
Rainfall Similarity Search Based on Deep Learning by Using Precipitation Images


Abstract
:1. Introduction
2. Related Studies
2.1. Image Feature Extraction
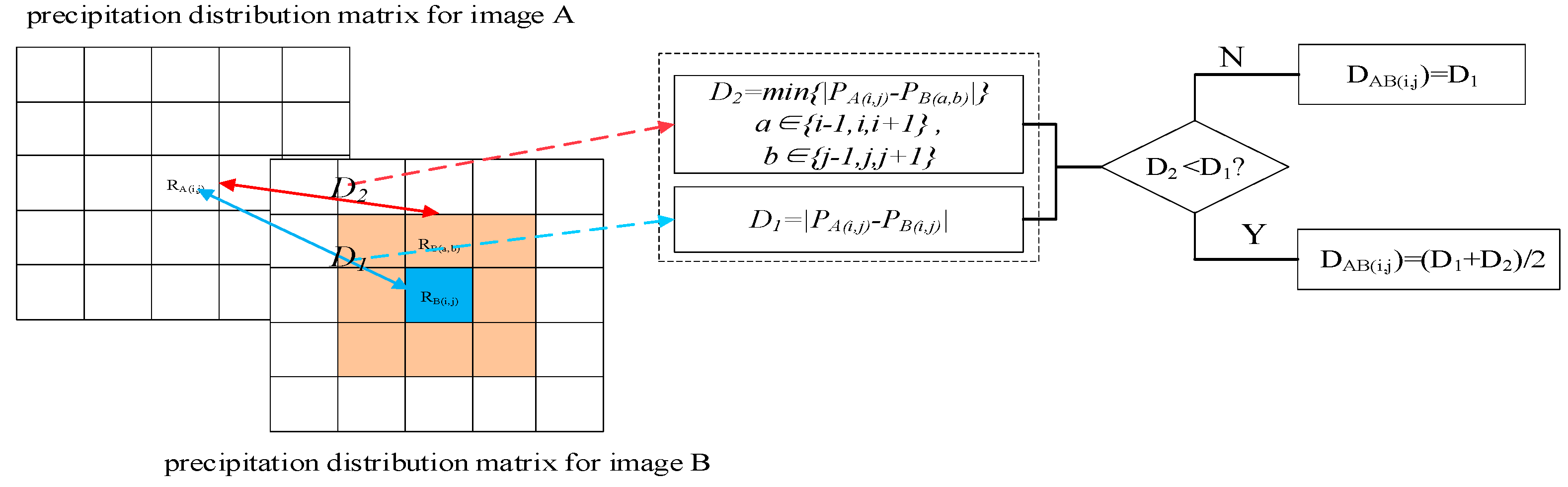
2.2. Similarity Search
2.3. Deep Learning
3. Rainfall Similarity Search Based on NDCG-IPSO
3.1. Feature Extraction
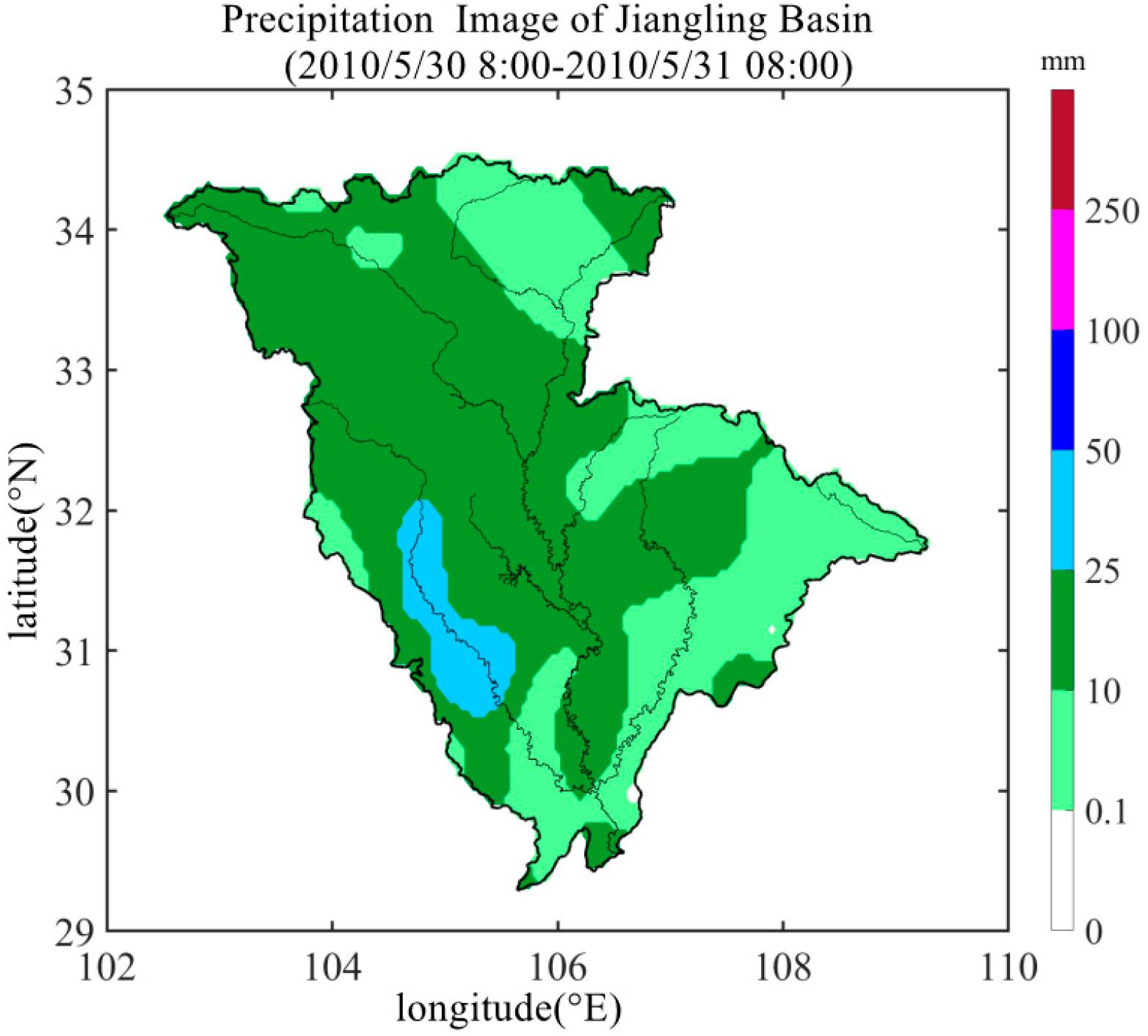
3.1.1. Regional Precipitation
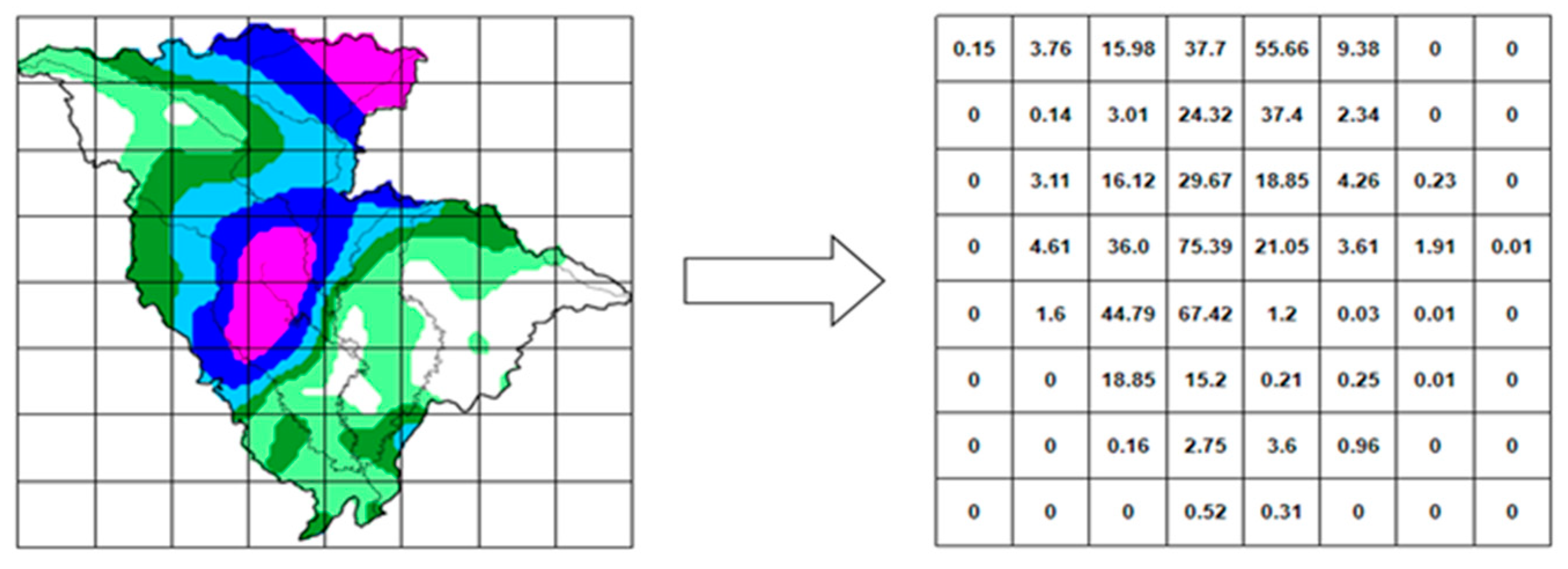
3.1.2. Precipitation Distribution
3.1.3. Precipitation Center
3.2. Image Similarity Search Based on NDCG-IPSO
3.2.1. Evaluation Metrics
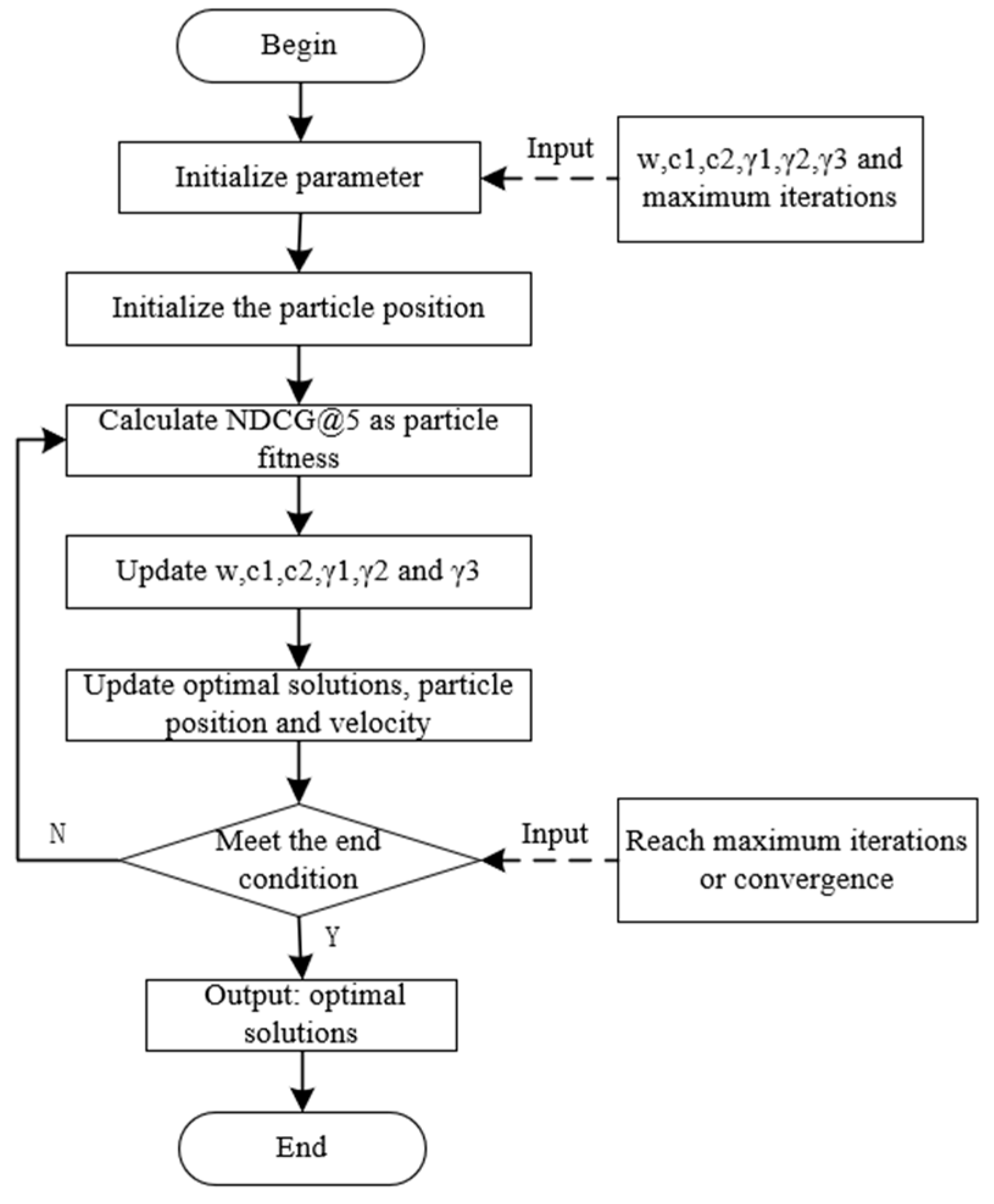
3.2.2. Parameter Optimization
- Inertia weight w;
- Learning ratio c1 and c2;
4. Experiment and Result Analysis
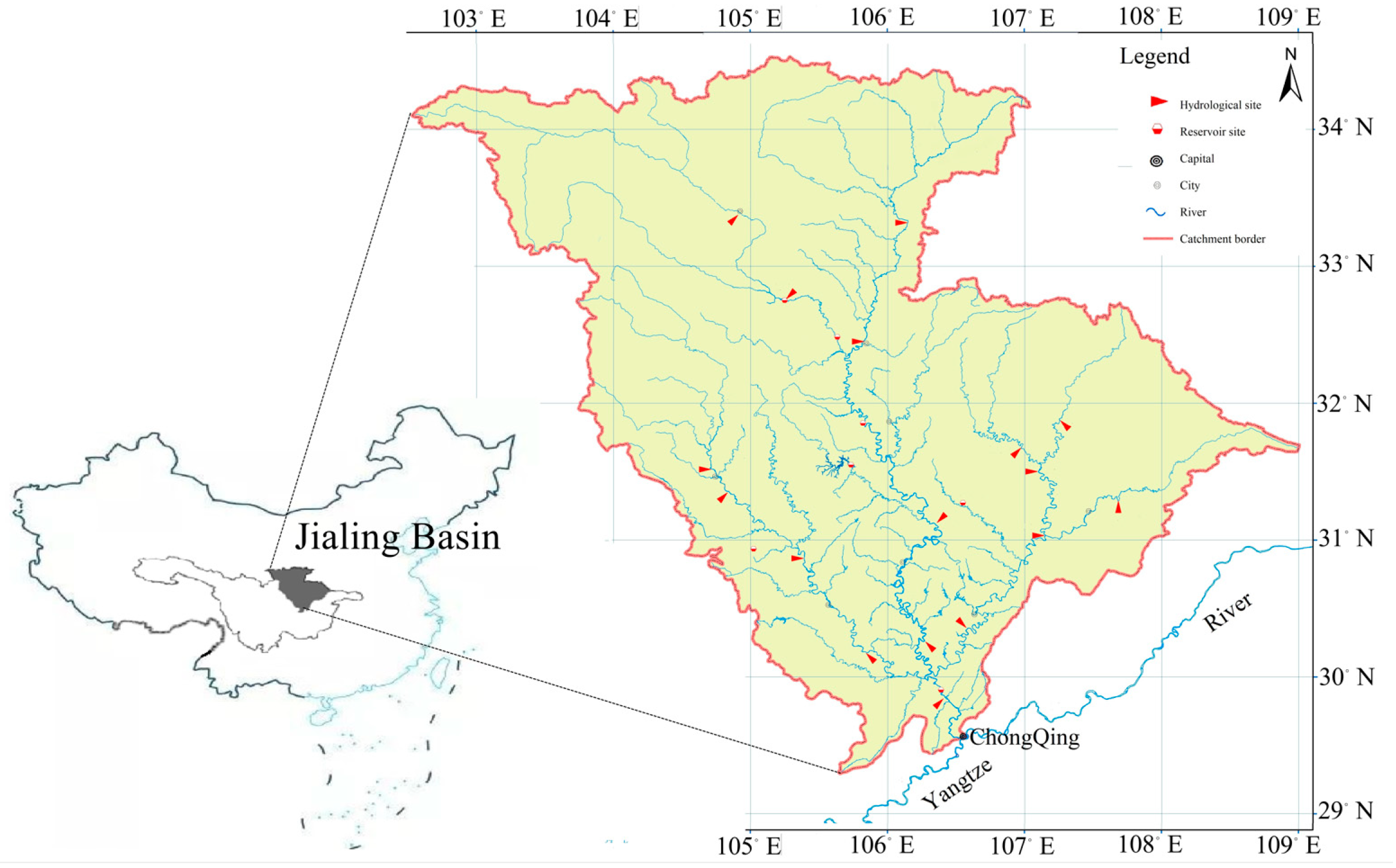
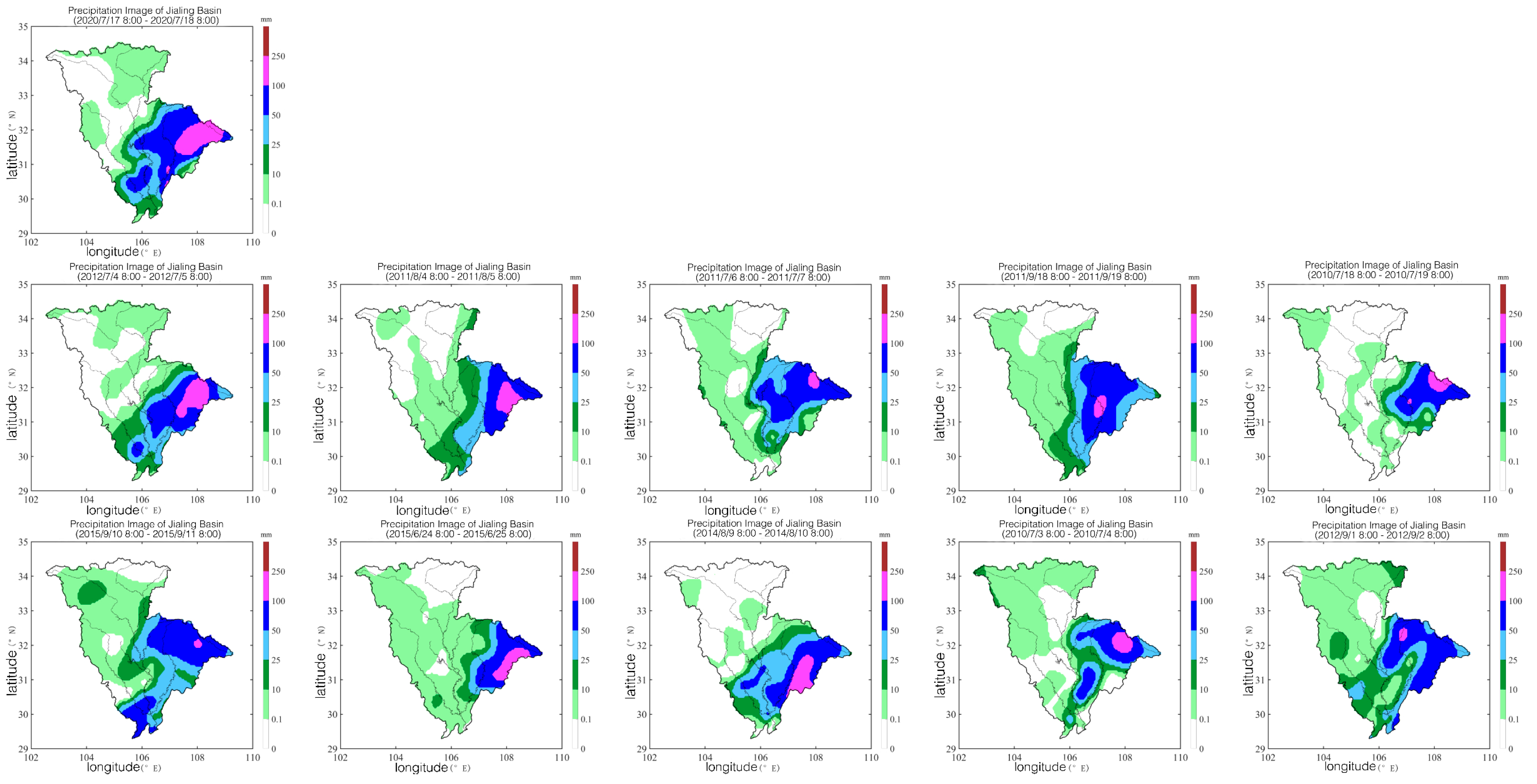
4.1. Study Area and Data Preprocessing
4.2. Results Analysis
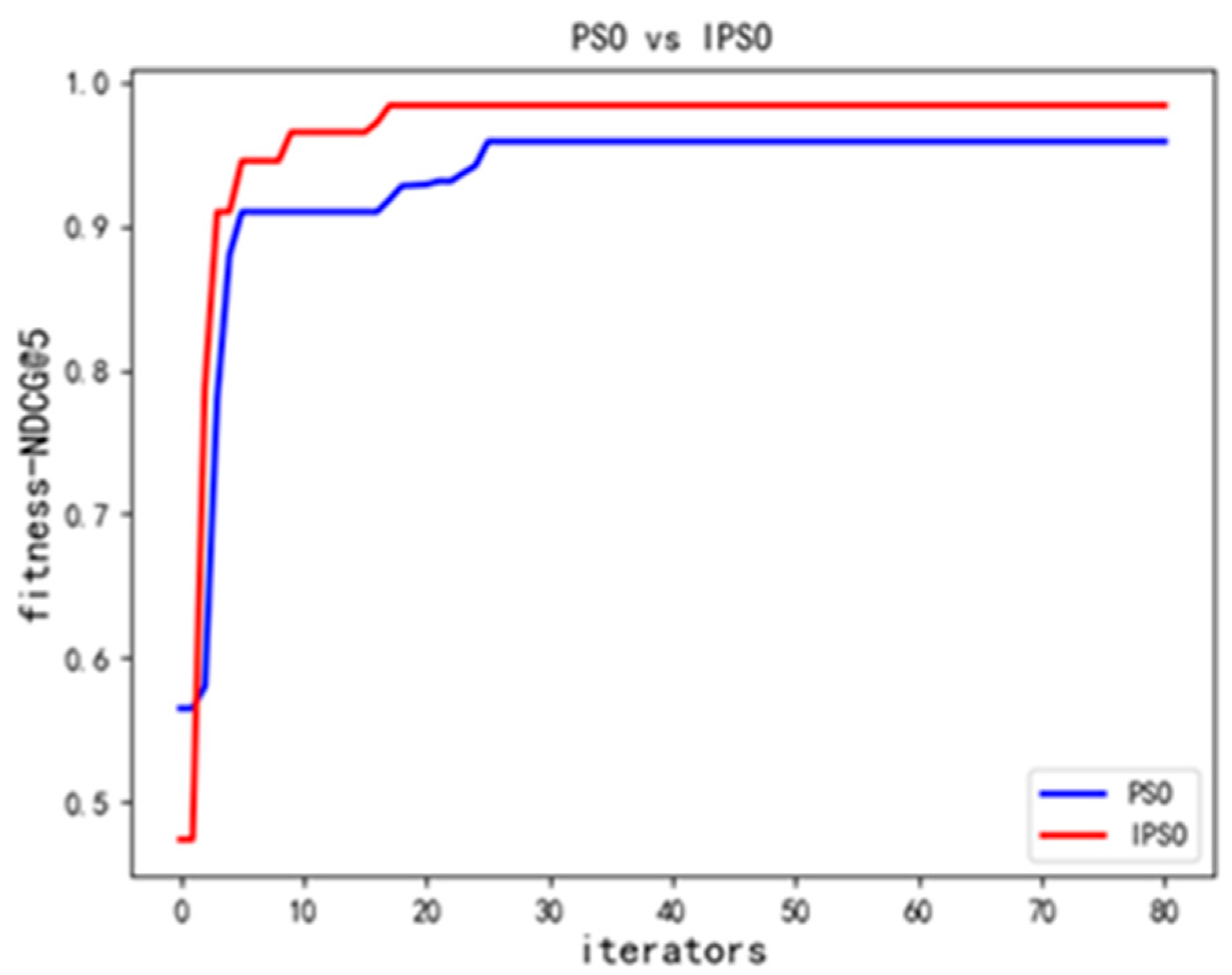
4.3. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, B.; Liang, Z.; Bao, Z.; Wang, J.; Hu, Y. Changes in streamflow and sediment for a planned large reservoir in the middle Yellow River. Land Degrad. Dev. 2019, 30, 878–893. [Google Scholar] [CrossRef] [Green Version]
