1. Introduction
This article introduces a ship defense strategy using a clustered formation of multiple drones. We handle a scenario where a high-speed target with variable velocity heads towards the ship. The role of the drone team is to protect the ship from the incoming target.
We propose a ship defense approach with multiple drones, such that each drone is not equipped with powerful sensors or an on-board computer. Thus, a drone cannot measure the target, and the target moves based on the commands sent by the ship. In this way, we can decrease the cost of a drone, which can be destroyed once it intersects the target. This enables us to develop rather cheap drones.
Instead, the ship measures the position of the target in real time. Position measurements can be provided by various sensors, such as radar, IR, or laser sensors of the ship. Each drone’s guidance law is calculated by the ship’s on-board computer and is transmitted to each drone in real time. (This approach relies on the communication between the ship and a drone. Since the signal speed is sufficiently fast ( m/s) in the air, we argue that signal delay is negligible in our ship defense scenario.)
Consider a high-speed target whose goal is to hit a ship. The target heads towards its goal (ship) at least in the terminal phase. Otherwise, it is impossible to make a target hit the ship.
Therefore, this paper lets multiple drones form a planar grid formation, whose center lies on the line segment connecting the target and the ship. Moreover, the planar grid formation is generated to be perpendicular to the line segment connecting the target and the formation center. The grid formation can be considered as a “net” structure for capturing the incoming target. The target may perform elusive maneuvers, and there may be measurement noise in measuring the target position. By maximizing the grid formation size, we can increase the capture rate, even when there exists error in the prediction of the target’s position. Since the target is guided to hit its goal (ship), the drones can effectively block the target using this grid formation.
As an interceptor, we consider a highly maneuverable drone, such as a quadrotor drone [
1,
2,
3], which is much slower than the incoming target. This article addresses a high-level path planner, which generates reference position signals for a low-level controller [
1,
2,
3].
To the best of our knowledge, our paper is novel in developing a ship defense approach using clustered multiple drones. Our paper is novel in addressing a 3D formation of multiple drones for intercepting a high-speed target with variable speeds. We show that in the case where the drones block the LOS line between the target and the ship, the target cannot reach the ship without being captured by the drones. Since the target is guided to hit its goal (ship), the drones can effectively block the target using this strategy. We further let slow drones stay close to the ship in order to protect the ship from the fast target. As far as we know, our paper is novel in showing that slow drones can capture a fast target by staying close to the ship while blocking the LOS at all times.
Our paper is unique in capturing a maneuvering target with variable speeds, which can be faster than the interceptors. In order to estimate the pose of a maneuvering high-speed target, we applied target-tracking filters in [
4]. We control the drone formation, based on the prediction of the target’s position after one sample-index in the future. This prediction may be erroneous due to the target’s elusive maneuvers or measurement noise. This is the motivation for utilizing a grid formation of drones instead of a single drone. Since we use a grid formation, we can increase the capture rate even when the target prediction is erroneous. By maximizing the grid formation size, we can increase the capture rate even when there exists error in the prediction of the target’s position.
To the best of our knowledge, our paper is novel in the following aspects:
We develop a ship defense approach using clustered multiple drones;
We use a 3D formation of multiple drones for intercepting a high-speed target with variable speeds;
We let the drones stay close to the ship while blocking the LOS between the ship and the target. Thus, we enable slow drones to capture a fast target.
Through MATLAB simulations, the effectiveness of our multi-agent guidance law is verified by comparing it with other state-of-the-art guidance controls.
We organize this article as follows.
Section 2 addresses the literature review of this paper.
Section 3 addresses the preliminary information of this paper.
Section 4 discusses several definitions and assumptions in this article.
Section 5 introduces our multi-agent guidance law.
Section 6 shows simulation results to present the effectiveness of the proposed guidance law.
Section 7 provides a conclusion.
2. Literature Review
There are many papers on interceptors’ guidance laws [
5,
6,
7,
8]. The authors of [
9,
10,
11,
12,
13,
14,
15,
16] applied motion camouflage to develop the guidance law of an interceptor. Here, we say that the interceptor is in the motion camouflage state if an interceptor moves in the presence of a target while appearing stationary at a focal point.
References [
17,
18] developed a motion camouflage guidance law so that the interceptor approaches the target while appearing stationary at a focal point that is infinitely far from the interceptor. The authors of [
19] used a neural network architecture to perform motion camouflage in 2D environments. The authors of [
12] developed an optimal control approach to derive a 2D motion camouflage position for an interceptor, assuming there is a constant velocity (speed and heading) target. However, assuming a target with constant velocity is not realistic since a maneuvering target could escape from the interceptor. Our paper thus handles a target with variable velocity.
Proportional Navigation Guidance (PNG) laws have been widely applied to let an interceptor hit the target [
20,
21,
22,
23]. PNG laws are designed considering an interceptor that can measure the bearing of the target by utilizing on-board sensors. PNG laws are based on the fact that two vehicles are on a collision course when their direct Line-Of-Sight (LOS) does not change direction as they get closer to each other. PNG laws are designed so that the interceptor velocity vector rotates at a rate proportional to the rotation rate of the line-of-sight and in the same direction.
Multi-agent systems can be applied for many tasks, such as monitoring environments [
24,
25], multi-agent herding [
26], and sensor deployment [
27,
28,
29,
30]. References [
31,
32] controlled multiple mobile sensors to estimate the target position in real time. References [
33,
34] considered the case where two interceptors, which measure bearings of a target, track the target in two dimensions. The formulation of the homing problem of multiple missiles against a single target, subject to constraints on the impact time, was discussed in [
35]. In [
36], a fully distributed adaptive method was proposed to solve the simultaneous attack problem with multiple missiles against maneuvering targets. The authors of [
37] considered the relative interception angle constraints of multiple interceptors, which is intended to enhance the survivability of multiple interceptors against a defense system with a high value target and also to maximize the collateral target damage. The authors of [
38] addressed simultaneous cooperative interception for a scenario where the successful handover cannot be guaranteed by a single interceptor due to the target maneuver and movement information errors at the handover moment.
As far as we know, other guidance laws in the literature make one or more interceptors continue to chase the target. Our paper is unique in making slow interceptors (drones in our paper) stay close to the ship, so they can block a fast target from reaching the ship. This blocking strategy is desirable considering the energy consumption of an interceptor since an interceptor does not have to move far from the ship. Through MATLAB simulations, the effectiveness of this blocking strategy is verified by comparing it with other state-of-the-art guidance controls.
3. Preliminaries
This article utilizes two frames: an inertial reference frame
and a body-fixed frame
[
39]. We address several definitions in rigid-body dynamics [
39].
The origin of is a point with three axes pointing North, East, and Down, respectively. We use the virtual agent for drone controls. The virtual agent is a virtual drone located at the center of the grid formation. is fixed to the virtual agent, such that the origin of is at the virtual agent’s center.
The virtual agent changes its yaw and pitch while not rotating its body. In rigid-body dynamics [
39],
and
define
pitch and
yaw, respectively. For convenience, let
define
. In addition, let
define
. Let
define
.
The rotation matrix indicating the counterclockwise (CC) rotation of an angle
centered at the
z-axis in
is
The rotation matrix representing the CC rotation of an angle
centered at the
y-axis in
is
The combined rotation matrix is built by multiplying Equations (
1) and (
2) to obtain
4. Assumptions and Definitions
This section discusses assumptions and definitions in our paper. returns a bigger value between two variables (a and b). In addition, returns a smaller value between two variables (a and b). In our paper, bold characters are used to denote vectors and matrices. is the angle formed by two vectors ( and ). Mathematically, . Here, . is the line segment connecting two locations and . Furthermore, indicates the length of .
This article uses the discrete-time system, where T denotes the sample duration. In this article, all drones make a planar grid formation to protect against the incoming target. The grid formation can be considered as a “net” structure for capturing the incoming target.
Let
M indicate the total number of drones.
M is selected such that
where
is a positive integer.
In the case where , we use only one drone. In this case, the grid formation cannot be used, and the waypoint of the drone is set as the virtual agent.
In the inertial reference frame, let define the 3D Cartesian coordinates of the virtual agent. In the inertial reference frame, let denote the 3D Cartesian coordinates of the i-th drone at sample-index k. Note that the subscript k indicates the sample-index k.
In the inertial reference frame, let denote the target’s 3D Cartesian coordinates at sample-index k. In the inertial reference frame, let denote the ship’s 3D Cartesian coordinates at sample-index k.
