


QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques


Abstract
:1. Introduction
2. QUIC Protocol
3. Related Work
4. Methodology
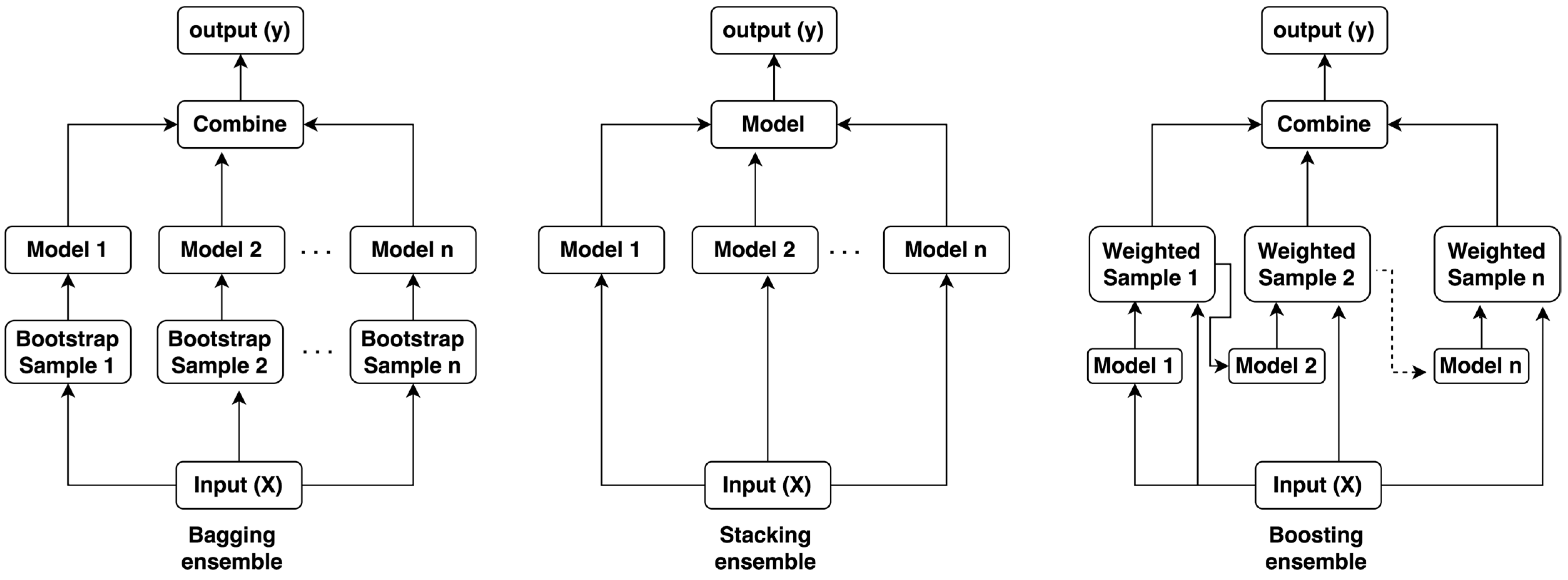
4.1. Ensemble Techniques
4.1.1. Random Forest
4.1.2. Extra Trees
4.1.3. Gradient Boosting Tree
4.1.4. Extreme Gradient Boosting Tree
4.1.5. Light Gradient Boosting Model
4.2. Model Evaluation
5. Experiments
5.1. Environment Setup
5.2. Hyperparameters Selection
- n_estimators: Number of trees in the model.
- criterion: Quality measurement of the split.
- max_depth: Maximum depth of the tree.
- min_samples_split: Minimum number of samples required to split.
- min_samples_leaf: Minimum number of samples required for a leaf.