- Stenta, H.R.; Riccardi, G.A.; Basile, P.A. Grid size effects analysis and hydrological similarity of surface runoff in flatland basins. Hydrol. Sci. J. 2017, 62, 1736–1754. [Google Scholar] [CrossRef]
- Liang, Z.; Xiao, Z.; Wang, J.; Sun, L.; Li, B.; Hu, Y.; Wu, Y. An improved chaos similarity model for hydrological forecasting. J. Hydrol. 2019, 577, 123953. [Google Scholar] [CrossRef]
- Dilmi, D.; Barthès, L.; Mallet, C.; Aymeric, C. Modified DTW for a quantitative estimation of the similarity between rainfall time series. EGU Gen. Assem. 2017, 19, EGU2017-16005. [Google Scholar]
- Xiao, Z.; Liang, Z.; Li, B.; Hou, B. New flood early warning and forecasting method based on similarity theory. J. Hydrol. Eng. 2019, 24, 04019023. [Google Scholar] [CrossRef] [Green Version]
- Barthel, R.; Haaf, E.; Giese, M.; Nygren, M.; Heudorfer, B.; Stahl, K. Similarity-based approaches in hydrogeology: Proposal of a new concept for data-scarce groundwater resource characterization and prediction. Hydrogeol. J. 2021, 29, 1693–1709. [Google Scholar] [CrossRef]