Let denote the target’s speed at sample-index k. Let denote the speed of the i-th drone at sample-index k. Let indicate the maximum speed of a drone or the virtual agent. Note that , , and are scalar values.
We say that the target is
captured when the relative distance between the target and any drone is less than a constant, say
. The motion model of the
i-th drone (
) is
Here,
indicates the
i-th drone’s heading vector at sample-index
k. Note that
is a unit vector presenting the
i-th drone’s heading direction. The motion model in Equation (
5) is commonly used in multi-drone systems [
40,
41,
42,
43,
44,
45,
46].
In Equation (
5),
generates the high-level reference position signal at every sample-index
k. For letting the
i-th drone move towards
at every sample-index
k, one utilizes low-level controls in [
1,
2,
3].
The motion model of the virtual agent is
Recall that the virtual agent is at the center of the grid formation. We say that the virtual agent is in the lineState at sample-index k if the line segment meets the virtual agent position . At every sample-index k, and are set so that the virtual agent is in the lineState.
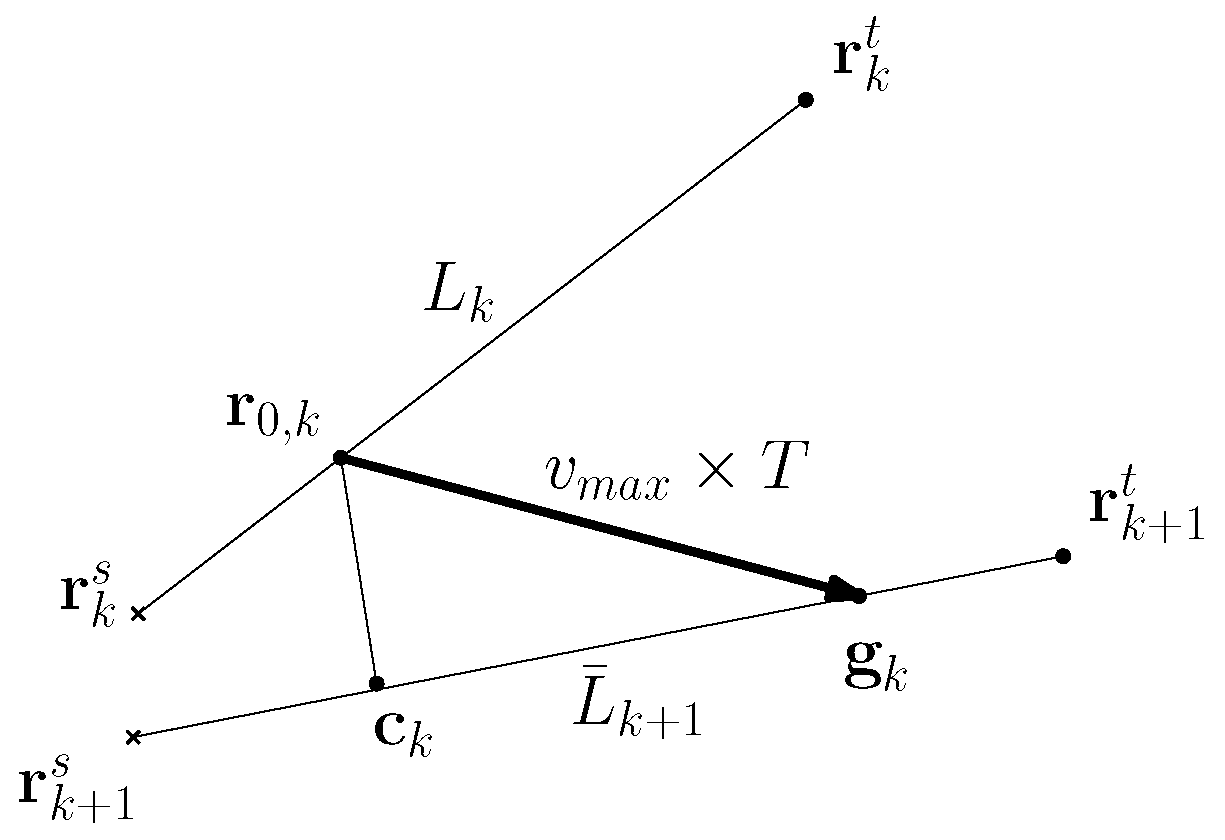
Let denote the infinite line crossing both and at sample-index k. Let denote the infinite line crossing both and . is the point on , which is the closest to .
Figure 1 depicts the case where the ship moves as the time index changes from
k to
. The ship positions are indicated by crosses. In this figure,
,
, and
are depicted.
Assumptions
This article assumes that both the ship and a drone’s 3D Cartesian coordinates are measured in real time. Global Positioning Systems (GPSs) and Inertial Measurement Units (IMUs) can be used for this localization.
Furthermore, the ship can measure the target’s 3D Cartesian coordinates at every sample-index. Position measurements can be provided by various sensors, such as radar sensors or laser sensors. Therefore, the ship at sample-index k can derive .
Furthermore, based on the target’s recent trajectory, the ship at sample-index
k can predict
, the target’s 3D Cartesian coordinates, after one sample-index in the future.
Section 5.1 shows how to predict the target’s 3D Cartesian coordinates after one sample-index in the future.
The ship can also predict , the ship’s 3D Cartesian coordinates, after one sample-index in the future. This is feasible because the ship has GPS and IMU. Therefore, the ship can predict , which crosses both and .
It is desirable that as the target is caught, it is sufficiently far from the ship. Otherwise, the ship may be partially caught by the debris of the target. Let define the safety distance. The safety distance is set by the operator of the drones. As the target is caught, it is desirable that its distance from the ship is bigger than the safety distance . This way, we can assure the safety of the ship.
5. Multi-Drone Guidance Law
We consider a high-speed target whose goal is to hit a ship. The target heads towards its goal (ship) at least in the terminal phase. Otherwise, it is impossible to make a target hit the ship.
Therefore, we let multiple drones form a planar grid formation, whose center lies on the line segment connecting the target and the ship. Moreover, the planar grid formation is generated to be perpendicular to the line segment connecting the target and the formation center. The grid formation can be considered as a “net” structure for capturing the incoming target. By maximizing the grid formation size, we can increase the capture rate, even when there exists error in the prediction of the target’s position. Since the target is guided to hit its goal (the ship), the drones can effectively block the target using this grid formation.
The proposed multi-drone guidance law is summarized as follows. At every sample-index, the ship measures the 3D Cartesian coordinates of the incoming target. Thereafter, we run the Kalman filter to predict the target’s 3D Cartesian coordinates after one sample-index in the future. See
Section 5.1 for the prediction of the target’s position after one sample-index.
Based on the predicted target pose, the virtual agent is guided to remain in the lineState. See
Section 5.2 for the guidance law of the virtual agent. In addition, each drone is guided to generate a grid formation centered at the virtual agent. See
Section 5.3 for the guidance law of a drone.
Figure 2 shows the block diagram of the proposed multi-drone guidance law.
5.1. Prediction of the Target’s Position after One Sample-Index
The ship can measure the target’s 3D Cartesian coordinates at every sample-index. To track a target with variable velocity, we present how to predict the target one sample-index forward in time. In order to track a maneuvering target, we applied target-tracking filters to [
4].
In the inertial reference frame, let
indicate the vector presenting the 3D coordinates of the target at sample-index
k. In addition,
denotes the vector presenting the target velocity at sample-index
k. Furthermore,
defines the vector presenting the target acceleration at sample-index
k. Let
define the vector presenting the target state. Based on [
4], the target’s process model is set as
where
is the process noise with following properties:
. Here,
denotes a Gaussian distribution with a mean of
and a covariance matrix
. Furthermore,
in Equation (
7) is
where we use
In
,
is set as
where
a and
in Equation (
10) are tuning parameters for tracking a maneuvering target. Detailed derivations of Equation (
7) appear in [
4].
At every sample-index
k, the ship measures the target’s 3D position, say
. See the first block of
Figure 2. The target measurement model is
where
is
Furthermore,
is the measurement noise, such that
. We assume that
is known a priori.
The Kalman filter (KF) [
47] is applied to obtain the estimate vector and its covariance at every sample-index. The KF is composed of the prediction step and the measurement update step. In the KF, the prediction step uses Equation (
7), and the measurement update step uses Equation (
12).
Let define the estimation of derived using all measurements up to sample-index k. Let define the error covariance matrix of .
