2.3.1. Database Preparation
The main step to obtaining an artificial intelligence model is to have a sufficiently large and complete database to allow training, validation, and testing of a model as efficiently as possible. To obtain the most valid results, the RF signal database called “RADIOML 2018.01A” [
27], which was created and used for the first time in paper [
12], was chosen as a starting point.
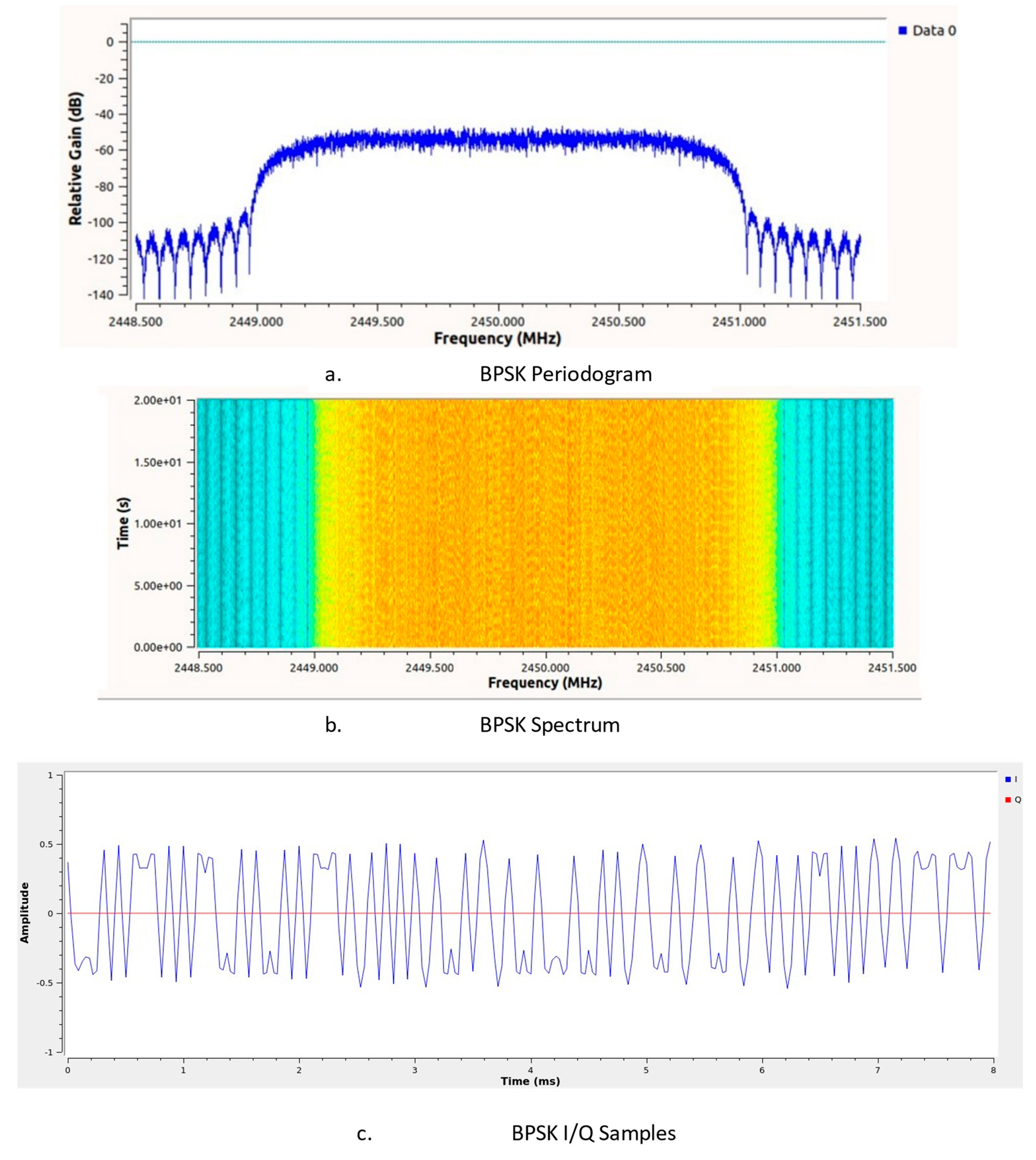
In this database, we find signals that are modulated using the following 24 modulation schemes: OOK, 4ASK, 8ASK, BPSK, QPSK, 8PSK, 16PSK, 32PSK, 16APSK, 32APSK, 64APSK, 128APSK, 16QAM, 32QAM, 64QAM, 128QAM, 256QAM, AM-SSB-WC, AM-SSB-SC, AM-DSB-WC, AM-DSB-SC, FM, GMSK, and OQPSK.