- Wang, H.; Xing, C.; Yu, F. Study of the hydrological time series similarity search based on Daubechies wavelet transform. In Unifying Electrical Engineering and Electronics Engineering, Proceedings of the 2012 International Conference on Electrical and Electronics Engineering, London, UK, 4–6 July 2012; Springer: New York, NY, USA, 2013; pp. 2051–2057. [Google Scholar]
- Yang, J.; Wan, D.; Yu, Y. Similarity Search Method of Hydrological Time Series based on Fragment Alignment Distance and Dynamic Time Warping. In Proceedings of the IEEE 2022 5th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Wuhan, China, 22–24 April 2022; pp. 214–220. [Google Scholar]
- Zhang, L.; Zhu, Y.; Li, S.; Gao, X. Study on Similarity Model of Precipitation Series Based on Precipitation Type Histogram. J. China Hydrol. 2013, 33, 10–16. [Google Scholar]
- Ohno, G.; Kazunori, I. Flood Forecast Based on Deep Learning Using Distribution MAP of Precipitation. In Proceedings of the 22nd IAHR APD Congress, Sapporo, Japan, 14–17 September 2020. [Google Scholar]
- Wang, X.; Liu, Y.; Chen, Y.; Liu, Y. An adaptive density-based time series clustering algorithm: A case study on rainfall patterns. ISPRS Int. J. Geo-Inf. 2016, 5, 205. [Google Scholar] [CrossRef] [Green Version]
- Gang, J.; Zhao, W. RETRACTED ARTICLE: Remote sensing image-based rainfall changes in plain areas and IoT motion image detection. Arab. J. Geosci. 2021, 14, 1–17. [Google Scholar] [CrossRef]
- Pradhan, J.; Kumar, S.; Pal, A.K.; Banka, H. Texture and colour region separation based image retrieval using probability annular histogram and weighted similarity matching scheme. IET Image Process. 2020, 14, 1303–1315. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, L.; Berretti, S.; Wan, S. Medical Image Encryption by Content-Aware DNA Computing for Secure Healthcare. IEEE Trans. Ind. Inform. 2023, 19, 2089–2098. [Google Scholar] [CrossRef]