In the prediction step of the KF, we derive the predicted state vector as
where Equation (
7) is used. Utilizing Equations (
7) and (
10), the covariance matrix is predicted as
The measurement update step is
where
Here, we use
In addition, the covariance matrix is updated using
The ship at sample-index
k predicts the target state after one sample-index forward in time using Equation (
14). Let
denote the target position at sample-index
, which is predicted using all measurements up to sample-index
k. Using Equation (
14),
is predicted as
Here, recall that
was defined in Equation (
13).
We acknowledge that the prediction of the target’s position may not be accurate due to the target’s elusive maneuvers or measurement noise. This is the motivation for using a formation of drones instead of a single drone.
In our paper, a formation of drones is used instead of a single drone in order to increase the capture rate. Since we use a drone formation, we can increase the capture rate even when the target prediction is erroneous. Through MATLAB simulations, the effectiveness of our formation-based guidance law is verified by comparing it with other state-of-the-art guidance controls.
5.2. Guidance Law of the Virtual Agent
Using the predicted 3D coordinates of the target, the virtual agent is guided to remain in the lineState. At every sample-index k, the virtual agent is guided to head towards the guidance point , which is defined as follows:
1. Suppose that
. This implies that the ship needs to expel the virtual agent away from the ship. Moreover, suppose that
holds. Then, we set the guidance point as
Here,
is defined as
This implies that
is
. See
Figure 1 for an illustration of this case.
2. Otherwise, we set the guidance point as
At every sample-index
k, the virtual agent moves to reach
if possible. Suppose that
. Furthermore, suppose that Equation (
21) holds, as depicted in
Figure 1. Consider a sphere centered at
, whose radius is
. Using Equation (
21),
meets this sphere at two points. Between these two points,
is the point that is closer to
. In this way, the virtual agent can approach the target while staying on the line segment that connects the target and the ship.
The direction command
is selected to make the virtual agent move towards
at sample-index
. At every sample-index
k, the direction command is set as follows.
At every sample-index k, the virtual agent sets the new direction command as
Note that the direction command is a unit vector.
In addition, the speed command at sample-index
k is set as follows.
At every sample-index k, the virtual agent sets the new speed command as
This implies that the virtual agent moves with the maximum speed
when it is too far from the guidance point
.
Consider the situation in which holds. In this situation, the virtual agent heads towards directly while not using the direction command . In this way, the target is caught at sample-index .
According to the definitions of the guidance point
(see Equations (
22) and (
24)),
lies on
.
In the case where
, the heading command (Equation (
25)) and speed command (Equation (
26)) lead to
We thus have the following theorem.
Theorem 1. Suppose that . The heading command (Equation (25)) and speed command (Equation (26)) make exist on . Theorem 1 implies that in the case where , the virtual agent position is on the line segment . Since the target’s goal is reaching the ship, the target must be hit by the virtual agent eventually.
and Meet at a Point
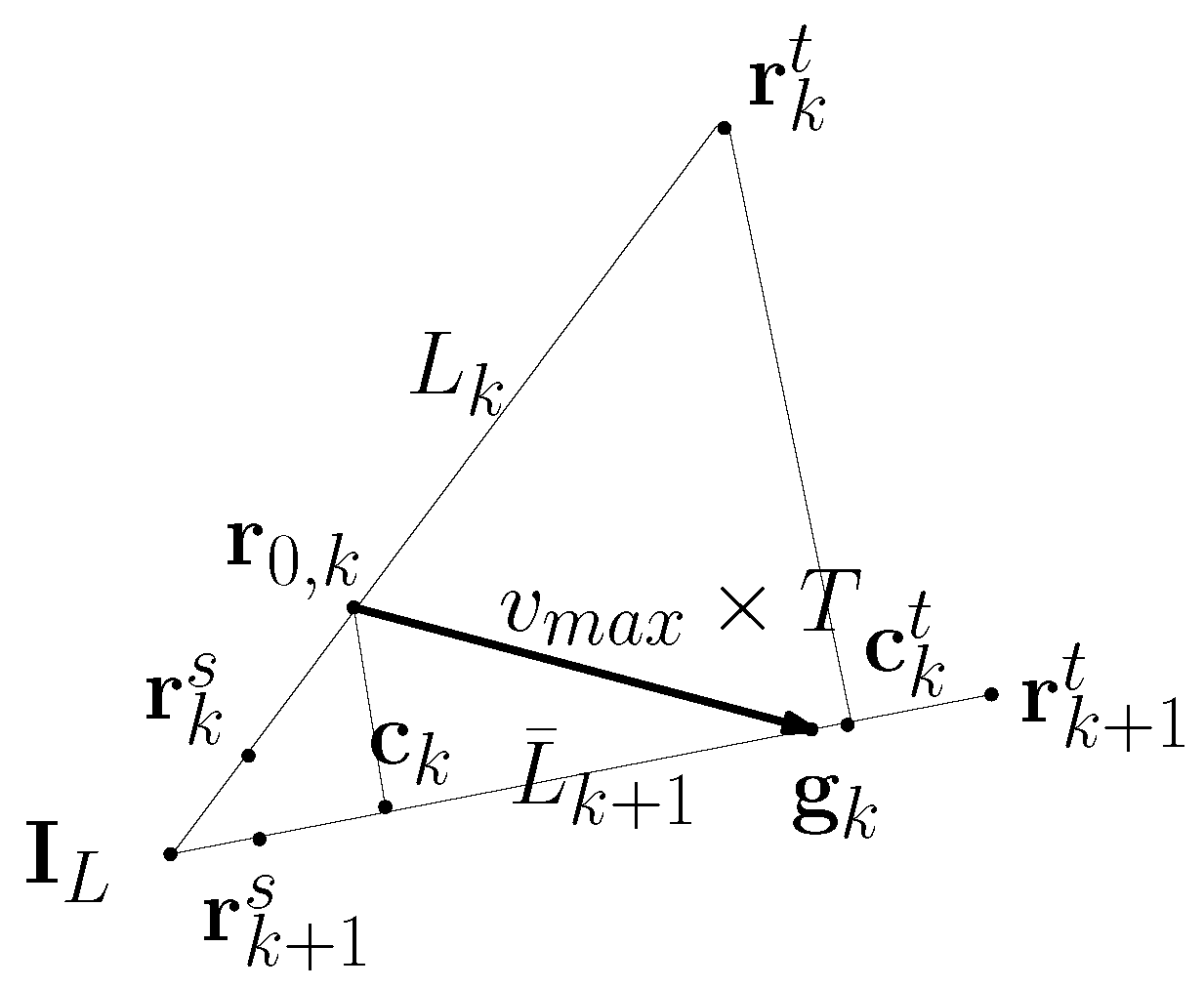
Next, we consider a special case where and meet at a point. Here, recall that denotes the infinite line crossing both and . In the inertial reference frame, let denote the 3D coordinates of the intersection between and . For instance, if the ship is static, then and meet at the ship position .
Suppose that lies on . Let denote the point on , which is the closest to . Let for convenience.
Figure 3 depicts the case where
and
meet at
. Using the geometry in this figure, we have
Since the target speed is
, we have
Using Equations (
28) and (
29), we have
Suppose that the drone’s maximum speed
satisfies
The next theorem addresses the condition for remaining in the lineState at every sample-index.
Theorem 2. Suppose that and meet at a point, say . Suppose that lies on . The target speed is . If the drone’s maximum speed satisfies Equation (31), then lies on . Proof. Suppose the drone’s maximum speed satisfies Equation (
31). Then, Equations (
30) and (
31) lead to
This implies that Equation (
21) is met. In the case where Equation (
21) is met, Theorem 1 makes
exist on
. The proof is complete. □
In practice, the ship moves much slower than the target. Thus, the ship position is close to
, as plotted in
Figure 3. Consider the case where the virtual agent is sufficiently close to the ship. In this case,
is small to satisfy Equation (
31). Then, using Corollary 2,
lies on
. Thus, the virtual agent remains in the lineState at sample-index
.
In the case where the virtual agent stays in the lineState at all times, the target cannot reach the ship without being captured by the virtual agent. In order to stay in the lineState at each sample-index, it is desirable that the virtual agent does not become too far from the ship.
In the case where
is met, the guidance point is set using Equation (
24) instead of Equation (
22). In this way, drones stay close to the ship while staying in the lineState at all times.
Note that Equation (
31) can be satisfied even when
. This implies that even slow drones can capture a fast target when the drones stay close to the ship while staying in the lineState at all times.