All these data are saved in the “hdf5” file format used especially for keeping multidimensional data strings. The data are split into three strings, each of which is used to describe a specific detail about the database. After analyzing the file, the following details about the three strings were extracted:
The first string has 2,555,904 recordings, each having 1024 complex elements. These elements represent the modulated signal samples.
The second string has the same number of elements in which the type of modulation the signal has is noted.
The third string has the same size as the previous two, these containing a single element, each having values starting with −20 and ending with 30 signifying the SNR level in dB at which the signal was acquired.
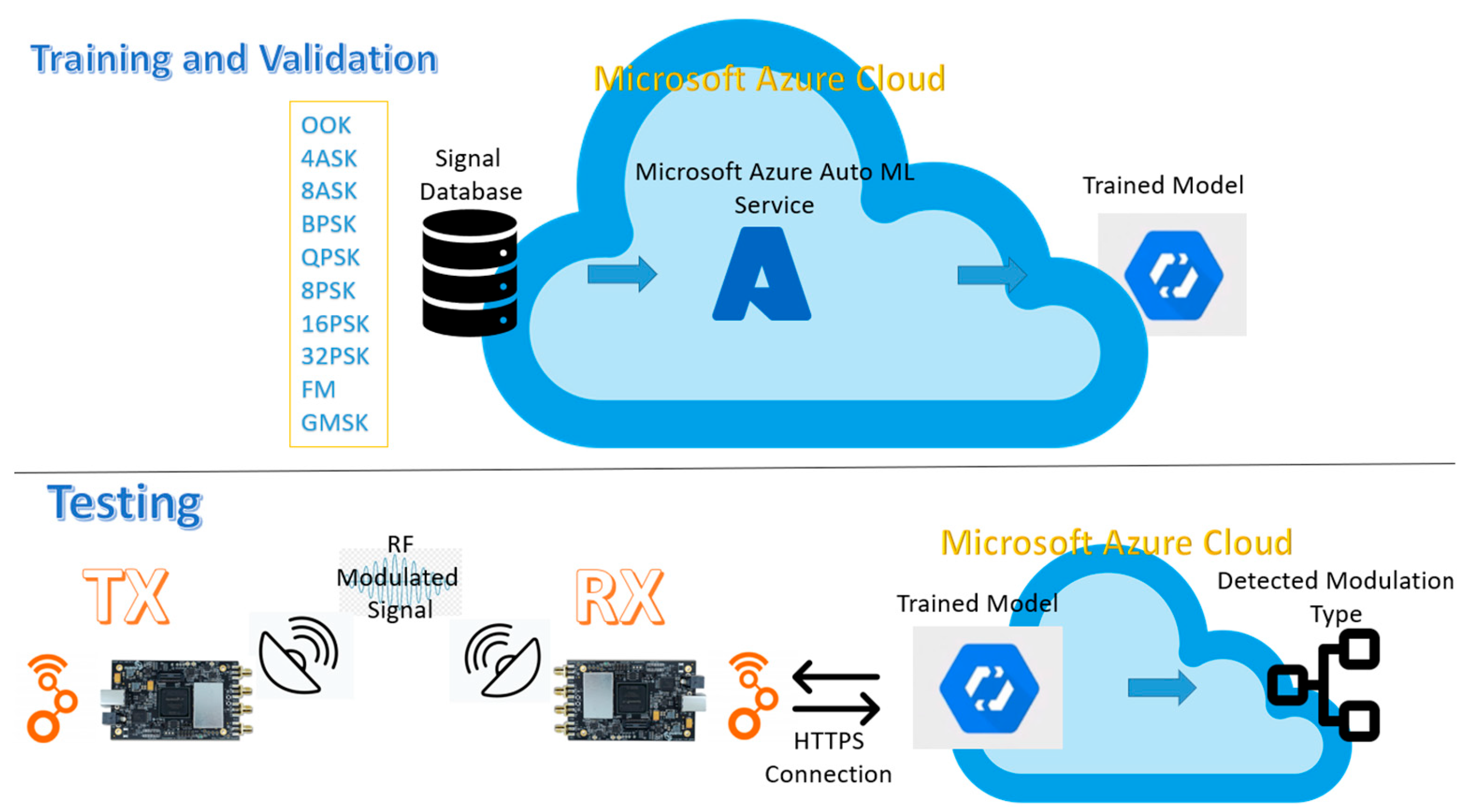
To obtain the desired dataset for training the artificial network, only records for the following ten modulation classes were extracted from the database: OOK, 4ASK, 8ASK, BPSK, QPSK, 8PSK, 16PSK, 32PSK, FM, and GMSK. Additionally, these are the investigations and research scenarios used in our paper. Only these ten modulations were selected because they are enough to validate our approach, and many of them are used in mobile communications.