5.3. Data Preparation
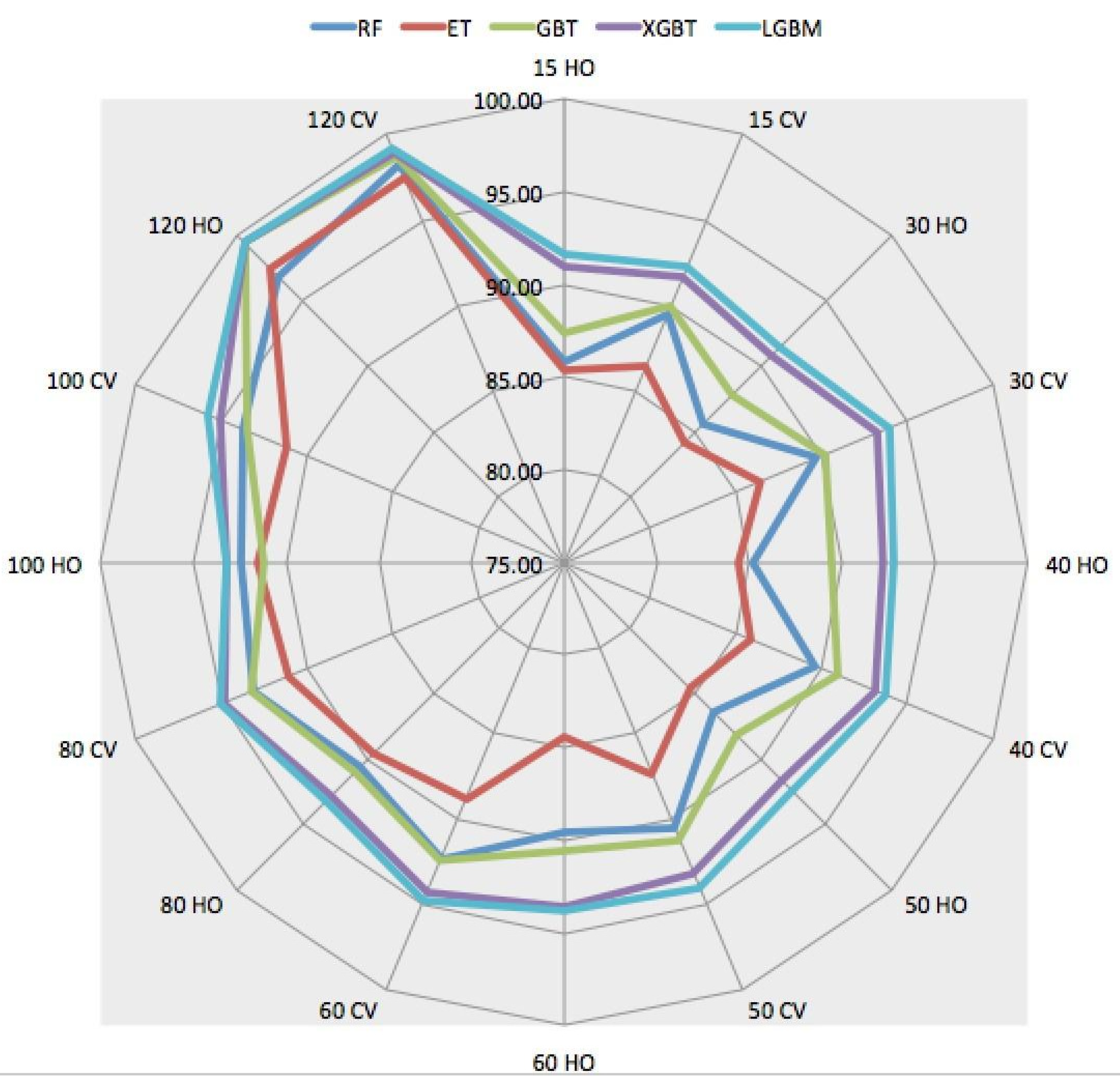
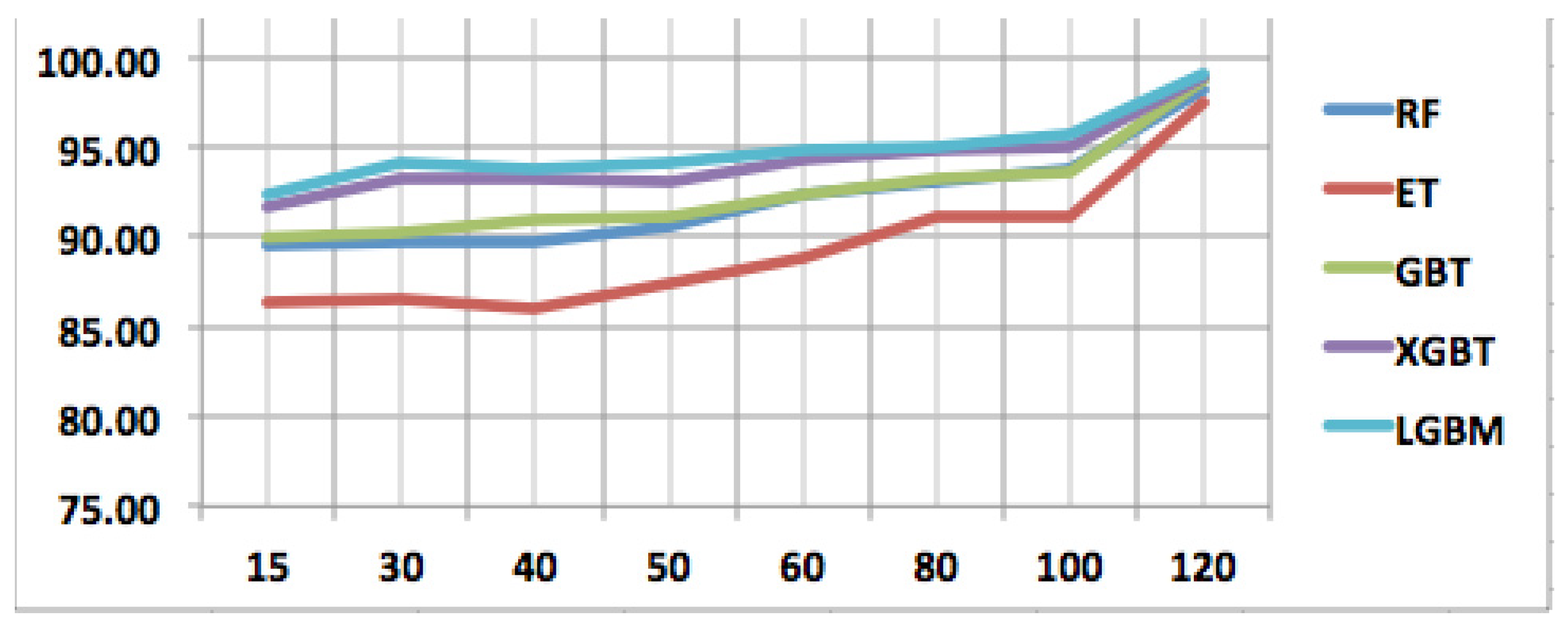
5.4. QUIC Traffic Classification
5.5. Time Cost and Model Size Comparison
5.6. Comparison with Other Works
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, P.; Dezfouli, B. Implementation and analysis of QUIC FOR MQTT. Comput. Netw. 2019, 150, 28–45. [Google Scholar] [CrossRef] [Green Version]
- Erman, J.; Gopalakrishnan, V.; Jana, R.; Ramakrishnan, K.K. Towards a spdy’ier mobile web? IEEE/ACM Trans. Netw. 2015, 23, 2010–2023. [Google Scholar] [CrossRef]
- Langley, A.; Riddoch, A.; Wilk, A.; Vicente, A.; Krasic, C.; Zhang, D.; Yang, F.; Kouranov, F.; Swett, I.; Iyengar, J.; et al. The quic transport protocol: Design and internet-scale deployment. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 183–196. [Google Scholar]
- Al-Bakhat, L.; Almuhammadi, S. Intrusion detection on Quic Traffic: A machine learning approach. In Proceedings of the 2022 7th International Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 1–3 March 2022. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. How to achieve high classification accuracy with just a few labels: A semi-supervised approach using sampled packets. arXiv 2020, arXiv:1812.09761v2. [Google Scholar]
- Sandvine. Global Internet Phenomena Report. 2022. Available online: https://www.sandvine.com/global-internet-phenomena-report-2022 (accessed on 20 February 2023).
- Secchi, R.; Cassara, P.; Gotta, A. Exploring machine learning for classification of QUIC flows over satellite. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Multitask Learning for Network Traffic Classification. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020. [Google Scholar] [CrossRef]
- Akbari, I.; Salahuddin, M.A.; Ven, L.; Limam, N.; Boutaba, R.; Mathieu, B.; Moteau, S.; Tuffin, S. Traffic classification in an increasingly encrypted web. Commun. ACM 2022, 65, 75–83. [Google Scholar] [CrossRef]
- Towhid, M.S.; Shahriar, N. Encrypted network traffic classification using self-supervised learning. In Proceedings of the 2022 IEEE 8th International Conference on Network Softwarization (NetSoft), Milan, Italy, 27 June–1 July 2022. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef] [Green Version]
- Iyengar, J.; Thomson, M. QUIC: A UDP-Based Multiplexed and Secure Transport. In RFC 9000. 2021. Available online: https://datatracker.ietf.org/doc/rfc9000/ (accessed on 20 February 2023).