5.3. Guidance Law of Every Drone
We let multiple drones form a planar grid formation, such that the formation is perpendicular to the line segment connecting the target and the formation center. The grid formation can be considered a “net” structure for capturing the incoming target. By maximizing the grid formation size, we can increase the capture rate, even when there exists error in the prediction of the target’s position. Since the target is guided to hit its goal (ship), the drones can effectively block the target using this grid formation.
We next handle the guidance law of a drone for the generation of the grid formation. At sample-index k, let grid formation denote a planar formation composed of cells, each with side length . The grid formation is centered at the virtual agent, and we adjust the grid formation so that it is normal to at each sample-index k. We change the pitch and yaw of the virtual agent, but we do not change the roll of the virtual agent. Thus, the grid formation does not roll either.
Let denote the relative position of the target with respect to the virtual agent at sample-index k. At each sample-index k, the planar grid formation is oriented, such that the formation plane is perpendicular to .
For
and
, let
be defined as
Since
and
, we have
Here, Equation (
4) is used. Using Equations (
33) and (
34), the drone index
has its associated
.
For
and
, let
denote the
n-th drone’s waypoint in the body-fixed frame at sample-index
k. See that these
waypoints are generated on the
plane in the body-fixed frame. From now on,
n denotes
for notation simplicity.
In the case where we set
, we use only one drone. In this case, the grid formation cannot be generated. If we use only one drone, then the drone’s waypoint in the body-fixed frame is set as
instead of Equation (
35). Equation (
36) is used to make the single drone move towards the virtual agent. In other words, the waypoint of the drone is set as the virtual agent.
At sample-index 0, all drones are located inside the grid cell of the ship. At sample-index 0, the planar grid formation’s orientation (normal vector) is represented as initial yaw
and initial pitch
, respectively. Under Equation (
3), the
n-th drone’s initial position is located at
, which is given as
Equation (
37) implies that all drones are initially located to form the grid formation with side length
.
Once the drones are launched from the ship, the planar grid formation at each sample-index
k is oriented, such that it becomes perpendicular to
. The unit vector associated with
is
where
.
At each sample-index
k, the planar grid formation’s orientation (normal vector) is represented as
and
, respectively. Since the virtual agent does not rotate, the formation’s orientation does not include rolling motions. Under Equation (
3), the
n-th drone’s waypoint in the inertial frame is
The axis of the grid formation is oriented towards the target
since
, where
. In other words, the planar grid formation is oriented such that it is perpendicular to
.
We next calculate the planar grid formation’s orientation (normal vector),
, and
in Equation (
39), associated with
in Equation (
38). We apply
,
, and
. Here,
indicates the
j-th element of
.
Under Equation (
38), we obtain
Under Equation (
38), we derive
as follows. If
, then we use
If
, then we use
Recall that
defines the waypoint assigned to the
n-th drone at sample-index
k. The heading command of the
n-th drone is set towards
at every sample-index
k.
The heading vector from Equation (5) is set as follows.At every sample-index k, the n-th drone sets its speed command from Equation (5) as The control commands, Equations (
43) and (
44), are used to satisfy
if possible. Once Equation (
45) is met for all
, then all drones form a grid formation at sample-index
.
Consider the case where
at every sample-index
k. In this case, Equation (
45) is met at every sample-index
k.
At sample-index 0, all drones are located inside the ship. At sample-index 0, all drones form the initial grid formation, as presented in Equation (
37). Note that each drone is assigned to a waypoint that is in the body-fixed frame of the virtual agent. See Equation (
39) for waypoint assignments.
Moreover, [
48] can be used to assign a drone to each waypoint, such that the makespan (time for all robots to reach their waypoints) is minimized while also preventing collisions among drones. The authors of [
48] mentioned that their assignment algorithm scales well, such that it can compute the mapping for 1000 robots in less than half a second.
In the worst case, there may be a case where a drone meets another drone while moving toward its assigned waypoint. This case can happen due to localization errors or environment disturbance, such as wind. The drone then uses reactive collision avoidance controls, such as [
49,
50,
51,
52], to avoid an abrupt collision with another drone. Under reactive collision avoidance controls, the drone can change its speed and heading to avoid a sudden collision. We acknowledge that a drone may not reach its waypoint, as it performs evasive maneuvers to avoid a sudden collision with another drone. For instance, suppose that a drone slows downs to avoid a sudden collision at sample-index
k. At the next sample-index
, the drone needs to speed up to reach its new waypoint at sample-index
.
6. MATLAB Simulation
This section demonstrates the effectiveness of our multi-agent guidance law through MATLAB simulations. The sample interval is s. The safety distance is set as 100 m.
In Equation (
12), the measurement noise
is generated with
, where
is the identity matrix such that every diagonal element is 1. This implies that the standard deviation of measurement noise is 1 meter.
Considering the process noise, the motion model of the
i-th drone (
) is
Here,
indicates the process noise of the
i-th drone, such that each term in
has a Gaussian distribution with a mean of 0 and a standard deviation of 1 meter. Because Equation (
47) contains the process noise term
, Equation (
47) is distinct from Equation (
5).
At sample-index 0, the target is at (0, 10,000, 5000) in meters, and the virtual agent is at the origin. The ship is located at (0,0,0) at sample-index 0. Furthermore, the maximum speed of a drone is meters per second. At every sample-index k, the target’s speed, , is 200 meters per second. See that the target moves much faster than a drone.
We say that a target is captured when the distance between a drone and the target is less than meters. Moreover, a target is captured at sample-index k when crosses the grid formation between sample-index and k. Because , the target is considered to be captured between sample-index and k.
Furthermore, a simulation ends when the distance between the ship and the target is less than . This implies that the ship is hit by the target.
6.1. Monte-Carlo Simulations
Multiple Monte-Carlo (MC) simulations are needed to prove the effectiveness of the proposed method rigorously since the measurements are noisy. We run MC simulations while changing generated noise.
At the end of each MC simulation, the target hits the ship or is captured by a drone. We use three metrics (, , and ) to analyze the proposed controls.
Let denote the number of MC simulations where the target is captured by a drone. Considering the analysis of MC simulations, presents the capture rate (in percents) as we run MC simulations. It is desirable that the is as large as possible.
Let (m) represent the average distance between the ship and all drones’ center position when an MC simulation ends. In the case where a single drone is considered, represents the average distance between the ship and the drone when an MC simulation ends. Large implies that at the end of a simulation, a drone is far from the ship.
Let denote the average time (in seconds) spent until each MC simulation ends. Note that an MC simulation ends when the target hits the ship or is captured by a drone.
6.2. 3D PNG Law
The target applies the PNG laws in [
20] to approach the ship as time elapses. We briefly introduce the 3D PNG law in [
20]. The rotation vector of the line-of-sight at sample-index
k is
where
is the relative velocity of the ship with respect to the target. Furthermore,
, and
. The PNG law is set as
where
is a constant. The target’s velocity is updated as
Then, the target’s position is updated using
6.3. Scenario 1
In this scenario, the ship moves at a velocity of (−5,0,0) in m/s.
We set
in Equation (
4). This implies that we use
drones in total.