For each of these 10 classes, 1024 training records and 256 testing records were extracted for each of the SNR levels between [2 dB, 30 dB]. A total of 153,600 records are available for training and 38,400 for testing, with each of them having 1024 complex elements.
It was decided to use a smaller number of modulation classes at higher SNR levels to obtain a model that performs better at high SNR. However, if the SNR is low, the detection rate of any intelligent network is very low because the modulation pattern is not easily detected; this can be seen in [
12,
15].
In order to extract the samples from the dataset, a shell script was used. The script has put the data in a separate folder for each modulation and inside the modulation folder in separate folders for test and training. The extracted complex data is written to a “CSV” (comma-separated values) file, which is the final database that is used for training, validation, and testing. In
Table 2, the internal structure and content of the database can be seen.
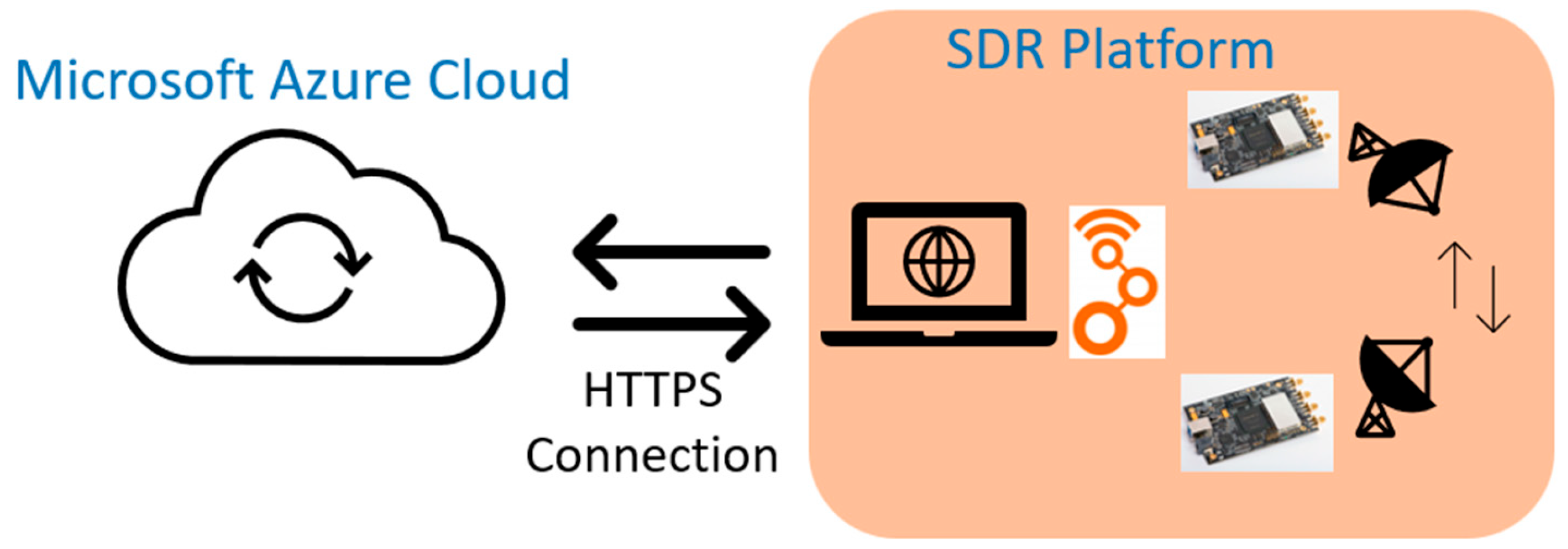