- Divakar, R.; Singh, B.; Bajpai, A.; Kumar, A. Image pattern recognition by edge detection using discrete wavelet transforms. J. Decis. Anal. Intell. Comput. 2022, 2, 26–35. [Google Scholar]
- Alsmadi, M.K. Content-based image retrieval using color, shape and texture descriptors and features. Arab. J. Sci. Eng. 2020, 45, 3317–3330. [Google Scholar] [CrossRef]
- Kumbure, M.M.; Luukka, P. A generalized fuzzy k-nearest neighbor regression model based on Minkowski distance. Granul. Comput. 2022, 7, 657–671. [Google Scholar] [CrossRef]
- Gassouma, M.S.; Benhamed, A.; El Montasser, G. Investigating similarities between Islamic and conventional banks in GCC countries: A dynamic time warping approach. Int. J. Islam. Middle East. Financ. Manag. 2023, 16, 103–129. [Google Scholar] [CrossRef]
- Ristad, E.S.; Yianilos, P.N. Learning String-Edit Distance. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 20, 522–532. [Google Scholar] [CrossRef] [Green Version]
- Benti, N.E.; Chaka, M.D.; Semie, A.G. Forecasting Renewable Energy Generation with Machine learning and Deep Learning: Current Advances and Future Prospects. Preprints.org 2023, 2023030451. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Frana, R.P.; Monteiro, A.; Arthur, R.; Lano, Y. An overview of deep learning in big data, image, and signal processing in the modern digital age. Trends Deep. Learn. Methodol. 2021, 63–87. [Google Scholar] [CrossRef]
- Wu, Y.; Guo, H.; Chakraborty, C.; Khosravi, M.; Berretti, S.; Wan, S. Edge Computing Driven Low-Light Image Dynamic Enhancement for Object Detection. IEEE Trans. Netw. Sci. Eng. 2022, 3151502. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Paramanik, A.R.; Sarkar, S.; Sarkar, B. OSWMI: An Objective-Subjective Weighted method for Minimizing Inconsistency in multi-criteria decision making. Comput. Ind. Eng. 2022, 169, 108138. [Google Scholar] [CrossRef]
- Furui, K.; Ohue, M. Compound virtual screening by learning-to-rank with gradient boosting decision tree and enrichment-based cumulative gain. In Proceedings of the 2022 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Ottawa, ON, Canada, 15–17 August 2022; pp. 1–7. [Google Scholar]