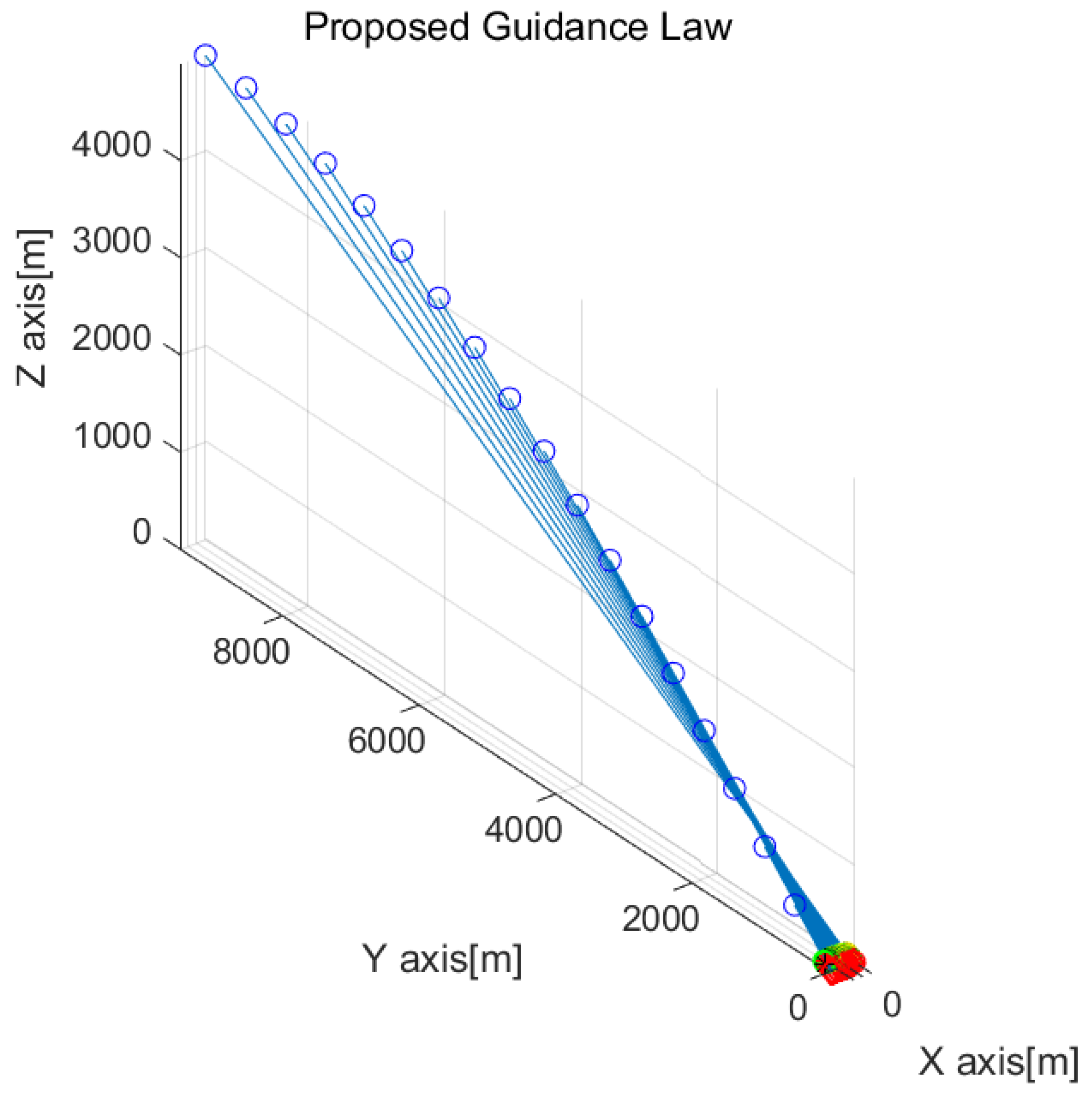
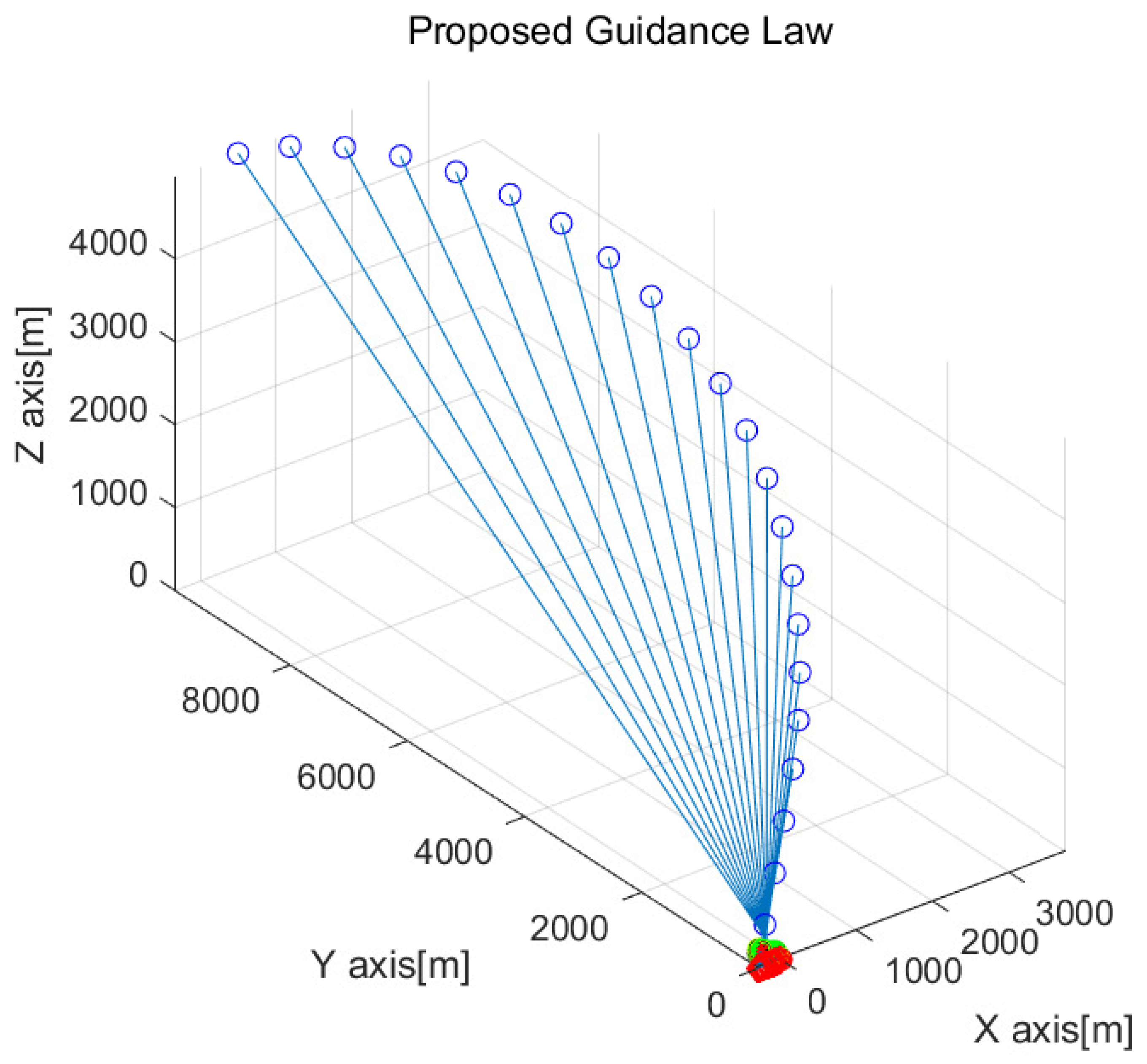
Figure 4 shows the result of one MC simulation using nine drones. In
Figure 4, the target’s position at every 3 s is marked as blue circles. The position of every drone at every 3 s is depicted as circles with distinct colors. A red asterisk depicts the position of the virtual agent at every 3 s. The position of the ship at every 3 s is indicated by red diamonds.