The extracted data is written in a “CSV” file to ensure compatibility with the “Azure AutoML” service that is used to train and integrate the intelligent network. It must be clearly defined which data constitutes the inputs from which the characteristics necessary for training will be extracted and which data represent the outputs according to which the classification of the obtained results will be carried out.
Each signal describing a modulation type consists of 1024 complex values. These complex values are divided into the real part and the imaginary part of the complex number. These are then arranged in rows describing each of the 1024 real values and 1024 complex values. Each column has a header describing the index of each value. At the end, a final column is inserted where the type of signal characterized by the input values is described.
The headers are very important because they are used to train and then validate and test the AI model.
2.3.2. Network Training
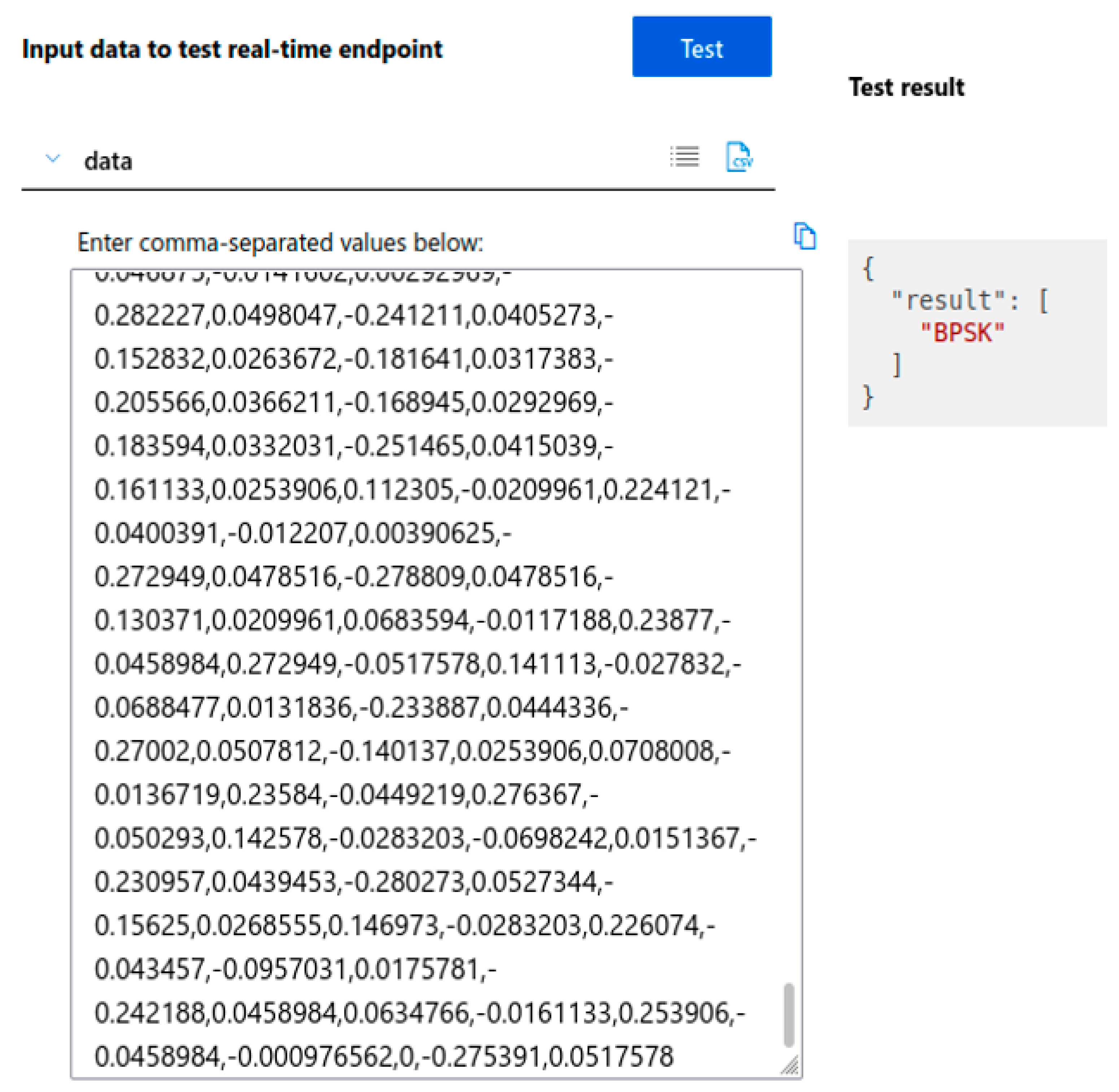
Automated ML functionality from the “Microsoft Azure AutoML” service was used to define, train, test, and validate the intelligent network. After the definition of the new model has been started, the database that is used for training and validation is chosen. The next step is to