- Tong, V.; Tran, H.A.; Souihi, S.; Mellouk, A. A novel quic traffic classifier based on convolutional neural networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic 516classification using Deep Learning. Soft Comput. 2019, 24, 1999–2012. [Google Scholar] [CrossRef] [Green Version]
- Williams, N.; Zander, S.; Armitage, G. A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification. ACM SIGCOMM Comput. Commun. Rev. 2006, 36, 5–16. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Network traffic classifier with convolutional and recurrent neural networks for internet of things. IEEE Access 2017, 5, 18042–18050. [Google Scholar] [CrossRef]
- Izadi, S.; Ahmadi, M.; Nikbazm, R. Network traffic classification using convolutional neural network and ant-lion optimization. Comput. Electr. Eng. 2022, 101, 108024. [Google Scholar] [CrossRef]
- Izadi, S.; Ahmadi, M.; Rajabzadeh, A. Network traffic classification using Deep Learning Networks and bayesian data fusion. J. Netw. Syst. Manag. 2022, 30, 25. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, Y.; Li, J.; Sun, C.; Zhang, S. A deep learning-based encrypted VPN traffic classification method using packet block image. Electronics 2022, 12, 115. [Google Scholar] [CrossRef]
- Liu, W.; Zhu, C.; Ding, Z.; Zhang, H.; Liu, Q. Multiclass imbalanced and Concept Drift Network traffic classification framework based on online active learning. Eng. Appl. Artif. Intell. 2022, 117, 105607. [Google Scholar] [CrossRef]
- Bühlmann, P. Bagging, boosting and ensemble methods. In Handbook of Computational Statistics; Springer: Berlin/Heidelberg, Germany, 2012; pp. 985–1022. [Google Scholar]
- Zhang, C.; Ma, Y. Ensemble Machine Learning: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E. The boosting approach to machine learning: An overview. In Nonlinear Estimation and Classification; Springer: New York, NY, USA, 2003; pp. 149–171. [Google Scholar]
- Chen, J.; Huang, H.; Cohn, A.G.; Zhang, D.; Zhou, M. Machine learning-based classification of rock discontinuity trace: SMOTE oversampling integrated with GBT ensemble learning. Int. J. Min. Sci. Technol. 2022, 32, 309–322. [Google Scholar] [CrossRef]
- Chen, T.; He, T. Higgs boson discovery with boosted trees. In Proceedings of the NIPS 2014 Workshop on High-Energy Physics and Machine Learning, Montreal, QC, Canada, 13 December 2014; pp. 69–80. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016; Volume 785, p. 794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | n_Estimators | Criterion | Max Depth | Min Samples Split | Min Samples Leaf |
|---|---|---|---|---|---|
| RF | 100 | Gini | None | 2 | 1 |
| ET | 100 | Gini | None | 2 | 1 |
| GBT | 100 | friedman_mse | 3 | 2 | 1 |
| XGBT | 100 | friedman_mse | 3 | 2 | 1 |
| LGBM | 100 | friedman_mse | 3 | 2 | 1 |
| Traffic | Label | Training Size | Testing Size | Sum |
|---|---|---|---|---|
| Google Drive | 1 | 1434 | 100 | 1534 |
| YouTube | 2 | 877 | 100 | 977 |
| Google Doc | 3 | 1021 | 100 | 1121 |
| Google Search | 4 | 1715 | 100 | 1815 |
| Google Music | 5 | 392 | 100 | 492 |
| Total | 5439 | 500 | 5939 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 87.61 | 85.80 | 85.59 | 85.80 | 89.47 | 9.63 |
| ET | 86.67 | 85.40 | 85.24 | 85.40 | 86.43 | 3.59 |
| GBT | 88.30 | 87.40 | 87.37 | 87.40 | 89.96 | 58.01 |
| XGBT | 91.52 | 91.00 | 91.02 | 91.00 | 91.67 | 50.16 |
| LGBM | 91.94 | 91.60 | 91.61 | 91.60 | 92.31 | 22.7 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 87.42 | 85.60 | 85.30 | 85.60 | 89.72 | 12.52 |
| ET | 85.39 | 84.20 | 84.00 | 84.20 | 86.45 | 6.53 |