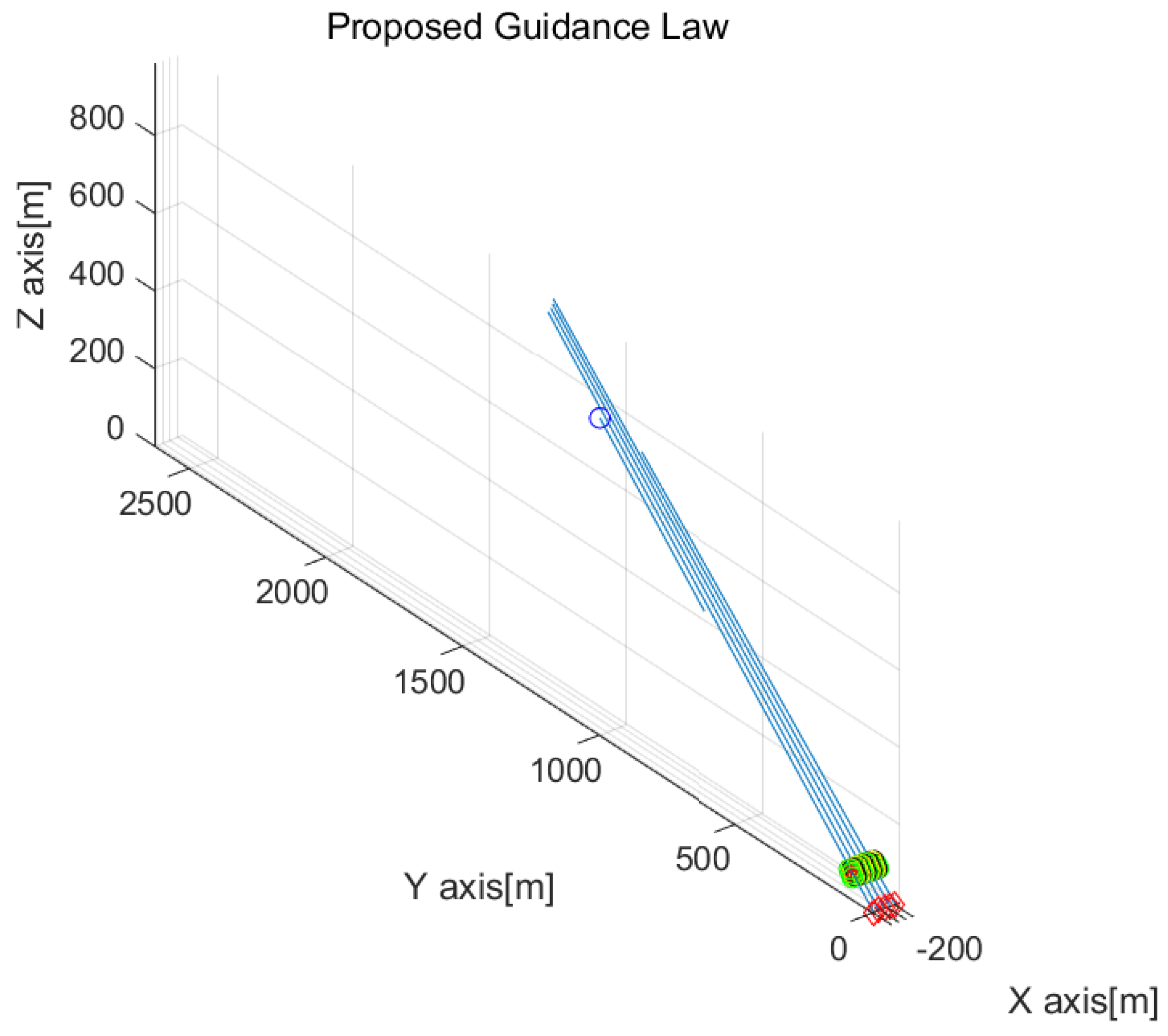
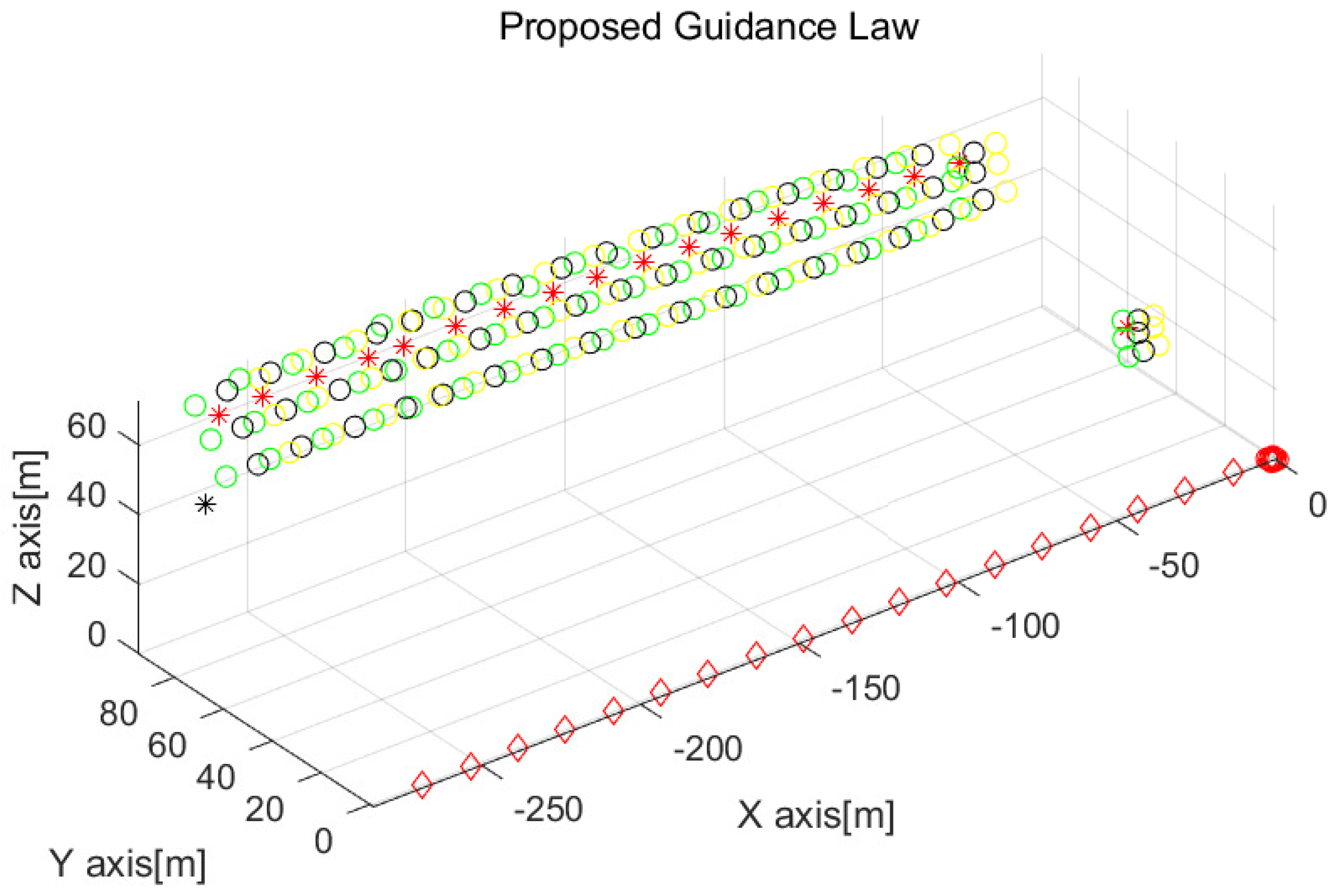
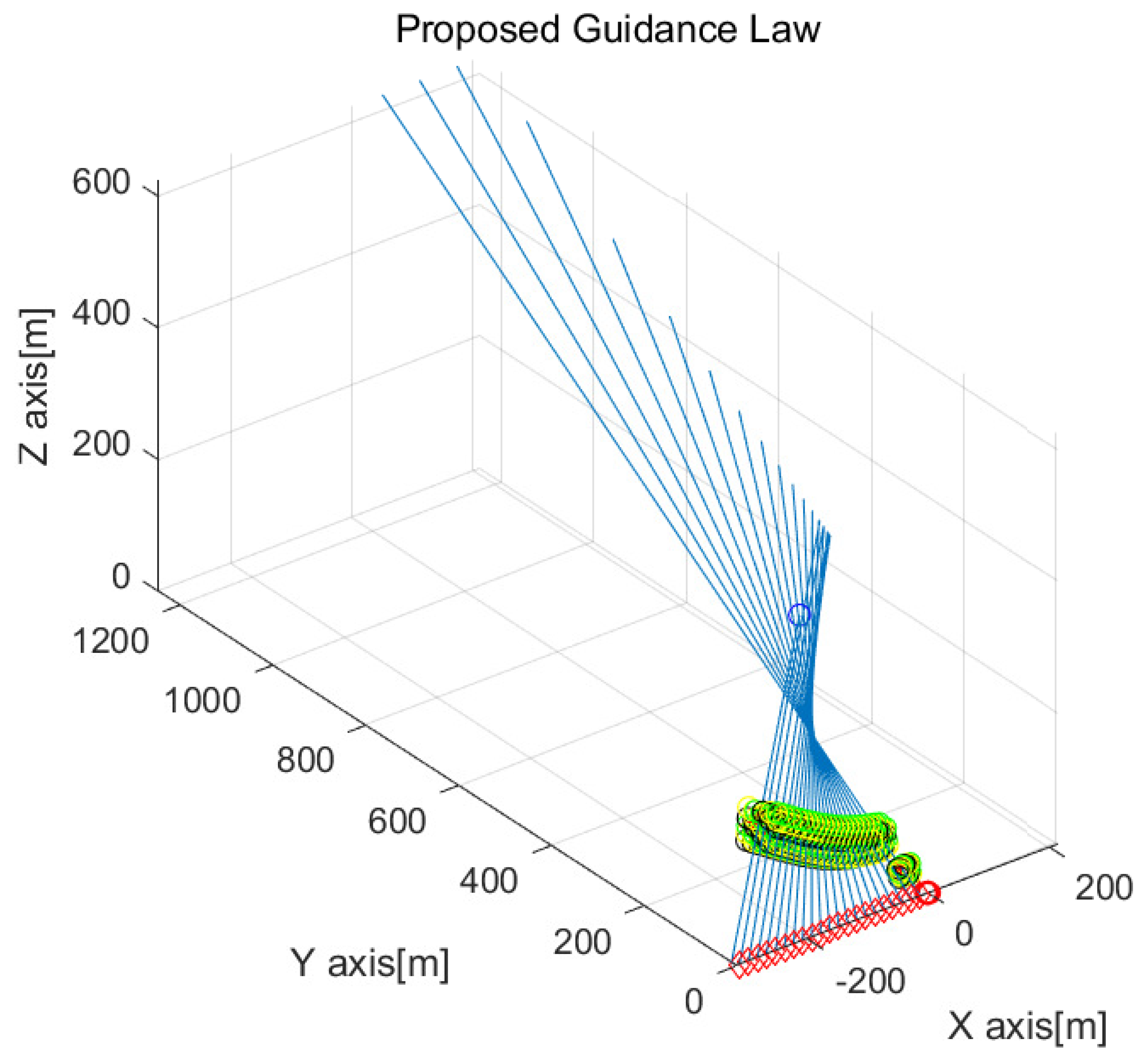
Figure 5 is the enlarged figure of
Figure 4. The position of every drone at every 3 s is depicted as circles with distinct colors. The drones generate a grid formation for protection against the incoming target.