analyze the data to identify potential problems. As possible problems, the following can be mentioned: missing data in certain columns, not all input data having the same format, or for some input data, we do not have output data.
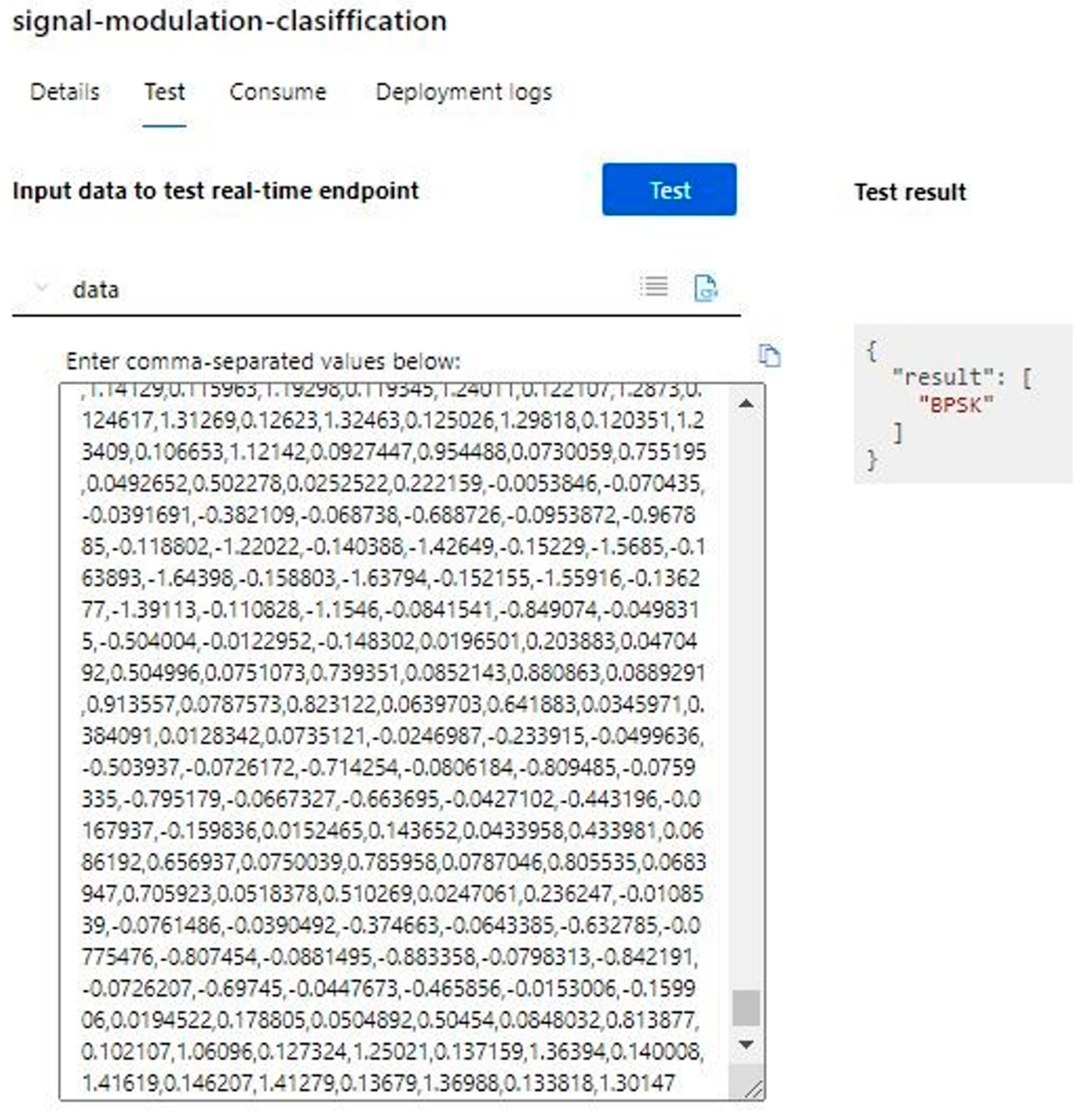
The training is configured to be performed using “Signal Type” as the target column. This column describes the type of signal that is characterized by the input data. As hardware support, a virtual machine is used with a 6-core CPU, 28 GB RAM (random-access memory), and 56 GB (gigabyte) storage memory.
To configure the model training, three options are available. From the three options, the model that performs data classification based on the input data is chosen. The “Deep Learning” option is also enabled to ensure a better extraction of the model’s features and to obtain a more efficient trained model. The first additional setting configured is the metric used. Accuracy is chosen because it best characterizes the model to be implemented. By accuracy, what is meant is the number of correctly predicted input data out of the total amount of data. It is chosen to use all possible algorithms to see exactly which one is the most efficient. The running time is set to the maximum possible of 24 h, which is the maximum training time offered for a model where the “Deep Learning” option is activated. No step is set for the validation metric, trying to obtain a result as close to perfection as possible. After all configuration work is complete, the training process is started.
The training process begins by checking several elements. The first thing that is checked is whether the input data is divided in an approximately equal way for each signal type. The second checked element is the lack of samples in any of the input vectors. The last element checked is if one or multiple samples from the input vectors have a value too high that may bias the detection result in a wrong way. By a much too high value is understood the fact that this value has an order of magnitude two or more times higher than the other samples from the rest of the data vectors. This value can spoil the detection because the model resulting from training with this data will always expect certain samples from the input data to have such high values, which will not happen if the data are correct.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}