- Feng, K.; Li, X.; Qian, X.; Wu, L.; Zheng, H.; Chen, M.; Li, M.; Liu, B. Atmospheric Optical Turbulence Profile Model Fitting Based on Improved Particle Swarm Algorithm. Laser Optoelectron. Prog. 2022, 59, 73–84. [Google Scholar]
- Liu, C.; Sui, X.; Kuang, X.; Liu, Y.; Gu, G.; Chen, Q. Optimized Contrast Enhancement for Infrared Images Based on Global and Local Histogram Specification. Remote Sens. 2019, 11, 849. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Sun, X.; Gao, B.; Zhou, J. Weighted Histogram Block Detection Algorithm for Digital Trunking Terminal. In Proceedings of the International Conference on Intelligent Automation and Soft Computing, Chicago, IL, USA, 28–30 May 2021; Springer: Cham, Switzerland, 2021; pp. 166–172. [Google Scholar]
- Muhammad, M.; Oscar, V. Pairwise consensus and the Borda rule. Math. Soc. Sci. 2022, 116, 17–21. [Google Scholar]
- Boudou, A.; Viguier-Pla, S. Principal components analysis and cyclostationarity. J. Multivar. Anal. 2022, 189, 104875. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Distance | γ1 | γ2 | γ3 |
|---|---|---|---|
| coefficient | 0.46 | 0.12 | 0.42 |
| Accuracy | NDCG@5 | NDCG@10 | |
|---|---|---|---|
| Images | |||
| Training sample | 0.984 | 0.978 | |
| Test sample | 0.978 | 0.964 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; He, X.; Zhu, Y.; Wan, D. Rainfall Similarity Search Based on Deep Learning by Using Precipitation Images. Appl. Sci. 2023, 13, 4883. https://doi.org/10.3390/app13084883
Yu Y, He X, Zhu Y, Wan D. Rainfall Similarity Search Based on Deep Learning by Using Precipitation Images. Applied Sciences. 2023; 13(8):4883. https://doi.org/10.3390/app13084883
Chicago/Turabian StyleYu, Yufeng, Xingu He, Yuelong Zhu, and Dingsheng Wan. 2023. "Rainfall Similarity Search Based on Deep Learning by Using Precipitation Images" Applied Sciences 13, no. 8: 4883. https://doi.org/10.3390/app13084883
APA StyleYu, Y., He, X., Zhu, Y., & Wan, D. (2023). Rainfall Similarity Search Based on Deep Learning by Using Precipitation Images. Applied Sciences, 13(8), 4883. https://doi.org/10.3390/app13084883