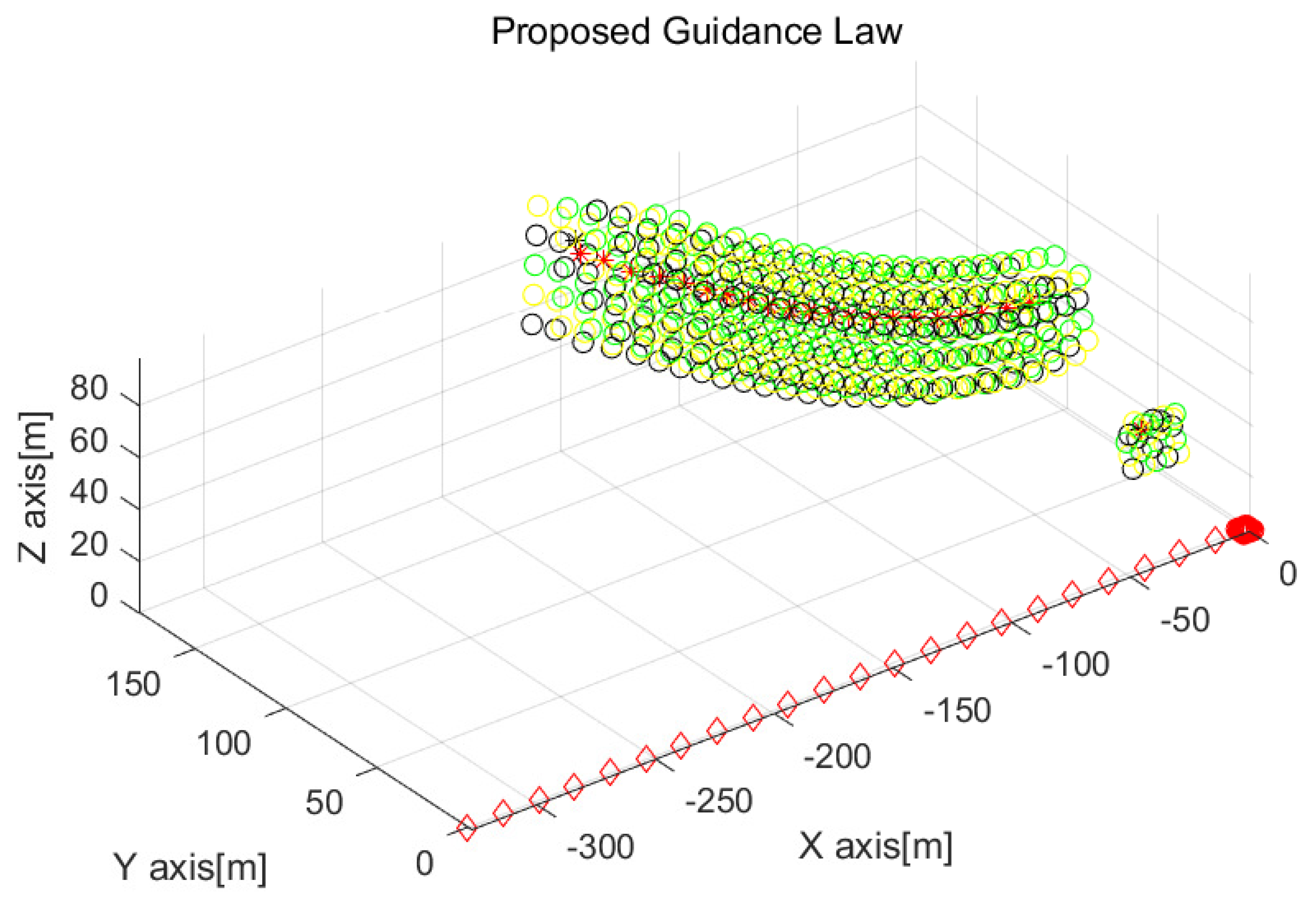
Considering the scenario in
Figure 5,
Figure 6 removes the plots for the target’s positions in order to see the drones’ maneuvers clearly. The position of every drone at every 3 s is depicted as circles with distinct colors. A red asterisk depicts the position of the virtual agent at every 3 s. The position of the ship at every 3 s is indicated by red diamonds. A black asterisk presents the target’s position when the target is hit by a drone.
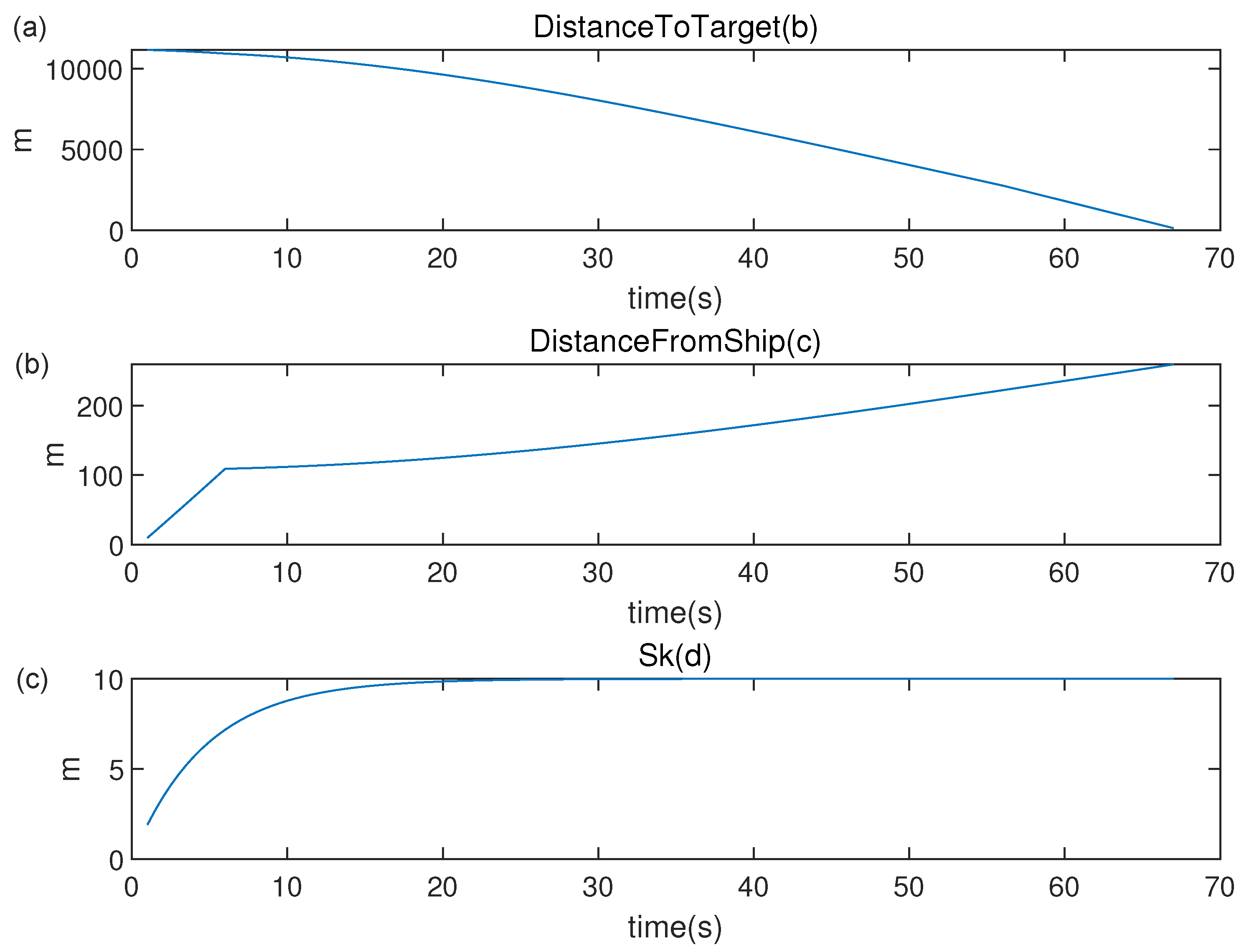
Figure 7a plots the distance between the virtual agent and the target as time elapses. The relative distance keeps decreasing as time elapses.
