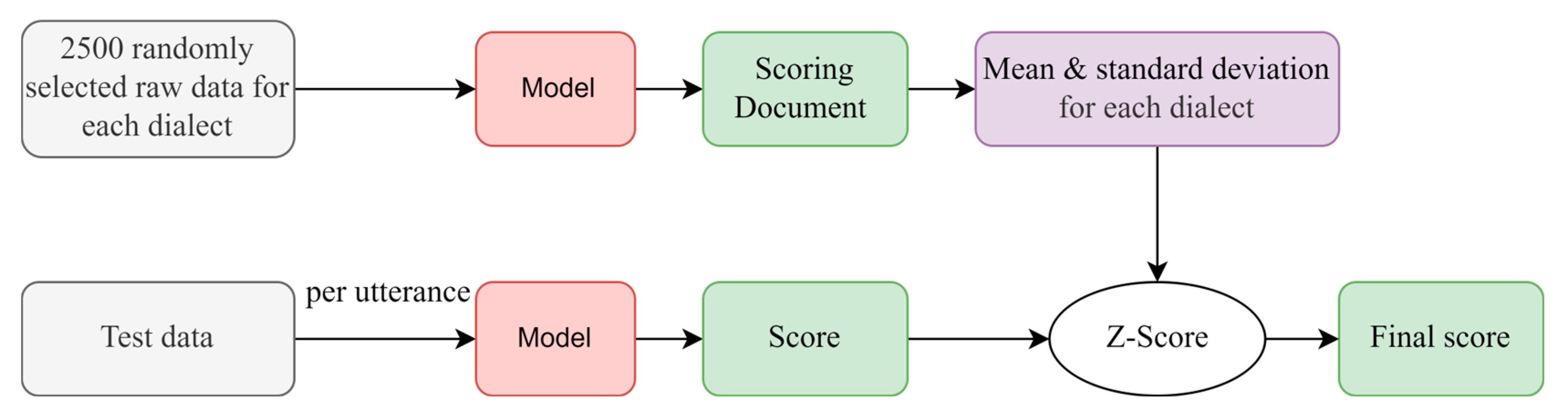
- We investigate the complementary effects of training models with diverse data and introduce the Z-Score standardization approach to address the variations in score distribution among distinct dialects.
2. Related Works
2.1. SE-Res2Block
2.2. Multi-Level Inputs, Multi-Scale Aggregation, and Attention Pooling
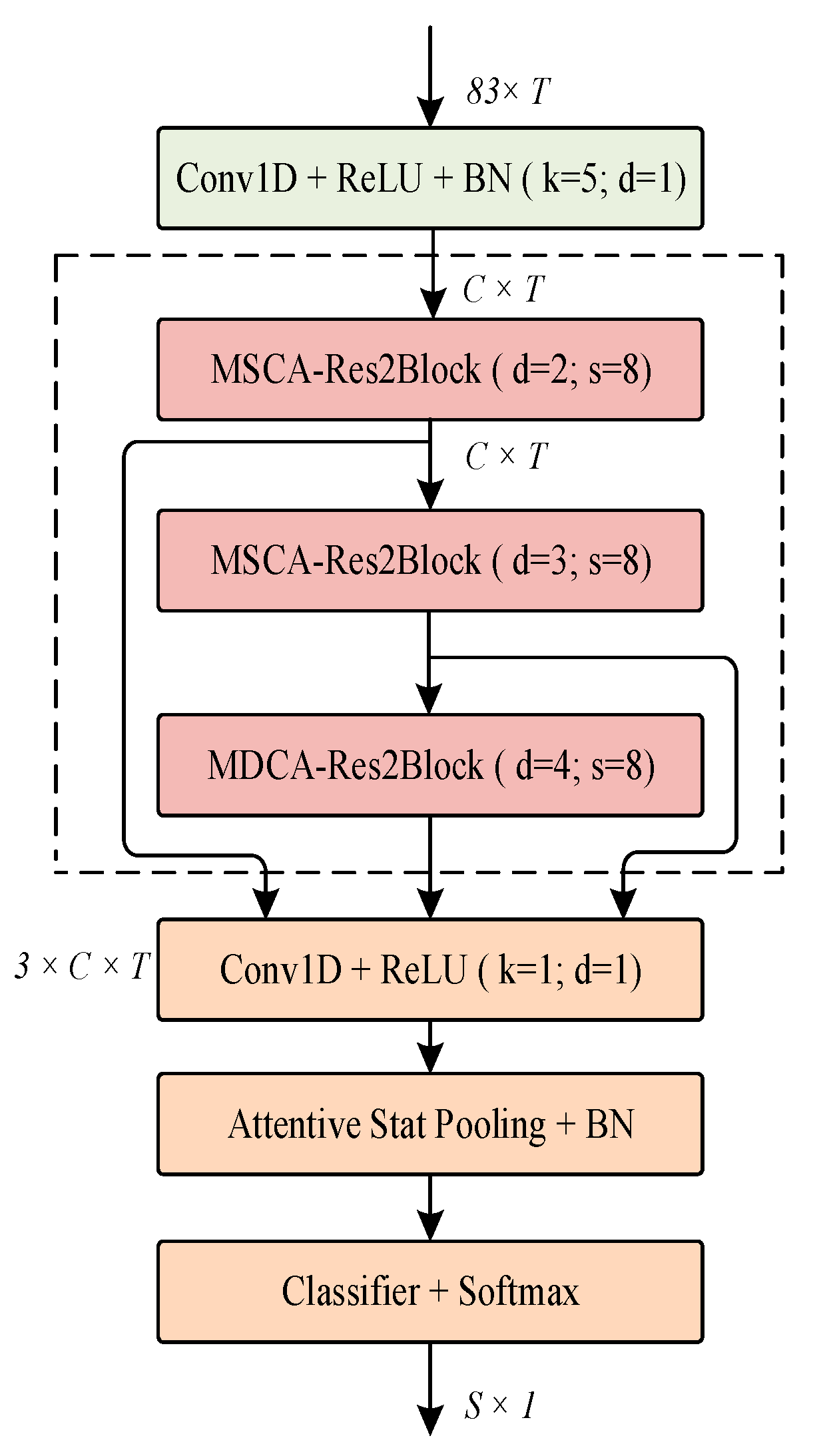
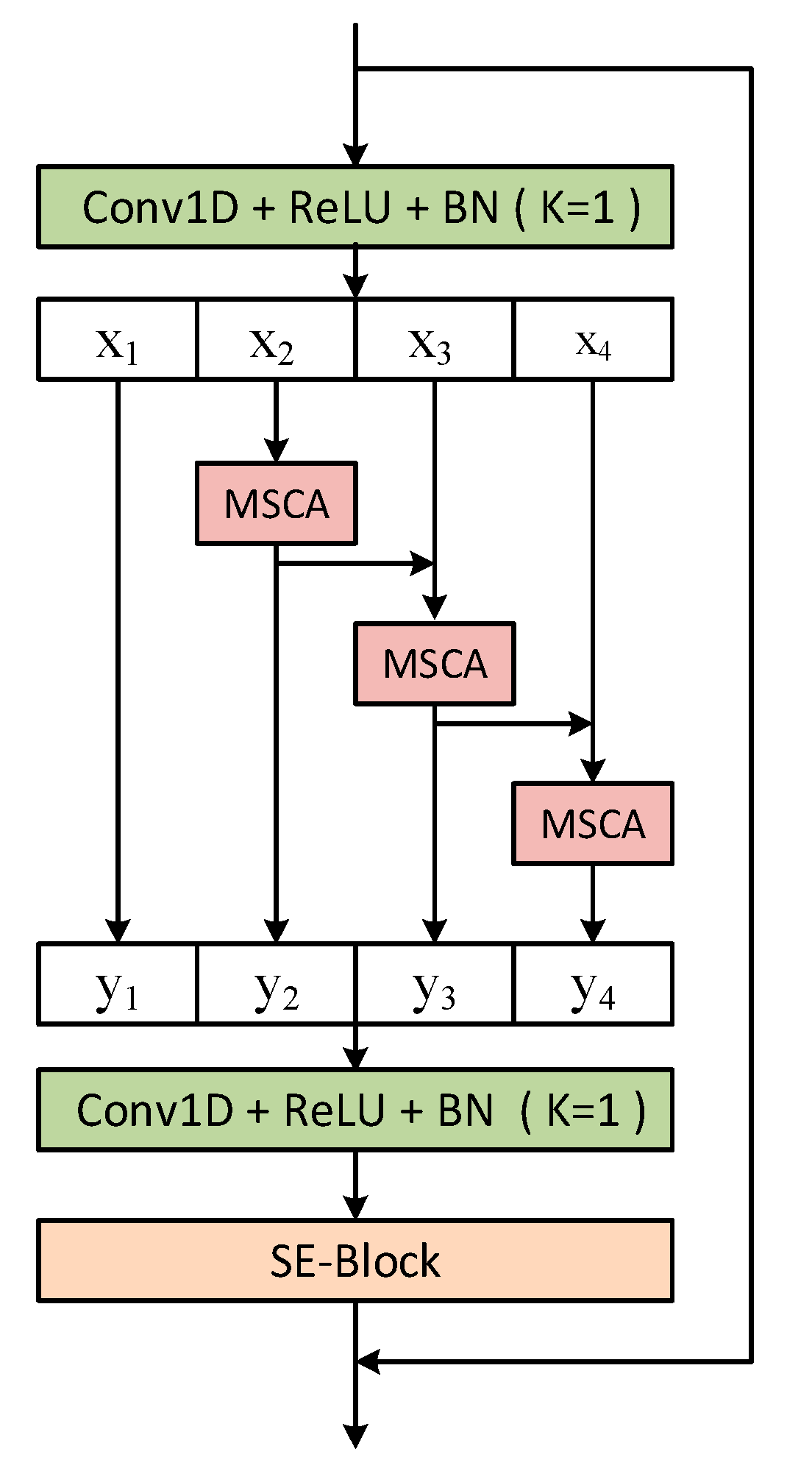
3. The Proposed Model Architecture
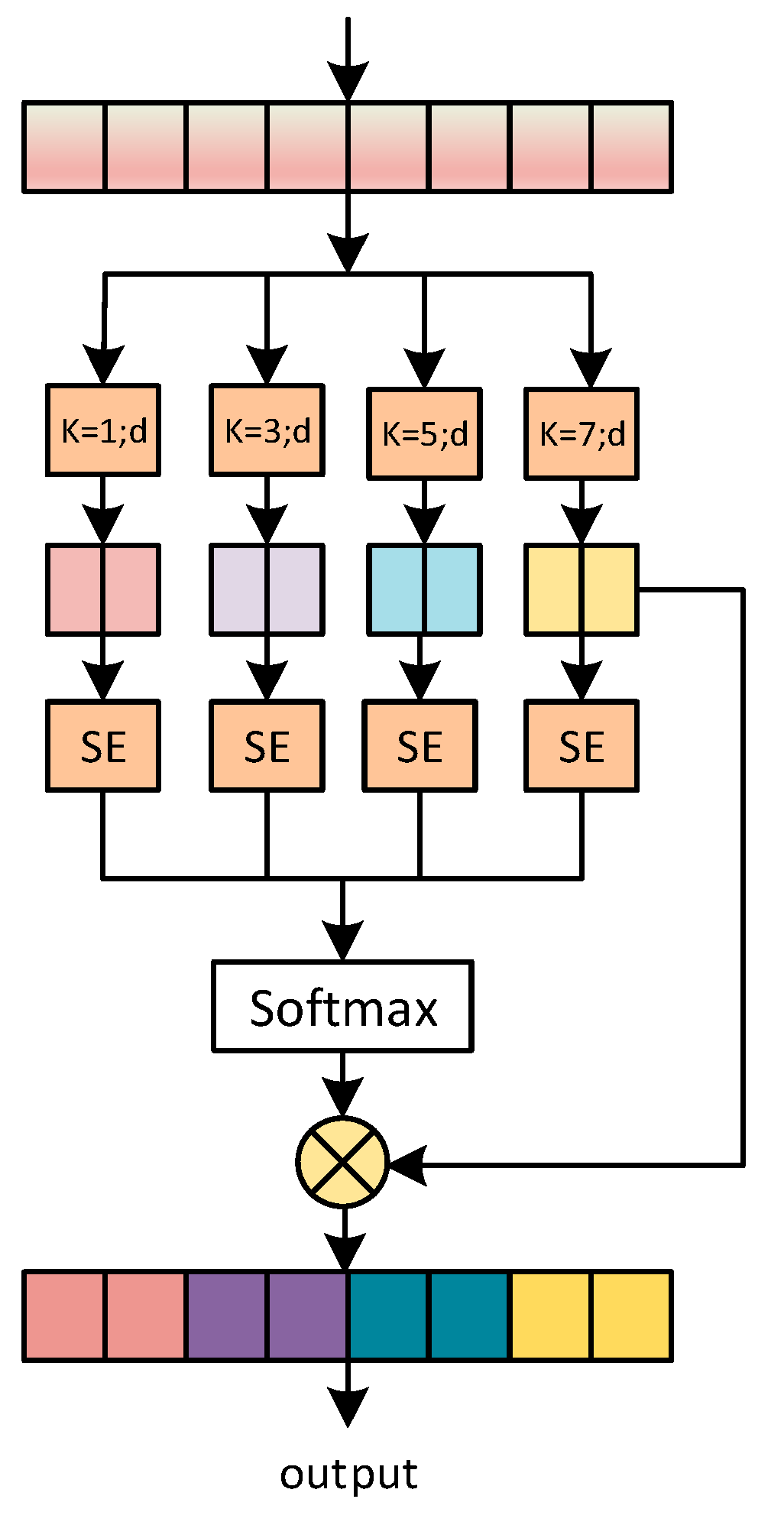
MSCA-Res2Block
4. Experimental Setup
4.1. Dataset
4.2. Experimental Details
4.3. Evaluation Protocol
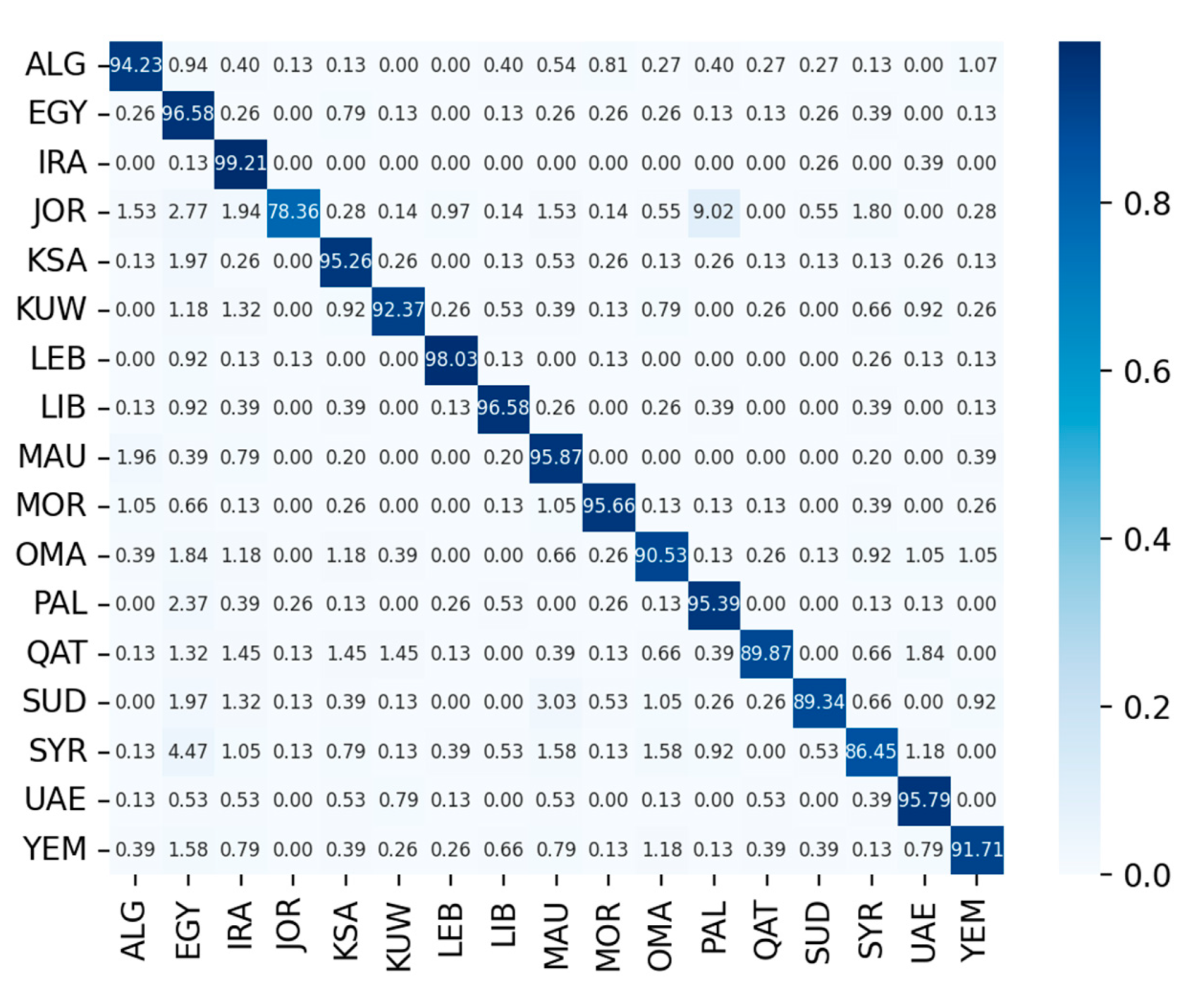
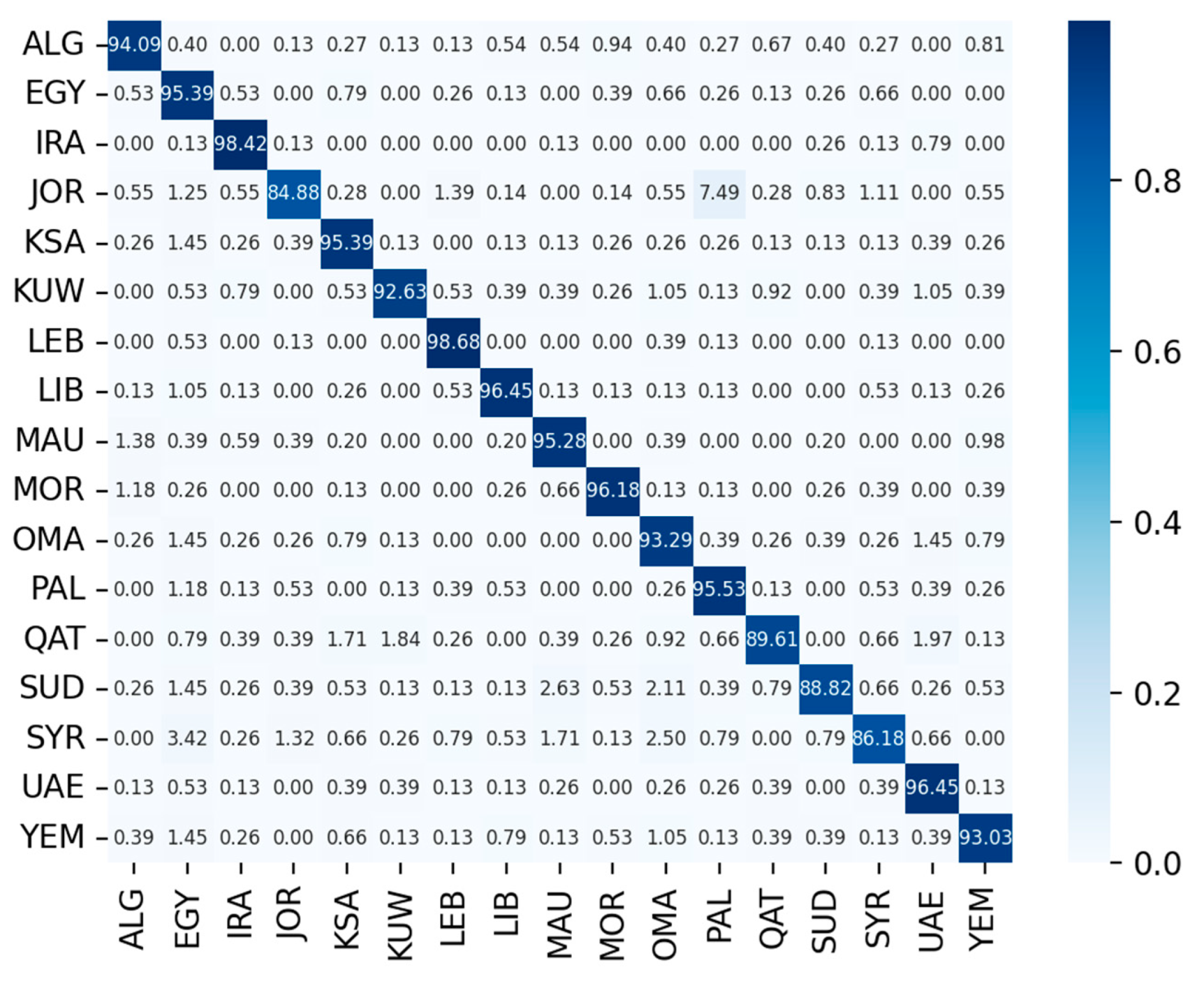
5. Result and Analysis
5.1. Comparison of ECAPA-TDNN and MSCA-TDNN Systems
5.2. Comparison with Advanced Systems
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dehak, N.; Torres-Carrasquillo, P.A.; Reynolds, D.; Dehak, R. Language Recognition via I-Vectors and Dimensionality Reduction. In Proceedings of the Interspeech 2011, Florence, Italy, 27 August 2011; pp. 857–860. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; McCree, A.; Sell, G.; Povey, D.; Khudanpur, S. Spoken Language Recognition Using X-Vectors. In Proceedings of the The Speaker and Language Recognition Workshop (Odyssey 2018), Baltimore, MD, USA, 26 June 2018; pp. 105–111. [Google Scholar]
- Richardson, F.; Reynolds, D.A.; Dehak, N. A Unified Deep Neural Network for Speaker and Language Recognition. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015; pp. 1146–1150. [Google Scholar]
- Biadsy, F. Automatic Dialect and Accent Recognition and Its Application to Speech Recognition; Columbia University: New York, NY, USA, 2011. [Google Scholar]
- Jiao, Y.; Tu, M.; Berisha, V.; Liss, J. Accent Identification by Combining Deep Neural Networks and Recurrent Neural Networks Trained on Long and Short Term Features. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8 September 2016; pp. 2388–2392. [Google Scholar]
- Li, B.; Sainath, T.N.; Sim, K.C.; Bacchiani, M.; Weinstein, E.; Nguyen, P.; Chen, Z.; Wu, Y.; Rao, K. Multi-Dialect Speech Recognition with a Single Sequence-to-Sequence Model. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4749–4753. [Google Scholar]
- Gao, Q.; Wu, H.; Sun, Y.; Duan, Y. An End-to-End Speech Accent Recognition Method Based on Hybrid CTC/Attention Transformer ASR. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7253–7257. [Google Scholar]
- Li, Z.; Zhao, M.; Hong, Q.; Li, L.; Tang, Z.; Wang, D.; Song, L.; Yang, C. AP20-OLR Challenge: Three Tasks and Their Baselines. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 550–555. [Google Scholar]
- Wang, B.; Hu, W.; Li, J.; Zhi, Y.; Li, Z.; Hong, Q.; Li, L.; Wang, D.; Song, L.; Yang, C. OLR 2021 Challenge: Datasets, Rules and Baselines. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1097–1103. [Google Scholar]
- Lin, W.; Madhavi, M.; Das, R.K.; Li, H. Transformer-Based Arabic Dialect Identification. In Proceedings of the 2020 International Conference on Asian Language Processing (IALP), Kuala Lumpur, Malaysia, 4–6 December 2020; pp. 192–196. [Google Scholar]
- Amani, A.; Mohammadamini, M.; Veisi, H. Kurdish Spoken Dialect Recognition Using X-Vector Speaker Embedding. In Proceedings of the Speech and Computer; Springer: Cham, Switzerland, 2021; pp. 50–57. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A Time Delay Neural Network Architecture for Efficient Modeling of Long Temporal Contexts. In Proceedings of the Interspeech 2015, Dresden, Germany, 6 September 2015; pp. 3214–3218. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; McCree, A.; Povey, D.; Khudanpur, S. Speaker Recognition for Multi-Speaker Conversations Using X-Vectors. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5796–5800. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks. In Proceedings of the Interspeech 2018, Hyderabad, India, 2 September 2018; pp. 3743–3747. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3830–3834. [Google Scholar]
- Ali, A.; Shon, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Glass, J.; Renals, S.; Choukri, K. The MGB-5 Challenge: Recognition and Dialect Identification of Dialectal Arabic Speech. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 1026–1033. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, J.; Jiang, T.; Li, Z.; Li, L.; Hong, Q. Deep Speaker Embedding Extraction with Channel-Wise Feature Responses and Additive Supervision Softmax Loss Function. In Proceedings of the Interspeech 2019, Graz, Austria, 15 September 2019; pp. 2883–2887. [Google Scholar]
- Lee, J.; Nam, J. Multi-Level and Multi-Scale Feature Aggregation Using Pretrained Convolutional Neural Networks for Music Auto-Tagging. IEEE Signal Process. Lett. 2017, 24, 1208–1212. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Song, Y.; McLoughlin, I.; Li, P.; Jiang, Y.; Dai, L.-R. Improving Aggregation and Loss Function for Better Embedding Learning in End-to-End Speaker Verification System. In Proceedings of the Interspeech 2019, ISCA, Graz, Austria, 15 September 2019; pp. 361–365. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive Statistics Pooling for Deep Speaker Embedding. In Proceedings of the Interspeech 2018, Hyderabad, India, 2 September 2018; pp. 2252–2256. [Google Scholar]
- Shon, S.; Ali, A.; Samih, Y.; Mubarak, H.; Glass, J. ADI17: A Fine-Grained Arabic Dialect Identification Dataset. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8244–8248. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. (Eds.) The Kaldi Speech Recognition Toolkit; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Sadjadi, S.O.; Kheyrkhah, T.; Tong, A.; Greenberg, C.; Reynolds, D.; Singer, E.; Mason, L.; Hernandez-Cordero, J. The 2017 NIST Language Recognition Evaluation. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2018), ISCA, Les Sables d’Olonne, France, 26 June 2018; pp. 82–89. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Dev | Test | |
|---|---|---|---|
| Dur (h) | 3033.4 | 24.9 | 33.1 |
| Utterances | 1,043,269 | 8955 | 12,615 |
| Data Usage | ECAPA-TDNN | MSCA-TDNN |
|---|---|---|
| Balance data | 6.83 | 6.30 |
| Speed perturbation data | 6.09 | 5.28 |
| Balanced fine-tuning | 5.43 | 4.57 |
| Balance + speed+ fine-tuning | 6.00 | 5.54 |
| Balance + speed + fine-tuning + Z-Score | 5.39 | 4.19 |
| System | Overall | <5 s | 5∼20 s | >20 s | ||||
|---|---|---|---|---|---|---|---|---|
| Cavg | Acc | Cavg | Acc | Cavg | Acc | Cavg | Acc | |
| E2E (Softmax) [23] | 13.7 | 82.0 | 18.8 | 76.2 | 10.9 | 85.1 | 6.7 | 90.4 |
| Transformer [10] | - | 82.54 | - | 76.21 | - | 86.01 | - | 90.58 |
| UKent [16] | 6.2 | 91.1 | 8.3 | 88.4 | 5.3 | 92.3 | 2.5 | 96.1 |