| GBT | 88.70 | 87.80 | 87.76 | 87.80 | 90.22 | 117.76 |
| XGBT | 91.56 | 90.80 | 90.75 | 90.80 | 93.29 | 77.58 |
| LGBM | 92.15 | 91.40 | 91.34 | 91.40 | 94.04 | 29.70 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 86.92 | 85.20 | 84.95 | 85.20 | 89.70 | 13.94 |
| ET | 85.66 | 84.40 | 84.12 | 84.40 | 85.95 | 4.48 |
| GBT | 90.23 | 89.40 | 89.31 | 89.40 | 90.99 | 155.32 |
| XGBT | 93.07 | 92.20 | 92.17 | 92.20 | 93.20 | 105.12 |
| LGBM | 93.31 | 92.80 | 92.77 | 92.80 | 93.80 | 35.94 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 88.00 | 86.40 | 86.24 | 86.40 | 90.51 | 15.44 |
| ET | 85.52 | 84.60 | 84.36 | 84.60 | 87.42 | 5.09 |
| GBT | 89.02 | 88.20 | 88.12 | 88.20 | 91.21 | 199.23 |
| XGBT | 92.26 | 91.60 | 91.58 | 91.60 | 93.14 | 119.82 |
| LGBM | 92.79 | 92.40 | 92.36 | 92.40 | 94.04 | 41.13 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 89.83 | 89.60 | 89.54 | 89.60 | 92.37 | 16.86 |
| ET | 84.55 | 84.40 | 84.22 | 84.40 | 88.86 | 7.06 |
| GBT | 90.92 | 90.60 | 90.55 | 90.60 | 92.41 | 239.78 |
| XGBT | 93.83 | 93.60 | 93.58 | 93.60 | 94.30 | 149.52 |
| LGBM | 94.03 | 93.80 | 93.77 | 93.80 | 94.80 | 49.70 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 91.06 | 90.60 | 90.57 | 90.60 | 93.11 | 18.35 |
| ET | 89.92 | 89.60 | 89.56 | 89.60 | 91.06 | 5.88 |
| GBT | 91.69 | 91.00 | 90.98 | 91.00 | 93.25 | 317.11 |
| XGBT | 93.32 | 92.80 | 92.79 | 92.80 | 94.80 | 174.21 |
| LGBM | 93.50 | 93.20 | 93.16 | 93.20 | 95.05 | 58.53 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 92.91 | 92.40 | 92.39 | 92.40 | 93.82 | 20.30 |
| ET | 92.00 | 91.60 | 91.54 | 91.60 | 91.17 | 7.00 |
| GBT | 92.19 | 91.20 | 91.23 | 91.20 | 93.53 | 393.74 |
| XGBT | 93.84 | 93.20 | 93.16 | 93.20 | 95.07 | 202.63 |
| LGBM | 93.66 | 93.20 | 93.17 | 93.20 | 95.79 | 70.22 |
| Model | Precision | Recall | F1-Score | Accuracy | 10-Fold Cross- Validation Acc. | Training Time (s) |
|---|---|---|---|---|---|---|
| RF | 96.93 | 96.80 | 96.78 | 96.80 | 98.24 | 14.67 |
| ET | 97.48 | 97.40 | 97.40 | 97.40 | 97.43 | 8.17 |
| GBT | 99.40 | 99.40 | 99.40 | 99.40 | 98.66 | 523.32 |
| XGBT | 99.40 | 99.40 | 99.40 | 99.40 | 98.92 | 156.47 |
| LGBM | 99.41 | 99.40 | 99.40 | 99.40 | 99.12 | 69.46 |
| Ref. | Year | Dataset | Algorithms | Main Objective | Score |
|---|---|---|---|---|---|
| [9] | 2022 | Orange’20, UC Davis QUIC [5] | CNN and Stacked LSTM | Encrypted web traffic classification | 99.37% (Acc.) |
| [10] | 2022 | Orange’20, UC Davis QUIC [5], ISCX | ResNet34 | Encrypted network traffic classification | 99.24% (Acc.) |
| [8] | 2020 | UC Davis QUIC [5] | CNN | Network traffic classification | 90.00% (Acc.) |
| Proposed work | UC Davis QUIC [5] | RF, ET GBT, XGBT, LGBM | Encrypted traffic classification | 99.40 (Acc.) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almuhammadi, S.; Alnajim, A.; Ayub, M. QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques. Appl. Sci. 2023, 13, 4725. https://doi.org/10.3390/app13084725
Almuhammadi S, Alnajim A, Ayub M. QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques. Applied Sciences. 2023; 13(8):4725. https://doi.org/10.3390/app13084725
Chicago/Turabian StyleAlmuhammadi, Sultan, Abdullatif Alnajim, and Mohammed Ayub. 2023. "QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques" Applied Sciences 13, no. 8: 4725. https://doi.org/10.3390/app13084725
APA StyleAlmuhammadi, S., Alnajim, A., & Ayub, M. (2023). QUIC Network Traffic Classification Using Ensemble Machine Learning Techniques. Applied Sciences, 13(8), 4725. https://doi.org/10.3390/app13084725