Figure 7b depicts the distance between the virtual agent and the ship as time elapses. You can see that the virtual agent stays close to the safety distance
while protecting the ship.
Figure 7c depicts the side length as time elapses. As time elapses, the side length increases to
.
6.3.1. The Effect of Changing System PARAMETERS (Number of Drones and Noise Strength)
We discuss the effect of the number of drones. We also present the effect of noise on the control performance. Let
denote the standard deviation of measurement noise. In Equation (
12), the measurement noise
is generated with
, where
is the diagonal matrix such that every diagonal element is
. This implies that the standard deviation of measurement noise is
in meters.
Table 1 summarizes the MC simulation results representing the effect of system parameters. We apply three metrics (
,
, and
) to analyze the proposed controls. As the number of drones increases,
increases in general. This is due to the fact that as we deploy more drones, the area covered by the drones increases. Furthermore, as the measurement noise
increases to 10 meters, the
decreases. Note that an MC simulation ends when the distance between a drone and the target is less than
m.
6.3.2. Comparison with Other State-of-the-Art Guidance Laws (Scenario 1)
To the best of our knowledge, this article is novel in developing a ship defense approach using clustered multiple drones. For comparison, we consider the case where only one drone is used, and the virtual agent applies the 3D PNG law in
Section 6.2 to capture the target. We also consider the case where only one drone is used, and the drone applies the 3D Motion Camouflage Guidance (MCG) law in [
18] to chase the target. We further consider the case where only one drone is used, and the drone applies the 3D Command to Line-Of-Sight (CLOS) guidance law in [
53].
Table 2 shows the MC simulation comparison results of Scenario 1. We run
MC simulations per each control law. Let
indicate the proposed guidance law using
in Equation (
4). Note that only one drone is used in
. Moreover, nine drones are used in
.
In
Table 2,
presents the case where the 3D MCG law is used.
presents the case where the 3D PNG law is used.
presents the case where the 3D CLOS law is used. See that the proposed control outperforms all other state-of-the-art controls.
Note that Equation (
31) can be satisfied even when
. This implies that even slow drones can capture a fast target when the drones stay close to the ship while staying in the lineState at all times. However, other state-of-the-art guidance laws (
,
, and
) make a drone continue to chase the target. This maneuver makes the drone move away from the ship, which is not desirable for capturing a fast target using a slow interceptor.
Other state-of-the-art guidance laws (, , and ) make a single drone chase the target. In our paper, we let multiple drones form a planar grid formation, which can be considered a “net” structure to capture the incoming target. The target may perform elusive maneuvers, and there may be measurement noise in measuring the target position. By maximizing the grid formation size, the capture rate is 100, even when there exists error in the prediction of the target’s position. Since the target is guided to hit its goal (ship), the drones can effectively block the target using this grid formation.
6.4. Scenario 2
We introduce Scenario 2 in
Figure 8. The distinctions of
Figure 8 from
Figure 4 are as follows. As the relative distance between the target and the ship is less than 3000 m, the target moves towards the ship directly while increasing its speed to 240 m/s.
Figure 8 depicts the result of one MC simulation. We set
in Equation (
4), i.e., we use
drones in total. The position of every drone at every 3 s is depicted as circles with distinct colors. A red asterisk depicts the position of the virtual agent at every 3 s.
Figure 8 shows the case where the target is captured by a drone.
Figure 9 is the enlarged figure of
Figure 8. The position of every drone at every 3 s is depicted as circles with distinct colors. See that the grid formation is generated to protect the ship from the incoming target.
Considering the scenario in
Figure 9,
Figure 10 removes the plots for the target’s positions in order to see the drones’ maneuvers clearly. The position of every drone at every 3 s is depicted as circles with distinct colors. A red asterisk depicts the position of the virtual agent at every 3 s. The position of the ship at every 3 s is indicated by red diamonds. A black asterisk presents the target’s position when the target is hit by a drone.
Figure 11a depicts the distance between the virtual agent and the target as time elapses. See that the relative distance continuously decreases over time.
Figure 11b depicts the distance between the virtual agent and the ship as time elapses. See that the virtual agent stays close to the safety distance
while protecting the ship.
Figure 11c depicts the side length as time elapses. As time elapses, the side length increases to
.
Comparison with Other State-of-the-Art Guidance Laws (Scenario 2)
Table 3 shows the MC comparison results of Scenario 2. In this table,
denotes the measurement noise. We run
MC simulations per each control law.
In
Table 3,
indicates the proposed guidance law using
in (
4). Note that only one drone is used in
. Moreover, 25 drones are used in
.
Table 3 shows that the proposed control outperforms all other controls.
,
, and
make a drone keep chasing the target. This maneuver makes the drone move away from the ship, which is not desirable for capturing a fast target using a slow interceptor.
Other state-of-the-art guidance laws (, , and ) make a single drone chase the target. Our strategy is to let multiple drones form a planar grid formation, which can be considered as a “net” for capturing the incoming target. By maximizing the grid formation size, the captureRate is 100 even when there exists error in the prediction of the target’s position.
7. Conclusions
This article introduces a multi-agent guidance law so that a formation of drones protects the ship from an incoming high-speed target. The drones generate a planar grid formation, whose center is guided to remain on the line connecting the target and the ship. Moreover, the planar formation is generated to be perpendicular to the line segment connecting the target and the formation center. Since a target heads towards its goal at least in the terminal phase, maintaining a position on this line segment is effective in protecting the ship.
We enable slow drones to capture a fast target by letting the drones stay close to the ship while staying in the lineState at all times. This blocking strategy is desirable considering the energy consumption of the interceptor since an interceptor does not have to move far from the ship.
We control the drone formation based on the prediction of the target’s position after one sample-index in the future. Since we use a grid formation of drones, we can increase the capture rate even when the target prediction is erroneous.
As far as we know, this article is novel in developing a ship defense approach using multiple clustered drones. In addition, our paper is novel in addressing the 3D formation control that can handle uncertainty in the target prediction. The effectiveness of our multi-agent guidance law is shown by comparing it with other state-of-the-art guidance laws under MATLAB simulations. We verify that the proposed multi-drone guidance scheme increases the capture probability significantly compared to the case where a single interceptor is used. In the future, we will do experiments to verify our multi-agent guidance law using real drones.
In practice, the presence of wind can affect and modify a drone’s path. Many papers handled how to control a drone under the effect of wind [
54,
55,
56,
57,
58]. The authors of [
54] improved the accelerated A-star algorithm with a converted wind vector, and [
55] addressed the problem of a drone’s path planning operating in complex four-dimensional (time and spatially varying) wind-fields. Additionally, refs. [
56,
57,
58] handled adaptive path planning in windy conditions. The authors of [
58] added a wind model to the existing path planning algorithm and combined it with a drone’s control systems. In the future, we will combine the proposed guidance scheme with a wind model so that multiple drones can safely maneuver in time-varying wind-fields.
Note that the proposed guidance scheme can be applied to protect an entity other than a ship, as long as the goal of the target is known a priori. For instance, the proposed multi-agent guidance law can be generalized to protect any vehicles, such as tanks or ground stations.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}