| DKU [16] | - | 93.8 | - | - | - | - | - | - |
| DKU (Fusion) [16] | 4.3 | 94.9 | 5.5 | 93.3 | 3.7 | 95.6 | 2.0 | 97.7 |
| MSCA-TDNN (Ours) | 4.19 | 94.28 | 5.64 | 92.23 | 3.45 | 95.22 | 1.98 | 98.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Q.; Zhou, R. Multi-Scale Channel Adaptive Time-Delay Neural Network and Balanced Fine-Tuning for Arabic Dialect Identification. Appl. Sci. 2023, 13, 4233. https://doi.org/10.3390/app13074233
Luo Q, Zhou R. Multi-Scale Channel Adaptive Time-Delay Neural Network and Balanced Fine-Tuning for Arabic Dialect Identification. Applied Sciences. 2023; 13(7):4233. https://doi.org/10.3390/app13074233
Chicago/Turabian StyleLuo, Qibao, and Ruohua Zhou. 2023. "Multi-Scale Channel Adaptive Time-Delay Neural Network and Balanced Fine-Tuning for Arabic Dialect Identification" Applied Sciences 13, no. 7: 4233. https://doi.org/10.3390/app13074233
APA StyleLuo, Q., & Zhou, R. (2023). Multi-Scale Channel Adaptive Time-Delay Neural Network and Balanced Fine-Tuning for Arabic Dialect Identification. Applied Sciences, 13(7), 4233. https://doi.org/10.3390/app13074233